LLM - 基于LM Studio本地部署DeepSeek-R1的蒸馏量化模型
文章目录
- 前言
- 开发环境
- 快速开始
- LM Studio
- 简单设置
- 模型下载
- 开始对话
- 模型选择
- 常见错误
- 最后
前言
目前,受限于设备性能,在本地部署的基本都是DeepSeek-R1的蒸馏量化模型,这些蒸馏量化模型的表现可能并没有你想象的那么好。绝大部分人并不需要本地部署,直接用现成的服务是更好的选择(特别是只能部署14B参数以下模型的设备)。

本文章基于macOS以及LM Studio本地部署,全程无需代理,力求让你快速学会部署自己的大语言模型。当然,你也可以参考其他文章使用Ollama部署。
开发环境
- macOS: 15.3
- LM Studio: 0.3.9
- 芯片: Apple M2 Pro (10核CPU/16核GPU/16核ANE)
- 内存: 32GB
快速开始
LM Studio
下载地址:LM Studio
下载完成后打开拖拽LM Studio.app到Applications目录完成安装。
简单设置
- 设置语言
LM Studio提供简体中文(beta版,不完全中文),可以通过右下角的设置按钮进入设置:

这个设置不是必须的,可以不设置,这里是为了降低使用难度。
- 用户界面复杂度级别
在左下角有三个级别选项:User / Power User / Developer,请至少切换到Power User级别。在User级别下,不会显示左侧边栏,里面有本地模型管理功能:

模型下载
如果你想在LM Studio下载模型,大概率会遇到这种情况:Model details error: fetch failed

这是因为huggingface.co在国内没办法直接访问,配置了代理实测也不行,他应该不走。macOS上我没找到有设置的地方,可能只能修改LM Studio.app。不过,这不重要,我们可以将模型下载后复制到指定模型目录。
这是huggingface.co的国内镜像hf-mirror.com,我们先下载一个 DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf 模型:

除了网页下载,你也可以通过命令行工具下载(感觉下载速度更快点):
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download lmstudio-community/DeepSeek-R1-Distill-Qwen-14B-GGUF DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
下载完成后将模型复制到指定模型目录(默认是/User/用户名/.lmstudio/models):

开始对话
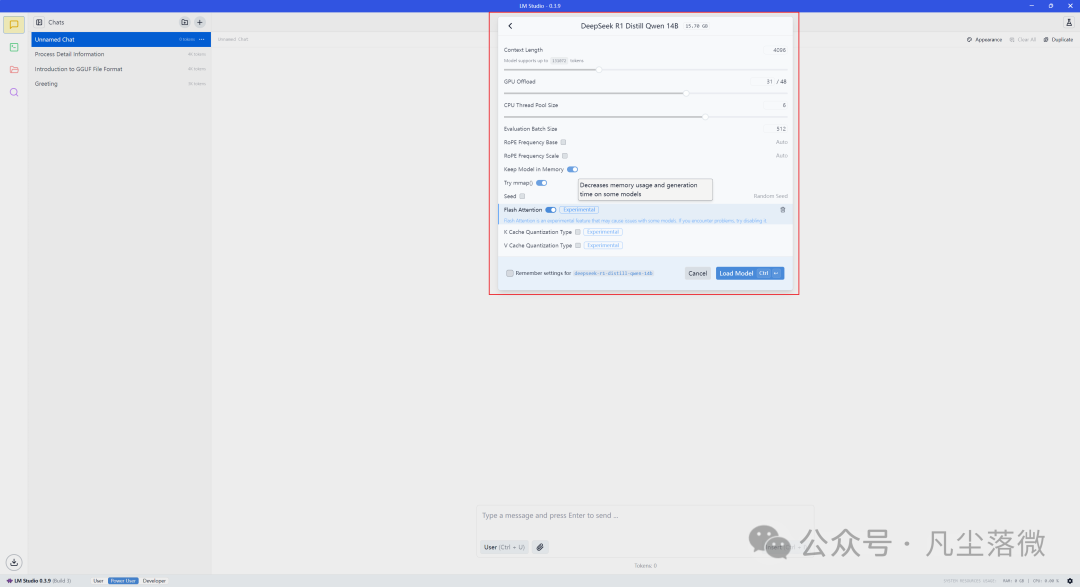
新建会话,然后点击顶部的选择要加载的模型:

模型设置先默认就行,后面可以自行研究。接下来就可以发消息开始对话:

实测本地跑这模型生成速度大概15 tok/sec,内存占用9GB+。
模型选择
先简单了解一下知识蒸馏:用一个大模型训练一个小模型,让小模型学习大模型的知识,从而减少计算量,提升推理速度,并保留大部分性能。
例如前面模型名称中的DeepSeek-R1-Distill-Qwen-14B部分,即表示用DeepSeek-R1模型训练Qwen-14B模型,以Qwen-14B模型的结构去学习DeepSeek-R1模型的知识。
DeepSeek-R1模型有671B参数,而Qwen-14B模型只有14B参数,就像是能力有限的学生跟随能力强大的老师,只能挑点重点学习。同时,学生之间的能力也有区别,参数更多的Qwen-32B模型也普遍比Qwen-14B模型能学的更多更强。并且,学生之间的底子也有区别,有些学生是基于Qwen(通义千问),有些是基于Llama(Meta),不同的底子对不同知识点的学习能力也有所差别,比如Qwen更擅长中文任务。
可见,本地部署的这个蒸馏模型并不是原版的模型,该模型已经可以看作是一个新模型,性能要求降低的同时你也别指望结果能和原版一样。
然后再简单了解一下模型量化:降低模型参数的数值精度来减少模型的存储需求和计算成本,从而加快推理速度,降低功耗。
例如前面模型名称中的Q4_K_M部分,Q4表示4-bit量化,K_M代表特定量化方案。Q后面的数字越低量化程度越高精度越低。
可见,模型量化通过牺牲精度,进一步降低模型大小以及内存等要求。同时,对结果的预期你也要降低。
最后简单了解一下模型格式:格式本身不会直接影响模型的推理精度或本质性能,但它可能间接影响加载效率和兼容性,需要关注的是当前支持运行什么格式。
例如LM Studio目前支持两种模型格式,分别是GGUF和MLX:

DeepSeek默认提供的是.safetensors格式模型,虽然下载后自己也能转格式,但是这个模型没经过量化大很多,LM Studio又提供了现成的,所以这就是为什么前面没有从deepseek-ai下载的原因。
看到这,你会选模型了吗?别急,再看一组我电脑的实测数据:
| 模型名称 | 模型大小 | 内存占用(GB) | 生成速度(tok/sec) |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf | 1.12GB | 1.4+ | 75 |
| DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf | 4.68GB | 4.8+ | 25 |
| DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf | 8.99GB | 9.4+ | 15 |
| DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf | 19.85GB | 内存不足 | N/A |
注意:以上内存占用和生成速度仅供参考,提示词/上下文越长,内存占用越多,生成速度越慢。
除了32B参数的没能跑起来,其他运行没什么问题,如果精度再降低到Q3可能能行,但是太勉强会影响其他软件的日常使用没有意义。
再补充一个CPU/GPU/ANE(Apple神经引擎)的使用情况:1.5B/7B/14B参数模型的CPU使用率很低,GPU差不多在14B参数模型时接近满载(更小的模型如果提示词/上下文长也可能满载),ANE没有使用。

注:功耗数据通过sudo powermetrics命令查看。
综上,为了更好的体验,建议先追求更大参数量的模型,然后再根据可用内存选择量化程度。至于选Qwen还是Llama,中文任务的话建议选Qwen。
个人建议,16GB内存选7B参数量Q4量化的模型,32GB内存选14B参数量Q4量化的模型。补充一点,由于macOS使用统一内存(内存显存共享),所以这只是基于macOS的建议,Windows还是要注意显存大小,好像显存不够可以使用内存,不知道性能怎么样没测试。
最后,还是提一句暂时不推荐本地部署,本地部署对于大部分人是伪需求。
常见错误
The model has crashed without additional information. (Exit code:5)
通常是内存不足,换个内存要求更低的模型吧。
Trying to keep the first xxx tokens when context the overflows. However, the model is loaded with context length of only 4096 tokens, which is not enough. Try to load the model with a larger context length, or provide a shorter input.
输入文本的长度超过了模型能够处理的最大上下文长度。可以尝试以下解决方法:
- 减小输入文本长度或改为发送文本附件
- 在模型设置中增加上下文长度
- 更换支持更长上下文长度的模型
最后
如果这篇文章对你有所帮助,点赞👍收藏🌟支持一下吧,谢谢~
本篇文章由@crasowas发布于CSDN。
相关文章:
LLM - 基于LM Studio本地部署DeepSeek-R1的蒸馏量化模型
文章目录 前言开发环境快速开始LM Studio简单设置模型下载开始对话 模型选择常见错误最后 前言 目前,受限于设备性能,在本地部署的基本都是DeepSeek-R1的蒸馏量化模型,这些蒸馏量化模型的表现可能并没有你想象的那么好。绝大部分人并不需要本…...
本地部署 DeepSeek-R1:简单易上手,AI 随时可用!
🎯 先看看本地部署的运行效果 为了测试本地部署的 DeepSeek-R1 是否真的够强,我们随便问了一道经典的“鸡兔同笼”问题,考察它的推理能力。 📌 问题示例: 笼子里有鸡和兔,总共有 35 只头,94 只…...

实现网站内容快速被搜索引擎收录的方法
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/6.html 实现网站内容快速被搜索引擎收录,是网站运营和推广的重要目标之一。以下是一些有效的方法,可以帮助网站内容更快地被搜索引擎发现和收录: 一、确…...
)
浅谈量化感知训练(QAT)
1. 为什么要量化? 假设你训练了一个神经网络模型(比如人脸识别),效果很好,但模型太大(比如500MB),手机根本跑不动。于是你想压缩模型,让它变小、变快。 最直接的压缩方法…...

对象的实例化、内存布局与访问定位
一、创建对象的方式 二、创建对象的步骤: 一、判断对象对应的类是否加载、链接、初始化: 虚拟机遇到一条new指令,首先去检查这个指令的参数能否在Metaspace的常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已经被加载、解析和初始化…...

制造业设备状态监控与生产优化实战:基于SQL的序列分析与状态机建模
目录 1. 背景与挑战 2. 数据建模与采集 2.1 数据表设计 设备状态表(记录设备实时状态变更)...

OpenAI推出Deep Research带给我们怎样的启示
OpenAI 又发新产品了,这次是面向深度研究领域的智能体产品 ——「Deep Research」,貌似被逼无奈的节奏… 在技术方面,Deep Research搭载了优化后o3模型并通过端到端强化学习在多个领域的复杂浏览和推理任务上进行了训练。因没有更多的技术暴露…...

K8S学习笔记-------1.安装部署K8S集群环境
1.修改为root权限 #sudo su 2.修改主机名 #hostnamectl set-hostname k8s-master01 3.查看网络地址 sudo nano /etc/netplan/01-netcfg.yaml4.使网络配置修改生效 sudo netplan apply5.修改UUID(某些虚拟机系统,需要设置才能生成UUID)#…...

【基于SprintBoot+Mybatis+Mysql】电脑商城项目之用户登录
🧸安清h:个人主页 🎥个人专栏:【Spring篇】【计算机网络】【Mybatis篇】 🚦作者简介:一个有趣爱睡觉的intp,期待和更多人分享自己所学知识的真诚大学生。 目录 🎯1.登录-持久层 &…...

【Deep Seek本地化部署】模型实测:规划求解python代码
目录 前言 一、实测 1、整数规划问题 2、非线性规划问题 二、代码正确性验证 1、整数规划问题代码验证 2、非线性规划问题代码验证 三、结果正确性验证 1、整数规划问题结果正确性验证 2、非线性规划问题正确性验证 四、整数规划问题示例 后记 前言 模型ÿ…...

虚幻基础17:动画蓝图
能帮到你的话,就给个赞吧 😘 文章目录 animation blueprint图表(Graph): 编辑动画逻辑。变量(Variables): 管理动画参数。函数(Functions): 自定义…...

【游戏设计原理】98 - 时间膨胀
从上文中,我们可以得到以下几个启示: 游戏设计的核心目标是让玩家感到“时间飞逝” 游戏的成功与否,往往取决于玩家的沉浸感。如果玩家能够完全投入游戏并感受到时间飞逝,说明游戏设计在玩法、挑战、叙事等方面达到了吸引人的平衡…...

C语言基础系列【1】第一个C程序:Hello, World!
C语言的历史与特点 历史背景 C语言起源于20世纪70年代,最初是由美国贝尔实验室的Dennis Ritchie和Ken Thompson为了开发UNIX操作系统而设计的一种编程语言。在UNIX系统的开发过程中,他们发现原有的B语言(由Thompson设计)在功能和…...

【LLM】DeepSeek-R1-Distill-Qwen-7B部署和open webui
note DeepSeek-R1-Distill-Qwen-7B 的测试效果很惊艳,CoT 过程可圈可点,25 年应该值得探索更多端侧的硬件机会。 文章目录 note一、下载 Ollama二、下载 Docker三、下载模型四、部署 open webui 一、下载 Ollama 访问 Ollama 的官方网站 https://ollam…...

go-zero学习笔记(三)
利用goctl生成rpc服务 编写proto文件 // 声明 proto 使用的语法版本 syntax "proto3";// proto 包名 package demoRpc;// golang 包名(可选) option go_package "./demo";// 如需为 .proto 文件添加注释,请使用 C/C 样式的 // 和 /* ... */…...

C# 修改项目类型 应用程序程序改类库
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 源码指引:github源…...

普罗米修斯监控服务搭建位置全解析:权衡与抉择
在数字化时代,监控系统对于企业的稳定运营和业务发展至关重要。普罗米修斯作为一款备受青睐的开源监控和告警工具,其搭建位置的决策绝非小事,它紧密关联着监控系统的性能、可靠性与安全性,如同为整座大厦奠定基石。接下来…...

为什么“记住密码”适合持久化?
✅ 特性 1:应用重启后仍需生效 记住密码的本质是长期存储用户的登录凭证(如用户名、密码、JWT Token),即使用户关闭应用、重启设备,仍然可以自动登录。持久化存储方案: React Native 推荐使用 AsyncStorag…...

地址查询API接口:高效查询地址信息,提升数据处理效率
地址查询各省市区API接口 地址查询是我们日常生活中经常遇到的一个需求,无论是在物流配送、地图导航还是社交网络等应用中,都需要通过地址来获取地理位置信息。为了满足这个需求,我们可以使用地址查询API接口来高效查询地址信息,提…...
)
2021版小程序开发5——小程序项目开发实践(1)
2021版小程序开发5——小程序项目开发实践(1) 学习笔记 2025 使用uni-app开发一个电商项目; Hbuidler 首选uni-app官方推荐工具:https://www.dcloud.io/hbuilderx.htmlhttps://dev.dcloud.net.cn/pages/app/list 微信小程序 管理后台:htt…...
)
元音字母(模拟)
给定一个由大小写字母、空格和问号组成的字符串。 请你判断字符串中的最后一个字母是否是元音字母。 我们认为元音字母共有 66 个,分别为:AA、EE、II、OO、UU、YY(当然还有它们的小写)。 输入格式 一个由大小写字母、空格和问…...

如何处理 Typecho Joe 主题被抄袭或盗版的问题
在开源社区中,版权保护是一个非常重要的话题。如果你发现自己的主题(如 Joe 主题)被其他主题(如子比主题)抄袭或盗版,你可以采取以下措施来维护自己的权益。 一、确认侵权行为 在采取任何行动之前…...

将markdown文件和LaTex公式转为word
通义千问等大模型生成的回答多数是markdown类型的,需要将他们转为Word文件 一 pypandoc 介绍 1. 项目介绍 pypandoc 是一个用于 pandoc 的轻量级 Python 包装器。pandoc 是一个通用的文档转换工具,支持多种格式的文档转换,如 Markdown、HTM…...

自动化测试框架搭建-封装requests-优化
目的 1、实际的使用场景,无法避免的需要区分GET、POST、PUT、PATCH、DELETE等不同的方式请求,以及不同请求的传参方式 2、python中requests中,session.request方法,GET请求,只支持params传递参数 session.request(me…...

Smart contract -- 钱包合约
在区块链的世界里,钱包是存储和管理加密货币的基本工具。今天,我们将通过 Solidity 智能合约来创建一个简单的以太坊钱包。这个钱包将允许用户存入和取出以太坊主币(ETH),并且只有管理员(合约的创建者&…...

模拟实战-用CompletableFuture优化远程RPC调用
实战场景 这是广州某500-900人互联网厂的面试原题 手写并发优化解决思路 我们要调用对方的RPC接口,我们的RPC接口每调用一次对方都会阻塞50ms 但是我们的业务要批量调用RPC,例如我们要批量调用1k次,我们不可能在for循环里面写1k次远程调用…...

图 、图的存储
图的基本概念: 图g由顶点集v和边集e组成,记为g(v,e) 用|v|表示图g中顶点的个数,也称图g的阶,用|e|表示图g中边的条数 线性表可以是空表,树可以是空树,但图不可以是空&…...

快速提升网站收录:利用网站新闻发布功能
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/63.html 利用网站新闻发布功能快速提升网站收录是一个有效的策略。以下是一些具体的建议,帮助你更好地利用这一功能: 一、保持新闻更新频率 搜索引擎尤其重视网站的…...
 | 洛谷 P11228 [CSP-J 2024] 地图探险)
信息学奥赛一本通 2112:【24CSPJ普及组】地图探险(explore) | 洛谷 P11228 [CSP-J 2024] 地图探险
【题目链接】 ybt 2112:【24CSPJ普及组】地图探险(explore) 洛谷 P11228 [CSP-J 2024] 地图探险 【题目考点】 1. 模拟 2. 二维数组 3. 方向数组 在一个矩阵中,当前位置为(sx, sy),将下一个位置与当前位置横纵坐…...

【数据结构】(4) 线性表 List
一、什么是线性表 线性表就是 n 个相同类型元素的有限序列,每一个元素只有一个前驱和后继(除了第一个和最后一个元素)。 数据结构中,常见的线性表有:顺序表、链表、栈、队列。 二、什么是 List List 是 Java 中的线性…...