Edge-TTS在广电系统中的语音合成技术的创新应用
Edge-TTS在广电系统中的语音合成技术的创新应用
作者:本人是一名县级融媒体中心的工程师,多年来一直坚持学习、提升自己。喜欢Python编程、人工智能、网络安全等多领域的技术。
摘要
随着人工智能技术的快速发展,文字转语音(Text-to-Speech, TTS)系统已成为多种应用的重要组成部分,尤其在广播电视领域。本文介绍了一种基于Edge-TTS大模型的文字转语音工具,该工具结合了现代文本处理和语音合成技术,为用户提供了高效的音频生成解决方案。通过对该工具的设计与实现进行分析,本文探讨了其在广播电视行业中的潜在应用场景及未来发展方向。
引言
文字转语音技术使得计算机能够将书面文字转换为自然的人声,这对于广播电视行业至关重要。它可以用于生成新闻播报、广告配音、教育培训等多种场景,以提高信息传达的效率和生动性。随着神经网络技术的发展,现代TTS模型已经能够生成接近人类自然声音质量的语音。
Edge-TTS 模型介绍
Edge-TTS是一个基于微软 Azure Cognitive Services 的开源文本转语音(Text-to-Speech,TTS)工具,它利用微软的语音合成技术,将文本转换为自然流畅的语音输出。以下是关于 Edge-TTS 的详细介绍:
1.功能特点
• 高质量语音合成:
• Edge-TTS 能够生成非常自然和清晰的语音,通过对语音的韵律、语调、重音等方面进行精细模拟,使得合成的语音接近人类自然发音。
• 支持多种语言和方言,能够根据语言特点调整发音规则。
• 丰富的语言和语音风格支持:
• 支持超过40种语言和300多种声音选项。
• 提供多种语音风格,包括男性、女性、年轻、成熟等,用户可以根据场景选择合适的语音。
• 易于使用:
• 提供简单易用的接口,支持命令行和编程接口。
• 开发者可以通过 Python 等编程语言调用 Edge-TTS,实现个性化的文本转语音应用。
• 开源免费:
• Edge-TTS 是开源项目,用户可以免费使用。
• 源代码在 GitHub 上公开,社区成员可以贡献代码和进行功能扩展。
2.技术原理
• 文本到语音转换:
• 将文本信息转换为语音输出,包括文本分析、分词、音素转换等步骤。
• 语音合成引擎:
• 利用微软 Azure Cognitive Services 的语音合成 API,生成高质量的语音。
• 自然语音流:
• 通过先进的语音合成技术,生成流畅自然的语音流,包括适当的语调、节奏和强度变化。
• 参数调整:
• 用户可以调整语音的参数,如语速、音量、语调等,以获得最佳的语音输出效果。
3.应用场景
• 语音助手:为用户提供自然便捷的语音交互方式。
• 电子书阅读器:将电子书内容转换为语音,方便用户听书。
• 视频制作:为视频添加语音旁白,提高视频质量。
• 教育领域:帮助教师制作教学课件,为视力障碍学生提供学习支持。
• 智能客服:将客服回复的文本转换为语音,提高服务效率。
4.使用方法
• 命令行使用:
• 安装 Edge-TTS:
pip install edge-tts
• 将文本转换为语音文件:
edge-tts --text "Hello, world!" --voice en-US-JennyNeural --write-media output.wav
• 编程接口:
• 使用 Python 调用 Edge-TTS:
import asyncioimport edge_ttsasync def generate_audio(text, voice, output_file):tts = edge_tts.Communicate(text, voice)await tts.save(output_file)asyncio.run(generate_audio("Hello, world!", "en-US-JennyNeural", "output.wav"))
5.优势
• 自然流畅的语音输出:通过精细的语音合成技术,生成自然流畅的语音。
• 多样化的语音选择:支持多种语言和语音风格,满足不同用户的需求。
• 易于集成和使用:提供简单易用的接口,方便开发者在应用程序中集成语音功能。
• 开源免费:开源项目,用户可以免费使用并进行定制。
文本转语音工具概述
本文中所展示的代码实现了一个简单而有效的文字转语音工具,其主要功能包括:
-
文本输入:用户可以在界面上输入或粘贴需要转换为语音的文本。文本框支持多行输入,适用于长篇文章或复杂内容。
-
语音选择:用户可以从多种可用的语音角色中选择合适的声音,以满足不同的内容需求。该工具集成了多种音色,包括男性和女性的不同口音,使得用户可以根据目标受众选择最合适的语音风格。
-
语速调整:用户可以根据需要调整语音的播放速度,从而增强节目的灵活性和可读性。通过下拉菜单,用户可选择从-100%到+100%的各个速度级别,使得生成的音频更符合特定场合的需求。
-
输出目录选择:用户可以自定义输出目录以便于管理生成的音频文件。通过文件选择对话框,用户可以轻松选择个人设备上的任意文件夹,提升了使用便利性。
-
右键菜单操作:在文本输入框中,用户可以使用右键菜单进行文本复制、剪切和粘贴等常用操作。这一功能不仅简化了文本输入过程,也提升了用户体验,尤其对于长文本的编辑。
-
异步任务处理:为了提高程序的响应速度,工具采用了异步编程模式。在合成音频的过程中,主线程不会被阻塞,这意味着用户仍然可以进行其他操作,而不会感到延迟。此设计显著提高了用户体验。
-
文件管理:工具自动管理文件输出,包括创建必要的目录结构和命名规则。用户可以方便地选择输出目录,并自定义文件名称,使得生成的音频文件易于查找和管理。同时,系统会确保生成的文件不与已有文件冲突。
运行环境
操作系统: Windows系统、Mac系统、Linux系统(本事例是Mac系统)
IDE:Pycharm 2024.1
开发语言:Python 3.12
代码实现分析
源代码如下:
import os
import tempfile
import asyncio
import pygame.mixer
import customtkinter as ctk
from tkinter import filedialog
from tkinter import messagebox
from edge_tts import Communicate
from tkinter import Menu
import tkinter as tkpygame.mixer.init()# 用于异步执行 my_function 函数,以提高响应速度
async def my_function(text, output, voice, rate):volume = '+0%'tts = Communicate(text=text, voice=voice, rate=rate, volume=volume)await tts.save(output)# 将训练好的语言模型以字典的形式存储,字典的键为神经网络的汉字名,字典的值为神经网络的训练模型名
# 这样做是为了给使用者更直观、更容易理解的界面菜单
voice_dict = {'(女)小小神经网络': 'zh-CN-XiaoxiaoNeural', '(女)小一神经网络': 'zh-CN-XiaoyiNeural','(男)云健神经网络': 'zh-CN-YunjianNeural', '(男)云熙神经网络': 'zh-CN-YunxiNeural','(女)云霞神经网络': 'zh-CN-YunxiaNeural', '(男标准话)云阳神经网络': 'zh-CN-YunyangNeural','(女)辽宁-小贝神经网络': 'zh-CN-liaoning-XiaobeiNeural','(女)陕西-小妮神经网络': 'zh-CN-shaanxi-XiaoniNeural', '(女)香港-HiuGa神经网络': 'zh-HK-HiuGaaiNeural','(女)香港-HiuMa神经网络': 'zh-HK-HiuMaanNeural', '(男)香港-万隆神经网络': 'zh-HK-WanLungNeural','(女)台湾-Hsiao陈神经网络': 'zh-TW-HsiaoChenNeural', '(女)台湾-Hsiao于神经网络': 'zh-TW-HsiaoYuNeural','(男普通话)台湾-云J何神经网络': 'zh-TW-YunJheNeural'}def show_context_menu(event):context_menu.post(event.x_root, event.y_root)# 定义 synthesize_text 函数:这个函数是主要的功能实现部分。
# 首先从文本输入框中获取要转换的文本。
def synthesize_text():text = text_entry.get("1.0", ctk.END).strip()voice = voice_dict[voice_var.get()]rate = rate_var.get()# 生成输出的文件目录out_dir = output_dir_entry.get()output_dir = os.path.join(out_dir, "mp3")if not os.path.exists(output_dir):os.makedirs(output_dir)# 选择的语音模式作为文件名filename_save = text_entry_filename.get("1.0", ctk.END).strip() + '-' + voice_var.get()filename = os.path.join(output_dir, filename_save + ".mp3")with tempfile.NamedTemporaryFile(delete=False, suffix=".mp3", dir=output_dir) as temp_file:temp_filename = temp_file.nameloop = asyncio.get_event_loop()loop.run_until_complete(my_function(text, temp_filename, voice, rate))os.rename(temp_filename, filename)messagebox.showinfo("成功", "音频文件生成成功!")# 定义 select_output_directory 函数, 这个函数用于打开文件选择对话框,让用户选择输出目录。
def select_output_directory():output_dir = filedialog.askdirectory()if output_dir:output_dir_entry.delete(0, ctk.END)output_dir_entry.insert(ctk.END, output_dir)# 设置 CustomTkinter 主题
ctk.set_appearance_mode("System")
ctk.set_default_color_theme("blue")# 创建主窗口
root = tk.Tk()
# root = ctk.CTk()
root.title("文字转语音工具--微信公众号:强壮Python")
root.geometry("730x700")
root.resizable(False, False)# 创建标题
title_label = ctk.CTkLabel(root, text="文字转语音工具", font=("Arial", 24, "bold"), pady=20)
title_label.pack()# 创建文本输入框
text_label = ctk.CTkLabel(root, text="请输入要转换为语音的文本:", font=("Arial", 14))
text_label.pack()text_entry = tk.Text(root, height=15, width=100, font=("Arial", 12))
text_entry.pack()# 创建右键菜单
context_menu = Menu(root, tearoff=0)
context_menu.add_command(label="复制", command=lambda: text_entry.event_generate("<<Copy>>"))
context_menu.add_command(label="剪切", command=lambda: text_entry.event_generate("<<Cut>>"))
context_menu.add_command(label="粘贴", command=lambda: text_entry.event_generate("<<Paste>>"))# 绑定右键菜单到文本输入框# # 自添代码,保存文件的名称
text_label_filename = ctk.CTkLabel(root, text="请输入保存的文件名称:", font=("Arial", 14))
text_label_filename.pack()# text_entry_filename = ctk.CTkTextbox(root, height=20, width=210, font=("Arial", 12))
text_entry_filename = tk.Text(root, height=3, width=30, font=("Arial", 12))
text_entry_filename.pack()# 绑定右键菜单到文本输入框
text_entry.bind("<Button-2>", show_context_menu)
# 创建输出目录选择框
output_dir_label = ctk.CTkLabel(root, text="选择输出目录:", font=("Arial", 14))
output_dir_label.pack()output_dir_frame = ctk.CTkFrame(root)
output_dir_frame.pack()output_dir_entry = ctk.CTkEntry(output_dir_frame, font=("Arial", 12), width=50)
output_dir_entry.pack(side=ctk.LEFT)output_dir_button = ctk.CTkButton(output_dir_frame, text="选择目录", font=("Arial", 12),command=select_output_directory)
output_dir_button.pack(side=ctk.LEFT)# 创建语音选择下拉框
voice_label = ctk.CTkLabel(root, text="请选择要使用的语音角色:", font=("Arial", 14))
voice_label.pack()voice_var = ctk.StringVar()
# voice_var.set(voice_dict["(女)小小神经网络"])
if not voice_var:print('请选择语音模式')
voice_select = ctk.CTkOptionMenu(root, variable=voice_var, values=list(voice_dict.keys()),font=("Arial", 12), width=20)
voice_select.pack()# 创建语速选择下拉框
rate_label = ctk.CTkLabel(root, text="调整语速:", font=("Arial", 14))
rate_label.pack()rate_var = ctk.StringVar()
rate_var.set("+0%")rate_select = ctk.CTkOptionMenu(root, variable=rate_var,values=["-100%", "-90%", "-80%", "-70%", "-60%", "-50%", "-40%", "-30%","-20%", "-10%", "+0%", "+10%", "+20%", "+30%", "+40%", "+50%", "+60%", "+70%","+80%", "+90%", "+100%"], font=("Arial", 12), width=20)
rate_select.pack()# 创建合成按钮
synthesize_button = ctk.CTkButton(root, text="合成音频", font=("Arial", 16, "bold"), command=synthesize_text, width=150,height=50)
synthesize_button.pack(pady=20)root.mainloop()界面设计
工具的用户界面采用customtkinter框架构建,支持多种操作,包括文本输入、文件选择以及右键菜单操作。用户友好的界面设计能够有效降低使用门槛,使得即使是非技术人员也能轻松操作。整体布局简洁明了,每一项功能模块都进行了合理的分组与标注,确保了良好的用户交互体验。
运行界面如下图所示:
运行程序,文本框的文字可以通过点击鼠标右键(粘贴、复制、剪切),如下图所示:
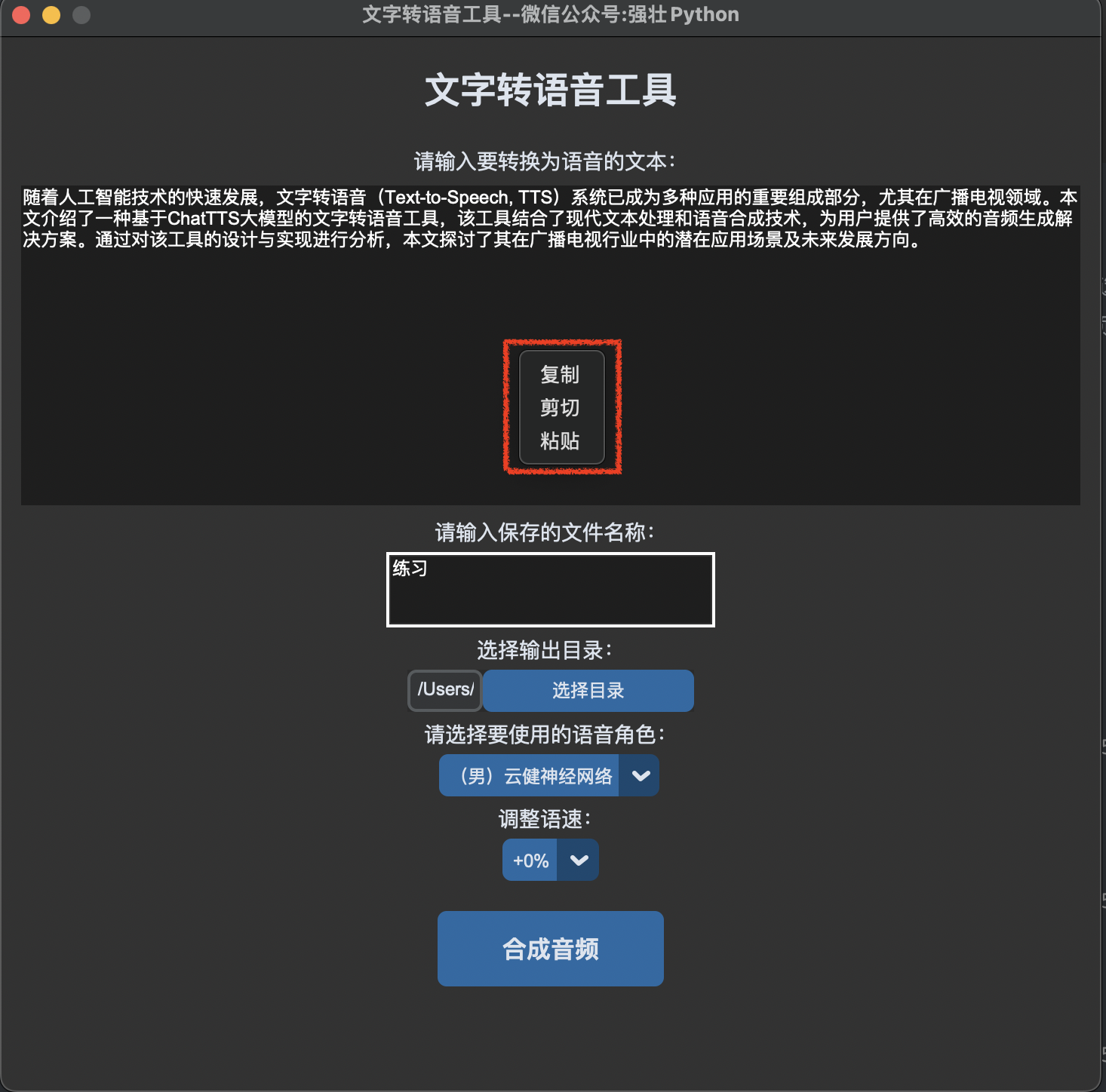
将文本内容粘贴或者直接输入到上图中的文本框,选择输出目录,如下图所示:
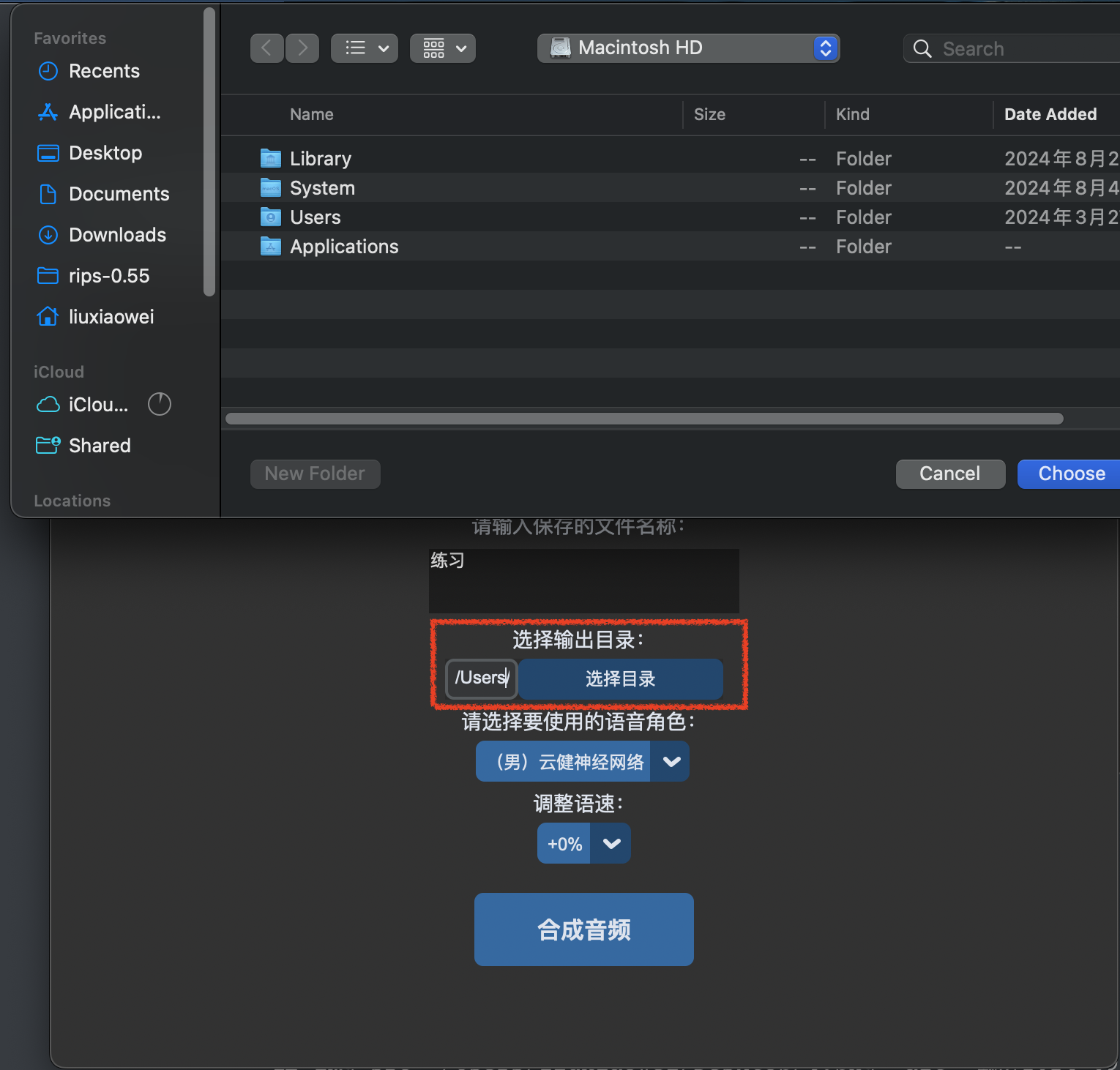
选择语音角色,如下图所示:
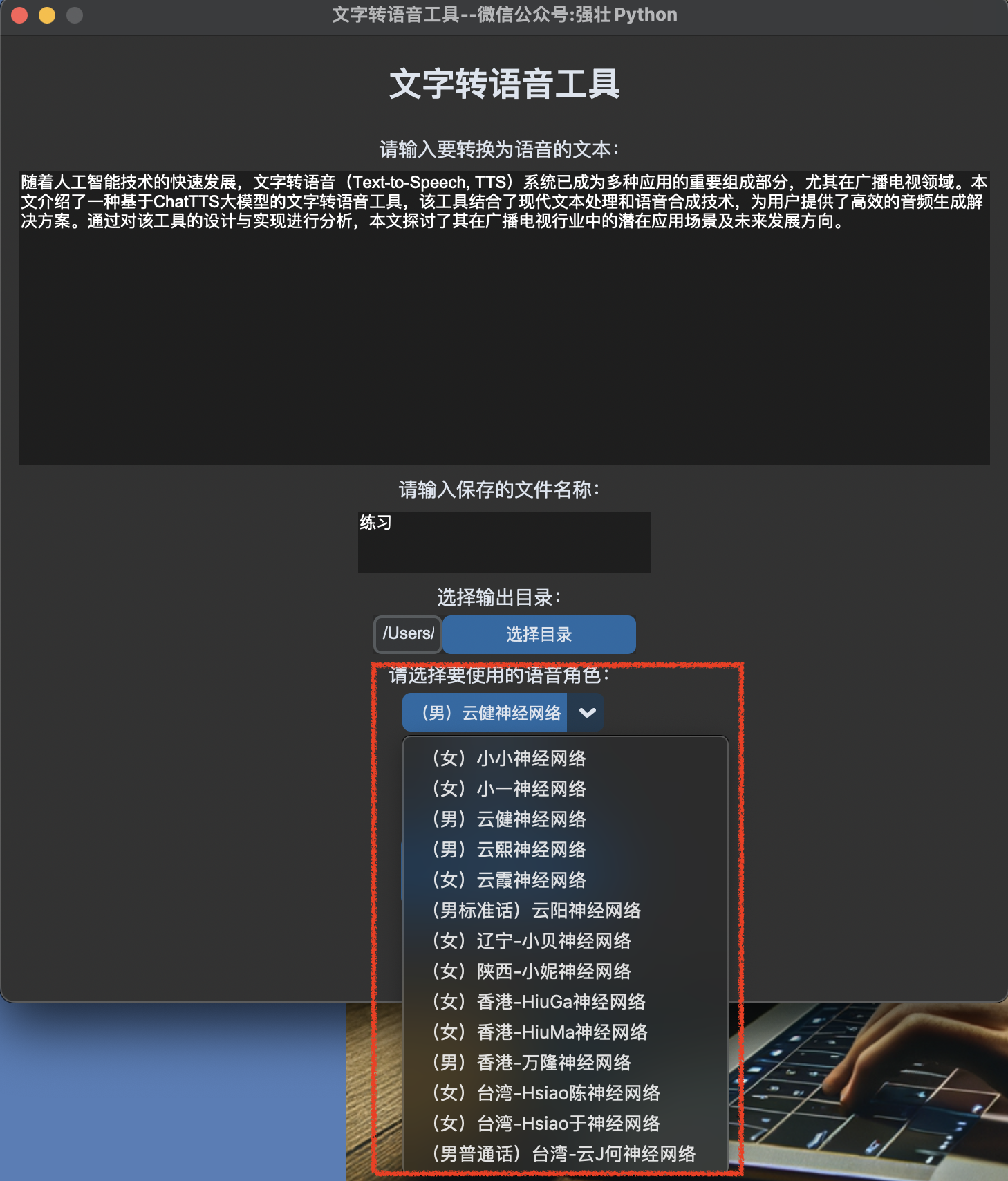
选择需要的语速,默认是0,也就是正常语速,如下图所示:
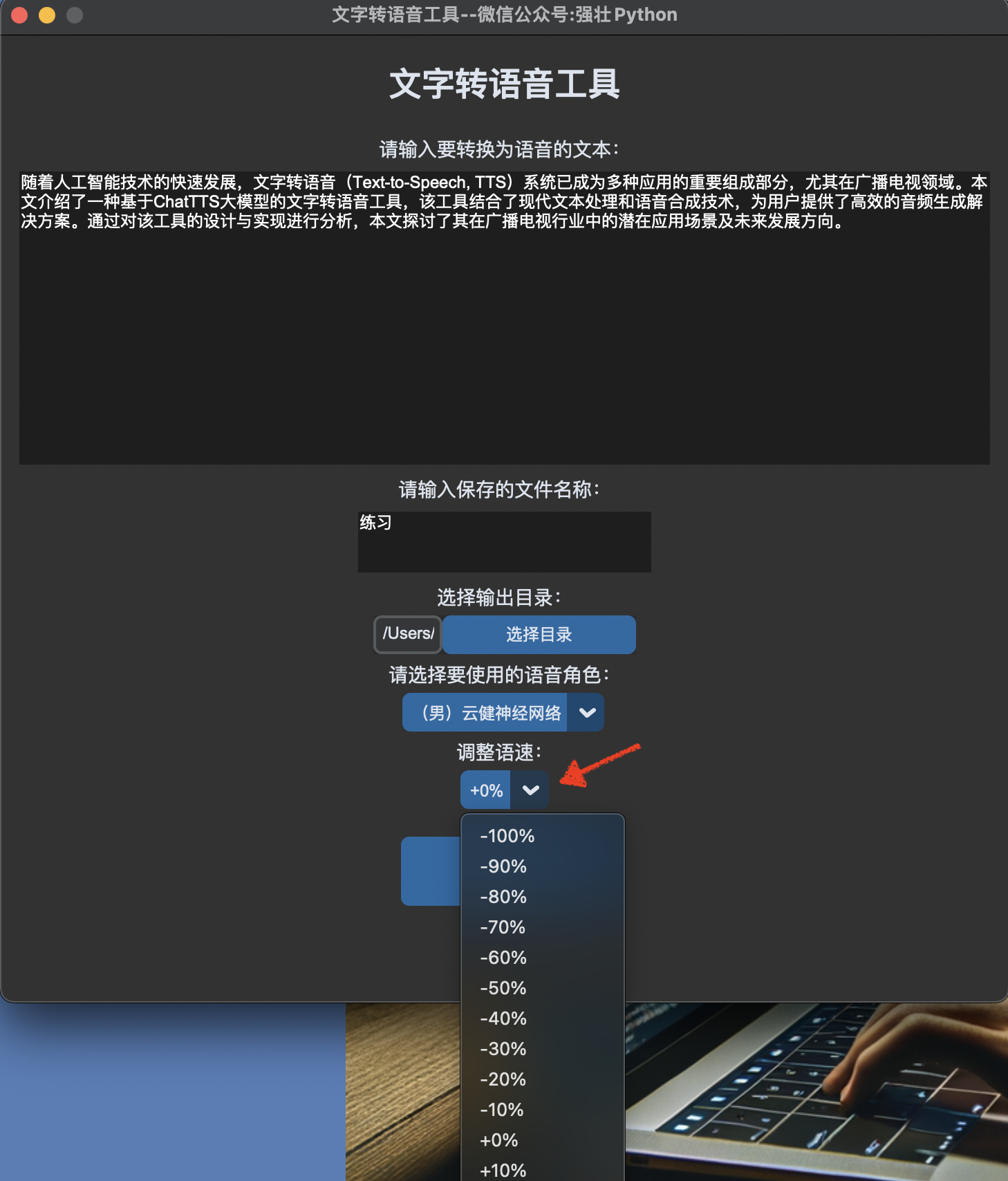
点击合成音频按钮,转换成功,会自动弹窗音频文件生成成功。如下图所示:
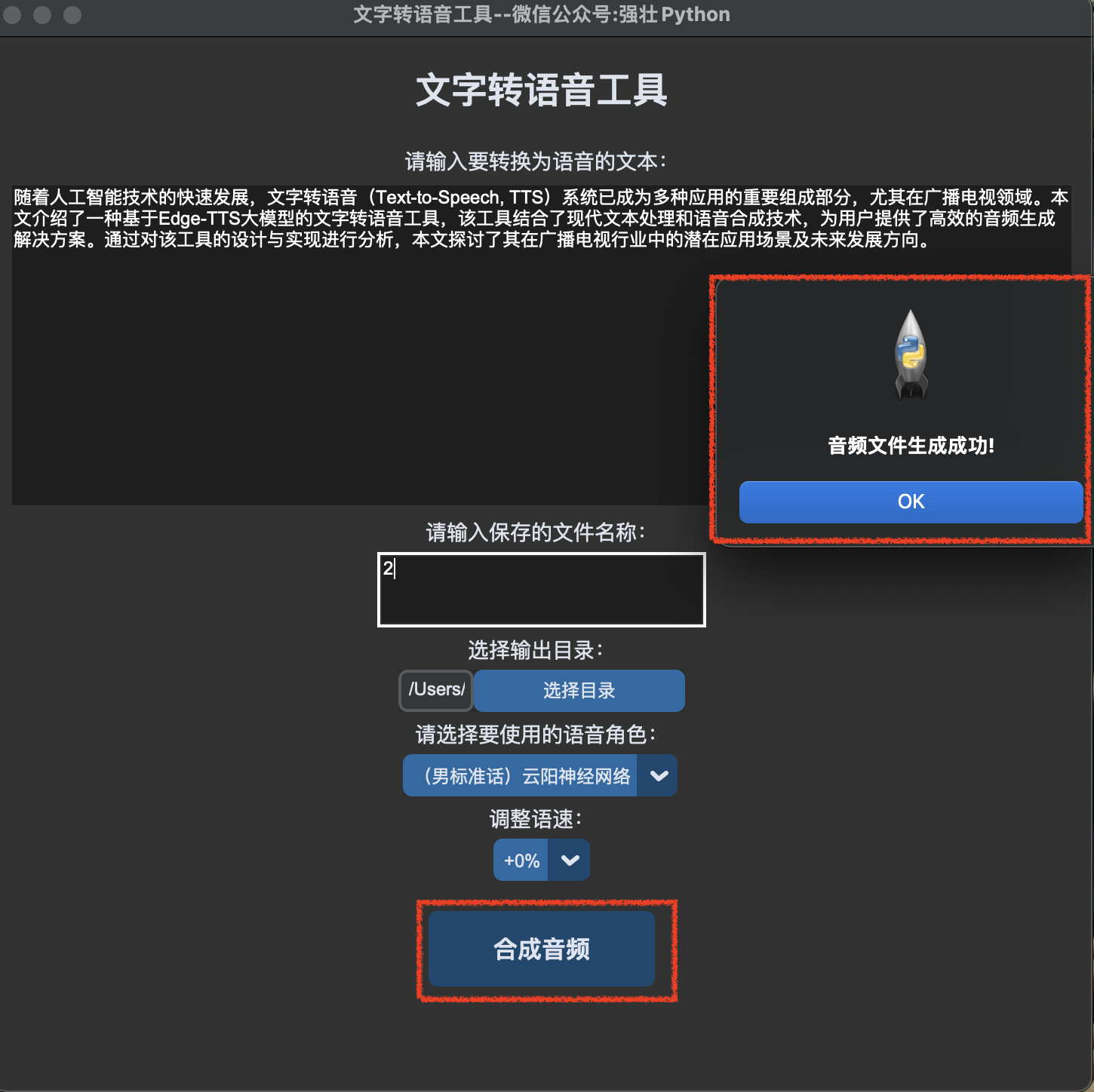
异步任务处理
为了提高程序的响应速度,工具采用了异步编程模式。通过使用asyncio库,合成音频的任务在后台运行,确保界面持续响应用户的其他操作。这种设计方式不仅增强了程序的流畅性,还避免了在较大文本量处理时可能出现的“卡顿”现象。
文件管理
工具的文件管理功能非常健全。首先,用户可以选择生成的音频文件保存的目录,系统会检查该目录是否存在,如不存在则自动创建。此外,音频文件命名方面,工具支持用户自定义文件名,确保生成的音频文件易于识别和分类。最终,所有生成的文件均以.mp3格式存储,以保证广泛的兼容性。
应用场景
本工具的设计理念和实现方式使其在广播电视行业具有广泛的应用前景:
-
新闻播报:通过快速生成新闻稿件的音频版本,提升新闻传播的效率。媒体机构可以在紧急情况下迅速将消息以语音形式发布,提高信息传递的时效性。
-
广告制作:为广告文案提供音频支持,增强广告的吸引力和传播效果。企业在制作广告时,可以根据目标受众选择合适的声音角色,提升广告的亲和力。
-
教育培训:为在线教育平台提供课程内容的音频化服务,提高学生的学习兴趣和效果。教师可以利用此工具将教学材料转化为声音,让学习变得更加生动。
未来发展方向
随着深度学习和自然语言处理技术的不断进步,TTS系统将朝着更高的音质、更丰富的声音特征和更自然的表达方式发展。未来,本工具可以进一步集成情感识别、个性化声音合成等高级功能,以更好地服务于广播电视行业的多样化需求。例如,通过分析文本的情感因素,生成情感丰富的语音输出,以增强听众的参与感和沉浸感。
结论
基于Edge-TTS大模型的文字转语音工具展现了强大的潜力,在广播电视领域具有实际应用价值。通过不断优化和扩展工具的功能,可以为行业提供更加高效、灵活的音频合成解决方案,助力信息传播的全面升级。本文的研究不仅为当前技术的应用提供了一定的参考,也为未来的研究方向指明了道路。
以上是对Edge-TTS大模型在广播电视领域应用的详细解释和说明,旨在深化理解并完善论文内容。通过这些具体的功能描述和应用场景分析,希望能够为相关领域的研究者和开发者提供有益的参考和启示。
原创不易,欢迎点赞、关注、转发、收藏!!!
相关文章:
Edge-TTS在广电系统中的语音合成技术的创新应用
Edge-TTS在广电系统中的语音合成技术的创新应用 作者:本人是一名县级融媒体中心的工程师,多年来一直坚持学习、提升自己。喜欢Python编程、人工智能、网络安全等多领域的技术。 摘要 随着人工智能技术的快速发展,文字转语音(Te…...

2025课题推荐——USBL与DVL数据融合的实时定位系统
准确的定位技术是现代海洋探测、海洋工程和水下机器人操作的基础。超短基线(USBL)和多普勒速度计(DVL)是常用的水下定位技术,但单一技术难以应对复杂环境。因此,USBL与DVL的数据融合以构建实时定位系统&…...

RK3588平台开发系列讲解(ARM篇)ARM64底层中断处理
文章目录 一、异常级别二、异常分类2.1、同步异常2.2、异步异常三、中断向量表沉淀、分享、成长,让自己和他人都能有所收获!😄 一、异常级别 ARM64处理器确实定义了4个异常级别(Exception Levels, EL),分别是EL0到EL3。这些级别用于管理处理器的特权级别和权限,级别越高…...

MyBatis最佳实践:提升数据库交互效率的秘密武器
第一章:框架的概述: MyBatis 框架的概述: MyBatis 是一个优秀的基于 Java 的持久框架,内部对 JDBC 做了封装,使开发者只需要关注 SQL 语句,而不关注 JDBC 的代码,使开发变得更加的简单MyBatis 通…...
Three.js实战项目02:vue3+three.js实现汽车展厅项目
文章目录 实战项目02项目预览项目创建初始化项目模型加载与展厅灯光加载汽车模型设置灯光材质设置完整项目下载实战项目02 项目预览 完整项目效果: 项目创建 创建项目: pnpm create vue安装包: pnpm add three@0.153.0 pnpm add gsap初始化项目 修改App.js代码&#x…...

CPP-存储区域
CPP支持手动开辟和释放内存,所以对于内存的理解非常重要! 在C中,内存存储通常可以大致分为几个区域,这些区域根据存储的数据类型、生命周期和作用域来划分。这些区域主要包括: 代码区(Code Segment/Text S…...

1月27(信息差)
🌍喜大普奔,适用于 VS Code 的 GitHub Copilot 全新免费版本正式推出,GitHub 全球开发者突破1.5亿 🎄Kimi深夜炸场:满血版多模态o1级推理模型!OpenAI外全球首次!Jim Fan:同天两款国…...

开发环境搭建-3:配置 nodejs 开发环境 (fnm+ node + pnpm)
在 WSL 环境中配置:WSL2 (2.3.26.0) Oracle Linux 8.7 官方镜像 node 官网:https://nodejs.org/zh-cn/download 点击【下载】,选择想要的 node 版本、操作系统、node 版本管理器、npm包管理器 根据下面代码提示依次执行对应代码即可 基本概…...

深入理解Pytest中的Setup和Teardown
关注开源优测不迷路 大数据测试过程、策略及挑战 测试框架原理,构建成功的基石 在自动化测试工作之前,你应该知道的10条建议 在自动化测试中,重要的不是工具 对于简单程序而言,使用 Pytest 运行测试直截了当。然而,当你…...

一个局域网通过NAT访问另一个地址重叠的局域网(IP方式访问)
正文共:1335 字 7 图,预估阅读时间:4 分钟 现在,我们已经可以通过调整两台设备的组合配置(地址重叠时,用户如何通过NAT访问对端IP网络?)或仅调整一台设备的配置(仅操作一…...

MongoDB中常用的几种高可用技术方案及优缺点
MongoDB 的高可用性方案主要依赖于其内置的 副本集 (Replica Set) 和 Sharding 机制。下面是一些常见的高可用性技术方案: 1. 副本集 (Replica Set) 副本集是 MongoDB 提供的主要高可用性解决方案,确保数据在多个节点之间的冗余存储和自动故障恢复。副…...

DeepSeek学术题目选择效果怎么样?
论文选题 一篇出色的论文背后,必定有一个“智慧的选题”在撑腰。选题足够好文章就能顺利登上高水平期刊;选题不行再精彩的写作也只能“当花瓶”。然而许多宝子们常常忽视这个环节,把大量时间花在写作上,选题时却像抓阄一样随便挑一…...

Lesson 119 A true story
Lesson 119 A true story 词汇 story n. 故事,传记,小说,楼层storey 搭配:tell a story 讲故事,说谎 true story 真实的故事 the second floor 二楼 例句:我猜他正在说谎。 I guess he…...

正反转电路梯形图
1、正转联锁控制。按下正转按钮SB1→梯形图程序中的正转触点X000闭合→线圈Y000得电→Y000自锁触点闭合,Y000联锁触点断开,Y0端子与COM端子间的内部硬触点闭合→Y000自锁触点闭合,使线圈Y000在X000触点断开后仍可得电。 Y000联锁触点断开&…...

Java并发学习:进程与线程的区别
进程的基本原理 一个进程是一个程序的一次启动和执行,是操作系统程序装入内存,给程序分配必要的系统资源,并且开始运行程序的指令。 同一个程序可以多次启动,对应多个进程,例如同一个浏览器打开多次。 一个进程由程…...
)
解锁罗技键盘新技能:轻松锁定功能键(罗技K580)
在使用罗技键盘的过程中,你是否曾因 F11、F12 功能键的默认设置与实际需求不符而感到困扰? 别担心,今天就为大家分享一个简单实用的小技巧 —— 锁定罗技键盘的 F11、F12 功能键,让你的操作更加得心应手! 通常情况下…...

分布式微服务系统架构第88集:kafka集群
使用集 群最大的好处是可以跨服务器进行负载均衡,再则就是可以使用复制功能来避免因单点故 障造成的数据丢失。在维护 Kafka 或底层系统时,使用集群可以确保为客户端提供高可用 性。 需要多少个broker 一个 Kafka 集群需要多少个 broker 取决于以下几个因…...
)
ESP32-S3模组上跑通esp32-camera(33)
接前一篇文章:ESP32-S3模组上跑通esp32-camera(32) 一、OV5640初始化 2. 相机初始化及图像传感器配置 上一回开始解析camera_probe函数的第8段即最后一段代码,本回继续解析该段代码。为了便于理解和回顾,再次贴出camera_probe函数源码,在components/esp32-camera/drive…...

一次端口监听正常,tcpdump无法监听到指定端口报文问题分析
tcpdump命令: sudo tcpdump -i ens2f0 port 6471 -XXnnvvv 下面是各个部分的详细解释: 1.tcpdump: 这是用于捕获和分析网络数据包的命令行工具。 2.-i ens2f0: 指定监听的网络接口。ens2f0 表示本地网卡),即计算机该指定网络接口捕…...

高可用集群故障之join
本文记录了在部署高可用的k8s集群时,遇到的一个故障及其解决方法。 集群环境 描述:三主三从,eth0为外网网卡,eth1为内网网卡,内网互通。 需求:eth0只负责访问外网,eth1作为集群间的通信。 主…...

uniapp版本升级
1.样式 登录进到首页,弹出更新提示框,且不可以关闭,侧边返回直接退出! 有关代码: <uv-popup ref"popupUpdate" round"8" :close-on-click-overlay"false"><view style"…...

Ubuntu 20.04 x64下 编译安装ffmpeg
试验的ffmpeg版本 4.1.3 本文使用的config命令 ./configure --prefixhost --enable-shared --disable-static --disable-doc --enable-postproc --enable-gpl --enable-swscale --enable-nonfree --enable-libfdk-aac --enable-decoderh264 --enable-libx265 --enable-libx…...

【Web开发】一步一步详细分析使用Bolt.new生成的简单的VUE项目
https://bolt.new/ 这是一个bolt.new生成的Vue小项目,让我们来一步一步了解其架构,学习Vue开发,并美化它。 框架: Vue 3: 用于构建用户界面。 TypeScript: 提供类型安全和更好的开发体验。 Vite: 用于快速构建和开发 主界面如下:…...

SpringBoot源码解析(八):Bean工厂接口体系
SpringBoot源码系列文章 SpringBoot源码解析(一):SpringApplication构造方法 SpringBoot源码解析(二):引导上下文DefaultBootstrapContext SpringBoot源码解析(三):启动开始阶段 SpringBoot源码解析(四):解析应用参数args Sp…...

在ubuntu下一键安装 Open WebUI
该脚本用于自动化安装 Open WebUI,并支持以下功能: 可选跳过 Ollama 安装:通过 --no-ollama 参数跳过 Ollama 的安装。自动清理旧目录:如果安装目录 (~/open-webui) 已存在,脚本会自动删除旧目录并重新安装。完整的依…...

Flutter子页面向父组件传递数据方法
在 Flutter 中,如果父组件需要调用子组件的方法,可以通过以下几种方式实现。以下是常见的几种方法: 方法 1:使用 GlobalKey 和 State 调用子组件方法 这是最直接的方式,通过 GlobalKey 获取子组件的 State,…...

论文阅读 AlphaFold 2
用AlphaFold进行非常精确的蛋白质结构的预测(AlphaFold2) 发表于2021年07月15日 NatureDOI: 10.1038/s41586-021-03819-2自然和科学杂志评选为2021年最重要的科学突破之一2021年AI在科学界最大的突破 前言 2020年11月30号, deepmind博客说AlphaFold解决了50年以来生物学的大挑…...

计算机网络 (62)移动通信的展望
一、技术发展趋势 6G技术的崛起 内生智能:6G将强调自适应网络架构,通过AI驱动的智能算法提升通信能力。例如,基于生成式AI的6G内生智能架构将成为重要研究方向,实现低延迟、高效率的智能通信。信息编码与调制技术:新型…...

如何学习Java后端开发
文章目录 一、Java 语言基础二、数据库与持久层三、Web 开发基础四、主流框架与生态五、分布式与高并发六、运维与部署七、项目实战八、持续学习与提升总结路线图 学习 Java 后端开发需要系统性地掌握多个技术领域,从基础到进阶逐步深入。以下是一个详细的学习路线和…...

探索与创新:DeepSeek R1与Ollama在深度研究中的应用
在当今信息爆炸的时代,获取和处理信息的能力变得至关重要。特别是在学术和研究领域,如何有效地进行深度研究是一个亟待解决的问题。最近,一个名为DeepSeek R1的模型结合Ollama平台提供了一种创新的解决方案。本文将分析并解构这一新兴的研究工…...