25寒假算法刷题 | Day1 | LeetCode 240. 搜索二维矩阵 II,148. 排序链表
目录
- 240. 搜索二维矩阵 II
- 题目描述
- 题解
- 148. 排序链表
- 题目描述
- 题解
240. 搜索二维矩阵 II
点此跳转题目链接
题目描述
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。
示例 1:

输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5
输出:true
示例 2:

输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20
输出:false
提示:
m == matrix.lengthn == matrix[i].length1 <= n, m <= 300-109 <= matrix[i][j] <= 109- 每行的所有元素从左到右升序排列
- 每列的所有元素从上到下升序排列
-109 <= target <= 109
题解
暴力算法直接遍历整个矩阵,时间复杂度为 O ( m n ) O(mn) O(mn) , m 、 n m、n m、n 分别为矩阵的行、列数。
由于题中矩阵在行和列上的元素都是升序的,所以想到可以从上到下逐行利用二分查找解决:
class Solution {
public:int binarySearch(const vector<int>& arr, int target) {int left = 0;int right = arr.size() - 1;while (left <= right) {int mid = left + (right - left) / 2;if (arr[mid] < target) {left = mid + 1;} else if (arr[mid] > target) {right = mid - 1;} else {return mid;}}return -1;}bool searchMatrix(vector<vector<int>>& matrix, int target) {if (matrix.empty()) {return false;}// 逐行使用二分法查找targetfor (const vector<int>& line : matrix) {if (binarySearch(line, target) != -1) {return true;}}return false;}
};
行内 n n n 个元素做二分查找的时间复杂度为 O ( l o g n ) O(logn) O(logn) ,共 m m m 行,故时间复杂度为 O ( m l o g n ) O(mlogn) O(mlogn) 。
不过上面两种方法似乎都过于直白简单了,考虑到这个题目带的是“中等”tag,肯定还有更高效的算法:
🔗 以下内容来自 LeetCode官方题解
我们可以从矩阵 matrix 的右上角 (0,n−1) 进行搜索。在每一步的搜索过程中,如果我们位于位置 (x,y) ,那么我们希望在以 matrix 的左下角为左下角、以 (x,y) 为右上角的矩阵中进行搜索,即行的范围为 [x,m−1] ,列的范围为 [0,y] :
- 如果
matrix[x,y]=target,说明搜索完成 - 如果
matrix[x,y]>target,由于每一列的元素都是升序排列的,那么在当前的搜索矩阵中,所有位于第y列的元素都是严格大于target的,因此我们可以将它们全部忽略,即将y减少 1 - 如果
matrix[x,y]<target,由于每一行的元素都是升序排列的,那么在当前的搜索矩阵中,所有位于第x行的元素都是严格小于target的,因此我们可以将它们全部忽略,即将x增加 1。
在搜索的过程中,如果我们超出了矩阵的边界,那么说明矩阵中不存在 target 。代码实现如下:
class Solution {
public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int x = 0;int y = matrix[0].size() - 1;while (x < matrix.size() && y >= 0) {if (matrix[x][y] < target) {x++;} else if (matrix[x][y] > target) {y--;} else {return true;}}return false;}
};
时间复杂度: O ( m + n ) O(m+n) O(m+n) 。在搜索的过程中,如果我们没有找到 target ,那么我们要么将 y 减少 1,要么将 x 增加 1。由于 (x,y) 的初始值分别为 (0,n−1) ,因此 y 最多能被减少 n 次, x 最多能被增加 m 次,总搜索次数为 m+n 。在这之后, x 和 y 就会超出矩阵的边界。
148. 排序链表
点此跳转题目链接
题目描述
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:

输入:head = [4,2,1,3]
输出:[1,2,3,4]
示例 2:
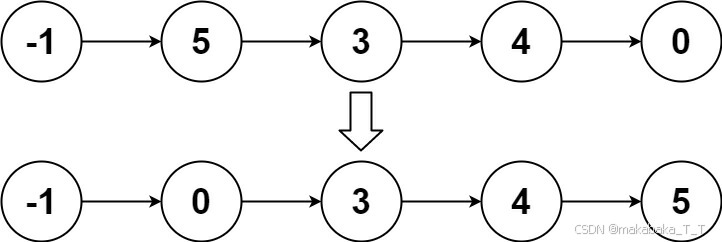
输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
示例 3:
输入:head = []
输出:[]
提示:
- 链表中节点的数目在范围
[0, 5 * 104]内 -105 <= Node.val <= 105
进阶: 你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
题解
暴力解法无需多言,遍历一遍链表获取全部元素、排序后重新整一个新链表即可:
struct ListNode
{int val;ListNode *next;ListNode() : val(0), next(nullptr) {}ListNode(int x) : val(x), next(nullptr) {}ListNode(int x, ListNode *next) : val(x), next(next) {}
};class Solution {
public:ListNode* sortList(ListNode* head) {vector<int> elements;while (head){elements.push_back(head->val);head = head->next;}sort(elements.begin(), elements.end());ListNode *dummyHead = new ListNode();ListNode *cur = dummyHead;for (int element : elements) {cur->next = new ListNode(element);cur = cur->next;}return dummyHead->next;}
};
上述算法时间复杂度为 sort() 的 O ( n log n ) O(n\log{n}) O(nlogn) ,空间复杂度为 O ( n ) O(n) O(n) ——因为新建了一个链表。 直接看看进阶要求:时间复杂度为 O ( n log n ) O(n\log{n}) O(nlogn) ,空间复杂度为常数级。
考虑算法题中常用的高效排序算法——归并排序,有:
class Solution {
public:ListNode *merge(ListNode *L, ListNode *R) {ListNode dummyHead;ListNode *cur = &dummyHead;while (L && R) {if (L->val < R->val) {cur->next = L;L = L->next;} else {cur->next = R;R = R->next;}cur = cur->next;}cur->next = L ? L : R;return dummyHead.next;}ListNode *sortList(ListNode *head, ListNode *tail) {if (!head || head == tail) return head;// 快慢指针找到链表中点ListNode *slow = head, *fast = head;while (fast != tail && fast->next != tail) {slow = slow->next;fast = fast->next->next;}ListNode *mid = slow->next;slow->next = nullptr; // 断开链表return merge(sortList(head, slow), sortList(mid, tail));}ListNode *sortList(ListNode *head) { return sortList(head, nullptr); }
};
上述算法时间复杂度为 O ( n log n ) O(n\log{n}) O(nlogn) ,即归并排序的时间复杂度。空间复杂度取决于递归调用的栈空间,为 O ( log n ) O(\log{n}) O(logn) ,还是没到最佳的常数级别。为此,需要采用“自底向上”的归并排序实现 O ( 1 ) O(1) O(1) 的空间复杂度:
🔗 以下内容参考 LeetCode官方题解
首先求得链表的长度 length ,然后将链表拆分成子链表进行合并。具体做法如下:
- 用
subLength表示每次需要排序的子链表的长度,初始时subLength=1。 - 每次将链表拆分成若干个长度为
subLength的子链表(最后一个子链表的长度可以小于subLength),按照每两个子链表一组进行合并,合并后即可得到若干个长度为subLength×2的有序子链表(最后一个子链表的长度可以小于subLength×2)。合并两个子链表仍然使用之前用过的归并算法。 - 将
subLength的值加倍,重复第 2 步,对更长的有序子链表进行合并操作,直到有序子链表的长度大于或等于length,整个链表排序完毕。
通过数学归纳法易证最后得到的链表是有序的(每次合并用到的子链表是有序的,合并后的也是有序的)。
class Solution {
public:ListNode *merge(ListNode *L, ListNode *R) {ListNode dummyHead;ListNode *cur = &dummyHead;while (L && R) {if (L->val < R->val) {cur->next = L;L = L->next;} else {cur->next = R;R = R->next;}cur = cur->next;}cur->next = L ? L : R;return dummyHead.next;}ListNode *sortList(ListNode *head) {if (!head) {return nullptr;}// 获取链表长度int length = 0;ListNode *cur = head;while (cur != nullptr) {length++;cur = cur->next;}// 自底向上,两两合并长度为subLength的子链表ListNode *dummyHead = new ListNode(0, head);for (int subLength = 1; subLength < length; subLength <<= 1) {ListNode *prev = dummyHead;cur = prev->next;while (cur != nullptr) {// 获取第一个子链表ListNode *head1 = cur;for (int i = 1; i < subLength && cur->next != nullptr; ++i) {cur = cur->next;}// 获取第二个子链表ListNode *head2 = cur->next;cur->next = nullptr; // 断开第一个子链表结尾cur = head2;for (int i = 1; i < subLength && cur && cur->next; ++i) {cur = cur->next;}// 预存第三个子链表(即下一轮的第一个子链表)的头节点// 即第二个子链表结尾节点的next节点ListNode *nextHead = nullptr;if (cur != nullptr) {nextHead = cur->next;cur->next = nullptr; // 断开第二个子链表结尾}// 合并第一、二个子链表ListNode *merged = merge(head1, head2);// 更新prev、cur指针prev->next = merged;while (prev->next != nullptr) {prev = prev->next;}cur = nextHead;}}return dummyHead->next;}
};
该算法时间复杂度为 O ( n log n ) O(n \log{n}) O(nlogn) ,空间复杂度为 O ( 1 ) O(1) O(1) 。
相关文章:
25寒假算法刷题 | Day1 | LeetCode 240. 搜索二维矩阵 II,148. 排序链表
目录 240. 搜索二维矩阵 II题目描述题解 148. 排序链表题目描述题解 240. 搜索二维矩阵 II 点此跳转题目链接 题目描述 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。每列的元素从上到…...

[paddle] 矩阵相关的指标
行列式 det 行列式定义参考 d e t ( A ) ∑ i 1 , i 2 , ⋯ , i n ( − 1 ) σ ( i 1 , ⋯ , i n ) a 1 , i 1 a 2 , i 2 , ⋯ , a n , i n det(A) \sum_{i_1,i_2,\cdots,i_n } (-1)^{\sigma(i_1,\cdots,i_n)} a_{1,i_1}a_{2,i_2},\cdots, a_{n,i_n} det(A)i1,i2,⋯,in…...

何谓共赢?
A和B是人或组织,他们怎样的合作才是共赢呢? 形态1:A提供自己的身份证等个人信息,B用来作贷款等一些事务,A每月得到一笔钱。 A的风险远大于收益,或者B从事的是非法行为; 形态2:A单方面提前终止了与B的合作…...

Kanass基础教程-创建项目
Kanass是一款国产开源免费的项目管理工具,工具简洁易用,开源免费,之前介绍过kanass的一些产品简介及安装配置方法,本文就从如何创建第一个项目来开始kanass上手之旅吧。 1. 创建项目 点击项目->项目添加 按钮进入项目添加页面…...
实验9 JSP访问数据库(二)
实验9 JSP访问数据库(二) 目的: 1、熟悉JDBC的数据库访问模式。 2、掌握预处理语句的使用 实验要求: 1、使用Tomcat作为Web服务器 2、通过JDBC访问数据库,实现增删改查功能的实现 3、要求提交实验报告,将代…...

DeepSeek 核心技术全景解析
DeepSeek 核心技术全景解析:突破性创新背后的设计哲学 DeepSeek的创新不仅仅是对AI基础架构的改进,更是一场范式革命。本文将深入剖析其核心技术,探讨 如何突破 Transformer 计算瓶颈、如何在 MoE(Mixture of Experts)…...

单片机基础模块学习——DS1302时钟芯片
一、DS1302时钟简介 1.与定时器对比 DS1302时钟也称为RTC时钟(Real Time Clock,实时时钟),说到时钟,可能会想到定时器,下表来简单说明一下两者的区别。 定时器(Timer)实时时钟(RTC)精度高,可达微秒级精度较低,多为秒级计时范围短计时范围长2.开发板所在位置 下面方框里…...

Vue+Echarts 实现青岛自定义样式地图
一、效果 二、代码 <template><div class"chart-box"><chart ref"chartQingdao" style"width: 100%; height: 100%;" :options"options" autoresize></chart></div> </template> <script> …...

FIR滤波器:窗函数法
一、FIR滤波器基础 FIR(有限脉冲响应)滤波器的三大特点: 绝对稳定:没有反馈回路,不会出现失控振荡 线性相位:信号通过后波形不失真 直观设计:通过窗函数法、频率采样法等方法实现 二、窗函…...

【AI】探索自然语言处理(NLP):从基础到前沿技术及代码实践
Hi ! 云边有个稻草人-CSDN博客 必须有为成功付出代价的决心,然后想办法付出这个代价。 目录 引言 1. 什么是自然语言处理(NLP)? 2. NLP的基础技术 2.1 词袋模型(Bag-of-Words,BoWÿ…...

M|哪吒之魔童闹海
rating: 8.5 豆瓣: 8.5 上映时间: “2025” 类型: M动画 导演: 饺子 主演: 国家/地区: 中国大陆 片长/分钟: 144分钟 M|哪吒之魔童闹海 制作精良,除了剧情逻辑有一点瑕疵,各方面都很到位。总体瑕不掩瑜。 上映时间: &…...

DeepSeek 介绍及对外国的影响
DeepSeek 简介 DeepSeek(深度求索)是一家专注实现 AGI(人工通用智能)的中国科技公司,2023 年成立,总部位于杭州,在北京设有研发中心。与多数聚焦具体应用(如人脸识别、语音助手&…...

力扣动态规划-18【算法学习day.112】
前言 ###我做这类文章一个重要的目的还是记录自己的学习过程,我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非常非常高滴!!! 习题 1.下降路径最小和 题目链接:931. …...

DBASE DBF数据库文件解析
基于Java实现DBase DBF文件的解析和显示 JDK19编译运行,实现了数据库字段和数据解析显示。 首先解析数据库文件头代码 byte bytes[] Files.readAllBytes(Paths.get(file));BinaryBufferArray bis new BinaryBufferArray(bytes);DBF dbf new DBF();dbf.VersionN…...

【ESP32】ESP-IDF开发 | WiFi开发 | UDP用户数据报协议 + UDP客户端和服务器例程
1. 简介 UDP协议(User Datagram Protocol),全称用户数据报协议,它是一种面向非连接的协议,面向非连接指的是在正式通信前不必与对方先建立连接, 不管对方状态就直接发送。至于对方是否可以接收到这些数据内…...

【Qt】常用的容器
Qt提供了多个基于模板的容器类,这些容器类可用于存储指定类型的数据项。例如常用的字符串列表类 QStringList 可用来操作一个 QList<QString>列表。 Qt的容器类比标准模板库(standard template library,STL)中的容器类更轻巧、使用更安全且更易于使…...

tiktok 国际版抖抖♬♬ X-Bogus参数算法逆向分析
加密请求参数得到乱码,最终得到X-Bogus...

【AI】人工智能没那么神秘!
AI是什么? 人工智能(Artificial Intelligence),英文缩写为AI。 AI人工智能不是简单的应用程序,而是一类技术,包含机器学习、自然语言处理、计算机视觉等多个领域。AI系统通常由算法、数据、模型和代码组成…...

C#面试常考随笔9:什么是闭包?
最简单的例子: Lambda可以访问Lambda表达式块外部的变量,叫闭包。 定义 闭包是指有权访问另一个函数作用域中的变量的函数。即使该函数已经执行完毕,其作用域内的变量也不会被销毁,而是会被闭包所捕获并保留,供闭包…...
)
记录 | 基于MaxKB的仿小红书旅游文章AI制作(含图文、视频)
目录 前言一、创建应用Step1 表单Step2 AI对话生成旅游攻略提炼场景Step3 图片生成Step4 视频生成Step5 指定回复二、检验效果三、整体结构视图更新时间前言 参考文章: 自己的感想 想复现文章的内容你需要先学习下我之前的三篇文章中的记录。 1、记录 | Docker的windows版安装…...

C++ Primer 命名空间的using声明
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...

c语言(关键字)
前言: 感谢b站鹏哥c语言 内容: 栈区(存放局部变量) 堆区 静态区(存放静态变量) rigister关键字 寄存器,cpu优先从寄存器里边读取数据 #include <stdio.h>//typedef,类型…...

Kafka SASL/SCRAM介绍
文章目录 Kafka SASL/SCRAM介绍1. SASL/SCRAM 认证机制2. SASL/SCRAM 认证工作原理2.1 SCRAM 认证原理2.1.1 密码存储和加盐2.1.2 SCRAM 认证流程 2.2 SCRAM 认证的关键算法2.3 SCRAM 密码存储2.4 SCRAM 密码管理 3. 配置和使用 Kafka SASL/SCRAM3.1 Kafka 服务器端配置3.2 创建…...

ARM内核:嵌入式时代的核心引擎
引言 在当今智能设备无处不在的时代,ARM(Advanced RISC Machines)处理器凭借其高性能、低功耗的特性,成为智能手机、物联网设备、汽车电子等领域的核心引擎。作为精简指令集(RISC)的典范,ARM核…...

一文大白话讲清楚webpack进阶——8——Module Federation
文章目录 一文大白话讲清楚webpack进阶——8——Module Federation1. 啥是Module Federation2. 这里讲两个基础概念3. 容器应用配置4. 远程应用配置5. 模块使用5. ModuleFederation好在哪里6. ModuleFederation实战 一文大白话讲清楚webpack进阶——8——Module Federation 1.…...

Airflow:选择合适执行器扩展任务执行
Apache Airflow是面向开发人员使用的,以编程方式编写、调度和监控的数据流程平台。可伸缩性是其关键特性之一,Airflow支持使用不同的执行器来执行任务。在本文中,我们将深入探讨如何利用这些执行器在Airflow中有效地扩展任务执行。 理解Airfl…...

DeepSeek-R1 论文. Reinforcement Learning 通过强化学习激励大型语言模型的推理能力
论文链接: [2501.12948] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 实在太长,自行扔到 Model 里,去翻译去提问吧。 工作原理: 主要技术,就是训练出一些专有用途小模型&…...

CoRAG 来自微软与人大的创新RAG框架技术
微软与人大合作开发的CoRAG(Chain-of-Retrieval Augmented Generation)是一种创新的检索增强生成(RAG)框架,旨在通过模拟人类思考方式来提升大语言模型(LLM)在复杂问题上的推理和回答能力。以下是对CoRAG的深度介绍: 1. CoRAG的核心理念 CoRAG的核心思想是通过动态调…...

Qt Creator 中使用 vcpkg
Qt Creator 中使用 vcpkg Qt Creator 是一个跨平台的轻量级 IDE,做 Qt 程序开发的同学们肯定对这个 IDE 都比较属于。这个 IDE 虽然没有 Visual Stdio 功能那么强,但是由于和 Qt 集成的比较深,用来开发 Qt 程序还是很顺手的。 早期…...

mysql中in和exists的区别?
大家好,我是锋哥。今天分享关于【mysql中in和exists的区别?】面试题。希望对大家有帮助; mysql中in和exists的区别? 在 MySQL 中,IN 和 EXISTS 都是用于子查询的操作符,但它们在执行原理和适用场景上有所不…...