【2024年华为OD机试】 (B卷,100分)- 字符串摘要(JavaScriptJava PythonC/C++)

一、问题描述
题目描述
给定一个字符串的摘要算法,请输出给定字符串的摘要值。具体步骤如下:
- 去除字符串中非字母的符号:只保留字母字符。
- 处理连续字符:如果出现连续字符(不区分大小写),则输出该字符(小写)加上连续出现的次数。
- 处理非连续字符:如果是非连续字符(不区分大小写),则输出该字符(小写)加上该字母之后字符串中出现的该字符的次数。
- 排序:对按照以上方式表示后的字符串进行排序。字母和紧随的数字作为一组进行排序,数字大的在前,数字相同的则按字母进行排序,字母小的在前。
输入描述
一行字符串,长度为[1,200]。
输出描述
摘要字符串。
用例
用例1
输入
aabbcc
输出
a2b2c2
说明
字符串中的字符都是连续的,因此直接输出每个字符及其连续出现的次数。
用例2
输入
bAaAcBb
输出
a3b2b2c0
说明
- 第一个
b是非连续字母,该字母之后字符串中还出现了2次(最后的两个Bb),所以输出b2。 a连续出现3次,输出a3。c非连续,该字母之后字符串再没有出现过c,输出c0。Bb连续2次,输出b2。- 对
b2a3c0b2进行排序,最终输出a3b2b2c0。
题目解析
主要难点
- 非连续字符的处理:对于非连续字符,需要统计该字符在当前位置之后出现的次数。为了避免重复扫描,可以预先统计每个字符的总出现次数,并在遍历时动态更新剩余次数。
- 排序规则:排序时,字母和紧随的数字作为一组进行排序。数字大的在前,数字相同的则按字母进行排序,字母小的在前。
解题思路
- 预处理字符串:去除字符串中非字母的符号,并将所有字符转换为小写。
- 统计字符出现次数:预先统计每个字符在字符串中的总出现次数。
- 遍历字符串:
- 对于连续字符,统计连续出现的次数,并输出字符及其次数。
- 对于非连续字符,输出字符及其在后续字符串中出现的次数。
- 排序:根据排序规则对输出结果进行排序,最终得到摘要字符串。
注意事项
- 在处理连续字符时,需要注意大小写不敏感。
- 在统计非连续字符的后续出现次数时,需要动态更新剩余次数。
- 排序时需要将字母和数字作为一组进行排序,确保排序规则正确。
通过以上步骤,可以有效地解决该问题,并生成符合要求的摘要字符串。
二、JavaScript算法源码
以下是代码的详细解析和实现思路:
代码解析
1. 输入处理
- 使用
readline模块从控制台读取输入。 - 将输入字符串转换为小写,以便不区分大小写。
2. 统计字母出现次数
- 使用一个对象
count来统计每个字母在字符串中出现的总次数。 - 过滤掉非字母字符,并将字母存入数组
letters中。
3. 处理连续和非连续字符
- 遍历字符串,记录当前字符
cur和上一个字符pre。 - 如果当前字符与上一个字符相同,则增加连续次数
repeat。 - 如果当前字符与上一个字符不同,则根据连续次数判断:
- 如果
repeat > 1,说明是连续字符,输出pre + repeat。 - 否则,说明是非连续字符,输出
pre + count[pre](即后续该字符的出现次数)。
- 如果
- 更新
pre和repeat,继续遍历。
4. 排序和输出
- 将结果数组
ans按照规则排序:- 数字大的在前。
- 数字相同的,字母小的在前。
- 将排序后的结果拼接成字符串并返回。
代码实现
const readline = require("readline");const rl = readline.createInterface({input: process.stdin,output: process.stdout,
});rl.on("line", (line) => {console.log(getResult(line));
});function getResult(s) {// 将字符串转换为小写s = s.toLowerCase();// 统计每个字母出现的次数const count = {};// 去除字符串中的非字母const letters = [];for (let c of s) {if (c >= "a" && c <= "z") {count[c] = (count[c] ?? 0) + 1;letters.push(c);}}// 在字符串末尾加一个空格,方便处理最后一个字符s = letters.join("") + " ";// 记录连续字母和非连续字母const ans = [];// 上一个位置的字母let pre = s[0];// 该字母连续次数记为1let repeat = 1;// 后续该字母还有 count[pre]-=1 个count[pre]--;for (let i = 1; i < s.length; i++) {// 当前位置的字母const cur = s[i];// 后续该字母还有 count[cur]-=1 个count[cur]--;if (cur == pre) {// 如果当前位置和上一个位置的字母相同,则产生连续// 连续次数 +1repeat++;} else {// 如果当前位置和上一个位置的字母不同,则连续打断// 如果 pre 字母连续次数 >1,则是真连续,输出 pre + repeat// 否则是假连续,输出 pre + count[pre]ans.push([pre, repeat > 1 ? repeat : count[pre]]);// 更新 pre 为 curpre = cur;// 更新 pre 连续次数为 1repeat = 1;}}// 字母和紧随的数字作为一组进行排序// 数字大的在前,数字相同的,则按字母进行排序,字母小的在前return ans.sort((a, b) =>a[1] != b[1] ? b[1] - a[1] : a[0].charCodeAt() - b[0].charCodeAt()).map(([letter, num]) => letter + num).join("");
}
示例运行
输入 1
aabbcc
输出 1
a2b2c2
输入 2
bAaAcBb
输出 2
a3b2b2c0
代码优化点
-
末尾空格的处理:
- 代码中在字符串末尾加了一个空格,目的是为了简化最后一个字符的处理逻辑。如果不加空格,需要在遍历结束后单独处理最后一个字符。
- 可以通过其他方式优化,避免添加空格。
-
性能优化:
- 如果字符串长度较大(接近 200),可以考虑优化统计和遍历的逻辑,减少不必要的操作。
-
代码可读性:
- 可以提取部分逻辑为独立函数,提高代码的可读性和可维护性。
总结
该代码实现了题目要求的字符串摘要算法,通过统计字符出现次数、处理连续和非连续字符,并按照规则排序输出结果。代码逻辑清晰,能够正确处理各种边界情况。
三、Java算法源码
以下是 Java 代码的详细解析和实现思路:
代码解析
1. 数据结构
- 定义了一个内部类
Letter,用于存储字母及其对应的数字(连续次数或后续出现次数)。 Letter类包含两个属性:letter:字母。num:数字(连续次数或后续出现次数)。
- 重写了
toString方法,方便输出格式化为字母 + 数字。
2. 输入处理
- 使用
Scanner从控制台读取输入字符串。 - 将字符串转换为小写,以便不区分大小写。
3. 统计字母出现次数
- 使用一个长度为 128 的数组
count来统计每个字母的出现次数(ASCII 码范围)。 - 过滤掉非字母字符,并将字母存入
StringBuilder中。
4. 处理连续和非连续字符
- 遍历字符串,记录当前字符
cur和上一个字符pre。 - 如果当前字符与上一个字符相同,则增加连续次数
repeat。 - 如果当前字符与上一个字符不同,则根据连续次数判断:
- 如果
repeat > 1,说明是连续字符,输出pre + repeat。 - 否则,说明是非连续字符,输出
pre + count[pre](即后续该字符的出现次数)。
- 如果
- 更新
pre和repeat,继续遍历。
5. 排序和输出
- 将结果列表
ans按照规则排序:- 数字大的在前。
- 数字相同的,字母小的在前。
- 将排序后的结果拼接成字符串并返回。
代码实现
import java.util.ArrayList;
import java.util.Scanner;public class Main {// 字母数字类static class Letter {char letter;int num;public Letter(char letter, int num) {this.letter = letter;this.num = num;}@Overridepublic String toString() {return this.letter + "" + this.num;}}public static void main(String[] args) {Scanner sc = new Scanner(System.in);System.out.println(getResult(sc.nextLine()));}public static String getResult(String s) {// 将字符串转换为小写s = s.toLowerCase();// 统计每个字母出现的次数int[] count = new int[128];// 去除字符串中的非字母StringBuilder sb = new StringBuilder();for (int i = 0; i < s.length(); i++) {char c = s.charAt(i);if (c >= 'a' && c <= 'z') {count[c]++;sb.append(c);}}// 在字符串末尾加一个空格,方便处理最后一个字符s = sb + " ";// 记录连续字母和非连续字母ArrayList<Letter> ans = new ArrayList<>();// 上一个位置的字母char pre = s.charAt(0);// 该字母连续次数记为1int repeat = 1;// 后续该字母还有 count[pre]-=1 个count[pre]--;for (int i = 1; i < s.length(); i++) {// 当前位置的字母char cur = s.charAt(i);// 后续该字母还有 count[cur]-=1 个count[cur]--;if (cur == pre) {// 如果当前位置和上一个位置的字母相同,则产生连续// 连续次数 +1repeat++;} else {// 如果当前位置和上一个位置的字母不同,则连续打断// 如果 pre 字母连续次数 >1,则是真连续,输出 pre + repeat// 否则是假连续,输出 pre + count[pre]ans.add(new Letter(pre, repeat > 1 ? repeat : count[pre]));// 更新 pre 为 curpre = cur;// 更新 pre 连续次数为 1repeat = 1;}}// 字母和紧随的数字作为一组进行排序// 数字大的在前,数字相同的,则按字母进行排序,字母小的在前ans.sort((a, b) -> a.num != b.num ? b.num - a.num : a.letter - b.letter);StringBuilder res = new StringBuilder();for (Letter an : ans) {res.append(an.toString());}return res.toString();}
}
示例运行
输入 1
aabbcc
输出 1
a2b2c2
输入 2
bAaAcBb
输出 2
a3b2b2c0
代码优化点
-
末尾空格的处理:
- 代码中在字符串末尾加了一个空格,目的是为了简化最后一个字符的处理逻辑。如果不加空格,需要在遍历结束后单独处理最后一个字符。
- 可以通过其他方式优化,避免添加空格。
-
性能优化:
- 如果字符串长度较大(接近 200),可以考虑优化统计和遍历的逻辑,减少不必要的操作。
-
代码可读性:
- 可以提取部分逻辑为独立方法,提高代码的可读性和可维护性。
总结
该 Java 代码实现了题目要求的字符串摘要算法,通过统计字符出现次数、处理连续和非连续字符,并按照规则排序输出结果。代码逻辑清晰,能够正确处理各种边界情况。
四、Python算法源码
以下是 Python 代码的详细解析和实现思路:
代码解析
1. 输入处理
- 使用
input()获取输入字符串。 - 将字符串转换为小写,以便不区分大小写。
2. 统计字母出现次数
- 使用字典
count统计每个字母的出现次数。 - 过滤掉非字母字符,并将字母存入列表
letters中。
3. 处理连续和非连续字符
- 在字符串末尾加一个空格,方便处理最后一个字符。
- 遍历字符串,记录当前字符
cur和上一个字符pre。 - 如果当前字符与上一个字符相同,则增加连续次数
repeat。 - 如果当前字符与上一个字符不同,则根据连续次数判断:
- 如果
repeat > 1,说明是连续字符,输出pre + repeat。 - 否则,说明是非连续字符,输出
pre + count[pre](即后续该字符的出现次数)。
- 如果
- 更新
pre和repeat,继续遍历。
4. 排序和输出
- 将结果列表
ans按照规则排序:- 数字大的在前。
- 数字相同的,字母小的在前。
- 将排序后的结果拼接成字符串并返回。
代码实现
# 输入获取
s = input()# 算法入口
def getResult():global s# 不区分大小写s = s.lower()# 统计每个字母出现的次数count = {}# 去除字符串中的非字母letters = []for c in s:if 'z' >= c >= 'a':count[c] = count.get(c, 0) + 1letters.append(c)# 加空格是为了避免后续的收尾操作,如果有疑问可以移除下面加空格操作s = "".join(letters) + " "count[' '] = 1# 记录连续字母和非连续字母ans = []# 上一个位置的字母pre = s[0]# 该字母连续次数记为1repeat = 1# 后续该字母还有count[pre]-=1个count[pre] -= 1for i in range(1, len(s)):# 当前位置的字母cur = s[i]# 后续该字母还有count[cur]-=1个count[cur] -= 1if cur == pre:# 如果当前位置和上一个位置的字母相同,则产生连续# 连续次数+1repeat += 1else:# 如果当前位置和上一个位置的字母不同,则连续打断# 如果pre字母连续次数>1,则是真连续,那么就是pre+repeat,否则就是假连续,是pre+count[pre]ans.append([pre, repeat if repeat > 1 else count[pre]])# 更新pre为curpre = cur# 更新pre连续次数为1repeat = 1# 字母和紧随的数字作为一组进行排序,数字大的在前,数字相同的,则按字母进行排序,字母小的在前ans.sort(key=lambda x: (-x[1], x[0]))return "".join(map(lambda x: x[0] + str(x[1]), ans))# 算法调用
print(getResult())
示例运行
输入 1
aabbcc
输出 1
a2b2c2
输入 2
bAaAcBb
输出 2
a3b2b2c0
代码优化点
-
末尾空格的处理:
- 代码中在字符串末尾加了一个空格,目的是为了简化最后一个字符的处理逻辑。如果不加空格,需要在遍历结束后单独处理最后一个字符。
- 可以通过其他方式优化,避免添加空格。
-
性能优化:
- 如果字符串长度较大(接近 200),可以考虑优化统计和遍历的逻辑,减少不必要的操作。
-
代码可读性:
- 可以提取部分逻辑为独立函数,提高代码的可读性和可维护性。
总结
该 Python 代码实现了题目要求的字符串摘要算法,通过统计字符出现次数、处理连续和非连续字符,并按照规则排序输出结果。代码逻辑清晰,能够正确处理各种边界情况。
五、C/C++算法源码:
C 语言代码解析
1. 输入处理
- 使用
gets获取输入字符串(注意:gets不安全,建议使用fgets替代)。 - 将字符串转换为小写,并过滤掉非字母字符。
2. 统计字母出现次数
- 使用数组
count统计每个字母的出现次数(ASCII 码范围)。 - 过滤掉非字母字符,并将字母存入数组
ss中。
3. 处理连续和非连续字符
- 遍历字符串,记录当前字符
cur和上一个字符pre。 - 如果当前字符与上一个字符相同,则增加连续次数
repeat。 - 如果当前字符与上一个字符不同,则根据连续次数判断:
- 如果
repeat > 1,说明是连续字符,输出pre + repeat。 - 否则,说明是非连续字符,输出
pre + count[pre](即后续该字符的出现次数)。
- 如果
- 更新
pre和repeat,继续遍历。
4. 排序和输出
- 将结果数组
res按照规则排序:- 数字大的在前。
- 数字相同的,字母小的在前。
- 将排序后的结果拼接成字符串并输出。
C 语言代码实现
#include <stdio.h>
#include <string.h>
#include <stdlib.h>#define MAX_SIZE 201typedef struct {char letter;int num;
} Letter;// 排序比较函数
int cmp(const void *a, const void *b) {Letter *A = (Letter *) a;Letter *B = (Letter *) b;return A->num != B->num ? B->num - A->num : A->letter - B->letter;
}int main() {char s[MAX_SIZE];fgets(s, MAX_SIZE, stdin); // 使用 fgets 替代 gets,避免缓冲区溢出unsigned long long len = strlen(s);// 记录转小写,去除非字母后的 s 字符串char ss[MAX_SIZE];int ss_size = 0;// 统计每个字母出现的次数int count[128] = {0};for (int i = 0; i < len; i++) {char c = s[i];if (c >= 'a' && c <= 'z') {count[c]++;ss[ss_size++] = c;} else if (c >= 'A' && c <= 'Z') {count[c + 32]++; // 转换为小写ss[ss_size++] = (char) (c + 32);}}// 记录连续字母和非连续字母Letter res[MAX_SIZE];int res_size = 0;// 上一个位置的字母char pre = ss[0];// 该字母连续次数记为 1int repeat = 1;// 后续该字母还有 count[pre]-=1 个count[pre]--;for (int i = 1; i <= ss_size; i++) {// 当前位置的字母char cur = ss[i];// 后续该字母还有 count[cur]-=1 个count[cur]--;if (cur == pre) {// 如果当前位置和上一个位置的字母相同,则产生连续// 连续次数 +1repeat++;} else {// 如果当前位置和上一个位置的字母不同,则连续打断// 如果 pre 字母连续次数 >1,则是真连续,那么就是 pre + repeat// 否则是假连续,是 pre + count[pre]res[res_size].num = repeat > 1 ? repeat : count[pre];res[res_size].letter = pre;res_size++;// 更新 pre 为 curpre = cur;// 更新 pre 连续次数为 1repeat = 1;}}// 字母和紧随的数字作为一组进行排序,数字大的在前,数字相同的,则按字母进行排序,字母小的在前qsort(res, res_size, sizeof(Letter), cmp);char ans[MAX_SIZE] = {'\0'};for (int i = 0; i < res_size; i++) {char letter[2];sprintf(letter, "%c", res[i].letter);char num[10];sprintf(num, "%d", res[i].num);strcat(ans, letter);strcat(ans, num);}puts(ans);return 0;
}
C++ 代码实现
以下是 C++ 版本的实现,使用了 STL 容器和算法:
#include <iostream>
#include <vector>
#include <algorithm>
#include <cctype>
#include <cstring>using namespace std;struct Letter {char letter;int num;Letter(char l, int n) : letter(l), num(n) {}// 排序规则:数字大的在前,数字相同的字母小的在前bool operator<(const Letter &other) const {if (num != other.num) return num > other.num;return letter < other.letter;}
};int main() {string s;getline(cin, s);// 统计每个字母出现的次数int count[128] = {0};string ss;for (char c : s) {if (isalpha(c)) {char lower_c = tolower(c);count[lower_c]++;ss.push_back(lower_c);}}// 记录连续字母和非连续字母vector<Letter> res;char pre = ss[0];int repeat = 1;count[pre]--;for (size_t i = 1; i <= ss.size(); i++) {char cur = ss[i];count[cur]--;if (cur == pre) {repeat++;} else {res.emplace_back(pre, repeat > 1 ? repeat : count[pre]);pre = cur;repeat = 1;}}// 排序sort(res.begin(), res.end());// 输出结果for (const auto &item : res) {cout << item.letter << item.num;}cout << endl;return 0;
}
代码讲解
1. C 语言代码
- 使用结构体
Letter存储字母及其对应的数字。 - 使用
qsort对结果进行排序。 - 使用
sprintf和strcat拼接结果字符串。
2. C++ 代码
- 使用
vector存储结果,方便动态扩展。 - 使用
sort对结果进行排序。 - 使用
emplace_back高效地插入元素。 - 使用
isalpha和tolower处理大小写转换。
示例运行
输入 1
aabbcc
输出 1
a2b2c2
输入 2
bAaAcBb
输出 2
a3b2b2c0
总结
- C 语言版本适合底层开发,代码较为冗长,但性能较高。
- C++ 版本利用 STL 简化了代码,提高了可读性和开发效率。
- 两种版本均实现了题目要求的功能,能够正确处理各种边界情况。
六、尾言
什么是华为OD?
华为OD(Outsourcing Developer,外包开发工程师)是华为针对软件开发工程师岗位的一种招聘形式,主要包括笔试、技术面试以及综合面试等环节。尤其在笔试部分,算法题的机试至关重要。
为什么刷题很重要?
-
机试是进入技术面的第一关:
华为OD机试(常被称为机考)主要考察算法和编程能力。只有通过机试,才能进入后续的技术面试环节。 -
技术面试需要手撕代码:
技术一面和二面通常会涉及现场编写代码或算法题。面试官会注重考察候选人的思路清晰度、代码规范性以及解决问题的能力。因此提前刷题、多练习是通过面试的重要保障。 -
入职后的可信考试:
入职华为后,还需要通过“可信考试”。可信考试分为三个等级:- 入门级:主要考察基础算法与编程能力。
- 工作级:更贴近实际业务需求,可能涉及复杂的算法或与工作内容相关的场景题目。
- 专业级:最高等级,考察深层次的算法以及优化能力,与薪资直接挂钩。
刷题策略与说明:
2024年8月14日之后,华为OD机试的题库转为 E卷,由往年题库(D卷、A卷、B卷、C卷)和全新题目组成。刷题时可以参考以下策略:
-
关注历年真题:
- 题库中的旧题占比较大,建议优先刷历年的A卷、B卷、C卷、D卷题目。
- 对于每道题目,建议深度理解其解题思路、代码实现,以及相关算法的适用场景。
-
适应新题目:
- E卷中包含全新题目,需要掌握全面的算法知识和一定的灵活应对能力。
- 建议关注新的刷题平台或交流群,获取最新题目的解析和动态。
-
掌握常见算法:
华为OD考试通常涉及以下算法和数据结构:- 排序算法(快速排序、归并排序等)
- 动态规划(背包问题、最长公共子序列等)
- 贪心算法
- 栈、队列、链表的操作
- 图论(最短路径、最小生成树等)
- 滑动窗口、双指针算法
-
保持编程规范:
- 注重代码的可读性和注释的清晰度。
- 熟练使用常见编程语言,如C++、Java、Python等。
如何获取资源?
-
官方参考:
- 华为招聘官网或相关的招聘平台会有一些参考信息。
- 华为OD的相关公众号可能也会发布相关的刷题资料或学习资源。
-
加入刷题社区:
- 找到可信的刷题交流群,与其他备考的小伙伴交流经验。
- 关注知名的刷题网站,如LeetCode、牛客网等,这些平台上有许多华为OD的历年真题和解析。
-
寻找系统性的教程:
- 学习一本经典的算法书籍,例如《算法导论》《剑指Offer》《编程之美》等。
- 完成系统的学习课程,例如数据结构与算法的在线课程。
积极心态与持续努力:
刷题的过程可能会比较枯燥,但它能够显著提升编程能力和算法思维。无论是为了通过华为OD的招聘考试,还是为了未来的职业发展,这些积累都会成为重要的财富。
考试注意细节
-
本地编写代码
- 在本地 IDE(如 VS Code、PyCharm 等)上编写、保存和调试代码,确保逻辑正确后再复制粘贴到考试页面。这样可以减少语法错误,提高代码准确性。
-
调整心态,保持冷静
- 遇到提示不足或实现不确定的问题时,不必慌张,可以采用更简单或更有把握的方法替代,确保思路清晰。
-
输入输出完整性
- 注意训练和考试时都需要编写完整的输入输出代码,尤其是和题目示例保持一致。完成代码后务必及时调试,确保功能符合要求。
-
快捷键使用
- 删除行可用
Ctrl+D,复制、粘贴和撤销分别为Ctrl+C,Ctrl+V,Ctrl+Z,这些可以正常使用。 - 避免使用
Ctrl+S,以免触发浏览器的保存功能。
- 删除行可用
-
浏览器要求
- 使用最新版的 Google Chrome 浏览器完成考试,确保摄像头开启并正常工作。考试期间不要切换到其他网站,以免影响考试成绩。
-
交卷相关
- 答题前,务必仔细查看题目示例,避免遗漏要求。
- 每完成一道题后,点击【保存并调试】按钮,多次保存和调试是允许的,系统会记录得分最高的一次结果。完成所有题目后,点击【提交本题型】按钮。
- 确保在考试结束前提交试卷,避免因未保存或调试失误而丢分。
-
时间和分数安排
- 总时间:150 分钟;总分:400 分。
- 试卷结构:2 道一星难度题(每题 100 分),1 道二星难度题(200 分)。及格分为 150 分。合理分配时间,优先完成自己擅长的题目。
-
考试环境准备
- 考试前请备好草稿纸和笔。考试中尽量避免离开座位,确保监控画面正常。
- 如需上厕所,请提前规划好时间以减少中途离开监控的可能性。
-
技术问题处理
- 如果考试中遇到断电、断网、死机等技术问题,可以关闭浏览器并重新打开试卷链接继续作答。
- 出现其他问题,请第一时间联系 HR 或监考人员进行反馈。
祝你考试顺利,取得理想成绩!
相关文章:
【2024年华为OD机试】 (B卷,100分)- 字符串摘要(JavaScriptJava PythonC/C++)
一、问题描述 题目描述 给定一个字符串的摘要算法,请输出给定字符串的摘要值。具体步骤如下: 去除字符串中非字母的符号:只保留字母字符。处理连续字符:如果出现连续字符(不区分大小写),则输…...

DIY QMK量子键盘
最近放假了,趁这个空余在做一个分支项目,一款机械键盘,量子键盘取自固件名称QMK(Quantum Mechanical Keyboard)。 键盘作为计算机或其他电子设备的重要输入设备之一,通过将按键的物理动作转换为数字信号&am…...

mamba论文学习
rnn 1986 训练速度慢 testing很快 但是很快就忘了 lstm 1997 训练速度慢 testing很快 但是也会忘(序列很长的时候) GRU实在lstm的基础上改进,改变了一些门 transformer2017 训练很快,testing慢些,时间复杂度高&am…...

智慧消防营区一体化安全管控 2024 年度深度剖析与展望
在 2024 年,智慧消防营区一体化安全管控领域取得了令人瞩目的进展,成为保障营区安全稳定运行的关键力量。这一年,行业在政策驱动、技术创新应用、实践成果及合作交流等方面呈现出多元且深刻的发展态势,同时也面临着一系列亟待解决…...

解锁微服务:五大进阶业务场景深度剖析
目录 医疗行业:智能诊疗的加速引擎 电商领域:数据依赖的破局之道 金融行业:运维可观测性的提升之路 物流行业:智慧物流的创新架构 综合业务:服务依赖的优化策略 医疗行业:智能诊疗的加速引擎 在医疗行业迈…...

pip 安装 numpy 报错 AttributeError: module ‘pkgutil‘ has no attribute ‘ImpImporter‘
conda 环境下 pip 安装 numpy 1.x 版本,报如下错误 File "C:\Users\UserName\AppData\Local\Temp\pip-build-env-_lgbq70y\overlay\Lib\site-packages\pkg_resources\__init__.py", line 2191, in <module>register_finder(pkgutil.ImpImporter, fi…...

javascript-es6 (一)
作用域(scope) 规定了变量能够被访问的“范围”,离开了这个“范围”变量便不能被访问 局部作用域 函数作用域: 在函数内部声明的变量只能在函数内部被访问,外部无法直接访问 function getSum(){ //函数内部是函数作用…...

Babylon.js 中的 setHardwareScalingLevel和getHardwareScalingLevel:作用与配合修改内容
在 Babylon.js 中,Engine类提供了setHardwareScalingLevel和getHardwareScalingLevel方法,用于管理和调整渲染分辨率与屏幕分辨率的比例。这些方法在优化性能和提升画质方面非常有用。尤其是在某些平台不支持硬件反锯齿时,可以考虑使用setHar…...

二十三种设计模式-桥接模式
桥接模式(Bridge Pattern)是一种结构型设计模式,其核心思想是将抽象与实现解耦,让它们可以独立变化。桥接模式主要用于解决类的继承问题,避免由于继承而带来的类层次结构过于复杂和难以维护的问题。 1. 核心概念 桥接…...

jenkins-k8s pod方式动态生成slave节点
一. 简述: 使用 Jenkins 和 Kubernetes (k8s) 动态生成 Slave 节点是一种高效且灵活的方式来管理 CI/CD 流水线。通过这种方式,Jenkins 可以根据需要在 Kubernetes 集群中创建和销毁 Pod 来执行任务,从而充分利用集群资源并实现更好的隔离性…...

代码工艺:实践 Spring Boot TDD 测试驱动开发
TDD 的核心理念是 “先写测试,再写功能”,其过程遵循一个严格的循环,即 Red-Green-Refactor: TDD 的流程 1. Red(编写失败的测试) 根据需求,先编写一个测试用例,描述期望的行为。…...
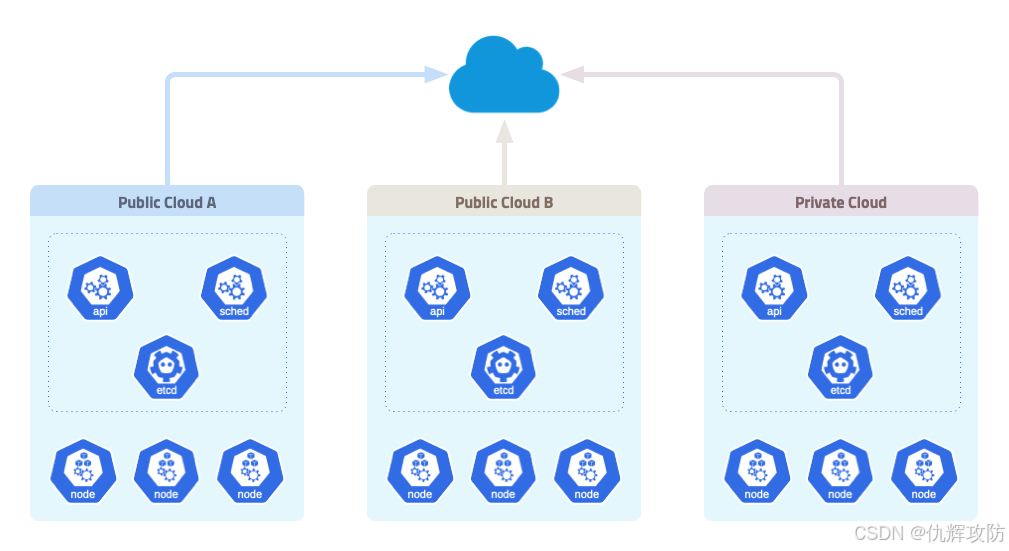
【云安全】云原生-K8S-简介
K8S简介 Kubernetes(简称K8S)是一种开源的容器编排平台,用于管理容器化应用的部署、扩展和运维。它由Google于2014年开源并交给CNCF(Cloud Native Computing Foundation)维护。K8S通过提供自动化、灵活的功能…...

aws(学习笔记第二十六课) 使用AWS Elastic Beanstalk
aws(学习笔记第二十六课) 使用aws Elastic Beanstalk 学习内容: AWS Elastic Beanstalk整体架构AWS Elastic Beanstalk的hands onAWS Elastic Beanstalk部署node.js程序包练习使用AWS Elastic Beanstalk的ebcli 1. AWS Elastic Beanstalk整体架构 官方的guide AWS…...

反向代理模块。。
1 概念 1.1 反向代理概念 反向代理是指以代理服务器来接收客户端的请求,然后将请求转发给内部网络上的服务器,将从服务器上得到的结果返回给客户端,此时代理服务器对外表现为一个反向代理服务器。 对于客户端来说,反向代理就相当于…...

C语言的灵魂——指针(1)
指针是C语言的灵魂,有了指针C语言才能完成一些复杂的程序;没了指针就相当于C语言最精髓的部分被去掉了,可见指针是多么重要。废话不多讲我们直接开始。 指针 一,内存和地址二,编址三,指针变量和地址1&#…...

14-6-2C++STL的list
(一)list对象的带参数构造 1.list(elem);//构造函数将n个elem拷贝给本身 #include <iostream> #include <list> using namespace std; int main() { list<int> lst(3,7); list<int>::iterator it; for(itlst.begi…...

Linux 基础1
gcc的编译过程 预处理——编译——汇编——链接 Linux文件类型 普通文件,目录文件,管道文件,链接文件,块设备文件,字符设备文件,套接字文件 Linux系统下的软链接和硬链接有什么异同 linux中软链接和硬…...
Ubuntu Server 安装 XFCE4桌面
Ubuntu Server没有桌面环境,一些软件有桌面环境使用起来才更加方便,所以我尝试安装桌面环境。常用的桌面环境有:GNOME、KDE Plasma、XFCE4等。这里我选择安装XFCE4桌面环境,主要因为它是一个极轻量级的桌面环境,适合内…...

xarray转换nc文件经度范围:0-360更改为-180-180
原文见https://blog.csdn.net/weixin_44237337/article/details/119707332,因为觉得很实用就转载一下。 lon_name longitude #你的nc文件中经度的命名 ds[longitude_adjusted] xr.where(ds[lon_name] > 180,ds[lon_name] - 360,ds[lon_name]) ds (ds.swap_d…...
:数据类型与操作数据库和数据表)
MySQL 基础学习(1):数据类型与操作数据库和数据表
MySQL 基础学习:数据类型与操作数据库和数据表 在这篇博客中,我们将深入学习 MySQL 的基础操作,重点关注数据库和数据表的操作,以及 MySQL 中常见的数据类型。希望本文能帮助你更好地理解和掌握 MySQL 的基本用法。 一、操作数据…...

一个简单的自适应html5导航模板
一个简单的 HTML 导航模板示例,它包含基本的导航栏结构,同时使用了 CSS 进行样式美化,让导航栏看起来更美观。另外,还添加了一些 JavaScript 代码,用于在移动端实现导航菜单的展开和收起功能。 PHP <!DOCTYPE htm…...

深入解析“Wholesome”的含义及用法
深入解析“Wholesome”的含义及用法 一、引言 在阅读英文材料时,我们经常会遇到一些词汇,它们的含义既有直接的字面意思,又带有丰富的情感色彩。“Wholesome”就是这样一个词。它表面上看似简单,但在不同语境中却有多重内涵。在…...

供水企业满意度调查报告
民安智库作为一家独立的第三方评估机构,致力于为供水企业提供全面的客户满意度调查服务。本报告将详细介绍民安智库的调查方法、结果和建议,以帮助供水企业更好地理解其服务质量和客户需求。 一、调查方法 民安智库首先对客户进行了分类,包括…...

实现B-树
一、概述 1.历史 B树(B-Tree)结构是一种高效存储和查询数据的方法,它的历史可以追溯到1970年代早期。B树的发明人Rudolf Bayer和Edward M. McCreight分别发表了一篇论文介绍了B树。这篇论文是1972年发表于《ACM Transactions on Database S…...

无人机微波图像传输数据链技术详解
无人机微波图像传输数据链技术是无人机通信系统中的关键组成部分,它确保了无人机与地面站之间高效、可靠的图像数据传输。以下是对该技术的详细解析: 一、技术原理 无人机微波图像传输数据链主要基于微波通信技术实现。在数据链路中,图像数…...

【Leetcode 热题 100】300. 最长递增子序列
问题背景 给你一个整数数组 n u m s nums nums,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如, [ 3 , 6 , 2 , 7 ] [3,6,2,7] [3,6,2…...

macos的图标过大,这是因为有自己的设计规范
苹果官方链接:App 图标 | Apple Developer Documentation 这个在官方文档里有说明,并且提供了sketch 和 ps 的模板。 figma还提供了模板: Figma...

信号处理以及队列
下面是一个使用C和POSIX信号处理以及队列的简单示例。这个示例展示了如何使用信号处理程序将信号放入队列中,并在主循环中处理这些信号。 #include <iostream> #include <csignal> #include <queue> #include <mutex> #include <thread…...

微信阅读网站小程序的设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

美国公司有意收购TikTok(抖音)
众所周知,2016年TikTok由字节跳动集团推出,最初以“抖音”为名在中国市场推广,随后于2017年下半年出海,面向国际市场更名为“TikTok”。 新华社1月19日快讯:“TikTok公司当地时间18日晚通知美国用户,由于美…...