LLM - 大模型 ScallingLaws 的指导模型设计与实验环境(PLM) 教程(4)
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/145323420
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。
Scaling Laws (缩放法则) 是大模型领域中,用于描述 模型性能(Loss) 与 模型规模N、数据量D、计算资源C 之间关系的经验规律,揭示在大模型中,随着模型参数数量、数据集大小和计算资源的增加,模型性能的变化模式,指导更高效地分配资源,优化模型训练过程,实现更好的性能。这些规律不仅有助于预测不同规模模型的表现,还能为模型设计和训练提供理论依据,是推动大模型发展和应用的重要理论基础。
使用 ScalingLaws 指导模型设计,验证模型效果,超过根据经验设计的模型,以及介绍模型的训练环境与超参数。
系列文章:
- 大模型 ScallingLaws 的 C=6ND 公式推导
- 大模型 ScallingLaws 的 CLM 和 MLM 中不同系数
- 大模型 ScallingLaws 的迁移学习与混合训练
- 大模型 ScallingLaws 的指导模型设计与实验环境
- 大模型 ScallingLaws 的设计 100B 预训练方案
1. ScalingLaws 指导模型设计
验证根据 ScalingLaws 指导模型设计的效果:

根据 PLM 的 ScalingLaw 公式计算,CLM 模型,模型规模(N)是 7.2 B 7.2B 7.2B,数据量(D)是 265 B 265B 265B,计算量( C C C) 是 1.14 × 1 0 22 1.14 \times 10^{22} 1.14×1022,即输入计算量,输出模型规模与数据量,公式如下:
N = ( 1.26 × 1 0 − 3 ) × C 0.578 N = 1.26 × 1 0 − 3 × ( 1.14 × 1 0 22 ) 0.578 = 7.067 × 1 0 9 D = ( 1.23 × 1 0 2 ) × C 0.422 D = 1.23 × 1 0 2 × ( 1.14 × 1 0 22 ) 0.422 = 250 × 1 0 9 \begin{align} N &= (1.26 \times 10^{-3}) \times C^{0.578} \\ N &= 1.26 \times 10^{-3} \times (1.14 \times 10^{22})^{0.578} \\ &= 7.067 \times 10^9 \\ D &= (1.23 \times 10^{2}) \times C^{0.422} \\ D &= 1.23 \times 10^{2} \times (1.14 \times 10^{22})^{0.422} \\ &= 250 \times 10^9 \\ \end{align} NNDD=(1.26×10−3)×C0.578=1.26×10−3×(1.14×1022)0.578=7.067×109=(1.23×102)×C0.422=1.23×102×(1.14×1022)0.422=250×109
Protein 的 CLM 模型公式,参考:大模型 ScallingLaws 的 CLM 和 MLM 中不同系数(PLM),使用 Latex 计算数值,可以使用 SymboLab 工具。
根据 PLM 的 ScalingLaw 公式计算,MLM 模型,模型规模(N)是 10.7 B 10.7B 10.7B,数据量(D)是 260 B 260B 260B,计算量( C C C) 是 1.68 × 1 0 22 1.68 \times 10^{22} 1.68×1022,即输入计算量为,输出模型规模与数据量,公式如下:
N = ( 6.19 × 1 0 − 8 ) × C 0.776 N = ( 6.19 × 1 0 − 8 ) × ( 1.68 × 1 0 22 ) 0.776 = 10.93 × 1 0 9 D = ( 2.02 × 1 0 6 ) × C 0.230 D = ( 2.02 × 1 0 6 ) × ( 1.68 × 1 0 22 ) 0.230 = 261 × 1 0 9 \begin{align} N &= (6.19 \times 10^{-8}) \times C^{0.776} \\ N &= (6.19 \times 10^{-8}) \times (1.68 \times 10^{22})^{0.776} \\ &= 10.93 \times 10^9 \\ D &= (2.02 \times 10^{6}) \times C^{0.230} \\ D &= (2.02 \times 10^{6}) \times (1.68 \times 10^{22})^{0.230} \\ &= 261 \times 10^9 \\ \end{align} NNDD=(6.19×10−8)×C0.776=(6.19×10−8)×(1.68×1022)0.776=10.93×109=(2.02×106)×C0.230=(2.02×106)×(1.68×1022)0.230=261×109
与表格的数值类似。
在 MLM 与 CLM+MLM 的对比实验中,根据 PLM 的 ScalingLaw 公式计算,MLM 模型规模(N)是 470 M 470M 470M,数据量(D)是 106 B 106B 106B,计算量( C C C) 是 3 × 1 0 20 3 \times 10^{20} 3×1020,即输入计算量为,输出模型规模与数据量,计算结果 103 × 1 0 9 ∼ 106 B 103 \times 10^9 \sim 106B 103×109∼106B,公式如下:
N = ( 6.19 × 1 0 − 8 ) × C 0.776 N = ( 6.19 × 1 0 − 8 ) × ( 3 × 1 0 20 ) 0.776 = 480 × 1 0 6 D = ( 2.02 × 1 0 6 ) × C 0.230 D = ( 2.02 × 1 0 6 ) × ( 3 × 1 0 20 ) 0.230 = 103 × 1 0 9 \begin{align} N &= (6.19 \times 10^{-8}) \times C^{0.776} \\ N &= (6.19 \times 10^{-8}) \times (3 \times 10^{20})^{0.776} \\ &= 480 \times 10^6 \\ D &= (2.02 \times 10^{6}) \times C^{0.230} \\ D &= (2.02 \times 10^{6}) \times (3 \times 10^{20})^{0.230} \\ &= 103 \times 10^9 \\ \end{align} NNDD=(6.19×10−8)×C0.776=(6.19×10−8)×(3×1020)0.776=480×106=(2.02×106)×C0.230=(2.02×106)×(3×1020)0.230=103×109
在 CLM+MLM 模型中,MLM 模型规模(N)是 470 M 470M 470M,计算量( C C C) 是 3 × 1 0 20 3 \times 10^{20} 3×1020 一致,数据量(D)是 106 B 106B 106B 不同,计算结果 18.83 × 1 0 9 ∼ 21 B 18.83 \times 10^9 \sim 21B 18.83×109∼21B,公式如下:
D t = k × 1 D f α × 1 N β = 3.65 × 1 0 5 × 1 D f − 0.137 × 1 N − 0.369 D t = 3.65 × 1 0 5 × 1 ( 85 × 102 4 3 ) − 0.137 × 1 ( 480 × 102 4 2 ) − 0.369 = 18.83 × 1 0 9 \begin{align} D_{t} &= k \times \frac{1}{D_{f}^{\alpha}} \times \frac{1}{N^{\beta}} \\ &= 3.65 \times 10^5 \times \frac{1}{D_{f}^{-0.137}} \times \frac{1}{N^{-0.369}} \\ D_{t} &= 3.65 \times 10^5 \times \frac{1}{(85 \times 1024^3)^{-0.137}} \times \frac{1}{(480 \times 1024^2)^{-0.369}} \\ &= 18.83 \times 10^9 \end{align} DtDt=k×Dfα1×Nβ1=3.65×105×Df−0.1371×N−0.3691=3.65×105×(85×10243)−0.1371×(480×10242)−0.3691=18.83×109
与表格的数值类似。
2. ScalingLaws 模型效果
在 CLM 模型中,PROGEN2-xlarge(6.4B) 与 Our-7.2B 对比,在 序列生成的困惑度(Perplexity)、结构预测的 pLDDT、FoldSeek 搜索的 TM-Score、聚类(Cluster) 的分布 中,这 4 个领域的实验结果,Our-7.2B 都优于 PROGEN2-xlarge(6.4B)。如图:

在 MLM 模型中,ESM-2 (3B) 与 Ours-10.7B 对比,使用 LoRA 进行微调下游任务,包括 接触预测(Contact Prediction)、折叠分类(Fold Classification)、荧光蛋白(Fluorescence) 的 Spearman 相似度,这 3 个领域的实验结果,Our-10.7B 都优于 ESM-2(3B),同时,470M 模型的迁移学习优于从头训练。如图:

3. 实验参数
核心的实验参数,包括 大规模数据集(UniMeta200B)、MLM的掩码率(Mask Ratios)、MLM的下游任务(Downstream)。
3.1 大规模数据(UniMeta200B)
验证 大规模数据集(UniMeta200B) 的有效性,优于小批量数据的过采样(UR50/S),采样方法包括 Bootstrap、Local Shuffle、Global Shuffle,即:
- Bootstrap:从 UR50/S 数据集中有放回地处理了200B Tokens,在每个训练周期中,随机抽取数据集的 65%。
- Local Shuffle:每个 Epoch 都使用全部的 UR50/S Tokens,进行 Shuffle。
- Global Shuffle:将重复的全部 UR50/S Tokens,进行 Shuffle,分配至每个 Epoch。

3.2 掩码率(Mask Ratios)
验证 掩码率(Mask Ratios) 的超参,掩码率 10%~20% 的效果最好,最终选择 15% 的掩码率,同时,满足80-10-10 策略,在 15% 的掩码部分,其中 80% 替换成掩码,10% 随机替换、10% 保持不变,同时验证,下游任务中,也是 15% 掩码率最好,即:

3.3 下游任务(Downstream)
验证 MLM 与 CLM 在下游任务(downstream) 的效果,即接触预测(Contact Prediction),显示相同计算量和相同的 Loss 情况下,MLM 优于 CLM,微调方法 LoRA 优于 Probing,即:

P@L/5即Precision at L/5,其中 L 代表序列长度,计算的是在前 L/5 最高预测概率中,预测正常的比例。
4. ScalingLaws 实验环境
实验环境包括:
- 设备 带有 NVLink 的 Ampere A100 GPU (80G),GLM 框架,训练 1M(Million) 小时的 GPU,即 768 卡,训练 ( 1 × 1 0 6 h ) / ( 768 ) / ( 24 h / D ) ≈ 55 D (1 \times 10^{6}h) / (768) / (24h/D) \approx 55D (1×106h)/(768)/(24h/D)≈55D
- 小模型(<2B) 只使用 数据并行(Data Parallelism),没有使用 模型并行(Model Parallelism) 和 流水线并行(Pipeline Parallelism)。
- 改进的 Transformer 架构:DeepNorm + LayerNorm、激活函数 GeLU、位置编码 RoPE
- 其他:
- FlashAttention
- 余弦衰减策略(Cosine Decay Strategy) + 预热(Warm-Up) 2.5%
- 序列长度1024 +
<EOS>分隔符(Delimiter) - AdamW
- BFloat16(Brain Floating Point 16-bit)
- 迁移学习:忽略预训练优化状态、预热 5%。
使用带有 NVLink 的 Ampere A100 GPU (80G) 完成所有实验,基于 DeepSpeed 和 Megatron 开发的 GLM 框架,总共使用大约 1M(Million) 小时的 GPU 计算时间,小模型(<2B) 主要使用 数据并行(Data Parallelism),没有使用 模型并行(Model Parallelism) 和 流水线并行(Pipeline Parallelism),简化部署。
使用改进的 Transformer 架构:
(1) 使用 DeepNorm + LayerNorm,即:
D e e p N o r m ( x ) = L a y e r N o r m ( α ⋅ x + N e t w o r k ( x ) ) DeepNorm(x) = LayerNorm(\alpha \cdot x + Network(x)) DeepNorm(x)=LayerNorm(α⋅x+Network(x))
其中,缩放因子 α \alpha α 的值为 ( 2 N ) 1 2 (2N)^{\frac{1}{2}} (2N)21, N N N 是模型的层数,即层数越深,原始输入的权重越高,例如 ( 2 × 70 ) 1 2 = 11.83 (2 \times 70)^{\frac{1}{2}}=11.83 (2×70)21=11.83
(2) 使用 激活函数 GeLU,即:
G e L U ( x ) = x ⋅ P ( X < = x ) = x ⋅ Φ ( x ) G e L U ( x ) = x ⋅ 1 + e r f ( x 2 ) 2 \begin{align} GeLU(x) &= x \cdot P(X<=x) = x \cdot \Phi(x) \\ GeLU(x) &= x \cdot \frac{1+erf(\frac{x}{\sqrt{2}})}{2} \end{align} GeLU(x)GeLU(x)=x⋅P(X<=x)=x⋅Φ(x)=x⋅21+erf(2x)
其中, Φ ( x ) \Phi(x) Φ(x) 是标准正态分布的累积分布函数(CDF), e r f ( x ) erf(x) erf(x) 是高斯误差函数。
基于 Sigmoid 的近似公式,即:
G e L U ( x ) ≈ x ⋅ σ ( 1.702 x ) GeLU(x) \approx x \cdot \sigma(1.702x) GeLU(x)≈x⋅σ(1.702x)
PyTorch 源码:
def gelu(x):return x * 0.5 * (1.0 + torch.erf(x / torch.sqrt(2.0)))
GeLU 图示:

(3) 使用 位置编码 RoPE,即:
P E ( p o s , k ) = c o s ( p o s 50000 0 k d m ) + i ⋅ s i n ( p o s 50000 0 k d m ) θ k = 1 50000 0 k d m P E ( p o s , k ) = c o s ( p o s ⋅ θ k ) + i ⋅ s i n ( p o s ⋅ θ k ) = e i ⋅ p o s ⋅ θ k PE_{(pos,k)} = cos(\frac{pos}{500000^{\frac{k}{d_{m}}}})+i\cdot sin(\frac{pos}{500000^{\frac{k}{d_{m}}}}) \\ \theta_{k} = \frac{1}{500000^{\frac{k}{d_{m}}}} \\ PE_{(pos,k)} = cos(pos \cdot \theta_{k})+i\cdot sin(pos \cdot \theta_{k})=e^{i \cdot pos \cdot \theta_{k}} PE(pos,k)=cos(500000dmkpos)+i⋅sin(500000dmkpos)θk=500000dmk1PE(pos,k)=cos(pos⋅θk)+i⋅sin(pos⋅θk)=ei⋅pos⋅θk
RoPE 参考:理解 旋转位置编码(RoPE)
(4) 使用 FlashAttention 加速训练过程,参考 FlashAttention 的 Safe-Softmax 与 One-Pass Tiling 计算
(5) 使用 余弦衰减策略(Cosine Decay Strategy),最大学习率(LR) 经验范围是 6 × 1 0 − 4 ∼ 1.2 × 1 0 − 4 6 \times 10^{-4} \sim 1.2 \times 10^{-4} 6×10−4∼1.2×10−4,衰减至 最大LR 的 0.1 倍,预热步数(warm-up) 是 2.5%。
(6) 序列长度设置为 1024,序列通过 <EOS>分隔符(delimiter) 进行拼接。
(7) 优化器使用 AdamW,参数更新,即:
θ t + 1 = θ t − α v t + ϵ m t − λ θ t m t = β 1 m t − 1 + ( 1 − β 1 ) ∇ L ( θ t − 1 ) v t = β 2 v t − 1 + ( 1 − β 2 ) ∇ L ( θ t − 1 ) 2 \begin{align} \theta_{t+1} &= \theta_{t} - \frac{\alpha}{\sqrt{v_{t}}+\epsilon} m_{t} - \lambda\theta_{t} \\ m_{t} &= \beta_{1}m_{t-1} + (1-\beta_{1}) \nabla L(\theta_{t-1}) \\ v_{t} &= \beta_{2}v_{t-1} + (1-\beta_{2}) \nabla L(\theta_{t-1})^{2} \\ \end{align} θt+1mtvt=θt−vt+ϵαmt−λθt=β1mt−1+(1−β1)∇L(θt−1)=β2vt−1+(1−β2)∇L(θt−1)2
其中, m t m_{t} mt 是一阶矩估计(Mean), v t v_{t} vt 是二阶距估计(Variance), α \alpha α 是学习率。
超参数包括 4 个,即 β 1 \beta_{1} β1 是一阶矩衰减率(0.9), β 2 \beta_{2} β2 是二阶距衰减率(0.95), ϵ \epsilon ϵ 是小常数( 1 × 1 0 − 8 1 \times 10^{-8} 1×10−8), λ \lambda λ 是权重衰减系数(0.01)。
(8) 省略 Dropout,使用 BFloat16(Brain Floating Point 16-bit) 数据格式,即1位符号位、8位指数位、7位尾数位,FP16 是 1-5-10。BFloat16 比 FP16 的数值范围更大,精度降低,数值范围 − 3.4 × 1 0 38 ∼ 3.4 × 1 0 38 -3.4 \times 10^{38} \sim 3.4 \times 10^{38} −3.4×1038∼3.4×1038,即:
B F 1 6 m a x = 2 127 × ( 1 + 127 128 ) = 2 127 × 1.9921875 ≈ 3.4 × 1 0 38 B F 1 6 m i n = 2 − 126 × 1 128 = 2 − 133 ≈ 9.2 × 1 0 − 41 \begin{align} BF16_{max} &= 2^{127} \times (1 + \frac{127}{128}) = 2^{127} \times 1.9921875 \approx 3.4 \times 10^{38} \\ BF16_{min} &= 2^{-126} \times \frac{1}{128} = 2^{-133} \approx 9.2 \times 10^{-41} \end{align} BF16maxBF16min=2127×(1+128127)=2127×1.9921875≈3.4×1038=2−126×1281=2−133≈9.2×10−41
(9) 迁移学习,只使用模型,忽略预训练的优化状态,预热使用最大LR的 5% 总步数,学习剩余的 Tokens。
模型参数:

相关文章:
LLM - 大模型 ScallingLaws 的指导模型设计与实验环境(PLM) 教程(4)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/145323420 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 Scalin…...
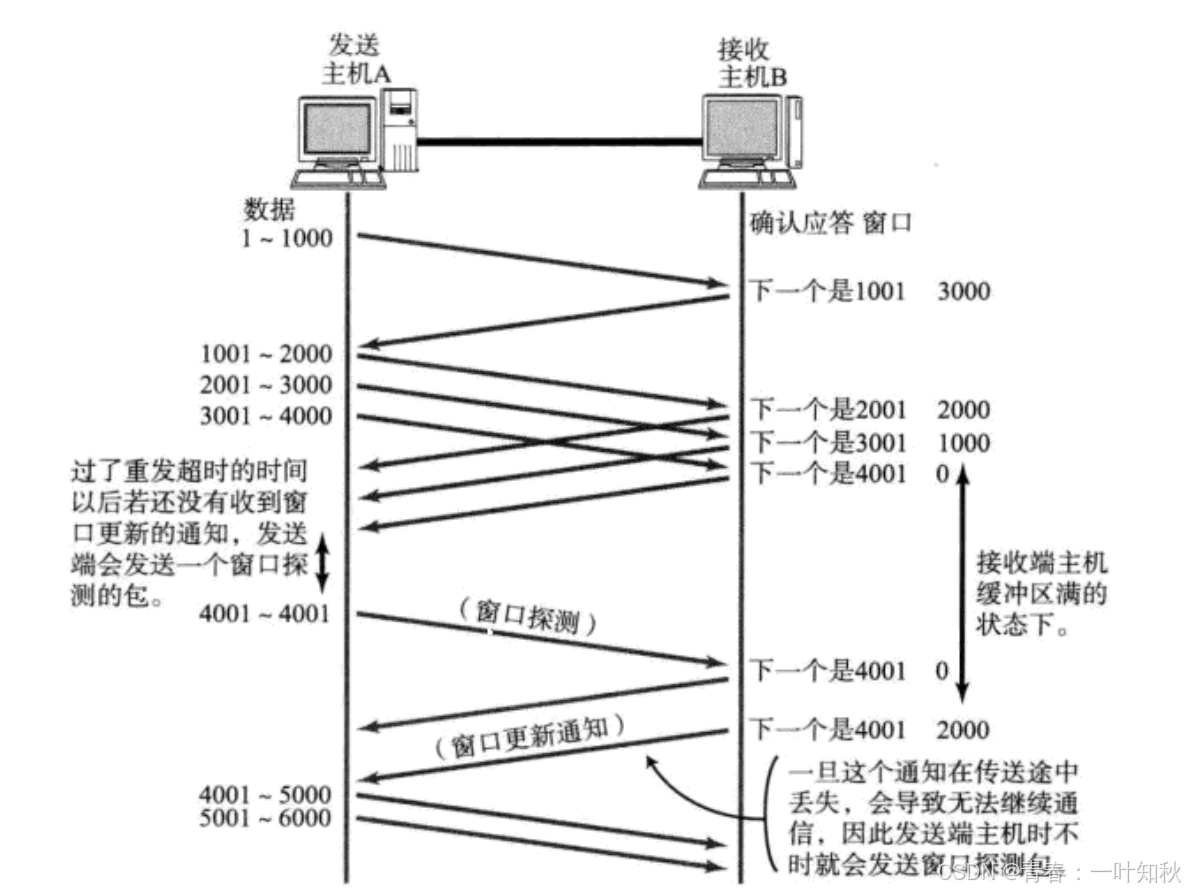
【Linux网络编程】传输层协议
目录 一,传输层的介绍 二,UDP协议 2-1,UDP的特点 2-2,UDP协议端格式 三,TCP协议 3-1,TCP报文格式 3-2,TCP三次握手 3-3,TCP四次挥手 3-4,滑动窗口 3-5…...

salesforce 可以 outbound profile 吗
在 Salesforce 中,Profile(配置文件) 通常不能直接通过标准的Change Set(变更集) 或 Outbound Migration(外部迁移工具) 进行完整的迁移,但可以通过以下方法来实现部分或全部迁移&am…...

FreeRtos的使用教程
定义: RTOS实时操作系统, (Real Time Operating System), 指的是当外界事件发生时, 能够有够快的响应速度,调度一切可利用的资源, 控制实时任务协调一致的运行。 特点: 支持多任务管理, 处理多个事件, 实现更复杂的逻辑。 与计算…...

windows系统如何检查是否开启了mongodb服务
windows系统如何检查是否开启了mongodb服务!我们有很多软件开发,网站开发时候需要使用到这个mongodb数据库,下面我们看看,如何在windows系统内排查,是否已经启动了本地服务。 在 Windows 系统上,您可以通过…...
)
windows蓝牙驱动开发-生成和发送蓝牙请求块 (BRB)
以下过程概述了配置文件驱动程序生成和发送蓝牙请求块 (BRB) 应遵循的一般流程。 BRB 是描述要执行的蓝牙操作的数据块。 生成和发送 BRB 分配 IRP。 分配BRB,请调用蓝牙驱动程序堆栈导出以供配置文件驱动程序使用的 BthAllocateBrb 函数。;初始化 BRB…...

基于Ubuntu交叉编译ZLMediaKit
一、确保基于虚拟机VMVare的Ubuntu能正常上网 1、设置WIFI硬件无线网卡上网 菜单栏的“编辑”->选择“虚拟网络编辑器”,在弹出的窗口中,点击桥接模式的VMnet0,然后在下方选择“桥接模式”,网卡下拉栏,选择你目前…...

【PyTorch][chapter 29][李宏毅深度学习]Fine-tuning LLM
参考: https://www.youtube.com/watch?veC6Hd1hFvos 目录: 什么是 Fine-tune 为什么需要Fine-tuning 如何进行Fine-tune Fine-tuning- Supervised Fine-tuning 流程 Fine-tuning参数训练的常用方案 LORA 简介 示例代码 一 什么是 Fine-tune …...

git回退
git回退 1、未使用 git add 缓存代码时 git checkout –- filepathname 放弃单个文件的修改 git checkout . 放弃所有的文件修改 此命令用来放弃掉所有还没有加入到缓存区(就是 git add 命令)的修改:内容修改与整个文件删除。但是此命令不…...

数字图像处理:实验七
uu们!这是我们目前数字图像系列的最后一张,之后有关人工智能结合的数字图像处理咸鱼哥正在学习和创作中,所以还请大家给咸鱼哥点时间,同时也提前预祝大家2025年新春快乐!(咸鱼哥真诚的祝愿每一个人…...
)
网易前端开发面试题200道及参考答案 (下)
阐述如何实现 img 按照原比例最大化放置在 div 中? 要让 img 按照原比例最大化放置在 div 中,可通过以下几种方式实现: 使用 object - fit 属性 object - fit 是 CSS 中用于规定如何调整替换元素(如 <img>、<video>)的内容以适应其容器的属性。 object - fit…...
通义灵码插件保姆级教学-IDEA(安装及使用)
一、JetBrains IDEA 中安装指南 官方下载指南:通义灵码安装教程-阿里云 步骤 1:准备工作 操作系统:Windows 7 及以上、macOS、Linux; 下载并安装兼容的 JetBrains IDEs 2020.3 及以上版本,通义灵码与以下 IDE 兼容&…...

利用双指针一次遍历实现”找到“并”删除“单链表倒数第K个节点(力扣题目为例)
Problem: 19. 删除链表的倒数第 N 个结点 文章目录 题目描述思路复杂度Code 题目描述 思路 1.欲找到倒数第k个节点,即是找到正数的第n-k1、其中n为单链表中节点的个数个节点。 2.为实现只遍历一次单链表,我们先可以使一个指针p1指向链表头部再让其先走k步…...

2025美赛倒计时,数学建模五类模型40+常用算法及算法手册汇总
数学建模美赛倒计时,对于第一次参加竞赛且没有相关基础知识的同学来讲,掌握数学建模常用经典的模型算法知识,并熟练使用相关软件进行建模是关键。本文将介绍一些常用的模型算法,以及软件操作教程。 数学建模常用模型包括…...

sql中INNER JOIN、LEFT JOIN、RIGHT JOIN
INNER JOIN 的作用 INNER JOIN 只会将相关联表匹配到的数据进行展示 假设我们有两个表:sys_user和 sys_user_role SELECT s1.* from sys_user s1 INNER JOIN sys_user_role s2 on s1.id s2.user_id 这样只会展示s1.id s2.user_id相匹配到的数据,其他数…...

二十三种设计模式-享元模式
享元模式(Flyweight Pattern)是一种结构型设计模式,旨在通过共享相同对象来减少内存使用,尤其适合在大量重复对象的情况下。 核心概念 享元模式的核心思想是将对象的**可共享部分(内部状态)提取出来进行共…...

前端【10】jQuery DOM 操作
目录 jquery捕获查取 获得内容 - text()、html() 以及 val() 获取属性 - attr() 编辑 jQuery 修改/设置内容和属性 设置内容 - text()、html() 以及 val() 设置属性 - attr() jQuery添加元素 jQuery - 删除元素 前端【9】初识jQuery:让JavaScript变得更简…...

Day34:字符串的替换
在 Python 中,字符串替换是一个非常常见的操作,主要用于修改字符串中的某些部分。字符串的替换操作通常不修改原始字符串,因为字符串在 Python 中是不可变的,而是返回一个新的字符串。 Python 提供了 str.replace() 方法来执行替…...

汇编的使用总结
一、汇编的组成 1、汇编指令(指令集) 数据处理指令: 数据搬移指令 数据移位指令 位运算指令 算术运算指令 比较指令 跳转指令 内存读写指令 状态寄存器传送指令 异常产生指令等 2、伪指令 不是汇编指令,但是可以起到指令的作用,伪…...
)
力扣【347. 前 K 个高频元素】Java题解(堆)
TopK问题,我们直接上堆。 首先遍历一次然后把各个数字的出现频率存放在哈希表中便于后面堆的操作。 因为是出现频率前 k 高,所以用小顶堆,当我们遍历的频率值大于堆顶值时就可以替换堆顶。 代码: class Solution {public int[] …...

【计算机网络】host文件
host文件的主要功能: 域名解析 本地映射:host文件的主要功能是将**域名映射到相应的 IP 地址**。当计算机需要访问一个网站或服务时,它会首先在 host文件中查找该域名对应的 IP 地址。如果在 host文件中找到了匹配的域名和 IP 地址映射&…...

git如何设置pull的时候有些文件不pull
在 Git 中,没有直接的方法在 git pull 时排除特定文件,但可以通过以下方式实现类似效果: 方法 1: 使用 .gitignore .gitignore 文件可以忽略未跟踪的文件,但对已跟踪的文件无效。如果你希望某些文件不被拉取,可以先将…...

第五节 MATLAB命令
本节的内容将提供常用的一些MATLAB命令。 在之前的篇章中我们已经知道了MATLAB数值计算和数据可视化是一个交互式程序,在它的命令窗口中您可以在MATLAB提示符“>>”下键入命令。 MATLAB管理会话的命令 MATLAB提供管理会话的各种命令。如下表所示:…...

性能测试丨JVM 性能数据采集
什么是JVM性能数据采集? JVM性能数据采集是指通过一些工具和技术采集与Java虚拟机相关的性能数据。这些数据包括但不限于内存使用、CPU使用、垃圾回收(GC)行为、线程活动等。合理地分析这些数据,可以帮助我们找出系统的瓶颈&…...

vue3 vue2区别
Vue 3 和 Vue 2 之间存在多个方面的区别,以下是一些主要的差异点: 1. 性能改进 Vue 3:在性能上有显著提升,包括更小的包体积、更快的渲染速度和更好的内存管理。Vue 2:性能相对较低,尤其是在大型应用中。…...

快速更改WampServer根目录php脚本
快速更改WampServer根目录php脚本 <?php // 配置文件地址 $apacheConfPath C:\Install\CTF\Wampserver\bin\apache\apache2.4.62.1\conf\httpd.conf; $apacheConfPath2 C:\Install\CTF\Wampserver\bin\apache\apache2.4.62.1\conf\extra\httpd-vhosts.conf; // 新根目录…...

金价高企需求疲软,周大福近三个月零售值下降14.2%
1月22日,周大福在港交所发布公告称,截至2024年12月31日止三个月(第三季度),集团零售值下降14.2%。其中,中国内地市场零售值下降13.0%,香港及澳门市场零售值下降20.4%,其他市场零售值…...

想品客老师的第七天:闭包和作用域
闭包之前的内容写在这里 环境、作用域、回收 首先还是数据的回收问题,全局变量一般都是通过关闭页面回收的;而局部变量的值不用了,会被自动回收掉 像这种写在全局里的就不会被主动回收捏: let title 荷叶饭function fn() {ale…...

Web 代理、爬行器和爬虫
目录 Web 在线网页代理服务器的使用方法Web 在线网页代理服务器使用流程详解注意事项 Web 请求和响应中的代理方式Web 开发中的请求方法借助代理进行文件下载的示例 Web 服务器请求代理方式代理、网关和隧道的概念参考文献说明 爬虫的工作原理及案例网络爬虫概述爬虫工作原理 W…...

速通Docker === Docker 镜像分层存储机制
目录 分层存储的概念 分层存储的实现 镜像层 容器层 分层存储的优势 1. 镜像轻量化 2. 快速构建与部署 3. 高效的镜像共享 4. 版本控制 分层存储的示例 容器层的临时性与数据持久化 总结 Docker 的分层存储机制是其核心特性之一,它使得镜像的构建、共享和…...