pytorch实现长短期记忆网络 (LSTM)
人工智能例子汇总:AI常见的算法和例子-CSDN博客
LSTM 通过 记忆单元(cell) 和 三个门控机制(遗忘门、输入门、输出门)来控制信息流:
记忆单元(Cell State)
- 负责存储长期信息,并通过门控机制决定保留或丢弃信息。
遗忘门(Forget Gate, ftf_tft)

输入门(Input Gate, iti_tit)

输出门(Output Gate, oto_tot)
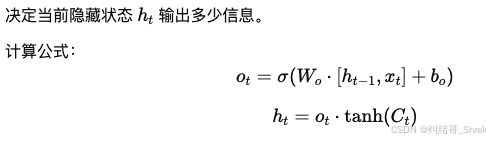
| 特性 | 传统 RNN | LSTM |
|---|---|---|
| 记忆能力 | 短期记忆 | 长短期记忆 |
| 计算复杂度 | 低 | 高 |
| 解决梯度消失 | 否 | 是 |
| 适用场景 | 短序列数据 | 长序列数据 |
LSTM 应用场景
- 自然语言处理(NLP):文本生成、情感分析、机器翻译
- 时间序列预测:股票预测、天气预报、传感器数据分析
- 语音识别:自动字幕生成、语音转文字(ASR)
- 机器人与控制系统:智能体决策、自动驾驶
例子:
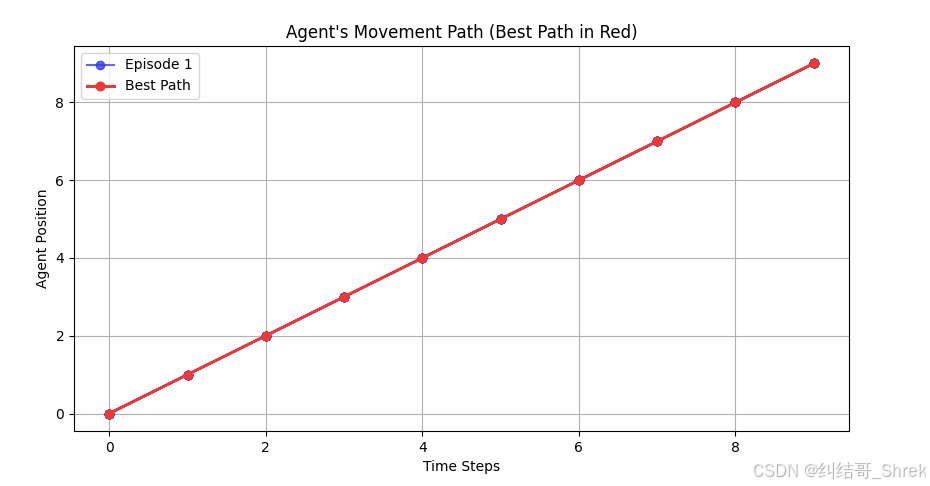
下面例子实现了一个 基于 LSTM 的强化学习智能体,在 1D 网格环境 里移动,并找到最优路径。
最终,我们 绘制 5 条测试路径,并高亮显示最佳路径(红色)
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt# ========== 1. 定义 LSTM 策略网络 ==========
class LSTMPolicy(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers=1):super(LSTMPolicy, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)self.softmax = nn.Softmax(dim=-1)def forward(self, x, hidden_state):batch_size = x.size(0)# 确保 hidden_state 维度正确if hidden_state[0].dim() == 2:hidden_state = (hidden_state[0].unsqueeze(1).repeat(1, batch_size, 1),hidden_state[1].unsqueeze(1).repeat(1, batch_size, 1))out, hidden_state = self.lstm(x, hidden_state)out = self.fc(out[:, -1, :]) # 取最后时间步的输出action_prob = self.softmax(out) # 归一化输出,作为策略return action_prob, hidden_statedef init_hidden(self, batch_size=1):return (torch.zeros(self.num_layers, batch_size, self.hidden_size),torch.zeros(self.num_layers, batch_size, self.hidden_size))# ========== 2. 创建网格环境 ==========
class GridWorld:def __init__(self, grid_size=10, goal_position=9):self.grid_size = grid_sizeself.goal_position = goal_positionself.reset()def reset(self):self.position = 0return self.positiondef step(self, action):if action == 0:self.position = max(0, self.position - 1)elif action == 1:self.position = min(self.grid_size - 1, self.position + 1)reward = 1 if self.position == self.goal_position else -0.1done = self.position == self.goal_positionreturn self.position, reward, done# ========== 3. 训练智能体 ==========
def train(num_episodes=500, max_steps=50):env = GridWorld()input_size = 1hidden_size = 64output_size = 2num_layers = 1policy = LSTMPolicy(input_size, hidden_size, output_size, num_layers)optimizer = optim.Adam(policy.parameters(), lr=0.01)gamma = 0.99for episode in range(num_episodes):state = torch.tensor([[env.reset()]], dtype=torch.float32).unsqueeze(0) # (1, 1, input_size)hidden_state = policy.init_hidden(batch_size=1)log_probs = []rewards = []for step in range(max_steps):action_probs, hidden_state = policy(state, hidden_state)action = torch.multinomial(action_probs, 1).item()log_prob = torch.log(action_probs.squeeze(0)[action])log_probs.append(log_prob)next_state, reward, done = env.step(action)rewards.append(reward)if done:breakstate = torch.tensor([[next_state]], dtype=torch.float32).unsqueeze(0)# 计算回报并更新策略returns = []R = 0for r in reversed(rewards):R = r + gamma * Rreturns.insert(0, R)returns = torch.tensor(returns, dtype=torch.float32)returns = (returns - returns.mean()) / (returns.std() + 1e-9)loss = sum([-log_prob * R for log_prob, R in zip(log_probs, returns)])optimizer.zero_grad()loss.backward()optimizer.step()if (episode + 1) % 50 == 0:print(f"Episode {episode + 1}/{num_episodes}, Total Reward: {sum(rewards)}")torch.save(policy.state_dict(), "policy.pth")# 训练智能体
train(500)# ========== 4. 测试智能体并绘制最佳路径 ==========
def test(num_episodes=5):env = GridWorld()input_size = 1hidden_size = 64output_size = 2num_layers = 1policy = LSTMPolicy(input_size, hidden_size, output_size, num_layers)policy.load_state_dict(torch.load("policy.pth"))plt.figure(figsize=(10, 5))best_path = Nonebest_steps = float('inf')for episode in range(num_episodes):state = torch.tensor([[env.reset()]], dtype=torch.float32).unsqueeze(0) # (1, 1, input_size)hidden_state = policy.init_hidden(batch_size=1)positions = [env.position] # 记录位置变化while True:action_probs, hidden_state = policy(state, hidden_state)action = torch.argmax(action_probs, dim=-1).item()next_state, reward, done = env.step(action)positions.append(next_state)if done:breakstate = torch.tensor([[next_state]], dtype=torch.float32).unsqueeze(0)# 记录最佳路径(最短步数)if len(positions) < best_steps:best_steps = len(positions)best_path = positions# 绘制普通路径(蓝色)plt.plot(range(len(positions)), positions, marker='o', linestyle='-', color='blue', alpha=0.6,label=f'Episode {episode + 1}' if episode == 0 else "")# 绘制最佳路径(红色)if best_path:plt.plot(range(len(best_path)), best_path, marker='o', linestyle='-', color='red', linewidth=2,label="Best Path")# 打印最佳路径print(f"Best Path (steps={best_steps}): {best_path}")plt.xlabel("Time Steps")plt.ylabel("Agent Position")plt.title("Agent's Movement Path (Best Path in Red)")plt.legend()plt.grid(True)plt.show()# 测试并绘制智能体移动路径
test(5)
相关文章:
pytorch实现长短期记忆网络 (LSTM)
人工智能例子汇总:AI常见的算法和例子-CSDN博客 LSTM 通过 记忆单元(cell) 和 三个门控机制(遗忘门、输入门、输出门)来控制信息流: 记忆单元(Cell State) 负责存储长期信息&…...

AI学习指南HuggingFace篇-模型部署与推理
一、引言 将训练好的模型部署为API并实现推理是将AI模型应用于实际场景的关键步骤。Hugging Face提供了多种工具和框架,支持快速部署和优化模型推理。本文将介绍如何将Hugging Face模型部署为API,探讨模型部署的常见方法和优化技巧,帮助读者将模型应用于实际场景。 二、模型…...

Games104——引擎工具链高级概念与应用
世界编辑器 其实是一个平台(hub),集合了所有能够制作地形世界的逻辑 editor viewport:可以说是游戏引擎的特殊视角,会有部分editor only的代码(不小心开放就会变成外挂入口)Editable Object&…...

【PyQt】学习PyQt进行GUI开发从基础到进阶逐步掌握详细路线图和关键知识点
学习PyQt的必要性 PyQt是开发跨平台GUI应用的强大工具,适合需要构建复杂、高性能界面的开发者。无论是职业发展还是项目需求,学习PyQt都具有重要意义。 1. 跨平台GUI开发 跨平台支持:PyQt基于Qt框架,支持Windows、macOS、Linux…...

消息队列应用示例MessageQueues-STM32CubeMX-FreeRTOS《嵌入式系统设计》P343-P347
消息队列 使用信号量、事件标志组和线标志进行任务同步时,只能提供同步的时刻信息,无法在任务之间进行数据传输。要实现任务间的数据传输,一般使用两种方式: 1. 全局变量 在 RTOS 中使用全局变量时,必须保证每个任务…...

Hive之数据定义DDL
Hive之数据定义DDL 文章目录 Hive之数据定义DDL写在前面创建数据库查询数据库显示数据库查看数据库详情切换当前数据库 修改数据库删除数据库创建表管理表(内部表)外部表管理表与外部表的互相转换 修改表重命名表增加、修改和删除表分区增加/修改/替换列信息 删除表 写在前面 …...

ROS-SLAM
基本概念 SLAM 即 Simultaneous Localization and Mapping,中文名为同时定位与地图构建,是机器人、自动驾驶、增强现实等领域中的关键技术。 在未知环境中,搭载特定传感器的主体(如机器人、无人机等)在运动过程中&am…...

网络攻防实战指北专栏讲解大纲与网络安全法
专栏 本专栏为网络攻防实战指北,大纲如下所示 进度:目前已更完准备篇、HTML基础 计划:所谓基础不牢,地动山摇。所以下一步将持续更新基础篇内容 讲解信息安全时,结合《中华人民共和国网络安全法》(以下简…...

Spark的基本概念
个人博客地址:Spark的基本概念 | 一张假钞的真实世界 编程接口 RDD:弹性分布式数据集(Resilient Distributed Dataset )。Spark2.0之前的编程接口。Spark2.0之后以不再推荐使用,而是被Dataset替代。Datasetÿ…...

效用曲线的三个实例
效用曲线的三个实例 文章目录 效用曲线的三个实例什么是效用曲线风险与回报:投资决策消费选择:价格与质量的平衡程序员绩效评估:准时与程序正确性 分析- 风险与回报:投资决策分析- 消费选择:价格与质量的平衡- 程序员绩…...

JavaScript面向对象编程:Prototype与Class的对比详解
JavaScript面向对象编程:Prototype与Class的对比详解 JavaScript面向对象编程:Prototype与Class的对比详解引言什么是JavaScript的面向对象编程?什么是Prototype?Prototype的定义Prototype的工作原理示例代码优点缺点 什么是JavaS…...

neo4j-community-5.26.0 create new database
1.edit neo4j.conf 把 # The name of the default database initial.dbms.default_databasehonglouneo4j # 写上自己的数据库名称 和 # Name of the service #5.0 server.windows_service_nameneo4j #4.0 dbms.default_databaseneo4j #dbms.default_databaseneo4jwind serve…...

pytorch实现门控循环单元 (GRU)
人工智能例子汇总:AI常见的算法和例子-CSDN博客 特性GRULSTM计算效率更快,参数更少相对较慢,参数更多结构复杂度只有两个门(更新门和重置门)三个门(输入门、遗忘门、输出门)处理长时依赖一般适…...

有没有个性化的UML图例
绿萝小绿萝 (53****338) 2012-05-10 11:55:45 各位大虾,有没有个性化的UML图例 绿萝小绿萝 (53****338) 2012-05-10 11:56:03 例如部署图或时序图的图例 潘加宇 (35***47) 2012-05-10 12:24:31 "个性化"指的是? 你的意思使用你自己的图标&…...

在CentOS服务器上部署DeepSeek R1
在CentOS服务器上部署DeepSeek R1,并通过公网IP与其进行对话,可以按照以下步骤操作: 一、环境准备 系统要求: CentOS 8+(需支持AVX512指令集)。 硬件配置: GPU版本:NVIDIA驱动520+,CUDA 11.8+。 CPU版本:至少16核处理器,64GB内存。 存储空间:原始模型需要30GB,量…...

Vue3.0实战:大数据平台可视化
文章目录 创建vue3.0项目项目初始化项目分辨率响应式设置项目顶部信息条创建页面主体创建全局引入echarts和axios后台接口创建express销售总量图实现完整项目下载项目任何问题都可在评论区,或者直接私信即可。 创建vue3.0项目 创建项目: vue create vueecharts选择第三项:…...

洛谷 P1130 红牌 C语言
题目描述 某地临时居民想获得长期居住权就必须申请拿到红牌。获得红牌的过程是相当复杂,一共包括 N 个步骤。每一步骤都由政府的某个工作人员负责检查你所提交的材料是否符合条件。为了加快进程,每一步政府都派了 M 个工作人员来检查材料。不幸的是&…...

语音识别播报人工智能分类垃圾桶(论文+源码)
2.1 需求分析 本次语音识别播报人工智能分类垃圾桶,设计功能要求如下∶ 1、具有四种垃圾桶,分别为用来回收厨余垃圾,有害垃圾,可回收垃圾,其他垃圾。 2、当用户语音说出“旧报纸”,“剩菜”等特定词语时…...

MVC、MVP和MVVM模式
MVC模式中,视图和模型之间直接交互,而MVP模式下,视图与模型通过Presenter进行通信,MVVM则采用双向绑定,减少手动同步视图和模型的工作。每种模式都有其优缺点,适合不同规模和类型的项目。 ### MVVM 与 MVP…...

shiro学习五:使用springboot整合shiro。在前面学习四的基础上,增加shiro的缓存机制,源码讲解:认证缓存、授权缓存。
文章目录 前言1. 直接上代码最后在讲解1.1 新增的pom依赖1.2 RedisCache.java1.3 RedisCacheManager.java1.4 jwt的三个类1.5 ShiroConfig.java新增Bean 2. 源码讲解。2.1 shiro 缓存的代码流程。2.2 缓存流程2.2.1 认证和授权简述2.2.2 AuthenticatingRealm.getAuthentication…...

负载均衡器高可用部署
Haproxy 和 Keepalived安装Haproxy配置文件准备Keepalived配置及健康检查启动Haproxy & Keepalived服务继续上一篇文章《K8S集群架构及主机准备》,下面介绍负载均衡器搭建过程 Haproxy 和 Keepalived安装 在负载均衡器两个主机上安装即可 apt install haproxy keepalived…...

属性编程与权限编程
问题 如何获取文件的大小,时间戳以及类型等信息? 再论 inode 文件的物理载体是硬盘,硬盘的最小存储单元是扇区 (每个扇区 512 字节) 文件系统以 块 为单位(每个块 8 个扇区) 管理文件数据 文件元信息 (创建者、创建日期、文件大小&#x…...

用 HTML、CSS 和 JavaScript 实现抽奖转盘效果
顺序抽奖 前言 这段代码实现了一个简单的抽奖转盘效果。页面上有一个九宫格布局的抽奖区域,周围八个格子分别放置了不同的奖品名称,中间是一个 “开始抽奖” 的按钮。点击按钮后,抽奖区域的格子会快速滚动,颜色不断变化…...

R语言绘制有向无环图(DAG)
有向无环图(Directed Acyclic Graph,简称DAG)是一种特殊的有向图,它由一系列顶点和有方向的边组成,其中不存在任何环路。这意味着从任一顶点出发,沿着箭头方向移动,你永远无法回到起始点。 从流…...

报错Too many open files
1、先查看系统最大打开文件数 # 查看当前系统打开文件最大数 # ulimit -a core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signal…...

Spring Web MVC基础第一篇
目录 1.什么是Spring Web MVC? 2.创建Spring Web MVC项目 3.注解使用 3.1RequestMapping(路由映射) 3.2一般参数传递 3.3RequestParam(参数重命名) 3.4RequestBody(传递JSON数据) 3.5Pa…...

129.求根节点到叶节点数字之和(遍历思想)
Problem: 129.求根节点到叶节点数字之和 文章目录 题目描述思路复杂度Code 题目描述 思路 遍历思想(利用二叉树的先序遍历) 直接利用二叉树的先序遍历,将遍历过程中的节点值先利用字符串拼接起来遇到根节点时再转为数字并累加起来,在归的过程中…...

unity中的动画混合树
为什么需要动画混合树,动画混合树有什么作用? 在Unity中,动画混合树(Animation Blend Tree)是一种用于管理和混合多个动画状态的工具,包括1D和2D两种类型,以下是其作用及使用必要性的介绍&…...

AWS EMR使用Apache Kylin快速分析大数据
在AWS Elastic MapReduce(EMR)集群上部署和使用Apache Kylin,以实现对大规模数据集的快速分析,企业可以充分利用云计算的强大资源和Kylin的数据分析能力,实现快速、高效的数据分析。以下是该案例的详细步骤和要点&…...
MySQL存储过程和存储函数_mysql 存储过 call proc_stat_data(3,null)
2)很难调试存储过程。只有少数数据库管理系统允许调试存储过程。不幸的是,MySQL不提供调试存储过程的功能。 1.2 数据准备 创建数据库: DEFAULT CHARACTER SET utf8; use test;这里记得设置编码! 创建测试表: DROP…...