利用Redis实现数据缓存
目录
1 为啥要缓存捏?
2 基本流程(以查询商铺信息为例)
3 实现数据库与缓存双写一致
3.1 内存淘汰
3.2 超时剔除(半自动)
3.3 主动更新(手动)
3.3.1 双写方案
3.3.2 读写穿透方案
3.3.3 写回方案
4 缓存穿透的解决方案
1)缓存空对象
2)布隆过滤
(缓存空对象)解决缓存穿透问题流程
5 缓存雪崩解决方案
6 缓存击穿的解决方案
6.1 基于互斥锁解决缓存击穿问题
6.2 基于逻辑过期解决缓存击穿问题
7 缓存工具封装
1 为啥要缓存捏?
速度快,好用
缓存数据存储于代码中,而代码运行在内存中,内存的读写性能远高于磁盘,缓存可以大大降低用户访问并发量带来的服务器读写压力
实际开发过程中,企业的数据量,少则几十万,多则几千万,这么大数据量,如果没有缓存来作为"避震器",系统是几乎撑不住的,所以企业会大量运用到缓存技术

2 基本流程(以查询商铺信息为例)

3 实现数据库与缓存双写一致
首先我们需要明确数据一致性问题的主要原因是什么,从主要原因入手才是解决问题的关键!数据一致性的根本原因是 缓存和数据库中的数据不同步,那么我们该如何让 缓存 和 数据库 中的数据尽可能的即时同步?这就需要选择一个比较好的缓存更新策略了
常见的缓存更新策略:

3.1 内存淘汰
利用Redis的内存淘汰机制实现缓存更新,Redis的内存淘汰机制是当Redis发现内存不足时,会根据一定的策略自动淘汰部分数据
这种策略模型优点在于没有维护成本,但是内存不足这种无法预定的情况就导致了缓存中会有很多旧的数据,数据一致性差。
Redis中常见的淘汰策略:
1 noeviction(默认):当达到内存限制并且客户端尝试执行写入操作时,Redis 会返回错误信息,拒绝新数据的写入,保证数据完整性和一致性
2 allkeys-lru:从所有的键中选择最近最少使用(Least Recently Used,LRU)的数据进行淘汰。即优先淘汰最长时间未被访问的数据
3 allkeys-random:从所有的键中随机选择数据进行淘汰
4 volatile-lru:从设置了过期时间的键中选择最近最少使用的数据进行淘汰
5 volatile-random:从设置了过期时间的键中随机选择数据进行淘汰
6 volatile-ttl:从设置了过期时间的键中选择剩余生存时间(Time To Live,TTL)最短的数据进行淘汰
3.2 超时剔除(半自动)
手动给缓存数据添加TTL,到期后Redis自动删除缓存
这种策略数据一致性一般,维护成本有但是较低,一般用于兜底方案~
3.3 主动更新(手动)
手动编码实现缓存更新,在修改数据库的同时更新缓存
这种策略数据一致性就是最高的(毕竟自己动手,丰衣足食),但同时维护成本也是最高的。
3.3.1 双写方案
1)读取(Read):当需要读取数据时,首先检查缓存是否存在该数据。如果缓存中存在,直接返回缓存中的数据。如果缓存中不存在,则从底层数据存储(如数据库)中获取数据,并将数据存储到缓存中,以便以后的读取操作可以更快地访问该数据。
2)写入(Write):当进行数据写入操作时,首先更新底层数据存储中的数据。然后,根据具体情况,可以选择直接更新缓存中的数据(使缓存与底层数据存储保持同步),或者是简单地将缓存中与修改数据相关的条目标记为无效状态(缓存失效),以便下一次读取时重新加载最新数据
!在更新数据的情况下 优先选择删除缓存模式 其次是更新缓存模式
问题:操作时,先操作数据库还是先操作缓存捏?
答案:先操作数据库,再删缓存
如果先操作缓存:先删缓存,再更新数据库
当线程1删除缓存到更新数据库之间的时间段,会有其它线程进来查询数据,由于没有加锁,且前面的线程将缓存删除了,这就导致请求会直接打到数据库上,给数据库带来巨大压力。这个事件发生的概率很大,因为缓存的读写速度块,而数据库的读写较慢。
这种方式的不足之处:存在缓存击穿问题,且概率较大
如果先操作数据库:先更新数据库,再删缓存
当线程1在查询缓存且未命中,此时线程1查询数据,查询完准备写入缓存时,由于没有加锁线程2乘虚而入,线程2在这期间对数据库进行了更新,此时线程1将旧数据返回了,出现了脏读,这个事件发生的概率很低,因为先是需要满足缓存未命中,且在写入缓存的那段时间内有一个线程进行更新操作,缓存的读写和查询很快,这段空隙时间很小,所以出现脏读现象的概率也很低
这种方式的不足之处:存在脏读现象,但概率较小
要保证两个操作同时操作 在单体项目中可以放在同一个事务中
3.3.2 读写穿透方案
将读取和写入操作首先在缓存中执行,然后再传播到数据存储
1)读取穿透(Read Through):当进行读取请求时,首先检查缓存。如果所请求的数据在缓存中找到,直接返回数据。如果缓存中没有找到数据,则将请求转发给数据存储以获取数据。获取到的数据随后存储在缓存中,然后返回给调用者。
2)写入穿透(Write Through):当进行写入请求时,首先将数据写入缓存。缓存立即将写操作传播到数据存储,确保缓存和数据存储之间的数据保持一致。这样保证了后续的读取请求从缓存中返回更新后的数据。
3.3.3 写回方案
调用者只操作缓存,其他线程去异步处理数据库,实现最终一致
1)读取(Read):先检查缓存中是否存在数据,如果不存在,则从底层数据存储中获取数据,并将数据存储到缓存中。
2)写入(Write):先更新底层数据存储,然后将待写入的数据放入一个缓存队列中。在适当的时机,通过批量操作或异步处理,将缓存队列中的数据写入底层数据存储
-
主动更新策略中三种方案的应用场景:
- 双写方案 较适用于读多写少的场景,数据的一致性由应用程序主动管理
- 读写穿透方案 适用于数据实时性要求较高、对一致性要求严格的场景
- 写回方案 适用于追求写入性能的场景,对数据的实时性要求相对较低、可靠性也相对低
-
更新策略的应用场景:
- 对于低一致性需求,可以使用内存淘汰机制。例如店铺类型数据的查询缓存
- 对于高一致性需求,可以采用主动更新策略,并以超时剔除作为兜底方案。例如店铺详情数据查询的缓存
4 缓存穿透的解决方案
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
常见解决缓存穿透的解决方案:
1)缓存空对象
就是给redis缓存一个空对象并设置TTL存活时间
优点:实现简单,维护方便
缺点:额外的内存消耗,可能造成短期的不一致
2)布隆过滤
通俗的说,就是中间件~
优点:内存占用较少,没有多余key
缺点:实现复杂,存在误判可能(有穿透的风险),无法删除数据

上面两种方式都是被动的解决缓存穿透方案,此外我们还可以采用主动的方案预防缓存穿透,比如:增强id的复杂度避免被猜测id规律、做好数据的基础格式校验、加强用户权限校验、做好热点参数的限流
(缓存空对象)解决缓存穿透问题流程

5 缓存雪崩解决方案
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
就是说,一群设置了有效期的key同时消失了,或者说redis罢工了,导致所有的或者说大量的请求会给数据库带来巨大压力叫做缓存雪崩~
- 缓存雪崩的常见解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略,比如快速失败机制,让请求尽可能打不到数据库上
- 给业务添加多级缓存
6 缓存击穿的解决方案
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
大概击穿流程:
第一个线程,查询redis发现未命中,然后去数据库查询并重建缓存,这个时候因为在缓存重建业务较为复杂的情况下,重建时间较久,又因为高并发的环境下,在线程1重建缓存的时间内,会有其他的大量的其他线程进来,发现查找缓存仍未命中,导致继续重建,如此死循环。

缓存击穿的常见解决方案:
互斥锁(时间换空间)
优点:内存占用小,一致性高,实现简单
缺点:性能较低,容易出现死锁
逻辑过期(空间换时间)
优点:性能高
缺点:内存占用较大,容易出现脏读
两者相比较,互斥锁更加易于实现,但是容易发生死锁,且锁导致并行变成串行,导致系统性能下降,逻辑过期实现起来相较复杂,且需要耗费额外的内存,但是通过开启子线程重建缓存,使原来的同步阻塞变成异步,提高系统的响应速度,但是容易出现脏读
6.1 基于互斥锁解决缓存击穿问题
就是当线程查询缓存未命中时,尝试去获取互斥锁,然后在重建缓存数据,在这段时间里,其他线程也会去尝试获取互斥锁,如果失败就休眠一段时间,并继续,不断重试,等到数据重建成功,其他线程就可以命中数据了。这样就不会导致缓存击穿。这个方案数据一致性是绝对的,但是相对来说会牺牲性能。
这里我们获取互斥锁可以使用redis中string类型中的setnx方法 ,因为setnx方法是在key不存在的情况下才可以创建成功的,所以我们重建缓存时,使用setnx来将锁的数据加入到redis中,并且通过判断这个锁的key是否存在,如果存在就是获取锁成功,失败就是获取失败,这样刚好可以实现互斥锁的效果。
释放锁就更简单了,直接删除我们存入的锁的key来释放锁。
//获取锁public Boolean tryLock(String key){Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);return BooleanUtil.isTrue(flag);}//释放锁方法public void unlock(String key){stringRedisTemplate.delete(key);}
6.2 基于逻辑过期解决缓存击穿问题
给redis缓存字段中添加一个过期时间,然后当线程查询缓存的时候,先判断是否已经过期,如果过期,就获取互斥锁,并开启一个子线程进行缓存重建任务,直到子线程完成任务后,释放锁。在这段时间内,其他线程获取互斥锁失败后,并不是继续等待重试,而是直接返回旧数据。这个方法虽然性能较好,但也牺牲了数据一致性。
所谓的逻辑过期,类似于逻辑删除,并不是真正意义上的过期,而是新增一个字段,用来标记key的过期时间,这样能能够避免key过期而被自动删除,这样数据就永不过期了,从根本上解决因为热点key过期导致的缓存击穿。一般搞活动时,比如抢优惠券,秒杀等场景,请求量比较大就可以使用逻辑过期,等活动一过就手动删除逻辑过期的数据
逻辑过期一定要先进行数据预热,将我们热点数据加载到缓存中
逻辑过期时间根据具体业务而定,逻辑过期过长,会造成缓存数据的堆积,浪费内存,过短造成频繁缓存重建,降低性能,所以设置逻辑过期时间时需要实际测试和评估不同参数下的性能和资源消耗情况,可以通过观察系统的表现,在业务需求和性能要求之间找到一个平衡点

7 缓存工具封装
调用者
/*** 根据id查询商铺数据** @param id* @return*/@Overridepublic Result queryById(Long id) {// 调用解决缓存穿透的方法
// Shop shop = cacheClient.handleCachePenetration(CACHE_SHOP_KEY, id, Shop.class,
// this::getById, CACHE_SHOP_TTL, TimeUnit.MINUTES);
// if (Objects.isNull(shop)){
// return Result.fail("店铺不存在");
// }// 调用解决缓存击穿的方法Shop shop = cacheClient.handleCacheBreakdown(CACHE_SHOP_KEY, id, Shop.class,this::getById, CACHE_SHOP_TTL, TimeUnit.SECONDS);if (Objects.isNull(shop)) {return Result.fail("店铺不存在");}return Result.ok(shop);}
工具类
@Component
@Slf4j
public class CacheClient {private final StringRedisTemplate stringRedisTemplate;public CacheClient(StringRedisTemplate stringRedisTemplate) {this.stringRedisTemplate = stringRedisTemplate;}/*** 将数据加入Redis,并设置有效期** @param key* @param value* @param timeout* @param unit*/public void set(String key, Object value, Long timeout, TimeUnit unit) {stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), timeout, unit);}/*** 将数据加入Redis,并设置逻辑过期时间** @param key* @param value* @param timeout* @param unit*/public void setWithLogicalExpire(String key, Object value, Long timeout, TimeUnit unit) {RedisData redisData = new RedisData();redisData.setData(value);// unit.toSeconds()是为了确保计时单位是秒redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(timeout)));stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), timeout, unit);}/*** 根据id查询数据(处理缓存穿透)** @param keyPrefix key前缀* @param id 查询id* @param type 查询的数据类型* @param dbFallback 根据id查询数据的函数* @param timeout 有效期* @param unit 有效期的时间单位* @param <T>* @param <ID>* @return*/public <T, ID> T handleCachePenetration(String keyPrefix, ID id, Class<T> type,Function<ID, T> dbFallback, Long timeout, TimeUnit unit) {String key = keyPrefix + id;// 1、从Redis中查询店铺数据String jsonStr = stringRedisTemplate.opsForValue().get(key);T t = null;// 2、判断缓存是否命中if (StrUtil.isNotBlank(jsonStr)) {// 2.1 缓存命中,直接返回店铺数据t = JSONUtil.toBean(jsonStr, type);return t;}// 2.2 缓存未命中,判断缓存中查询的数据是否是空字符串(isNotBlank把null和空字符串给排除了)if (Objects.nonNull(jsonStr)) {// 2.2.1 当前数据是空字符串(说明该数据是之前缓存的空对象),直接返回失败信息return null;}// 2.2.2 当前数据是null,则从数据库中查询店铺数据t = dbFallback.apply(id);// 4、判断数据库是否存在店铺数据if (Objects.isNull(t)) {// 4.1 数据库中不存在,缓存空对象(解决缓存穿透),返回失败信息this.set(key, "", CACHE_NULL_TTL, TimeUnit.SECONDS);return null;}// 4.2 数据库中存在,重建缓存,并返回店铺数据this.set(key, t, timeout, unit);return t;}/*** 缓存重建线程池*/public static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);/*** 根据id查询数据(处理缓存击穿)** @param keyPrefix key前缀* @param id 查询id* @param type 查询的数据类型* @param dbFallback 根据id查询数据的函数* @param timeout 有效期* @param unit 有效期的时间单位* @param <T>* @param <ID>* @return*/public <T, ID> T handleCacheBreakdown(String keyPrefix, ID id, Class<T> type,Function<ID, T> dbFallback, Long timeout, TimeUnit unit) {String key = keyPrefix + id;// 1、从Redis中查询店铺数据,并判断缓存是否命中String jsonStr = stringRedisTemplate.opsForValue().get(key);if (StrUtil.isBlank(jsonStr)) {// 1.1 缓存未命中,直接返回失败信息return null;}// 1.2 缓存命中,将JSON字符串反序列化未对象,并判断缓存数据是否逻辑过期RedisData redisData = JSONUtil.toBean(jsonStr, RedisData.class);// 这里需要先转成JSONObject再转成反序列化,否则可能无法正确映射Shop的字段JSONObject data = (JSONObject) redisData.getData();T t = JSONUtil.toBean(data, type);LocalDateTime expireTime = redisData.getExpireTime();if (expireTime.isAfter(LocalDateTime.now())) {// 当前缓存数据未过期,直接返回return t;}// 2、缓存数据已过期,获取互斥锁,并且重建缓存String lockKey = LOCK_SHOP_KEY + id;boolean isLock = tryLock(lockKey);if (isLock) {// 获取锁成功,开启一个子线程去重建缓存CACHE_REBUILD_EXECUTOR.submit(() -> {try {// 查询数据库T t1 = dbFallback.apply(id);// 将查询到的数据保存到Redisthis.setWithLogicalExpire(key, t1, timeout, unit);} finally {unlock(lockKey);}});}// 3、获取锁失败,再次查询缓存,判断缓存是否重建(这里双检是有必要的)jsonStr = stringRedisTemplate.opsForValue().get(key);if (StrUtil.isBlank(jsonStr)) {// 3.1 缓存未命中,直接返回失败信息return null;}// 3.2 缓存命中,将JSON字符串反序列化未对象,并判断缓存数据是否逻辑过期redisData = JSONUtil.toBean(jsonStr, RedisData.class);// 这里需要先转成JSONObject再转成反序列化,否则可能无法正确映射Shop的字段data = (JSONObject) redisData.getData();t = JSONUtil.toBean(data, type);expireTime = redisData.getExpireTime();if (expireTime.isAfter(LocalDateTime.now())) {// 当前缓存数据未过期,直接返回return t;}// 4、返回过期数据return t;}/*** 获取锁** @param key* @return*/private boolean tryLock(String key) {Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);// 拆箱要判空,防止NPEreturn BooleanUtil.isTrue(flag);}/*** 释放锁** @param key*/private void unlock(String key) {stringRedisTemplate.delete(key);}
}
相关文章:
利用Redis实现数据缓存
目录 1 为啥要缓存捏? 2 基本流程(以查询商铺信息为例) 3 实现数据库与缓存双写一致 3.1 内存淘汰 3.2 超时剔除(半自动) 3.3 主动更新(手动) 3.3.1 双写方案 3.3.2 读写穿透方案 3.3.…...

如何使用 pytest-html 创建自定义 HTML 测试报告
关注开源优测不迷路 大数据测试过程、策略及挑战 测试框架原理,构建成功的基石 在自动化测试工作之前,你应该知道的10条建议 在自动化测试中,重要的不是工具 测试 Python 代码对于提高代码质量、检测漏洞或意外行为至关重要。 但测试结果又该…...

服务器中的流量主要是指什么?
服务器流量就是指服务器在单位时间内所传输的数据量,服务器流量在互联网中起着十分重要的作用,一般会被用来处理网站的访问请求,当用户在网站中浏览网页和视频时,服务器会接收到用户的请求,同时会返回网站的内容。 服务…...

飞牛NAS安装过程中的docker源问题
采用CloudFlare进行飞牛NAS的远程访问 【安全免费】无需公网IP、端口号,NAS外网访问新方法_网络存储_什么值得买 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<EOF {"registry-mirrors": ["https://docker.1panel.dev&quo…...

【动态规划】--- 斐波那契数模型
Welcome to 9ilks Code World (๑•́ ₃ •̀๑) 个人主页: 9ilk (๑•́ ₃ •̀๑) 文章专栏: 算法Journey 🏠 第N个泰波那契数模型 📌 题目解析 第N个泰波那契数 题目要求的是泰波那契数,并非斐波那契数。 &…...

php-phar打包避坑指南2025
有很多php脚本工具都是打包成phar形式,使用起来就很方便,那么如何自己做一个呢?也找了很多文档,也遇到很多坑,这里就来总结一下 phar安装 现在直接装yum php-cli包就有phar文件,很方便 可通过phar help查看…...

ChirpIoT技术的优势以及局限性
ChirpIoT是一种由上海磐启微电子开发的国产无线射频通讯技术,ChirpIoT技术基于磐启多年对雷达等线性扩频信号的深入研究,并在此基础上对线性扩频信号的变化进行了改进,实现了远距离传输的一种无线通信技术。相关产品型号有E29-400T22D、E290-…...

java提取系统应用的日志中的sql获取表之间的关系
为了获取到对应的sql数据,分了三步骤 第一步,获取日志文件,解析日志文件中的查询sql,递归解析sql,获取表关系集合 递归解析sql,获取表与表之间的关系 输出得到的对应关联关系数据 第二步,根据获…...

PyQt6医疗多模态大语言模型(MLLM)实用系统框架构建初探(下.代码部分)
医疗 MLLM 框架编程实现 本医疗 MLLM 框架结合 Python 与 PyQt6 构建,旨在实现多模态医疗数据融合分析并提供可视化界面。下面从数据预处理、模型构建与训练、可视化界面开发、模型 - 界面通信与部署这几个关键部分详细介绍编程实现。 6.1 数据预处理 在医疗 MLLM 框架中,多…...
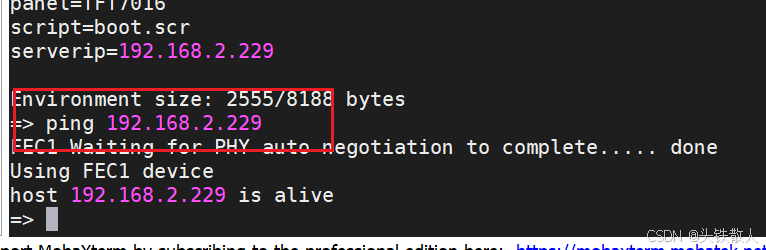
IMX6ull项目环境配置
文件解压缩: .tar.gz 格式解压为 tar -zxvf .tar.bz2 格式解压为 tar -jxvf 2.4版本后的U-boot.bin移植进SD卡后,通过串口启动配置开发板和虚拟机网络。 setenv ipaddr 192.168.2.230 setenv ethaddr 00:04:9f:…...
命令详解:wc)
Linux(Centos 7.6)命令详解:wc
1.命令作用 打印文件的行数、单词数、字节数,如果指定了多个文件,还会打印以上三种数据的总和(Print newline, word, and byte counts for each FILE, and a total line if more than one FILE is specified) 2.命令语法 Usage: wc [OPTION]... [FIL…...

Gradle buildSrc模块详解:集中管理构建逻辑的利器
文章目录 buildSrc模块二 buildSrc的使命三 如何使用buildSrc1. 创建目录结构2. 配置buildSrc的构建脚本3. 编写共享逻辑4. 在模块中引用 四 典型使用场景1. 统一依赖版本管理2. 自定义Gradle任务 3. 封装通用插件4. 扩展Gradle API 五 注意事项六 与复合构建(Compo…...
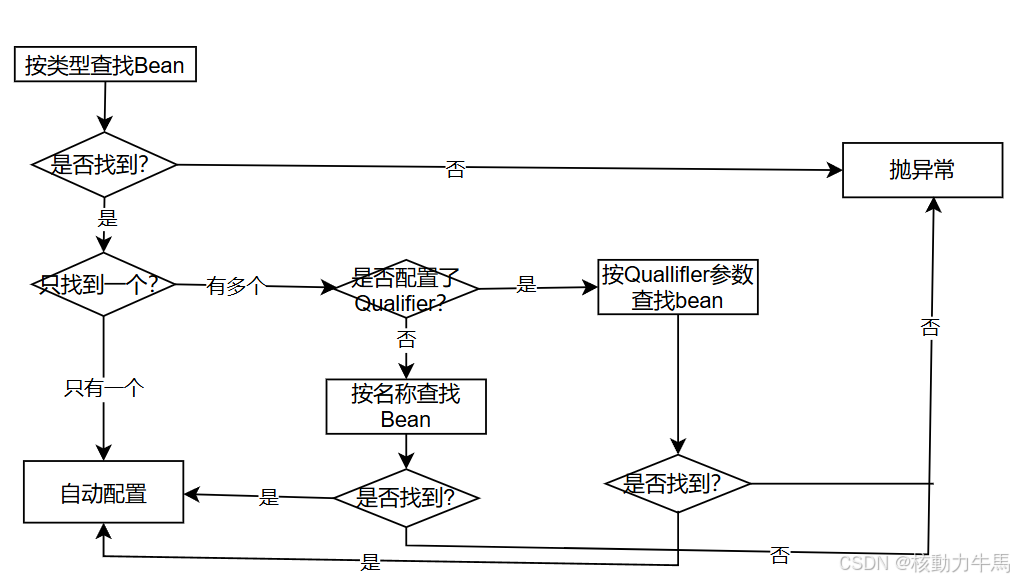
六、深入了解DI
依赖注入是⼀个过程,是指IoC容器在创建Bean时,去提供运⾏时所依赖的资源,⽽资源指的就是对象. 在上⾯程序案例中,我们使⽤了 Autowired 这个注解,完成了依赖注⼊的操作. 简单来说,就是把对象取出来放到某个类的属性中。 关于依赖注…...

基于RAG构建Text2SQL的实战教程
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于大模型算法的研究与应用。曾担任百度千帆大模型比赛、BPAA算法大赛评委,编写微软OpenAI考试认证指导手册。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。授权多项发明专利。对机器学…...

【论文阅读】HumanPlus: Humanoid Shadowing and Imitation from Humans
作者:Zipeng Fu、Qingqing Zhao、Qi Wu、Gordon Wetstein、Chelsea Finn 项目共同负责人,斯坦福大学 项目网址:https://humanoid-ai.github.io 摘要 制造外形与人类相似的机器人的一个关键理由是,我们可以利用大量的人类数据进行…...

第25篇 基于ARM A9处理器用C语言实现中断<一>
Q:怎样理解基于ARM A9处理器用C语言实现中断的过程呢? A:同样以一段使用C语言实现中断的主程序为例介绍,和汇编语言实现中断一样这段代码也使用了定时器中断和按键中断。执行该主程序会在DE1-SoC的红色LED上显示流水灯…...

Spring WebSocket 与 STOMP 协议结合实现私聊私信功能
目录 后端pom.xmlConfig配置类Controller类DTO 前端安装相关依赖websocketService.js接口javascripthtmlCSS 效果展示简单测试连接: 报错解决方法1、vue3 使用SockJS报错 ReferenceError: global is not defined 功能补充拓展1. 安全性和身份验证2. 异常处理3. 消息…...

RabbitMQ5-死信队列
目录 死信的概念 死信的来源 死信实战 死信之TTl 死信之最大长度 死信之消息被拒 死信的概念 死信,顾名思义就是无法被消费的消息,一般来说,producer 将消息投递到 broker 或直接到queue 里了,consumer 从 queue 取出消息进…...

[JavaScript] 面向对象编程
JavaScript 是一种多范式语言,既支持函数式编程,也支持面向对象编程。在 ES6 引入 class 语法后,面向对象编程在 JavaScript 中变得更加易于理解和使用。以下将详细讲解 JavaScript 中的类(class)、构造函数࿰…...

Windows上通过Git Bash激活Anaconda
在Windows上配置完Anaconda后,普遍通过Anaconda Prompt激活虚拟环境并执行Python,如下图所示: 有时需要连续执行多个python脚本时,直接在Anaconda Prompt下可以通过在以下方式,即命令间通过&&连接,…...

XSLT 编辑 XML:深度解析与实际应用
XSLT 编辑 XML:深度解析与实际应用 引言 XML(可扩展标记语言)和XSLT(可扩展样式表语言转换)是处理和转换XML数据的重要工具。本文将深入探讨XSLT在编辑XML文档中的应用,包括其基本概念、语法结构、以及实…...

主机监控软件WGCLOUD使用指南 - 如何设置主题背景色
WGCLOUD运维监控系统,从v3.5.7版本开始支持设置不同的主题背景色,如下 更多主题查看说明 如何设置主题背景色 - WGCLOUD...

C语言教程——文件处理(2)
目录 前言 一、顺序读写函数(续) 1.1fprintf 1.2fscanf 1.3fwrite 1.4fread 二、流和标准流 2.1流 2.2标准流 2.3示例 三、sscanf和sprintf 3.1sprintf 3.2sscanf 四、文件的随机读写 4.1fseek 4.2ftell 4.3rewind 五、文件读取结束的…...

ios打包:uuid与udid
ios的uuid与udid混乱的网上信息 新人开发ios,发现uuid和udid在网上有很多帖子里是混淆的,比如百度下,就会说: 在iOS中使用UUID(通用唯一识别码)作为永久签名,通常是指生成一个唯一标识…...

Spring Boot应用中实现基于JWT的登录拦截器,以保证未登录用户无法访问指定的页面
目录 一、配置拦截器进行登录校验 1. 在config层设置拦截器 2. 实现LoginInterceptor拦截器 3. 创建JWT工具类 4. 在登录时创建JWT并存入Cookie 二、配置JWT依赖和环境 1. 添加JWT依赖 2. 配置JWT环境 本篇博客将为大家介绍了如何在Spring Boot应用中实现基于JWT的登录…...
.NET9增强OpenAPI规范,不再内置swagger
ASP.NETCore in .NET 9.0 OpenAPI官方文档ASP.NET Core API 应用中的 OpenAPI 支持概述 | Microsoft Learnhttps://learn.microsoft.com/zh-cn/aspnet/core/fundamentals/openapi/overview?viewaspnetcore-9.0https://learn.microsoft.com/zh-cn/aspnet/core/fundamentals/ope…...

pytest自动化测试 - pytest夹具的基本概念
<< 返回目录 1 pytest自动化测试 - pytest夹具的基本概念 夹具可以为测试用例提供资源(测试数据)、执行预置条件、执行后置条件,夹具可以是函数、类或模块,使用pytest.fixture装饰器进行标记。 1.1 夹具的作用范围 夹具的作用范围: …...

hot100_234. 回文链表
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。 示例 1: 输入:head [1,2,2,1] 输出:true 示例 2: 输入:head …...

【超详细】ELK实现日志采集(日志文件、springboot服务项目)进行实时日志采集上报
本文章介绍,Logstash进行自动采集服务器日志文件,并手把手教你如何在springboot项目中配置logstash进行日志自动上报与日志自定义格式输出给logstash。kibana如何进行配置索引模式,可以在kibana中看到采集到的日志 日志流程 logfile-> l…...
和事件捕获(Event Capturing)的理解)
谈谈对JavaScript 中的事件冒泡(Event Bubbling)和事件捕获(Event Capturing)的理解
JavaScript 中的事件冒泡(Event Bubbling)和事件捕获(Event Capturing),是浏览器在处理事件时采用的两种机制,它们在事件的传播顺序上有显著区别。这两种机制帮助开发者在事件触发时,能够以不同…...