Django基础之ORM
一.前言
上一节简单的讲了一下orm,主要还是做个了解,这一节将和大家介绍更加细致的orm,以及他们的用法,到最后再和大家说一下cookie和session,就结束了全部的django基础部分
二.orm的基本操作
1.settings.py,连接数据库

2.settings.py,注册app

3.各app下面的models.py 编写models.类
class UserInfo(models.Model):
.....
.....
4.执行命令
python manage.py makemigrations # 找到所有已注册的app中的models.py中的类读取 -> migrations配置
python manage.py migrate # 读取已注册的app下的migrations配置 -> SQL语句 -> 同步数据库
三.连接数据库
我们django支持各种类型的数据库,例如mysql,sqlite3(默认的)等等,我们连接不同的数据库需要的是改settings.py下面的DATABASES
1.连接django默认自带的sqlite3
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}
2.连接mysql
-
安装MySQL & 启动MySQL服务
-
手动创建数据库
-
django的settings.py配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'xxxxxxxx', # 数据库名字
'USER': 'root',
'PASSWORD': 'root123', #数据库密码
'HOST': '127.0.0.1', # ip
'PORT': 3306,
}
}
安装第三方组件(两个选一个,推荐安装pymysql)
-
pymysql
pip install pymysql
项目根目录/项目名目录/__init__.pyimport pymysqlpymysql.install_as_MySQLdb()
-
mysqlclient
pip install mysqlclient
电脑上先提前安装MySQL。
四.连接池
django默认内置没有数据库连接池 ,所以我们要使用第三方的。
pip install django-db-connection-pool
DATABASES = {
"default": {
'ENGINE': 'dj_db_conn_pool.backends.mysql',
'NAME': 'day04', # 数据库名字
'USER': 'root',
'PASSWORD': 'root123',
'HOST': '127.0.0.1', # ip
'PORT': 3306,
'POOL_OPTIONS': {
'POOL_SIZE': 10, # 最小
'MAX_OVERFLOW': 10, # 在最小的基础上,还可以增加10个,即:最大20个。
'RECYCLE': 24 * 60 * 60, # 连接可以被重复用多久,超过会重新创建,-1表示永久。
'TIMEOUT':30, # 池中没有连接最多等待的时间。
}
}
}
五.多数据库
多数据库我们平时都用不上,只有在后续开发大项目时才能用得上,大家做个了解就好
DATABASES = {
"default": {
'ENGINE': 'dj_db_conn_pool.backends.mysql',
'NAME': 'day05db', # 数据库名字
'USER': 'root',
'PASSWORD': 'root123',
'HOST': '127.0.0.1', # ip
'PORT': 3306,
'POOL_OPTIONS': {
'POOL_SIZE': 10, # 最小
'MAX_OVERFLOW': 10, # 在最小的基础上,还可以增加10个,即:最大20个。
'RECYCLE': 24 * 60 * 60, # 连接可以被重复用多久,超过会重新创建,-1表示永久。
'TIMEOUT': 30, # 池中没有连接最多等待的时间。
}
},
"bak": {
'ENGINE': 'dj_db_conn_pool.backends.mysql',
'NAME': 'day05bak', # 数据库名字
'USER': 'root',
'PASSWORD': 'root123',
'HOST': '127.0.0.1', # ip
'PORT': 3306,
'POOL_OPTIONS': {
'POOL_SIZE': 10, # 最小
'MAX_OVERFLOW': 10, # 在最小的基础上,还可以增加10个,即:最大20个。
'RECYCLE': 24 * 60 * 60, # 连接可以被重复用多久,超过会重新创建,-1表示永久。
'TIMEOUT': 30, # 池中没有连接最多等待的时间。
}
},
}
5.1 读写分离
我们有时候会进行读写分离,这个就需要用到多数据库,我们配置如下
192.168.1.2 default master [写]
组件
192.168.2.12 bak slave [读]
生成数据库表
python manage.py makemigrations # 找到所有已注册的app中的models.py中的类读取 -> migrations配置
python manage.py migrate
python manage.py migrate --database=default
python manage.py migrate --database=bak
后续再进行开发时
models.UserInfo.objects.using("default").create(title="外交部")
models.UserInfo.objects.using("bak").all()
我们通过using来选择配置的数据库

我们这里看不见数据是因为读取的数据库我们没有做同步的组件
我们发现我们这样读写分离时每次都要选择指定的数据库,这样很难整,我们可以手动编写router类,让我们每次不需要指定就能知道
编写router类:(两个函数必须叫这个名字)
class DemoRouter(object):def db_for_read(self,model,**hints):return 'settings下面DATABASES的键'def db_for_write(self,model,**hints):return 'settings下面DATABASES的键'

然后我们在settings里面配置一下
DATABASE_ROUTERS=['utils.router.DemoRouter']
这样就是基本的router,然后我们还可以进行更细致的判断

我们说两个常用的对象
model._meta.app_label #app的名字 model._meta.model_name #modelss的名字(全小写)也就是表名
我们也可以基于这个来判断用哪个表
5.2 分库(多app)
也叫多app对应多个数据库

如图我们两个app里有两个model,我们想吧一个app的放在default数据库,另一个app的放在bak数据库,这个时候我们提交的命令就要改,然后就借助我们前面说的router进行判断以此来选择数据库
python manage.py makemigrations
python manage.py migrate 第一个app名字 --database=default
python manage.py migrate 第二个app名字 --database=bak
.......
提交好后我们就来开始编辑router

我们现在就通过了一个简单的if判断实现了不同app选择不同数据库的需求了
5.3 分库(单app)
在一个app中,我们想把多个模型拆分到不同的数据库中就需要,但是此时我们使用命令是无法完成的,我们就需要借助router来编写了

例如这个,我们想把第一张表放在default里面,下面两张表放在bak里面
def allow_migrate(self,db,app_label,model_name=None,**hints):'''执行这个命令的时候python manage.py migrate app名字 --database=defaultapp_label=app名字db=defaultmodel_name 就是models里面的名字(全小写)通过return True 和False判断是否生成'''pass
我们同样还是先执行python manage.py makemigrations

我们编写好后执行
python manage.py migrate web --database=default
migrate web --database=bak
注意:当我们--database=bak 一定要加上app名字 不然会不成功
六.表关系
这个我们在上一节已经给大家介绍过了(具体的比如参数我就不介绍,这里就直接放代码
一对多:
from django.db import modelsclass Depart(models.Model):title=models.CharField(verbose_name='标题',max_length=32,unique=True)class UserInfo(models.Model):name=models.CharField(verbose_name='姓名',max_length=32,db_index=True)dp=models.ForeignKey(to='Depart',on_delete=models.CASCADE)class Meta:db_table='depart'这个最后的class Meta下面的db_table='depart'的意思是让在数据库创建的表名为depart,入过不设置的话就是app名字_类名的小写,我们一般都不会设置,因为这样可以避免表名冲突,这里也是给大家引个介绍
多对多:
from django.db import models
class Boy(models.Model):name = models.CharField(verbose_name='姓名', max_length=32)class Girl(models.Model):name = models.CharField(verbose_name='姓名', max_length=32)class B2G(models.Model):bid=models.ForeignKey(to='Boy',on_delete=models.CASCADE)gid=models.ForeignKey(to='Girl',on_delete=models.CASCADE)这里我们就不用ManyToManyField这个字段了,上一节也说了
一对一:
这个是上一节没和大家介绍的,当然肯定有人要问,一对一有啥好用的,为什么不创建一张表呢,但是大家想一想,在有的特殊的场景里面,就拿CSDN来说,我们是不是注册需要名称和密码,但是此时此刻我们还没有开通博客专区,如果我们要开通博客专区,是不是又得创建一张博客表,里面存放我们博客的地址和简介页面,这个时候就会用到一对一
from django.db import models
class UserInfo(models.Model):name=models.CharField(verbose_name='姓名',max_length=32,db_index=True)dp=models.ForeignKey(to='Depart',on_delete=models.CASCADE)class Blog(models.Model):user=models.OneToOneField(to='UserInfo',on_delete=models.CASCADE)blog=models.CharField(verbose_name='博客地址',max_length=128)summery=models.CharField(verbose_name='简介',max_length=255)七.数据操作
7.1 单表数据操作
以这个数据库为例:
class Role(models.Model):title=models.CharField(verbose_name='标题',max_length=32)od=models.IntegerField(verbose_name='排序',default=0)
1.创建:
obj1 = models.Role.objects.create(title="管理员", od=1)
obj2 = models.Role.objects.create(**{"title": "管理员", "od": 1})
#通过以上两种直接创建,数据多用下面的那种,数据少用上面的那种,记住下面的字典前面一定要加上**obj = models.Role(title="客户", od=1)
obj.od = 100
obj.save()obj = models.Role(**{"title": "管理员", "od": 1})
obj.od = 100
obj.save()
#这种是先创建对象,放在内存里面,创建完的对象可以修改值,然后.save()就可以提交到数据库
2.删除:
删除很简单,理论上就是先查找再删除,只要记住找到对象然后再.delete()
models.Role.objects.all().delete() models.Role.objects.filter(title="管理员").delete() #第一个是查找全部的对象,第二个filter里面是跟着各种条件,找到以后delete()就行了,他们的返回值是受影响的行数
3.更新
更新和删除的原理都一样,只要记得找到对象然后再update(数据)
models.Role.objects.all().update(od=99)
models.Role.objects.filter(id=7).update(od=99, title="管理员")
models.Role.objects.filter(id=7).update(**{"od": 99, "title": "管理员"})
4.查找
我们前面删除和更新其实都用到查询了,大家可以发现查询可以查询全部也可以筛选完查询,查询得到的结果类型是QuerySet,里面套着obj类型,很像列表但是不是,我们可以for循环得到里面的每个元素,并且查询得到得返回值还可以.query得到他原本查询得命令
v1 = models.Role.objects.all()
for obj in v1:print(obj, obj.id, obj.title, obj.od)v2 = models.Role.objects.filter(**{"od": 99, "id": 99}) #和前面一样支持两种
for obj in v2:print(obj, obj.id, obj.title, obj.od)v3 = models.Role.objects.filter(id=99)
print(v3.query)v3 = models.Role.objects.filter(id__gt=2)
print(v3.query)v3 = models.Role.objects.filter(id__gte=2)
print(v3.query)v3 = models.Role.objects.filter(id__lt=2)
print(v3.query)v3 = models.Role.objects.filter(id__in=[11, 22, 33])
print(v3.query)v3 = models.Role.objects.filter(title__contains="户")
print(v3.query)v3 = models.Role.objects.filter(title__startswith="户")
print(v3.query)v3 = models.Role.objects.filter(title__isnull=True)
print(v3.query)# 不等于
v3 = models.Role.objects.exclude(id=99)
print(v3.query)#不等于完还能再筛选
v3 = models.Role.objects.exclude(id=99).filter(od=88)
print(v3.query)

大家执行一下然后再看query语句就知道了,我在这里总结一下
全部用.all(),筛选让条件满足用.filter(id=99),筛选让条件取反.exclude(id=99)
__gt= 大于
__gte= 大于等于
__lt= 小于
__lte= 小于等于
__in=[11, 22, 33] 在这个里面
__contains=“户” 包含这个
__startswith="户" 以户开头
__isnull=True 为空
我们上面说的都是QuerySet里面套着obj,但是接下来会讲一些有用的
v4 = models.Role.objects.filter(id__gt=0).values("id", 'title')
print(v4)
v4 = models.Role.objects.filter(id__gt=0).values_list("id", 'title')
print(v4)
v4=models.Role.objects.all().first()
print(v4)
v4 = models.Role.objects.filter(id__gt=0).values("id", 'title').first()
print(v4)
v4 = models.Role.objects.filter(id__gt=10).exists() #判断这个对象是否存在 返回True或者False
print(v4)
# asc
v8 = models.Role.objects.filter(id__gt=0).order_by("id")
print(v8)
# id desc od asc
v9 = models.Role.objects.filter(id__gt=0).order_by("-id", 'od')
print(v9)

我们所有的都总结一下就是,通过.filter()和.all()拿到的数据就是QuerySet[obj,obj,obj]这种类型的数据。
如果我们想要改变里面的数据类型就可以再在后面加上.value()和.values_list(),不过这里就要加上子弹名字,分别以这些字段构成的字典和元组,只要类型是QuerySet,我们既可以通过.first()拿到QuerySet的第一个元素(无论是对象,字典,元组)。
如果我们想判断QuerySet是否不为空就用.exists()。
如果我们想对拿到的QuerySet里面的元素(无论是对象,字典,元组)进行排序就用.order_by(),里面的参数就是字段名,这就是想升序,字段名前面加了个-就是降序,如果有多个值就是以第一个值为准,如果第一个值一样就按照第二个的来排,理解这些是不是对这些参数运用熟悉多了,所以学习这些还是得先学会数据类型。
7.2 一对多数据操作
class Depart(models.Model):title=models.CharField(verbose_name='标题',max_length=32,unique=True)class UserInfo(models.Model):name=models.CharField(verbose_name='姓名',max_length=32,db_index=True)dp=models.ForeignKey(to='Depart',on_delete=models.CASCADE)
我们一对多以这个数据库为例,当然有很多都是和单表操作是重复的,我这里只和大家说不是重复的部分,也不会和上面讲的那么细
1.创建
models.UserInfo.objects.create(name='往日情怀酿作酒',dp_id=1)obj=models.Depart.objects.filter(id=2).first() models.UserInfo.objects.create(name='往日情怀酿作酒',dp=obj) models.UserInfo.objects.create(name='往日情怀酿作酒',dp_id=obj.id)
这里在我们创建ForeignKey关联字段的时候,他在表中的名字会加上_关联字段名字(因为我们上面没有指定to_field,所以默认指定到了id),我们也可以直接用字段,但是后面=的参数就要是个对象了
2.更新
这里我就给大家介绍一个需要注意的点,我们可以通过ForeignKey__标题来实现跨表操作,但是我们更新只能本表数据
models.UserInfo.objects.filter(name="往日情怀酿作酒").update(dp_id=2)#这个是没有问题的 models.UserInfo.objects.filter(id=2).update(dp__title="销售部")#这样是不行的,不能删跨表更改
3.查找
这里不和大家说删除了,是因为主要就是查找,和前面没什么区别,介绍创建主要是为了和大家说一下ForeignKey关联的字段
v1=models.UserInfo.objects.all()
for obj in v1: #但是如果要跨表也就是加上__字段我们通常不会用这个,因为这个效率太差了print(obj.name,obj.id,obj.dp_id) #我们可以通过ForeignKey字段名__另一张表名来跨表v2=models.UserInfo.objects.all().select_related("dp")
for obj in v2: #加上.select_related("depart")相当于把两张表给连起来了,效率就会高很多print(obj.name,obj.id,obj.dp_id)v3=models.UserInfo.objects.all().values('id','name','dp__title')
print(v3)v3 = models.UserInfo.objects.all().values_list('id', 'name', 'dp__title')
print(v3)
我们可以通过ForeignKey字段__来找到跨表的数据,这个是需要关注的
4.重点(容易犯毛病)
#正向操纵
# 我们可以通过ForeignKey进行跨表,这个是没有问题的
v1=models.UserInfo.objects.all().values('id','name','dp_id','dp__title')
print(v1)#反向操作
#django里面会默认把我们用ForeignKey关联的表也可以通过__来连接起来
#例如这个关联了userinfo,那么userinfo也就是代表这个表关联字段的id,userinfo__name代表跨的表名
v2=models.Depart.objects.all().values('id','title','userinfo','userinfo__name')
print(v2)
但是我们假设一下,如果用户表里面有两个ForeignKey,那么他这个表名到底是关联的哪一个ForeignKey字段的id呢?那我们先来更新一下表

我们按照我们需求创建一个新部门new_dp,也是ForeignKey关联的,但是当我们更新表的时候,他会提示报错,这是因为django关联表的时候已经想到反向关联表会出现冲突,这个时候我们就要加上related_name用来做为反向关联的
class UserInfo(models.Model):name=models.CharField(verbose_name='姓名',max_length=32,db_index=True)dp=models.ForeignKey(to='Depart',on_delete=models.CASCADE,related_name='dp1')new_dp=models.ForeignKey(to='Depart',on_delete=models.CASCADE,related_name='dp2',default=1)
related_name就是当多个ForeignKey关联同一个表时要加上的,到时候我们反向关联就不能用表名了,而是要用related_name

7.3 多对多数据操作
class Boy(models.Model):name = models.CharField(verbose_name='姓名', max_length=32)class Girl(models.Model):name = models.CharField(verbose_name='姓名', max_length=32)class B2G(models.Model):bid=models.ForeignKey(to='Boy',on_delete=models.CASCADE)gid=models.ForeignKey(to='Girl',on_delete=models.CASCADE)adress=models.CharField(verbose_name='约会地点',max_length=32,default='北京中路八号ma')
1.创建
models.Boy.objects.create(name="宝强") models.Boy.objects.create(name="羽凡") models.Boy.objects.create(name="乃亮")models.Girl.objects.bulk_create(objs=[models.Girl(name="小路"), models.Girl(name="百合"), models.Girl(name="马蓉")],batch_size=3 )models.B2G.objects.create(bid_id=1, gid_id=3, adress="北京") models.B2G.objects.create(bid_id=1, gid_id=2, adress="上海") models.B2G.objects.create(bid_id=2, gid_id=2, adress="芜湖") models.B2G.objects.create(bid_id=2, gid_id=1, adress="安庆")
这里都一样,但是补前面没说的知识点就是批量创建, 用.bulk_create,参数是objs=[],里面是models.表名,不用加上objects,batch_size就是一次提交几个,如果数据多于batch_size那么就第二次创建
2.查找
# 1.宝强都与谁约会。
q = models.B2G.objects.filter(bid__name='宝强').select_related("gid")
for item in q:print(item.id, item.adress, item.bid.name, item.gid.name)# 2.百合 都与谁约会。
q = models.B2G.objects.filter(gid__name='百合').values("id", 'bid__name', 'gid__name')
for item in q:print(item['id'], item['bid__name'], item['gid__name'])
这个没啥特殊的,就举几个例子和大家看看
7.4 一对一数据操作
一对多大家都会,一对一怎么可能会不会呢?我就不多写了,难打字!
八.cookie和session
8.1 cookie
cookie前面都给大家介绍过了,这里来说一些用到的重要参数
def show(request):res=HttpResponse("返回")res.set_cookie("name",'Mr.7',max_age=100,path='/',domain='www.yy.com',secure=False,httponly=True)return resmax_age:cookie存活时间
path:哪些路径会携带这个cookie
domain:哪些域名会携带这个cookie
secure:是否只在https下携带
httponly:只允许请求使用cookie,这些参数不写也可以

这里要注意一下就是当我们用到域名的时候要在这里加上,通常使用*
8.2 session
session我们通常都是和cookie一起,这样比较方便

用到session我们的这个中间件一定要打开
文件配置:
SESSION_ENGINE = 'django.contrib.sessions.backends.file' SESSION_FILE_PATH = 'session' SESSION_COOKIE_NAME = "sid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串 SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径 SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名 SESSION_COOKIE_SECURE = False # 是否Https传输cookie SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输 SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周)SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期 SESSION_SAVE_EVERY_REQUEST = True # 是否每次请求都保存Session,默认修改之后才保存
数据库配置:

我们要把这个session的app给打开,并且重新执行makemigrations和migrate让他重新生成session的数据库
# session
SESSION_ENGINE = 'django.contrib.sessions.backends.db'SESSION_COOKIE_NAME = "sid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串
SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径
SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名
SESSION_COOKIE_SECURE = False # 是否Https传输cookie
SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输
SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周)SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期
SESSION_SAVE_EVERY_REQUEST = True # 是否每次请求都保存Session,默认修改之后才保存
缓存版:
我们首先要创建缓存,这里介绍用redis,首先要安装模块
pip install django-redis
再在settings.py里面创建 CACHES
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100}
# "PASSWORD": "密码",
}
}
}
# session
SESSION_ENGINE = 'django.contrib.sessions.backends.cache'
SESSION_CACHE_ALIAS = 'default'SESSION_COOKIE_NAME = "sid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串
SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径
SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名
SESSION_COOKIE_SECURE = False # 是否Https传输cookie
SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输
SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周)SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期
SESSION_SAVE_EVERY_REQUEST = True # 是否每次请求都保存Session,默认修改之后才保存
九.总结
今天的内容有很多,主要就是麻烦,大家后期肯定会大量的用到,毕竟是最重要的,所以内容多也很正常,我感觉主要还是得先理解数据类型,这样就会更好理解
十.补充
下一期将和大家开始讲项目,期待大家的点赞关注加收藏
相关文章:
Django基础之ORM
一.前言 上一节简单的讲了一下orm,主要还是做个了解,这一节将和大家介绍更加细致的orm,以及他们的用法,到最后再和大家说一下cookie和session,就结束了全部的django基础部分 二.orm的基本操作 1.settings.py&#x…...

大模型知识蒸馏技术(2)——蒸馏技术发展简史
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl2006年模型压缩研究 知识蒸馏的早期思想可以追溯到2006年,当时Geoffrey Hinton等人在模型压缩领域进行了开创性研究。尽管当时深度学习尚未像今天这样广泛普及,但Hinton的研究已经为知识迁移和模…...

android获取EditText内容,TextWatcher按条件触发
android获取EditText内容,TextWatcher按条件触发 背景:解决方案:效果: 背景: 最近在尝试用原生安卓实现仿element-ui表单校验功能,其中涉及到EditText组件内容的动态校验,初步实现功能后&#…...

毕业设计--具有车流量检测功能的智能交通灯设计
摘要: 随着21世纪机动车保有量的持续增加,城市交通拥堵已成为一个日益严重的问题。传统的固定绿灯时长方案导致了大量的时间浪费和交通拥堵。为解决这一问题,本文设计了一款智能交通灯系统,利用车流量检测功能和先进的算法实现了…...

[权限提升] 操作系统权限介绍
关注这个专栏的其他相关笔记:[内网安全] 内网渗透 - 学习手册-CSDN博客 权限提升简称提权,顾名思义就是提升自己在目标系统中的权限。现在的操作系统都是多用户操作系统,用户之间都有权限控制,我们通过 Web 漏洞拿到的 Web 进程的…...
Qt Designer and Python: Build Your GUI
1.install pyside6 2.pyside6-designer.exe 发送到桌面快捷方式 在Python安装的所在 Scripts 文件夹下找到此文件。如C:\Program Files\Python312\Scripts 3. 打开pyside6-designer 设计UI 4.保存为simple.ui 文件,再转成py文件 用代码执行 pyside6-uic.exe simpl…...

数据结构与算法之栈: LeetCode LCR 152. 验证二叉搜索树的后序遍历序列 (Ts版)
验证二叉搜索树的后序遍历序列 https://leetcode.cn/problems/er-cha-sou-suo-shu-de-hou-xu-bian-li-xu-lie-lcof/description/ 描述 请实现一个函数来判断整数数组 postorder 是否为二叉搜索树的后序遍历结果 示例 1 输入: postorder [4,9,6,5,8] 输出: false解释&#…...
)
蓝桥备赛指南(5)
这篇文章相对简单,主要是让大家简单了解下stack函数。 stack的定义和结构 stack是一种先进后出的数据结构,使用前也需要包含头文件<stack>。stack提供了一组函数来操作和访问元素,但它的功能相对简单。 stack的常用函数 1.push&…...

[STM32 - 野火] - - - 固件库学习笔记 - - -十三.高级定时器
一、高级定时器简介 高级定时器的简介在前面一章已经介绍过,可以点击下面链接了解,在这里进行一些补充。 [STM32 - 野火] - - - 固件库学习笔记 - - -十二.基本定时器 1.1 功能简介 1、高级定时器可以向上/向下/两边计数,还独有一个重复计…...
)
【面试题】 Java 三年工作经验(2025)
问题列表 为什么选择 spring boot 框架,它与 Spring 有什么区别?spring mvc 的执行流程是什么?如何实现 spring 的 IOC 过程,会用到什么技术?spring boot 的自动化配置的原理是什么?如何理解 spring boot 中…...

【信息系统项目管理师-选择真题】2006下半年综合知识答案和详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...
(read)-示例及核心部件)
easyexcel-导入(读取)(read)-示例及核心部件
文章目录 导入(读取)(read)-示例及核心部件导入(读取)(read)-核心部件EasyExcel(EasyExcelFactory) # 入口read() # read()方法用于构建workbook(工作簿)对象,new ExcelReaderBuilder()doReadAll()这里选XlsxSaxAnalyser这个实现类吧然后到这个类XlsxRowHandler&…...

IPhone13 Pro Max设备详情
目录 产品宣传图内部图——后设备详细信息 产品宣传图 内部图——后 设备详细信息 信息收集于HubWeb.cn...

K8S中高级存储之PV和PVC
高级存储 PV和PVC 由于kubernetes支持的存储系统有很多,要求客户全都掌握,显然不现实。为了能够屏蔽底层存储实现的细节,方便用户使用, kubernetes引入PV和PVC两种资源对象。 PV(Persistent Volume) PV是…...

SVG 矩形:深入理解与实际应用
SVG 矩形:深入理解与实际应用 引言 SVG(可缩放矢量图形)是一种基于可扩展标记语言的图形矢量格式,用于在网页上创建矢量图形。SVG矩形是SVG图形中的一种基本形状,它允许用户在网页上绘制不同大小和颜色的矩形。本文将…...

高效学习方法分享
高效学习方法分享 引言 在信息高速发展的今天,学习已经成为每个人不可或缺的一部分。你是否曾感到学习的疲惫,信息的爆炸让你无从下手?今天,我们将探讨几种高效的学习方法,帮助你从中找到适合自己的学习之道。关于学…...

Linux---架构概览
一、Linux 架构分层的深度解析 1. 用户空间(User Space) 用户空间是应用程序运行的环境,与内核空间隔离,确保系统稳定性。 应用程序层: 用户程序:如 edge、vim,通过调用标准库(如 …...

2501,20个窗口常用操作
窗口是屏幕上的一个矩形区域.窗口分为3种:覆盖窗口,弹窗和子窗口.每个窗口都有由系统绘画的"非客户区"和应用绘画的"客户区". 在MFC中,CWnd类为各种窗口提供了基类. 1,通过窗柄取得CWnd指针 可调用Cwnd::FromHandle函数,通过窗柄取得Cwnd指针. void CD…...

[论文总结] 深度学习在农业领域应用论文笔记14
当下,深度学习在农业领域的研究热度持续攀升,相关论文发表量呈现出迅猛增长的态势。但繁荣背后,质量却不尽人意。相当一部分论文内容空洞无物,缺乏能够落地转化的实际价值,“凑数” 的痕迹十分明显。在农业信息化领域的…...

蓝桥杯例题一
不管遇到多大的困难,我们都要坚持下去。每一次挫折都是我们成长的机会,每一次失败都是我们前进的动力。路漫漫其修远兮,吾将上下而求索。只有不断努力奋斗,才能追逐到自己的梦想。不要害怕失败,害怕的是不敢去尝试。只…...

WPF基础 | 深入 WPF 事件机制:路由事件与自定义事件处理
WPF基础 | 深入 WPF 事件机制:路由事件与自定义事件处理 一、前言二、WPF 事件基础概念2.1 事件的定义与本质2.2 常见的 WPF 事件类型 三、路由事件3.1 路由事件的概念与原理3.2 路由事件的三个阶段3.3 路由事件的标识与注册3.4 常见的路由事件示例 四、自定义事件处…...

C++封装红黑树实现mymap和myset和模拟实现详解
文章目录 map和set的封装map和set的底层 map和set的模拟实现insertiterator实现的思路operatoroperator- -operator[ ] map和set的封装 介绍map和set的底层实现 map和set的底层 一份模版实例化出key的rb_tree和pair<k,v>的rb_tree rb_tree的Key和Value不是我们之前传统意…...

洛谷P11464 支配剧场
支配剧场 题目背景 May all the beauty be blessed. 题目描述 布洛妮娅和符华在寻找琪亚娜的途中,被支配之律者困在了支配剧场的高塔回廊之中。布洛妮娅敏锐地发现,虚无回廊是由一些支配之律者生成的积木构成的,只要击碎其中一些积木&#…...

自动化数据备份与恢复:让数据安全无忧
友友们好! 我的新专栏《Python进阶》正式启动啦!这是一个专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会找到: ● 深入解析:每一篇文章都将…...

如何用matlab画一条蛇
文章目录 源代码运行结果代码说明结果 源代码 % 画蛇的代码 % 2025-01-28/Ver1 % 清空环境 clc; clear; close all;% 定义蛇的身体坐标 t linspace(0, 4*pi, 100); % 参数化变量 x t; % x坐标 y sin(t) 0.5 * sin(3*t); % y坐标,形成更复…...

DVC - 数据版本和机器学习实验的命令行工具和 VS Code 扩展
文章目录 一、关于 DVC二、快速启动三、DVC的工作原理四、VS代码扩展五、安装Snapcraft(Linux)Chocolatey (Windows)Brew (mac OS)Anaconda (Any platform)PyPI(Python)Package (Platform-specific)Ubuntu / Debian (deb)Fedora /…...
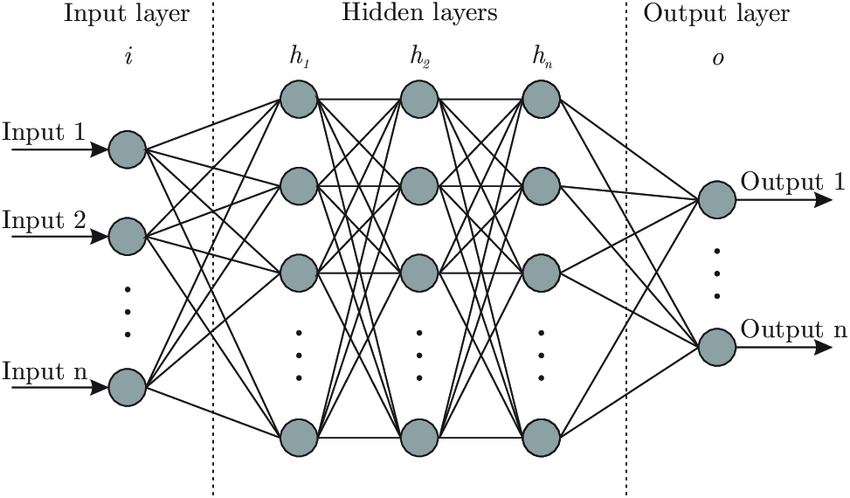
理解神经网络:Brain.js 背后的核心思想
温馨提示 这篇文章篇幅较长,主要是为后续内容做铺垫和说明。如果你觉得文字太多,可以: 先收藏,等后面文章遇到不懂的地方再回来查阅。直接跳读,重点关注加粗或高亮的部分。放心,这种“文字轰炸”不会常有的,哈哈~ 感谢你的耐心阅读!😊 欢迎来到 brain.js 的学习之旅!…...

Maui学习笔记- SQLite简单使用案例02添加详情页
我们继续上一个案例,实现一个可以修改当前用户信息功能。 当用户点击某个信息时,跳转到信息详情页,然后可以点击编辑按钮导航到编辑页面。 创建项目 我们首先在ViewModels目录下创建UserDetailViewModel。 实现从详情信息页面导航到编辑页面…...

typescript 简介
可选链操作符 可选链操作符( ?. ) 允许读取位于连接对象链深处的属性的值,而不必明确验证链中的每个引用是否有效。?. 操作符的功能类似于 . 链式操作符,不同之处在于,在引用为空(nullish ) (null 或者 undefined) 的情况下不会引起错误&a…...

selenium定位网页元素
1、概述 在使用 Selenium 进行自动化测试时,定位网页元素是核心功能之一。Selenium 提供了多种定位方法,每种方法都有其适用场景和特点。以下是通过 id、linkText、partialLinkText、name、tagName、xpath、className 和 cssSelector 定位元素的…...