Kafka 压缩算法详细介绍
文章目录
- 一 、Kafka 压缩算法概述
- 二、Kafka 压缩的作用
- 2.1 降低网络带宽消耗
- 2.2 提高 Kafka 生产者和消费者吞吐量
- 2.3 减少 Kafka 磁盘存储占用
- 2.4 减少 Kafka Broker 负载
- 2.5 降低跨数据中心同步成本
- 三、Kafka 压缩的原理
- 3.1 Kafka 压缩的基本原理
- 3.2. Kafka 压缩的工作流程
- 3.3 Kafka 压缩的数据存储格式
- 四、Kafka 压缩方式配置
- 4.1 Kafka 生产者(Producer)端压缩配置
- 4.2 Kafka Broker 端压缩配置
- 4.3 Kafka 消费者(Consumer)端解压缩
- 五、不同压缩方式对比
- 5.1 Kafka 支持的四种压缩方式
- 5.2 Kafka 压缩方式对比分析
- 六、Kafka 压缩场景
- 6.1 日志收集与分析(ELK / Flink / Kafka)
- 6.2 实时流数据处理(Flink / Spark Streaming)
- 6.3 电商高并发订单系统
- 6.4. 跨数据中心(Multi-DC)Kafka 同步
- 6.5 数据存储优化(Kafka + HDFS)
一 、Kafka 压缩算法概述
Kafka 支持 GZIP、Snappy、LZ4 和 Zstd 四种压缩算法,以减少网络传输负担、降低存储成本,同时提高 Kafka 吞吐量。压缩的主要作用是优化 Kafka 的生产(Producer)、存储(Broker)和消费(Consumer) 过程,从而提高消息系统的整体效率。
二、Kafka 压缩的作用
Kafka 压缩的主要作用是 提高吞吐量、减少存储占用、降低网络带宽消耗,并优化整体性能。
2.1 降低网络带宽消耗
Kafka 作为分布式消息系统,数据在 生产者(Producer)、Broker、消费者(Consumer) 之间传输。未压缩的数据体积大,会导致:
- 网络流量增加,影响 Kafka 集群性能。
- 数据传输速度变慢,影响吞吐量。
Kafka 压缩的好处:
✅ 减少带宽占用 → 适用于跨数据中心同步。
✅ 提升吞吐量 → 生产者和消费者都能更快发送和接收消息。
✅ 降低网络成本 → 特别是在云环境或受限带宽的场景。
📌 示例:
- 未压缩消息:1000 条 JSON 消息 50MB
- 使用 Zstd 压缩:仅 10MB,减少 80% 的网络流量。
2.2 提高 Kafka 生产者和消费者吞吐量
Kafka 处理批量数据(batch processing),压缩后可以减少单个 batch 的大小,从而:
- 生产者(Producer)可以更快地发送消息
- Broker 可以更快地写入磁盘
- 消费者(Consumer)可以更快地消费数据
📌 示例:
- Producer 批量发送未压缩数据(每条 1KB,1000 条消息):
- 发送数据量 = 1MB
- Kafka 需要处理的 batch 很大,写入磁盘速度慢。
- Producer 采用 Snappy 压缩(50% 压缩率):
- 发送数据量 = 500KB
- Kafka 处理的数据减少一半,提升吞吐量。
✅ 适用于高并发写入场景,如电商订单流、日志数据流。
2.3 减少 Kafka 磁盘存储占用
Kafka 消息存储在 Broker 上,未压缩的数据会占用大量磁盘空间,导致:
- 磁盘利用率增加,需要更多存储。
- I/O 负载加大,影响 Kafka 读取性能。
📌 示例:
| 数据量 | 未压缩存储 (MB) | Snappy 压缩后 (MB) | GZIP 压缩后 (MB) |
|---|---|---|---|
| 100 万条日志 | 500 MB | 250 MB | 100 MB |
Kafka 压缩带来的好处:
✅ 减少磁盘存储需求(压缩率通常在 30%-90%)。
✅ 降低存储成本(云存储或本地磁盘使用更少)。
✅ 适用于日志归档、数据存储优化等场景。
2.4 减少 Kafka Broker 负载
Kafka Broker 负责持久化消息和转发数据,如果数据未压缩:
- 磁盘 I/O 负担加重 → 影响写入和读取速度。
- 分区数据量过大 → Broker 压力大,影响副本同步。
- 网络传输慢 → 影响消费者消费速度。
📌 解决方案:
- 采用Zstd或Snappy压缩,在保证吞吐量的同时降低 Broker 负载。
- 适用于高并发日志流、事件流、实时数据传输等场景。
✅ 压缩后,Kafka 需要处理的 I/O 数据变少,性能更优。
2.5 降低跨数据中心同步成本
在跨数据中心部署 Kafka(如灾备中心或全球业务同步),数据需要在不同机房同步。如果数据未压缩:
- 带宽成本高,影响云服务费用(AWS/GCP)。
- 延迟增加,导致跨数据中心数据同步慢。
📌 示例:
未压缩: 10GB 日志/小时 → 需要大带宽传输。
Zstd 压缩(90%) → 仅 1GB,带宽节省 90%。
✅ 适用于跨地域业务、CDN 日志同步、全球电商架构。
| 作用 | 具体表现 |
|---|---|
| 减少网络带宽 | 压缩 50%~90%,适用于跨数据中心 |
| 提升吞吐量 | Producer 发送更快,Consumer 消费更快 |
| 减少磁盘占用 | 存储节省 30%~90% |
| 降低 Broker 负载 | 减少磁盘 I/O,优化 Kafka 处理效率 |
| 降低跨数据中心成本 | 跨机房同步更快,节省流量费用 |
三、Kafka 压缩的原理
Kafka 通过批量(Batch)压缩的方式减少数据传输和存储的开销,从而提高吞吐量、降低网络带宽占用、减少磁盘存储成本。Kafka 的压缩主要在 Producer 端执行,并在 Consumer 端自动解压,而 Broker 仅存储和转发压缩数据。
3.1 Kafka 压缩的基本原理
Kafka 不会对单条消息进行压缩,而是采用批量(Batch)压缩:
- Producer 端:批量收集消息后,对整个 Batch 进行压缩,然后发送到 Kafka Broker。
- Broker 端:直接存储和转发压缩后的数据,而不会解压消息。
- Consumer 端:读取 Broker 发送的压缩 Batch,并在消费时解压。
📌 关键点
- Kafka 只压缩批量数据(Batch),不会压缩单条消息。
- Broker 不解压数据,仅存储 Producer 发送的压缩数据。
- Consumer 端必须支持相应的压缩算法,否则无法解压数据。
3.2. Kafka 压缩的工作流程
Kafka 压缩主要涉及 Producer(生产者)、Broker(消息代理)、Consumer(消费者),其工作流程如下:
📌 生产者端(Producer)压缩
Producer 批量收集消息,然后进行压缩
- Producer 端接收到多条待发送的消息。
- Producer 进行批量处理(Batching),将多条消息合并到一个 Batch 中。
- 选择指定的压缩算法(如 GZIP、Snappy、LZ4、Zstd)。
- 对整个 Batch 进行压缩,然后发送到 Kafka Broker。
示例:
假设 Producer 发送 5 条 JSON 消息:
[{"id":1, "name":"A"},{"id":2, "name":"B"},{"id":3, "name":"C"},{"id":4, "name":"D"},{"id":5, "name":"E"}
]
如果不压缩,发送的数据大小为 5KB,但如果使用 GZIP 压缩,则大小可能只有 1KB,节省 80% 网络带宽。
Producer 配置示例(producer.properties):
compression.type=snappy # 可选 gzip, snappy, lz4, zstd
batch.size=65536 # 设定批次大小,提高吞吐量
linger.ms=10 # 允许 Kafka 等待 10ms 批量收集消息,提高压缩效果
📌 Broker 端(Kafka 存储与转发)
- Broker 直接存储 Producer 发送的压缩 Batch,不进行解压。
- Consumer 读取数据时才会解压,Kafka 仅作为存储和转发的角色。
示例:
Producer 发送压缩后的数据:
[Compressed Batch (Snappy)] -> Kafka Topic Partition
Kafka 不会解压,而是原样存储,并在 Consumer 端解压。
Broker 配置(server.properties):
compression.type=producer # 继承 Producer 端的压缩方式
Kafka Broker 的 compression.type=producer 让 Kafka 直接存储 Producer 的压缩格式,而不会重新压缩数据。
📌 Consumer 端(解压数据)
- Consumer 读取 Kafka Broker 发送的压缩数据。
- Consumer 端会自动解压,然后消费单条消息。
示例:
Consumer 端读取 GZIP 压缩的 Batch,并进行解压:
[Compressed Batch (GZIP)] -> 解压 -> 单条消息处理
Consumer 配置(consumer.properties):
fetch.min.bytes=1048576 # 限制最小 fetch 批次,提高吞吐量
fetch.max.wait.ms=500 # 适当增加等待时间,提高 batch 读取效率
Kafka Consumer 自动解压缩,不需要额外的配置。
3.3 Kafka 压缩的数据存储格式
Kafka 采用批量压缩,因此存储格式如下:
未压缩的 Kafka 消息存储格式
[Message1][Message2][Message3][Message4][Message5]
使用压缩后的 Kafka 消息存储格式
[Compressed Batch (Snappy)]
- 整个 Batch 作为一个数据块压缩,并存储在 Kafka 主题(Topic)中。
- Kafka 只存储和转发已压缩的 Batch,不会解压数据。
四、Kafka 压缩方式配置
4.1 Kafka 生产者(Producer)端压缩配置
Kafka Producer 端负责压缩数据,并发送给 Kafka Broker。
✅ 生产者配置参数
在 producer.properties 中,配置 compression.type:
compression.type=snappy # 可选值:gzip, snappy, lz4, zstd
batch.size=65536 # 设定批次大小,提高吞吐量
linger.ms=10 # 允许 Kafka 等待 10ms 批量收集消息,提高压缩效果
✅ 代码示例
使用 Java 代码配置 Kafka Producer
import org.apache.kafka.clients.producer.*;import java.util.Properties;public class KafkaProducerCompressionExample {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 配置压缩方式props.put("compression.type", "snappy"); // 可选 gzip, lz4, zstdprops.put("batch.size", 16384); // 16KB 批次大小props.put("linger.ms", 5); // 5ms 等待时间,提高批量压缩效果KafkaProducer<String, String> producer = new KafkaProducer<>(props);ProducerRecord<String, String> record = new ProducerRecord<>("test_topic", "key", "message with compression");producer.send(record);producer.close();}
}
4.2 Kafka Broker 端压缩配置
Kafka Broker 可以控制是否允许压缩消息传输,并决定是否改变 Producer 发送的压缩方式。
✅ Broker 配置参数
在 server.properties 中:
log.cleanup.policy=delete # Kafka 日志清理策略
compression.type=producer # 继承 Producer 端的压缩方式
log.segment.bytes=1073741824 # 每个分段日志文件最大 1GB
📌 compression.type=producer 让 Broker 直接存储 Producer 压缩的消息,而不会改变其压缩格式。
📌 Broker 端压缩策略
| 配置项 | 作用 |
|---|---|
compression.type=none | Kafka 不进行任何压缩,存储 Producer 发送的原始数据 |
compression.type=producer | Broker 采用 Producer 发送的数据的压缩格式 |
compression.type=gzip | 强制所有数据存储为 GZIP 压缩 |
compression.type=snappy | 强制所有数据存储为 Snappy 压缩 |
4.3 Kafka 消费者(Consumer)端解压缩
Kafka Consumer 端会自动解压 Producer 发送的压缩数据,因此默认无需额外配置。
✅ Consumer 配置参数
在 consumer.properties 中:
fetch.min.bytes=1048576 # 限制最小 fetch 批次,提高吞吐量
fetch.max.wait.ms=500 # 增加等待时间,提高 batch 读取效率
✅ 代码示例
使用 Java 配置 Kafka Consumer
import org.apache.kafka.clients.consumer.*;import java.util.Collections;
import java.util.Properties;public class KafkaConsumerCompressionExample {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test-group");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList("test_topic"));while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {System.out.println("Received: " + record.value());}}}
}
📌 Consumer 端压缩行为
- Kafka Consumer 自动解压缩 Producer 端压缩的数据。
- 不需要额外配置,但如果批量消费,可以调整
fetch.min.bytes和fetch.max.wait.ms以提高吞吐量。
五、不同压缩方式对比
5.1 Kafka 支持的四种压缩方式
Kafka 主要支持以下压缩算法:
| 压缩方式 | 介绍 | 压缩率 | 压缩速度 | 解压速度 | CPU 占用 |
|---|---|---|---|---|---|
| GZIP | 经典的高压缩率算法 | 高 | 低 | 低 | 高 |
| Snappy | Google 开发的快速压缩 | 低 | 高 | 很高 | 低 |
| LZ4 | 适用于高吞吐的快速压缩 | 中 | 很高 | 极高 | 低 |
| Zstd | Facebook 开发的新一代压缩 | 最高 | 中等 | 高 | 中等 |
5.2 Kafka 压缩方式对比分析
(1) 压缩率对比
压缩率决定了 Kafka 消息存储占用多少空间,压缩率越高,磁盘存储和网络传输占用越少。
| 压缩方式 | 压缩率 (%) | 示例数据 (100MB 日志文件压缩后大小) |
|---|---|---|
| GZIP | 85-90% | 10MB |
| Snappy | 50-60% | 50MB |
| LZ4 | 60-70% | 40MB |
| Zstd | 90-95% | 5-8MB |
📌 结论:
- Zstd 和 GZIP 的压缩率最高,适用于存储优化和跨数据中心数据同步。
- Snappy 和 LZ4 压缩率较低,但速度快,适用于高吞吐场景。
(2) 压缩速度对比
压缩速度影响 Kafka Producer 端的吞吐量,速度越快,Kafka 生产端的效率越高。
| 压缩方式 | 压缩速度 (MB/s) |
|---|---|
| GZIP | 30-50MB/s |
| Snappy | 150-250MB/s |
| LZ4 | 200-400MB/s |
| Zstd | 100-300MB/s |
📌 结论:
- LZ4 和 Snappy 压缩速度最快,适合高吞吐量、低延迟的实时数据流。
- GZIP 压缩速度最慢,适用于存储优化而不是高并发场景。
- Zstd 在不同压缩级别下可调节压缩速度,适用于平衡吞吐量和存储需求的场景。
(3) 解压速度对比
解压速度影响 Kafka Consumer 端的消费吞吐量。
| 压缩方式 | 解压速度 (MB/s) |
|---|---|
| GZIP | 50-100MB/s |
| Snappy | 300-500MB/s |
| LZ4 | 400-800MB/s |
| Zstd | 200-600MB/s |
📌 结论:
- LZ4 和 Snappy 解压速度最快,适用于需要低延迟消费的应用,如日志流分析、流式计算。
- GZIP 解压速度最慢,会影响消费者消费吞吐量。
- Zstd 解压速度介于 GZIP 和 Snappy 之间,且压缩率更高。
(4) CPU 占用对比
CPU 占用影响 Kafka 生产者和消费者的性能,CPU 负载越低,Kafka 处理能力越强。
| 压缩方式 | CPU 占用率 |
|---|---|
| GZIP | 高 (占用 40-70%) |
| Snappy | 低 (占用 5-15%) |
| LZ4 | 低 (占用 5-15%) |
| Zstd | 中等 (占用 10-30%) |
📌 结论:
- GZIP 消耗 CPU 最多,影响 Kafka 高吞吐应用。
- Snappy 和 LZ4 CPU 占用最低,适用于高并发场景。
- Zstd 占用适中,可调节压缩级别来平衡 CPU 负载。
六、Kafka 压缩场景
Kafka 的压缩适用于多个场景,不同业务需求决定了选择不同的压缩方式。
6.1 日志收集与分析(ELK / Flink / Kafka)
📌 场景描述
- 业务系统(微服务、Web 服务器)产生大量日志数据,需要采集并存储到 Kafka。
- 这些日志最终会被消费,并存入 Elasticsearch 或 HDFS 进行分析。
❌ 传统方式的痛点
- 日志量庞大,未压缩时数据传输慢,网络负载高。
- 生产者(如 Filebeat)发送未压缩数据,导致 Kafka 磁盘占用过多。
✅ 解决方案
- 使用 GZIP 或 Zstd 压缩:高压缩率,减少磁盘占用和网络流量。
- 示例:
- 未压缩:100 万条日志 500MB
- GZIP 压缩后:仅 80MB,节省 84% 存储
- Zstd 压缩后:仅 60MB,比 GZIP 还少 20%
🔧 Kafka 配置
compression.type=gzip # 也可以使用 zstd(更快更高效)
🎯 适用场景
✅ ELK 日志分析(Filebeat + Kafka + Logstash)
✅ Flink 处理 Kafka 日志流
✅ CDN 访问日志传输
6.2 实时流数据处理(Flink / Spark Streaming)
📌 场景描述
- 电商订单、用户行为数据、监控指标需要实时流式处理。
- 生产者每秒写入 几十万 条事件,消费者(Flink/Spark)进行计算。
❌ 传统方式的痛点
- 未压缩数据会导致 Kafka 传输延迟增加。
- 高吞吐数据增加 Kafka Broker 负载,影响集群稳定性。
✅ 解决方案
- 使用 Snappy 或 LZ4 压缩:保证低延迟,高吞吐,快速解压。
- 示例:
- 未压缩:1 秒 100 万条,每条 1KB → 总量 1GB/s
- LZ4 压缩后:仅 400MB/s,解压极快,适用于流式计算。
🔧 Kafka 配置
compression.type=snappy # 或 lz4,适用于高吞吐场景
🎯 适用场景
✅ 实时订单处理(Kafka + Flink)
✅ 用户行为分析(Spark Streaming)
✅ 监控系统数据流(Prometheus + Kafka)
6.3 电商高并发订单系统
📌 场景描述
- 订单系统需要将支付、库存变更等数据通过 Kafka 传输到多个消费者(结算、物流、推荐)。
- 订单数据量巨大,高并发时每秒处理数十万条消息。
❌ 传统方式的痛点
- 高并发导致 Kafka 负载飙升,影响延迟。
- 订单数据结构复杂,未压缩时数据量较大。
✅ 解决方案
- 使用 LZ4 或 Snappy 压缩:快速压缩解压,适应高吞吐写入。
- 示例:
- 未压缩:1 小时 500GB 订单数据
- LZ4 压缩后:仅 150GB,减少 70% 传输成本
- Snappy 压缩后:仅 200GB,解压更快
🔧 Kafka 配置
compression.type=lz4 # 适用于高吞吐订单流
🎯 适用场景
✅ 秒杀系统订单处理(Kafka + Redis)
✅ 库存变更消息流(Kafka + MySQL)
✅ 支付流水异步处理
6.4. 跨数据中心(Multi-DC)Kafka 同步
📌 场景描述
- 企业在多个地区部署 Kafka,需要跨数据中心同步日志或交易数据。
- 由于带宽有限,未压缩数据传输成本高,速度慢。
❌ 传统方式的痛点
- Kafka MirrorMaker 传输数据时,占用大量带宽,增加延迟。
- 存储数据量大,导致远程机房的存储成本上升。
✅ 解决方案
- 使用 Zstd 或 GZIP 压缩:降低带宽消耗,提高传输效率。
- 示例:
- 未压缩:每天跨数据中心传输 10TB 日志
- GZIP 压缩后:仅 2TB
- Zstd 压缩后:仅 1.5TB,节省 85% 带宽
🔧 Kafka 配置
compression.type=zstd # 推荐 Zstd,节省带宽 & 高效
🎯 适用场景
✅ 全球业务同步(美洲-欧洲-亚洲数据中心)
✅ 金融数据跨机房同步(Kafka MirrorMaker)
✅ AWS/GCP/Azure 云环境带宽优化
6.5 数据存储优化(Kafka + HDFS)
📌 场景描述
- Kafka 消息最终存储到 HDFS / S3 / ClickHouse,数据存储成本高。
- 需要降低 Kafka 存储和 HDFS 存储成本,同时保持查询性能。
❌ 传统方式的痛点
- Kafka 数据存储占用大量磁盘,导致 Broker 负载增加。
- HDFS 存储成本高,特别是数据湖存储。
✅ 解决方案
- 使用 GZIP 或 Zstd 压缩:最大限度减少存储空间。
- 示例:
- 未压缩:1 天 Kafka 消息 5TB
- GZIP 压缩后:仅 1TB
- Zstd 压缩后:800GB
🔧 Kafka 配置
compression.type=gzip # 或 zstd,存储优化
🎯 适用场景
✅ Kafka + HDFS(数据归档)
✅ Kafka + ClickHouse(大数据查询)
✅ Kafka + Presto(数据湖查询)
Kafka 压缩方式选择总结
| 场景 | 推荐压缩算法 | 目标 |
|---|---|---|
| 日志收集(ELK、CDN) | GZIP / Zstd | 存储优化,减少磁盘占用 |
| 实时流处理(Flink、Spark) | Snappy / LZ4 | 低延迟,高吞吐 |
| 电商订单高并发 | LZ4 / Snappy | 快速压缩解压,减少 Kafka 负载 |
| 跨数据中心同步 | Zstd / GZIP | 降低带宽,提升传输效率 |
| 大数据存储(HDFS、ClickHouse) | GZIP / Zstd | 存储优化,减少磁盘开销 |
相关文章:

Kafka 压缩算法详细介绍
文章目录 一 、Kafka 压缩算法概述二、Kafka 压缩的作用2.1 降低网络带宽消耗2.2 提高 Kafka 生产者和消费者吞吐量2.3 减少 Kafka 磁盘存储占用2.4 减少 Kafka Broker 负载2.5 降低跨数据中心同步成本 三、Kafka 压缩的原理3.1 Kafka 压缩的基本原理3.2. Kafka 压缩的工作流程…...

GWO优化GRNN回归预测matlab
灰狼优化算法(Grey Wolf Optimizer,简称 GWO),是一种群智能优化算法,由澳大利亚格里菲斯大学的 Mirjalii 等人于 2014 年提出。该算法的设计灵感源自灰狼群体的捕食行为,核心思想在于模拟灰狼社会的结构与行…...

Unity 粒子特效在UI中使用裁剪效果
1.使用Sprite Mask 首先建立一个粒子特效在UI中显示 新建一个在场景下新建一个空物体,添加Sprite Mask组件,将其的Layer设置为UI相机渲染的UI层, 并将其添加到Canvas子物体中,调整好大小,并选择合适的Spriteÿ…...

【大厂AI实践】OPPO:大规模知识图谱及其在小布助手中的应用
导读:OPPO知识图谱是OPPO数智工程系统小布助手团队主导、多团队协作建设的自研大规模通用知识图谱,目前已达到数亿实体和数十亿三元组的规模,主要落地在小布助手知识问答、电商搜索等场景。 本文主要分享OPPO知识图谱建设过程中算法相关的技…...
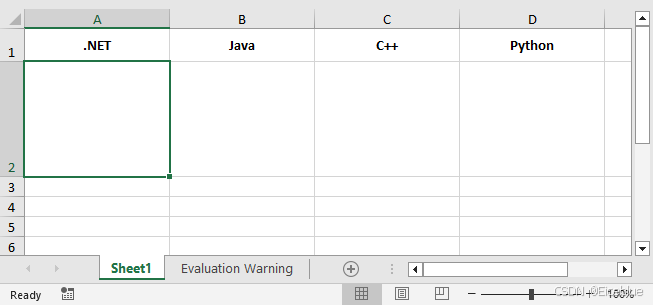
C# 添加、替换、提取、或删除Excel中的图片
在Excel中插入与数据相关的图片,能将关键数据或信息以更直观的方式呈现出来,使文档更加美观。此外,对于已有图片,你有事可能需要更新图片以确保信息的准确性,或者将Excel 中的图片单独保存,用于资料归档、备…...

AI大模型开发原理篇-5:循环神经网络RNN
神经概率语言模型NPLM也存在一些明显的不足之处:模型结构简单,窗口大小固定,缺乏长距离依赖捕捉,训练效率低,词汇表固定等。为了解决这些问题,研究人员提出了一些更先进的神经网络语言模型,如循环神经网络、…...

赛博算卦之周易六十四卦JAVA实现:六幺算尽天下事,梅花化解天下苦。
佬们过年好呀~新年第一篇博客让我们来场赛博算命吧! 更多文章:个人主页 系列文章:JAVA专栏 欢迎各位大佬来访哦~互三必回!!! 文章目录 #一、文化背景概述1.文化起源2.起卦步骤 #二、卦象解读#三、just do i…...

iperf 测 TCP 和 UDP 网络吞吐量
注:本文为 “iperf 测网络吞吐量” 相关文章合辑。 未整理去重。 使用 iperf3 监测网络吞吐量 Tom 王 2019-12-21 22:23:52 一 iperf3 介绍 (1.1) iperf3 是一个网络带宽测试工具,iperf3 可以擦拭 TCP 和 UDP 带宽质量。iperf3 可以测量最大 TCP 带宽…...

内外网文件摆渡企业常见应用场景和对应方案
在如今的企业环境中,内外网文件摆渡的需求越来越常见,也变得越来越重要。随着信息化的不断推进,企业内部和外部之间的数据交换越来越频繁,如何安全、高效地进行文件传输成了一个关键问题。今天,咱就来聊聊内外网文件摆…...

【微服务与分布式实践】探索 Sentinel
参数设置 熔断时长 、最小请求数、最大RT ms、比例阈值、异常数 熔断策略 慢调⽤⽐例 当单位统计时⻓内请求数⽬⼤于设置的最⼩请求数⽬,并且慢调⽤的⽐例⼤于阈值,则接下来的熔断时⻓内请求会⾃动被熔断 异常⽐例 当单位统计时⻓内请求数⽬⼤于设置…...

论文阅读(十五):DNA甲基化水平分析的潜变量模型
1.论文链接:Latent Variable Models for Analyzing DNA Methylation 摘要: 脱氧核糖核酸(DNA)甲基化与细胞分化密切相关。例如,已经观察到肿瘤细胞中的DNA甲基化编码关于肿瘤的表型信息。因此,通过研究DNA…...

Android View 的事件分发机制解析
前言:当一个事件发生时(例如触摸屏幕),事件会从根View(通常是Activity的布局中的最顶层View)开始,通过一个特定的路径传递到具体的View,这个过程涉及到三个关键的阶段:事…...

内容检索(2025.01.30)
随着创作数量的增加,博客文章所涉及的内容越来越庞杂,为了更为方便地阅读,后续更新发布的文章将陆续在此汇总并附上原文链接,感兴趣的小伙伴们可持续关注文章发布动态! 博客域名:http://my-signal.blog.cs…...

【25美赛A题-F题全题目解析】2025年美国大学生数学建模竞赛(MCM/ICM)解题思路|完整代码论文集合
我是Tina表姐,毕业于中国人民大学,对数学建模的热爱让我在这一领域深耕多年。我的建模思路已经帮助了百余位学习者和参赛者在数学建模的道路上取得了显著的进步和成就。现在,我将这份宝贵的经验和知识凝练成一份全面的解题思路与代码论文集合…...
新鲜速递:DeepSeek-R1开源大模型本地部署实战—Ollama + MaxKB 搭建RAG检索增强生成应用
在AI技术快速发展的今天,开源大模型的本地化部署正在成为开发者们的热门实践方向。最火的莫过于吊打OpenAI过亿成本的纯国产DeepSeek开源大模型,就在刚刚,凭一己之力让英伟达大跌18%,纳斯达克大跌3.7%,足足是给中国AI产…...

H264原始码流格式分析
1.H264码流结构组成 H.264裸码流(Raw Bitstream)数据主要由一系列的NALU(网络抽象层单元)组成。每个NALU包含一个NAL头和一个RBSP(原始字节序列载荷)。 1.1 H.264码流层次 H.264码流的结构可以分为两个层…...

Xposed-Hook
配置 Xposed 模块的 AndroidManifest.xml: <?xml version"1.0" encoding"utf-8"?> <manifest xmlns:android"http://schemas.android.com/apk/res/android"package"your.package.name"><applicationandr…...

【PyTorch】6.张量形状操作:在深度学习的 “魔方” 里,玩转张量形状
目录 1. reshape 函数的用法 2. transpose 和 permute 函数的使用 4. squeeze 和 unsqueeze 函数的用法 5. 小节 个人主页:Icomi 专栏地址:PyTorch入门 在深度学习蓬勃发展的当下,PyTorch 是不可或缺的工具。它作为强大的深度学习框架&am…...

实现基础的shell程序
1. 实现一个基础的 shell 程序,主要完成两个命令的功能 cp 和 ls 1.1.1. cp 命令主要实现: ⽂件复制⽬录复制 1.1.2. ls 命令主要实现: ls -l 命令的功能 1.1. 在框架设计上,采⽤模块化设计思想,并具备⼀定的可扩…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】1.18 逻辑运算引擎:数组条件判断的智能法则
1.18 逻辑运算引擎:数组条件判断的智能法则 1.18.1 目录 #mermaid-svg-QAFjJvNdJ5P4IVbV {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-QAFjJvNdJ5P4IVbV .error-icon{fill:#552222;}#mermaid-svg-QAF…...

【Leetcode 每日一题】350. 两个数组的交集 II
问题背景 给你两个整数数组 n u m s 1 nums_1 nums1 和 n u m s 2 nums_2 nums2,请你以数组形式返回两数组的交集。返回结果中每个元素出现的次数,应与元素在两个数组中都出现的次数一致(如果出现次数不一致,则考虑取较小值…...

一文读懂fgc之cms
一文读懂 fgc之cms-实战篇 1. 前言 线上应用运行过程中可能会出现内存使用率较高,甚至达到95仍然不触发fgc的情况,存在内存打满风险,持续触发fgc回收;或者内存占用率较低时触发了fgc,导致某些接口tp99,tp…...

集合的奇妙世界:Python集合的经典、避坑与实战
集合的奇妙世界:Python集合的经典、避坑与实战 内容简介 本系列文章是为 Python3 学习者精心设计的一套全面、实用的学习指南,旨在帮助读者从基础入门到项目实战,全面提升编程能力。文章结构由 5 个版块组成,内容层层递进&#x…...

知识库管理系统助力企业实现知识共享与创新价值的转型之道
内容概要 知识库管理系统(KMS)作为现代企业知识管理的重要组成部分,其定义涵盖了系统化捕捉、存储、共享和应用知识的过程。这类系统通过集成各种信息来源,不仅为员工提供了一个集中式的知识平台,还以其结构化的方式提…...

SpringBoot 日志与配置文件
SpringBoot 配置文件格式 Properties 格式 Component ConfigurationProperties(prefix "person") //和配置文件person前缀的所有配置进行绑定 Data public class Person {private String name;private Integer age;private Date birthDay;private Boolean like;pr…...

【C语言】static关键字的三种用法
【C语言】static关键字的三种用法 C语言中的static关键字是一个存储类说明符,它可以用来修饰变量和函数。static关键字的主要作用是控制变量或函数的生命周期和可见性。以下是static关键字的一些主要用法和含义: 局部静态变量: 当static修饰…...

Qt中Widget及其子类的相对位置移动
Qt中Widget及其子类的相对位置移动 最后更新日期:2025.01.25 下面让我们开始今天的主题… 一、开启篇 提出问题:请看上图,我们想要实现的效果是控件黄色的Widge(m_infobarWidget)t随着可视化窗口(m_glWidge…...

【Node.js】Koa2 整合接口文档
部分学习来源:https://blog.csdn.net/qq_38734862/article/details/107715579 依赖 // koa2-swagger-ui UI视图组件 swagger-jsdoc 识别写的 /***/ 转 json npm install koa2-swagger-ui swagger-jsdoc --save配置 config\swaggerConfig.js const Router requir…...
Docker/K8S
文章目录 项目地址一、Docker1.1 创建一个Node服务image1.2 volume1.3 网络1.4 docker compose 二、K8S2.1 集群组成2.2 Pod1. 如何使用Pod(1) 运行一个pod(2) 运行多个pod 2.3 pod的生命周期2.4 pod中的容器1. 容器的生命周期2. 生命周期的回调3. 容器重启策略4. 自定义容器启…...

leetcode——排序链表(java)
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 示例 1: 输入:head [4,2,1,3] 输出:[1,2,3,4] 示例 2: 输入:head [-1,5,3,4,0] 输出:[-1,0,3,4,5] 示例 3: …...