DeepSeek R1 简易指南:架构、本地部署和硬件要求
DeepSeek 团队近期发布的DeepSeek-R1技术论文展示了其在增强大语言模型推理能力方面的创新实践。该研究突破性地采用强化学习(Reinforcement Learning)作为核心训练范式,在不依赖大规模监督微调的前提下显著提升了模型的复杂问题求解能力。
技术架构深度解析
模型体系:
DeepSeek-R1系列包含两大核心成员:
DeepSeek-R1-Zero
参数规模:6710亿(MoE架构,每个token激活370亿参数)
训练特点:完全基于强化学习的端到端训练
核心优势:展现出自我验证、长链推理等涌现能力
典型表现:AIME 2024基准测试71%准确率
DeepSeek-R1
参数规模:与Zero版保持相同体量
训练创新:多阶段混合训练策略
核心改进:监督微调冷启动 + 强化学习优化
性能提升:AIME 2024准确率提升至79.8%
训练方法论对比
强化学习与主要依赖监督学习的传统模型不同,DeepSeek-R1广泛使用了RL。训练利用组相对策略优化(GRPO),注重准确性和格式奖励,以增强推理能力,而无需大量标记数据。
蒸馏技术:为了普及高性能模型,DeepSeek 还发布了 R1 的精简版本,参数范围从 15 亿到 700 亿不等。这些模型基于 Qwen 和 Llama 等架构,表明复杂的推理可以封装在更小、更高效的模型中。提炼过程包括利用完整的 DeepSeek-R1 生成的合成推理数据对这些较小的模型进行微调,从而在降低计算成本的同时保持高性能。
DeepSeek-R1-Zero训练流程:
基础模型 → 直接强化学习 → 基础奖励机制(准确率+格式)
DeepSeek-R1四阶段训练法:
精选监督微调(数千高质量样本)
推理任务强化学习
拒绝采样数据扩充
全任务强化学习优化
关键技术亮点:
组相对策略优化(GRPO):兼顾格式与准确性的奖励机制
知识蒸馏技术:支持从1.5B到70B的参数规模适配
多架构兼容:基于Qwen/Llama等主流架构的轻量化版本
性能实测数据
| 测试基准 | DeepSeek-R1 | OpenAI o1-1217 |
|---|---|---|
| AIME 2024 | 79.8% | 79.2% |
| MATH-500 | 97.3% | 96.4% |
接口调用效率:在标准测试环境下展现优异性价比,较同类产品降低30%
部署方案全解析
云端接入方案:
对话平台接入
访问DeepSeek Chat平台
选择"深度思考"模式体验链式推理

API集成
import openai
client = openai.OpenAI(base_url="https://api.deepseek.com/v1",api_key="your_api_key"
)
response = client.chat.completions.create(model="deepseek-r1",messages=[{"role":"user","content":"解释量子纠缠现象"}]
)深度求索R1部署全方案详解
一、云端接入方案
1. 网页端交互(DeepSeek Chat平台)
步骤详解:
访问平台:打开浏览器进入 https://chat.deepseek.com
账户认证:
新用户:点击"注册" → 输入邮箱/手机号 → 完成验证码校验
已有账户:直接登录
模式选择:
在对话界面右上角选择「深度思考」模式
开启「增强推理」选项(默认启用)
会话管理:
新建对话:点击+号创建新会话
历史记录:左侧边栏查看过往对话
高级设置:
温度参数:滑动条调节生成多样性(0.1-1.0)
最大生成长度:设置响应token上限(默认2048)
2. API集成方案
# 完整API接入示例(Python)
import openai
from dotenv import load_dotenv
import os# 环境配置
load_dotenv()
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")# 客户端初始化
client = openai.OpenAI(base_url="https://api.deepseek.com/v1",api_key=DEEPSEEK_API_KEY,timeout=30 # 超时设置
)# 带重试机制的请求函数
def query_deepseek(prompt, max_retries=3):for attempt in range(max_retries):try:response = client.chat.completions.create(model="deepseek-r1",messages=[{"role": "user", "content": prompt}],temperature=0.7,top_p=0.9,max_tokens=1024)return response.choices[0].message.contentexcept Exception as e:if attempt == max_retries - 1:raise eprint(f"请求失败,正在重试... ({attempt+1}/{max_retries})")# 使用示例
if __name__ == "__main__":result = query_deepseek("用React实现可拖拽的甘特图组件")print(result)二、本地部署方案
1. 硬件配置要求
| 模型类型 | 最小GPU配置 | CPU配置 | 内存要求 | 磁盘空间 |
|---------------|----------------|------------------|---------|--------|
| R1-Zero全量版 | RTX 4090(24GB) | Xeon 8核+128GB | 128GB | 500GB |
| R1蒸馏版-70B | RTX 3090(24GB) | i9-13900K+64GB | 64GB | 320GB |
| R1蒸馏版-14B | RTX 3060(12GB) | Ryzen 7+32GB | 32GB | 80GB |
| R1蒸馏版-1.5B | 无需GPU | 任意四核处理器+8GB | 8GB | 12GB |2. Ollama本地部署全流程

# 完整部署流程(Ubuntu示例)
# 步骤1:安装依赖
sudo apt update && sudo apt install -y nvidia-driver-535 cuda-12.2# 步骤2:安装Ollama
curl -fsSL https://ollama.com/install.sh | sh# 步骤3:配置环境变量
echo 'export OLLAMA_HOST=0.0.0.0' >> ~/.bashrc
source ~/.bashrc# 步骤4:启动服务
sudo systemctl start ollama# 步骤5:拉取模型(以14B为例)
ollama pull deepseek-r1:14b# 步骤6:运行模型(带GPU加速)
ollama run deepseek-r1:14b --gpu# 步骤7:验证部署
curl http://localhost:11434/api/tags | jq3. 高级部署方案
方案一:vLLM服务化部署
# 启动推理服务
vllm serve --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \
--tensor-parallel-size 2 \
--max-model-len 32768 \
--gpu-memory-utilization 0.9# 客户端调用
from vllm import LLM, SamplingParams
llm = LLM("deepseek-ai/DeepSeek-R1-Distill-Qwen-32B")
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
print(llm.generate(["解释BERT模型的注意力机制"], sampling_params))方案二:llama.cpp量化部署
# 模型转换
./quantize ./models/deepseek-r1-14b.gguf ./models/deepseek-r1-14b-Q5_K_M.gguf Q5_K_M# 启动推理
./main -m ./models/deepseek-r1-14b-Q5_K_M.gguf \
-n 1024 \
--repeat_penalty 1.1 \
--color \
-i三、混合部署方案
边缘计算场景配置
# docker-compose.yml配置示例
version: '3.8'services:ollama:image: ollama/ollamadeploy:resources:reservations:devices:- driver: nvidiacount: 1capabilities: [gpu]volumes:- ollama:/root/.ollamaports:- "11434:11434"api-gateway:image: nginx:alpineports:- "80:80"volumes:- ./nginx.conf:/etc/nginx/nginx.confvolumes:ollama:性能优化技巧
显存优化:使用
--num-gpu 1参数限制GPU使用数量量化加速:尝试GGUF格式的Q4_K_M量化版本
批处理优化:设置
--batch-size 32提升吞吐量缓存策略:启用Redis缓存高频请求prompt
最后
从DeepSeek-R1-Zero到DeepSeek-R1,代表了研究中的一个重要学习历程。DeepSeek-R1-Zero 证明了纯粹的强化学习是可行的,而 DeepSeek-R1 则展示了如何将监督学习与强化学习相结合,从而创建出能力更强、更实用的模型。
"本文所述技术参数均来自公开研究文献,实际部署需遵守当地法律法规"
最后:
React Hook 深入浅出
CSS技巧与案例详解
vue2与vue3技巧合集
VueUse源码解读
相关文章:
DeepSeek R1 简易指南:架构、本地部署和硬件要求
DeepSeek 团队近期发布的DeepSeek-R1技术论文展示了其在增强大语言模型推理能力方面的创新实践。该研究突破性地采用强化学习(Reinforcement Learning)作为核心训练范式,在不依赖大规模监督微调的前提下显著提升了模型的复杂问题求解能力。 技…...

Ollama教程:轻松上手本地大语言模型部署
Ollama教程:轻松上手本地大语言模型部署 在大语言模型(LLM)飞速发展的今天,越来越多的开发者希望能够在本地部署和使用这些模型,以便更好地控制数据隐私和计算资源。Ollama作为一个开源工具,旨在简化大语言…...
)
并行计算、分布式计算与云计算:概念剖析与对比研究(表格对比)
什么是并行计算?什么是分布计算?什么是云计算?我们如何更好理解这3个概念,我们采用概念之间的区别和联系的方式来理解,做到切实理解,深刻体会。 1、并行计算与分布式计算 并行计算、分布式计算都属于高性…...

Java牙科诊所管理系统web医院病例挂号预约平台springboot/ssm代码编写
Java牙科诊所管理系统web医院病例挂号预约平台springboot/ssm代码编写 基于springboot(可改ssm)htmlvue项目 开发语言:Java 框架:springboot/可改ssm vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库&…...

【Linux系统】信号:再谈OS与内核区、信号捕捉、重入函数与 volatile
再谈操作系统与内核区 1、浅谈虚拟机和操作系统映射于地址空间的作用 我们调用任何函数(无论是库函数还是系统调用),都是在各自进程的地址空间中执行的。无论操作系统如何切换进程,它都能确保访问同一个操作系统实例。换句话说&am…...

自定义数据集 使用paddlepaddle框架实现逻辑回归
导入必要的库 import numpy as np import paddle import paddle.nn as nn 数据准备: seed1 paddle.seed(seed)# 1.散点输入 定义输入数据 data [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6…...

LabVIEW图片识别逆向建模系统
本文介绍了一个基于LabVIEW的图片识别逆向建模系统的开发过程。系统利用LabVIEW的强大视觉处理功能,通过二维图片快速生成对应的三维模型,不仅降低了逆向建模的技术门槛,还大幅提升了建模效率。 项目背景 在传统的逆向建模过程中…...

MySQL(高级特性篇) 13 章——事务基础知识
一、数据库事务概述 事务是数据库区别于文件系统的重要特性之一 (1)存储引擎支持情况 SHOW ENGINES命令来查看当前MySQL支持的存储引擎都有哪些,以及这些存储引擎是否支持事务能看出在MySQL中,只有InnoDB是支持事务的 &#x…...

前端进阶:深度剖析预解析机制
一、预解析是什么? 在前端开发中,我们常常会遇到一些看似不符合常规逻辑的代码执行现象,比如为什么在变量声明之前访问它,得到的结果是undefined,而不是报错?为什么函数在声明之前就可以被调用?…...

C++实现一款功能丰富的通讯录管理系统
在学习编程的过程中,如何设计一个实用的项目是许多同学头疼的问题。如果你是一位正在学习C的同学,想通过实际项目巩固知识,那么这个通讯录管理系统绝对是一个理想的练手项目。在本文中,我将详细拆解代码逻辑,帮助你理解…...

Selenium 使用指南:从入门到精通
Selenium 使用指南:从入门到精通 Selenium 是一个用于自动化 Web 浏览器操作的强大工具,广泛应用于自动化测试和 Web 数据爬取中。本文将带你从入门到精通地掌握 Selenium,涵盖其基本操作、常用用法以及一个完整的图片爬取示例。 1. 环境配…...

【力扣】53.最大子数组和
AC截图 题目 思路 这道题主要考虑的就是要排除负数带来的负面影响。如果遍历数组,那么应该有如下关系式: currentAns max(prenums[i],nums[i]) pre是之前记录的最大和,如果prenums[i]小于nums[i],就要考虑舍弃pre,从…...

基于Spring Security 6的OAuth2 系列之七 - 授权服务器--自定义数据库客户端信息
之所以想写这一系列,是因为之前工作过程中使用Spring Security OAuth2搭建了网关和授权服务器,但当时基于spring-boot 2.3.x,其默认的Spring Security是5.3.x。之后新项目升级到了spring-boot 3.3.0,结果一看Spring Security也升级…...

vim-plug的自动安装与基本使用介绍
vim-plug介绍 Vim-plug 是一个轻量级的 Vim 插件管理器,它允许你轻松地管理 Vim 插件的安装、更新和卸载。相较于其他插件管理器,vim-plug 的优点是简单易用,速度较快,而且支持懒加载插件(即按需加载) 自动…...

Deep Crossing:深度交叉网络在推荐系统中的应用
实验和完整代码 完整代码实现和jupyter运行:https://github.com/Myolive-Lin/RecSys--deep-learning-recommendation-system/tree/main 引言 在机器学习和深度学习领域,特征工程一直是一个关键步骤,尤其是对于大规模的推荐系统和广告点击率预…...
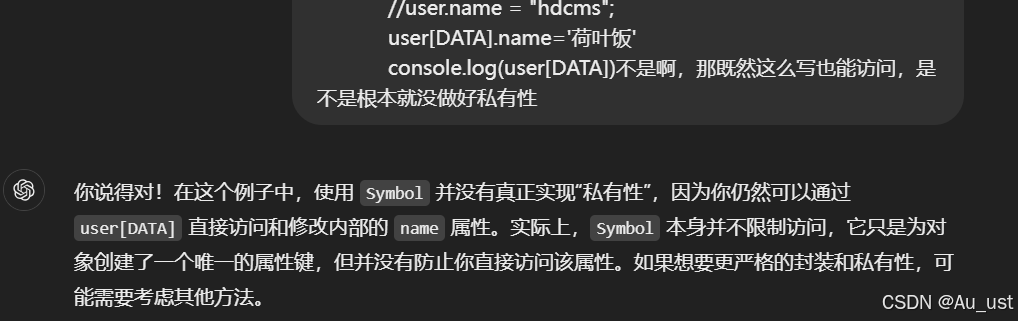
想品客老师的第十天:类
类是一个优化js面向对象的工具 类的声明 //1、class User{}console.log(typeof User)//function//2、let Hdclass{}//其实跟1差不多class Stu{show(){}//注意这里不用加逗号,对象才加逗号get(){console.log(后盾人)}}let hdnew Stu()hd.get()//后盾人 类的原理 类…...
:AJAX技术(前端发送请求))
4 前端前置技术(上):AJAX技术(前端发送请求)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 前言...

MyBatis-Plus速成指南:条件构造器和常用接口
Wrapper 介绍 Wrapper:条件构造抽象类,最顶端父类 AbstractWrapper:用于查询条件封装,生成 SQL 的 where 条件QueryWrapper:查询条件封装UpdateWrapper:Update 条件封装AbstractLambdaWrapper:使…...
空间复杂度-一次遍历双指针)
LeetCode 0922.按奇偶排序数组 II:O(1)空间复杂度-一次遍历双指针
【LetMeFly】922.按奇偶排序数组 II:O(1)空间复杂度-一次遍历双指针 力扣题目链接:https://leetcode.cn/problems/sort-array-by-parity-ii/ 给定一个非负整数数组 nums, nums 中一半整数是 奇数 ,一半整数是 偶数 。 对数组进…...

windows环境下如何在PyCharm中安装软件包
windows环境下如何在pyCharm中安装wxPython软件包 在windows环境中,安装软件包可以使用 终端 的方式,在IDE下方的终端中执行pip install wxPython进行安装,安装完毕之后,使用pip show wxPython检查也符合预期。 但是在代码文件中导…...

(脚本学习)BUU18 [CISCN2019 华北赛区 Day2 Web1]Hack World1
自用 题目 考虑是不是布尔盲注,如何测试:用"1^1^11 1^0^10,就像是真真真等于真,真假真等于假"这个测试 SQL布尔盲注脚本1 import requestsurl "http://8e4a9bf2-c055-4680-91fd-5b969ebc209e.node5.buuoj.cn…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.25 多线程并行:GIL绕过与真正并发
2.25 多线程并行:GIL绕过与真正并发 目录 #mermaid-svg-JO4lsTIyjOweVkos {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-JO4lsTIyjOweVkos .error-icon{fill:#552222;}#mermaid-svg-JO4lsTIyjOweVkos …...

Java 大视界 -- Java 大数据在智能医疗影像诊断中的应用(72)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也期待你毫无保留地分享独特见解,愿我们于此携手成长,共赴新程!💖 一、…...

【Leetcode刷题记录】1456. 定长子串中元音的最大数目---定长滑动窗口即解题思路总结
1456. 定长子串中元音的最大数目 给你字符串 s 和整数 k 。请返回字符串 s 中长度为 k 的单个子字符串中可能包含的最大元音字母数。 英文中的 元音字母 为(a, e, i, o, u)。 这道题的暴力求解的思路是通过遍历字符串 s 的每一个长度为 k 的子串…...

upload-labs安装与配置
前言 作者进行upload-labs靶场练习时,在环境上出了很多问题,吃了很多苦头,甚至改了很多配置也没有成功。 upload-labs很多操作都是旧时代的产物了,配置普遍都比较老,比如PHP版本用5.2.17(还有中间件等&am…...

从Transformer到世界模型:AGI核心架构演进
文章目录 引言:架构革命推动AGI进化一、Transformer:重新定义序列建模1.1 注意力机制的革命性突破1.2 从NLP到跨模态演进1.3 规模扩展的黄金定律二、通向世界模型的关键跃迁2.1 从语言模型到认知架构2.2 世界模型的核心特征2.3 混合架构的突破三、构建世界模型的技术路径3.1 …...

pytorch深度Q网络
人工智能例子汇总:AI常见的算法和例子-CSDN博客 DQN 引入了深度神经网络来近似Q函数,解决了传统Q-learning在处理高维状态空间时的瓶颈,尤其是在像 Atari 游戏这样的复杂环境中。DQN的核心思想是使用神经网络 Q(s,a;θ)Q(s, a; \theta)Q(s,…...

C++ 实现Arp断网
此程序由AI生成,测试过了,可以使用 但是,貌似全部都会断网 #include <pcap.h> #include <WinSock2.h> #include <iostream> #include <vector> #include <string> #include <sstream> #include <iom…...

每日一博 - 三高系统架构设计:高性能、高并发、高可用性解析
文章目录 引言一、高性能篇1.1 高性能的核心意义1.2 影响系统性能的因素1.3 高性能优化方法论1.3.1 读优化:缓存与数据库的结合1.3.2 写优化:异步化处理 1.4 高性能优化实践1.4.1 本地缓存 vs 分布式缓存1.4.2 数据库优化 二、高并发篇2.1 高并发的核心意…...

Vue2 项目中使用 Swiper
Swiper 是一个功能强大的轮播图库,支持触摸滑动、分页器、导航按钮等功能。本文将详细介绍如何在Vue2项目中集成Swiper 5,并通过watch和nextTick确保Swiper在数据加载完成后正确初始化。 1. 安装Swiper 5 首先,我们需要通过npm或yarn安装Sw…...