YOLO目标检测4
一. 参考资料
《YOLO目标检测》 by 杨建华博士
本篇文章的主要内容来自于这本书,只是作为学习记录进行分享。

二. 环境搭建
(1) ubuntu20.04 anaconda安装方法
(2) 搭建yolo训练环境
# 首先,我们建议使用Anaconda来创建一个conda的虚拟环境
conda create -n yolo python=3.6
# 然后, 请激活已创建的虚拟环境
conda activate yolo
# 接着,配置环境:
pip install -r requirements.txt
# 项目作者所使用的环境配置:PyTorch = 1.9.1
Torchvision = 0.10.1
# 为了能够正常运行该项目的代码,请确保您的torch版本为1.x系列。三. YOLOv1代码解读
3.1 YOLOv1整体框架
# YOLO_Tutorial/models/yolov1/yolov1.py
# --------------------------------------------------------
...class YOLOv1(nn.Module):def __init__(self, cfg, device, input_size, num_classes,
trainable, conf_thresh, nms_thresh):super(YOLOv1, self).__init__()self.cfg=cfg # 模型配置文件self.device=device # 设备、CUDA或CPUself.num_classes=num_classes # 类别的数量self.trainable=trainable # 训练的标记self.conf_thresh=conf_thresh # 得分阈值self.nms_thresh=nms_thresh # NMS阈值self.stride=32 # 网络的最大步长# >>>>>>>>>>>>>>>>>>>> 主干网络 <<<<<<<<<<<<<<<<<<<<<# TODO: 构建我们的backbone网络# self.backbone=?# >>>>>>>>>>>>>>>>>>>> 颈部网络 <<<<<<<<<<<<<<<<<<<<<# TODO: 构建我们的neck网络# self.neck=?# >>>>>>>>>>>>>>>>>>>> 检测头 <<<<<<<<<<<<<<<<<<<<<# TODO: 构建我们的detection head 网络# self.head=?# >>>>>>>>>>>>>>>>>>>> 预测层 <<<<<<<<<<<<<<<<<<<<<# TODO: 构建我们的预测层# self.pred=?def create_grid(self, input_size):# TODO: 用于生成网格坐标矩阵def decode_boxes(self, pred):# TODO: 解算边界框坐标def nms(self, bboxes, scores):# TODO: 非极大值抑制操作def postprocess(self, bboxes, scores):# TODO: 后处理, 包括得分阈值筛选和NMS操作@torch.no_grad()def inference(self, x):# TODO: YOLOv1前向推理def forward(self, x, targets=None):# TODO: YOLOv1的主体运算函数3.2 YOLOv1主干网络
作者改进的YOLOv1使用较轻量的ResNet-18作为主干网络。由于PyTorch官方已提供了ResNet的源码和相应的预训练模型,因此,这里就不需要我们自己去搭建ResNet的网络和训练了。为了方便调用和查看,ResNet的代码文件放在项目中models/yolov1/yolov1_backbone.py文件下,感兴趣的读者可以打开该文件来查看ResNet网络的代码。在确定了主干网络后,我们只需在YOLOv1框架中编写代码即可调用ResNet-18网络,如代码4-5所示。
# >>>>>>>>>>>>>>>>>>>>主干网络<<<<<<<<<<<<<<<<<<<<<
# TODO:构建我们的backbone网络
self.backbone,feat_dim=build_backbone(cfg['backbone'],trainable&cfg['pretrained'])在代码4-5中,cfg是模型的配置文件,feat_dim变量是主干网络输出的特征图的通道数,这在后续的代码会使用到。我们通过trainable&cfg['pretrained']的组合来决定是否加载预训练权重。代码4-6展示了模型的配置文件所包含的一些参数,包括网络结构的参数、损失函数所需的权重参数、优化器参数以及一些训练配置参数等,每个参数的含义都已标注在注释中。
# YOLO_Tutorial/config/mode1_config/yolov1_config.py
# --------------------------------------------------------
...yolov1_cfg={# input'trans_type': 'ssd', # 使用SSD风格的数据增强'multi_scale': [0.5, 1.5], # 多尺度的范围# model'backbone': 'resnet18', # 使用ResNet-18作为主干网络'pretrained': True, # 加载预训练权重'stride': 32, # P5 # 网络的最大输出步长# neck'neck': 'sppf', # 使用SPP作为颈部网络'expand_ratio': 0.5, # SPP的模型参数'pooling_size': 5, # SPP的模型参数'neck_act': 'lrelu', # SPP的模型参数'neck_norm': 'BN', # SPP的模型参数'neck_depthwise': False, # SPP的模型参数# head'head': 'decoupled_head', # 使用解耦检测头'head_act': 'lrelu', # 检测头所需的参数'head_norm': 'BN', # 检测头所需的参数'num_cls_head': 2, # 解耦检测头的类别分支所包含的卷积层数'num_reg_head': 2, # 解耦检测头的回归分支所包含的卷积层数'head_depthwise': False, # 检测头所需的参数# loss weight'loss_obj_weight': 1.0, # obj损失的权重'loss_cls_weight': 1.0, # cls损失的权重'loss_box_weight': 5.0, # box损失的权重# training configuration'no_aug_epoch': -1, # 关闭马赛克增强和混合增强的节点# optimizer'optimizer': 'sgd', # 使用SGD优化器'momentum': 0.937, # SGD优化器的momentum参数'weight_decay': 5e-4, # SGD优化器的weight_decay参数'clip_grad': 10, # 梯度剪裁参数# model EMA'ema_decay': 0.9999, # 模型EMA参数'ema_tau': 2000, # 模型EMA参数# lr schedule'scheduler': 'linear', # 使用线性学习率衰减策略'lr0': 0.01, # 初始学习率'lrf': 0.01, # 最终的学习率=lr0 * lrf'warmup_momentum': 0.8, # Warmup阶段, 优化器的momentum参数的初始值'warmup_bias_lr': 0.1, # Warmup阶段, 优化器为模型的bias参数设置的学习率初始值
}3.3 YOLOv1颈部网络
作者改进的YOLOv1选择SPP模块作为颈部网络。SPP网络的结构非常简单,仅由若干不同尺寸的核的最大池化层所组成,实现起来也非常地简单,相关代码我们已经在前面展示了。而在YOLOv1中,我们直接调用相关的函数来使用SPP即可,如代码4-7所示。
# >>>>>>>>>>>>>>>>>>>> 颈部网络 <<<<<<<<<<<<<<<<<<<<<
# TODO: 构建我们的颈部网络
self.neck=build_neck(cfg, feat_dim, out_dim=512)
head_dim=self.neck.out_dim3.4 YOLOv1检测头
有关检测头的代码和预测层相关的代码已经在前面介绍过了,这里,我们只需要调用相关的函数来使用解耦检测头,然后再使用卷积创建预测层,如代码4-8所示。
# >>>>>>>>>>>>>>>>>>>> 检测头 <<<<<<<<<<<<<<<<<<<<<
# TODO: 构建我们的detection head 网络
## 检测头
self.head=build_head(cfg, head_dim, head_dim, num_classes)# >>>>>>>>>>>>>>>>>>>> 预测层 <<<<<<<<<<<<<<<<<<<<<
# TODO: 构建我们的预测层
self.obj_pred=nn.Conv2d(head_dim, 1, kernel_size=1)
self.cls_pred=nn.Conv2d(head_dim, num_classes, kernel_size=1)
self.reg_pred=nn.Conv2d(head_dim, 4, kernel_size=1)3.5 YOLOv1前向推理函数
在上述所示的推理代码中,作者对pred操作执行了view操作,将和
两个维度合并到一起,由于这之后不会再有任何卷积操作了,而仅仅是要计算损失,因此,将输出张量的维度从
调整为
的目的仅是方便后续的损失计算和后处理,而不会造成其他不必要的负面影响。
def forward(self, x):if not self.trainable:return self.inference(x)else:# 主干网络feat=self.backbone(x)# 颈部网络feat=self.neck(feat)# 检测头cls_feat, reg_feat=self.head(feat)# 预测层obj_pred=self.obj_pred(cls_feat)cls_pred=self.cls_pred(cls_feat)reg_pred=self.reg_pred(reg_feat)fmp_size=obj_pred.shape[-2:]# 对pred 的size做一些调整, 便于后续的处理# [B, C, H, W] -> [B, H, W, C] -> [B, H*W, C]obj_pred=obj_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)cls_pred=cls_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)reg_pred=reg_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)# 解耦边界框box_pred=self.decode_boxes(reg_pred, fmp_size)# 网络输出outputs={"pred_obj": obj_pred, # (Tensor) [B, M, 1]"pred_cls": cls_pred, # (Tensor) [B, M, C]"pred_box": box_pred, # (Tensor) [B, M, 4]"stride": self.stride, # (Int)"fmp_size": fmp_size # (List) [fmp_h, fmp_w]}return outputs另外,在测试阶段,我们只需要推理当前输入图像,无须计算损失,所以我们单独实现了一个inference函数,如代码4-10所示。
@torch.no_grad()
def inference(self, x):# 主干网络feat=self.backbone(x)# 颈部网络feat=self.neck(feat)# 检测头cls_feat, reg_feat=self.head(feat)# 预测层obj_pred=self.obj_pred(cls_feat)cls_pred=self.cls_pred(cls_feat)reg_pred=self.reg_pred(reg_feat)fmp_size=obj_pred.shape[-2:]# 对pred 的size做一些调整, 便于后续的处理# [B, C, H, W] -> [B, H, W, C] -> [B, H*W, C]obj_pred=obj_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)cls_pred=cls_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)reg_pred=reg_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)# 测试时, 默认batch是1# 因此, 我们不需要用batch这个维度, 用[0]将其取走obj_pred=obj_pred[0] # [H*W, 1]cls_pred=cls_pred[0] # [H*W, NC]reg_pred=reg_pred[0] # [H*W, 4]# 每个边界框的得分scores=torch.sqrt(obj_pred.sigmoid() * cls_pred.sigmoid())# 解算边界框, 并归一化边界框: [H*W, 4]bboxes=self.decode_boxes(reg_pred, fmp_size)# 将预测放在CPU处理上, 以便进行后处理scores=scores.cpu().numpy()bboxes=bboxes.cpu().numpy()# 后处理bboxes, scores, labels=self.postprocess(bboxes, scores)return bboxes, scores, labels在上面的用于推理的代码中,装饰器@torch.no_grad()表示该inference函数不会存在任何梯度,因为推理阶段不会涉及反向传播,无须计算变量的梯度。在这段代码中,多了一个后处理postprocess函数的调用,将在后续进行说明。
至此,我们搭建完了YOLOv1的网络,只需将上面的单独实现分别对号入座地加入YOLOv1的网络框架里。最后,我们就可以获得网络的3个预测分支的输出。但是,这里还遗留下了以下3个问题尚待处理。
(1) 如何有效地计算出边界框的左上角点坐标和右下角点坐标。
(2) 如何计算3个分支的损失。
(3) 如何对预测结果进行后处理。
3.6 YOLOv1的后处理
(1) 求解预测边界框的坐标
对于某一处的网格,YOLOv1输出的边界框的中心点偏移量预测为
和
,宽和高的对数映射预测为
和
,我们使用公式(4-6)即可解算出边界框的中心点坐标
和
与宽高
和
其中,是Sigmoid函数。从公式中可以看出,为了计算预测的边界框的中心点坐标,我们需要获得网格的坐标
,因为我们的YOLOv1也是在每个网格预测偏移量,从而获得精确的边界框中心点坐标。直接的方法就是遍历每一个网格,以获取网格坐标,然后加上此处预测的偏移量即可获得此处预测出的边界框中心点坐标,但是这种for循环操作的效率不高。在一般情况下,能用矩阵运算来实现的操作就尽量避免使用for循环,因为不论是GPU还是CPU,矩阵运算都是可以并行处理的,开销更小,因此,这里我们采用一个讨巧的等价方法。
在计算边界框坐标之前,先生成一个保存网格所有坐标的矩阵,其中
和
是输出的特征图的空间尺寸,2是网格的横纵坐标。
就是输出特征图上
处的网格坐标
,即
,
,如图4-7所示。

所以,在清楚了G矩阵的含义后,我们便可以编写相应的代码来生成G矩阵,如代码4-11所示。
def create_grid(self, input_size):# 输入图像的宽和高w, h=input_size, input_size# 特征图的宽和高ws, hs=w // self.stride, h // self.stride# 生成网格的x坐标和y坐标grid_y, grid_x=torch.meshgrid([torch.arange(hs), torch.arange(ws)])# 将x和y两部分的坐标拼起来:[H, W, 2]grid_xy=torch.stack([grid_x, grid_y], dim=-1).float()# [H, W, 2] -> [HW, 2]grid_xy=grid_xy.view(-1, 2).to(self.device)return grid_xy注意,为了后续解算边界框的方便,将grid_xy的维度调整成的形式,因为在讲解YOLOv1的前向推理的代码时,输出的txtytwth_pred的维度被调整为
的形式,这里我们为了保持维度一致,也做了同样的处理。在得到了G矩阵之后,我们就可以很容易计算边界框的位置参数了,包括边界框的中心点坐标、宽、高、左上角点坐标和右下角点坐标,代码4-12展示了这一计算过程。
def decode_boxes(self, pred, fmp_size):"""将txtytwth转换为常用的x1y1x2y2形式"""# 生成网格坐标矩阵grid_cell=self.create_grid(fmp_size)# 计算预测边界框的中心点坐标、宽和高pred_ctr=(torch.sigmoid(pred[..., :2]) + grid_cell) * self.stridepred_wh=torch.exp(pred[..., 2:]) * self.stride# 将所有边界框的中心点坐标、宽和高换算成x1y1x2y2形式pred_x1y1=pred_ctr - pred_wh * 0.5pred_x2y2=pred_ctr + pred_wh * 0.5pred_box=torch.cat([pred_x1y1, pred_x2y2], dim=-1)return pred_box最终,我们会得到边界框的左上和右下角点坐标。
3.7 后处理
当我们得到了边界框的位置参数后,我们还需要对预测结果做进一步的后处理,滤除那些得分低的边界框和检测到同一目标的冗余框。因此,后处理的主要作用可以总结为两点:
(1)滤除得分低的低质量边界框;
(2)滤除对同一目标的冗余检测结果,即非极大值抑制(NMS)处理。在清楚了后处理的逻辑和目的后,我们就可以编写相应的代码了,如代码4-13所示。
def postprocess(self, bboxes, scores):# 将得分最高的类别作为预测的类别标签labels=np.argmax(scores, axis=1)# 预测标签所对应的得分scores=scores[(np.arange(scores.shape[0]), labels)]# 阈值筛选keep=np.where(scores >=self.conf_thresh)bboxes=bboxes[keep]scores=scores[keep]labels=labels[keep]# 非极大值抑制keep=np.zeros(len(bboxes), dtype=np.int)for i in range(self.num_classes):inds=np.where(labels==i)[0]if len(inds)==0:continuec_bboxes=bboxes[inds]c_scores=scores[inds]c_keep=self.nms(c_bboxes, c_scores)keep[inds[c_keep]]=1keep=np.where(keep > 0)bboxes=bboxes[keep]scores=scores[keep]labels=labels[keep]return bboxes, scores, labels我们采用十分经典的基于Python语言实现的代码作为本文的非极大值抑制。在入门阶段,希望读者能够将这段代码烂熟于心,这毕竟是此领域的必备算法之一。相关代码如代码4-14所示。
def nms(self, bboxes, scores):"""Pure Python NMS baseline."""x1=bboxes[:, 0] #xminy1=bboxes[:, 1] #yminx2=bboxes[:, 2] #xmaxy2=bboxes[:, 3] #ymaxareas=(x2 - x1) * (y2 - y1)order=scores.argsort()[::-1]keep=[]while order.size > 0:i=order[0]keep.append(i)# 计算交集的左上角点和右下角点的坐标xx1=np.maximum(x1[i], x1[order[1:]])yy1=np.maximum(y1[i], y1[order[1:]])xx2=np.minimum(x2[i], x2[order[1:]])yy2=np.minimum(y2[i], y2[order[1:]])# 计算交集的宽和高w=np.maximum(1e-10, xx2 - xx1)h=np.maximum(1e-10, yy2 - yy1)# 计算交集的面积inter=w * h# 计算交并比iou=inter / (areas[i] + areas[order[1:]] - inter)# 滤除超过NMS阈值的边界框inds=np.where(iou <=self.nms_thresh)[0]order=order[inds + 1]return keep经过后处理后,我们得到了最终的3个输出变量:
(1)变量bboxes,包含每一个边界框的左上角坐标和右下角坐标;
(2)变量scores,包含每一个边界框的得分;
(3)变量labels,包含每一个边界框的类别预测。
至此,我们填补了之前留下来的空白,只需要将上面实现的每一个函数放置到YOLOv1的代码框架中,即可组成最终的模型代码。读者可以打开项目中的models/yolov1/yolov1.py文件来查看完整的YOLOv1的模型代码。
四.代码
https://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorialhttps://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorialhttps://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorialhttps://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorialhttps://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorialhttps://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorial![]() https://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorial
https://github.com/Tipriest/Lessons/tree/master/YOLO/YOLO_Tutorial
相关文章:
YOLO目标检测4
一. 参考资料 《YOLO目标检测》 by 杨建华博士 本篇文章的主要内容来自于这本书,只是作为学习记录进行分享。 二. 环境搭建 (1) ubuntu20.04 anaconda安装方法 (2) 搭建yolo训练环境 # 首先,我们建议使用Anaconda来创建一个conda的虚拟环境 conda cre…...

ONES 春节假期服务通知
ONES 春节假期服务通知 灵蛇贺岁,瑞气盈门。感谢大家一直以来对 ONES 的认可与支持,祝您春节快乐! 「2025年1月28日 ~ 2025年2月4日」春节假期期间,我们的值班人员将为您提供如下服务 : 紧急问题 若有紧急问…...

DeepSeek异军突起,重塑AI格局
DeepSeek异军突起,重塑AI格局这两天AI 圈发生了比过年更令人兴奋的事情,“Meta内部反水事件”、“黄仁勋的底盘问题”,以及AI格局的大动荡,一切都是因为那个叫DeepSeek的“中国自主AI”!它由幻方量化开发,以…...

Redis部署方式全解析:优缺点大对比
Redis部署方式全解析:优缺点大对比 一、引言 Redis作为一款高性能的内存数据库,在分布式系统、缓存、消息队列等众多场景中都有着广泛的应用。选择合适的Redis部署方式,对于系统的性能、可用性、可扩展性以及成本等方面都有着至关重要的影响…...

Rust:如何动态调用字符串定义的 Rhai 函数?
在 Rust 中使用 Rhai 脚本引擎时,你可以动态地调用传入的字符串表示的 Rhai 函数。Rhai 是一个嵌入式脚本语言,专为嵌入到 Rust 应用中而设计。以下是一个基本示例,展示了如何在 Rust 中调用用字符串传入的 Rhai 函数。 首先,确保…...

关于使用微服务的注意要点总结
一、防止过度设计 微服务的拆分一定要结合团队人员规模来考虑,笔者就曾遇到过一个公司的项目,是从外部采购回来的,微服务划分为十几个应用,我们在此项目基础上进行自行维护和扩展。由于公司业务规模不大,而且二次开发的…...

【新春不断更】数据结构与算法之美:二叉树
Hello大家好,我是但凡!很高兴我们又见面啦! 眨眼间已经到了2024年的最后一天,在这里我要首先感谢过去一年陪我奋斗的每一位伙伴,是你们给予我不断前行的动力。银蛇携福至,万象启新程。蛇年新春之际…...

Linux环境基础开发工具的使用(apt, vim, gcc, g++, gbd, make/Makefile)
什么是软件包 在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序. 但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安 装程序)放在一个服务器上, 通过包管理器可以很方便的获取到这个编译好的…...

渗透测试之WAF规则触发绕过规则之规则库绕过方式
目录 Waf触发规则的绕过 特殊字符替换空格 实例 特殊字符拼接绕过waf Mysql 内置得方法 注释包含关键字 实例 Waf触发规则的绕过 特殊字符替换空格 用一些特殊字符代替空格,比如在mysql中%0a是换行,可以代替空格 这个方法也可以部分绕过最新版本的…...

新站如何快速获得搜索引擎收录?
本文来自:百万收录网 原文链接:https://www.baiwanshoulu.com/8.html 新站想要快速获得搜索引擎收录,需要采取一系列有针对性的策略。以下是一些具体的建议: 一、网站内容优化 高质量原创内容: 确保网站内容原创、…...

Harmony Next 跨平台开发入门
ArkUI-X 官方介绍 官方文档:https://gitee.com/arkui-x/docs/tree/master/zh-cn ArkUI跨平台框架(ArkUI-X)进一步将ArkUI开发框架扩展到了多个OS平台:目前支持OpenHarmony、Android、 iOS,后续会逐步增加更多平台支持。开发者基于一套主代码…...

小阿卡纳牌
小阿卡纳牌 风:热湿 火:热干 水:冷湿 土:冷干 火风:温度相同,但是湿度不同,二人可能会在短期内十分热情,但是等待热情消退之后,会趋于平淡。 湿度相同、温度不同&#x…...

【llm对话系统】LLM 大模型Prompt 怎么写?
如果说 LLM 是一个强大的工具,那么 Prompt 就是使用这个工具的“说明书”。一份好的 Prompt 可以引导 LLM 生成更准确、更相关、更符合你期望的输出。 今天,我们就来聊聊 LLM Prompt 的编写技巧,掌握这把解锁 LLM 潜能的钥匙! 一…...

【现代深度学习技术】深度学习计算 | 参数管理
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

c++ 定点 new
(1) 代码距离: #include <new> // 需要包含这个头文件 #include <iostream>int main() {char buffer[sizeof(int)]; // 分配一个足够大的字符数组作为内存池int* p new(&buffer) int(42); // 使用 placement new…...

Myeclipse最新版本 C1 2019.4.0
Myeclipse C1 2019.4.0下载地址:链接: https://pan.baidu.com/s/1MbOMLewvAdemoQ4FNfL9pQ 提取码: tmf6 1.1、什么是集成开发环境? ★集成开发环境讲究-站式开发,使用这个工具即可。有提示功能,有自动纠错功能。 ★集成开发环境可以让软件开…...

使用 lock4j-redis-template-spring-boot-starter 实现 Redis 分布式锁
在分布式系统中,多个服务实例可能同时访问和修改共享资源,从而导致数据不一致的问题。为了解决这个问题,分布式锁成为了关键技术之一。本文将介绍如何使用 lock4j-redis-template-spring-boot-starter 来实现 Redis 分布式锁,从而…...

thinkphp6+swoole使用rabbitMq队列
安装think-swoole安装 composer require php-amqplib/php-amqplib,以支持rabbitMq使用安装rabbitMq延迟队列插件 安装 rabbitmq_delayed_message_exchange 插件,按照以下步骤操作: 下载插件:https://github.com/rabbitmq/rabbitmq-delayed-…...

大一计算机的自学总结:异或运算
前言 异或运算这个操作看上去很匪夷所思,实际上作用非常大。 一、异或运算的性质 1.异或运算就是无进位相加。 2.满足交换律、结合律。 3.0^nn,n^n0。 4.若集合B为集合A子集,集合A异或和为x,集合B异或和为y,则集…...

宫本茂的游戏设计思想:有趣与风格化
作为独立游戏开发者之一,看到任天堂宫本茂20年前的言论后,深感认同。 游戏研发思想,与企业战略是互为表里的,游戏是企业战略的具体战术体现,虚空理念的有形载体。 任天堂长盛不衰的关键就是靠简单有趣的游戏…...
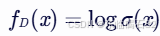
【AI论文】扩散对抗后训练用于一步视频生成总结
摘要:扩散模型被广泛应用于图像和视频生成,但其迭代生成过程缓慢且资源消耗大。尽管现有的蒸馏方法已显示出在图像领域实现一步生成的潜力,但它们仍存在显著的质量退化问题。在本研究中,我们提出了一种在扩散预训练后针对真实数据…...

使用Python Dotenv库管理环境变量
使用Python Dotenv库管理环境变量 在开发Python应用程序时,管理配置信息(如API密钥、数据库连接字符串等)是一个常见的需求。为了确保安全性和灵活性,通常不建议将这些敏感信息硬编码在代码中。这时,dotenv库就派上了…...

oracle 分区表介绍
oracle 分区表介绍 Oracle 分区表是一个非常强大的数据库功能,可以将一个大的表分割成多个更小、更易管理的块(分区)。这种分区结构在处理大规模数据时非常有用,因为它能改善性能、简化维护和管理,并支持高效的数据存取…...

在线可编辑Excel
1. Handsontable 特点: 提供了类似 Excel 的表格编辑体验,包括单元格样式、公式计算、数据验证等功能。 支持多种插件,如筛选、排序、合并单元格等。 轻量级且易于集成到现有项目中。 具备强大的自定义能力,可以调整外观和行为…...
)
基于 Node.js 的天气查询系统实现(附源码)
项目概述 这是一个基于 Node.js 的全栈应用,前端使用原生 JavaScript 和 CSS,后端使用 Express 框架,通过调用第三方天气 API 实现天气数据的获取和展示。 主要功能 默认显示多个主要城市的天气信息 支持城市天气搜索 响应式布局设计 深色主题界面 优雅的加载动画 技术栈 …...

【javaweb项目idea版】蛋糕商城(可复用成其他商城项目)
该项目虽然是蛋糕商城项目,但是可以复用成其他商城项目或者购物车项目 想要源码的uu可点赞后私聊 技术栈 主要为:javawebservletmvcc3p0idea运行 功能模块 主要分为用户模块和后台管理员模块 具有商城购物的完整功能 基础模块 登录注册个人信息编辑…...

langchain基础(三)
Chain: 关于三个invoke: 提示模板、聊天模型和输出解析器都实现了langchain的runnable接口, 都具有invoke方法(因为invoke方法是Runnable的通用调用方法) 所以可以一次性调用多次invoke直接得到最终结果:…...

在Ubuntu上用Llama Factory命令行微调Qwen2.5的简单过程
半年多之前写过一个教程:在Windows上用Llama Factory微调Llama 3的基本操作_llama-factory windows-CSDN博客 如果用命令行做的话,前面的步骤可以参考上面这个博客。安装好环境后, 用自我认知数据集微调Lora模块:data/identity.j…...

go 循环处理无限极数据
数据表结构: CREATE TABLE permission (id int(11) NOT NULL AUTO_INCREMENT COMMENT 权限ID,permission_name varchar(255) DEFAULT NULL COMMENT 权限名称,permission_url varchar(255) DEFAULT NULL COMMENT 权限路由,status tinyint(1) DEFAULT NULL COMMENT 权…...

Kafka 深入服务端 — 时间轮
Kafka中存在大量的延迟操作,比如延时生产、延时拉取和延时删除等。Kafka基于时间轮概念自定义实现了一个用于延时功能的定时器,来完成这些延迟操作。 1 时间轮 Kafka没有使用基于JDK自带的Timer或DelayQueue来实现延迟功能,因为它们的插入和…...