核心集:DeepCore: A Comprehensive Library for CoresetSelection in Deep Learning
目录
一、TL;DR
二、为什么研究核心集?
三、问题定义和如何做
3.1 问题定义
3.2 业界方法
3.2.1 基于几何的方法
3.2.2 基于不确定性的方法
3.2.3 基于误差/损失的方法
3.2.5 GraNd 和 EL2N 分数
3.2.6 重要性采样
3.2.7 基于决策边界的办法
3.2.8 基于梯度匹配的方法
四、综述-应用(直接翻译)
4.1 数据高效学习
4.2 持续学习
4.3 主动学习
五、DeepCore的库能力和bechmark
5.1 为什么要提出DeepCore
5.2 DeepCore实现了什么coreset算法
5.3 CIFAR10的benchmark
5.4 Imagenet的benchmark
5.5 跨架构的benchmark(模型无关性)
一、TL;DR
-
核心集的目的是选择最具信息量的训练子集,但之前的coreset选择方法不是为了深度学习设计的,会导致效果差
-
作者贡献了deepcore的工具,集成了最近很多关于深度学习的核心集选择方法
-
在Imagenet/cifar10等数据集上验证,结论如下:
-
在CIFAR10数据集上,基于次模函数的方法在小核心集<1%时表现最佳,比其他方法高出5%以上。
-
在ImageNet数据集上,基于误差的方法(如遗忘和GraNd)在小核心集(少于10%)时表现较好。
-
当核心集大小增加到30%以上时,随机选择成为了一个强大且稳定的基线,大多数方法难以超越。
-
二、为什么研究核心集?
- NN化的规模越来越大,训练数据集也在不断扩展,这需要大量的内存和计算资源才能达到最先进的性能,核心集的选择能够极大的降低计算成本,其目标是从给定的大型训练数据集 T 中选择一个最具信息量的小型训练样本子集 S。在核心集上训练的模型,其泛化性能应与在原始训练集上训练的模型相近。
- 之前的传统的核心集选择方法在NN领域上是否work不太确定
- 作者使用deepcore这个库继承了12种核心集的选择方法
三、问题定义和如何做
3.1 问题定义
在学习任务中,我们给定一个大型训练集 T={(xi,yi)}i=1∣T∣,其中 xi∈X 是输入,yi∈Y 是 xi 的真实标签,X 和 Y 分别表示输入空间和输出空间。核心集选择的目标是找到一个最具信息量的子集 S⊂T,满足 ∣S∣<∣T∣,使得在 S 上训练的模型 θS 与在完整训练集 T 上训练的模型 θT 具有相近的泛化性能。
3.2 业界方法
3.2.1 基于几何的方法
假设在特征空间中彼此接近的数据点倾向于具有相似的属性。因此,基于几何的方法试图移除那些提供冗余信息的数据点,剩下的数据点形成一个核心集 S,其中 ∣S∣≪∣T∣。
- Herding:Herding 方法根据核心集中心与原始数据集中心在特征空间中的距离选择数据点。该算法逐步且贪婪地每次向核心集中添加一个样本,以最小化两个中心之间的距离。
- k-Center Greedy:该方法试图解决最小最大设施选址问题,即从完整数据集 T 中选择 k 个样本作为 S,使得 T∖S 中的数据点与其在 S 中最近的数据点之间的最大距离最小化:
![]()
其中 D(⋅,⋅) 是距离函数。该问题是 NP-hard 的,文献中提出了一个称为 k-Center Greedy 的贪婪近似算法。k-Center Greedy 已成功扩展到广泛的应用场景,例如主动学习和高效的 GAN 训练。
3.2.2 基于不确定性的方法
置信度较低的样本可能对模型优化的影响大于置信度较高的样本,因此应包含在核心集中。以下是给定特定分类器和训练周期时常用的样本不确定性度量,其中 C 是类别数量:

最后根据这个分数来对降序选择样本
3.2.3 基于误差/损失的方法
在数据集中,对训练神经网络的误差或损失贡献更大的训练样本更为重要。可以通过每个样本的损失或梯度,或其在模型训练过程中对其他样本预测的影响来衡量重要性。选择重要性最大的样本作为核心集。
3.2.4 遗忘事件
Toneva 等人统计在训练过程中遗忘发生的次数,即在当前周期中对样本的误分类,而在前一个周期中已正确分类,形式上为 accti>accti+1,其中 accti 表示样本 i 在周期 t 时预测的正确性(真或假)。遗忘的次数揭示了训练数据的内在属性,允许移除那些难以遗忘的样本,以最小的性能下降。
3.2.5 GraNd 和 EL2N 分数
样本 (x,y) 在周期 t 的 GraNd 分数定义为:

它衡量了每个样本在早期周期 t 对训练损失下降的平均贡献,并且在几次不同的独立运行中。在早期训练阶段(例如,几个周期后)计算的分数效果良好,因此这种方法的计算成本较低。还提供了一种 GraNd 分数的近似值,称为 EL2N 分数,它衡量误差向量的范数:

3.2.6 重要性采样
在重要性采样(或自适应采样)中,我们定义 s(x,y) 是数据点 (x,y) 对总损失函数的上界(最坏情况)贡献,即敏感度分数。它可以表示为:

其中 L(x,y) 是具有参数 θ∈Θ 的非负成本函数。对于 T 中的每个数据点,被选中的概率设置为 p(x,y)=∑(x,y)∈Ts(x,y)s(x,y)。根据这些概率构建核心集 S。在黑箱学习器和 Jtt中也提出了类似的想法,其中错误分类的样本将被加权或增加其采样概率。
3.2.7 基于决策边界的办法
由于分布在决策边界附近的数据点难以区分(百度的数据挖掘核心理念之一),因此,那些最接近决策边界的点也可以被用作核心集。
对抗性 DeepFool:尽管无法获取到确切的决策边界距离,但 Ducoffe 和 Precioso试图在输入空间 X 中寻找这些距离的近似值。通过对样本施加扰动,直到样本的预测标签发生改变,那些需要最小对抗性扰动的数据点最接近决策边界。
对比主动学习:为了找到决策边界附近的数据点,对比主动学习(Contrastive Active Learning, CAL)选择那些预测似然与邻居差异最大的样本,以构建核心集。
3.2.8 基于梯度匹配的方法

四、综述-应用(直接翻译)
4.1 数据高效学习
核心集选择的基本应用是实现高效的机器学习。在核心集上训练模型可以在保留测试性能的同时降低训练成本。特别是在神经架构搜索(NAS)中,需要训练并评估成千上万甚至数百万个深度模型,且这些模型都在同一数据集上进行评估。核心集可以作为代理数据集,高效地训练和评估候选模型,从而显著降低计算成本。
4.2 持续学习
核心集选择也是构建持续学习或增量学习记忆的关键技术,用于缓解灾难性遗忘问题。在流行的持续学习设置中,维护一个记忆缓冲区以存储来自先前任务的信息量大的训练样本,以便在未来的任务中进行复习。研究表明,持续学习的性能在很大程度上依赖于记忆的质量,即核心集。
4.3 主动学习
主动学习旨在通过从未标记池 P 中选择信息量大的样本进行标记,以最小的查询成本实现更好的性能。因此,它可以被视为一个核心集选择问题。
除了上述应用之外,核心集选择还在许多其他机器学习问题中得到研究并成功应用,例如对抗噪声的鲁棒学习、聚类、半监督学习、无监督学习、高效的 GAN 训练、回归任务等。
五、DeepCore的库能力和bechmark
5.1 为什么要提出DeepCore
核心集选择方法已在不同的实验设置下被提出并测试,这些设置包括数据集、模型架构、核心集大小、数据增强、训练策略等。但是相互之间比较不太公平,有的是在MNIST,有的是在Imagenet、即使数据集一样,不同的paper用的数据增强等策略也不一样,因此提出deepcore,在同一个维度上比较。
5.2 DeepCore实现了什么coreset算法
根据第三节实现了如下的方法:
-
基于几何的方法:上下文多样性(Contextual Diversity, CD)、Herding和k-Center Greedy。
-
基于不确定性的方法:最低置信度(Least Confidence)、熵(Entropy)和边缘(Margin)。
-
基于误差/损失的方法:遗忘(Forgetting)和GraNd。
-
基于决策边界的方法:CAL和DeepFool。
-
基于梯度匹配的方法:Craig和GradMatch。
-
双层优化方法:Glister。
-
基于次模性的方法:图割(Graph Cut, GC)和设施选址(Facility Location, FL)函数。 我们还将随机选择(Random selection)作为基线。
5.3 CIFAR10的benchmark
实验和超参数设置
-
优化器:使用随机梯度下降(SGD)作为优化器,批大小为128,初始学习率为0.1,采用余弦退火调度器,动量为0.9,权重衰减为 5×10−4,训练周期为200轮。
-
数据增强:对32×32的训练图像应用随机裁剪(4像素填充)和随机翻转。
-
核心集比例:分别选择整个训练集的0.1%、0.5%、1%、5%、10%、20%、30%、40%、50%、60%和90%作为核心集。
-
全数据集训练:在完整数据集上的训练结果被视为性能的上限。
-
特征提取:对于需要样本梯度、预测概率或特征向量的方法,使用在完整数据集上训练了10轮的ResNet-18模型来提取上述指标。当需要梯度向量 ∇θL(x,y;θ) 时,使用最终全连接层的参数梯度,如许多先前研究所建议的那样。这使得梯度向量可以在不进行全网络反向传播的情况下轻松获得。
-
样本选择:虽然DeepCore支持平衡和不平衡的样本选择,但本文的所有实验均采用平衡选择,即每个类别选择相同数量的样本。


-
次模函数方法的优势:在小比例(0.1%-1%)和大比例设置中,基于次模函数的方法均取得了良好的实验结果。特别是图割(Graph Cut, GC)方法表现突出,在选择0.1%到10%的训练数据时取得了最佳结果。当每类选择50个样本时(即整个训练集的1%),图割方法在测试精度上比其他方法高出超过5%。CAL方法在0.1%-5%的小比例设置中也表现出色,性能与设施选址(Facility Location, FL)相当。然而,随着核心集大小的增加,尤其是在选择超过30%的训练数据时,其优势逐渐消失。
-
其他方法的表现:除了上述方法外,其他方法在0.1%-1%的小比例设置中均未能超越随机采样基线。遗忘(Forgetting)方法在30%比例设置中表现优于其他方法。在40%-60%的比例设置中,GraNd和基于不确定性分数的方法表现突出。在所有比例设置中,GradMatch和Herding仅勉强超过随机采样。需要注意的是,GradMatch在原始论文中的实验设置是自适应采样,即随着网络训练的进行迭代更新子集。为了进行公平比较,本文在选择核心集后将其固定用于所有训练周期。Herding最初是为从高斯混合中提取的固定表示而设计的,因此其性能在很大程度上取决于嵌入函数。需要注意的是,上述发现是基于一种超参数设置的,如果超参数发生变化,发现的结果可能会改变。例如,如果用于特征提取的模型完全训练,Herding可能会有更好的表现。我们将在后面研究一些超参数的影响。
5.4 Imagenet的benchmark

实验结果如表2(Tab. 2)所示。结果显示,基于误差的方法,如遗忘(Forgetting)和GraNd,在ImageNet上通常表现更好。特别是,当选择少于10%的数据作为核心集时,遗忘方法明显优于随机选择(Random)。然而,当核心集的大小较大时(例如选择30%的数据),没有任何方法能够超越random。random仍然是一个强大且稳定的基线。
5.5 跨架构的benchmark(模型无关性)
为了检验表现良好的方法是否具有模型无关性,即当在一种架构上选择核心集,然后在其他架构上进行测试时,核心集是否仍然表现良好。
结论:使用图割进行的次模选择在测试结果上表现稳定良好;GraNd显示出对计算梯度范数的模型的偏好,resnet和Inception存在差异;

相关文章:
核心集:DeepCore: A Comprehensive Library for CoresetSelection in Deep Learning
目录 一、TL;DR 二、为什么研究核心集? 三、问题定义和如何做 3.1 问题定义 3.2 业界方法 3.2.1 基于几何的方法 3.2.2 基于不确定性的方法 3.2.3 基于误差/损失的方法 3.2.5 GraNd 和 EL2N 分数 3.2.6 重要性采样 3.2.7 基于决策边界的办法 …...

Hot100之矩阵
73矩阵置零 题目 思路解析 收集0位置所在的行和列 然后该行全部初始化为0 该列全部初始化为0 代码 class Solution {public void setZeroes(int[][] matrix) {int m matrix.length;int n matrix[0].length;List<Integer> list1 new ArrayList<>();List<…...
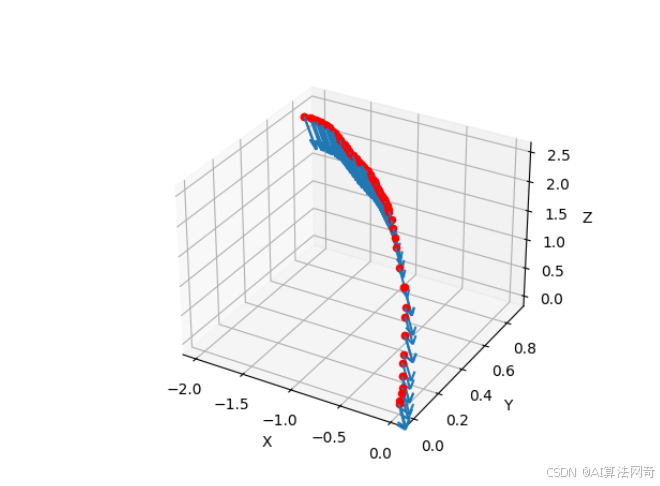
可视化相机pose colmap形式的相机内参外参
目录 内参外参转换 可视化相机pose colmap形式的相机内参外参 内参外参转换 def visualize_cameras(cameras, images):fig plt.figure()ax fig.add_subplot(111, projection3d)for image_id, image_data in images.items():qvec image_data[qvec]tvec image_data[tvec]#…...

第十二章 I 开头的术语
文章目录 第十二章 I 开头的术语以 I 开头的术语被识别 (identified by)识别关系 (identifying relationship)身份 (identity)idkey隐式全局引用 (implicit global reference)隐含命名空间 (implied namespace)包含文件 (include file)传入锁 (incoming lock) 索引 (index)索引…...

C# 类与对象详解
.NET学习资料 .NET学习资料 .NET学习资料 在 C# 编程中,类与对象是面向对象编程的核心概念。它们让开发者能够将数据和操作数据的方法封装在一起,从而构建出模块化、可维护且易于扩展的程序。下面将详细介绍 C# 中类与对象的相关知识。 一、类的定义 …...

Windsurf cursor vscode+cline 与Python快速开发指南
Windsurf简介 Windsurf是由Codeium推出的全球首个基于AI Flow范式的智能IDE,它通过强大的AI助手功能,显著提升开发效率。Windsurf集成了先进的代码补全、智能重构、代码生成等功能,特别适合Python开发者使用。 Python环境配置 1. Conda安装…...

深度解析:网站快速收录与服务器性能的关系
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/37.html 网站快速收录与服务器性能之间存在着密切的关系。服务器作为网站运行的基础设施,其性能直接影响到搜索引擎对网站的抓取效率和收录速度。以下是对这一关系的深度解析&am…...

Linux tr 命令使用详解
简介 tr (translate)命令用于在 Linux 中翻译或删除输入流(通常是 stdin )中的字符。它主要用于文本操作,并且可以作为转换或删除文本文件或流中的特定字符的方便工具。 基本语法 tr [OPTION] [SET1] [SET2]SET1&am…...

数据库内存与Buffer Pool
数据库内存与Buffer Pool 文章目录 数据库内存与Buffer Pool一:MySQL内存结构1:MySQL工作组件2:工作线程的本地内存3:共享内存区域4:存储引擎缓冲区 二:InnoDB的核心:Buffer Pool1:数…...

程序员学英文之At the Airport Customs
Dialogue-1 Making Airline Reservation预定机票 My cousin works for Xiamen Airlines. 我表哥在厦航上班。I’d like to book an air ticket. 我想预定一张机票。Don’t judge a book by its cover. 不要以貌取人。I’d like to book / re-serve a table for 10. 我想预定一…...

Redis代金卷(优惠卷)秒杀案例-单应用版
优惠卷表:优惠卷基本信息,优惠金额,使用规则 包含普通优惠卷和特价优惠卷(秒杀卷) 优惠卷的库存表:优惠卷的库存,开始抢购时间,结束抢购时间.只有特价优惠卷(秒杀卷)才需要填写这些信息 优惠卷订单表 卷的表里已经有一条普通优惠卷记录 下面首先新增一条秒杀优惠卷记录 { &quo…...

51单片机 01 LED
一、点亮一个LED 在STC-ISP中单片机型号选择 STC89C52RC/LE52RC;如果没有找到hex文件(在objects文件夹下),在keil中options for target-output- 勾选 create hex file。 如果要修改编程 :重新编译-下载/编程-单片机重…...

MusicFree-开源的第三方音乐在线播放和下载工具, 支持歌单导入[对标落雪音乐]
MusicFree 链接:https://pan.xunlei.com/s/VOI0RrVLTTWE9kkpt0U7ofGBA1?pwd4ei6#...

消息队列篇--原理篇--常见消息队列总结(RabbitMQ,Kafka,ActiveMQ,RocketMQ,Pulsar)
1、RabbitMQ 特点: AMQP协议:RabbitMQ是基于AMQP(高级消息队列协议)构建的,支持多种消息传递模式,如发布/订阅、路由、RPC等。多语言支持:支持多种编程语言的客户端库,包括Java、P…...

nacos 配置管理、 配置热更新、 动态路由
文章目录 配置管理引入jar包添加 bootstrap.yaml 文件配置在application.yaml 中添加自定义信息nacos 配置信息 配置热更新采用第一种配置根据服务名确定配置文件根据后缀确定配置文件 动态路由DynamicRouteLoaderNacosConfigManagerRouteDefinitionWriter 路由配置 配置管理 …...

程序代码篇---Numpyassert迭代器
文章目录 前言第一部分:Numpy1. 创建数组2. 数组索引和切片3. 数组形状操作4. 数组运算5. 数学函数6. 随机数生成7. 数组排序 第二部分:assert基本语法1.condition2.error_message 示例注意事项断言的用途 第三部分:迭代器迭代器协议1.__iter…...

(笔记+作业)书生大模型实战营春节卷王班---L0G2000 Python 基础知识
学员闯关手册:https://aicarrier.feishu.cn/wiki/QtJnweAW1iFl8LkoMKGcsUS9nld 课程视频:https://www.bilibili.com/video/BV13U1VYmEUr/ 课程文档:https://github.com/InternLM/Tutorial/tree/camp4/docs/L0/Python 关卡作业:htt…...

分布式微服务系统架构第90集:现代化金融核心系统
#1.1 深化数字化转型,核心面临新挑战 1、架构侧:无法敏捷协同数字金融经营模式转型。 2、需求侧:业务需求传导低效始终困扰金融机构。 3、开发侧:创新产品上市速度低于期望。 4、运维侧:传统面向资源型监控体系难以支撑…...

浅谈Linux 权限、压缩、进程与服务
概述 放假回家,对Linux系统的一些知识进行重新的整理,做到温故而知新,对用户权限管理、文件赋权、压缩文件、进程与服务的知识进行了一次梳理和总结。 权限管理 Linux最基础的权限是用户和文件,先了解基础的用户权限和文件权限…...

SpringBoot中Excel表的导入、导出功能的实现
文章目录 一、easyExcel简介二、Excel表的导出2.1 添加 Maven 依赖2.2 创建导出数据的实体类4. 编写导出接口5. 前端代码6. 实现效果 三、excel表的导出1. Excel表导入的整体流程1.1 配置文件存储路径 2. 前端实现2.1 文件上传组件 2.2 文件上传逻辑3. 后端实现3.1 文件上传接口…...

JavaScript前后端交互-AJAX/fetch
摘自千峰教育kerwin的js教程 AJAX 1、AJAX 的优势 不需要插件的支持,原生 js 就可以使用用户体验好(不需要刷新页面就可以更新数据)减轻服务端和带宽的负担缺点: 搜索引擎的支持度不够,因为数据都不在页面上…...

动态规划DP 背包问题 完全背包问题(题目分析+C++完整代码)
概览检索 动态规划DP 概览(点击链接跳转) 动态规划DP 背包问题 概览(点击链接跳转) 完全背包问题 原题链接 AcWiing 3. 完全背包问题 题目描述 有 N种物品和一个容量是 V的背包,每种物品都有无限件可用。 第 i种物…...

【cocos creator】【模拟经营】餐厅经营demo
下载:【cocos creator】模拟经营餐厅经营...
--编译优化技术详解)
JavaScript系列(52)--编译优化技术详解
JavaScript编译优化技术详解 🚀 今天,让我们深入探讨JavaScript的编译优化技术。通过理解和应用这些技术,我们可以显著提升JavaScript代码的执行效率。 编译优化基础概念 🌟 💡 小知识:JavaScript引擎通常…...

【深度学习】softmax回归的从零开始实现
softmax回归的从零开始实现 (就像我们从零开始实现线性回归一样,)我们认为softmax回归也是重要的基础,因此(应该知道实现softmax回归的细节)。 本节我们将使用Fashion-MNIST数据集,并设置数据迭代器的批量大小为256。 import torch from IP…...

【Redis】set 和 zset 类型的介绍和常用命令
1. set 1.1 介绍 set 类型和 list 不同的是,存储的元素是无序的,并且元素不允许重复,Redis 除了支持集合内的增删查改操作,还支持多个集合取交集,并集,差集 1.2 常用命令 命令 介绍 时间复杂度 sadd …...

程序诗篇里的灵动笔触:指针绘就数据的梦幻蓝图<3>
大家好啊,我是小象٩(๑ω๑)۶ 我的博客:Xiao Xiangζั͡ޓއއ 很高兴见到大家,希望能够和大家一起交流学习,共同进步。 今天我们来对上一节做一些小补充,了解学习一下assert断言,指针的使用和传址调用…...

代码随想录-训练营-day16
530. 二叉搜索树的最小绝对差 - 力扣(LeetCode) /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode…...

Vue 3 中的父子组件传值:详细示例与解析
在 Vue 3 中,父子组件之间的数据传递是一个常见的需求。父组件可以通过 props 将数据传递给子组件,而子组件可以通过 defineProps 接收这些数据。本文将详细介绍父子组件传值的使用方法,并通过优化后的代码示例演示如何实现。 1. 父子组件传值…...

谈谈你所了解的AR技术吧!
深入探讨 AR 技术的原理与应用 在科技飞速发展的今天,AR(增强现实)技术已经悄然改变了我们与周围世界互动的方式。你是否曾想象过如何能够通过手机屏幕与虚拟物体进行实时互动?在这篇文章中,我们将深入探讨AR技术的原…...