分析一个深度学习项目并设计算法和用PyTorch实现的方法和步骤
算法设计分析
明确问题类型
- 分类问题:例如图像分类,像判断一张图片是猫还是狗。算法设计可能会采用经典的卷积神经网络(CNN)结构,如ResNet、VGG等。以ResNet为例,其通过残差连接解决了深层网络训练时梯度消失的问题,使得网络可以更深,从而学习到更复杂的图像特征。
除了ResNet、VGG等经典卷积神经网络算法外,深度学习图像分类还有以下算法和方法:
经典CNN改进算法
- DenseNet:即密集连接卷积网络,其核心是在各层之间建立密集连接,使每一层都能直接获取前面所有层的特征图,加强了特征传播,提升了模型的表达能力,减少了参数数量,降低了过拟合风险。
- InceptionNet:也叫GoogLeNet,引入了Inception模块,该模块能并行地使用不同大小的卷积核进行卷积操作,还使用了平均池化层代替全连接层等,有效减少了模型参数,提高了计算效率和分类准确率。
注意力机制相关算法
- CBAM:即卷积块注意力模块,它将通道注意力机制和空间注意力机制结合起来,能让模型自适应地关注图像中更重要的区域和通道特征,提升对关键信息的提取能力,从而提高分类精度。
- SENet:即挤压激励网络,通过挤压和激励操作,对通道间的依赖关系进行建模,自适应地调整每个通道的重要性,增强了模型对不同特征的关注能力,在图像分类等任务中取得了很好的效果。
其他算法
- Vision Transformer(ViT):将Transformer架构应用于图像分类任务,把图像分割成多个patch,将其线性嵌入后输入Transformer编码器进行处理,能捕捉长序列图像特征间的依赖关系,在大规模图像数据集上表现出色。
- Swin Transformer:一种基于滑动窗口的Transformer架构,通过在局部窗口内进行自注意力计算,降低了计算复杂度,提高了对图像局部特征的建模能力,在图像分类、目标检测等多个视觉任务中都取得了优异成绩。
- 回归问题:比如预测房价。可能会设计一个多层感知机(MLP),输入房屋的面积、房间数量等特征,输出价格。在算法设计上要考虑选择合适的激活函数,如对于输出层可以使用线性函数(因为是回归问题),隐藏层可以用ReLU等激活函数来增加模型的非线性表达能力。
除了上述提及的基于多层感知机(MLP)解决深度学习回归问题的方法外,还有以下几种常见的算法和方法:
卷积神经网络(CNN)
- 原理:利用卷积层、池化层和全连接层自动提取数据的特征。卷积层通过卷积核在数据上滑动进行卷积操作,提取局部特征;池化层对卷积层的输出进行下采样,减少数据维度;全连接层将提取到的特征进行整合,输出最终结果。
- 应用场景:在处理具有空间结构的数据,如图像、视频等回归问题时表现出色。比如通过房屋外观图像预测房价,可利用CNN提取图像中的建筑风格、周边环境等特征用于房价预测。
循环神经网络(RNN)及其变体
- 原理:RNN能够处理序列数据,通过隐藏状态记住之前的信息,并在每个时间步更新隐藏状态和输出。长短期记忆网络(LSTM)和门控循环单元(GRU)是RNN的变体,能更好地处理长期依赖问题。
- 应用场景:适用于时间序列数据的回归问题。例如在分析房价随时间的变化趋势时,可利用LSTM或GRU处理历史房价数据,预测未来房价走势。
注意力机制(Attention Mechanism)
- 原理:让模型在处理数据时能够自动聚焦于关键信息,为不同的输入特征分配不同的权重,从而更有效地利用数据中的重要信息。
- 应用场景:可与其他深度学习模型结合,在处理复杂的回归问题时提高模型的性能。如在房价预测中,可让模型自动关注对房价影响较大的特征,如房屋所在区域的学校质量、交通便利性等。
生成对抗网络(GAN)的变体
- 原理:生成对抗网络由生成器和判别器组成,二者相互对抗、不断优化。一些GAN的变体,如条件生成对抗网络(cGAN)可以在给定某些条件的情况下生成符合特定分布的数据。
- 应用场景:在房价预测中,可利用cGAN根据给定的房屋特征和市场条件等生成房价数据,用于预测和数据增强等任务。
图神经网络(GNN)
- 原理:用于处理具有图结构的数据,能够对图中的节点和边进行建模,学习节点之间的关系和特征表示。
- 应用场景:在房价预测中,如果考虑房屋之间的地理位置关系、周边设施的关联等图结构信息,GNN可以有效地利用这些信息进行回归预测。
- 生成问题:如生成对抗网络(GAN)用于生成图像。生成器网络试图生成逼真的图像,鉴别器网络则用于判断图像是真实的还是生成的。它们相互对抗训练,促使生成器生成质量更高的图像。
除了生成对抗网络(GAN)外,深度学习中用于生成问题的算法和方法还有以下几种:
变分自编码器(VAE)
- 原理:VAE基于概率图模型,由编码器和解码器构成。编码器将输入数据映射到潜在空间的分布,解码器从潜在空间采样生成数据。训练时通过最大化变分下界来学习数据分布,使生成的数据既有多样性又与原始数据分布相似。
- 应用:在图像生成中可生成新的图像样本,在文本生成中也能根据学习到的文本分布生成新文本。
自回归模型
- 原理:自回归模型根据历史数据预测下一个数据,以序列数据为输入,如循环神经网络(RNN)及其变体长短期记忆网络(LSTM)、门控循环单元(GRU)等。通过逐个生成元素来构建输出序列,每个元素的生成基于之前生成的元素和模型参数。
- 应用:在自然语言处理的文本生成中应用广泛,如生成故事、对话等,也可用于时间序列数据生成,如股票价格预测等。
流模型(Flow-based Models)
- 原理:流模型通过一系列可逆变换将简单的先验分布转化为复杂的数据分布。利用可逆神经网络实现变换,通过最大化数据的对数似然进行训练,能精确计算数据点的概率密度。
- 应用:在图像生成、语音合成等领域有应用,能生成高质量的样本,在密度估计任务中表现出色。
扩散模型(Diffusion Models)
- 原理:扩散模型基于非平衡热力学,正向过程逐步向数据添加噪声直至变为纯噪声,反向过程学习从噪声中恢复原始数据。通过神经网络预测噪声来实现数据生成,训练时最小化预测噪声与真实噪声的差异。
- 应用:在图像生成领域取得了显著成果,能生成高分辨率、逼真的图像,在文本到图像生成等跨模态任务中也有出色表现。
数据预处理与特征工程
- 数据归一化:对于图像数据,可能将像素值归一化到[0, 1]或[-1, 1]区间。在PyTorch中,可以使用 torchvision.transforms 中的 Normalize 函数来实现。例如,对于MNIST手写数字数据集,将图像数据归一化可以帮助模型更快地收敛。
除了上述图像数据归一化方法外,深度学习中数据归一化还有以下算法和方法:
数值型数据归一化
- Min-Max标准化:将数据映射到[0,1]或其他指定区间。公式为 x n o r m = x − x m i n x m a x − x m i n x_{norm}=\frac{x - x_{min}}{x_{max}-x_{min}} xnorm=xmax−xminx−xmin, x m i n x_{min} xmin和 x m a x x_{max} xmax是数据中的最小值和最大值。
- Z-Score标准化:使数据符合均值为0,标准差为1的正态分布。公式为 x n o r m = x − μ σ x_{norm}=\frac{x - \mu}{\sigma} xnorm=σx−μ, μ \mu μ是均值, σ \sigma σ是标准差。
- 对数变换:对数据取对数,可用于将具有指数增长或偏态分布的数据转换为更接近正态分布的数据,如 x n o r m = log ( x + 1 ) x_{norm}=\log(x + 1) xnorm=log(x+1)。
- Box-Cox变换:一种广义的幂变换方法,可用于将数据转换为更接近正态分布的形式,在处理非正态数据时很有用,公式为 y ( λ ) = { x λ − 1 λ , λ ≠ 0 ln ( x ) , λ = 0 y(\lambda)=\begin{cases}\frac{x^{\lambda}-1}{\lambda}, & \lambda\neq0 \\ \ln(x), & \lambda = 0\end{cases} y(λ)={λxλ−1,ln(x),λ=0λ=0。
文本数据归一化
- 词频-逆文档频率(TF-IDF):用于衡量一个词在文档集合中的重要性,综合考虑词在文档中的出现频率和在整个文档集合中的稀有程度。
- Word2Vec:将文本中的单词映射到低维向量空间,通过训练词向量模型,使语义相似的单词在向量空间中距离较近。
- GloVe:全局向量表示模型,结合了词共现矩阵的全局统计信息和局部上下文信息来学习词向量。
其他数据归一化
-
白化(Whitening):使数据的协方差矩阵为单位矩阵,消除数据特征之间的相关性,且让各特征具有相同的方差。
-
层归一化(Layer Normalization):在神经网络的每一层对输入数据进行归一化,计算每个样本在该层的均值和方差并进行归一化,常用于RNN、Transformer等模型。
-
实例归一化(Instance Normalization):对每个实例(样本)的每个通道分别进行归一化,常用于图像生成等领域。
-
组归一化(Group Normalization):将通道分组,对每组通道进行归一化,在批量大小较小时表现较好。
-
特征提取(如果适用):在处理文本数据时,可能需要将文本转换为词向量。可以使用预训练的词嵌入模型(如Word2Vec、GloVe等),或者在训练过程中学习词嵌入。
除了Word2Vec、GloVe等预训练词嵌入模型外,深度学习中用于文本特征提取的算法和方法还有以下几种:
基于深度学习架构的方法
- 卷积神经网络(CNN):通过卷积层中的卷积核在文本序列上滑动进行卷积操作,捕捉文本中的局部特征,如n-gram特征。池化层则对卷积后的特征进行压缩,提取关键特征,能有效捕捉文本中的局部上下文信息,在文本分类、情感分析等任务中表现出色。
- 循环神经网络(RNN)及其变体:RNN可以处理序列数据中的长期依赖关系,其变体如LSTM(长短期记忆网络)和GRU(门控循环单元)能更好地解决长期依赖问题,能对文本中的上下文信息进行建模,适用于机器翻译、文本生成等任务。
- 注意力机制(Attention):允许模型在处理文本时动态地关注不同位置的信息,为不同的文本片段分配不同的权重,能让模型更聚焦于关键信息,提高特征提取的准确性,在机器翻译、问答系统等任务中广泛应用。
其他词嵌入相关方法
- FastText:与Word2Vec类似,但它将单词表示为字符n-gram的组合,能更好地处理未登录词,在文本分类等任务中有时能取得更好的效果。
- ELMo(Embeddings from Language Models):基于语言模型预训练得到词向量表示,它是一种深度语境化的词向量,能根据文本的上下文动态地生成词的嵌入表示,在自然语言处理的多个任务中都有很好的应用效果。
- BERT(Bidirectional Encoder Representations from Transformers):采用双向Transformer编码器,在大规模文本数据上进行无监督预训练,能学习到更丰富的文本语义信息,可用于多种自然语言处理任务的特征提取,通过微调能在各种任务上取得优异成绩。
模型架构选择与设计
- 借鉴现有架构:如果是图像识别项目,对于一般的场景识别任务可以选择轻量级的MobileNet。它的设计特点是采用深度可分离卷积,在保证一定精度的同时大大减少了计算量,适合在移动设备等资源受限的环境中使用。
- 自定义架构:如果现有架构不能满足需求,可以自定义模型。例如,设计一个包含多个LSTM层的循环神经网络(RNN)用于处理序列数据,如时间序列预测或自然语言处理中的文本生成任务。
PyTorch实现步骤
数据加载与预处理
- 使用数据集类:PyTorch提供了 torch.utils.data.Dataset 和 torch.utils.data.DataLoader 来方便地加载和批量处理数据。例如,对于CIFAR - 10图像分类数据集:
import torch
import torchvision
import torchvision.transforms as transformstransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2)
- 自定义数据集类(如果需要):如果数据格式比较特殊,需要自定义数据集类。例如,对于一个自定义的文本分类数据集,需要继承 Dataset 类,并重写 len 和 getitem 方法来实现数据的读取和预处理。
模型定义 - 使用预定义模型:
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
这里加载了预训练的ResNet18模型,可以用于图像分类等任务。如果要进行微调,可以修改最后一层的输出类别数,例如对于一个10分类任务:
num_ftrs = resnet18.fc.in_features
resnet18.fc = torch.nn.Linear(num_ftrs, 10)- 自定义模型定义:
import torch.nn as nnclass SimpleMLP(nn.Module):def __init__(self):super(SimpleMLP, self).__init__()self.fc1 = nn.Linear(784, 256)self.fc2 = nn.Linear(256, 10)self.relu = nn.ReLU()def forward(self, x):x = x.view(-1, 784)x = self.relu(self.fc1(x))x = self.fc2(x)return x
这个自定义的多层感知机可以用于MNIST手写数字分类等任务。
训练循环
- 定义损失函数和优化器:
import torch.optim as optimcriterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(resnet18.parameters(), lr=0.001, momentum=0.9)
这里以交叉熵损失函数和随机梯度下降(SGD)优化器为例,用于分类问题的模型训练。
- 训练步骤:
for epoch in range(10):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = dataoptimizer.zero_grad()outputs = resnet18(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print('Epoch %d loss: %.3f' % (epoch + 1, running_loss / len(trainloader)))
这个训练循环会迭代数据集多次(这里是10次,即10个epoch),每次迭代计算损失、反向传播并更新模型的参数。
模型评估与测试
- 在验证集上评估:
correct = 0
total = 0
with torch.no_grad():for data in val_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()
print('Accuracy of the model on the validation set: %d %%' % (100 * correct / total))
- 在测试集上测试(最终评估):类似于在验证集上的评估,只是使用测试集的数据,这可以得到模型在未见过的数据上的性能指标,如准确率、召回率等(根据任务而定)。
分析一个深度学习项目并设计算法,以及使用PyTorch实现,通常包括以下几个步骤:
步骤1:明确项目需求
- 问题定义:确定你要解决的问题是什么,例如图像分类、文本生成、语音识别等。
- 性能指标:确定如何衡量模型的性能,如准确率、召回率、F1分数等。
步骤2:数据准备
- 数据收集:根据问题定义收集相应的数据。
- 数据预处理:清洗数据、标准化、数据增强等。
步骤3:选择模型架构
- 现有模型:研究并选择合适的预训练模型,如ResNet、BERT、Transformer等。
- 自定义模型:如果现有模型不满足需求,设计新的网络架构。
步骤4:算法设计
- 损失函数:选择适合问题的损失函数,如交叉熵、均方误差等。
- 优化器:选择优化算法,如SGD、Adam等。
- 正则化:设计防止过拟合的策略,如Dropout、权重衰减等。
步骤5:实现与训练
- 编码:使用PyTorch实现模型、损失函数和优化器。
- 训练:编写训练循环,监控训练过程和性能。
步骤6:评估与优化
- 评估:在测试集上评估模型性能。
- 调优:根据评估结果调整模型参数或结构。
以下是一些具体例子:
例子1:图像分类
- 问题定义:将图片分为猫、狗等类别。
- 数据准备:使用ImageNet数据集或自定义数据集。
- 模型架构:使用预训练的ResNet模型。
- 算法设计:使用交叉熵损失函数和Adam优化器。
- PyTorch实现:
import torchimport torchvision.models as modelsimport torchvision.transforms as transformsfrom torch.utils.data import DataLoaderfrom torchvision.datasets import ImageFolder# 数据预处理transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])# 数据加载dataset = ImageFolder('path_to_data', transform=transform)dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# 模型model = models.resnet50(pretrained=True)# 损失函数和优化器criterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters())# 训练循环for epoch in range(num_epochs):for inputs, labels in dataloader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()
例子2:文本生成
- 问题定义:生成连贯的文本段落。
- 数据准备:使用文本数据集,如Wikipedia文章。
- 模型架构:使用基于Transformer的GPT模型。
- 算法设计:使用语言建模损失函数和Adam优化器。
- PyTorch实现:
import torch.nn as nn from transformers import GPT2Tokenizer, GPT2LMHeadModel # 加载预训练模型和分词器 tokenizer = GPT2Tokenizer.from_pretrained('gpt2') model = GPT2LMHeadModel.from_pretrained('gpt2') # 生成文本 inputs = tokenizer("The quick brown fox jumps over the lazy dog", return_tensors="pt") outputs = model(**inputs, labels=inputs["input_ids"]) loss = outputs.loss
这些例子展示了如何从问题定义到PyTorch实现的过程。每个项目都有其独特性,因此具体实现可能会有所不同。在设计算法和实现时,重要的是要理解问题的本质,选择合适的模型和训练策略,并能够根据实验结果进行调优。
分析一个深度学习项目并设计算法,然后使用PyTorch实现,通常涉及以下几个关键步骤:问题定义、数据准备、模型选择与构建、训练与评估。下面通过几个例子来具体说明这个过程。
例子1:图像分类(手写数字识别)
问题定义:建立一个能够对手写数字进行分类的深度学习模型。
数据准备:使用MNIST数据集,包含60000张训练图片和10000张测试图片,每张图片大小为28x28像素。
模型选择与构建:选择卷积神经网络(CNN)作为模型架构。使用PyTorch构建模型,包括卷积层、池化层、全连接层等。
训练与评估:定义损失函数和优化器,使用训练数据对模型进行训练,并在测试数据上评估模型性能。
PyTorch实现示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms# 数据准备
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)# 模型构建
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3)self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)self.fc1 = nn.Linear(32 * 13 * 13, 10)def forward(self, x):x = self.pool(torch.relu(self.conv1(x)))x = x.view(-1, 32 * 13 * 13)x = self.fc1(x)return xmodel = CNN()# 训练与评估
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)for epoch in range(10): # 迭代10个epochfor i, (images, labels) in enumerate(train_loader):outputs = model(images)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 100 == 0:print(f'Epoch [{epoch+1}/10], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
例子2:图像风格迁移
问题定义:将一幅图像的风格迁移到另一幅图像上。
数据准备:准备两张图像,一张作为内容图像,另一张作为风格图像。
模型选择与构建:使用预训练的VGG模型提取图像特征,并构建风格迁移模型。
训练与评估:定义内容损失和风格损失,通过优化算法更新模型参数,使生成图像既保留内容图像的内容,又具有风格图像的风格。
PyTorch实现:此过程较复杂,通常涉及多个预训练模型和损失函数的组合,具体实现可参考相关教程或论文。
例子3:基于循环神经网络的文本分类
问题定义:利用序列数据进行文本分类。
数据准备:准备文本数据集,并进行预处理,如分词、去除停用词等。
模型选择与构建:选择循环神经网络(RNN)或其变体(如LSTM、GRU)作为模型架构。使用PyTorch构建模型,包括嵌入层、RNN层、全连接层等。
训练与评估:定义损失函数和优化器,使用训练数据对模型进行训练,并在测试数据上评估模型性能。
PyTorch实现示例(简化版):
import torch
import torch.nn as nn# 假设已有预处理好的文本数据和标签
# texts, labels = ... # 模型构建
class RNNTextClassifier(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_classes):super(RNNTextClassifier, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.rnn = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, num_classes)def forward(self, x):embedded = self.embedding(x)output, (hidden, cell) = self.rnn(embedded)hidden = hidden.squeeze(0) # 取最后一个时间步的隐藏状态logits = self.fc(hidden)return logits# 模型实例化等后续步骤省略...
相关文章:

分析一个深度学习项目并设计算法和用PyTorch实现的方法和步骤
算法设计分析 明确问题类型 分类问题:例如图像分类,像判断一张图片是猫还是狗。算法设计可能会采用经典的卷积神经网络(CNN)结构,如ResNet、VGG等。以ResNet为例,其通过残差连接解决了深层网络训练时梯度…...

大模型训练策略与架构优化实践指南
标题:大模型训练策略与架构优化实践指南 文章信息摘要: 该分析全面探讨了大语言模型训练、架构选择、部署维护等关键环节的优化策略。在训练方面,强调了pre-training、mid-training和post-training的不同定位与目标;在架构选择上…...

机器学习:支持向量机
支持向量机(Support Vector Machine)是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的广义线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。 假设两类数据可以被 H x : w T x…...

Spring Boot(6)解决ruoyi框架连续快速发送post请求时,弹出“数据正在处理,请勿重复提交”提醒的问题
一、整个前言 在基于 Ruoyi 框架进行系统开发的过程中,我们常常会遇到各种有趣且具有挑战性的问题。今天,我们就来深入探讨一个在实际开发中较为常见的问题:当连续快速发送 Post 请求时,前端会弹出 “数据正在处理,请…...

「 机器人 」扑翼飞行器控制的当前挑战与后续潜在研究方向
前言 在扑翼飞行器设计与控制方面,虽然已经取得了显著的进步,但在飞行时间、环境适应性、能量利用效率及模型精度等方面依旧存在亟待解决的挑战。以下内容概括了这些挑战和可能的改进路径。 1. 当前挑战 1.1 飞行时间短 (1)主要原因 能源存储有限(电池容量小)、驱动系…...

2023年版本IDEA复制项目并修改端口号和运行内存
2023年版本IDEA复制项目并修改端口号和运行内存 1 在idea中打开server面板,在server面板中选择需要复制的项目右键,点击弹出来的”复制配置…(Edit Configuration…)“。如果idea上没有server面板或者有server面板但没有springbo…...

Spring Boot中如何实现异步处理
在 Spring Boot 中实现异步处理可以通过使用 Async 注解和 EnableAsync 注解来实现。以下是如何配置和使用异步处理的步骤和示例代码。 步骤: 启用异步支持: 在 Spring Boot 配置类上使用 EnableAsync 注解启用异步处理。使用 Async 注解异步方法&…...

微信小程序怎么制作自己的小程序?手把手带你入门(适合新手小白观看)
对于初学者来说,制作一款微信小程序总感觉高大上,又害怕学不会。不过,今天我就用最简单、最有耐心的方式,一步一步给大家讲清楚!让你知道微信小程序的制作,居然可以这么轻松(希望你别吓跑啊!)。文中还加了实战经验&…...

Vuex 的核心概念:State, Mutations, Actions, Getters
Vuex 的核心概念:State, Mutations, Actions, Getters Vuex 是 Vue.js 的官方状态管理库,提供了集中式的状态管理机制。它的核心概念包括 State(状态)、Mutations(变更)、Actions(动作…...
缓存)
Python OrderedDict 实现 Least Recently used(LRU)缓存
OrderedDict 实现 Least Recently used(LRU)缓存 引言正文 引言 LRU 缓存是一种缓存替换策略,当缓存空间不足时,会移除最久未使用的数据以腾出空间存放新的数据。LRU 缓存的特点: 有限容量:缓存拥有固定的…...

3.3 Go函数可变参数
可变参数(variadic parameters)是一种允许函数接受任意数量参数的机制。它在函数定义中使用 ...type 来声明参数类型,所有传递的参数会被收集为一个切片,函数内部可以像操作普通切片一样处理这些参数。 package mainimport "…...

EventBus事件总线的使用以及优缺点
EventBus EventBus (事件总线)是一种组件通信方法,基于发布/订阅模式,能够实现业务代码解耦,提高开发效率 发布/订阅模式 发布/订阅模式是一种设计模式,当一个对象的状态发生变化时,所有依赖…...

vim如何设置自动缩进
:set autoindent 设置自动缩进 :set noautoindent 取消自动缩进 (vim如何使设置自动缩进永久生效:vim如何使相关设置永久生效-CSDN博客)...

LongLoRA:高效扩展大语言模型上下文长度的微调方法
论文地址:https://arxiv.org/abs/2309.12307 github地址:https://github.com/dvlab-research/LongLoRA 1. 背景与挑战 大语言模型(LLMs)通常在预定义的上下文长度下进行训练,例如 LLaMA 的 2048 个 token 和 Llama2 的…...

NoSQL使用详解
文章目录 NoSQL使用详解一、引言二、NoSQL数据库的基本概念三、NoSQL数据库的分类及使用场景1. 键值存储数据库示例代码(Redis): 2. 文档存储数据库示例代码(MongoDB): 3. 列存储数据库4. 图数据库 四、使用…...

《FreqMamba: 从频率角度审视图像去雨问题》学习笔记
paper:FreqMamba: Viewing Mamba from a Frequency Perspective for Image Deraining GitHub:GitHub - aSleepyTree/FreqMamba 目录 摘要 1、介绍 2、相关工作 2.1 图像去雨 2.2 频率分析 2.3 状态空间模型 3、方法 3.1 动机 3.2 预备知识 3…...

试用ChatGPT开发一个大语言模型聊天App
参考官方文档,安装android studio https://developer.android.com/studio/install?hlzh-cn 参考这个添加permission权限: https://blog.csdn.net/qingye_love/article/details/14452863 参考下面链接完成Android Studio 给项目添加 gradle 依赖 ht…...

第30周:文献阅读
目录 摘要 Abstract 文献阅读 问题引入 方法论 堆叠集成模型 深度学习模型 创新点 堆叠模型 敏感性和不确定性分析 优化模型 实验研究 数据集 水质指数WQI的计算 模型的构建与训练 模型性能评估 敏感性和不确定性分析 结论 摘要 本文聚焦于利用深度学习算…...

The just sharing principle: advice for advice givers
原文 A while ago I wrote about how Only you know what’s best for your application. That’s because only you fully understand the context within which you are making technical decisions. Any advice need to filtered through that context in order to determi…...

【PVE】PVE部署磁盘阵列
什么是磁盘阵列? 磁盘阵列是一种存储技术,通过将多个物理磁盘组合成一个逻辑存储单元,提供数据冗余和/或性能提升。它的核心目的是提高数据的可靠性、可用性和访问速度。磁盘阵列可以由专用硬件或软件实现。 PVE部署磁盘阵列并加入虚拟机 …...

实战Linux Swap扩展分区
文章目录 定义命令格式案例注释 定义 Swap分区是Linux系统中的一种虚拟内存实现方式,它是磁盘上预留的专用区域。当系统的物理内存不足时,会将部分不活跃的数据从物理内存移动到Swap分区,从而释放更多可用内存空间。 命令格式 关闭Swap分区…...
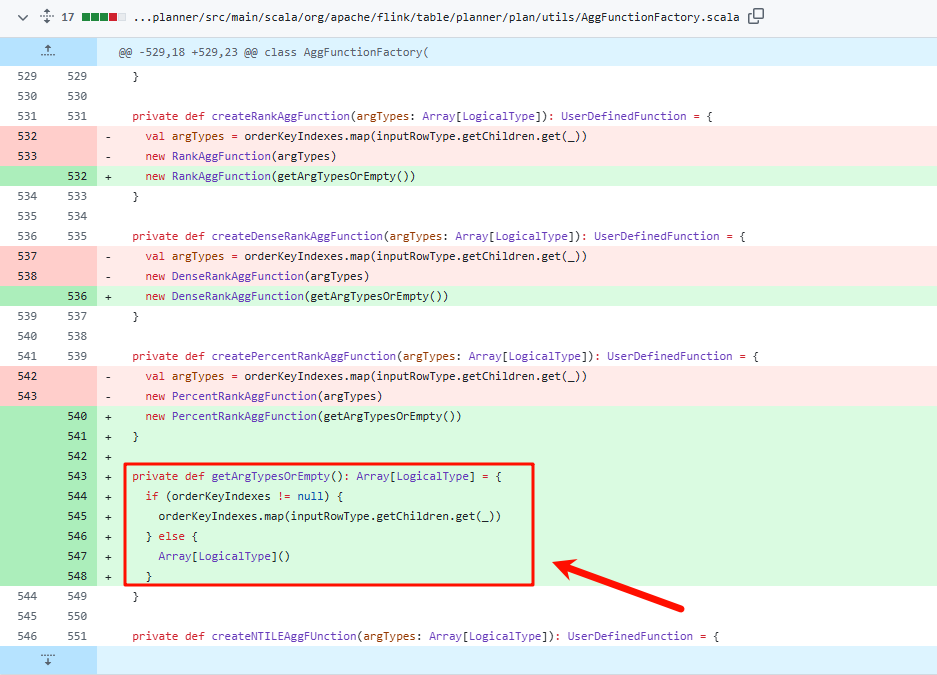
FlinkSql使用中rank/dense_rank函数报错空指针
问题描述 在flink1.16(甚至以前的版本)中,使用rank()或者dense_rank()进行排序时,某些场景会导致报错空指针NPE(NullPointerError) 报错内容如下 该报错没有行号/错误位置,无法排查 现状 目前已经确认为bug,根据github上的PR日…...

AF3 AtomAttentionDecoder类源码解读
AlphaFold3的AtomAttentionDecoder类旨在从每个 token 的表示扩展到每个原子的表示,同时通过交叉注意力机制对原子及其对关系进行建模。这种设计可以在生物分子建模中捕获复杂的原子级别交互。 源代码: class AtomAttentionDecoder(nn.Module):"""AtomAtten…...

Ubuntu介绍、与centos的区别、基于VMware安装Ubuntu Server 22.04、配置远程连接、安装jdk+Tomcat
目录 ?编辑 一、Ubuntu22.04介绍 二、Ubuntu与Centos的区别 三、基于VMware安装Ubuntu Server 22.04 下载 VMware安装 1.创建新的虚拟机 2.选择类型配置 3.虚拟机硬件兼容性 4.安装客户机操作系统 5.选择客户机操作系统 6.命名虚拟机 7.处理器配置 8.虚拟机内存…...

一个基于Python+Appium的手机自动化项目~~
本项目通过PythonAppium实现了抖音手机店铺的自动化询价,可以直接输出excel,并带有详细的LOG输出。 1.excel输出效果: 2. LOG效果: 具体文件内容见GitCode: 项目首页 - douyingoods:一个基于Pythonappium的手机自动化项目,实现了…...

ubuntu 更新24LTS中断导致“系统出错且无法恢复,请联系系统管理员”
22LTS to 24LTS 更新过程中手jian把更新程序controlC导致的。 解决 目前企图完成更新来恢复,重启后有软件包冲突,sudo apt upgrade报冲突。无法进行。 将原来source.list重新 sudo dpkg --configure -a sudo apt install -f 这些都不管用。还是显示gno…...

(2025,DeepSeek-R1-Zero,DeepSeek-R1,两阶段强化学习,两阶段监督微调,蒸馏,冷启动数据)通过强化学习激励 LLM 的推理能力
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 目录 0. 摘要 1. 简介 1.1 贡献 1.2 评测结果总结 2. 方法 2.1 概述 2.2 DeepSeek-R1-Zero:基础模型上的强化学习 2.2.1. 强化学习算法 2.2.2. 奖励建模 2.2.3. 训练…...

k8s支持自定义field-selector spec.hostNetwork过滤
好久没写博客啦,年前写一个博客就算混过去啦😂 写一个小功能,对于 Pod,在没有 label 的情况下,支持 --field-selector spec.hostNetwork 查询 Pod 是否为 hostNetwork 类型,只为了熟悉 APIServer 是如何构…...

图漾相机搭配VisionPro使用简易教程
1.下载并安装VisionPro软件 请自行下载VisonPro软件。 VisionPro 9.0/9.5/9.6版本经测试,可正常打开图漾相机,建议使用图漾测试过的版本。 2.下载PercipioCameraForVisionPro软件包 使用浏览器下载:https://gitee.com/percipioxyz/camport3…...

【MFC】C++所有控件随窗口大小全自动等比例缩放源码(控件内字体、列宽等未调整) 20250124
MFC界面全自动等比例缩放 1.在初始化里 枚举每个控件记录所有控件rect 2.在OnSize里,根据当前窗口和之前保存的窗口的宽高求比例x、y 3.枚举每个控件,根据比例x、y调整控件上下左右,并移动到新rect struct ControlInfo {CWnd* pControl;CRect original…...