【C++篇】哈希表
目录
一,哈希概念
1.1,直接定址法
1.2,哈希冲突
1.3,负载因子
二,哈希函数
2.1,除法散列法 /除留余数法
2.2,乘法散列法
2.3,全域散列法
三,处理哈希冲突
3.1,开放定址法
线性探测
二次探测
双重探测
3.2,开放定址法代码实现
哈希表扩容问题
key不能取模的问题
完整代码实现
3.3,链地址法
哈希表扩容问题
链地址法代码实现
小结:
一,哈希概念
哈希(hash)又称散列,是一种组织数据的方式。从译名看,有散乱排列的意思。本质就是通过哈希函数把关键字key和存储位置建立一个映射关系,查找时通过这个哈希函数计算出key存储的位置,实现快速查找。
说白了,hash函数就是根据key计算出应该存储地址的位置,而哈希表是基于hash函数建立的一种查找表。
1.1,直接定址法
当关键字的范围比较集中时,直接定址法就是非常简单高效的方法。比如一组关键字的值在[0,99]之间,那么我们开一个100大小的数组,每个关键字的值直接就是存储位置的下标。再比如一组数据a~z的字符,我们可以开一个大小为26的数组,每个关键字的acsll值减去 a的ascll值,就是对应的存储位置下标。也就是说直接定址法是用关键字计算出一个绝对位置或相对位置。
本题链接:387. 字符串中的第一个唯一字符 - 力扣(LeetCode)

class Solution {
public:
int firstUniqChar(string s) {
int hash[26]={0};
//统计次数
for(auto& ch:s)
{
hash[ch-'a']++;
}
for(int i=0;i<s.size();i++)
{
if(hash[s[i]-'a']==1)
return i;
}
return -1;
}
};
1.2,哈希冲突
不同的key值产生相同的地址,即H(key1)=H(key2)。这种问题叫做哈希冲突或哈希碰撞。
1.3,负载因子
假设哈希表已经存储N个值,哈希表的大小为M,那么负载因子=N/M。负载因子越大,代表哈希冲突的概率越高,空间利用率越高;负载因子越小,代表哈希冲突的概率越低,空间利用率越低。
二,哈希函数
两个不同的key值可能 会映射到同一个位置,这个问题叫做哈希冲突。理想情况是找一个哈希函数避免冲突,但是实际场景中,冲突不可避免,所以我们尽可能设计出好的哈希函数,来减少哈希冲突。
哈希函数的设计可能有很多讲究,比如要考虑均匀性、确定性、高效性等等。不同的应用场景可能需要不同的哈希函数。比如,非加密的哈希函数可能更注重速度,而加密的哈希函数则需要更高的安全性,防止被逆向或者找到碰撞。
2.1,除法散列法 /除留余数法
- 除法散列法也叫除留余数法,假设哈希表的大小为M,那么通过key除以M的余数作为映射的下标。也就是哈希函数为H(key)=key%M。
- 当使用 除法散列法时,应避免M的大小为某些值,比如2的幂,10的幂等。如果是2的x次方,那么key%2^x相当于保留key的二进制前x位。那么前x位二进制相同的key值,计算出的哈希值都是一样的,就会加剧哈希冲突。原因:key%2^x,相当于key&(2^x-1),其中 2^x-1的二进制表示中前x均为1,其余为均为0,所以最后按位与的结果取决于key的前x位。【见下图】

- 当使用除法散列 法时,建议M取不太接近2的整数次幂的一个质数(素数)
2.2,乘法散列法
- 乘法散列法对哈希表的大小M没有要求,它的大思路第一步:用关键字key乘上A(0<A<1),并抽取出key*A的小数部分。第二步:再用M乘以key*A的小数部分,再向下取整。
- H(key)=floor(M*((A*key)%1.0)),其中floor表示对表达式进行向下取整。0<A<1,这里最重要的时A的值该如何设定。Knuth认为设为黄金分割点比较好
2.3,全域散列法
- 如果存在一个对手,他针对我们的哈希函数,特意构造出一个发生严重冲突的数据集。比如,让所有关键字落入同一个位置,这种情况是可以存在的。只要哈希函数公开且时确定的,就可以实现次攻击。解决此方法就是给哈希函数增加随机性,攻击者就无法找出确定的导致冲突 加剧的数据。这种方法叫做全域散列。
- H[a][b](key)=((a*key+b)%P)%M。P选择一个足够大的质数,a可以任意选[1,P-1]之间的一个整数,b可以选[0,P-1]之间的任意整数,这些函数就构成了一个P*(P-1)组全域散列函数组。假设P=17,M=6,a=3,b=4,则H[3][4](8)=((3*8+4)&17)%6=5。
- 需要注意的是,每次初始化哈希表时,随机选取全域散列函数组中的一个散列(哈希)函数使用,后序增删查改都固定使用这个散列函数。否则每次哈希都是随机选一个散列函数,那么插入是一个散列函数,查找又是另一个散列函数,就会导致查找不到插入的key值。
总结:实践中,哈希表一般是选择除法散列法作为哈希函数。当然哈希表无论选择什么哈希函数,都无法避免哈希冲突,那么插入数据时,如何解决哈希冲突呢?主要有两种方法,开放定址法和链地址法。
三,处理哈希冲突
3.1,开放定址法
开放定址法中,所有元素都放到哈希表里。当一个关键字key用哈希函数计算出的位置冲突了,则按照某种规则找到一个没有存储数据的位置存储。这里的规则有三种:线性探测,二次探测,双重探测。
线性探测
- 从发生冲突的位置开始,依次向后进行 线性探测,直到寻找到一个没有存储数据的位置为止,如果走到哈希表尾,则回绕到哈希表头 的位置。
- H(key)=key%M=hash0,其中hash0代表映射的位置,如果该位置没有数据,则将key填入 。如果hash0位置已经存在数据,也就是hash0位置冲突了,则线性探测公式为:Hc(key)=(hash0+i)%M=hashi,i=0,1,2,3...,M-1。其中hashi就是经过线性探测找到没有存储数据的位置,再将key填入。
下面演示{19,30,5,36,13,20,21,12} 等映射到M=11的表中.

- 线性探测问题,假设hash0位置连续冲突,hash0,hash1,hash2已经存储数据了,后序映射到hash0,hash1,hash2的值都会 争夺hash3位置,这种现象叫做群集/堆积。下面的二次探测可以解决这个问题。
二次探测
- 从发生冲突的位置,依次左右按二次方跳跃式探测,直到寻找到下一个没有存储数据的位置为止。如果 往右走到哈希表尾,则回绕到哈希表头的位置;如果往左走到哈希表头,则会绕道哈希表尾的位置。
- H(key)=key%M=hash0,hash0位置冲突了,则二次探测公式为,Hc(key)=(hash0+/-i*i)%M,i=1,2,3..,M/=hashi.
- 二次探测结果hashi可能为负数,当hashi<0时,hashi+=M。
下面演示{19,30,52,63,11,22}映射到M=11的表中

双重探测
- 第⼀个哈希函数计算出的值发生冲突,使用第二个哈希函数计算出⼀个跟key相关的偏移量值,不断往后探测,直到寻找到下一个没有存储数据的位置为止。
- H(key)=key%M=hash0,hash0位置冲突了,则双重探测公式为:Hc(key)=(hash0+i*H2(key))%M=hashi,i=1,2,3,...,M
3.2,开放定址法代码实现
开放定址法在时间中不如下面的连地址法,所以我们选择简单的线性探测实现即可。
结构:
//当前位置的状态
//存在 空 已删除
enum State
{EXIT,EMPTY,DELETE
};template <class k,class v>
struct HashData
{pair<k, v> _kv;State _state = EMPTY;
};template <class k,class v>
class HashTable
{
private:vector<Hashdata<k, v>> _tables; //哈希表size_t n = 0; //表中存储数据的个数
};要注意的是这⾥需要给每个存储值的位置加⼀个状态标识,否则删除⼀些值以后,会影响后⾯冲突的值的查找。如下图,我们删除30,会导致查找20失败,当我们给每个位置加⼀个状态标识{EXIST,EMPTY,DELETE},删除30就可以不用删除值,而是把状态改为DELETE,那么查找20时遇到EMPTY才停,就可以找到20。

哈希表扩容问题
这里我们哈希表负载因子控制在0.7,当负载因子到0.7以后我们就需要扩容了,我们如果还是按照2倍扩 容,但是同时我们要保持哈希表大小是一个质数,第一个是质数,2倍后就不是质数了。所以我们可以按照sgi版本的哈希表使用的方法。,给了⼀个近似2倍的质数表,每次去质数表获取扩容后的大小。
inline unsigned long __stl_next_prime(unsigned long n)
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + __stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
在需要扩容时,调用__stl_next_prime(n),在__stl_prime_list数组中查找第一个大于等于n的数组并返回。
key不能取模的问题
当key是string/Date等类型时,key不能取模,那么我们需要给HashTable增加⼀个仿函数,这个仿函 数⽀持把key转换成⼀个可以取模的整形,如果key可以转换为整形并且不容易冲突,那么这个仿函数就用默认参数即可,如果这个Key不能转换为整形我们就需要自己实现⼀个仿函数传给这个参数,实 现这个仿函数的要求就是尽量key的每个值都参与到计算中,让不同的key转换出的整形值不同。string做哈希表的key值很常见,我们可以考虑把string特化一下。
template <class k>
class HashFunc
{
size_t operator()(const k& key)
{
return (size_t)key;
}
};
//特化
template<>
struct HashFunc<string>
{
// 字符串转换成整形,可以把字符ascii码相加即可
// 但是直接相加的话,类似"abcd"和"bcad"这样的字符串计算出是相同的
// 这⾥我们使⽤BKDR哈希的思路,用上次的计算结果去乘以⼀个质数,这个质数⼀般去31, 131等效果会比较好
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash += ch;
hash *= 131;
}
return hash;
}
};
完整代码实现
//当前位置的状态
//存在 空 已删除
enum State
{EXIT,EMPTY,DELETE
};template <class k,class v>
struct HashData
{pair<k, v> _kv;State _state = EMPTY;
};template <class k>
class HashFunc
{size_t operator()(const k& key){return (size_t)key;}
};
//特化
template<>
struct HashFunc<string>
{// 字符串转换成整形,可以把字符ascii码相加即可// 但是直接相加的话,类似"abcd"和"bcad"这样的字符串计算出是相同的// 这⾥我们使⽤BKDR哈希的思路,⽤上次的计算结果去乘以⼀个质数,这个质数⼀般去31, 131等效果会比较好size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash += ch;hash *= 131;}return hash;}
};template<class k, class v, class Hash = HashFunc<k>>
class HashTable
{
public:HashTable():_tables(__stl_next_prime(0)), _n(0){}inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}bool insert(const pair<k, v>& kv){Hash hash;//负载因子>=0.7 扩容if (_n * 10 / _tables.size() >= 7){//创建一个新表HashTable<k, v, Hash> newht;//扩容newht._tables.resize(__stl_next_prime(_tables.size() + 1));//旧表数据映射到新表for (auto& data : _tables){if (data._state == EXIST)newht.insert(data._kv);}//_tables=newht._tables;_tables.swap(newht._tables);}size_t hash0 = hash(kv.first) % _tables.size();size_t hashi = hash0;int i = 1;while (_tables[hashi]._state == EXIST){//线性探测hashi = (hash0 + i) % _tables.size();//防止越界i++;}_tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;_n++;return true;}HashData<k, v>* find(const k& key){Hash hash;size_t hash0 = hash(key) % _tables.size();size_t hashi = hash0;int i = 1;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._kv.first == key && _tables[hashi]._state == EXIST){return &_tables[hashi];}//线性探测hashi = (hash0 + i) % _tables.size();//防止越界i++;}return nullptr;}bool erase(const k& key){HashData<k, v>* ret = find(key);if (ret){ret->_state = DELETE;return true;}else{return false;}}
private:vector<HashData<k, v>> _tables;size_t _n;
};
3.3,链地址法
开放定址法中所有的元素都放到哈希表里,链地址法中所有的数据不再直接存储在哈希表中。哈希表 中存储一个指针,没有数据映射这个位置时,这个指针为空,有多个数据映射到这个位置时,我们把这些冲突的数据链接成⼀个链表,挂在哈希表这个位置下面,链地址法也叫做拉链法或者哈希桶。
下面演示{19,30,5,36,13,20,21,12,24,96} 等这一组值映射到M=11的表中
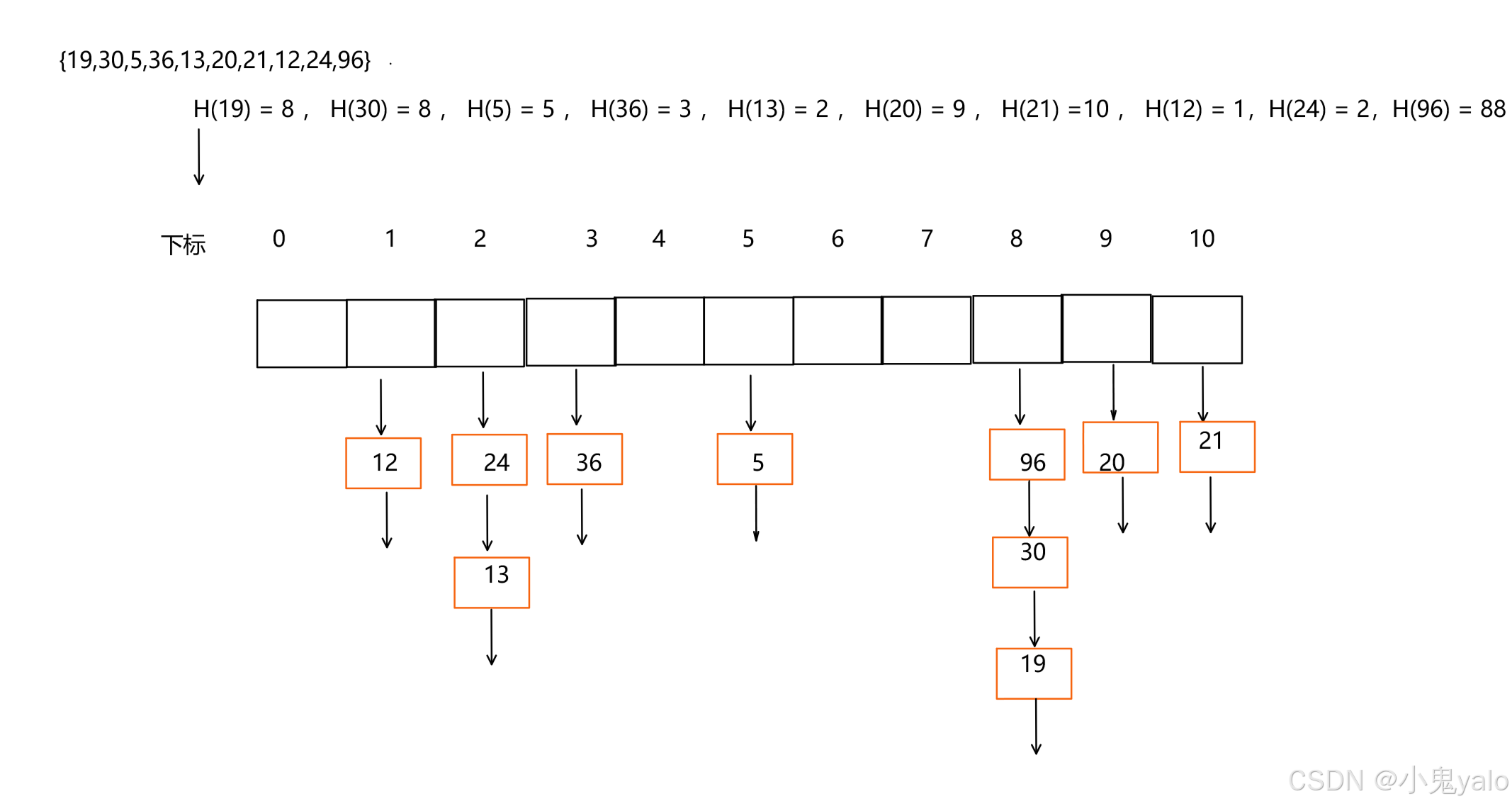
哈希表扩容问题
开放定址法负载因子必须小于1,链地址法的负载因子就没有限制了,可以大于1。负载因子越大,哈 希冲突的概率越高,空间利用率越高;负载因子越小,哈希冲突的概率越低,空间利用率越低;STL中的unordered_map和unordered_set最大复杂因子进本控制在1,大于1就开始扩容。
链地址法代码实现
//链地址法
//哈希桶
template<class k, class v>
struct HashNode
{pair<k, v> _kv;HashNode<k, v>* _next;HashNode(const pair<k, v>& kv):_kv(kv), _next(nullptr){}
};
template<class k, class v>
class Hash_bucket
{
public:typedef HashNode<k, v> Node;Hash_bucket():_tables(__stl_next_prime(0)), _n(0){}~Hash_bucket(){for (int i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list + __stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}bool insert(const pair<k, v>& kv){//防止键值冗余if (find(kv.first))return false;//负载因子>=1时,扩容if (_n / _tables.size() >= 1){//创建新表vector<Node*> newtables(__stl_next_prime(_tables.size() + 1));for (int i = 0; i < _tables.size(); i++){Node* cur = _tables[i];//直接将旧表中的节点插入到新表中 所映射的位置while (cur){Node* next = cur->_next;//直接插入到新表size_t hashi = cur->_kv.first % newtables.size();cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}}_tables.swap(newtables);}size_t hashi = kv.first % _tables.size();Node* newnode = new Node(kv);//头插到新表newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}Node* find(const k& key){size_t hashi = key % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key)return cur;cur = cur->_next;}return nullptr;}bool erase(const k& key){size_t hashi = key % _tables.size();Node* cur = _tables[hashi];Node* prev = nullptr;while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}else{prev = cur;cur = cur->_next;}}return false;}private:vector<Node*> _tables;size_t _n;
};
小结:
哈希表这种数据结构,是利用哈希函数来快速定位数据的位置,然后存储到数组中的相应位置。
这样在查找的时候,时间复杂度可以接近O(1),非常高效。不过如果多个键被哈希到同一个位置,就会发生冲突,这时候需要解决冲突的方法,比如链地址法或者开放寻址法。
那哈希表的实现原理大概是怎样的呢?当插入一个键值对时,首先用哈希函数计算键的哈希值,然后根据哈希值找到对应的数组下标,如果该位置已经有元素了,就用链表或者其他方式处理冲突,然后存储进去。查找的时候同样计算哈希值,找到位置后,如果该位置有多个元素,需要遍历链表进行查找。好的哈希函数应该尽量均匀分布,减少冲突,这样哈希表的效率才会高。
相关文章:
【C++篇】哈希表
目录 一,哈希概念 1.1,直接定址法 1.2,哈希冲突 1.3,负载因子 二,哈希函数 2.1,除法散列法 /除留余数法 2.2,乘法散列法 2.3,全域散列法 三,处理哈希冲突 3.1&…...

TVM调度原语完全指南:从入门到微架构级优化
调度原语 在TVM的抽象体系中,调度(Schedule)是对计算过程的时空重塑。每一个原语都是改变计算次序、数据流向或并行策略的手术刀。其核心作用可归纳为: 优化目标 max ( 计算密度 内存延迟 指令开销 ) \text{优化目标} \max…...

《解锁AI黑科技:数据分类聚类与可视化》
在当今数字化时代,数据如潮水般涌来,如何从海量数据中提取有价值的信息,成为了众多领域面临的关键挑战。人工智能(AI)技术的崛起,为解决这一难题提供了强大的工具。其中,能够实现数据分类与聚类…...

[MySQL]事务的隔离级别原理与底层实现
目录 1.为什么要有隔离性 2.事务的隔离级别 读未提交 读提交 可重复读 串行化 3.演示事务隔离级别的操作 查看与设置事务的隔离级别 演示读提交操作 演示可重复读操作 1.为什么要有隔离性 在真正的业务场景下,MySQL服务在同一时间一定会有大量的客户端进程…...

数据密码解锁之DeepSeek 和其他 AI 大模型对比的神秘面纱
本篇将揭露DeepSeek 和其他 AI 大模型差异所在。 目录 编辑 一本篇背景: 二性能对比: 2.1训练效率: 2.2推理速度: 三语言理解与生成能力对比: 3.1语言理解: 3.2语言生成: 四本篇小结…...

知识管理系统推动企业知识创新与人才培养的有效途径分析
内容概要 本文旨在深入探讨知识管理系统在现代企业中的应用及其对于知识创新与人才培养的重要性。通过分析知识管理系统的概念,企业可以认识到它不仅仅是信息管理的一种工具,更是提升整体创新能力的战略性资产。知识管理系统通过集成企业内部信息资源&a…...

【数据结构与算法】动态规划
目录 动态规划 1. 基本概念 2. 基本步骤 3. 经典应用场景 4. 优点和局限性 最长递增子序列(中等) 最大子数组和(中等) 动态规划 动态规划是一种用于解决多阶段决策问题的算法思想,它将复杂问题分解为一系列相对…...
 容器获取并执行自定义服务)
ASP.NET Core 中使用依赖注入 (DI) 容器获取并执行自定义服务
目录 一、ASP.NET Core 中使用依赖注入 (DI) 容器获取并执行自定义服务 1. app.Services 2. GetRequiredService() 3. Init() 二、应用场景 三、依赖注入使用拓展 1、使用场景 2、使用步骤 1. 定义服务接口和实现类 2. 注册服务到依赖注入容器 3. 使用依赖注入获取并…...

Nginx知识
nginx 精简的配置文件 worker_processes 1; # 可以理解为一个内核一个worker # 开多了可能性能不好events {worker_connections 1024; } # 一个 worker 可以创建的连接数 # 1024 代表默认一般不用改http {include mime.types;# 代表引入的配置文件# mime.types 在 ngi…...

CSES Missing Coin Sum
思路是对数组排序 设 S [ i ] S[i] S[i] 是数组的前缀和 R [ i ] R[i] R[i] 是递增排序后的数组 遍历数组,如果出现 S [ i − 1 ] 1 < R [ i ] S[i - 1] 1 < R[i] S[i−1]1<R[i],就代表S[i - 1] 1是不能被合成出来的数字 因为:…...

nth_element函数——C++快速选择函数
目录 1. 函数原型 2. 功能描述 3. 算法原理 4. 时间复杂度 5. 空间复杂度 6. 使用示例 8. 注意事项 9. 自定义比较函数 11. 总结 nth_element 是 C 标准库中提供的一个算法,位于 <algorithm> 头文件中,用于部分排序序列。它的主要功能是将…...

Hot100之双指针
283移动零 题目 思路解析 那我们就把不为0的数字都放在数组前面,然后数组后面的数字都为0就行了 代码 class Solution {public void moveZeroes(int[] nums) {int left 0;for (int num : nums) {if (num ! 0) {nums[left] num;// left最后会变成数组中不为0的数…...

DeepSeek-R1论文研读:通过强化学习激励LLM中的推理能力
DeepSeek在朋友圈,媒体,霸屏了好长时间,春节期间,研读一下论文算是时下的回应。论文原址:[2501.12948] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 摘要: 我们…...

p1044 栈
两种递推细节不同 1,将1和n在序列末尾的情况单独放出来处理,因为dp[0]0; 2,将所有情况统一处理,这种情况就要要求dp[1]1; 这里的n在解题中可以看做是元素数量 思路是,根据出栈最后一个元素,统计它前面的元素数量的输出序列数和…...

群晖Alist套件无法挂载到群晖webdav,报错【连接被服务器拒绝】
声明:我不是用docker安装的 在套件中心安装矿神的Alist套件后,想把夸克挂载到群晖上,方便复制文件的,哪知道一直报错,最后发现问题出在两个地方: 1)挂载的路径中,直接填 dav &…...

three.js+WebGL踩坑经验合集(6.2):负缩放,负定矩阵和行列式的关系(3D版本)
本篇将紧接上篇的2D版本对3D版的负缩放矩阵进行解读。 (6.1):负缩放,负定矩阵和行列式的关系(2D版本) 既然three.js对3D版的负缩放也使用行列式进行判断,那么,2D版的结论用到3D上其实是没毛病的,THREE.Li…...

【ubuntu】双系统ubuntu下一键切换到Windows
ubuntu下一键切换到Windows 1.4.1 重启脚本1.4.2 快捷方式1.4.3 移动快捷方式到系统目录 按前文所述文档,开机默认启动ubuntu。Windows切换到Ubuntu直接重启就行了,而Ubuntu切换到Windows稍微有点麻烦。可编辑切换重启到Windows的快捷方式。 1.4.1 重启…...

力扣第149场双周赛
文章目录 题目总览题目详解找到字符串中合法的相邻数字重新安排会议得到最多空余时间I 第149场双周赛 题目总览 找到字符串中合法的相邻数字 重新安排会议得到最多空余时间I 重新安排会议得到最多空余时间II 变成好标题的最少代价 题目详解 找到字符串中合法的相邻数字 思…...

在线课堂小程序设计与实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

https的原理
HTTPS 的原理 HTTPS(HyperText Transfer Protocol Secure)是一种通过计算机网络进行安全通信的传输协议。它在 HTTP 的基础上增加了 SSL/TLS 协议,以实现数据传输的安全性和完整性。以下是 HTTPS 的基本原理: 1. 基本概念 HTTP…...

当卷积神经网络遇上AI编译器:TVM自动调优深度解析
从铜线到指令:硬件如何"消化"卷积 在深度学习的世界里,卷积层就像人体中的毛细血管——数量庞大且至关重要。但鲜有人知,一个简单的3x3卷积在CPU上的执行路径,堪比北京地铁线路图般复杂。 卷积的数学本质 对于输入张…...

Flask 使用Flask-SQLAlchemy操作数据库
username db.Column(db.String(64), uniqueTrue, indexTrue); password db.Column(db.String(64)); 建立对应关系 如果是多对多关系就建一张表,关联两个表的id role_id db.Column(db.Integer, db.ForeignKey(‘roles.id’)) ‘’’ 帮助作关联查询 relati…...

[EAI-023] FAST,机器人动作专用的Tokenizer,提高VLA模型的能力和训练效率
Paper Card 论文标题:FAST: Efficient Action Tokenization for Vision-Language-Action Models 论文作者:Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, Sergey Levine 论文链接&…...

使用Pygame制作“太空侵略者”游戏
1. 前言 在 2D 游戏开发中,“太空侵略者”是一款入门难度适中、却能覆盖多种常见游戏机制的项目: 玩家控制飞船(Player)左右移动,发射子弹。敌人(Enemy)排列成一行或多行,从屏幕顶…...

《逆向工程核心原理》第三~五章知识整理
查看上一章节内容《逆向工程核心原理》第一~二章知识整理 对应《逆向工程核心原理》第三章到第五章内容 小端序标记法 字节序 多字节数据在计算机内存中存放的字节顺序分为小端序和大端序两大类 大端序与小端序 BYTE b 0x12; WORD w 0x1234; DWORD dw 0x12345678; cha…...

2025 AI行业变革:从DeepSeek V3到o3-mini的技术演进
【核心要点】 DeepSeek V3引领算力革命,成本降至1/20o3-mini以精准优化回应市场挑战AI技术迈向真正意义的民主化行业生态正在深刻重构 一、市场格局演变 发展脉络 2025年初,AI行业迎来重要转折。DeepSeek率先发布V3模型,通过革命性的架构创…...

SAP SD学习笔记28 - 请求计划(开票计划)之2 - Milestone请求(里程碑开票)
上一章讲了请求计划(开票计划)中的 定期请求。 SAP SD学习笔记27 - 请求计划(开票计划)之1 - 定期请求-CSDN博客 本章继续来讲请求计划(开票计划)的其他内容: Milestone请求(里程碑请求)。 目录 1,Miles…...

算法随笔_27:最大宽度坡
上一篇:算法随笔_26: 按奇偶排序数组-CSDN博客 题目描述如下: 给定一个整数数组 nums,坡是元组 (i, j),其中 i < j 且 nums[i] < nums[j]。这样的坡的宽度为 j - i。 找出 nums 中的坡的最大宽度,如果不存在,返回 0 。 …...

SpringBoot+Vue的理解(含axios/ajax)-前后端交互前端篇
文章目录 引言SpringBootThymeleafVueSpringBootSpringBootVue(前端)axios/ajaxVue作用响应式动态绑定单页面应用SPA前端路由 前端路由URL和后端API URL的区别前端路由的数据从哪里来的 Vue和只用三件套axios区别 关于地址栏url和axios请求不一致VueJSPS…...

大白话讲清楚embedding原理
Embedding(嵌入)是一种将高维数据(如单词、句子、图像等)映射到低维连续向量的技术,其核心目的是通过向量表示捕捉数据之间的语义或特征关系。以下从原理、方法和应用三个方面详细解释Embedding的工作原理。 一、Embe…...