将 OneLake 数据索引到 Elasticsearch - 第 1 部分
作者:来自 Elastic Gustavo Llermaly

学习配置 OneLake,使用 Python 消费数据并在 Elasticsearch 中索引文档,然后运行语义搜索。
OneLake 是一款工具,可让你连接到不同的 Microsoft 数据源,例如 Power BI、Data Activator 和 Data factory 等。它支持将数据集中在 DataLakes 中,DataLakes 是支持全面数据存储、分析和处理的大容量存储库。
在本文中,我们将学习如何配置 OneLake、使用 Python 消费数据以及在 Elasticsearch 中索引文档,然后运行语义搜索。
有时,你可能希望在非结构化数据和来自不同来源和软件提供商的结构化数据中运行搜索,并使用 Kibana 创建可视化。对于这种任务,在 Elasticsearch 中索引文档作为中央存储库会变得非常有用。
在这个例子中,我们将使用一家名为 Shoestic 的虚拟公司,这是一家在线鞋店。我们在结构化文件 (CSV) 中列出了产品列表,而一些产品的数据表则采用非结构化格式 (DOCX)。这些文件存储在 OneLake 中。
你可以在此处找到包含完整示例(包括测试文档)的笔记本。
步骤
- OneLake 初始配置
- 使用 Python 连接到 OneLake
- 索引文档
- 查询
OneLake 初始配置
OneLake 架构可以总结如下:

要使用 OneLake 和 Microsoft Fabric,我们需要一个 Office 365 帐户。如果你没有,可以在此处创建一个试用帐户。
使用你的帐户登录 Microsoft Fabric。然后,创建一个名为 “ShoesticWorkspace” 的工作区。进入新创建的工作区后,创建一个 Lakehouse 并将其命名为“ShoesticDatalake”。最后一步是在 “Files” 中创建一个新文件夹。单击 “new subfolder” 并将其命名为 “ProductsData”。

完成了!我们准备开始提取数据了。
使用 Python 连接到 OneLake
配置完 OneLake 后,我们现在可以准备 Python 脚本。Azure 有处理凭据并与 OneLake 通信的库。
pip install azure-identity elasticsearch==8.14 azure-storage-file-datalake azure-cli python-docx“azure-identity azure-storage-file-datalake” 库让我们可以与 OneLake 交互,同时 “azure-cli” 可以访问凭据并授予权限。为了读取文件内容以便稍后将其索引到 Elasticsearch,我们使用 python-docx。
在我们的本地环境中保存 Microsoft 凭据
我们将使用 “az login” 进入我们的 Microsoft 帐户并运行:
az login --allow-no-subscriptions标志 “ --allow-no-subscriptions”允许我们在没有有效订阅的情况下向 Microsoft Azure 进行身份验证。
此命令将打开一个浏览器窗口,你必须在其中访问你的帐户,然后选择你帐户的订阅号。

现在我们可以开始编写代码了!
创建一个名为 onelake.py 的文件并添加以下内容:
_onelake.py_
# Importing dependencies
import chardet
from azure.identity import DefaultAzureCredential
from docx import Document
from azure.storage.filedatalake import DataLakeServiceClient # Initializing the OneLake client
ONELAKE_ACCOUNT_NAME = "onelake"
ONELAKE_WORKSPACE_NAME = "ShoesticWorkspace"
# Path in format <DataLake>.Lakehouse/files/<Folder path>
ONELAKE_DATA_PATH = "shoesticDatalake.Lakehouse/Files/ProductsData" # Microsoft token
token_credential = DefaultAzureCredential() # OneLake services
service_client = DataLakeServiceClient( account_url=f"https://{ONELAKE_ACCOUNT_NAME}.dfs.fabric.microsoft.com", credential=token_credential,
)
file_system_client = service_client.get_file_system_client(ONELAKE_WORKSPACE_NAME)
directory_client = file_system_client.get_directory_client(ONELAKE_DATA_PATH) # OneLake functions # Upload a file to a LakeHouse directory
def upload_file_to_directory(directory_client, local_path, file_name): file_client = directory_client.get_file_client(file_name) with open(local_path, mode="rb") as data: file_client.upload_data(data, overwrite=True) print(f"File: {file_name} uploaded to the data lake.") # Get directory contents from your lake folder
def list_directory_contents(file_system_client, directory_name): paths = file_system_client.get_paths(path=directory_name) for path in paths: print(path.name + "\n") # Get a file by name from your lake folder
def get_file_by_name(file_name, directory_client): return directory_client.get_file_client(file_name) # Decode docx
def get_docx_content(file_client): download = file_client.download_file() file_content = download.readall() temp_file_path = "temp.docx" with open(temp_file_path, "wb") as temp_file: temp_file.write(file_content) doc = Document(temp_file_path) text = [] for paragraph in doc.paragraphs: text.append(paragraph.text) return "\n".join(text) # Decode csv
def get_csv_content(file_client): download = file_client.download_file() file_content = download.readall() result = chardet.detect(file_content) encoding = result["encoding"] return file_content.decode(encoding) 将文件上传到 OneLake
在此示例中,我们将使用一个 CSV 文件和一些包含有关我们鞋店产品信息的 .docx 文件。虽然你可以使用 UI 上传它们,但我们将使用 Python 来完成。在此处下载文件。
我们将文件放在文件夹 /data 中,位于名为 upload_files.py 的新 Python 脚本旁边:
# upload_files.py # Importing dependencies
from azure.identity import DefaultAzureCredential
from azure.storage.filedatalake import DataLakeServiceClient from functions import list_directory_contents, upload_file_to_directory
from onelake import ONELAKE_DATA_PATH, directory_client, file_system_client csv_file_name = "products.csv"
csv_local_path = f"./data/{csv_file_name}" docx_files = ["beach-flip-flops.docx", "classic-loafers.docx", "sport-sneakers.docx"]
docx_local_paths = [f"./data/{file_name}" for file_name in docx_files] # Upload files to Lakehouse
upload_file_to_directory(directory_client, csv_local_path, csv_file_name) for docx_local_path in docx_local_paths: docx_file_name = docx_local_path.split("/")[-1] upload_file_to_directory(directory_client, docx_local_path, docx_file_name) # To check that the files have been uploaded, run "list_directory_contents" function to show the contents of the /ProductsData folder in our Datalake:
print("Upload finished, Listing files: ")
list_directory_contents(file_system_client, ONELAKE_DATA_PATH) 运行上传脚本:
python upload_files.py结果应该是:
Upload finished, Listing files:
shoesticDatalake.Lakehouse/Files/ProductsData/beach-flip-flops.docx
shoesticDatalake.Lakehouse/Files/ProductsData/classic-loafers.docx
shoesticDatalake.Lakehouse/Files/ProductsData/products.csv
shoesticDatalake.Lakehouse/Files/ProductsData/sport-sneakers.docx 现在我们已经准备好文件了,让我们开始使用 Elasticsearch 分析和搜索我们的数据!
索引文档
我们将使用 ELSER 作为向量数据库的嵌入提供程序,以便我们可以运行语义查询。
我们选择 ELSER 是因为它针对 Elasticsearch 进行了优化,在域外检索方面胜过大多数竞争对手,这意味着按原样使用模型,而无需针对你自己的数据进行微调。
配置 ELSER
首先创建推理端点:
PUT _inference/sparse_embedding/onelake-inference-endpoint
{ "service": "elser", "service_settings": { "num_allocations": 1, "num_threads": 1 } 在后台加载模型时,如果你以前没有使用过 ELSER,则可能会收到 502 Bad Gateway 错误。在 Kibana 中,你可以在 “Machine Learning” > “Trained Models” 中检查模型状态。等到模型部署完成后再继续执行后续步骤。

索引数据
现在,由于我们同时拥有结构化数据和非结构化数据,因此我们将在 Kibana DevTools 控制台中使用具有不同映射的两个不同索引。
对于我们的结构化销售,让我们创建以下索引:
PUT shoestic-products
{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "product_name": { "type": "text" }, "amount": { "type": "float" }, "tags": { "type": "keyword" } } }
} 为了索引我们的非结构化数据(产品数据表),我们将使用:
PUT shoestic-products-descriptions
{ "mappings": { "properties": { "title": { "type": "text", "analyzer": "english" }, "super_body": { "type": "semantic_text", "inference_id": "onelake-inference-endpoint" }, "body": { "type": "text", "copy_to": "super_body" } } }
} 注意:使用带有 copy_to 的字段很重要,这样还可以运行全文搜索,而不仅仅是在正文字段上运行语义搜索。
读取 OneLake 文件
在开始之前,我们需要使用这些命令(使用你自己的云 ID 和 API 密钥)初始化我们的 Elasticsearch 客户端。
创建一个名为 indexing.py 的 Python 脚本并添加以下几行:
# Importing dependencies
import csv
from io import StringIO from onelake import directory_client
from elasticsearch import Elasticsearch, helpers from functions import get_csv_content, get_docx_content, get_file_by_name
from upload_files_to_onelake import csv_file_client ELASTIC_CLUSTER_ID = "your-cloud-id"
ELASTIC_API_KEY = "your-api-key" # Elasticsearch client
es_client = Elasticsearch( cloud_id=ELASTIC_CLUSTER_ID, api_key=ELASTIC_API_KEY,
) docx_files = ["beach-flip-flops.docx", "classic-loafers.docx", "sport-sneakers.docx"]
docx_local_paths = [f"./data/{file_name}" for file_name in docx_files] csv_file_client = get_file_by_name("products.csv", directory_client)
docx_files_clients = [] for docx_file_name in docx_files: docx_files_clients.append(get_file_by_name(docx_file_name, directory_client)) # We use these functions to extract data from the files:
csv_content = get_csv_content(csv_file_client)
reader = csv.DictReader(StringIO(csv_content))
docx_contents = [] for docx_file_client in docx_files_clients: docx_contents.append(get_docx_content(docx_file_client)) print("CSV FILE CONTENT: ", csv_content)
print("DOCX FILE CONTENT: ", docx_contents) # The CSV tags are separated by commas (,). We'll turn these tags into an array:
rows = csv_content.splitlines()
reader = csv.DictReader(rows)
modified_rows = [] for row in reader: row["tags"] = row["tags"].replace('"', "").split(",") modified_rows.append(row) print(row["tags"]) # We can now index the files into Elasticsearch
reader = modified_rows
csv_actions = [{"_index": "shoestic-products", "_source": row} for row in reader] docx_actions = [ { "_index": "shoestic-products-descriptions", "_source": {"title": docx_file_name, "body": docx}, } for docx_file_name, docx in zip(docx_files, docx_contents)
] helpers.bulk(es_client, csv_actions)
print("CSV data indexed successfully.")
helpers.bulk(es_client, docx_actions)
print("DOCX data indexed successfully.") 现在运行脚本:
python indexing.py查询
在 Elasticsearch 中对文档进行索引后,我们就可以测试语义查询了。在本例中,我们将在某些产品(tag)中搜索唯一术语。我们将针对结构化数据运行关键字搜索,针对非结构化数据运行语义搜索。
1. 关键字搜索
GET shoestic-products/_search
{ "query": { "term": { "tags": "summer" } }
} 结果:
"_source": { "product_id": "P-118", "product_name": "Casual Sandals", "amount": "128.22", "tags": [ "casual", "summer" ] } 2. 语义搜索:
GET shoestic-products-descriptions/_search
{ "_source": { "excludes": [ "*embeddings", "*chunks" ] }, "query": { "semantic": { "field": "super_body", "query": "summer" } }
} *我们排除了嵌入和块只是为了便于阅读。
结果:
"hits": { "total": { "value": 3, "relation": "eq" }, "max_score": 4.3853106, "hits": [ { "_index": "shoestic-products-descriptions", "_id": "P2Hj6JIBF7lnCNFTDQEA", "_score": 4.3853106, "_source": { "super_body": { "inference": { "inference_id": "onelake-inference-endpoint", "model_settings": { "task_type": "sparse_embedding" } } }, "title": "beach-flip-flops.docx", "body": "Ideal for warm, sunny days by the water, these lightweight essentials are water-resistant and come in bright colors, bringing a laid-back vibe to any outing in the sun." } } ] } 如你所见,当使用关键字搜索时,我们会得到与其中一个标签的完全匹配,相反,当我们使用语义搜索时,我们会得到与描述中的含义匹配的结果,而无需完全匹配。
结论
OneLake 使使用来自不同 Microsoft 来源的数据变得更容易,然后索引这些文档 Elasticsearch 允许我们使用高级搜索工具。在第一部分中,我们学习了如何连接到 OneLake 并在 Elasticsearch 中索引文档。在第二部分中,我们将使用 Elastic 连接器框架制作更强大的解决方案。敬请期待!
想要获得 Elastic 认证?了解下一次 Elasticsearch 工程师培训的时间!
Elasticsearch 包含许多新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在你的本地机器上试用 Elastic。
原文:Indexing OneLake data into Elasticsearch - Part 1 - Elasticsearch Labs
相关文章:
将 OneLake 数据索引到 Elasticsearch - 第 1 部分
作者:来自 Elastic Gustavo Llermaly 学习配置 OneLake,使用 Python 消费数据并在 Elasticsearch 中索引文档,然后运行语义搜索。 OneLake 是一款工具,可让你连接到不同的 Microsoft 数据源,例如 Power BI、Data Activ…...

Spring Boot多环境配置实践指南
在开发Spring Boot应用时,我们常常需要根据不同的运行环境(如开发环境、测试环境和生产环境)来配置不同的参数。Spring Boot提供了非常灵活的多环境配置机制,通过使用profile-specific properties文件,我们可以轻松地管…...

C++11中array容器的常见用法
文章目录 一、概述二、std::array的特点三、std::array的定义与初始化三、std::array的常用成员函数四、与 C 风格数组的互操作 一、概述 在 C11 中,std::array 是一个新的容器类型,它提供了一个固定大小的数组封装。相比传统的 C 风格数组,…...

NFTs 是网络艺术,而非数字艺术
传统艺术界对 NFTs 的误解 传统艺术界(包括博物馆、策展人等)常常认为: “我们收藏和策展数字艺术已经数十年了。我们非常了解这个领域。或许少数 NFT 可以被视为优秀的数字艺术,但更多的只是糟糕的数字艺术,甚至根本称…...

澳洲硕士毕业论文写作中如何把握主题
每到毕业季时,澳洲硕士毕业论文写作是留学生学业的头等大事。但是经常有留学生在澳洲毕业论文写作过程中会遇到写了一半,但是不知道应该如何继续下去的问题。有时候是在literature review的部分就越写越觉得偏离了方向,有时候是在数据收集阶段…...

SQL server 数据库使用整理
标题:SQL server 数据库使用整理 1.字符串表名多次查询 2.读取SQL中Json字段中的值:JSON_VALUE(最新版本支持,属性名大小写敏感) 1.字符串表名多次查询 SELECT ROW_NUMBER() OVER (ORDER BY value ASC) rowid,value…...

在Windows系统中本地部署属于自己的大语言模型(Ollama + open-webui + deepseek-r1)
文章目录 1 在Windows系统中安装Ollama,并成功启动;2 非docker方式安装open-webui3下载并部署模型deepseek-r1 Ollama Ollama 是一个命令行工具,用于管理和运行机器学习模型。它简化了模型的下载与部署,支持跨平台使用,…...

nosql mysql的区别
NoSQL 和 MySQL 是两种不同类型的数据库管理系统,它们在设计理念、数据模型、可扩展性和应用场景等方面有着本质的区别。 NoSQL 数据库 特点: 灵活的数据模型: NoSQL 数据库通常没有固定的表结构,可以很容易地存储不同结构的文档或键值对。水平扩展: …...

DeepSeek辅助学术写作摘要内容
学术摘要写作 摘要是文章的精华,通常在200-250词左右。要包括研究的目的、方法、结果和结论。让AI工具作为某领域内资深的研究专家,编写摘要需要言简意赅,直接概括论文的核心,为读者提供快速了解的窗口。 下面我们使用DeepSeek编…...

网络工程师 (5)系统可靠性
前言 系统可靠性是指系统在规定的条件和规定的时间内,完成规定功能的能力。这种能力不仅涵盖了系统本身的稳定性和耐久性,还涉及了系统在面对各种内外部干扰和故障时的恢复能力和容错性。系统可靠性是评价一个系统性能优劣的关键指标之一,对于…...

Swoole的MySQL连接池实现
在Swoole中实现MySQL连接池可以提高数据库连接的复用率,减少频繁创建和销毁连接所带来的开销。以下是一个简单的Swoole MySQL连接池的实现示例: 首先,确保你已经安装了Swoole扩展和PDO_MySQL扩展(或mysqli,但在这个示…...

RoboVLM——通用机器人策略的VLA设计哲学:如何选择骨干网络、如何构建VLA架构、何时添加跨本体数据
前言 本博客内解读不少VLA模型了,包括π0等,且如此文的开头所说 前两天又重点看了下openvla,和cogact,发现 目前cogACT把openvla的动作预测换成了dit,在模型架构层面上,逼近了π0那为了进一步逼近&#…...

Vue.js 配合 Vue Router 使用 Vuex
Vue.js 配合 Vue Router 使用 Vuex 今天我们来聊聊如何将 Vue Router 和 Vuex 结合使用,以实现更高效的状态和路由管理。在大型 Vue.js 应用中,Vue Router 负责路由管理,Vuex 负责状态管理。将两者结合,可以实现如权限控制、动态…...

【Django教程】用户管理系统
Get Started With Django User Management 开始使用Django用户管理 By the end of this tutorial, you’ll understand that: 在本教程结束时,您将了解: Django’s user authentication is a built-in authentication system that comes with pre-conf…...

2024年终总结——今年是蜕变的一年
2024年终总结 摘要前因转折找工作工作的成长人生的意义 摘要 2024我从国企出来,兜兜转转还是去了北京,一边是工资低、感情受挫,一边是压力大、项目经历少,让我一度找不到自己梦寐以求的工作,我投了一家又一家ÿ…...
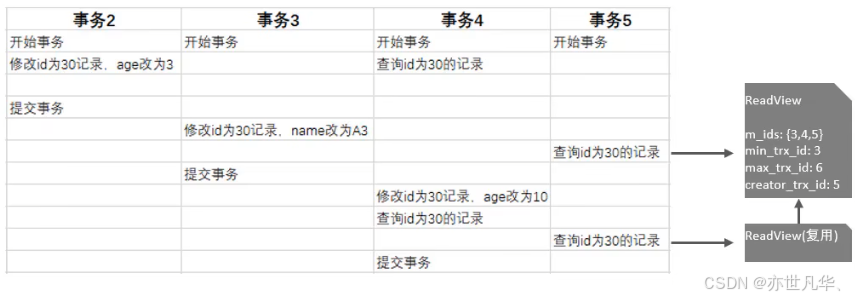
MySQL--》深度解析InnoDB引擎的存储与事务机制
目录 InnoDB架构 事务原理 MVCC InnoDB架构 从MySQL5.5版本开始默认使用InnoDB存储引擎,它擅长进行事务处理,具有崩溃恢复的特性,在日常开发中使用非常广泛,其逻辑存储结构图如下所示, 下面是InnoDB架构图…...

SpringCloudAlibaba 服务保护 Sentinel 项目集成实践
目录 一、简介1.1、服务保护的基本概念1.1.1、服务限流/熔断1.1.2、服务降级1.1.3、服务的雪崩效应1.1.4、服务的隔离的机制 1.2、Sentinel的主要特性1.3、Sentinel整体架构1.4、Sentinel 与 Hystrix 对比 二、Sentinel控制台部署3.1、版本选择和适配3.2、本文使用各组件版本3.…...

c++面试:类定义为什么可以放到头文件中
这个问题是刚了解预编译的时候产生的疑惑。 声明是指向编译器告知某个变量、函数或类的存在及其类型,但并不分配实际的存储空间。声明的主要目的是让编译器知道如何解析程序中的符号引用。定义不仅告诉编译器实体的存在,还会为该实体分配存储空间&#…...

DeepSeek理解概率的能力
问题: 下一个问题是概率问题。乘车时有一个人带刀子的概率是百分之一,两个人同时带刀子的概率是万分之一。有人认为如果他乘车时带上刀子,那么还有其他人带刀子的概率就是万分之一,他乘车就会安全得多。他的想法对吗?…...

STM32 GPIO配置 点亮LED灯
本次是基于STM32F407ZET6做一个GPIO配置,实现点灯实验。 新建文件 LED.c、LED.h文件,将其封装到Driver文件中。 双击Driver文件将LED.c添加进来 编写头文件,这里注意需要将Driver头文件声明一下。 在LED.c、main.c里面引入头文件LED.h LED初…...

模板泛化类如何卸载释放内存
CustomWidget::~CustomWidget() {for (size_t i 0; i < buttonManager.registerItem.size(); i) {delete buttonManager.registerItem(exitButton);} } 以上该怎么写删除对象操作,类如下:template <typename T> class GenericManager { public…...

MFC结构体数据文件读写实例
程序功能将结构体内数组数据写入文件和读出 2Dlg.h中代码: typedef struct Student {int nNum[1000];float fScore;CString sss;}stu; class CMy2Dlg : public CDialog { // Construction public:CMy2Dlg(CWnd* pParent NULL); // standard constructorstu stu1; ... } 2Dl…...

jemalloc 5.3.0的tsd模块的源码分析
一、背景 在主流的内存库里,jemalloc作为android 5.0-android 10.0的默认分配器肯定占用了非常重要的一席之地。jemalloc的低版本和高版本之间的差异特别大,低版本的诸多网上整理的总结,无论是在概念上和还是在结构体命名上在新版本中很多都…...

03-机器学习-数据获取
一、流行机器学习数据集 主流机器学习数据集汇总 数据集名称描述来源MNIST手写数字图像数据集,由美国人口普查局员工书写。MNIST官网ImageNet包含数百万张图像,用于图像分类和目标检测。ImageNet官网AudioSet包含YouTube音频片段,用于声音分…...

编程题-最长的回文子串(中等)
题目: 给你一个字符串 s,找到 s 中最长的回文子串。 示例 1: 输入:s "babad" 输出:"bab" 解释:"aba" 同样是符合题意的答案。示例 2: 输入:s &…...

爱书爱考平台说明
最近我开发了一个综合性的考试平台,内容包括但不限于职业资格证考试、成人教育、国家公务员考试等内容。目前1.0版本已经开发完成,其他的功能陆续完善中。 微信小程序搜索"爱书爱考" 微信小程序图标如下图: 目前维护了java相关的面试题的考题…...

doris: MAP数据类型
MAP<K, V> 表示由K, V类型元素组成的 map,不能作为 key 列使用。 目前支持在 Duplicate,Unique 模型的表中使用。 K, V 支持的类型有: BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, FLOAT, DOUBLE, DECIMAL, DECIMALV3, DAT…...

JUC--ConcurrentHashMap底层原理
ConcurrentHashMap底层原理 ConcurrentHashMapJDK1.7底层结构线程安全底层具体实现 JDK1.8底层结构线程安全底层具体实现 总结JDK 1.7 和 JDK 1.8实现有什么不同?ConcurrentHashMap 中的 CAS 应用 ConcurrentHashMap ConcurrentHashMap 是一种线程安全的高效Map集合…...

Sklearn 中的逻辑回归
逻辑回归的数学模型 基本模型 逻辑回归主要用于处理二分类问题。二分类问题对于模型的输出包含 0 和 1,是一个不连续的值。分类问题的结果一般不能由线性函数求出。这里就需要一个特别的函数来求解,这里引入一个新的函数 Sigmoid 函数,也成…...

Spring Boot 自定义属性
Spring Boot 自定义属性 在 Spring Boot 应用程序中,application.yml 是一个常用的配置文件格式。它允许我们以层次化的方式组织配置信息,并且比传统的 .properties 文件更加直观。 本文将介绍如何在 Spring Boot 中读取和使用 application.yml 中的配…...