使用朴素贝叶斯对散点数据进行分类
本文将通过一个具体的例子,展示如何使用 Python 和 scikit-learn 库中的 GaussianNB 模型,对二维散点数据进行分类,并可视化分类结果。
1. 数据准备
假设我们有两个类别的二维散点数据,每个类别包含若干个点。我们将这些点分别存储为 NumPy 数组,并为每个点分配一个类别标签。
import numpy as np# 类别 1 的点集
class1_points = np.array([[1.9, 1.2],[1.5, 2.1],[1.9, 0.5],[1.5, 0.9],[0.9, 1.2],[1.1, 1.7],[1.4, 1.1]])# 类别 2 的点集
class2_points = np.array([[3.2, 3.2],[3.7, 2.9],[3.2, 2.6],[1.7, 3.3],[3.4, 2.6],[4.1, 2.3],[3.0, 2.9]])# 合并数据
X = np.vstack((class1_points, class2_points))# 创建标签
y = np.array([0] * len(class1_points) + [1] * len(class2_points))2. 训练朴素贝叶斯模型
朴素贝叶斯分类器基于贝叶斯定理,假设特征之间相互独立。GaussianNB 是一种适用于连续数值型数据的朴素贝叶斯分类器,它假设每个特征的分布符合高斯分布。
from sklearn.naive_bayes import GaussianNB# 初始化朴素贝叶斯分类器
model = GaussianNB()# 训练模型
model.fit(X, y)3. 可视化分类结果
为了更好地理解模型的分类效果,我们可以绘制散点图,并显示决策边界。这有助于直观地观察模型如何区分两个类别。
import matplotlib.pyplot as plt# 创建网格点
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))# 预测网格点的类别
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)# 绘制决策边界和散点图
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Naive Bayes Decision Boundary')
plt.show()可视化结果展示:

4. 预测新数据点
训练好的模型可以用于对新的数据点进行分类。我们将提供一些新的数据点,并使用模型预测它们的类别。
# 新数据点
new_points = np.array([[2.0, 2.0],[3.5, 3.0]])# 预测新数据点的类别
new_predictions = model.predict(new_points)
print("New points predictions:", new_predictions)预测结果:

5. 完整代码
以下是完整的代码实现,包括数据准备、模型训练、可视化和新数据点的预测。
import numpy as np
from sklearn.naive_bayes import GaussianNB
import matplotlib.pyplot as plt# 类别 1 的点集
class1_points = np.array([[1.9, 1.2],[1.5, 2.1],[1.9, 0.5],[1.5, 0.9],[0.9, 1.2],[1.1, 1.7],[1.4, 1.1]])# 类别 2 的点集
class2_points = np.array([[3.2, 3.2],[3.7, 2.9],[3.2, 2.6],[1.7, 3.3],[3.4, 2.6],[4.1, 2.3],[3.0, 2.9]])# 合并数据
X = np.vstack((class1_points, class2_points))# 创建标签
y = np.array([0] * len(class1_points) + [1] * len(class2_points))# 初始化朴素贝叶斯分类器
model = GaussianNB()# 训练模型
model.fit(X, y)# 创建网格点
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))# 预测网格点的类别
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)# 绘制决策边界和散点图
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Naive Bayes Decision Boundary')
plt.show()# 新数据点
new_points = np.array([[2.0, 2.0],[3.5, 3.0]])# 预测新数据点的类别
new_predictions = model.predict(new_points)
print("New points predictions:", new_predictions)相关文章:
使用朴素贝叶斯对散点数据进行分类
本文将通过一个具体的例子,展示如何使用 Python 和 scikit-learn 库中的 GaussianNB 模型,对二维散点数据进行分类,并可视化分类结果。 1. 数据准备 假设我们有两个类别的二维散点数据,每个类别包含若干个点。我们将这些点分别存…...

【Pytorch和Keras】使用transformer库进行图像分类
目录 一、环境准备二、基于Pytorch的预训练模型1、准备数据集2、加载预训练模型3、 使用pytorch进行模型构建 三、基于keras的预训练模型四、模型测试五、参考 现在大多数的模型都会上传到huggface平台进行统一的管理,transformer库能关联到huggface中对应的模型&am…...

Python 深拷贝与浅拷贝:数据复制的奥秘及回溯算法中的应用
引言 在 Python 编程领域,数据复制是极为常见的操作。而深拷贝和浅拷贝这两个概念,如同紧密关联却又各具特色的双子星,在数据处理过程中扮演着重要角色。深入理解它们,不仅有助于编写出高效、准确的代码,还能避免许多…...

Node.js 和 npm 安装教程
Node.js 和 npm 安装教程 Node.js 和 npm 安装教程什么是 Node.js 和 npm?Node.jsnpm 安装前的注意事项在 Windows 上安装 Node.js 和 npm步骤 1:访问 Node.js 官网步骤 2:选择适合的版本步骤 3:下载安装包步骤 4:运行…...

简单易懂的倒排索引详解
文章目录 简单易懂的倒排索引详解一、引言 简单易懂的倒排索引详解二、倒排索引的基本结构三、倒排索引的构建过程四、使用示例1、Mapper函数2、Reducer函数 五、总结 简单易懂的倒排索引详解 一、引言 倒排索引是一种广泛应用于搜索引擎和大数据处理中的数据结构,…...

初级数据结构:栈和队列
目录 一、栈 (一)、栈的定义 (二)、栈的功能 (三)、栈的实现 1.栈的初始化 2.动态扩容 3.压栈操作 4.出栈操作 5.获取栈顶元素 6.获取栈顶元素的有效个数 7.检查栈是否为空 8.栈的销毁 9.完整代码 二、队列 (一)、队列的定义 (二)、队列的功能 (三)…...

在K8S中,pending状态一般由什么原因导致的?
在Kubernetes中,资源或Pod处于Pending状态可能有多种原因引起。以下是一些常见的原因和详细解释: 资源不足 概述:当集群中的资源不足以满足Pod或服务的需求时,它们可能会被至于Pending状态。这通常涉及到CPU、内存、存储或其他资…...

阿里云 - RocketMQ入门
前言 云消息队列 RocketMQ 版产品具备异步通信的优势,主要应用于【异步解耦】、【流量削峰填谷】等场景对于同步链路,需要实时返回调用结果的场景,建议使用RPC调用方案阿里云官网地址RocketMQ官网地址 模型概述 生产者生产消息并发送至服务…...

Agentic Automation:基于Agent的企业认知架构重构与数字化转型跃迁---我的AI经典战例
文章目录 Agent代理Agent组成 我在企业实战AI Agent企业痛点我构建的AI Agent App 项目开源 & 安装包下载 大家好,我是工程师令狐,今天想给大家讲解一下AI智能体,以及企业与AI智能体的结合,文章中我会列举自己在企业中Agent实…...

分享10个实用的Python工具的源码,支持定制
1.音频处理工具 【免费】一个功能丰富的音频处理工具箱,支持音频格式转换、剪辑和音量调节等功能资源-CSDN文库 2.视频转换工具 【免费】一个简单易用的视频格式转换工具,支持多种常见视频格式之间的转换资源-CSDN文库 3.PDF工具箱 【免费】一个功能…...

Denavit-Hartenberg DH MDH坐标系
Denavit-Hartenberg坐标系及其规则详解 6轴协作机器人的MDH模型详细图_6轴mdh-CSDN博客 N轴机械臂的MDH正向建模,及python算法_mdh建模-CSDN博客 运动学3-----正向运动学 | 鱼香ROS 机器人学:MDH建模 - 哆啦美 - 博客园 机械臂学习——标准DH法和改进MDH…...

WebPages 表单:设计与实现指南
WebPages 表单:设计与实现指南 引言 在当今的互联网时代,表单是WebPages与用户交互的重要手段。它不仅收集用户信息,还提供了一种便捷的交互方式。本文将详细介绍WebPages表单的设计与实现,旨在帮助开发者更好地理解并运用表单&…...

列表标签(无序列表、有序列表)
无序列表 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title> </head><…...

每天学点小知识之设计模式的艺术-策略模式
行为型模式的名称、定义、学习难度和使用频率如下表所示: 1.如何理解模板方法模式 模板方法模式是结构最简单的行为型设计模式,在其结构中只存在父类与子类之间的继承关系。通过使用模板方法模式,可以将一些复杂流程的实现步骤封装在一系列基…...

AI开发学习之——PyTorch框架
PyTorch 简介 PyTorch (Python torch)是由 Facebook AI 研究团队开发的开源机器学习库,广泛应用于深度学习研究和生产。它以动态计算图和易用性著称,支持 GPU 加速计算,并提供丰富的工具和模块。 PyTorch的主要特点 …...

SAP HCM insufficient authorization, no.skipped personnel 总结归纳
导读 权限:HCM模块中有普通权限和结构化权限。普通权限就是PFCG的权限,结构化权限就是按照部门ID授权,颗粒度更细,对分工明细化的单位尤其重要,今天遇到的问题就是结构化权限的问题。 作者:vivi,来源&…...

机器学习算法在网络安全中的实践
机器学习算法在网络安全中的实践 本文将深入探讨机器学习算法在网络安全领域的应用实践,包括基本概念、常见算法及其应用案例,从而帮助程序员更好地理解和应用这一领域的技术。"> 序言 网络安全一直是信息技术领域的重要议题,随着互联…...

DeepSeek V3 vs R1:大模型技术路径的“瑞士军刀“与“手术刀“进化
DeepSeek V3 vs R1:——大模型技术路径的"瑞士军刀"与"手术刀"进化 大模型分水岭:从通用智能到垂直突破 2023年,GPT-4 Turbo的发布标志着通用大模型进入性能瓶颈期。当模型参数量突破万亿级门槛后,研究者们开…...

STM32CUBEIDE编译的hex使用flymcu下载后不能运行
测试后确认,不论是1.10版本还是1.16版本,编译生成的hex下载后不能运行,需要更改boot 设置才能开始运行,flymcu下载后已经告知一切正常,跳转到8000 0000处开始运行,实际没有反应,而使用mdk编译生…...

图像噪声处理技术:让图像更清晰的艺术
在这个数字化时代,图像作为信息传递的重要载体,其质量直接影响着我们的视觉体验和信息解读。然而,在图像采集、传输或处理过程中,难免会遇到各种噪声干扰,如高斯噪声、椒盐噪声等,这些噪声会降低图像的清晰…...
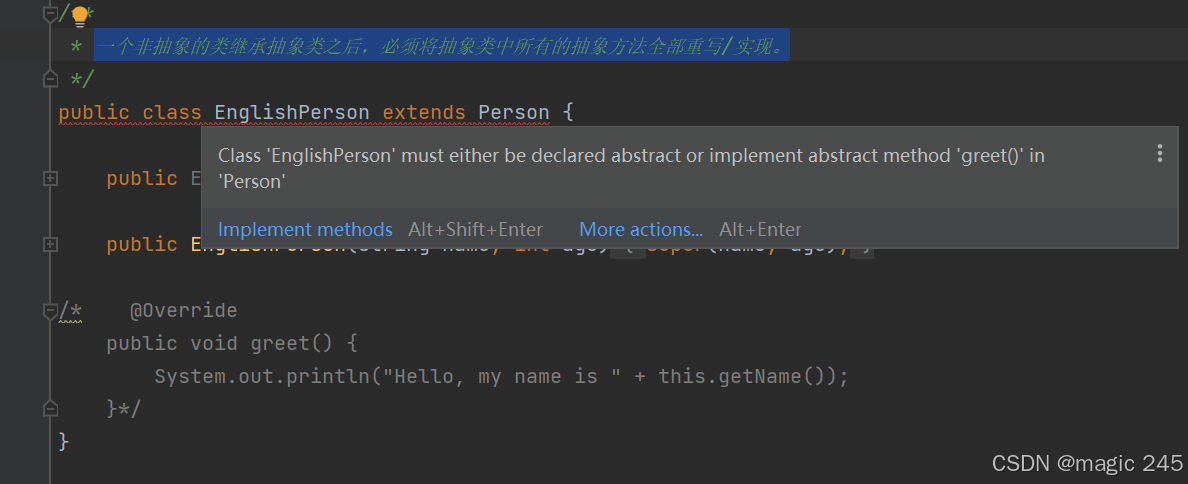
java-抽象类注意点
ChinesePerson 类 public class ChinesePerson extends Person{public ChinesePerson(){}public ChinesePerson(String name, int age){super(name, age);}Overridepublic void greet() {System.out.println("你好,我的名字叫" this.getName());} }Engl…...

【c++】类与对象详解
目录 面向过程思想和面向对象思想类的定义引入类的关键字类定义的两种方式类的访问限定符类的作用域类大小的计算封装 this指针类的6个默认成员函数构造函数初步理解构造函数深入理解构造函数初始化列表单参数构造函数引发的隐式类型转换 析构函数拷贝构造函数赋值运算符重载运…...
函数的使用问题)
MySQL的GROUP BY与COUNT()函数的使用问题
在MySQL中,GROUP BY和 COUNT()函数是数据聚合查询中非常重要的工具。正确使用它们可以有效地统计和分析数据。然而,不当的使用可能会导致查询结果不准确或性能低下。本文将详细讨论 GROUP BY和 COUNT()函数的使用方法及常见问题,并提供相应的…...

问deepseek,如何看待ai降低学习成本而导致软件开发岗位需求降低,和工资下降。 软件从业人员何去何从?
它给我的回答是这样的: 思考逻辑 嗯,用户问的是AI如何降低学习成本,进而导致软件开发岗位需求减少和工资下降,以及软件从业人员该怎么办。这个问题挺复杂的,我得先理清楚各个部分。首先,AI确实在改变很多行…...

Jason配置环境变量
jason官网 https://jason-lang.github.io/ https://github.com/jason-lang/jason/releases 步骤 安装 Java 21 或更高版本 安装 Visual Studio Code 根据操作系统,请按照以下具体步骤操作 视窗 下载 Jason 的最新版本,选择“jason-bin-3.3.0.zip”…...

word2vec 实战应用介绍
Word2Vec 是一种由 Google 在 2013 年推出的重要词嵌入模型,通过将单词映射为低维向量,实现了对自然语言处理任务的高效支持。其核心思想是利用深度学习技术,通过训练大量文本数据,将单词表示为稠密的向量形式,从而捕捉单词之间的语义和语法关系。以下是关于 Word2Vec 实战…...

AI技术在SEO关键词优化中的应用策略与前景展望
内容概要 在数字营销的快速发展中,AI技术逐渐成为SEO领域的核心驱动力。其通过强大的数据分析和处理能力,不仅改变了我们优化关键词的方式,也提升了搜索引擎优化的效率和效果。在传统SEO中,关键词的选择与组合常依赖人工经验和直…...

c/c++高级编程
1.避免变量冗余初始化 结构体初始化为0,等价于对该内存进行一次memset,对于较大的结构体或者热点函数,重复的赋值带来冗余的性能开销。现代编译器对此类冗余初始化代码具有一定的优化能力,因此,打开相关的编译选项的优…...

玩转Docker | 使用Docker部署MySQL数据库
玩转Docker | 使用Docker部署MySQL数据库 玩转Docker | 使用Docker部署MySQL数据库一、Docker简介(一)Docker是什么(二)Docker的优势二、准备工作(一)安装Docker(二)了解MySQL数据库三、使用Docker部署MySQL数据库(一)拉取MySQL镜像(二)运行MySQL容器(三)验证MyS…...

【网络】传输层协议TCP(重点)
文章目录 1. TCP协议段格式2. 详解TCP2.1 4位首部长度2.2 32位序号与32位确认序号(确认应答机制)2.3 超时重传机制2.4 连接管理机制(3次握手、4次挥手 3个标志位)2.5 16位窗口大小(流量控制)2.6 滑动窗口2.7 3个标志位 16位紧急…...