基于paddleocr的表单关键信息抽取
全流程如下:

数据集
XFUND数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集分别为:
ZH(中文)、JA(日语)、ES(西班牙)、FR(法语)、IT(意大利)、DE(德语)、PT(葡萄牙),
选取中文数据集,链接如下
GitHub - doc-analysis/XFUND: XFUND: A Multilingual Form Understanding Benchmark

进行下面这两步,命令行如下:
! wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
! tar -xf XFUND.tar目录结构

数据集标注格式

转换数据格式
转换脚本
按我这个来,他那个有些bug
import os
import cv2
import json
import shutil
from PIL import Image,ImageDrawtrain_path = '/home/aistudio/data/data140302/XFUND_ori/zh.train/'
eval_path = '/home/aistudio/data/data140302/XFUND_ori/zh.val/'
drawImg = False
if drawImg:os.makedirs('draw_imgs')rec_save_path = '/home/aistudio/XFUND/rec_imgs/'
if not os.path.exists(rec_save_path):os.makedirs(rec_save_path)def transfer_xfun_data(json_path=None, det_output_file=None, rec_output_file=None, di=set()):with open(json_path, "r", encoding='utf-8') as fin:lines = fin.readlines()json_info = json.loads(lines[0])documents = json_info["documents"]if 'train' in json_path:path = '/zh.train/'else:path = '/zh.val/'det_file = open(det_output_file, "w")rec_file = open(rec_output_file, "w")for idx, document in enumerate(documents):img_info = document["img"]document = document["document"]image_path = img_info["fname"]img = cv2.imread('data/data140302/XFUND_ori'+path+image_path)# 保存信息到检测文件中det_info = []if drawImg:img_pil = Image.fromarray(img)draw = ImageDraw.Draw(img_pil)num=0for doc in document:# 检测文件信息det_info.append({"transcription":doc["text"], "points":[[doc["box"][0],doc["box"][1]],[doc["box"][2],doc["box"][1]],[doc["box"][2],doc["box"][3]],[doc["box"][0],doc["box"][3]]]})# 保存识别图片pic = img[doc["box"][1]:doc["box"][3], doc["box"][0]:doc["box"][2]]rec_save_dir = rec_save_path + os.path.splitext(image_path)[0]+'_'+str(num).zfill(3)+".jpg"cv2.imwrite(rec_save_dir,pic)# 识别文件信息rec_line = '/'.join(rec_save_dir.split('/')[-2:]) + '\t' + doc["text"] + '\n'rec_file.write(rec_line)# 字典di = di | set(doc["text"])num+=1if drawImg:draw.polygon([(doc["box"][0],doc["box"][1]), (doc["box"][2],doc["box"][1]), (doc["box"][2],doc["box"][3]), (doc["box"][0],doc["box"][3])], outline=(255,0,0))if drawImg:img_pil.save('./draw_imgs/'+image_path)det_line = path+ image_path + '\t' + json.dumps(det_info,ensure_ascii=False) +'\n'det_file.write(det_line)det_file.close() rec_file.close()return di# =================检测文件=================
det_train = '/home/aistudio/XFUND/det_gt_train.txt'
det_test = '/home/aistudio/XFUND/det_gt_val.txt'# =================识别文件=================
rec_train = '/home/aistudio/XFUND/rec_gt_train.txt'
rec_test = '/home/aistudio/XFUND/rec_gt_val.txt'di_xfund = set()
di_xfund = transfer_xfun_data("/home/aistudio/data/data140302/XFUND_ori/zh.train.json", det_train, rec_train, di_xfund)
di_xfund = transfer_xfun_data("/home/aistudio/data/data140302/XFUND_ori/zh.val.json", det_test, rec_test, di_xfund)
文本检测的标注格式
中间用’\t’分隔:
”图像文件名 json.dumps编码的图像标注信息”ch4_test_images/img_61.jpg [{“transcription”: “MASA”, “points”:[[310, 104], [416, 141], [418, 216], [312, 179]]}, {⋯}]
json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 points 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。transcription 表示当前文本框的文字,当其内容为“###”时,表示该文本框无效,在训练时会跳过。
文本识别的标注格式
txt文件中默认请将图片路径和图片标签用’\t’分割,如用其他方式分割将造成训练报错

文本检测
方案1:• PP-OCRv2中英文超轻量检测预训练模型

下载模型
%mkdir /home/aistudio/PaddleOCR/pretrain/
%cd /home/aistudio/PaddleOCR/pretrain/
! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
! tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
% cd ..修改配置,主要是改路径

评估如下
%cd /home/aistudio/PaddleOCR
! python tools/eval.py \-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml
精度达到77%
finetune
100epoch,我直接用训练好的权重文件了
%cd /home/aistudio/PaddleOCR/
! python tools/eval.py \-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \-o Global.checkpoints="pretrain/ch_db_mv3-student1600-finetune/best_accuracy"
未finetune的如下,效果略微差了一点

导出模型
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。执行下面命令,即可导出模型。
%cd /home/aistudio/PaddleOCR/
! python tools/export_model.py \-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \-o Global.pretrained_model="pretrain/ch_db_mv3-student1600-finetune/best_accuracy" \Global.save_inference_dir="./output/det_db_inference/"会有这些文件

文本识别
预训练模型
%cd /home/aistudio/PaddleOCR/pretrain/
! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar
! tar -xf ch_PP-OCRv2_rec_train.tar && rm -rf ch_PP-OCRv2_rec_train.tar
% cd ..下载预训练模型,评估结果如下

XFUND数据集+finetune
训练代码如下,喜欢自己去跑,太慢了,玩不起
%cd /home/aistudio/PaddleOCR/! CUDA_VISIBLE_DEVICES=0 python tools/train.py \-c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml用人训练好的结果如下

XFUND数据集+finetune+真实通用识别数据
这部分数据人家没公开,公开了26W我也跑不动,还行,权重文件给了

下面就跟检测那部分一样导出模型就行了
文档视觉问答
主要分为SER和RE两个任务,先下载权重
%cd pretrain
#下载SER模型
! wget https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar && tar -xvf ser_LayoutXLM_xfun_zh.tar
%rm -rf ser_LayoutXLM_xfun_zh.tar
#下载RE模型
! wget https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar && tar -xvf re_LayoutXLM_xfun_zh.tar
%rm -rf re_LayoutXLM_xfun_zh.tar
%cd ../SER
SER: 语义实体识别 (Semantic Entity Recognition), 可以完成对图像中的文本识别与分类。
对于XFUND数据集,有QUESTION, ANSWER, HEADER 3种类别
用下面的命令下载数据集,不要用他环境提供的,会报错,数据格式有问题
! wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
! tar -xf XFUND.tar进行训练,命令行如下
%cd /home/aistudio/PaddleOCR/
! CUDA_VISIBLE_DEVICES=0 python3 tools/train.py -c configs/vqa/ser/layoutxlm.yml进行评估,代码如下
! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \-c configs/vqa/ser/layoutxlm.yml \-o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
完成ocr+SER串联
! CUDA_VISIBLE_DEVICES=0 python tools/infer_vqa_token_ser.py \-c configs/vqa/ser/layoutxlm.yml \-o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/ \Global.infer_img=doc/vqa/input/zh_val_42.jpg结果如下
import cv2
from matplotlib import pyplot as plt
# 在notebook中使用matplotlib.pyplot绘图时,需要添加该命令进行显示
%matplotlib inlineimg = cv2.imread('output/ser/zh_val_42_ser.jpg')
plt.figure(figsize=(48,24))
plt.imshow(img)
RE
基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair)
问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
训练命令如下
! CUDA_VISIBLE_DEVICES=0 python tools/train.py \-c configs/vqa/re/layoutxlm.yml进行评估
! CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py \-c configs/vqa/re/layoutxlm.yml \-o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/
串联全部
%cd /home/aistudio/PaddleOCR
! CUDA_VISIBLE_DEVICES=0 python3 tools/infer_vqa_token_ser_re.py \-c configs/vqa/re/layoutxlm.yml \-o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/ \Global.infer_img=test_imgs/ \-c_ser configs/vqa/ser/layoutxlm.yml \-o_ser Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
结果大概这样

红色是问题,蓝色是答案,用绿线连接表示关系
修改文件,导出excel
vim /home/aistudio/PaddleOCR/tools/infer_vqa_token_ser_re.py为了输出信息匹配对,我们修改tools/infer_vqa_token_ser_re.py文件中的line 194-197。
fout.write(img_path + "\t" + json.dumps({"ser_resule": result,}, ensure_ascii=False) + "\n")
更改为
result_key = {}
for ocr_info_head, ocr_info_tail in result:result_key[ocr_info_head['text']] = ocr_info_tail['text']fout.write(img_path + "\t" + json.dumps(result_key, ensure_ascii=False) + "\n")import json
import xlsxwriter as xwworkbook = xw.Workbook('output/re/infer_results.xlsx')
format1 = workbook.add_format({'align': 'center','valign': 'vcenter','text_wrap': True,
})
worksheet1 = workbook.add_worksheet('sheet1')
worksheet1.activate()
title = ['姓名', '性别', '民族', '文化程度', '身份证号码', '联系电话', '通讯地址']
worksheet1.write_row('A1', title)
i = 2with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:lines = fin.readlines()for line in lines:img_path, result = line.strip().split('\t')result_key = json.loads(result)# 写入Excelrow_data = [result_key['姓名'], result_key['性别'], result_key['民族'], result_key['文化程度'], result_key['身份证号码'], result_key['联系电话'], result_key['通讯地址']]row = 'A' + str(i)worksheet1.write_row(row, row_data, format1)i+=1
workbook.close()
相关文章:
基于paddleocr的表单关键信息抽取
全流程如下: 数据集 XFUND数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集分别为: ZH(中文)、JA(日语)、ES(西班牙)、FR(法语)、IT(意大利)、DE(德语)、PT(葡萄牙)&a…...

爬虫基础之爬取某基金网站+数据分析
声明: 本案例仅供学习参考使用,任何不法的活动均与本作者无关 网站:天天基金网(1234567.com.cn) --首批独立基金销售机构-- 东方财富网旗下基金平台! 本案例所需要的模块: 1.requests 2.re(内置) 3.pandas 4.pyecharts 其他均需要 pip install 模块名 爬取步骤: …...

深入理解动态规划(dp)--(提前要对dfs有了解)
前言:对于动态规划:该算法思维是在dfs基础上演化发展来的,所以我不想讲的是看到一个题怎样直接用动态规划来解决,而是说先用dfs搜索,一步步优化,这个过程叫做动态规划。(该文章教你怎样一步步的…...

(1)STM32 USB设备开发-基础知识
开篇感谢: 【经验分享】STM32 USB相关知识扫盲 - STM32团队 ST意法半导体中文论坛 单片机学习记录_桃成蹊2.0的博客-CSDN博客 USB_不吃鱼的猫丿的博客-CSDN博客 1、USB鼠标_哔哩哔哩_bilibili usb_冰糖葫的博客-CSDN博客 USB_lqonlylove的博客-CSDN博客 USB …...

基于STM32单片机设计的宠物喂食监控系统
1. 项目开发背景 随着宠物数量的增加,尤其是人们对宠物的养护需求日益增多,传统的人工喂养和管理方式难以满足现代养宠生活的需求。人们越来越希望通过智能化手段提高宠物养护的质量和效率,特别是对于宠物喂食、饮水、温湿度控制等方面的智能…...

MATLAB绘图:随机彩色圆点图
这段代码在MATLAB中生成并绘制了500个随机位置和颜色的散点图。通过随机生成的x和y坐标以及颜色,用户可以直观地观察到随机点的分布。这种可视化方式在数据分析、统计学和随机过程的演示中具有广泛的应用。 文章目录 运行结果代码代码讲解 运行结果 代码 clc; clea…...

重定向与缓冲区
4种重定向 我们有如下的代码: #include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> #include <string.h>#define FILE_NAME "log.txt"int main() {close(1)…...

【Elasticsearch】index:false
在 Elasticsearch 中,index 参数用于控制是否对某个字段建立索引。当设置 index: false 时,意味着该字段不会被编入倒排索引中,因此不能直接用于搜索查询。然而,这并不意味着该字段完全不可访问或没有其他用途。以下是关于 index:…...

Golang Gin系列-8:单元测试与调试技术
在本章中,我们将探讨如何为Gin应用程序编写单元测试,使用有效的调试技术,以及优化性能。这包括设置测试环境、为处理程序和中间件编写测试、使用日志记录、使用调试工具以及分析应用程序以提高性能。 为Gin应用程序编写单元测试 设置测试环境…...

九、CSS工程化方案
一、PostCSS介绍 二、PostCSS插件的使用 项目安装 - npm install postcss-cli 全局安装 - npm install postcss-cli -g postcss-cli地址:GitHub - postcss/postcss-cli: CLI for postcss postcss地址:GitHub - postcss/postcss: Transforming styles…...

YOLOv11改进,YOLOv11检测头融合DSConv(动态蛇形卷积),并添加小目标检测层(四头检测),适合目标检测、分割等任务
前言 精确分割拓扑管状结构例如血管和道路,对各个领域至关重要,可确保下游任务的准确性和效率。然而,许多因素使任务变得复杂,包括细小脆弱的局部结构和复杂多变的全局形态。在这项工作中,注意到管状结构的特殊特征,并利用这一知识来引导 DSCNet 在三个阶段同时增强感知…...

大数据治理实战指南:数据质量、合规与治理架构
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 引言 随着企业数字化转型的加速,大数据已成为驱动业务决策的核心资产。然而,数据治理的缺失或不完善&…...

SQL Server 建立每日自动log备份的维护计划
SQLServer数据库可以使用维护计划完成数据库的自动备份,下面以在SQL Server 2012为例说明具体配置方法。 1.启动SQL Server Management Studio,在【对象资源管理器】窗格中选择数据库实例,然后依次选择【管理】→【维护计划】选项࿰…...

three.js+WebGL踩坑经验合集(4.2):为什么不在可视范围内的3D点投影到2D的结果这么不可靠
上一篇,笔者留下了一个问题,three.js内置的THREE.Vector3.project方法算出来的结果对于超出屏幕可见范围的点来说错得相当离谱。 three.jsWebGL踩坑经验合集(4.1):THREE.Line2的射线检测问题(注意本篇说的是Line2,同样也不是阈值…...

window保存好看的桌面壁纸
1、按下【WINR】快捷键调出“运行”窗口,输入以下命令后回车。 %localappdata%\Packages\Microsoft.Windows.ContentDeliveryManager_cw5n1h2txyewy\LocalState\Assets 2、依次点击【查看】【显示】,勾选【隐藏的项目】,然后按【CtrlA】全部…...

Protobuf序列化协议使用指南
简介 在本篇博客中,将会介绍protobuf的理论及使用方法。该文章仅做分享使用及自我复习使用,使用的图片来自百度,无法找到作者,如若侵权请联系删除。 目录 简介 概述 1.protobuf是什么? 2.序列化/反序列是什么&…...

83,【7】BUUCTF WEB [MRCTF2020]你传你[特殊字符]呢
进入靶场 图片上这个人和另一道题上的人长得好像 54,【4】BUUCTF WEB GYCTF2020Ezsqli-CSDN博客 让我们上传文件 桌面有啥传啥 /var/www/html/upload/344434f245b7ac3a4fae0a6342d1f94a/123.php.jpg 成功后我就去用蚁剑连了,连不上 看了别的wp知需要…...

低代码系统-产品架构案例介绍、轻流(九)
轻流低代码产品定位为零代码产品,试图通过搭建来降低企业成本,提升业务上线效率。 依旧是从下至上,从左至右的顺序 名词概述运维层底层系统运维层,例如上线、部署等基础服务体系内置的系统能力,发消息、组织和权限是必…...

Linux——网络(udp)
文章目录 目录 文章目录 前言 一、upd函数及接口介绍 1. 创建套接字 - socket 函数 2. 绑定地址和端口 - bind 函数 3. 发送数据 - sendto 函数 4. 接收数据 - recvfrom 函数 5. 关闭套接字 - close 函数 二、代码示例 1.服务端 2.客户端 总结 前言 Linux——网络基础…...

Nxopen 直齿轮参数化设计
NXUG1953 Visualstudio 2019 参考论文: A Method for Determining the AGMA Tooth Form Factor from Equations for the Generated Tooth Root Fillet //FullGear// Mandatory UF Includes #include <uf.h> #include <uf_object_types.h>// Internal I…...

初阶数据结构:链表(二)
目录 一、前言 二、带头双向循环链表 1.带头双向循环链表的结构 (1)什么是带头? (2)什么是双向呢? (3)那什么是循环呢? 2.带头双向循环链表的实现 (1)节点结构 (2…...

Rust:高性能与安全并行的编程语言
引言 在现代编程世界里,开发者面临的最大挑战之一就是如何平衡性能与安全性。在许多情况下,C/C这样的系统级编程语言虽然性能强大,但其内存管理的复杂性导致了各种安全漏洞。为了解决这些问题,Rust 作为一种新的系统级编程语言进入…...

使用openwrt搭建ipsec隧道
背景:最近同事遇到了个ipsec问题,做的ipsec特性,ftp下载ipv6性能只有100kb, 正面定位该问题也蛮久了,项目没有用openwrt, 不过用了开源组件strongswan, 加密算法这些也是内核自带的,想着开源的不太可能有问题ÿ…...
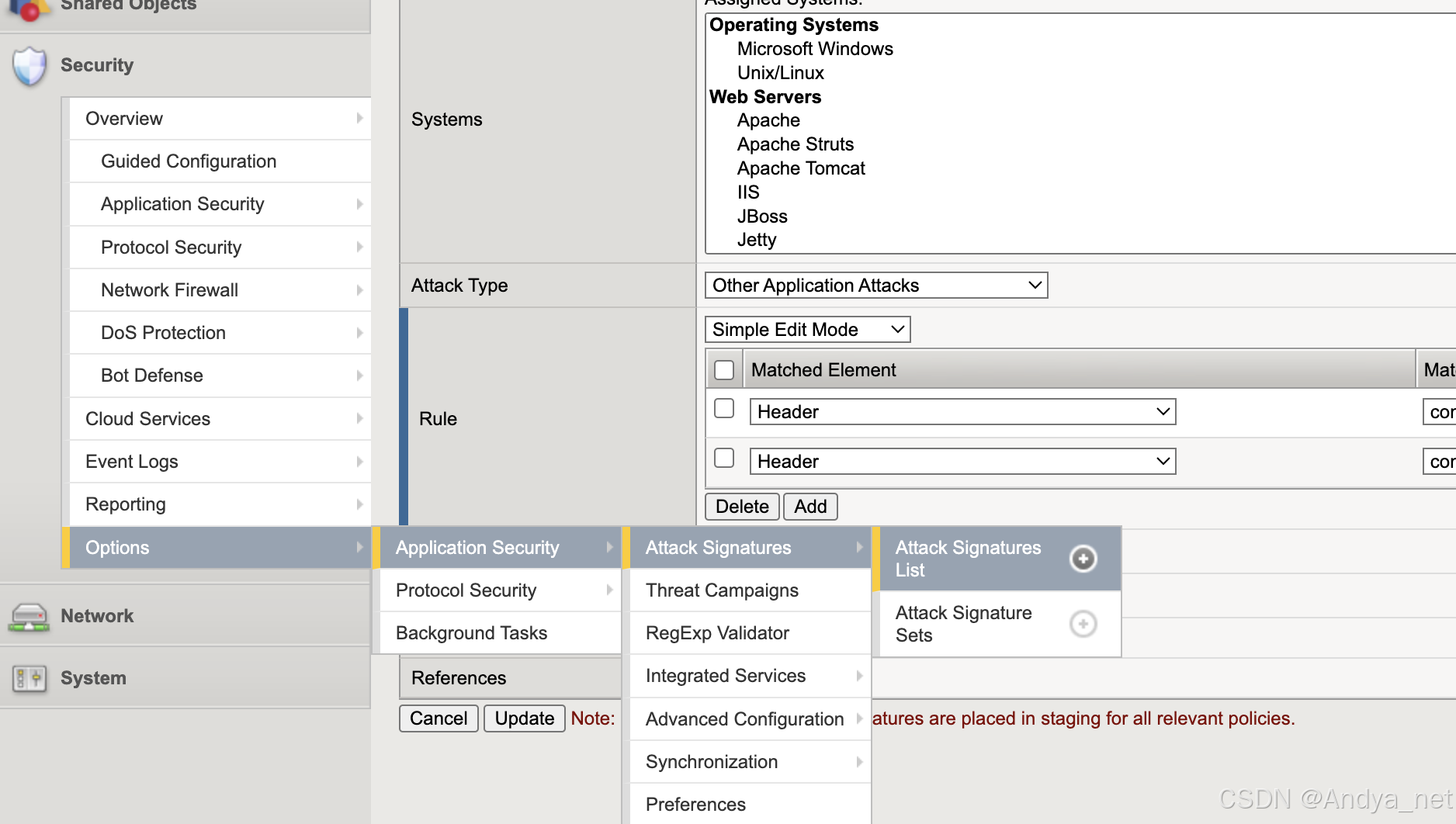
网络安全 | F5-Attack Signatures详解
关注:CodingTechWork 关于攻击签名 攻击签名是用于识别 Web 应用程序及其组件上攻击或攻击类型的规则或模式。安全策略将攻击签名中的模式与请求和响应的内容进行比较,以查找潜在的攻击。有些签名旨在保护特定的操作系统、Web 服务器、数据库、框架或应…...

MATLAB绘图时线段颜色、数据点形状与颜色等设置,介绍
MATLAB在绘图时,设置线段颜色和数据点的形状与颜色是提高图形可读性与美观性的重要手段。本文将详细介绍如何在 MATLAB 中设置这些属性。 文章目录 线段颜色设置单字母颜色表示法RGB 值表示法 数据点的形状与颜色设置设置数据点颜色和形状示例代码 运行结果小结 线段…...
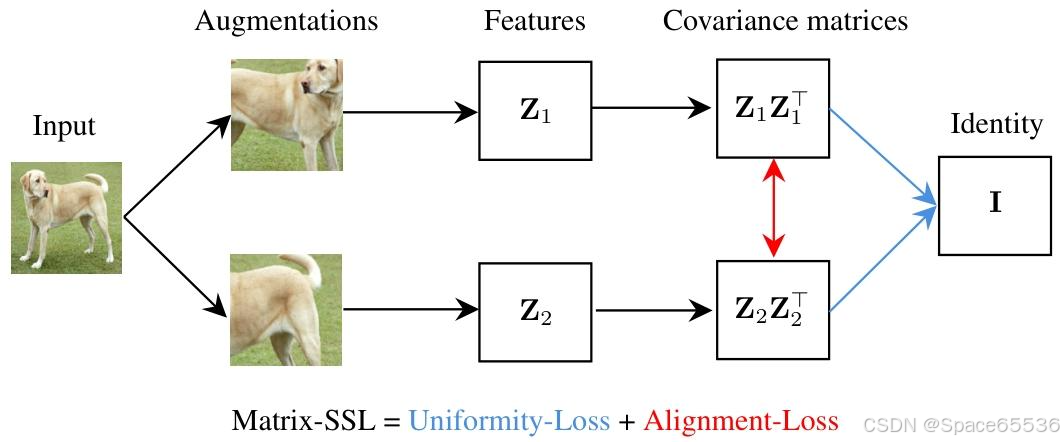
论文速读|Matrix-SSL:Matrix Information Theory for Self-Supervised Learning.ICML24
论文地址:Matrix Information Theory for Self-Supervised Learning 代码地址:https://github.com/yifanzhang-pro/matrix-ssl bib引用: article{zhang2023matrix,title{Matrix Information Theory for Self-Supervised Learning},author{Zh…...

FPGA工程师成长四阶段
朋友,你有入行三年、五年、十年的职业规划吗?你知道你所做的岗位未来该如何成长吗? FPGA行业的发展近几年是蓬勃发展,有越来越多的人才想要或已经踏进了FPGA行业的大门。很多同学在入行FPGA之前,都会抱着满腹对职业发…...
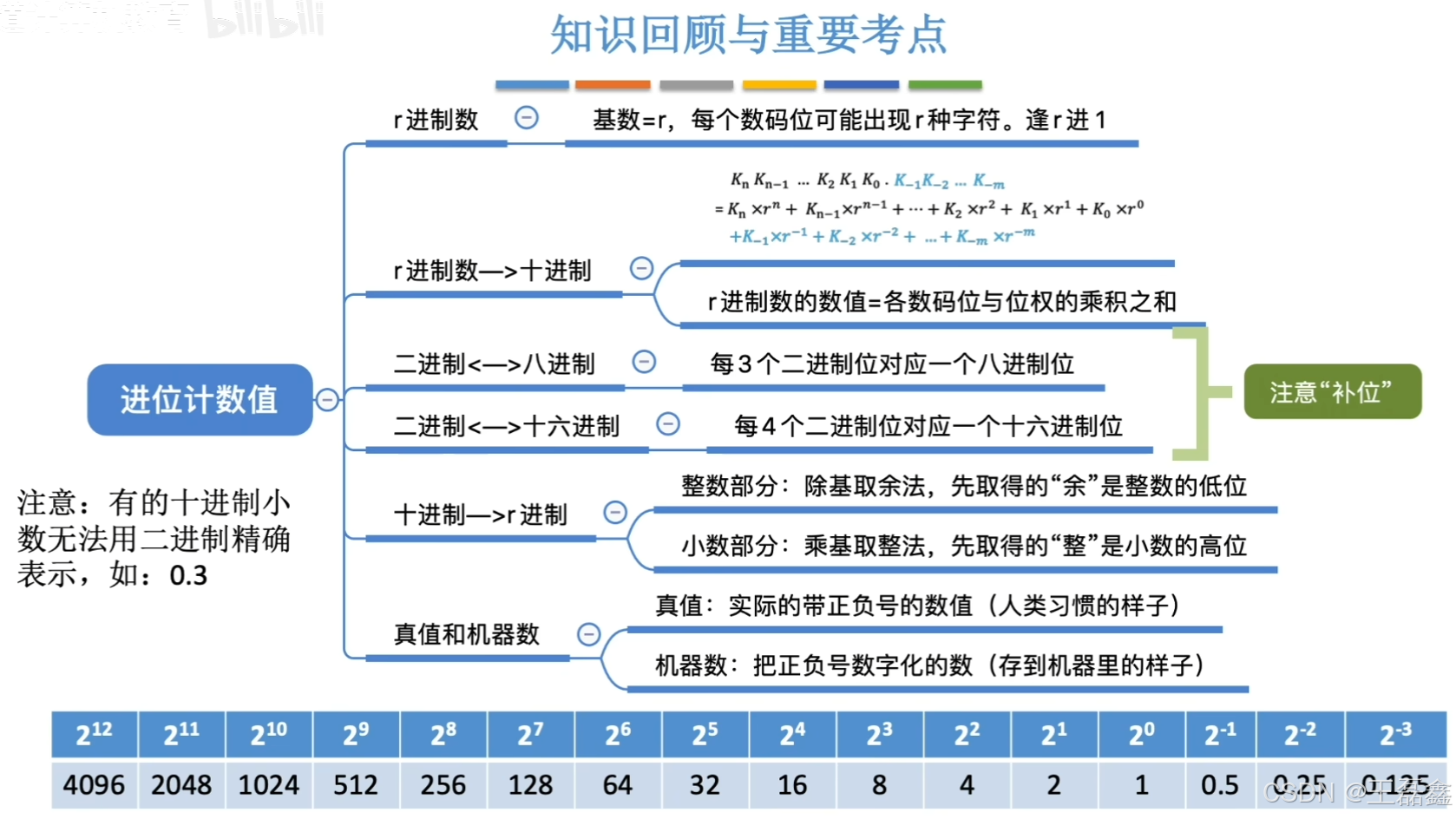
计算机组成原理(2)王道学习笔记
数据的表示和运算 提问:1.数据如何在计算机中表示? 2.运算器如何实现数据的算术、逻辑运算? 十进制计数法 古印度人发明了阿拉伯数字:0,1,2,3,4,5,6&#…...

Spring中的事件和事件监听器是如何工作的?
目录 一、事件(Event) 二、事件发布器(Event Publisher) 三、事件监听器(Event Listener) 四、使用场景 五、总结 以下是关于Spring中的事件和事件监听器的介绍与使用说明,结合了使用场景&…...

3097. 或值至少为 K 的最短子数组 II
3097. 或值至少为 K 的最短子数组 II 题目链接:3097. 或值至少为 K 的最短子数组 II 代码如下: class Solution { public:int minimumSubarrayLength(vector<int>& nums, int k) {int res INT_MAX;for (int i 0;i < nums.size();i) {in…...