用Python实现K均值聚类算法
在数据挖掘和机器学习领域,聚类是一种常见的无监督学习方法,用于将数据点划分为不同的组或簇。K均值聚类算法是其中一种简单而有效的聚类算法。今天,我将通过一个具体的Python代码示例,向大家展示如何实现K均值聚类算法,并通过可视化的方式呈现聚类过程。
1. K均值聚类算法简介
K均值聚类算法是一种划分方法,它将数据集划分为K个簇。算法的基本思想是:首先随机选择K个数据点作为初始聚类中心,然后计算每个数据点与这些聚类中心的距离,将数据点分配到最近的聚类中心所在的簇中。接着,根据每个簇中的数据点重新计算聚类中心,重复上述过程,直到聚类中心不再发生变化或达到设定的迭代次数。
2. 数据准备
在本例中,我们手动创建了四类数据点,每类数据点都具有一定的分布规律。这些数据点将作为我们聚类的对象。以下是数据点的代码定义:
class1_points = np.array([[1.9, 1.2],[1.5, 2.1],[1.9, 0.5],[1.5, 0.9],[0.9, 1.2],[1.1, 1.7],[1.4, 1.1]])class2_points = np.array([[-1.9, 1.2],[-1.5, 2.1],[-1.9, 0.5],[-1.5, 0.9],[-0.9, 1.2],[-1.1, 1.7],[-1.4, 1.1]])class3_points = np.array([[1.9, -1.2],[1.5, -2.1],[1.9, -0.5],[1.5, -0.9],[0.9, -1.2],[1.1, -1.7],[1.4, -1.1]])class4_points = np.array([[-1.9, -1.2],[-1.5, -2.1],[-1.9, -0.5],[-1.5, -0.9],[-0.9, -1.2],[-1.1, -1.7],[-1.4, -1.1]])我们将这四类数据点合并为一个数据集,用于后续的聚类操作:
data = np.concatenate((class1_points,class2_points,class3_points,class4_points))3. 聚类过程实现
3.1 初始化聚类中心
我们设定聚类数目为2(k = 2),并从数据集中随机选择两个数据点作为初始聚类中心:
centroids = data[np.random.choice(range(len(data)),k,replace=False)]3.2 迭代聚类
在每次迭代中,我们执行以下步骤:
3.2.1 计算距离
计算每个数据点与聚类中心的距离。这里使用了欧几里得距离:
distances = np.linalg.norm(data[:,np.newaxis,:]-centroids,axis=2)3.2.2 分配数据点到最近的聚类中心
根据计算出的距离,将每个数据点分配到最近的聚类中心所在的簇中:
labels = np.argmin(distances,axis=1)3.2.3 更新聚类中心
根据每个簇中的数据点,重新计算聚类中心:
new_centroids = np.array([data[labels == i].mean(axis = 0) for i in range(k)])3.3 聚类结果可视化
在每次迭代中,我们通过matplotlib库绘制数据点、聚类中心以及数据点与聚类中心的连接线,以直观地展示聚类过程:
plt.cla()
# 绘制连接线
for i in range(k):cluster_points = data[labels == i]centroid = centroids[i]for cluster_point in cluster_points:plt.plot([cluster_point[0], centroid[0]], [cluster_point[1], centroid[1]], 'k--')# 绘制四类点,并分别用不同颜色标出来
plt.scatter(class1_points[:, 0], class1_points[:, 1], c="red")
plt.scatter(class2_points[:, 0], class2_points[:, 1], c="blue")
plt.scatter(class3_points[:, 0], class3_points[:, 1], c="cyan")
plt.scatter(class4_points[:, 0], class4_points[:, 1], c="green")# 绘制聚类中心点,并用圆圈标记
plt.scatter(centroids[:, 0], centroids[:, 1], c="black", marker='o', s=100, label='Centroids')
plt.pause(1)3.4 判断收敛
如果新计算的聚类中心与上一次的聚类中心完全相同,说明算法已经收敛,可以结束迭代:
if np.all(centroids == new_centroids):break
centroids = new_centroids4. 运行结果
运行上述代码后,你将看到一个动态的聚类过程展示。数据点会逐渐被分配到不同的簇中,聚类中心也会不断调整,直到最终收敛。
由于点位是随机选取,所以可能会有不同的聚类结果:

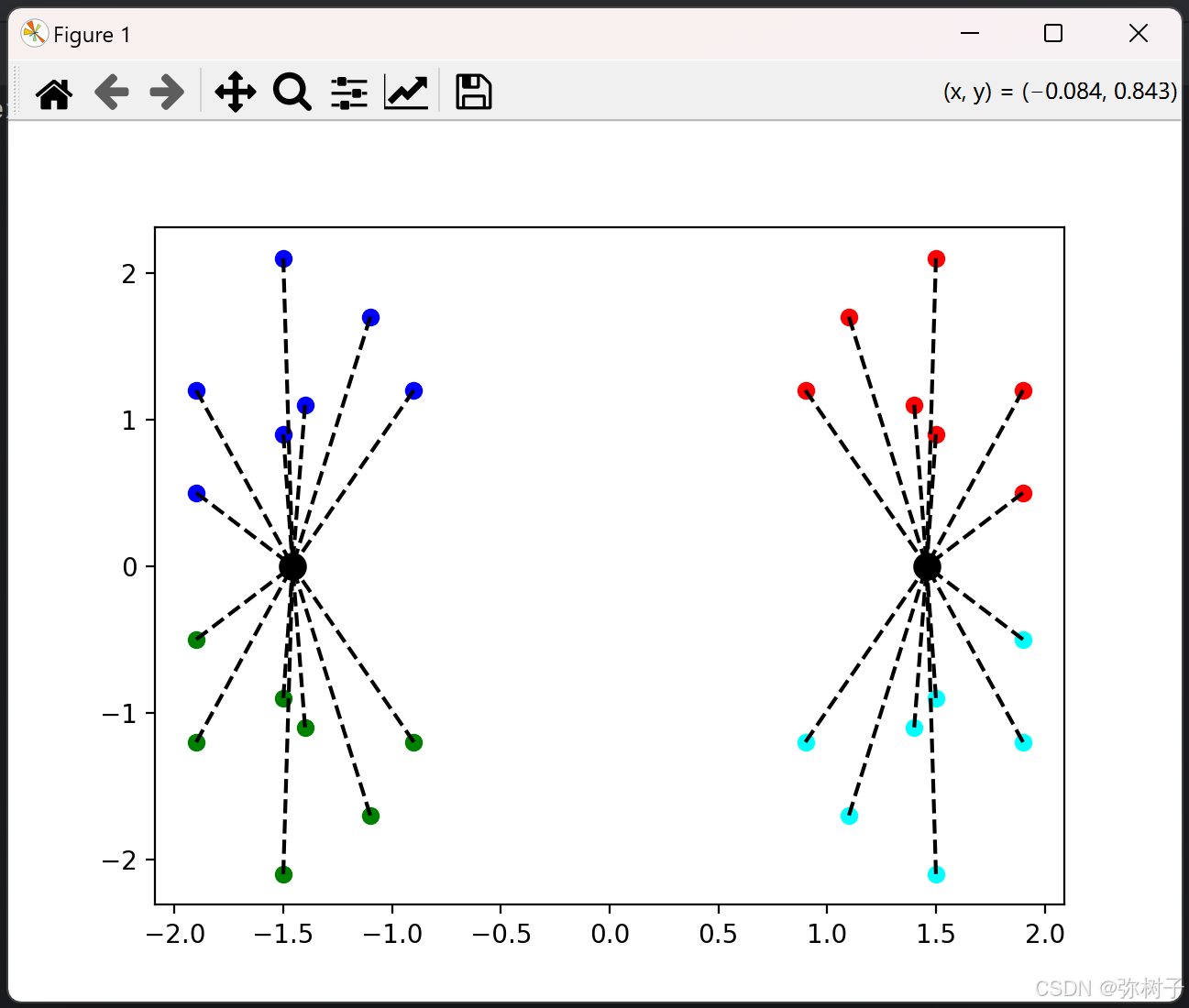
5.完整代码
import numpy as np
import matplotlib.pyplot as plt"""数学方法实现k均值聚类"""
# 创建示例数据
class1_points = np.array([[1.9, 1.2],[1.5, 2.1],[1.9, 0.5],[1.5, 0.9],[0.9, 1.2],[1.1, 1.7],[1.4, 1.1]])class2_points = np.array([[-1.9, 1.2],[-1.5, 2.1],[-1.9, 0.5],[-1.5, 0.9],[-0.9, 1.2],[-1.1, 1.7],[-1.4, 1.1]])class3_points = np.array([[1.9, -1.2],[1.5, -2.1],[1.9, -0.5],[1.5, -0.9],[0.9, -1.2],[1.1, -1.7],[1.4, -1.1]])class4_points = np.array([[-1.9, -1.2],[-1.5, -2.1],[-1.9, -0.5],[-1.5, -0.9],[-0.9, -1.2],[-1.1, -1.7],[-1.4, -1.1]])#合并四类数据点
data = np.concatenate((class1_points,class2_points,class3_points,class4_points))
# 设置聚类数目
k = 2# 迭代次数
max_iterations = 1000# 从一维 数组 range(len(data)) 中选出 k个元素 replace=False同一个元素只能被选取一次
centroids = data[np.random.choice(range(len(data)),k,replace=False)]
#创建图形窗口
plt.figure()#开始迭代
for a in range(max_iterations):# 3、计算每个数据点与聚类中心的距离distances = np.linalg.norm(data[:,np.newaxis,:]-centroids,axis=2)# 4、更新聚类中心# 分配每个数据点到最近的聚类中心labels = np.argmin(distances,axis=1)#更新新的中心new_centroids = np.array([data[labels == i].mean(axis = 0) for i in range(k)])plt.cla()# 绘制连接线for i in range(k):cluster_points = data[labels == i]centroid = centroids[i]for cluster_point in cluster_points:plt.plot([cluster_point[0], centroid[0]], [cluster_point[1], centroid[1]], 'k--')# 绘制四类点,并分别用不同颜色标出来plt.scatter(class1_points[:, 0], class1_points[:, 1], c="red")plt.scatter(class2_points[:, 0], class2_points[:, 1], c="blue")plt.scatter(class3_points[:, 0], class3_points[:, 1], c="cyan")plt.scatter(class4_points[:, 0], class4_points[:, 1], c="green")# 绘制聚类中心点,并用圆圈标记plt.scatter(centroids[:, 0], centroids[:, 1], c="black", marker='o', s=100, label='Centroids')plt.pause(1)# 显示图形# 如果新聚类中心与旧聚类中心相同,则收敛,结束迭代# np.all判断给定轴向上的所有元素是否都为Trueif np.all(centroids == new_centroids):break#更新聚类中心centroids = new_centroids
plt.show()相关文章:
用Python实现K均值聚类算法
在数据挖掘和机器学习领域,聚类是一种常见的无监督学习方法,用于将数据点划分为不同的组或簇。K均值聚类算法是其中一种简单而有效的聚类算法。今天,我将通过一个具体的Python代码示例,向大家展示如何实现K均值聚类算法࿰…...

Flask代码审计实战
文章目录 Flask代码审计SQL注入命令/代码执行反序列化文件操作XXESSRFXSS其他 审计实战后记reference Flask代码审计 SQL注入 1、正确的使用直白一点就是:使用”逗号”,而不是”百分号” stmt "SELECT * FROM table WHERE id?" connectio…...

Unity 2D实战小游戏开发跳跳鸟 - 跳跳鸟碰撞障碍物逻辑
在有了之前创建的可移动障碍物之后,就可以开始进行跳跳鸟碰撞到障碍物后死亡的逻辑,死亡后会产生一个对应的效果。 跳跳鸟碰撞逻辑 创建Obstacle Tag 首先跳跳鸟在碰撞到障碍物时,我们需要判定碰撞到的是障碍物,可以给障碍物的Prefab预制体添加一个Tag为Obstacle,添加步…...

【玩转 Postman 接口测试与开发2_015】第12章:模拟服务器(Mock servers)在 Postman 中的创建与用法(含完整实测效果图)
《API Testing and Development with Postman》最新第二版封面 文章目录 第十二章 模拟服务器(Mock servers)在 Postman 中的创建与用法1 模拟服务器的概念2 模拟服务器的创建2.1 开启侧边栏2.2 模拟服务器的两种创建方式2.3 私有模拟器的 API 秘钥的用法…...

mysql操作语句与事务
数据库设计范式 数据库设计的三大范式 第一范式(1NF):要求数据库表的每一列都是不可分割的原子数据项,即列中的每个值都应该是单一的、不可分割的实体。例如,如果一个表中的“地址”列包含了省、市、区等多个信息…...

android Camera 的进化
引言 Android 的camera 发展经历了3个阶段 : camera1 -》camera2 -》cameraX。 正文 Camera1 Camera1 的开发中,打开相机,设置参数的过程是同步的,就跟用户实际使用camera的操作步骤一样。但是如果有耗时情况发生时,会…...

ASP.NET Core Filter
目录 什么是Filter? Exception Filter 实现 注意 ActionFilter 注意 案例:自动启用事务的筛选器 事务的使用 TransactionScopeFilter的使用 什么是Filter? 切面编程机制,在ASP.NET Core特定的位置执行我们自定义的代码。…...

Git 的起源与发展
序章:版本控制的前世今生 在软件开发的漫长旅程中,版本控制犹如一位忠诚的伙伴,始终陪伴着开发者们。它的存在,解决了软件开发过程中代码管理的诸多难题,让团队协作更加高效,代码的演进更加有序。 简单来…...

基于SpringBoot电脑组装系统平台系统功能实现五
一、前言介绍: 1.1 项目摘要 随着科技的进步,计算机硬件技术日新月异,包括处理器(CPU)、主板、内存、显卡等关键部件的性能不断提升,为电脑组装提供了更多的选择和可能性。不同的硬件组合可以构建出不同类…...

【智力测试——二分、前缀和、乘法逆元、组合计数】
题目 代码 #include <bits/stdc.h> using namespace std; using ll long long; const int mod 1e9 7; const int N 1e5 10; int r[N], c[N], f[2 * N]; int nr[N], nc[N], nn, nm; int cntr[N], cntc[N]; int n, m, t;void init(int n) {f[0] f[1] 1;for (int i …...

第 1 天:UE5 C++ 开发环境搭建,全流程指南
🎯 目标:搭建 Unreal Engine 5(UE5)C 开发环境,配置 Visual Studio 并成功运行 C 代码! 1️⃣ Unreal Engine 5 安装 🔹 下载与安装 Unreal Engine 5 步骤: 注册并安装 Epic Game…...

axios如何利用promise无痛刷新token
目录 需求 需求解析 实现思路 方法一: 方法二: 两种方法对比 实现 封装axios基本骨架 instance.interceptors.response.use拦截实现 问题和优化 如何防止多次刷新token 同时发起两个或以上的请求时,其他接口如何重试 最后完整代…...

玉米苗和杂草识别分割数据集labelme格式1997张3类别
数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件) 图片数量(jpg文件个数):1997 标注数量(json文件个数):1997 标注类别数:3 标注类别名称:["corn","weed","Bean…...

【自学笔记】GitHub的重点知识点-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 GitHub使用指南详细知识点一、GitHub基础与账户管理1. GitHub简介2. 创建与管理GitHub账户3. 创建与配置仓库(Repository) 二、Git基础与Git…...

string例题
一、字符串最后一个单词长度 题目解析:由题输入一段字符串或一句话找最后一个单词的长度,也就是找最后一个空格后的单词长度。1.既然有空格那用我们常规的cin就不行了,我们这里使用getline,2.读取空格既然是最后一个空格后的单词,…...

算法基础——一致性
引入 最早研究一致性的场景既不是大数据领域,也不是分布式系统,而是多路处理器。 可以将多路处理器理解为单机计算机系统内部的分布式场景,它有多个执行单元,每一个执行单元都有自己的存储(缓存),一个执行单元修改了…...

【数据采集】案例01:基于Scrapy采集豆瓣电影Top250的详细数据
基于Scrapy采集豆瓣电影Top250的详细数据 Scrapy 官方文档:https://docs.scrapy.org/en/latest/豆瓣电影Top250官网:https://movie.douban.com/top250写在前面 实验目的:基于Scrapy框架采集豆瓣电影Top250的详细数据。 电脑系统:Windows 使用软件:PyCharm、Navicat Python…...

设计模式 - 行为模式_Template Method Pattern模板方法模式在数据处理中的应用
文章目录 概述1. 核心思想2. 结构3. 示例代码4. 优点5. 缺点6. 适用场景7. 案例:模板方法模式在数据处理中的应用案例背景UML搭建抽象基类 - 数据处理的 “总指挥”子类定制 - 适配不同供应商供应商 A 的数据处理器供应商 B 的数据处理器 在业务代码中整合运用 8. 总…...

Spring Boot框架下的单元测试
1. 什么是单元测试 1.1 基本定义 单元测试(Unit Test) 是对软件开发中最小可测单位(例如一个方法或者一个类)进行验证的一种测试方式。在 Java 后端的 Spring Boot 项目中,单元测试通常会借助 JUnit、Mockito 等框架对代码中核心逻辑进行快…...

git中文件的状态状态切换
在 Git 中,文件的状态是指文件相对于 Git 仓库的当前情况。以下是一些常见的文件状态及其含义: 未跟踪(Untracked): 这是新创建的文件或从其他位置复制过来的文件,Git 还没有开始跟踪这些文件的更改。 这些…...
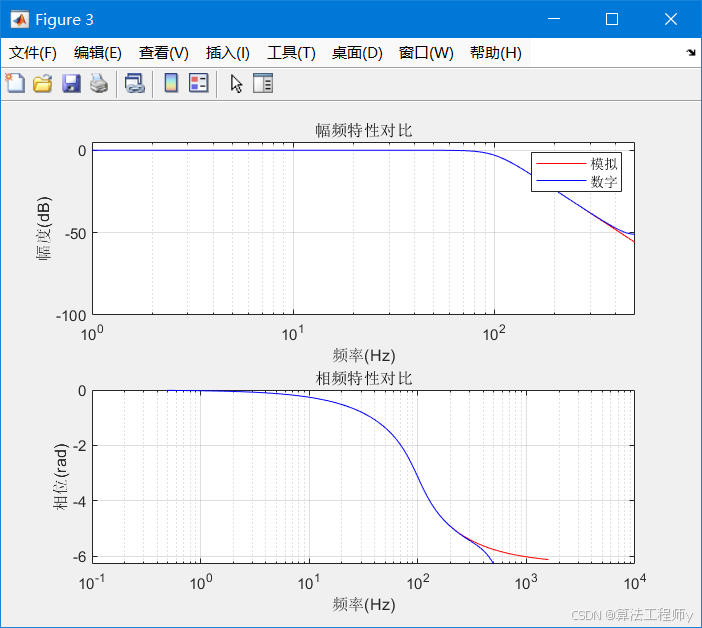
基于脉冲响应不变法的IIR滤波器设计与MATLAB实现
一、设计原理 脉冲响应不变法是一种将模拟滤波器转换为数字滤波器的经典方法。其核心思想是通过对模拟滤波器的冲激响应进行等间隔采样来获得数字滤波器的单位脉冲响应。 设计步骤: 确定数字滤波器性能指标 将数字指标转换为等效的模拟滤波器指标 设计对应的模拟…...

RabbitMQ快速上手及入门
概念 概念: publisher:生产者,也就是发送消息的一方 consumer:消费者,也就是消费消息的一方 queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理 exchang…...
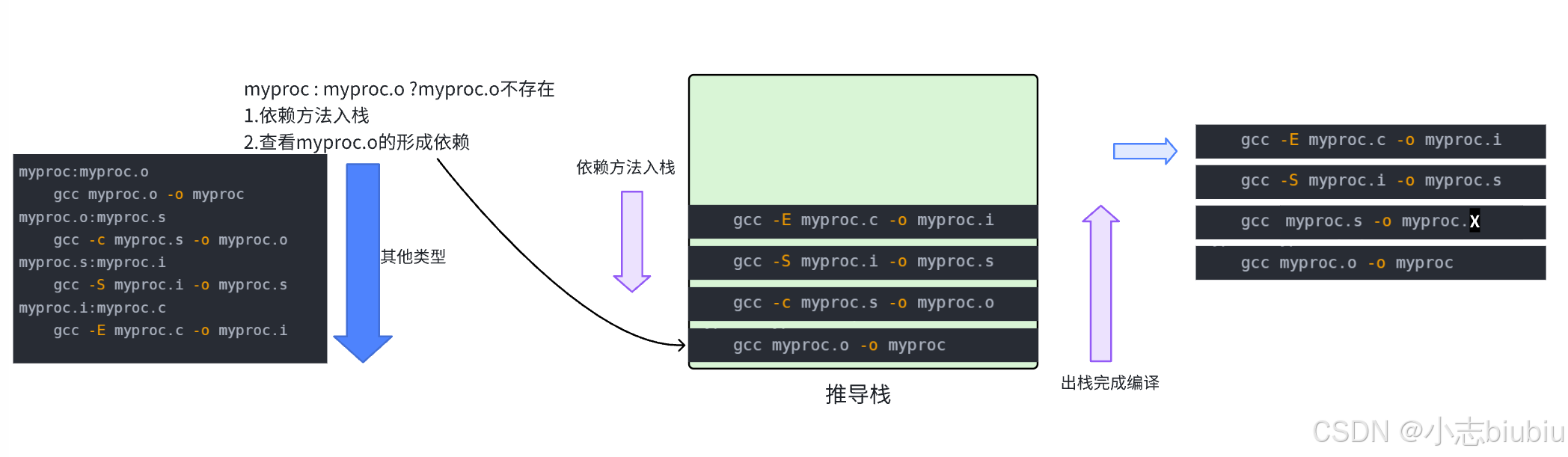
自动化构建-make/Makefile 【Linux基础开发工具】
文章目录 一、背景二、Makefile编译过程三、变量四、变量赋值1、""是最普通的等号2、“:” 表示直接赋值3、“?” 表示如果该变量没有被赋值,4、""和写代码是一样的, 五、预定义变量六、函数**通配符** 七、伪目标 .PHONY八、其他常…...

计算机网络之计算机网络的分类
计算机网络可以根据不同的角度进行分类,以下是几种常见的分类方式: 1. 按照规模和范围: 局域网(LAN,Local Area Network):覆盖较小范围(例如一个建筑物或校园)…...

MySQl的日期时间加
MySQL日期相关_mysql 日期加减-CSDN博客MySQL日期相关_mysql 日期加减-CSDN博客 raise notice 查询目标 site:% model:% date:% target:%,t_shipment_date.site,t_shipment_date.model,t_shipment_date.plant_date,v_date_shipment_qty_target;...

响应式编程与协程
响应式编程与协程的比较 响应式编程的弊端虚拟线程Java线程内核线程的局限性传统线程池的demo虚拟线程的demo 响应式编程的弊端 前面用了几篇文章介绍了响应式编程,它更多的使用少量线程实现线程间解耦和异步的作用,如线程的Reactor模型,主要…...

智能小区物业管理系统推动数字化转型与提升用户居住体验
内容概要 在当今快速发展的社会中,智能小区物业管理系统的出现正在改变传统的物业管理方式。这种系统不仅仅是一种工具,更是一种推动数字化转型的重要力量。它通过高效的技术手段,将物业管理与用户居住体验紧密结合,无疑为社区带…...

从Proxmox VE开始:安装与配置指南
前言 Proxmox Virtual Environment (Proxmox VE) 是一个开源的虚拟化平台,基于Debian Linux,支持KVM虚拟机和LXC容器。它提供了一个强大的Web管理界面,方便用户管理虚拟机、存储、网络等资源。Proxmox VE广泛应用于企业级虚拟化、云计算和开…...
)
【Docker项目实战】使用Docker部署MinIO对象存储(详细教程)
【Docker项目实战】使用Docker部署MinIO对象存储 前言一、 MinIO介绍1.1 MinIO简介1.2 主要特点1.3 主要使用场景二、本次实践规划2.1 本地环境规划2.2 本次实践介绍三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本四、下载MinIO镜像五、…...

【C++】B2115 密码翻译
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C 文章目录 💯前言💯题目解析💯1. 老师的做法代码实现:思路解析: 💯2. 我的做法代码实现:思路分析: 💯3. 老师…...