B-树:解锁大数据存储和与快速存储的密码
在我们学习数据结构的过程中,我们会学习到二叉搜索树、二叉平衡树、红黑树。
这些无一例外,是以一个二叉树展开的,那么对于我们寻找其中存在树中的数据,这个也是一个不错的方法。
但是,如若是遇到了非常大的数据容量进行存储的时候,此时呢,无法一次性加载到内存当中,那么此时,这样的二叉结构的树就显得力不从心了。
这是因为,我们二叉树中,一个节点只保存了一个数据域,此时遇到非常大数据量的时候,导致树高变得很高,进行遍历查询树的时候,需要遍历树较深的地方,当然,查询的数据如若是在较浅树层,那么查询的时间还好,如若是非常深,那么此时查询的时间就会变得很耗时。
所以我们干脆在一个节点中存储多个数值域,以达到减少树高,从而获得高效率的查询效率。
而我们数据结构中,正好有一种符合此特征的,那就是B-树
B-树
那么又是B-树?
定义:一种适合外查找的树,它是一种平衡的多叉树
那么它具有什么性质呢?
一颗M阶(M > 2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
1.根节点至少有两个孩子
2.每个非根节点的关键字至少有M/2-1(向上取整),至多有M-1个关键字,并以升序排列
比如当M=4,至少有(4/2-1=1)个关键字,至多有(4-1=3)个关键字.
3.每个非根节点的孩子至少有(M/2)向上取整,至多有M个孩子
比如当M=4,至少有(4/2=2)个孩子,至多有4个孩子
4. key[i]和key[i+1]之间的孩子节点的值介于key[i]、key[i+1]之间
5.所有叶子节点都在同一层
由此可得出,
孩子节点会比关键字多出一个。
值得注意的是,为了使其关键字和孩子访问速度较快,所以使用的是数组进行存储。
节点图例:

这里值得注意的是,上述节点图例,是一般情况下的,为了后续插入操作简易进行,所以节点内部会进行修改。后面的插入操作进行解释。
修改后的节点:

现在小编来分享下插入操作,以三叉树作为例子
插入
根据此修改后的插入节点图例,此节点定义代码如下:
//这里约定以三叉树作为实现public static int BT=3;//定义节点static class Node{//keys关键字数组public int [] keys;//孩子数组public Node [] subs;//有效数据大小public int Usize;//父亲节点public Node parent;//提供一个构造方法public Node(){//多给一个节点,利于后续分裂this.keys=new int[BT];//孩子域会比父亲域多一个this.subs=new Node[BT+1];}}插入操作其实是大致可说为,插入按照某个插入算法进行插入,满了就进行分裂。
假设我们有以下的插入数据
序列:53, 139, 75, 49, 145, 36, 101
那么初始插入,因为我们关键字数组是中是有序的序列,所以我们需要选用一个插入算法进行插入,这里选择的是直接插入排序
初始状态如下:

注意,我们是初始情况,即根节点是为空的
所以如何插入53的呢?
显然,先新建一个节点,然后直接放到keys[0],Usize++即可。
代码实例:
//定义一个头节点public Node root;public boolean insert(int key){//如若根节点为空if(root==null){root=new Node();root.keys[0]=key;root.Usize++;return true;}那么此时如若不为空呢?
即我们插入75的数据,那么此时我们先要找到75是否是存在于树中。
那么接下来说说,如何实现查找的
查找
我们以一个实例说明(值得注意的是,数据有序是因为以直接插入排序进行的)

假设我们要寻找的是54这个节点
显然我们在根节点是寻找不到的,那么此时该去哪个数值的子树去寻找呢?
因为我们的49是比54小的,那么接着去下一个数值去比较,即75
那么54和75比较,那么此时的是大于54的,所以就结束我们的比较
所以我们得去75的孩子节点数组去找,
那么此时就到了53这棵树这里,此时显然,54也是不在这里的,那么此时我们按照逻辑,还是得去子树再找,那么这里呢,没有子树了,所以导致我们寻找节点变为null了
这里要保存其父亲节点,进行后续的操作。
那么就有一个问题了
如若我们找到了,那我们一般也是返回当前的节点,如若我们找不到了,也是返回此时的保存下来的父亲节点,那么怎么区分他们是找到还是没有找到呢?
这里提供一个方案:
新建一个泛型类,存储下当前的节点以及一个整数值,通过整数值去判断是否是找到了
泛型类代码:
public class Pair<k,v> {public k key;public v val;public Pair(k key,v val){this.key=key;this.val=val;}public void setKey(k key) {this.key = key;}public void setVal(v val) {this.val = val;}public v getVal() {return val;}public k getKey() {return key;}
}
接下来是寻找节点代码
寻找节点代码:
private Pair<Node,Integer> findNode(int key) {Node cur=root;Node parent=null;while (cur!=null){int i=0;while (i<cur.Usize){if(cur.keys[i]==key){return new Pair<>(cur,i);}else if(cur.keys[i]<key){i++;}else {break;}}parent=cur;cur=cur.subs[i];}return new Pair<>(parent,-1);}此时,我们就可以判断返回值是不是负数即可。
//当根节点不为空,那么此时找出这个key是否存在B树中Pair<Node,Integer> node=findNode(key);//根据返回值是否插入还是修改if(node.val!=-1){System.out.println("此key值已存在!");return false;}//没有找到,那么此时就要插入这个新节点,//此时的插入操作就是以直接插入方法进行Node parent=node.getKey();int i=parent.Usize-1;for (;i>=0;i--){if(parent.keys[i]>=key){parent.keys[i+1]=parent.keys[i];}else {break;}}//此时i变成负数,我们要把0下标的值放进去。parent.keys[i+1]=key;parent.Usize++;if(parent.Usize >= BT){//超出容量,此时进行分裂Split(parent);return true;}else {return true;}}那么如若我们找不到的话,即这个数据是未曾插入的,所以我们要进行插入它。
那么插入的话选用了直接插入排序。
插入完成之后,我们还要判断下是否是大于了这个BT值,如若是大于了,此时我们就要进行分裂。
那么接下来就还有个分裂操作还没有分享。
分裂
这里的分裂分为根节点分裂,和孩子节点分裂
举例
根节点满时:

值得注意的是,我们把关键字移动的同时,也要把孩子数组对应到下标值,一一挪过去,挪过去的同时也要对subs[]数组中的值的父亲进行修改
然后呢,此时我们这里的举动是把同一层的孩子节点处理了,但是新出现的根节点
就比如现在的75,还没用进行处理,所以呢,我们要处理它,
比如keys[0]下标放的是75,subs[0]下标放的是53这个节点,sub[1]放的是139这个节点值
然后把53这个节点的父亲和139这个父亲,进行修改,然后还要修改对应的Usize。
private void Split(Node cur) {Node parent=cur.parent;Node newNode=new Node();int mid=cur.Usize>>1;int j=0;int i=mid+1;for (;i<cur.Usize;i++){newNode.keys[j]=cur.keys[i];newNode.subs[j]=cur.subs[i];if(newNode.subs[i]!=null){//修改迁移过去的父亲节点newNode.subs[j].parent=newNode;}j++;}//由于分配多了一个节点,那么此时就要再次拷贝下孩子newNode.subs[j]=cur.subs[i];if(newNode.subs[i]!=null){newNode.subs[i].parent=newNode;}//此时进行修改Usize和新创建节点的父亲节点cur.Usize=cur.Usize-j-1;newNode.Usize=j;if(cur==root){root=new Node();root.keys[0]=cur.keys[mid];root.subs[0]=cur;root.subs[1]=newNode;root.Usize++;cur.parent=root;newNode.parent=root;return;}newNode.parent=parent;这里是根节点的修改,还有孩子节点的分裂
孩子节点的分裂:
以下面例子举例:

显然,最左边的树,是满了,所以要进行分裂

孩子分裂出来的思路和刚刚根节点是差不多,
那么这里要说明的是下,对于孩子节点分裂完后,父亲节点的操作
即把49提到根节点后怎么操作。
插入49也是一个直接插入排序,所以不过多讲解。
如若我们定义一个endT=当前节点的.Usize-1,即是1-1=0,就是0下标。
那我们可以发现,没有分裂前,75这个节点subs[1]连接139这棵树。
那么如何把新增加53这棵树的节点插入到subs[1]呢?
显然,当我们把49和53排好序后,此时的endT=0
所以,subs[endT+2]的空间存储139这棵树节点即可。
等代码跳出循环后,再次把subs[1]的值赋值为53这棵树的节点值即可。
那么此时接着插入节点

可以注意到的是,101那边的这棵树也满了,继续分裂

再次注意到,出现了连续分裂,因为根节点这棵树也是满了,所以接着也要对根节点这棵树进行分裂,为了可以进行连续分裂,我们可以进行递归这样的方式
即判断下分裂完后,把139提到根节点后,当前的Usize值是否是满的,然后递归分裂

完整分裂代码:
private void Split(Node cur) {Node parent=cur.parent;Node newNode=new Node();int mid=cur.Usize>>1;int j=0;int i=mid+1;for (;i<cur.Usize;i++){newNode.keys[j]=cur.keys[i];newNode.subs[j]=cur.subs[i];if(newNode.subs[i]!=null){//修改迁移过去的父亲节点newNode.subs[j].parent=newNode;}j++;}//由于分配多了一个节点,那么此时就要再次拷贝下孩子newNode.subs[j]=cur.subs[i];if(newNode.subs[i]!=null){newNode.subs[i].parent=newNode;}//此时进行修改Usize和新创建节点的父亲节点cur.Usize=cur.Usize-j-1;newNode.Usize=j;if(cur==root){root=new Node();root.keys[0]=cur.keys[mid];root.subs[0]=cur;root.subs[1]=newNode;root.Usize++;cur.parent=root;newNode.parent=root;return;}newNode.parent=parent;//此时开始对父亲节点开始操作int endT=parent.Usize-1;int midVal=cur.keys[mid];//采取的是直接插入for(;endT>=0;endT--){if (parent.keys[endT]>=midVal){parent.keys[endT+1]=parent.keys[endT];parent.subs[endT+2]=parent.subs[endT+1];}else {break;}}parent.keys[endT+1]=midVal;parent.subs[endT+2]=newNode;parent.Usize++;if(parent.Usize>=BT){Split(parent);}}
ok,B-树的整个插入操作就讲完啦
那么接下来的删除操作
删除
就讲下思路:
1.定位关键字
2.是否是叶子节点还算是非叶子节点
叶子节点,直接删除即可
非叶子节点
那么就要找到前驱节点(左树最大值节点)后继(右树最小值节点),进行替换删除
3.判断删除后的节点是否符合B树节点最少性质
如若不符合,那就要向兄弟节点借
如若兄弟节点不够,那么此时就要和兄弟节点进行合并。
关于更多详细操作讲解,可请看这篇操作
面试官问你 B树 和 B+ 树,就把这篇文章丢给他-腾讯云开发者社区-腾讯云
那么关于B-树相关操作小编就分享到这了。
这里额外简单分享下B+树
什么是B+树?
其实也是和B-树的定义差不多。
不同的是,就是叶子节点会形成一个链表,使其寻找效率会进一步提高。
举个例子:

那什么又是B*树呢?
B*树就是在B+树的基础上,再增加非叶子节点之间的联系。

从而再次进行优化。
完!
相关文章:
B-树:解锁大数据存储和与快速存储的密码
在我们学习数据结构的过程中,我们会学习到二叉搜索树、二叉平衡树、红黑树。 这些无一例外,是以一个二叉树展开的,那么对于我们寻找其中存在树中的数据,这个也是一个不错的方法。 但是,如若是遇到了非常大的数据容量…...

园区智能化系统实现管理与服务的智能化转型与创新进阶
内容概要 园区智能化系统的出现,标志着管理与服务向智能化转型的重要一步。这一系统不仅仅是一个技术解决方案,更是一个全面提升园区运营效率与安全性的独特工具。通过集成大数据分析、物联网和人工智能,园区智能化系统能够为各类园区如工业…...

【Java异步编程】CompletableFuture实现:异步任务的串行执行
文章目录 一. thenApply():转换计算结果1. 一个线程中执行或多个线程中执行2. 使用场景说明 二. thenRun():执行无返回值的操作1. 语法说明2. 使用场景说明 三. thenAccept():消费计算结果1. 语法说明a. 前后任务是否在一个线程中执行b. 要点…...

工业相机如何获得更好的图像色彩
如何获得更好的图像色彩 大部分的工业自动化检测中对物体的色彩信息并不敏感,因此会使用黑白的相机,但是在显微镜成像、颜色分类识别等领域,相机的色彩还原就显得格外重要,在调节相机色彩方面的参数时,有以下几个方面需…...

Python获取能唯一确定一棵给定的树的最少数量的拓扑序列
称一个 1 1 1~ n n n的排列 { p } { p 1 , p 2 , ⋯ , p n } \{p\}\{p_1,p_2,\cdots,p_n\} {p}{p1,p2,⋯,pn}是一棵n个点、点编号为 1 1 1至 n n n的树 T T T的拓扑序列,当且仅对于任意 1 ≤ i < n 1\leq i<n 1≤i<n,恰好存在唯一的 j &…...
PyTorch中的movedim、transpose与permute
在PyTorch中,movedim、transpose 和 permute这三个操作都可以用来重新排列张量(tensor)的维度,它们功能相似却又有所不同。 movedim 🔗 torch.movedim 用途:将张量的一个或多个维度移动到新的位置。参数&…...

C#面试常考随笔7:什么是匿名⽅法?还有Lambda表达式?
匿名方法本质上是一种没有显式名称的方法,它可以作为参数传递给需要委托类型的方法,常用于事件处理、回调函数等场景,能够让代码更加简洁和紧凑。 使用场景 事件处理:在处理事件时,不需要为每个事件处理程序单独定义…...

四、jQuery笔记
(一)jQuery概述 jQuery本身是js的一个轻量级的库,封装了一个对象jQuery,jquery的所有语法都在jQuery对象中 浏览器不认识jquery,只渲染html、css和js代码,需要先导入jQuery文件,官网下载即可 jQuery中文说明文档:https://hemin.cn/jq/ (二)jQuery要点 1、jQuery对象 …...

SQL进阶实战技巧:如何构建用户行为转移概率矩阵,深入洞察会话内活动流转?
目录 1 场景描述 1.1 用户行为转移概率矩阵概念 1.2 用户行为转移概率矩阵构建方法 (1) 数据收集...

TCP/IP 协议:互联网通信的基石
TCP/IP 协议:互联网通信的基石 引言 TCP/IP协议,全称为传输控制协议/互联网协议,是互联网上应用最为广泛的通信协议。它定义了数据如何在网络上传输,是构建现代互联网的基础。本文将深入探讨TCP/IP协议的原理、结构、应用以及其在互联网通信中的重要性。 TCP/IP 协议概述…...

第25节课:前端缓存策略—提升网页性能与用户体验
目录 前端缓存的重要性HTTP缓存HTTP缓存的基本原理常见的HTTP缓存头Cache-ControlExpiresETagLast-Modified HTTP缓存的类型强缓存协商缓存 服务端渲染与SSR服务端渲染(SSR)简介SSR的优势SSR的挑战实践:使用SSR框架构建Web应用Next.js安装Nex…...

完美世界C++游戏开发面试题及参考答案
堆栈数据结构有什么区别,举例说明 栈(Stack)和堆(Heap)是两种不同的数据结构,它们在多个方面存在显著区别: 存储方式 栈:栈是一种后进先出(LIFO)的数据结构,它的存储空间是连续的。栈由系统自动分配和释放,用于存储函数调用时的局部变量、函数参数、返回地址等信息…...

LabVIEW无人机航线控制系统
介绍了一种无人机航线控制系统,该系统利用LabVIEW软件与MPU6050九轴传感器相结合,实现无人机飞行高度、速度、俯仰角和滚动角的实时监控。系统通过虚拟仪器技术,有效实现了数据的采集、处理及回放,极大提高了无人机航线的控制精度…...
AtCoder Beginner Contest 391(ABCDE)
A - Lucky Direction 翻译: 给你一个字符串 D,代表八个方向(北、东、西、南、东北、西北、东南、西南)之一。方向与其代表字符串之间的对应关系如下。 北: N东: E西: W南: S东…...

MINIRAG: TOWARDS EXTREMELY SIMPLE RETRIEVAL-AUGMENTED GENERATION论文翻译
感谢阅读 注意不含评估以后的翻译原论文地址标题以及摘要介绍部分MiniRAG 框架2.1 HETEROGENEOUS GRAPH INDEXING WITH SMALL LANGUAGE MODELS2.2 LIGHTWEIGHT GRAPH-BASED KNOWLEDGE RETRIEVAL2.2.1 QUERY SEMANTIC MAPPING2.2.2 TOPOLOGY-ENHANCED GRAPH RETRIEVAL 注意不含评…...
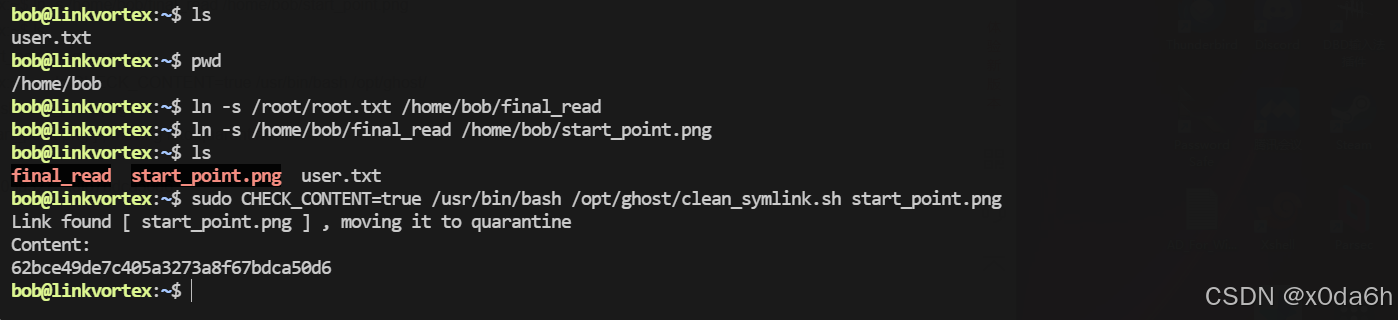
HTB:LinkVortex[WriteUP]
目录 连接至HTB服务器并启动靶机 信息收集 使用rustscan对靶机TCP端口进行开放扫描 使用nmap对靶机TCP开放端口进行脚本、服务扫描 使用nmap对靶机TCP开放端口进行漏洞、系统扫描 使用nmap对靶机常用UDP端口进行开放扫描 使用gobuster对靶机进行路径FUZZ 使用ffuf堆靶机…...

3D图形学与可视化大屏:什么是材质属性,有什么作用?
一、颜色属性 漫反射颜色 漫反射颜色决定了物体表面对入射光进行漫反射后的颜色。当光线照射到物体表面时,一部分光被均匀地向各个方向散射,形成漫反射。漫反射颜色的选择会直接影响物体在光照下的外观。例如,一个红色的漫反射颜色会使物体在…...

什么是门控循环单元?
一、概念 门控循环单元(Gated Recurrent Unit,GRU)是一种改进的循环神经网络(RNN),由Cho等人在2014年提出。GRU是LSTM的简化版本,通过减少门的数量和简化结构,保留了LSTM的长时间依赖…...

基于微信小程序的酒店管理系统设计与实现(源码+数据库+文档)
酒店管理小程序目录 目录 基于微信小程序的酒店管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、管理员模块的实现 (1) 用户信息管理 (2) 酒店管理员管理 (3) 房间信息管理 2、小程序序会员模块的实现 (1)系统首页 ÿ…...

Python-基于PyQt5,pdf2docx,pathlib的PDF转Word工具
前言:日常生活中,我们常常会跟WPS Office打交道。作表格,写报告,写PPT......可以说,我们的生活已经离不开WPS Office了。与此同时,我们在这个过程中也会遇到各种各样的技术阻碍,例如部分软件的PDF转Word需要收取额外费用等。那么,可不可以自己开发一个小工具来实现PDF转…...

Java-数据结构-优先级队列(堆)
一、优先级队列 ① 什么是优先级队列? 在此之前,我们已经学习过了"队列"的相关知识,我们知道"队列"是一种"先进先出"的数据结构,我们还学习过"栈",是"后进先出"的…...

爬虫基础(四)线程 和 进程 及相关知识点
目录 一、线程和进程 (1)进程 (2)线程 (3)区别 二、串行、并发、并行 (1)串行 (2)并行 (3)并发 三、爬虫中的线程和进程 &am…...

C语言初阶力扣刷题——349. 两个数组的交集【难度:简单】
1. 题目描述 力扣在线OJ题目 给定两个数组,编写一个函数来计算它们的交集。 示例: 输入:nums1 [1,2,2,1], nums2 [2,2] 输出:[2] 输入:nums1 [4,9,5], nums2 [9,4,9,8,4] 输出:[9,4] 2. 思路 直接暴力…...
)
Tailwind CSS - Tailwind CSS 引入(安装、初始化、配置、引入、构建、使用 Tailwind CSS)
一、Tailwind CSS 概述 Tailwind CSS 是一个功能优先的 CSS 框架,它提供了大量的实用类(utility classes),允许开发者通过组合这些类来快速构建用户界面 Tailwind CSS 与传统的 CSS 框架不同(例如,Bootstr…...

Sqoop导入MySQL中含有回车换行符的数据
个人博客地址:Sqoop导入MySQL中含有回车换行符的数据 MySQL中的数据如下图: 检查HDFS上的目标文件内容可以看出,回车换行符位置的数据被截断了,导致数据列错位。 Sqoop提供了配置参数,在导入时丢弃掉数据的分隔符&…...

LightM-UNet(2024 CVPR)
论文标题LightM-UNet: Mamba Assists in Lightweight UNet for Medical Image Segmentation论文作者Weibin Liao, Yinghao Zhu, Xinyuan Wang, Chengwei Pan, Yasha Wang and Liantao Ma发表日期2024年01月01日GB引用> Weibin Liao, Yinghao Zhu, Xinyuan Wang, et al. Ligh…...

stm32硬件实现与w25qxx通信
使用的型号为stm32f103c8t6与w25q64。 STM32CubeMX配置与引脚衔接 根据stm32f103c8t6引脚手册,采用B12-B15四个引脚与W25Q64连接,实现SPI通信。 W25Q64SCK(CLK)PB13MOSI(DI)PB15MISO(DO)PB14CS(…...

FPGA 使用 CLOCK_DEDICATED_ROUTE 约束
使用 CLOCK_DEDICATED_ROUTE 约束 CLOCK_DEDICATED_ROUTE 约束通常在从一个时钟区域中的时钟缓存驱动到另一个时钟区域中的 MMCM 或 PLL 时使 用。默认情况下, CLOCK_DEDICATED_ROUTE 约束设置为 TRUE ,并且缓存 /MMCM 或 PLL 对必须布局在相同…...

一个开源 GenBI AI 本地代理(确保本地数据安全),使数据驱动型团队能够与其数据进行互动,生成文本到 SQL、图表、电子表格、报告和 BI
一、GenBI AI 代理介绍(文末提供下载) github地址:https://github.com/Canner/WrenAI 本文信息图片均来源于github作者主页 在 Wren AI,我们的使命是通过生成式商业智能 (GenBI) 使组织能够无缝访问数据&…...

C动态库的生成与在Python和QT中的调用方法
目录 一、动态库生成 1)C语言生成动态库 2)c类生成动态库 二、动态库调用 1)Python调用DLL 2)QT调用DLL 三、存在的一些问题 1)python调用封装了类的DLL可能调用不成功 2)DLL格式不匹配的问题 四、…...