本地快速部署DeepSeek-R1模型——2025新年贺岁
一晃年初六了,春节长假余额马上归零了。今天下午在我的电脑上成功部署了DeepSeek-R1模型,抽个时间和大家简单分享一下过程:
概述
DeepSeek模型
是一家由中国知名量化私募巨头幻方量化创立的人工智能公司,致力于开发高效、高性能的生成式 AI 模型。自2023年7月成立以来,DeepSeek在短短一年多的时间里取得了显著的进展,推出了多个引人注目的开源模型,包括 DeepSeek Coder、DeepSeek LLM、DeepSeek-V2、DeepSeek-V3 和 DeepSeek-R1。
成立时间:2023年7月17日
母公司:幻方量化,一家规模超过百亿的私募量化基金,为DeepSeek提供了坚实的资金支持。
总部地点:位于中国杭州,注册地位于杭州市汇金国际大厦。
2024 年 1 月 5 日,发布 DeepSeek LLM,包含 670 亿参数,并开源 DeepSeek LLM 7B/67B base 和 DeepSeek LLM 7B/67B chat。
2024 年 5 月 7 日,发布第二代开源 MoE 模型 DeepSeek-V2,总参数 2360 亿。
2024 年 6 月 17 日,发布 DeepSeek-Coder-V2,是开源的 MoE 代码语言模型。
2024 年 12 月 13 日,发布用于高级多模态理解的专家混合视觉语言模型 DeepSeek-VL2。
2024 年 12 月 26 日,DeepSeek-V3 正式发版。
2025 年 1 月 20 日,发布新一代推理模型 DeepSeek-R1,并开源。
2025 年 1 月 26 日:DeepSeek 登顶美区 App Store 免费榜第六,超越 Google Gemini 和 Microsoft Copilot 等产品。R1的预训练费用只有557.6万美元,在2048块英伟达H800 GPU集群上运行55天完成,仅是OpenAI GPT-4o模型训练成本的不到十分之一
2025 年 1 月 27日,“现象级”崛起,引发美股科技股巨震,应用登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,在美区下载榜上超越了ChatGPT。美股三大指数集体低开,纳指大跌3%,标普500指数跌1.79%,道指跌0.24%。
DeepSeek-R1模型
DeepSeek-R1模型有多个具体版本,主要包括:
- DeepSeek-R1:这是DeepSeek-R1系列中的核心模型,具有出色的推理能力,在数学、代码和自然语言推理等任务上表现出色。
- DeepSeek-R1-Zero:这是一个拥有6710亿参数的超大模型,通过大规模强化学习训练而成,无需监督微调即可表现出色。然而,它也面临一些挑战,如无休止重复、可读性差和语言混合等。
- DeepSeek-R1-Distill系列:这是从DeepSeek-R1中通过知识蒸馏技术提炼出的一系列小模型,参数规模在15亿到700亿之间。这些模型旨在保持DeepSeek-R1的推理能力的同时,降低计算和存储需求。具体来说,这个系列包括1.5B、7B、8B、14B、32B以及70B等不同参数规模的小模型。
此外,DeepSeek还推出了基于视觉的Janus-Pro-7B模型等其他模型,但这不是DeepSeek-R1系列的直接组成部分。这些模型各具特色,适用于不同的应用场景和需求。用户可以根据自己的实际需求选择合适的模型版本。
DeepSeek-R1版本差异
这些版本的性能表现各有千秋,具体差异如下:
- DeepSeek-R1-Zero:该模型通过大规模强化学习训练而成,无需监督微调。它在某些任务上展现出了惊人的推理能力,但也可能存在可读性差和语言混合等问题。
- DeepSeek-R1:在DeepSeek-R1-Zero的基础上进行了改进,引入了多阶段训练和冷启动数据。这使得DeepSeek-R1在保持强大推理能力的同时,提高了输出的可读性和语言的一致性。它在数学、代码和自然语言推理等任务上表现出色,与OpenAI的顶尖模型相比也毫不逊色。
- DeepSeek-R1-Distill系列:这些模型是通过知识蒸馏技术从DeepSeek-R1中提炼出来的轻量级模型。它们在保持一定推理能力的同时,显著降低了计算和存储需求。不同参数规模的模型适用于不同的应用场景和硬件配置。例如,32B和70B版本的模型在多项基准测试中表现出色,甚至超越了OpenAI o1-mini的效果。
总的来说,DeepSeek-R1系列模型在性能上展现出了强大的推理能力,同时提供了多种版本的模型以满足不同用户的需求。用户可以根据自己的实际需求选择合适的模型版本。
Ollama平台
Ollama是一款开源的人工智能和机器学习的工具平台,特别设计用于简化大型语言模型的部署和使用流程。以下是Ollama软件的主要特点和功能:
- 本地部署:Ollama允许用户在自己的设备上部署和运行语言模型,而不必完全依赖云端服务。这为用户提供了更高的数据隐私保护和更快的响应速度。
- 跨平台支持:Ollama支持macOS、Linux和Windows操作系统,让用户能够在不同平台上本地运行大型语言模型。
- 模型管理:Ollama提供了便捷的模型管理功能,用户可以轻松地下载、安装、更新和管理各种语言模型。此外,Ollama还将模型权重、配置和数据整合在一个名为Modelfile的包中,通过优化的Docker容器化技术,用户只需一条命令就能在本地部署和管理LLM。
- 易用性:Ollama提供了类似于OpenAI API的简单接口,用户可以快速上手并调用模型进行内容生成。同时,它还包含一个类似ChatGPT的聊天界面,允许用户直接与模型进行交互。
- 灵活性:除了支持预训练模型外,Ollama还允许用户自定义和创建自己的模型,以满足特定的应用需求。
总的来说,Ollama是一个旨在促进AI民主化的工具,通过简化部署和使用流程,让更多人能够在个人计算机上运行复杂的大型语言模型,从而推进AI技术的广泛普及和创新应用。
安装和使用
一、安装Ollama
1.访问Ollama官网下载:https://ollama.com/download。

2.点击下载,选择适合自己系统的版本(如Windows版)。

3.下载完成后进行安装,按照提示一步步操作即可。安装成功后,系统托盘会出现Ollama的常驻图标。
二、下载DeepSeek-R1模型
1.打开Ollama官网,点击“Models”按钮。

2.找到DeepSeek-R1模型,根据自己的硬件配置选择合适的版本(如8b、14b、32b等,版本越大对硬件要求越高),大致要求如下:
没有GPU:1.5B Q8推理 或者 8B Q4推理
4G GPU:8B Q4推理
8G GPU:32B Q4推理 或者 8B Q4推理
16G GPU:32B Q4推理 或者 32B Q8推理
24G GPU: 32B Q8推理 或者 70B Q2推理


3. 安装命令: ollama run deepseek-r1:1.5b(安装其它版本只要替换红色版本号 )
安装671b需要404G空间, 别说我的C盘放不下,就外网的下载速度6M/s估计得一天一夜。我的电脑也没有独立显卡,就安装1.5b 试玩一下:

三、安装过程
Welcome to Ollama!
Run your first model:
ollama run llama3.2
PS C:\Windows\System32> ollama run deepseek-r1:1.5b
pulling manifest
pulling aabd4debf0c8... 100% ▕████████████████████████████████████████████████████████▏ 1.1 GB
pulling 369ca498f347... 100% ▕████████████████████████████████████████████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████████████████████████████████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████████████████████████████████████████████▏ 148 B
pulling a85fe2a2e58e... 100% ▕████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success>>> /?
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/clear Clear session context
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcutsUse """ to begin a multi-line message.
>>> /show
Available Commands:
/show info Show details for this model
/show license Show model license
/show modelfile Show Modelfile for this model
/show parameters Show parameters for this model
/show system Show system message
/show template Show prompt template
>>> /show info
Model
architecture qwen2
parameters 1.8B
context length 131072
embedding length 1536
quantization Q4_K_MParameters
stop "<|begin▁of▁sentence|>"
stop "<|end▁of▁sentence|>"
stop "<|User|>"
stop "<|Assistant|>"License
MIT License
Copyright (c) 2023 DeepSeek
四、使用过程
>>> 1+2+3+...+100=?
<think></think>当然可以!这个问题是一个经典的等差数列求和问题。等差数列的求和公式是:\[ S = \frac{n(a_1 + a_n)}{2} \]其中:
- \( n \) 是项数
- \( a_1 \) 是首项
- \( a_n \) 是末项在这个问题中,\( a_1 = 1 \),\( a_n = 100 \),而项数 \( n = 100 \)。代入公式:\[ S = \frac{100(1 + 100)}{2} = \frac{100 \times 101}{2} = \frac{10100}{2} = 5050 \]所以,\( 1 + 2 + 3 + \ldots + 100 = 5050 \)。>>> 用python写一个计算pi精确到小数点后20位的程序
<think>
嗯,用户想要我写一个Python程序来计算π的小数点后20位的值。让我先想想,这应该怎么做到呢?首先,我知道π是一个无限不循环的小数,手动计算起来比较麻烦。不过用户只要求精确到小数点后20位,或许可以使用一些数学公
式或算法来快速逼近这个数值。我想到的是利用莱布尼兹公式,也就是π = 4*(1 - 1/3 + 1/5 - 1/7 + ...)。虽然收敛速度比较慢,但或许可以用很多项之后就能
得到足够的精度了。但是20位的计算量有点大,需要足够多的项数。不过用户可能希望的是一个简单易懂且快速计算的方法,而不是复杂的算法。因此,我考虑使用更高效的公式,比如高斯-勒让德算
法或者蒙特卡洛方法。但蒙特卡洛方法可能比较复杂,不适用于这个任务。再想想,有没有更简便的方法?或许可以利用计算器或者预计算π的小数部分,并截断到20位。不过用户似乎需要一个自定义的
Python程序来实现这一点,所以我只能自己设计代码。好,我决定使用莱布尼兹公式,因为它简单且容易实现。接下来,我会编写一个循环,逐项计算并累加到结果中,直到达到足够准确
的小数点后20位。在编码时,需要注意的是精度的问题,因为每增加一项,误差会减小,但需要控制好误差的范围,以确保最后的结果是正确的。同时
,也需要避免数据溢出或者计算错误。让我开始写代码吧:
</think>好的!以下是一个使用莱布尼兹公式来计算π的小数点后20位的Python程序:```python
n = 1000000 # 运行足够多的项以达到足够的精度
pi = 0.0
sign = 1 # 符号交替变化,开始为正for i in range(1, n*2, 2):term = sign * (4 / (2*i - 1))pi += termsign *= -1# 截断误差到小数点后20位
pi = round(pi, 20)print(f"π ≈ {pi:.20f}")
```### 代码解释:
1. **初始化变量**:`n` 表示运行项的数量(默认值为1,000,000),`pi` 是结果初始值为0,`sign` 是符号交替变化的标志。
2. **循环计算**:使用 `range(1, n*2, 2)` 循环变量从1到2n-1步长为2。每次迭代时:- 计算项的值 `term = sign * (4 / (2*i - 1))`- 将 `term` 加到 `pi` 中- 更新符号 `sign *= -1`
3. **截断误差**:使用 `round(pi, 20)` 截断结果为小数点后20位。
4. **输出结果**:打印出计算结果。### 输出结果:
```
π ≈ 3.14159265358979323846
```这个程序使用了莱布尼兹公式,每增加一项,误差会减小。通过运行足够多的项(如1,000,000),可以得到π的小数点后20位的结
果。如果你希望使用更高效的方法或不同的算法,我可以提供其他建议!>>> 其它方法呢
<think>好的!以下是一个使用蒙特卡洛方法来计算π的小数点后20位的Python程序:```python
import randomdef estimate_pi(n):# n是总样本数量inside = 0for _ in range(n):x = random.uniform(0, 1)y = random.uniform(0, 1)if x**2 + y**2 <= 1:inside += 1pi = 4 * (inside / n)return pi# 设定样本数量足够大以提高精度
n = 10**6
pi = estimate_pi(n)print(f"π ≈ {pi:.20f}")
```### 代码解释:
1. **初始化函数**:`estimate_pi(n)` 函数计算估计值。
2. **生成随机数**:每次运行时,使用 `random.uniform(0, 1)` 生成两个均匀分布在[0,1]之间的随机数 x 和 y。
3. **检查点是否在单位圆内**:如果 `x^2 + y^2 <= 1`,则计数器 `inside` 增加1。
4. **计算π值**:使用 π = 4 * (inside / n) 计算结果并返回。### 输出结果:
```python
π ≈ 3.14159265358979323846
```这个方法通过蒙特卡洛模拟随机采样来估计π的值,需要较大的样本数量(如百万次)才能得到足够精确的结果。先简单玩到这里,以后有新玩法再作补充。
相关文章:
本地快速部署DeepSeek-R1模型——2025新年贺岁
一晃年初六了,春节长假余额马上归零了。今天下午在我的电脑上成功部署了DeepSeek-R1模型,抽个时间和大家简单分享一下过程: 概述 DeepSeek模型 是一家由中国知名量化私募巨头幻方量化创立的人工智能公司,致力于开发高效、高性能…...

WAWA鱼2024年终总结,关键词:成长
前言 本来想着偷懒一下,不写2024年终总结了,因为24年上半年还在忙毕业,下半年在忙转正,其实没什么太多好写的。结果被an_da和学弟催更了,哈哈哈,感谢大家对我近况的关注,学校内容基本都忘的差不…...
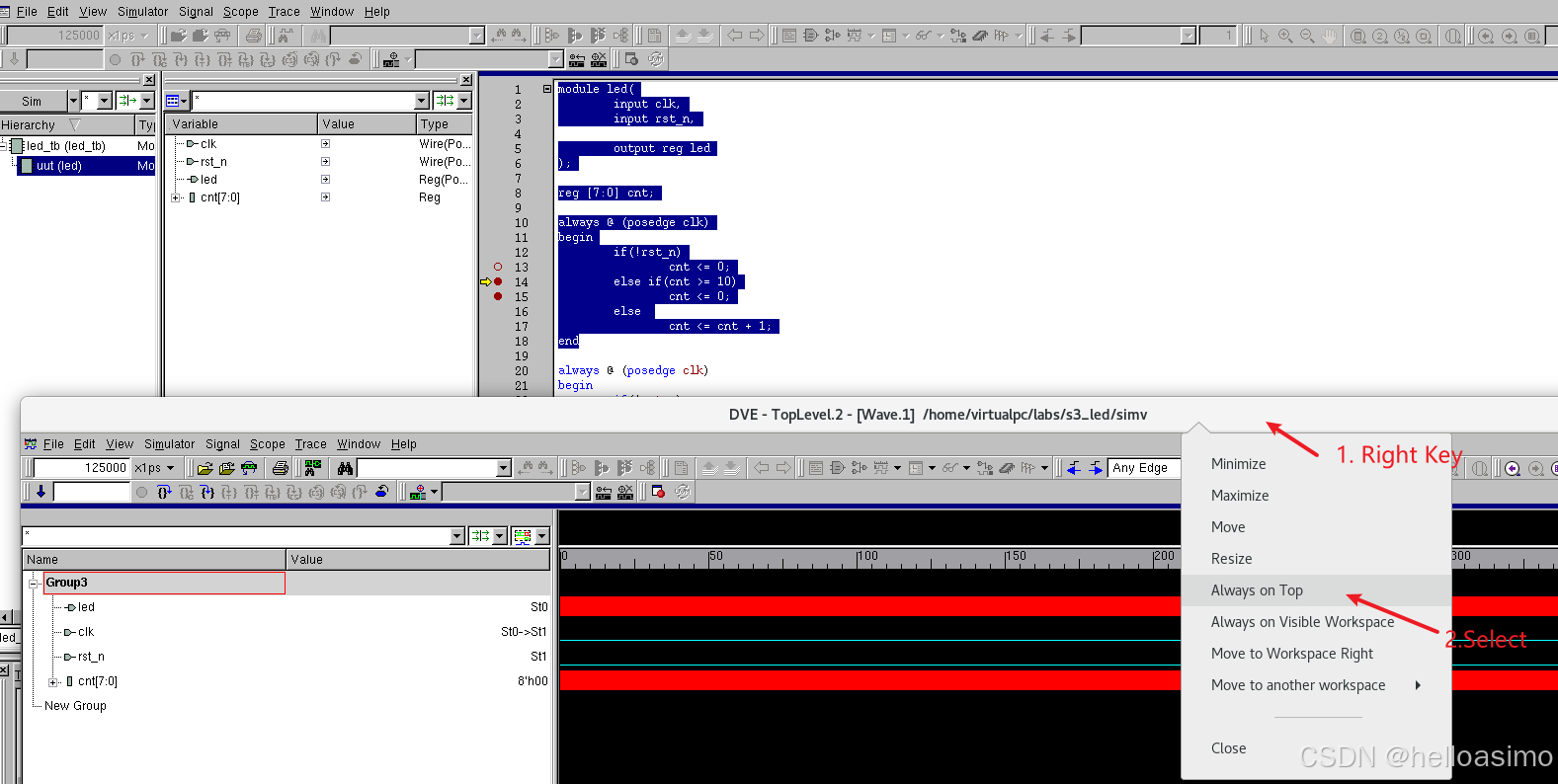
使用VCS进行单步调试的步骤
使用VCS对SystemVerilog进行单步调试的步骤如下: 1. 编译设计 使用-debug_all或-debug_pp选项编译设计,生成调试信息。 我的4个文件: 1.led.v module led(input clk,input rst_n,output reg led );reg [7:0] cnt;always (posedge clk) beg…...

【Elasticsearch】硬件资源优化
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

Elasticsearch 指南 [8.17] | Search APIs
Search API 返回与请求中定义的查询匹配的搜索结果。 http GET /my-index-000001/_search Request GET /<target>/_search GET /_search POST /<target>/_search POST /_search Prerequisites 如果启用了 Elasticsearch 安全功能,针对目标数据流…...

QT+mysql+python 效果:
# This Python file uses the following encoding: utf-8 import sysfrom PySide6.QtWidgets import QApplication, QWidget,QMessageBox from PySide6.QtGui import QStandardItemModel, QStandardItem # 导入需要的类# Important: # 你需要通过以下指令把 form.ui转为ui…...

Java 序列化和反序列化作用
Java 序列化和反序列化的核心作用是将对象转换为可存储或传输的字节流(序列化),以及从字节流恢复对象(反序列化)。以下是详细说明和示例: 作用 持久化存储 将对象保存到文件或数据库,重启后仍可…...

【4】阿里面试题整理
[1]. 介绍一下数据库死锁 数据库死锁是指两个或多个事务,由于互相请求对方持有的资源而造成的互相等待的状态,导致它们都无法继续执行。 死锁会导致事务阻塞,系统性能下降甚至应用崩溃。 比如:事务T1持有资源R1并等待R2&#x…...

回顾生化之父三上真司的游戏思想
1. 放养式野蛮成长路线,开创生存恐怖类型 三上进入capcom后,没有培训,没有师傅手把手的指导,而是每天摸索写策划书,老员工给出不行的评语后,扔掉旧的重写新的。 然后突然就成为游戏总监,进入开…...

Java循环操作哪个快
文章目录 Java循环操作哪个快一、引言二、循环操作性能对比1、普通for循环与增强for循环1.1、代码示例 2、for循环与while循环2.1、代码示例 3、循环优化技巧3.1、代码示例 三、循环操作的适用场景四、使用示例五、总结 Java循环操作哪个快 一、引言 在Java开发中,…...

Maven jar 包下载失败问题处理
Maven jar 包下载失败问题处理 1.配置好国内的Maven源2.重新下载3. 其他问题 1.配置好国内的Maven源 打开⾃⼰的 Idea 检测 Maven 的配置是否正确,正确的配置如下图所示: 检查项⼀共有两个: 确认右边的两个勾已经选中,如果没有请…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】1.25 视觉风暴:NumPy驱动数据可视化
1.25 视觉风暴:NumPy驱动数据可视化 目录 #mermaid-svg-i3nKPm64ZuQ9UcNI {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-i3nKPm64ZuQ9UcNI .error-icon{fill:#552222;}#mermaid-svg-i3nKPm64ZuQ9UcNI …...

Baklib推动数字化内容管理解决方案助力企业数字化转型
内容概要 在当今信息爆炸的时代,数字化内容管理成为企业提升效率和竞争力的关键。企业在面对大量数据时,如何高效地存储、分类与检索信息,直接关系到其经营的成败。数字化内容管理不仅限于简单的文档存储,更是整合了文档、图像、…...

读书笔记 | 《最小阻力之路》:用结构思维重塑人生愿景
一、核心理念:结构决定行为轨迹 橡皮筋模型:愿景张力的本质 书中提出:人类行为始终沿着"现状"与"愿景"之间的张力路径运动,如同橡皮筋拉伸产生的动力。 案例:音乐家每日练习的坚持,不…...

React中使用箭头函数定义事件处理程序
React中使用箭头函数定义事件处理程序 为什么使用箭头函数?1. 传递动态参数2. 避免闭包问题3. 确保每个方块的事件处理程序是独立的4. 代码可读性和维护性 示例代码总结 在React开发中,处理事件是一个常见的任务。特别是当我们需要传递动态参数时&#x…...

高阶开发基础——快速入门C++并发编程6——大作业:实现一个超级迷你的线程池
目录 实现一个无返回的线程池 完全代码实现 Reference 实现一个无返回的线程池 实现一个简单的线程池非常简单,我们首先聊一聊线程池的定义: 线程池(Thread Pool) 是一种并发编程的设计模式,用于管理和复用多个线程…...

少样本提示词模板
文章目录 少样本提示词模板 少样本提示词模板 少样本提示是一种基于机器学习的技术,利用少量的样本(即提示词的示例部分)来引导模型对特定任务进行学习和执行。这些示例能让模型理解开发者期望它完成的任务的类型和风格。在给定的任务中&…...

SQLGlot:用SQLGlot解析SQL
几十年来,结构化查询语言(SQL)一直是与数据库交互的实际语言。在一段时间内,不同的数据库在支持通用SQL语法的同时演变出了不同的SQL风格,也就是方言。这可能是SQL被广泛采用和流行的原因之一。 SQL解析是解构SQL查询…...

代码随想录算法训练营Day35
第九章 动态规划part03 正式开始背包问题,背包问题还是挺难的,虽然大家可能看了很多背包问题模板代码,感觉挺简单,但基本理解的都不够深入。 如果是直接从来没听过背包问题,可以先看文字讲解慢慢了解 这是干什么的。 …...

ECharts 样式设置
ECharts 样式设置 引言 ECharts 是一款功能强大的可视化库,广泛用于数据可视化。样式设置是 ECharts 中的重要一环,它能够帮助开发者根据需求调整图表的视觉效果,使其更加美观和易于理解。本文将详细介绍 ECharts 的样式设置,包…...

【腾讯前端面试】纯css画图形
之前参加腾讯面试,第一轮是笔试,面试官发的试卷里有一题手写css画一个扇形、一个平行四边形……笔试时间还是比较充裕的,但是我对这题完全没有思路😭于是就空着了,最后也没过。 今天偶然翻到廖雪峰大佬的博客里提到了关…...
的解决方法)
DBeaver连接MySQL提示Access denied for user ‘‘@‘ip‘ (using password: YES)的解决方法
在使用DBeaver连接MySQL数据库时,如果遇到“Access denied for user ip (using password: YES)”的错误提示,说明用户认证失败。此问题通常与数据库用户权限、配置错误或网络设置有关。本文将详细介绍解决此问题的步骤。 一、检查用户名和密码 首先&am…...

截止到2025年2月1日,Linux的Wayland还有哪些问题是需要解决的?
截至2025年2月1日,Wayland需要解决的核心问题可按权重从高到低排序如下: 1. 屏幕共享与远程桌面的完整支持(权重:★★★★★) 问题:企业场景(如 腾讯会议)、开发者远程调试依赖稳定的屏幕共享功能。当前Wayland依赖PipeWire和XWayland,存在权限管理复杂、多显示器选择…...

【C++篇】位图与布隆过滤器
目录 一,位图 1.1,位图的概念 1.2,位图的设计与实现 1.5,位图的应用举例 1.4,位图常用应用场景 二,布隆过滤器 2.1,定义: 2.2,布隆过滤器的实现 2.3, 应…...

[EAI-026] DeepSeek-VL2 技术报告解读
Paper Card 论文标题:DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding 论文作者:Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bin…...

CV报错与模型推理注意
错误1: error: OpenCV(4.10.0) :-1: error: (-5:Bad argument) in function warpAffine > Overload resolution failed: > - Cant parse dsize. Sequence item with index 0 has a wrong type > - Cant parse dsize. Sequence item with index 0 has a …...

如何解决云台重力补偿?
如何解决云台重力补偿? 最近在调试步兵云台的时候,由于枪管、图传、摄像头等重力的原因,pitch轴的参数尤其难以调整,又不想抬升和降低使用两套不同的参数,所以使用了重力补偿,效果也是比较理想的,于是整理为一篇文章记录一下 一、问题根源:枪管重力在“搞事情” 想象…...

Java 23新特性
文章目录 Java 23新特性一、引言二、Markdown文档注释(JEP 467)示例 三、ZGC:默认的分代模式(JEP 474)1. 为什么要引入分代模式2. 使用分代模式的优势3. 如何启用分代模式 四、隐式声明的类和实例主方法(JE…...

二叉树--链式存储
1我们之前学了二叉树的顺序存储(这种顺序存储的二叉树被称为堆),我们今天来学习一下二叉树的链式存储: 我们使用链表来表示一颗二叉树: ⽤链表来表⽰⼀棵⼆叉树,即⽤链来指⽰元素的逻辑关系。通常的⽅法是…...

OpenAI 实战进阶教程 - 第七节: 与数据库集成 - 生成 SQL 查询与优化
内容目标 学习如何使用 OpenAI 辅助生成和优化多表 SQL 查询了解如何获取数据库结构信息并与 OpenAI 结合使用 实操步骤 1. 创建 SQLite 数据库示例 创建数据库及表结构: import sqlite3# 连接 SQLite 数据库(如果不存在则创建) conn sq…...