KNIME:开源 AI 数据科学

KNIME(Konstanz Information Miner)是一款开源且功能强大的数据科学平台,由德国康斯坦茨大学的软件工程师团队开发,自2004年推出以来,广泛应用于数据分析、数据挖掘、机器学习和可视化等领域。以下是对KNIME的深度介绍:
1. 核心特点
1.1 图形化工作流编辑器
KNIME的核心是其直观的图形化用户界面(GUI),用户可以通过拖放节点的方式构建数据处理和分析的工作流。这种方式无需编程知识,适合从初学者到高级用户使用。
1.2 模块化设计
KNIME采用模块化设计,提供了超过4000个功能节点,覆盖数据预处理、统计分析、高阶分析、机器学习、可视化等多个领域。这些节点可以自由组合,支持复杂的数据分析任务。
1.3 强大的数据处理能力
KNIME支持多种数据源,包括CSV、Excel、SQL数据库、Hadoop等,并提供数据清洗、转换、合并、统计分析等功能。此外,KNIME还支持大规模数据处理,例如NGS(下一代测序)数据分析。

1.4 丰富的可视化工具
KNIME内置了丰富的可视化工具,如条形图、散点图、热力图等,使数据分析结果直观易懂。

1.5 自动化与可扩展性
KNIME支持自动化任务执行,通过工作流的重复运行提高效率。同时,KNIME允许用户开发自定义插件,以满足特定需求。
1.6 跨平台兼容性
KNIME支持Windows、MacOS和Linux操作系统,能够无缝集成到其他技术环境中。
2. 应用场景
2.1 数据分析与挖掘
KNIME广泛应用于数据分析和挖掘领域,包括数据清洗、统计分析、分类、聚类、回归等。

2.2 机器学习与建模
KNIME集成了多种机器学习算法,如决策树、支持向量机、K-means聚类等,并支持模型训练、验证和部署。

2.3 生物信息学与化学数据分析
KNIME在生物信息学和化学数据分析领域也有广泛应用,例如基因组数据分析、化学数据分析等。

2.4 商业智能与企业应用
KNIME Business Hub为企业提供了一套完整的解决方案,支持工作流管理、数据治理和AI治理。

3. 优势
3.1 易用性
KNIME的图形化界面降低了数据分析的门槛,即使是非程序员也能快速上手。
3.2 灵活性
KNIME支持多种数据源和算法,用户可以根据需求自由组合节点。
3.3 开源与社区支持
作为开源软件,KNIME拥有活跃的社区,用户可以在KNIME论坛中获取技术支持和资源分享。
3.4 高性能
KNIME支持大规模数据处理,并且能够利用GPU加速计算。
4. 最新发展
4.1 AI集成
KNIME不断引入人工智能技术,例如通过K-AI助手简化工作流构建。

4.2 扩展功能
KNIME持续推出新功能和扩展插件,例如Python集成、R集成、云服务连接等。
4.3 商业版本
KNIME Business Hub为企业用户提供了一套完整的解决方案,包括工作流管理、数据治理和AI治理。
5. 使用案例
5.1 教育与培训
KNIME提供了丰富的教程和案例,帮助用户快速掌握数据分析技能。

5.2 企业级应用
KNIME被广泛应用于金融、医疗、零售等行业,用于客户分析、市场预测和业务优化。

5.3 科研与学术
KNIME在科研领域也得到了广泛应用,例如生物信息学研究和化学数据分析。

总结
KNIME是一款功能全面且易于使用的开源数据分析平台,凭借其模块化设计、强大的数据处理能力和丰富的可视化工具,在多个领域展现了卓越的应用价值。无论是初学者还是专业数据科学家,都可以通过KNIME高效地完成复杂的数据分析任务,并推动业务决策和科学研究的发展。
KNIME图形化工作流编辑器的高级功能有哪些?
KNIME图形化工作流编辑器的高级功能包括以下几个方面:
-
模块化和可扩展性:KNIME通过模块化设计,允许用户轻松集成新的算法、数据操作或可视化方法作为新节点或模块。这种灵活性使得用户可以根据需求自定义工作流,从而实现复杂的数据处理任务。
-
支持多种编程语言:KNIME支持多种编程语言,包括R、Python和Java,这使得用户可以利用这些语言的强大功能来扩展和优化工作流。
-
数据处理能力:KNIME提供了强大的数据处理能力,包括数据I/O、数据转换、数据挖掘、机器学习、统计分析和可视化等功能。这些功能可以通过拖放节点的方式组合在一起,形成复杂的工作流。
-
工作流构建和调试:KNIME的工作流由节点、连接和工作区组成。节点是工作流的基本单位,每个节点执行特定的数据操作。用户可以通过拖放节点来构建工作流,并通过连接节点来实现数据的流动。此外,KNIME还提供了调试功能,帮助用户在运行工作流时定位和解决错误。
-
用户界面和用户体验:KNIME提供了现代和经典两种用户界面。现代界面可以直接打开现有工作流,而经典界面则需要通过导入现有工作流来打开。此外,KNIME允许用户自定义工作流组件和界面,例如调整节点布局、设置工作表标题和格式化Excel表格,以提高视觉吸引力和专业外观。
-
高级分析功能:KNIME支持高级分析功能,如相关性分析、K-means聚类、季节性分析等。这些功能可以通过KNIME提供的“STARTER”套件来简化实现。
-
报告和可视化:KNIME支持多种报告格式,包括PDF和HTML报告,并结合AI分析结果提供数据可视化功能。这些功能可以帮助用户更直观地展示分析结果。
-
协作和部署:KNIME Server和合作伙伴扩展支持商业化的协作、自动化、管理和部署功能,适用于本地安装和云环境。这使得KNIME能够更好地满足企业级用户的需求。
-
持续扩展和支持:KNIME不断推出新功能和改进现有功能。例如,最新版本中引入了Expression节点,支持AI功能,并改进了节点描述和编辑界面。
KNIME在生物信息学领域的具体应用案例是什么?
KNIME在生物信息学领域的具体应用案例包括以下几个方面:
-
基因表达数据分析:
KNIME被用于分析和注释基因表达数据,以寻找与特定疾病相关的基因。具体步骤包括从RNA测序数据中分析差异表达基因,使用R库edgeR进行差异表达分析、多组学分析、热图和层次聚类分析、通路富集分析以及靶向筛选寻找特定化合物的靶点基因。通过这些分析,研究人员可以识别与疾病相关的基因,并进一步研究其生物学功能和潜在的治疗靶点。 -
下一代测序(NGS)数据分析:
KNIME扩展了其在NGS数据分析中的应用,提供了一系列新的工作流和功能,使用户能够处理NGS数据。这些新节点利用KNIME的通用特性,如内存管理,可以在标准硬件上处理数十亿行数据,仅需约4GB的RAM。KNIME的工作流以纯XML文件形式存储,可以在几乎任何现代操作系统上运行,并且可以轻松地与数据交换或不与数据交换。KNIME支持读取FastQ文件、SAM/BAM文件和BED文件,并处理NGS数据的特定任务,如适配器去除和区域兴趣(ROIs)分析。此外,KNIME还支持数据清洗、对齐、创建BED文件、突变分析和ROI分析等任务。 -
高通量筛选实验中的分子选择:
HiTSEE(High-throughput Screening Explorer)是一个基于KNIME的工作流示例,展示了如何使用KNIME扩展进行数据输入、数据准备和迭代循环,以选择分子库的子集。HiTSEE利用KNIME的JChem库、ChemAxon和ChemMine等工具进行分子渲染、共通结构查找和交互式选择。此外,HiTSEE还展示了如何使用平方根缩放减少高度动态行为,并使用Meinl等人提出的算法来选择具有高结构多样性和高活性值的分子。
KNIME Business Hub相比免费版有哪些额外的功能和优势?
KNIME Business Hub相比免费版(KNIME Analytics Platform)提供了许多额外的功能和优势,主要体现在协作、自动化、治理和扩展性等方面。以下是详细对比:
1. 协作功能
- KNIME Analytics Platform:免费版支持基本的协作功能,允许用户浏览、下载和上传工作流,但协作范围有限,通常仅限于本地或小规模团队使用。
- KNIME Business Hub:商业版提供了更高级的协作功能,包括:
- 在团队或组织中共享和协作工作流。
- 提供文件夹功能,用于公开或私有空间中共享协作工作流。
- 支持可重用的工作流存储库,便于团队成员之间的协作。
2. 自动化功能
- KNIME Analytics Platform:免费版支持手动执行工作流,但缺乏高级自动化功能。
- KNIME Business Hub:商业版增加了自动化功能,包括:
- 自动化工作流运行,可以设置定时任务或周期性执行。
- 部署为交互式数据应用,并支持云原生架构。
- 提供版本控制功能,帮助用户跟踪工作流的调整和改进。
3. 治理功能
- KNIME Analytics Platform:免费版没有专门的治理功能,用户需要自行管理权限和资源。
- KNIME Business Hub:商业版提供了强大的治理功能,包括:
- 用户凭据管理,确保数据安全。
- 监控和管理功能,方便管理员对系统进行维护。
4. 扩展性和灵活性
- KNIME Analytics Platform:免费版虽然支持多种节点和插件,但扩展性有限,且需要用户自行配置。
- KNIME Business Hub:商业版支持更广泛的扩展性,包括:
- 支持任意数量的模型和用户。
- 提供低代码平台集成,简化了工作流的创建和部署。
- 集成节点开发服务和自动化服务,进一步增强工作流的灵活性。
5. 部署选项
- KNIME Analytics Platform:免费版通常部署在本地或开源环境中,灵活性较高。
- KNIME Business Hub:商业版支持私有云部署,适合企业级需求。
6. 其他优势
- KNIME Business Hub还支持跨人员、跨部门的知识传递和全流程管理协作工作,适用于数据科学家、业务人员和最终使用者等不同角色。
KNIME如何利用GPU加速计算,具体实现方式是什么?
KNIME可以通过多种方式利用GPU加速计算,具体实现方式主要依赖于其深度学习集成模块和相关工具。以下是详细的实现方式:
-
KNIME Deep Learning Integration
KNIME的深度学习集成模块(Deep Learning Integration)支持使用兼容的NVIDIA® GPU来加速深度学习模型的训练和推理。为了实现GPU加速,需要安装CUDA® Toolkit 8.0或更高版本。此外,KNIME的Deep Learning Integration模块支持通过TensorFlow和Keras进行深度学习计算,这些工具能够利用GPU进行高效的数值计算。 -
GPU支持的具体要求
- 显卡要求:需要NVIDIA GPU卡,并且GPU必须支持CUDA计算能力3.5或更高版本。
- 软件依赖:KNIME的深度学习集成模块会自动安装大部分依赖项(如CUDA®和cuDNN),但用户需要手动安装最新的NVIDIA® GPU驱动程序。
- 操作系统支持:GPU支持仅限于Linux和Windows系统,Mac系统不支持。
-
具体实现步骤
- 安装GPU驱动程序:首先确保系统中安装了最新版本的NVIDIA® GPU驱动程序。
- 安装深度学习集成模块:在KNIME Analytics Platform中,通过“File → Install KNIME Extensions”或“KNIME Labs Extensions”选项安装Deep Learning Integration模块。
- 配置环境:根据需要选择安装TensorFlow 1或TensorFlow 2,并确保安装了相应的GPU支持库(如
tensorflow-gpu)。
-
GPU加速的应用场景
- 深度学习模型训练与推理:KNIME的Deep Learning Integration模块支持使用GPU加速深度学习模型的训练和推理过程,从而显著提高计算效率。例如,在MNIST数据集上的实验中,使用GPU加速后的LeNet网络达到了98.71%的准确率。
- 图像处理:KNIME的Image Processing扩展程序也支持GPU加速,可以用于加速图像处理任务。
-
其他相关工具
- Enalos + KNIME:KNIME还可以通过Enalos工具箱集成GPU计算,用于加速化学信息学和纳米信息学中的耗时计算。
- KNIME WebPortal:KNIME Analytics Platform的WebPortal功能支持在本地或云环境中使用GPU加速深度学习模型的部署和运行。
总结来说,KNIME通过深度学习集成模块和相关工具,结合CUDA和cuDNN等技术,实现了对GPU的支持,从而在深度学习、图像处理等领域显著提升了计算效率。
KNIME的AI集成功能是如何工作的,有哪些实际应用案例?
KNIME的AI集成功能通过其内置的AI助手K-AI和多种扩展插件,为用户提供了强大的数据分析和自然语言处理能力。以下是KNIME AI集成功能的工作方式及其实际应用案例的详细说明:
KNIME AI集成功能的工作方式
-
K-AI助手:
- 问答和指导模式:K-AI助手可以作为聊天机器人,帮助用户解决在使用KNIME过程中遇到的问题。例如,当用户需要执行特定任务时,K-AI助手可以提供答案和工作流程指导。
- 工作流构建模式:K-AI助手能够根据用户提示从头开始创建工作流程,通过添加和连接节点,简化复杂工作流程的设计过程。
- 自定义语言模型:用户可以利用自己的数据连接、集成和自定义语言模型,为特定需求构建生成式AI应用程序。
-
大型语言模型(LLMs)集成:
- KNIME支持连接并提示OpenAI、Azure OpenAI、Hugging Face和GPT4ALL等LLMs,这些模型在自然语言处理任务中表现出色。
- 用户可以通过KNIME的图形界面无需编码即可实现LLMs的集成,包括获取API密钥、发送提示和连接模型。
-
向量存储和管理:
- KNIME支持向量存储和代理,用户可以安全地构建自定义业务逻辑和提示,以获得更相关的结果。
- 向量存储在文本处理中尤为重要,例如使用FAISS或Chroma库高效管理向量,进行相似性搜索和稠密向量聚类。
-
数据治理和安全:
- KNIME提供了防护机制,确保数据和模型治理,防止敏感信息被访问。用户可以通过AI Gateway对模型访问进行控制,确保数据不会被发送到不受信任的工具。
-
工作流自动化:
- KNIME的AI扩展可以自动生成Python脚本和可视化效果,极大地简化了数据分析任务。
- 用户可以利用KNIME的拖放式可视化编程,构建复杂的数据工作流,无需编写代码。
实际应用案例
-
自然语言处理(NLP):
- KNIME的AI扩展在产品推荐、情感分析和自动文本摘要生成等NLP任务中表现出色。例如,通过LLMs和向量存储,用户可以高效地处理大规模文本数据,并生成有价值的洞察。
-
生成式AI应用程序:
- 用户可以利用KNIME的K-AI助手和自定义语言模型,构建生成式AI应用程序。例如,通过连接和集成自己的数据源,用户可以创建用于特定业务需求的AI驱动应用程序。
-
数据科学工作流优化:
- KNIME的AI助手K-AI可以帮助用户快速学习和利用KNIME的分析功能,构建工作流程、编写脚本和创建可视化效果。这使得非编程背景的用户也能轻松构建复杂的工作流。
-
数据治理和安全:
- KNIME的AI Gateway和数据治理功能确保了数据的安全性和合规性。例如,在金融行业,用户可以利用这些功能保护个人身份信息(PII),并确保数据不被未经授权的工具访问。
-
跨平台兼容性:
- KNIME支持跨平台兼容,适用于所有操作系统。这使得不同背景的用户都能使用KNIME进行数据分析和AI建模。
总结
KNIME的AI集成功能通过其内置的K-AI助手、大型语言模型集成、向量存储管理以及数据治理和安全功能,为用户提供了一个强大且灵活的数据分析平台。这些功能不仅简化了数据分析任务,还为生成式AI应用程序的开发提供了支持。
相关文章:
KNIME:开源 AI 数据科学
KNIME(Konstanz Information Miner)是一款开源且功能强大的数据科学平台,由德国康斯坦茨大学的软件工程师团队开发,自2004年推出以来,广泛应用于数据分析、数据挖掘、机器学习和可视化等领域。以下是对KNIME的深度介绍…...

Office / WPS 公式、Mathtype 公式输入花体字、空心字
注:引文主要看注意事项。 1、Office / WPS 公式中字体转换 花体字 字体选择 “Eulid Math One” 空心字 字体选择 “Eulid Math Two” 2、Mathtype 公式输入花体字、空心字 2.1 直接输入 花体字 在 mathtype 中直接输入 \mathcal{L} L \Large \mathcal{L} L…...

[HOT 100] 2824. 统计和小于目标的下标对数目
文章目录 1. 题目链接2. 题目描述3. 题目示例4. 解题思路5. 题解代码6. 复杂度分析 1. 题目链接 2824. 统计和小于目标的下标对数目 - 力扣(LeetCode) 2. 题目描述 给你一个下标从 0 开始长度为 n 的整数数组 nums 和一个整数 target ,请你…...

建表注意事项(2):表约束,主键自增,序列[oracle]
没有明确写明数据库时,默认基于oracle 约束的分类 用于确保数据的完整性和一致性。约束可以分为 表级约束 和 列级约束,区别在于定义的位置和作用范围 复合主键约束: 主键约束中有2个或以上的字段 复合主键的列顺序会影响索引的使用,需谨慎设计 添加…...
Ubuntu20.04 磁盘空间扩展教程
Ubuntu20.04 磁盘空间扩展教程_ubuntu20 gpart扩容-CSDN博客文章浏览阅读2w次,点赞38次,收藏119次。执行命令查看系统容量相关的数据:df -h当前容量为20G,已用18G(96%),可用844M,可用…...

冯诺依曼体系架构和操作系统的概念
1.冯诺依曼体系架构 计算机的硬件大部分都遵循冯诺依曼体系架构,其图示如下 这里的存储器指的是内存,是一种断电易失的设备。 速度快 而磁盘,是一种永久存储的设备,其属于外设既是输出设备又是输入设备。速度慢 而运算器是一种…...
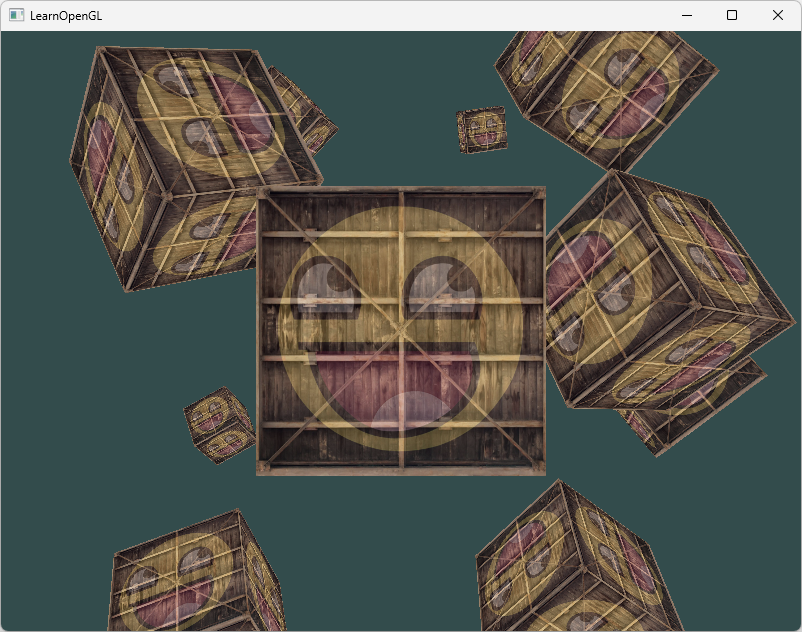
OpenGL学习笔记(六):Transformations 变换(变换矩阵、坐标系统、GLM库应用)
文章目录 向量变换使用GLM变换(缩放、旋转、位移)将变换矩阵传递给着色器坐标系统与MVP矩阵三维变换绘制3D立方体 & 深度测试(Z-buffer)练习1——更多立方体 现在我们已经知道了如何创建一个物体、着色、加入纹理。但它们都还…...

Linux第105步_基于SiI9022A芯片的RGB转HDMI实验
SiI9022A是一款HDMI传输芯片,可以将“音视频接口”转换为HDMI或者DVI格式,是一个视频转换芯片。本实验基于linux的驱动程序设计。 SiI9022A支持输入视频格式有:xvYCC、BTA-T1004、ITU-R.656,内置DE发生器,支持SYNC格式…...

测试工程师的DS使用指南
目录 引言DeepSeek在测试设计中的应用 2.1 智能用例生成2.2 边界值分析2.3 异常场景设计DeepSeek在自动化测试中的应用 3.1 脚本智能转换3.2 日志智能分析3.3 测试数据生成DeepSeek在质量保障体系中的应用 4.1 测试策略优化4.2 缺陷模式预测4.3 技术方案验证DeepSeek在测试效能…...

Qt常用控件 输入类控件
文章目录 1.QLineEdit1.1 常用属性1.2 常用信号1.3 例子1,录入用户信息1.4 例子2,正则验证手机号1.5 例子3,验证输入的密码1.6 例子4,显示密码 2. QTextEdit2.1 常用属性2.2 常用信号2.3 例子1,获取输入框的内容2.4 例…...

linux运行级别
运行级别:指linux系统在启动和运行过程中所处的不同的状态。 运行级别之间的切换:init (级别数) 示例: linux的运行级别一共有7种,分别是: 运行级别0:停机状态 运行级别1:单用户模式/救援模式…...
数据结构课程设计(四)校园导航
4 校园导航 4.1 需求规格说明 【问题描述】 一个学校平面图,至少包括10个以上的场所,每个场所带有编号、坐标、名称、类别等信息,两个场所间可以有路径相通,路长(耗时)各有不同。要求读取该校园平面图&a…...

50【Windows与Linux】
大家可能有些人听过Linux系统,很多初学者被灌输的理念就是服务器必须要装Linux系统 什么是系统? 比如你的电脑是Windows系统的,你手机是Android系统的,物理设备都需要系统,系统你可以理解成直接控制物理设备的一个东…...
——基础算法(D)——进制转换*)
蓝桥杯python基础算法(2-2)——基础算法(D)——进制转换*
目录 五、进制转换 十进制转任意进制,任意进制转十进制 例题 P1230 进制转换 作业 P2095 进制转化 作业 P2489 进制 五、进制转换 十进制转任意进制,任意进制转十进制 int_to_char "0123456789ABCDEF" def Ten_to_K(k, x):answer "…...

CSS 溢出内容处理:从基础到实战
CSS 溢出内容处理:从基础到实战 1. 什么是溢出?示例代码:默认溢出行为 2. 使用 overflow 属性控制溢出2.1 使用 overflow: hidden 裁剪内容示例代码:裁剪溢出内容 2.2 使用 overflow: scroll 显示滚动条示例代码:显示滚…...

嵌入式知识点总结 操作系统 专题提升(四)-上下文
针对于嵌入式软件杂乱的知识点总结起来,提供给读者学习复习对下述内容的强化。 目录 1.上下文有哪些?怎么理解? 2.为什么会有上下文这种概念? 3.什么情况下进行用户态到内核态的切换? 4.中断上下文代码中有哪些注意事项? 5.请问线程需要保存哪些…...

Elasticsearch基本使用详解
文章目录 Elasticsearch基本使用详解一、引言二、环境搭建1、安装 Elasticsearch2、安装 Kibana(可选) 三、索引操作1、创建索引2、查看索引3、删除索引 四、数据操作1、插入数据2、查询数据(1)简单查询(2)…...

携程Android开发面试题及参考答案
在项目中,给别人发的动态点赞功能是如何实现的? 数据库设计:首先要在数据库中为动态表添加一个点赞字段,用于记录点赞数量,同时可能需要一个点赞关系表,记录用户与动态之间的点赞关联,包括点赞时间等信息。界面交互:在 Android 界面上,为点赞按钮设置点击事件监听器。…...
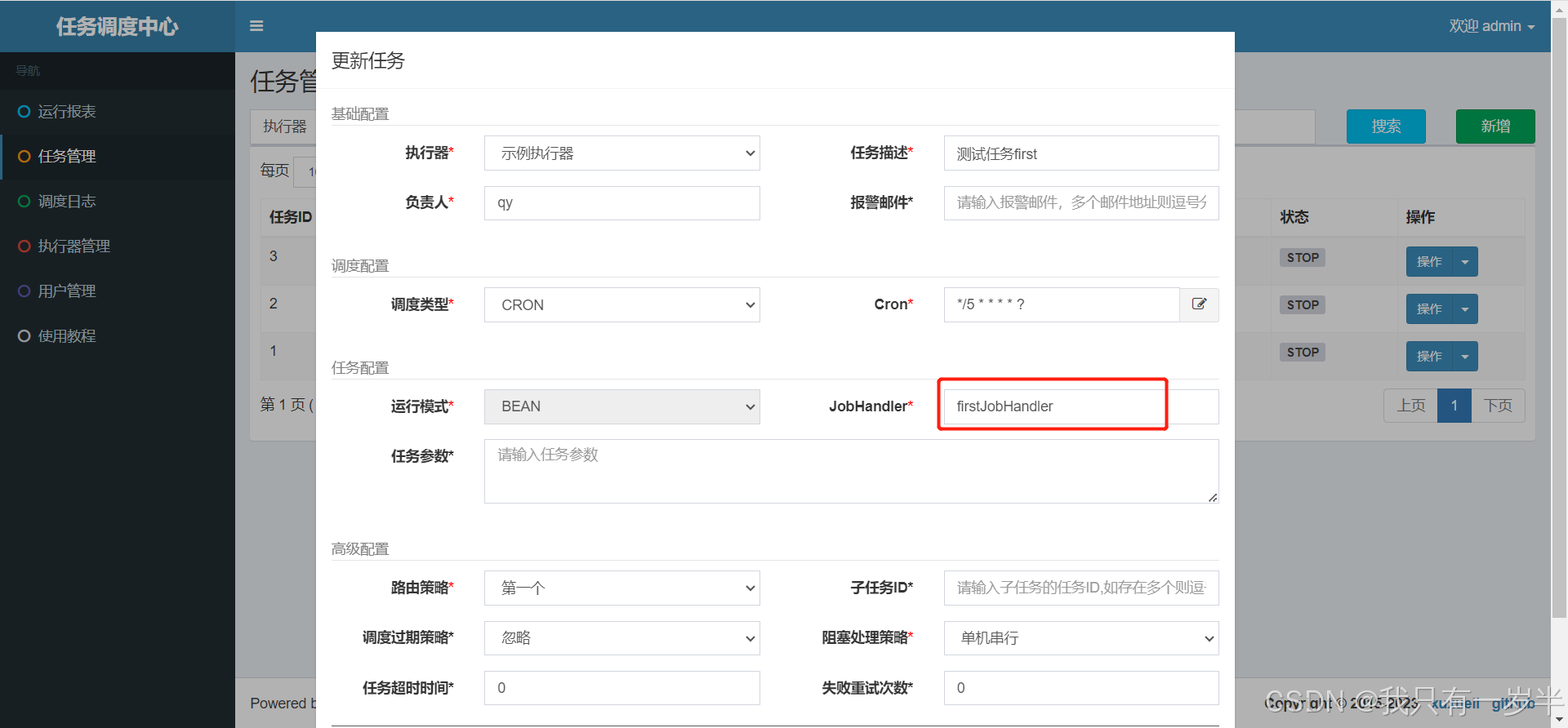
xxl-job 在 Java 项目的使用 以一个代驾项目中的订单模块举例
能搜到这里的最起码一定知道 xxl-job 是用来干什么的,我就不多啰嗦怎么下载以及它的历史了 首先我们要知道 xxl-job 这个框架的结构,如下图: xxl-job-master:xxl-job-admin:调度中心xxl-job-core:公共依赖…...

Alibaba开发规范_异常日志之日志规约:最佳实践与常见陷阱
文章目录 引言1. 使用SLF4J日志门面规则解释代码示例正例反例 2. 日志文件的保存时间规则解释 3. 日志文件的命名规范规则解释代码示例正例反例 4. 使用占位符进行日志拼接规则解释代码示例正例反例 5. 日志级别的开关判断规则解释代码示例正例反例 6. 避免重复打印日志规则解释…...
)
【数据分析】案例03:当当网近30日热销图书的数据采集与可视化分析(scrapy+openpyxl+matplotlib)
当当网近30日热销图书的数据采集与可视化分析(scrapy+openpyxl+matplotlib) 当当网近30日热销书籍官网写在前面 实验目的:实现当当网近30日热销图书的数据采集与可视化分析。 电脑系统:Windows 使用软件:Visual Studio Code Python版本:python 3.12.4 技术需求:scrapy、…...

需求分析应该从哪些方面来着手做?
需求分析一般可从以下几个方面着手: 业务需求方面 - 与相关方沟通:与业务部门、客户等进行深入交流,通过访谈、问卷调查、会议讨论等方式,明确他们对项目的期望、目标和整体业务需求,了解项目要解决的业务问题及达成的…...

申博经验贴
1. 所谓申博,最重要的就是定制的海投 分成两个部分 1. 定制 要根据每个教授去写不同的,一定不要泛泛的去写,一定要非常非常的具体,要引起教授的兴趣。每个教授每天都会收到几十封邮件,所以要足够的引起教授的注意&a…...

SpringAI 人工智能
随着 AI 技术的不断发展,越来越多的企业开始将 AI 模型集成到其业务系统中,从而提升系统的智能化水平、自动化程度和用户体验。在此背景下,Spring AI 作为一个企业级 AI 框架,提供了丰富的工具和机制,可以帮助开发者将…...

虚幻基础17:动画层接口
能帮到你的话,就给个赞吧 😘 文章目录 animation layer interface animation layer interface 动画层接口:动画图表的集。仅有名字。 添加到动画蓝图中,由动画蓝图实现动画图表。...

SQLAlchemy 2.0的简单使用教程
SQLAlchemy 2.0相比1.x进行了很大的更新,目前网上的教程不多,以下以链接mysql为例介绍一下基本的使用方法 环境及依赖 Python:3.8 mysql:8.3 Flask:3.0.3 SQLAlchemy:2.0.37 PyMySQL:1.1.1使用步骤 1、创建引擎,链接到mysql engine crea…...
 A-D)
Codeforces Round 1002 (Div. 2) A-D
复活!年后首场!本期封面是我自己AI弄的图 A - Milya and Two Arrays 题意 给两个所有数字出现次数都大于2的数组,问能不能修改排序之后对应位置相加得到新的数组使不同数字个数达到3 思路 直接计数就行了,不同的数字匹配一下…...

OpenGL学习笔记(七):Camera 摄像机(视图变换、LookAt矩阵、Camera类的实现)
文章目录 摄像机/观察空间/视图变换LookAt矩阵移动相机(处理键盘输入)移动速度欧拉角移动视角(处理鼠标输入)缩放场景(处理滚轮输入)Camera类 摄像机/观察空间/视图变换 在上一节变换中,我们讨…...

『VUE』vue-quill-editor富文本编辑器添加按钮houver提示(详细图文注释)
目录 预览效果新建一个config.js存放标题编写添加提示的方法调用添加标题方法的生命周期总结 欢迎关注 『VUE』 专栏,持续更新中 欢迎关注 『VUE』 专栏,持续更新中 预览效果 新建一个config.js存放标题 export const titleConfig [{ Choice: .ql-bold…...

如何使用 DeepSeek 和 Dexscreener 构建免费的 AI 加密交易机器人?
我使用DeepSeek AI和Dexscreener API构建的一个简单的 AI 加密交易机器人实现了这一目标。在本文中,我将逐步指导您如何构建像我一样的机器人。 DeepSeek 最近发布了R1,这是一种先进的 AI 模型。您可以将其视为 ChatGPT 的免费开源版本,但增加…...