C++并发编程指南07
文章目录
- @[TOC]
- 5.1 内存模型
- 5.1.1 对象和内存位置
- 图5.1 分解一个 `struct`,展示不同对象的内存位置
- 5.1.2 对象、内存位置和并发
- 5.1.3 修改顺序
- 示例代码
- 5.2 原子操作和原子类型
- 5.2.1 标准原子类型
- 标准库中的原子类型
- 特殊的原子类型
- 备选名称
- 内存顺序参数
- 5.2.2 `std::atomic_flag`
- 初始化
- 操作
- 自旋锁实现
- 5.2 原子操作和原子类型
- 5.2.2 `std::atomic_flag`
- 初始化
- 操作
- 自旋锁实现
- 5.2.3 `std::atomic<bool>`
- 初始化与赋值
- 操作
- “比较/交换”操作
- 其他特性
- 5.2.4 `std::atomic<T*>`
- 初始化与赋值
- 操作
- 其他整型原子类型
- 5.2 原子操作和原子类型
- 5.2.5 标准原子整型的相关操作
- 示例代码
- 5.2.6 `std::atomic<>` 类模板
- 示例代码
- 5.2.7 原子操作的非成员函数
- 常见的非成员函数
- 内存顺序参数
- 对 `std::shared_ptr<>` 的支持
- 并行技术规范扩展
文章目录
- @[TOC]
- 5.1 内存模型
- 5.1.1 对象和内存位置
- 图5.1 分解一个 `struct`,展示不同对象的内存位置
- 5.1.2 对象、内存位置和并发
- 5.1.3 修改顺序
- 示例代码
- 5.2 原子操作和原子类型
- 5.2.1 标准原子类型
- 标准库中的原子类型
- 特殊的原子类型
- 备选名称
- 内存顺序参数
- 5.2.2 `std::atomic_flag`
- 初始化
- 操作
- 自旋锁实现
- 5.2 原子操作和原子类型
- 5.2.2 `std::atomic_flag`
- 初始化
- 操作
- 自旋锁实现
- 5.2.3 `std::atomic<bool>`
- 初始化与赋值
- 操作
- “比较/交换”操作
- 其他特性
- 5.2.4 `std::atomic<T*>`
- 初始化与赋值
- 操作
- 其他整型原子类型
- 5.2 原子操作和原子类型
- 5.2.5 标准原子整型的相关操作
- 示例代码
- 5.2.6 `std::atomic<>` 类模板
- 示例代码
- 5.2.7 原子操作的非成员函数
- 常见的非成员函数
- 内存顺序参数
- 对 `std::shared_ptr<>` 的支持
- 并行技术规范扩展
5.1 内存模型
内存模型在C++中分为两大部分:内存布局和并发。并发的基本结构非常重要,特别是低层原子操作。由于C++中的所有对象都与内存位置有关,我们将从基本结构开始讲解。
5.1.1 对象和内存位置
在C++程序中,数据都是由对象构成的。例如,可以创建一个 int 的衍生类,或者使用具有成员函数的基本类型,甚至像Smalltalk和Ruby那样——“一切都是对象”。对象是对C++数据构建块的声明,C++标准定义类对象为“存储区域”,但对象也可以将自己的特性赋予其他对象。
- 基本类型:如
int或float。 - 用户定义类的实例:如自定义的类。
- 复杂对象:如数组、派生类的实例、具有非静态数据成员的类实例等。
无论是哪种类型,都会存储在一个或多个内存位置上。每个内存位置要么是一个标量类型的对象,要么是标量类型的子对象,例如 unsigned short、my_class* 或序列中的相邻位域。当使用位域时需要注意:虽然相邻位域是不同的对象,但仍被视为相同的内存位置。
图5.1 分解一个 struct,展示不同对象的内存位置

struct MyStruct {int bf1 : 3; // 位域bf1int bf2 : 5; // 位域bf2int bf3 : 0; // 位域bf3,宽度为0int bf4 : 7; // 位域bf4std::string s;
};
- 完整的
struct是由多个子对象(每一个成员变量)组成的对象。 - 位域
bf1和bf2共享同一个内存位置(假设int是4字节、32位类型)。 std::string类型的对象s由内部多个内存位置组成。- 其他成员各自拥有自己的内存位置。
- 宽度为0的位域
bf3如何与bf4分离,并拥有各自的内存位置。
四个需要牢记的原则:
- 每个变量都是对象,包括其成员变量的对象。
- 每个对象至少占有一个内存位置。
- 基本类型都有确定的内存位置(无论类型大小如何,即使它们是相邻的,或是数组的一部分)。
- 相邻位域是相同内存中的一部分。
你会奇怪,这些在并发中有什么作用?
5.1.2 对象、内存位置和并发
这部分对于C++的多线程编程至关重要。当两个线程访问不同的内存位置时,不会存在任何问题;当两个线程访问同一个内存位置时,就需要小心处理。
- 只读访问:如果线程不更新数据,只读数据不需要保护或同步。
- 写入访问:当线程对内存位置上的数据进行修改,就可能会产生条件竞争。
为了避免条件竞争,线程需要以一定的顺序执行。有两种主要方式:
- 使用互斥量:通过同一互斥量在两个线程同时访问前锁住,确保在同一时间内只有一个线程能够访问对应的内存位置。
- 使用原子操作:决定两个线程的访问顺序,当多个线程访问同一个内存地址时,对每个访问者都需要设定顺序。
如果不规定对同一内存地址访问的顺序,那么访问就不是原子的。当两个线程都是“写入者”时,就会产生数据竞争和未定义行为。
未定义的行为:是C++中的黑洞。一旦应用中有任何未定义的行为,就很难预料会发生什么事情。数据竞争绝对是一个严重的错误,要不惜一切代价避免它。
另一个重点是:当程序对同一内存地址中的数据访问存在竞争时,可以使用原子操作来避免未定义行为。当然,这不会影响竞争的产生——原子操作并没有指定访问顺序——而原子操作会把程序拉回到定义行为的区域内。
5.1.3 修改顺序
C++程序中的对象都有一个由程序中的所有线程对象在初始化开始阶段确定好的修改顺序。大多数情况下,这个顺序不同于执行中的顺序,但在给定的程序中,所有线程都需要遵守这个顺序。
- 非原子类型:必须确保有足够的同步操作,以确保线程都遵守了修改顺序。当不同线程在不同序列中访问同一个值时,可能会遇到数据竞争或未定义行为。
- 原子类型:编译器有责任去做同步。
因为当线程按修改顺序访问一个特殊的输入时,所以投机执行是不允许的。之后的读操作必须由线程返回新值,并且之后的写操作必须发生在修改顺序之后。虽然所有线程都需要遵守程序中每个独立对象的修改顺序,但没有必要遵守在独立对象上的操作顺序。
示例代码
#include <atomic>
#include <thread>std::atomic<int> counter(0);void increment_counter() {for (int i = 0; i < 1000; ++i) {counter.fetch_add(1, std::memory_order_relaxed);}
}int main() {std::thread t1(increment_counter);std::thread t2(increment_counter);t1.join();t2.join();std::cout << "Counter: " << counter.load() << std::endl;
}
在这个示例中,std::atomic<int> 确保了对 counter 的访问是线程安全的,并且通过 fetch_add 和 load 方法保证了修改顺序。
注意:虽然 memory_order_relaxed 不提供顺序保证,但它确保了操作的原子性,从而避免了数据竞争。
了解了对象和内存地址的概念后,接下来我们来看什么是原子操作以及如何规定顺序。
以上内容展示了如何使用对象、内存位置和并发来管理多线程程序中的同步问题。希望这些示例和解释能帮助你更好地理解和应用这些同步机制。
以下是经过优化排版后的5.2节内容,详细解释了C++中的原子操作和原子类型。每个部分都有详细的注释和结构化展示。
5.2 原子操作和原子类型
5.2.1 标准原子类型
原子操作是指不可分割的操作,系统的所有线程中不可能观察到原子操作完成了一半。如果读取对象的加载操作是原子的,那么这个对象的所有修改操作也是原子的,因此加载操作得到的值要么是对象的初始值,要么是某次修改操作存入的值。
另一方面,非原子操作可能会被另一个线程观察到只完成一半。如果这个操作是一个存储操作,那么其他线程看到的值可能既不是存储前的值,也不是存储的值。如果非原子操作是一个读取操作,可能先取到对象的一部分,然后值被另一个线程修改,然后再取到剩余的部分,所以它取到的既不是第一个值,也不是第二个值。这就构成了数据竞争(见5.1节),出现未定义行为。
标准库中的原子类型
标准原子类型定义在头文件 <atomic> 中。这些类型的操作都是原子的,语言定义中只有这些类型的操作是原子的,也可以用互斥锁来模拟原子操作。
-
is_lock_free() 成员函数:几乎所有的原子类型都有一个
is_lock_free()成员函数,可以让用户查询某个原子类型的操作是否直接使用了原子指令(x.is_lock_free()返回true),还是内部使用了一个锁结构(x.is_lock_free()返回false)。 -
无锁状态宏:C++17 中,所有原子类型有一个静态常量成员变量
is_always_lock_free,如果相应硬件上的原子类型是无锁类型,则返回true。例如:std::atomic<int> counter; if (counter.is_always_lock_free) {// 该平台上的 std::atomic<int> 是无锁的 } -
宏定义:编译时对各种整型原子操作是否无锁进行判别,如
ATOMIC_BOOL_LOCK_FREE,ATOMIC_CHAR_LOCK_FREE等。如果原子类型是无锁结构,值为 2;如果是基于锁的实现,值为 0;如果无锁状态在运行时才能确定,值为 1。
特殊的原子类型
-
std::atomic_flag:这是一个简单的布尔标志,并且在这种类型上的操作都是无锁的。初始化后,可以使用
test_and_set()和clear()成员函数进行查询和设置。std::atomic_flag f = ATOMIC_FLAG_INIT; f.clear(std::memory_order_release); // 清除标志 bool x = f.test_and_set(); // 设置标志并获取旧值 -
其他原子类型:可以通过特化
std::atomic<>得到更多功能,但不一定都是无锁的。主流平台上,原子变量是无锁的内置类型(如std::atomic<int>和std::atomic<void*>)。
备选名称
为了历史兼容性,标准库提供了备选名称,如 atomic_bool 对应 std::atomic<bool>,具体见表5.1。
| 原子类型 | 相关特化类 |
|---|---|
| atomic_bool | std::atomic |
| atomic_char | std::atomic |
| atomic_schar | std::atomic |
| atomic_uchar | std::atomic |
| atomic_int | std::atomic |
| atomic_uint | std::atomic |
| … | … |
内存顺序参数
每种原子类型的操作都有一个内存序参数,用于指定存储的顺序。常见的内存顺序选项包括:
- Store 操作:
memory_order_relaxed,memory_order_release,memory_order_seq_cst - Load 操作:
memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_seq_cst - Read-modify-write 操作:
memory_order_relaxed,memory_order_consume,memory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_seq_cst
默认的内存序是 memory_order_seq_cst。
5.2.2 std::atomic_flag
std::atomic_flag 是最简单的原子类型,只能在两个状态间切换:设置和清除。它作为构建块存在,通常用于实现自旋锁等简单同步机制。
初始化
std::atomic_flag 类型的对象必须使用 ATOMIC_FLAG_INIT 进行初始化:
std::atomic_flag f = ATOMIC_FLAG_INIT;
操作
- clear() 成员函数:清除标志,使用释放语义。
- test_and_set() 成员函数:设置标志并检索旧值,可以指定内存顺序。
示例代码:
f.clear(std::memory_order_release); // 使用释放语义清除标志
bool x = f.test_and_set(); // 设置标志并获取旧值,默认内存序为 memory_order_seq_cst
自旋锁实现
std::atomic_flag 非常适合实现自旋锁。以下是一个简单的自旋锁实现:
class spinlock_mutex {std::atomic_flag flag;
public:spinlock_mutex():flag(ATOMIC_FLAG_INIT){}void lock() {while(flag.test_and_set(std::memory_order_acquire)); // 等待直到获取锁}void unlock() {flag.clear(std::memory_order_release); // 释放锁}
};
在这个例子中,spinlock_mutex 类使用 std::atomic_flag 来实现一个简单的自旋锁。lock() 方法会不断循环调用 test_and_set(),直到成功获取锁为止。unlock() 方法则通过调用 clear() 来释放锁。
由于 std::atomic_flag 的局限性,实际操作中最好使用 std::atomic<bool>,它提供了更多的功能和灵活性。
以上内容展示了如何使用原子操作和原子类型来管理多线程程序中的同步问题。希望这些示例和解释能帮助你更好地理解和应用这些同步机制。
以下是经过优化排版后的5.2.2至5.2.4节内容,详细解释了C++中的 std::atomic_flag、std::atomic<bool> 和 std::atomic<T*> 的使用方法和特性。每个部分都有详细的注释和结构化展示。
5.2 原子操作和原子类型
5.2.2 std::atomic_flag
std::atomic_flag 是最简单的原子类型,用于在两个状态间切换:设置和清除。它通常作为构建块存在,适用于一些特别的情况。
初始化
std::atomic_flag 类型的对象必须通过 ATOMIC_FLAG_INIT 进行初始化:
std::atomic_flag f = ATOMIC_FLAG_INIT;
- 初始化:标志总是初始化为“清除”状态。
- 静态存储:如果
std::atomic_flag是静态存储的,则保证其是静态初始化的,避免初始化顺序问题。
操作
初始化后,可以进行以下操作:
- 销毁
- 清除:使用
clear()成员函数,并指定内存顺序。 - 设置(查询之前的值):使用
test_and_set()成员函数,并指定内存顺序。
示例代码:
f.clear(std::memory_order_release); // 使用释放语义清除标志
bool x = f.test_and_set(); // 设置标志并获取旧值,默认内存序为 memory_order_seq_cst
- clear():是一个存储操作,不能有
memory_order_acquire或memory_order_acq_rel语义。 - test_and_set():是一个“读-改-写”操作,可以应用于任何内存顺序。
自旋锁实现
std::atomic_flag 非常适合实现自旋锁。以下是一个简单的自旋锁实现:
class spinlock_mutex {std::atomic_flag flag;
public:spinlock_mutex():flag(ATOMIC_FLAG_INIT){}void lock() {while(flag.test_and_set(std::memory_order_acquire)); // 等待直到获取锁}void unlock() {flag.clear(std::memory_order_release); // 释放锁}
};
在这个例子中,spinlock_mutex 类使用 std::atomic_flag 来实现一个简单的自旋锁。lock() 方法会不断循环调用 test_and_set(),直到成功获取锁为止。unlock() 方法则通过调用 clear() 来释放锁。
由于 std::atomic_flag 的局限性,实际操作中最好使用 std::atomic<bool>,它提供了更多的功能和灵活性。
5.2.3 std::atomic<bool>
std::atomic<bool> 是最基本的原子布尔类型,具有比 std::atomic_flag 更多的功能。
初始化与赋值
虽然不能拷贝构造和拷贝赋值,但可以通过非原子的 bool 类型进行构造和赋值:
std::atomic<bool> b(true);
b = false;
操作
- store():写入
true或false,类似于std::atomic_flag中的clear()。 - test_and_set():可以替换为更通用的
exchange(),允许使用新值替换已存储的值,并检索原始值。 - load():加载当前值。
- compare_exchange_weak() 和 compare_exchange_strong():比较当前值与期望值,当两值相等时存储新值;否则更新期望值为当前值。
示例代码:
std::atomic<bool> b;
bool x = b.load(std::memory_order_acquire); // 加载当前值
b.store(true); // 存储 true
x = b.exchange(false, std::memory_order_acq_rel); // 交换值并返回原始值
“比较/交换”操作
- compare_exchange_weak():可能会伪失败,尤其是在缺少单条 CAS 操作的机器上。
- compare_exchange_strong():保证不会伪失败,但在某些情况下可能需要额外的开销。
示例代码:
bool expected = false;
extern std::atomic<bool> b; // 假设已经初始化
while (!b.compare_exchange_weak(expected, true) && !expected);
- 内存顺序参数:可以在成功和失败的情况下分别指定不同的内存顺序。默认情况下,所有操作都使用
memory_order_seq_cst。
其他特性
- is_lock_free():检查操作是否无锁。这是除了
std::atomic_flag外所有原子类型共有的特征。
5.2.4 std::atomic<T*>
std::atomic<T*> 是特化的原子指针类型,支持对指针的操作。
初始化与赋值
虽然不能拷贝构造和拷贝赋值,但可以通过合适的类型指针进行构造和赋值:
std::atomic<Foo*> p(some_array); // some_array 是 Foo 类型的数组
操作
- load():加载当前值。
- store():存储新值。
- exchange():交换值。
- compare_exchange_weak() 和 compare_exchange_strong():比较当前值与期望值,当两值相等时存储新值;否则更新期望值为当前值。
- fetch_add() 和 fetch_sub():在存储地址上做原子加法和减法,提供简易的封装。
示例代码:
class Foo {};
Foo some_array[5];
std::atomic<Foo*> p(some_array);Foo* x = p.fetch_add(2); // p 加 2,并返回原始值
assert(x == some_array);
assert(p.load() == &some_array[2]);x = (p -= 1); // p 减 1,并返回原始值
assert(x == &some_array[1]);
assert(p.load() == &some_array[1]);p.fetch_add(3, std::memory_order_release); // 使用释放语义增加指针
- 内存顺序参数:
fetch_add()和fetch_sub()是“读-改-写”操作,可以使用任意的内存顺序。
其他整型原子类型
剩下的原子类型基本上都是整型原子类型,并且拥有类似的接口(除了内置类型不同)。例如:
std::atomic<int>std::atomic<unsigned int>std::atomic<long>
这些类型的接口和操作方式与 std::atomic<bool> 和 std::atomic<T*> 类似。
以上内容展示了如何使用 std::atomic_flag、std::atomic<bool> 和 std::atomic<T*> 来管理多线程程序中的同步问题。希望这些示例和解释能帮助你更好地理解和应用这些同步机制。
以下是经过优化排版后的5.2.5至5.2.7节内容,详细解释了C++中的标准原子整型操作、std::atomic<> 类模板以及原子操作的非成员函数。每个部分都有详细的注释和结构化展示。
5.2 原子操作和原子类型
5.2.5 标准原子整型的相关操作
除了基本的操作集合(如 load()、store()、exchange()、compare_exchange_weak() 和 compare_exchange_strong()),标准原子整型(如 std::atomic<int> 和 std::atomic<unsigned long long>)还提供了一套完整的操作:
- fetch_add():原子加法操作,并返回旧值。
- fetch_sub():原子减法操作,并返回旧值。
- fetch_and():按位与操作,并返回旧值。
- fetch_or():按位或操作,并返回旧值。
- fetch_xor():按位异或操作,并返回旧值。
此外,还支持复合赋值方式(如 +=, -=, &=, |=, ^=)以及前缀和后缀的自增和自减操作(如 ++x, x++, --x, x--)。
示例代码
std::atomic<int> counter(0);counter.fetch_add(1); // 原子加法操作
counter.fetch_sub(1); // 原子减法操作
counter.fetch_and(0xFF); // 按位与操作
counter.fetch_or(0x100); // 按位或操作
counter.fetch_xor(0x80); // 按位异或操作counter += 5; // 复合赋值操作
++counter; // 前缀自增
counter++; // 后缀自增
这些操作通常用于计数器或掩码等场景。如果需要更复杂的操作(如除法、乘法或移位操作),可以使用 compare_exchange_weak() 或其他同步机制来实现。
5.2.6 std::atomic<> 类模板
std::atomic<> 类模板允许用户定义自己的原子类型,但有一些限制条件:
- 拷贝赋值运算符:类型必须有编译器生成的拷贝赋值运算符,不能有任何虚函数或虚基类。
- 所有基类和非静态数据成员:也必须支持拷贝赋值操作。
- 比较操作:比较-交换操作类似于
memcmp,而不是为用户定义类型(UDT)定义的比较操作符。
示例代码
struct MyType {int x;double y;
};std::atomic<MyType> atomic_var(MyType{1, 2.0});// 使用 load() 和 store()
MyType old_val = atomic_var.load();
MyType new_val{3, 4.0};
atomic_var.store(new_val);// 使用 exchange()
MyType exchanged_val = atomic_var.exchange(MyType{5, 6.0});// 使用 compare_exchange_weak()
MyType expected = atomic_var.load();
MyType desired{7, 8.0};
bool success = atomic_var.compare_exchange_weak(expected, desired);
对于大多数平台,当 UDT 的大小等于或小于一个 int 或 void* 类型时,std::atomic<UDT> 会使用原子指令。某些平台可能支持双字节比较和交换(DWCAS)指令,适用于两倍于 int 或 void* 大小的类型。
需要注意的是,复杂的数据结构(如 std::vector<int>)不适合用作原子类型,因为它们包含多个操作,而不仅仅是赋值和比较。在这种情况下,最好使用 std::mutex 来保护数据。

5.2.7 原子操作的非成员函数
除了成员函数外,C++ 标准库还提供了非成员函数来操作原子类型。这些非成员函数通常以 atomic_ 作为前缀,并且可以重载不同的原子类型。
常见的非成员函数
- std::atomic_load:加载原子变量的值。
- std::atomic_store:存储新值到原子变量。
- std::atomic_exchange:交换原子变量的值,并返回旧值。
- std::atomic_compare_exchange_weak 和 std::atomic_compare_exchange_strong:比较并交换值。
示例代码:
std::atomic<int> a(10);// 成员函数形式
int val1 = a.load(); // 加载值
a.store(20); // 存储新值
int val2 = a.exchange(30); // 交换值并返回旧值
bool success = a.compare_exchange_weak(val1, 40); // 比较并交换值// 非成员函数形式
int val3 = std::atomic_load(&a); // 加载值
std::atomic_store(&a, 50); // 存储新值
int val4 = std::atomic_exchange(&a, 60); // 交换值并返回旧值
success = std::atomic_compare_exchange_weak(&a, &val3, 70); // 比较并交换值
内存顺序参数
非成员函数可以通过 _explicit 后缀指定内存顺序参数。例如:
std::atomic_store_explicit(&a, 80, std::memory_order_release);
bool success_explicit = std::atomic_compare_exchange_weak_explicit(&a, &val3, 90, std::memory_order_acquire, std::memory_order_relaxed);
对 std::shared_ptr<> 的支持
C++ 标准库还为 std::shared_ptr<> 提供了原子操作的非成员函数:
std::shared_ptr<my_data> p;
void process_global_data() {std::shared_ptr<my_data> local = std::atomic_load(&p);process_data(local);
}void update_global_data() {std::shared_ptr<my_data> local(new my_data);std::atomic_store(&p, local);
}
这些函数打破了“只有原子类型才能提供原子操作”的原则,使得 std::shared_ptr<> 也能进行原子操作。
并行技术规范扩展
并行技术规范扩展提供了一种原子类型 std::experimental::atomic_shared_ptr<T>,声明在 <experimental/atomic> 头文件中。它支持无锁实现,并提供了 load、store、exchange 和 compare-exchange 等操作。
示例代码:
#include <experimental/atomic>std::experimental::atomic_shared_ptr<my_data> atomic_p;void process_global_data() {std::shared_ptr<my_data> local = atomic_p.load();process_data(local);
}void update_global_data() {std::shared_ptr<my_data> local(new my_data);atomic_p.store(local);
}
通过 is_lock_free() 函数可以确定在对应的硬件平台上是否无锁。
以上内容展示了如何使用标准原子整型操作、std::atomic<> 类模板以及原子操作的非成员函数来管理多线程程序中的同步问题。希望这些示例和解释能帮助你更好地理解和应用这些同步机制。
相关文章:
C++并发编程指南07
文章目录 [TOC]5.1 内存模型5.1.1 对象和内存位置图5.1 分解一个 struct,展示不同对象的内存位置 5.1.2 对象、内存位置和并发5.1.3 修改顺序示例代码 5.2 原子操作和原子类型5.2.1 标准原子类型标准库中的原子类型特殊的原子类型备选名称内存顺序参数 5.2.2 std::a…...

MySQL 容器已经停止(但仍然存在),但希望重新启动它,并使它的 3306 端口映射到宿主机的 3306 端口是不可行的
重新启动容器并映射端口是不行的 由于你已经有一个名为 mysql-container 的 MySQL 容器,你可以使用 docker start 启动它。想要让3306 端口映射到宿主机是不行的,实际上,端口映射是在容器启动时指定的。你无法在容器已经创建的情况下直接修改…...

AI大模型开发原理篇-6:Seq2Seq编码器-解码器架构
基本概念 Seq2Seq架构的全名是“Sequence-to-Sequence”,简称S2S,意为将一个序列映射到另一个序列。q2Seq编码器-解码器架构,这也是Transformer的基础架构。Seq2Seq架构是一个用于处理输入序列和生成输出序列的神经网络模型,由一…...

春晚舞台上的人形机器人:科技与文化的奇妙融合
文章目录 人形机器人Unitree H1的“硬核”实力传统文化与现代科技的创新融合网友热议与文化共鸣未来展望:科技与文化的更多可能结语 2025 年央视春晚的舞台,无疑是全球华人目光聚焦的焦点。就在这个盛大的舞台上,一场名为《秧BOT》的创意融合…...

【Leetcode刷题记录】166. 分数到小数
166. 分数到小数 给定两个整数,分别表示分数的分子 numerator 和分母 denominator,以 字符串形式返回小数 。 如果小数部分为循环小数,则将循环的部分括在括号内。 如果存在多个答案,只需返回 任意一个 。 对于所有给定的输入&…...

使用 Go 和 gqlgen 实现 GraphQL API:实战指南
使用 Go 和 gqlgen 实现 GraphQL API:实战指南 在本文中,我将分享如何使用 Go 语言和 gqlgen 框架实现一个完整的 GraphQL API。我们将构建一个包含用户、文章和评论功能的博客系统 API。 技术栈 Gogqlgen (GraphQL 框架)MySQL (数据存储)Redis (缓存…...

《程序人生》工作2年感悟
一些杂七杂八的感悟: 1.把事做好比什么都重要, 先树立量良好的形象,再横向发展。 2.职场就是人情世故,但也不要被人情世故绑架。 3.要常怀感恩的心,要记住帮助过你的人,愿意和你分享的人,有能力…...

将pandas.core.series.Series类型的小数转化成百分数
大年初二,大家过年好,蛇年行大运! 今天在编写一个代码的时候,使用 import pandas as pd产生了pandas.core.series.Series类型的数据,里面有小数,样式如下: 目的:将这些小数转化为百…...

详细解释java当中的所有知识点(前言及数据类型及变量)(第一部分)
会将java当中的所有的知识点以及相关的题目进行分享,这是其中的第一部分,用红色字体标注出重点,以及加粗的方式进行提醒 目录 一、Java语言概述 1.Java语言简介 2.语言优势 二、main方法 1.Java程序结构组成 2.运行Java程序 3.注释 4.…...
)
从0开始使用面对对象C语言搭建一个基于OLED的图形显示框架(动态菜单组件实现)
目录 面对对象C的程序设计(范例) 面对对象C的程序设计(应用) 进一步谈论我上面给出的代码——继承 实现一个面对对象的文本编辑器 所以,什么是继承 重申我们对菜单的抽象 抽象菜单项目 抽象菜单动画 实现菜单功…...

Java的StackWalker类
Java的StackWalker类怎么使用 Java 中的 StackWalker 类(自 Java 9 引入)提供了一种高效且灵活的方式来访问堆栈跟踪信息。以下是其使用方法的逐步说明: 1. 基本使用:获取当前堆栈跟踪 import java.lang.StackWalker;public cla…...

农产品价格报告爬虫使用说明
农产品价格报告爬虫使用说明 # ************************************************************************** # * * # * 农产品价格报告爬虫 …...

Pwn 入门核心工具和命令大全
一、调试工具(GDB 及其插件) GDB 启动调试:gdb ./binary 运行程序:run 或 r 设置断点:break *0x地址 或 b 函数名 查看寄存器:info registers 查看内存:x/10wx 0x地址 (查看 10 个 …...

字节iOS面试经验分享:HTTP与网络编程
字节iOS面试经验分享:HTTP与网络编程 🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 目录 字节iOS面试经验分享:HTT…...

在汇编语言中,ASSUME 是一个用于告诉汇编器如何将段寄存器与特定段名称关联的指令
在汇编语言中,ASSUME 是一个用于告诉汇编器如何将段寄存器与特定段名称关联的指令。它主要用于定义代码段、数据段和栈段等的段寄存器使用方式,帮助编译器生成正确的代码。 具体到 ASSUME DS:DATA, CS:CODE, SS:STACK,这行代码的作用如下&…...
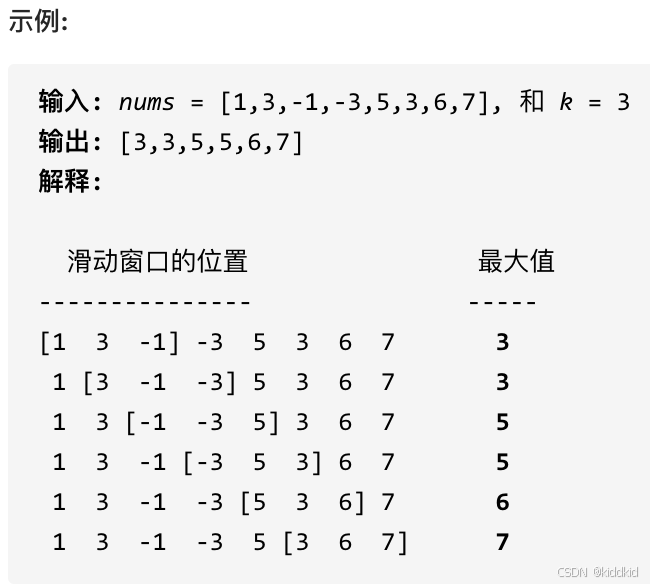
代码随想录_栈与队列
栈与队列 232.用栈实现队列 232. 用栈实现队列 使用栈实现队列的下列操作: push(x) – 将一个元素放入队列的尾部。 pop() – 从队列首部移除元素。 peek() – 返回队列首部的元素。 empty() – 返回队列是否为空。 思路: 定义两个栈: 入队栈, 出队栈, 控制出入…...

Ubuntu 手动安装 Open WebUI 完整指南
Ubuntu 手动安装 Open WebUI 完整指南 前提条件 在安装 Open WebUI 之前,请确保您的系统满足以下要求: Ubuntu 22.04 LTS 或更高版本Python 3.10Node.js 18Git至少 4GB 内存足够的磁盘空间(推荐 20GB 以上) 安装步骤 1. 更新…...

【Oracle篇】使用Hint对优化器的执行计划进行干预(含单表、多表、查询块、声明四大类Hint干预)
💫《博主介绍》:✨又是一天没白过,我是奈斯,从事IT领域✨ 💫《擅长领域》:✌️擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(…...

论文阅读(九):通过概率图模型建立连锁不平衡模型和进行关联研究:最新进展访问之旅
1.论文链接:Modeling Linkage Disequilibrium and Performing Association Studies through Probabilistic Graphical Models: a Visiting Tour of Recent Advances 摘要: 本章对概率图模型(PGMs)的最新进展进行了深入的回顾&…...

【信息系统项目管理师-选择真题】2005上半年综合知识答案和详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2~3题】【第4~6题】【第7题】【第8题】【第9题】【第10~11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18~19题】【第20题】【第21~22题】【第23题】【第24~25题】【第…...

【Matlab高端绘图SCI绘图模板】第006期 对比绘柱状图 (只需替换数据)
1. 简介 柱状图作为科研论文中常用的实验结果对比图,本文采用了3组实验对比的效果展示图,代码已调试好,只需替换数据即可生成相关柱状图,为科研加分。通过获得Nature配色的柱状图,让你的论文看起来档次更高࿰…...

【Elasticsearch】 Intervals Query
Elasticsearch Intervals Query 返回基于匹配术语的顺序和接近度的文档。 intervals 查询使用 匹配规则,这些规则由一小组定义构建而成。这些规则然后应用于指定 field 中的术语。 这些定义生成覆盖文本中术语的最小间隔序列。这些间隔可以进一步由父源组合和过滤…...

YOLOv8源码修改(4)- 实现YOLOv8模型剪枝(任意YOLO模型的简单剪枝)
目录 前言 1. 需修改的源码文件 1.1添加C2f_v2模块 1.2 修改模型读取方式 1.3 增加 L1 正则约束化训练 1.4 在tensorboard上增加BN层权重和偏置参数分布的可视化 1.5 增加剪枝处理文件 2. 工程目录结构 3. 源码文件修改 3.1 添加C2f_v2模块和模型读取 3.2 添加L1正则…...

数论问题80
命题1,证明,方程(2x)^(2x)-1y^(z1)没有正整数解。 分析:设x,y,z∈Z满足方程,当x1时,3y^(z1),无论任意y,z取任意正整数值,3y^(z1)都不成立。方程左端分解因式,…...

后端token校验流程
获取用户信息 前端中只有 await userStore.getInfo() 表示从后端获取数据 在页面中找到info对应的url地址,在IDEA中查找 这里是getInfo函数的声明,我们要找到这个函数的使用,所以点getInfo() Override public JSONObject getInfo() {JSO…...

Ansible自动化运维实战--通过role远程部署nginx并配置(8/8)
文章目录 1、准备工作2、创建角色结构3、编写任务4、准备配置文件(金甲模板)5、编写变量6、编写处理程序7、编写剧本8、执行剧本Playbook9、验证-游览器访问每台主机的nginx页面 在 Ansible 中,使用角色(Role)来远程部…...

C语言自定义数据类型详解(二)——结构体类型(下)
书接上回,前面我们已经给大家介绍了如何去声明和创建一个结构体,如何初始化结构体变量等这些关于结构体的基础知识。下面我们将继续给大家介绍和结构体有关的知识: 今天的主题是:结构体大小的计算并简单了解一下位段的相关知识。…...

OpenFeign的工作原理是什么?它第一次加载的时候为什么慢?
OpenFeign的工作原理是什么?它第一次加载的时候为什么慢? OpenFeign的工作原理 接口定义: 开发者定义一个接口,并使用 FeignClient 注解指定该接口所对应的微服务名称。在接口的方法上添加 HTTP 方法相关的注解(如 …...

LLM架构与优化:从理论到实践的关键技术
标题:“LLM架构与优化:从理论到实践的关键技术” 文章信息摘要: 文章探讨了大型语言模型(LLM)开发与应用中的关键技术,包括Transformer架构、注意力机制、采样技术、Tokenization等基础理论,以…...

Maven的单元测试
1. 单元测试的基本概念 单元测试(Unit Testing) 是一种软件测试方法,专注于测试程序中的最小可测试单元——通常是单个类或方法。通过单元测试,可以确保每个模块按预期工作,从而提高代码的质量和可靠性。 2.安装和配…...