二叉树高频题目——下——不含树型dp
一,普通二叉树上寻找两个节点的最近的公共祖先
1,介绍
LCA(Lowest Common Ancestor,最近公共祖先)是二叉树中经常讨论的一个问题。给定二叉树中的两个节点,它的LCA是指这两个节点的最低(最深)的公共祖先节点。这个问题常见于计算机科学和算法设计中,具体的问题可以是:
-
二叉搜索树(BST)中的LCA问题:给定两个节点,找出它们在BST中的最近公共祖先。
-
普通二叉树中的LCA问题:在普通的二叉树中,不一定是BST,也可以找出任意两个节点的最近公共祖先。
这个问题在树的数据结构和算法中很常见,通常可以通过深度优先搜索(DFS)或者广度优先搜索(BFS)等方法来解决。
深度优先搜索(DFS)和广度优先搜索(BFS)是两种常见的图和树的遍历算法,它们在解决许多问题中都非常有用。这里分别介绍它们的特点和应用场景:
深度优先搜索(DFS)
特点:
- 深度优先搜索是一种通过从根节点开始沿着树的深度遍历的算法。
- 在实现上,通常使用递归或显式的栈来存储遍历过程中的节点。
- 深度优先搜索会一直向深度方向探索,直到达到树的底部,然后再回溯到前面的节点进行其他路径的探索。
应用场景:
- 查找路径:在图或树中查找从一个节点到另一个节点的路径。
- 拓扑排序:在有向无环图(DAG)中对节点进行排序,使得所有的有向边从排在前面的节点指向排在后面的节点。
- 连通性检测:判断两个节点之间是否有路径相连。
- 生成迷宫:利用深度优先搜索来生成迷宫的布局。
广度优先搜索(BFS)
特点:
- 广度优先搜索是一种通过逐层遍历的方式,从根节点开始向外扩展搜索的算法。
- 使用队列来存储当前层级的所有节点,以确保按层级顺序处理。
- 从根节点开始,首先遍历所有与根节点直接相连的节点,然后依次遍历与这些节点相连的节点,以此类推。
应用场景:
- 最短路径:在无权图中查找从一个节点到另一个节点的最短路径。
- 最小生成树:在加权图中找到连接所有节点的最小权重的边的集合。
- 网络广播:在社交网络或信息传播中找到最快的传播路径。
- 解决迷宫问题:利用广度优先搜索来寻找迷宫中的最短路径或所有可能的路径。
总结
深度优先搜索和广度优先搜索在解决不同类型的问题时具有不同的优势和适用性。选择哪种算法取决于具体的问题和要求,例如是否需要最短路径、是否有环等因素。这两种算法都是基础且重要的数据结构和算法设计中的核心内容。
2,分析
假设有个二叉树:
1/ \2 3/ \ / \4 5 6 7/ \8 9
共同祖先有两种情况:
1)包含关系,例如4和8,共同祖先就是4.
2)并列关系,例如8和9,共同祖先就是4.
3,代码
Node* lowestCommonAncestor(Node* root, Node* p, Node* q)
{if (root == NULL || root == p || root == q) return root;//遇到空、q、p节点时直接返回,不再额外声明变量,直接把root当作临时变量。//左树搜索p和q,同样遇到p、q、空节点时直接返回。Node* l = lowestCommonAncestor(root->left, p, q);//右树搜索p和q,同样遇到p、q、空节点时直接返回。Node* r = lowestCommonAncestor(root->right, p, q);if (l != NULL && r != NULL) return root;//左树搜索到,右树也搜索到,返回root。if (l == NULL && r == NULL) return NULL;//如果都没有搜索到的话,就返回空。//l和r中有一个为空,一个不为空,就返回不为空的那一个。return l != NULL ? l : r;
}4,分析
难以理解,当然,我第一次看的时候也是一脸懵逼。
接下来分别分析:
第一种情况,就举2和5.

进行函数递归调用时遇到2,就直接开始返回2,后面的子树部分根本不会遍历。而右边3这部分子树只会返回NULL,最后就返回2.
第二种情况,举4和5吧

二,在搜索二叉树上寻找两个节点的最近公共祖先
1,介绍——搜索二叉树
搜索二叉树(Binary Search Tree,BST)是一种二叉树的特殊形式,具有以下性质:
-
结构特点:
- 每个节点最多有两个子节点,分别称为左子节点和右子节点。
- 对于每个节点,其左子树中的所有节点的值都小于该节点的值。
- 对于每个节点,其右子树中的所有节点的值都大于该节点的值。
- 左右子树本身也是BST。
-
排序性质:
- 中序遍历BST可以按照升序输出节点的值。
- 这是因为对于任意节点,其左子树中的值都小于该节点,右子树中的值都大于该节点,因此中序遍历会按顺序访问节点。
-
操作:
- 插入:将新值插入到BST中正确的位置,保持BST的性质。
- 搜索:根据给定值搜索节点。
- 删除:删除特定节点,并保持BST的性质。
搜索二叉树在数据结构中非常常见,因为它具有高效的搜索、插入和删除操作。然而,如果插入的节点顺序不当,可能导致BST失衡,影响其性能。
2,思路
假如找节点q和p,而 p 小于q。
1)当前节点小于p的话,就往右移到右节点,因为根据搜索二叉树的性质,左子树节点一定小于p。
2)当前节点大于q的话,就往左移到左节点。
3)当前节点大于p,小于q的话,直接返回该节点,一定是第一次遇到大于p小于q的节点。因为你想,如果第一次遇到后你还继续移动,后面节点的值都要大于第一次遇到节点的值,都要大于p的。
4)如果遇到p或q,直接返回。
3,补充
函数重载

4,代码

Node* lowestCommonAncestor_BST(Node* root, Node* p, Node* q)
{int min = p->value < q->value ? p->value : q->value;int max = p->value > q->value ? p->value : q->value;//root从上到下。while (root->value != p->value && root->value != q->value){//while里的条件是没有遇到p或q就继续遍历。if (min < root->value && root->value < max) break;root = root->value < min ? root->right : root->left;}return root;
}Node* lowestCommonAncestor_BST(Node* root, int p, int q)
{int min = p < q ? p : q;int max = p > q ? p : q;//root从上到下。while (root->value != p && root->value != q){//while里的条件是没有遇到p或q就继续遍历。if (min < root->value && root->value < max) break;root = root->value < min ? root->right : root->left;}return root;
}三,收集累加和等于aim的所有路径(递归恢复现场)
只收集从根节点一直走到叶节点的路径。
1,介绍
回溯(Backtracking)
在算法中,回溯(Backtracking)是一种递归的技术,常用于解决组合优化问题和搜索问题。它通过尝试所有可能的候选解,并在搜索过程中逐步构建解决方案。如果当前尝试的部分解不符合要求,回溯算法会放弃这个部分解,并尝试下一个候选解。
具体来说,回溯算法通常适用于如下情况:
-
决策树的遍历:通过构建一个决策树,每个节点代表问题的一部分解,从根节点开始逐步扩展,直到找到满足条件的解或者无法继续为止。
-
状态空间搜索:在搜索问题中,每个状态表示问题的一个可能状态,通过深度优先搜索(DFS)遍历状态空间,寻找解决方案。
回溯算法通常包括以下步骤:
- 选择:根据当前状态选择一个候选解。
- 约束:检查候选解是否满足问题的所有约束条件。
- 递归:如果候选解满足约束条件,则递归地继续尝试下一个部分解。
- 回溯:如果当前部分解无法继续扩展或者不符合条件,则回溯到上一步,尝试其他候选解。
回溯算法的经典应用包括八皇后问题、数独、组合求和等。它的优点在于简单易懂,并且能够找到所有解或者最优解(取决于具体实现)。然而,回溯算法的缺点是在大规模问题上可能会耗费大量时间,因为它会尝试所有可能的组合。
2,思路
将aim设为全局变量,同时准备一个全局变量来记录遍历过路径节点,在到达叶节点后发现满足条件就加入到大结果中去。
因为我们使用递归,要避免上一次的结果影响,所以在函数调用结束时抹除上一次的记录。
3,代码

假设我的aim是10,就有两个路径5->4->1和5->3->2。
错误
void process(Node* cur, int aim, int sum, list<int> path, list<list<int>> ans)这样传参是错误的,因为函数要修改全局变量,这是值传递,应该改为引用传递。
正确
list<list<int>> pathSum(Node* root, int aim)
{//先准备好全局变量list<list<int>> ans;if (root != NULL){list<int> path;process(root, aim, 0, path, ans);}return ans;
}void process(Node* cur, int aim, int sum, list<int>& path, list<list<int>>& ans)
{//注意sum不包括cur的值,而是cur上方经过节点值的总和。if (cur->left == NULL && cur->right == NULL)//当我遇到叶节点的时候{if (cur->value + sum == aim){//当满足目标值后,将该节点的值加入到path里去//同时复制一份到ans里面。path.push_back(cur->value);list<int> copylist(path);ans.push_back(copylist);path.pop_back();}}else //不是叶节点的时候{path.push_back(cur->value);if (cur->left != NULL) {process(cur->left, aim, sum + cur->value, path, ans);}//去探索左边的路径有没有等于aim,如果有就会加入到ans。if (cur->right != NULL){process(cur->right, aim, sum + cur->value, path, ans);}//探索完后,弹出cur,避免影响递归调回后的遍历。在回溯时会弹出节点。path.pop_back();//取名:恢复现场}
}
四,验证平衡二叉树(树型dp沾边)
1,平衡二叉树
平衡二叉树(Balanced Binary Tree)是一种特殊的二叉树,其特点是在插入和删除节点后,树的高度能够保持在一个相对较低的水平,从而确保各种操作(如查找、插入和删除)的时间复杂度保持在对数级别。平衡二叉树在计算机科学中广泛应用于各种数据结构和算法中,如数据库索引、内存管理以及各种需要高效查找的数据结构。
平衡二叉树的定义
平衡二叉树是一种二叉搜索树(Binary Search Tree,BST),它满足以下平衡条件之一:
-
高度平衡(Height-Balanced):
每个节点的左右子树高度差不超过1。这种平衡条件常见于AVL树。 -
黑平衡(Black-Height Balanced):
对于每个节点,从该节点到所有叶子节点的路径上,黑色节点的数量相同。这是红黑树的平衡条件。 -
其他平衡条件:
不同的平衡二叉树可能采用不同的平衡条件,如Splay树通过自适应调整保持平衡。
常见的平衡二叉树类型
1. AVL树(Adelson-Velsky and Landis Tree)
AVL树是最早提出的自平衡二叉搜索树之一,由G.M. Adelson-Velsky和E.M. Landis在1962年提出。其特点是:
- 平衡因子:每个节点的左子树和右子树的高度差(平衡因子)只能是-1、0或1。
- 旋转操作:在插入或删除节点后,如果某个节点的平衡因子超出范围,需要通过单旋转或双旋转来恢复平衡。
- 优点:查找操作效率高,适合频繁查找的场景。
- 缺点:插入和删除操作可能需要频繁的旋转,导致实现较为复杂。
2. 红黑树(Red-Black Tree)
红黑树是一种近似平衡的二叉搜索树,通过在每个节点上增加颜色属性(红色或黑色)来维持平衡。其特点包括:
- 性质:
- 每个节点要么是红色,要么是黑色。
- 根节点是黑色。
- 所有叶子节点(NIL节点)都是黑色。
- 如果一个节点是红色的,则其子节点必须是黑色的(即不能有两个连续的红色节点)。
- 从任一节点到其所有后代叶子节点的简单路径上,均包含相同数目的黑色节点。
- 旋转和颜色翻转:通过旋转和颜色翻转操作来维持红黑树的性质,从而保证树的平衡。
- 优点:插入和删除操作相对简单且高效,广泛应用于各种编程语言的标准库中,如C++的
std::map和std::set。 - 缺点:查找效率略低于AVL树,但在大多数应用中差异不大。
3. Splay树(伸展树)
Splay树是一种自调整的二叉搜索树,通过将最近访问的节点“伸展”到根部来保持树的局部性。其特点包括:
- 自调整:每次访问节点后,通过一系列旋转操作将该节点移至根部。
- 摊还复杂度:尽管单次操作的时间复杂度可能较高,但经过多次操作后的平均时间复杂度为对数级别。
- 优点:对于频繁访问某些节点的场景非常高效。
- 缺点:在最坏情况下,单次操作的时间复杂度为线性级别。
平衡二叉树的应用
- 数据库索引:平衡二叉树用于实现高效的索引结构,支持快速的数据检索、插入和删除。
- 内存管理:操作系统中的内存分配器使用平衡树来管理空闲内存块,确保快速分配和回收内存。
- 编程语言的标准库:许多编程语言的标准库使用平衡二叉树来实现关联容器,如C++的
std::map、Java的TreeMap等。 - 文件系统:一些文件系统使用平衡树来管理文件目录结构,确保快速的文件查找和操作。
总结
平衡二叉树通过保持树的高度在对数级别,从而确保各种操作的高效性。在实际应用中,根据具体需求和场景,可以选择不同类型的平衡二叉树,如AVL树适合查找频繁的场景,红黑树则在插入和删除操作频繁且对实现复杂度有要求的情况下表现更佳。理解平衡二叉树的原理和特点,有助于在设计高效数据结构和算法时做出更合适的选择。
我找的定义:左右子树高度相差不超过1,对于每一个节点。
代码
太蠢了,连抄代码都能抄错,问AI也打不出个所以然,下次在问AI前试着自己找出错误,最难就是逻辑上的。
class IsBalance
{
private:bool balance;public:bool isBalanced(Node* root){balance = true;//balance是全局变量,所有调用过程共享//每次开始设置为trueheight(root);return balance;}//对于判断平衡二叉树,一旦发现不平衡的节点,balance改为false并返回。//height函数的作用:求当前以cur为根节点的子树的高度;判断是否平衡。//一旦发现不平衡,返回什么高度就不重要了。int height(Node* cur){if (!balance || cur == NULL) return 0;int left_height = height(cur->left);int right_height = height(cur->right);if (abs(left_height - right_height) > 1){balance = false;}//发现不平衡后依旧正常返回return left_height > right_height ? left_height + 1 : right_height + 1;}
};
最sb的是我||写成&&。
五,验证搜索二叉树(树型dp沾边)
首先想到的就是中序遍历,看遍历结果是不是一直升序。
1,递归方式实现中序遍历,顺便验证是否是搜索二叉树
bool Is_BST(Node* root)
{stack<int> stack;midOrderTraverse(root, stack);int pre = stack.top(), cur;stack.pop();while (!stack.empty()){cur = stack.top();stack.pop();if (cur > pre) return false;pre = cur;}return true;
}void midOrderTraverse(Node* root, stack<int>& stack)
{if (!root) return;midOrderTraverse(root->left, stack);stack.push(root->value);midOrderTraverse(root->right, stack);
}2,搜索二叉树构建(递归方法)
// 插入节点的辅助函数TreeNode* insert(TreeNode* node, int val) {if (node == nullptr) {return new TreeNode(val);}if (val < node->val) {node->left = insert(node->left, val);} else if (val > node->val) {node->right = insert(node->right, val);}return node;}确实AI写得好一些,
#include<iostream>
#include<vector>struct Node
{int value;Node* left;Node* right;Node(int x) : value(x), left(NULL), right(NULL) {};
};class SearchBinaryTree
{
private:Node* root;// 插入节点的辅助函数,将值插入到以 node 为根的子树中Node* insert(Node* node, int value){if (node == NULL) return new Node(value);if (value < node->value){node->left = insert(node->left, value);}else if (value > node->value){node->right = insert(node->right, value);}return node;}// 中序遍历辅助函数,用于输出树的节点值void midOrderTraverse(Node* root){if (root == NULL) return;midOrderTraverse(root->left);std::cout << root->value << " ";midOrderTraverse(root->right);}
public:SearchBinaryTree() :root(NULL) {};// 插入元素到二叉搜索树中void insert(int value){root = insert(root, value);}// 对二叉搜索树进行中序遍历void midOrderTraverse(){midOrderTraverse(root);std::cout << std::endl;}
};int main()
{std::vector<int> nums = { 1,3,5,7,9,2,4,6,8 };SearchBinaryTree bst;for (int num : nums){bst.insert(num);}bst.midOrderTraverse();return 0;
}3,递归版判断(使用全局变量)
static int max;
static int min;
//这两个全局变量是用来表示子树所有节点中的最大/小值
//是在递归函数结束时,给父节点返回。让父节点知道左/右子树的最大/小值
//在判断完该节点后,重置这两个全局变量。bool Is_SBT1(Node* node)
{if (node == NULL){min = std::numeric_limits<int>::max();max = std::numeric_limits<int>::min();//确保比较有效return true;}bool lok = Is_SBT1(node->left);//左边是不是满足条件int lmin = min;int lmax = max;bool rok = Is_SBT1(node->right);//右边是不是。int rmin = min;int rmax = max;//更新此时的max和minmin = std::min(std::min(lmin, rmin), node->value);max = std::max(std::max(lmax, rmax), node->value);return lok && rok && lmax < node->value && node->value < rmin;
}
我觉得最神奇的是全局变量的使用。它们时刻都在被改变,只记录当时的最值。
六,修剪二叉树
修剪二叉树(Trim Binary Tree)是一种对二叉树进行操作的算法,通常应用于二叉搜索树(Binary Search Tree,BST),其目的是移除树中不符合特定范围条件的节点,使得最终得到的二叉树仅包含节点值在指定范围 [low, high] 内的节点。
修剪二叉树的基本原理
- 对于二叉搜索树,其性质是左子节点的值小于父节点的值,右子节点的值大于父节点的值。利用这个性质可以有效地修剪二叉搜索树。
修剪步骤
- 递归遍历:
- 通常使用递归的方式遍历二叉树,因为二叉树的结构非常适合递归操作。
- 从根节点开始,对于每个节点进行以下操作:
- 若节点的值小于范围的下限
low,那么该节点及其左子树都将被排除,所以修剪后的结果是对其右子树进行修剪的结果。 - 若节点的值大于范围的上限
high,那么该节点及其右子树都将被排除,所以修剪后的结果是对其左子树进行修剪的结果。 - 若节点的值在范围
[low, high]内,则该节点保留,并且对其左右子树分别进行修剪。
- 若节点的值小于范围的下限
1,看完视频第一次尝试
Node* trimBST(Node* root, int low, int high)
{if (root == NULL) return NULL;if (root->value >= low && root->value <= high){root->left = trimBST(root->left, low, high);root->right = trimBST(root->right, low, high);return root;}return NULL;
}没有正确处理当节点值不在范围之内时的情况,我是直接舍弃。这样会导致二叉树不完整。
2,第二次尝试
Node* trimBST(Node* root, int low, int high)
{if (root == NULL) return NULL;if (root->value < low){return trimBST(root->right, low, high);}else if (root->value > high){return trimBST(root->left, low, high);}else{root->left = trimBST(root->left, low, high);root->right = trimBST(root->right, low, high);return root;}}七,二叉树打家劫舍问题(树型dp沾边)
题目要求
题目描述:
有一个二叉树,每个节点代表一个房屋,节点的值表示房屋中的财富。你可以选择偷窃某个房屋,但你不能同时偷窃相邻的两个房屋(即不能偷窃父子节点)。现在,你要计算能偷窃的最大财富。你需要设计一个算法来找出最大的偷盗金额。
具体规则:
- 你不能偷窃父节点和子节点。
- 每个节点的值表示该节点所代表的房屋的财富。
- 你可以选择偷窃或不偷窃每个房屋,但相邻的两个房屋不能同时被偷窃。
任务:
给定一个二叉树,计算在遵守上述规则的情况下,你能偷窃的最大财富。
示例 1:
输入:
3/ \2 3\ \3 1
输出:
7
解释:
- 选择节点 3(根节点),然后选择节点 3(右子节点)。你不能选择节点 2 和节点 1,因为它们是相邻的。
- 偷窃的财富为 3 + 3 + 1 = 7。
示例 2:
输入:
3/ \4 5/ \ \1 3 1
输出:
9
解释:
- 选择节点 4 和节点 5,但不选择其子节点(1 和 3)。最终偷窃的财富为 4 + 5 = 9。
思路:
此题类似于动态规划或树的递归问题,我们可以通过递归来计算每个节点的最大偷窃金额。递归的核心思想是:
- 对于每个节点,我们有两种选择:
- 偷窃当前节点:那么它的子节点就不能被偷窃了,偷窃当前节点的最大值为
当前节点的值 + 左子树和右子树不偷窃时的最大值。 - 不偷窃当前节点:那么可以偷窃左右子树的最大值。
- 偷窃当前节点:那么它的子节点就不能被偷窃了,偷窃当前节点的最大值为
- 最终结果是,对于每个节点,返回偷窃和不偷窃两种选择的最大值。
递归实现:
在递归函数中,每个节点返回两种情况:
- 偷窃该节点的最大值。
- 不偷窃该节点的最大值。
通过递归得到每个节点的最大偷窃值,最终返回树的根节点的偷窃结果。
代码实现:
#include <iostream>
#include <algorithm>
using namespace std;// 树节点结构
struct Node {int value;Node* left;Node* right;Node(int val) : value(val), left(nullptr), right(nullptr) {}
};class BSTMaxTheft {
public:int maxStealedValue(Node* root);private:pair<int, int> recursion(Node* root); // 返回值为 pair,第一个是偷当前节点的最大值,第二个是不偷当前节点的最大值
};// 计算最大偷盗值
int BSTMaxTheft::maxStealedValue(Node* root)
{pair<int, int> result = recursion(root);return std::max(result.first, result.second);
}// 递归计算每个节点的最大偷盗值
pair<int, int> BSTMaxTheft::recursion(Node* root)
{if (root == nullptr) {return {0, 0}; // 当前节点为空,返回偷和不偷的最大值都是 0}// 递归计算左子树和右子树的最大偷盗值pair<int, int> left = recursion(root->left);pair<int, int> right = recursion(root->right);// 当前节点被偷时:当前节点的值 + 左子树和右子树不能偷的最大值int steal = root->value + left.second + right.second;// 当前节点不被偷时:选择左子树和右子树的最大值int notSteal = max(left.first, left.second) + max(right.first, right.second);return {steal, notSteal};
}// 主函数
int main()
{// 创建一个二叉树Node* root = new Node(3);root->left = new Node(2);root->right = new Node(3);root->left->right = new Node(3);root->right->right = new Node(1);BSTMaxTheft bst;int maxValue = bst.maxStealedValue(root);cout << "Max stolen value: " << maxValue << endl; // 输出 7return 0;
}
展开
解释:
-
recursion函数:- 该函数接收一个节点作为参数,返回一个
pair<int, int>,其中:first是偷窃当前节点的最大值。second是不偷窃当前节点的最大值。
- 递归的终止条件是遇到空节点,返回
(0, 0)。
- 该函数接收一个节点作为参数,返回一个
-
maxStealedValue函数:- 该函数调用
recursion获取根节点的最大偷盗值,并返回偷和不偷的最大值。
- 该函数调用
测试结果:
对于输入:
3/ \2 3\ \3 1
输出:
Max stolen value: 7
对于输入:
3/ \4 5/ \ \1 3 1
输出:
Max stolen value: 9利用全局变量和递归,在每一个节点讨论偷该节点和不偷该节点的情况。
原理
两种方法:
利用类成员变量起着全局变量的作用,实现更新。将 yes 和 no 的计算保留为成员变量,但在每个节点递归时,将递归结果传递给相应的成员变量。在这种实现方式中,我们将使用成员变量来存储“是否偷盗”以及“不偷盗”的最大价值。
直接返回结果,将递归函数的返回类型更改为 pair<int, int>,其中 first 表示当前节点被偷时的最大价值,second 表示当前节点不被偷时的最大价值。
法一(自己写的)
代码
int BSTMaxTheft::maxStealedValue(Node* root)
{recursion1(root);return std::max(yes, no);
}void BSTMaxTheft::recursion1(Node* root)
{int leftYes, rightYes;int leftNo, rightNo;if (root == NULL){yes = no = 0;return;}recursion1(root->left);//此时更新了成员变量yes和noleftYes = yes;leftNo = no;recursion1(root->right);rightYes = yes;rightNo = no;yes = root->value + leftNo + rightNo;no = std::max(leftYes, leftNo) + std::max(rightYes, rightNo);
}法二(自己写的)
int BSTMaxTheft::maxStealedValue2(Node* root)
{std::pair<int, int> ans = recursion2(root);return std::max(ans.first, ans.second);
}std::pair<int, int> BSTMaxTheft::recursion2(Node* root)
{if (root == NULL){return { 0,0 };}std::pair<int, int> left = recursion2(root->left);std::pair<int, int> right = recursion2(root->right);int yes = root->value + left.second + right.second;int no = std::max(left.first, left.second) + std::max(right.first, right.second);return { yes,no };
}相关文章:
二叉树高频题目——下——不含树型dp
一,普通二叉树上寻找两个节点的最近的公共祖先 1,介绍 LCA(Lowest Common Ancestor,最近公共祖先)是二叉树中经常讨论的一个问题。给定二叉树中的两个节点,它的LCA是指这两个节点的最低(最深&…...

vue事件总线(原理、优缺点)
目录 一、原理二、使用方法三、优缺点优点缺点 四、使用注意事项具体代码参考: 一、原理 在Vue中,事件总线(Event Bus)是一种可实现任意组件间通信的通信方式。 要实现这个功能必须满足两点要求: (1&#…...

PyCharm介绍
PyCharm的官网是https://www.jetbrains.com/pycharm/。 以下是在PyCharm官网下载和安装软件的步骤: 下载步骤 打开浏览器,访问PyCharm的官网https://www.jetbrains.com/pycharm/。在官网首页,点击“Download”按钮进入下载页面。选择适合自…...

《CPython Internals》读后感
一、 为什么选择这本书? Python 是本人工作中最常用的开发语言,为了加深对 Python 的理解,更好的掌握 Python 这门语言,所以想对 Python 解释器有所了解,看看是怎么使用C语言来实现Python的,以期达到对 Py…...

音频入门(一):音频基础知识与分类的基本流程
音频信号和图像信号在做分类时的基本流程类似,区别就在于预处理部分存在不同;本文简单介绍了下音频处理的方法,以及利用深度学习模型分类的基本流程。 目录 一、音频信号简介 1. 什么是音频信号 2. 音频信号长什么样 二、音频的深度学习分…...
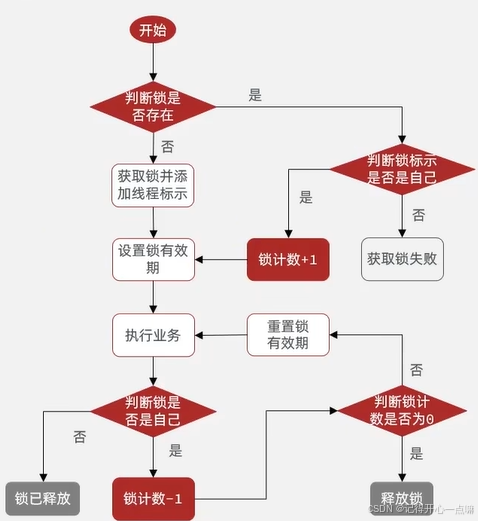
Redis --- 分布式锁的使用
我们在上篇博客高并发处理 --- 超卖问题一人一单解决方案讲述了两种锁解决业务的使用方法,但是这样不能让锁跨JVM也就是跨进程去使用,只能适用在单体项目中如下图: 为了解决这种场景,我们就需要用一个锁监视器对全部集群进行监视…...

用C++编写一个2048的小游戏
以下是一个简单的2048游戏的实现。这个实现使用了控制台输入和输出,适合在终端或命令行环境中运行。 2048游戏的实现 1.游戏逻辑 2048游戏的核心逻辑包括: • 初始化一个4x4的网格。 • 随机生成2或4。 • 处理玩家的移动操作(上、下、左、…...

【设计模式-行为型】状态模式
一、什么是状态模式 什么是状态模式呢,这里我举一个例子来说明,在自动挡汽车中,挡位的切换是根据驾驶条件(如车速、油门踏板位置、刹车状态等)自动完成的。这种自动切换挡位的过程可以很好地用状态模式来描述。状态模式…...

CentOS/Linux Python 2.7 离线安装 Requests 库解决离线安装问题。
root@mwcollector1 externalscripts]# cat /etc/os-release NAME=“Kylin Linux Advanced Server” VERSION=“V10 (Sword)” ID=“kylin” VERSION_ID=“V10” PRETTY_NAME=“Kylin Linux Advanced Server V10 (Sword)” ANSI_COLOR=“0;31” 这是我系统的版本,由于是公司内网…...

【flutter版本升级】【Nativeshell适配】nativeshell需要做哪些更改
flutter 从3.13.9 升级:3.27.2 nativeshell组合库中的 1、nativeshell_build库替换为github上的最新代码 可以解决两个问题: 一个是arg("--ExtraFrontEndOptions--no-sound-null-safety") 在新版flutter中这个构建参数不支持了导致的build错误…...

使用 Vue 3 的 watchEffect 和 watch 进行响应式监视
Vue 3 的 Composition API 引入了 <script setup> 语法,这是一种更简洁、更直观的方式来编写组件逻辑。结合 watchEffect 和 watch,我们可以轻松地监视响应式数据的变化。本文将介绍如何使用 <script setup> 语法结合 watchEffect 和 watch&…...

使用shell命令安装virtualbox的虚拟机并导出到vagrant的Box
0. 安装virtualbox and vagrant [rootolx79vagrant ~]# cat /etc/resolv.conf #search 114.114.114.114 nameserver 180.76.76.76-- install VirtualBox yum install oraclelinux-developer-release-* wget https://yum.oracle.com/RPM-GPG-KEY-oracle-ol7 -O /etc/pki/rpm-g…...
:排序查询和条件查询)
MySQL 基础学习(3):排序查询和条件查询
MySQL 查询与条件操作:详解与技巧 在本文中,我们将探讨 MySQL 中的查询操作及其相关功能,包括别名、去重、排序查询和条件查询等,并总结一些最佳实践和注意事项。 一、使用别名(AS) 在查询中,…...

2025数学建模美赛|赛题翻译|E题
2025数学建模美赛,E题赛题翻译 更多美赛内容持续更新中......

solidity高阶 -- 继承
Solidity是一种面向区块链的智能合约编程语言,广泛应用于以太坊等区块链平台。继承是Solidity中一个非常重要的特性,它允许开发者通过创建子合约来扩展父合约的功能,从而实现代码的复用和层次化设计。本文将通过具体实例详细介绍Solidity语言…...

SpringBoot统一数据返回格式 统一异常处理
统一数据返回格式 & 统一异常处理 1. 统一数据返回格式1.1 快速入门1.2 存在问题1.3 案列代码修改1.4 优点 2. 统一异常处理 1. 统一数据返回格式 强制登录案例中,我们共做了两部分⼯作 通过Session来判断⽤⼾是否登录对后端返回数据进⾏封装,告知前端处理的结果 回顾 后…...

C语言学习强化
前言 数据的逻辑结构包括: 常见数据结构: 线性结构:数组、链表、队列、栈 树形结构:树、堆 图形结构:图 一、链表 链表是物理位置不连续,逻辑位置连续 链表的特点: 1.链表没有固定的长度…...

反馈驱动、上下文学习、多语言检索增强等 | Big Model Weekly 第55期
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! 01 A Bayesian Approach to Harnessing the Power of LLMs in Authorship Attribution 传统方法严重依赖手动特征,无法捕捉长距离相关性,限制了其有效性。最近的研究利用预训练语言模型的…...

Redis 详解
简介 Redis 的全称是 Remote Dictionary Server,它是一个基于内存的 NoSQL(非关系型)数据库,数据以 键值对 存储,支持各种复杂的数据结构 为什么会出现 Redis? Redis 的出现是为了弥补传统数据库在高性能…...

git reset (取消暂存,保留工作区修改)
出现这种情况的背景:我不小心把node_modules文件添加到暂存区了,由于文件过大,导致不能提交,所以我想恢复之前的状态,但又不想把修改的代码恢复为之前的状态,所以使用这个命令可以只恢复暂存区的状态&#…...

C++ 自定义字面量
在C11中,用户自定义字面量(User-Defined Literals)为程序员提供了前所未有的灵活性和便利性,它允许我们根据自己的需求定义字面量,从而使代码更加直观、易读且富有表现力。 什么是用户定义字面量? 在C中&…...

2024年面对不确定性
24年处在了十字路口,面对工作、家庭、生活的责任,一切变得不确定了,量子力学给了我们新的认识世界的角度,不确定性才是这个世界的底色,我们怎么选择? 不停的思考 霍金在大设计书中给出了深刻的哲学思想&a…...

Coze插件开发之基于已有服务创建并上架到扣子商店
Coze插件开发之基于已有服务创建并上架到扣子商店 在应用开发中,需要调用各种插件,以快速进行开发。但有时需要调用的插件在扣子商店里没有,那怎么办呢? 今天就来带大家快速基于已有服务创建一个新的插件 简单来讲,就是…...

Oracle 创建用户和表空间
Oracle 创建用户和表空间 使用sys 账户登录 建立临时表空间 --建立临时表空间 CREATE TEMPORARY TABLESPACE TEMP_POS --创建名为TEMP_POS的临时表空间 TEMPFILE /oracle/oradata/POS/TEMP_POS.DBF -- 临时文件 SIZE 50M -- 其初始大小为50M AUTOEXTEND ON -- 支持…...

企业微信开发009_使用WxJava企业微信开发框架_封装第三方应用企业微信开发002_并且实现多企业授权访问---企业微信开发011
继续接上一节来贴代码: 接下来看 config部分的代码,这部分代码,系统启动的时候,就会执行,从而把配置的一些,配置读取出来,创建,针对每个企业微信的,操作service. 首先看yml配置文件中配置部分: 可以先看一下demo中: 提供了一个配置的示例,当然这个是针对 企业内部自建应用 …...

机器学习 - 初学者需要弄懂的一些线性代数的概念
一、单位矩阵 在数学中,单位矩阵是一个方阵,其主对角线上的元素全为1,其余元素全为0。单位矩阵在矩阵乘法中起到类似于数字1在数值乘法中的作用,即任何矩阵与单位矩阵相乘,结果仍为原矩阵本身。 单位矩阵的定义&…...

【学术会议-第五届机械设计与仿真国际学术会议(MDS 2025) 】前端开发:技术与艺术的完美融合
重要信息 大会官网:www.icmds.net 大会时间:2025年02月28日-03月02日 大会地点:中国-大连 会议简介 2025年第五届机械设计与仿真国际学术会议(MDS 2025) 将于2025年02月28-3月02日在中国大连召开。MDS 2025将围绕“机械设计”…...

RabbitMQ 分布式高可用
文章目录 前言一、持久化与内存管理1、持久化机制2、内存控制1、命令行2、配置文件 3、内存换页4、磁盘控制 二、集群1、Erlang的分布式特性2、RabbitMQ的节点类型2.1、磁盘节点 (Disk Node)2.2、内存节点 (RAM Node) 3、构建集群3.1 普通集群3.2 镜像队列3.3、高可用实现方案3…...

海康工业相机 SDK对接 Hikvision
有C#基础的,可以参考下,直接上代码 BaseResult 来自于Nuget包,搜Rotion可以搜出来 LS.Standard.Data 海康的接口操作,要先引用相应的dll using MvCamCtrl.NET; using PCZD.Commons.Data.CameraModel; using PCZD.Data; using Sys…...

开发技巧,vue 中的动态组件的引用 component + is
在项目中很多时候有切换 tab 的场景,一般来说都是用 v-if 或者 v-show 然后根据各种条件来控制显示隐藏。 其实我们可以使用 vue 中的动态组件,也能实现这个效果 <!-- currentTab 改变时组件也改变 --> <component :is"currentTab"…...