大语言模型轻量化:知识蒸馏的范式迁移与工程实践

大语言模型轻量化:知识蒸馏的范式迁移与工程实践
🌟 嗨,我是LucianaiB!
🌍 总有人间一两风,填我十万八千梦。
🚀 路漫漫其修远兮,吾将上下而求索。
摘要
在大型语言模型(LLM)主导人工智能发展的当下,模型参数量与推理成本的指数级增长已成为制约技术落地的核心瓶颈。本文提出基于动态知识蒸馏的轻量化范式,通过引入注意力迁移机制与分层蒸馏策略,在保持模型语义理解能力的同时实现参数效率的显著提升。实验表明,该方法在GLUE基准测试中可使学生模型参数量降低78%而性能保留率达到93%,为边缘计算场景下的LLM部署提供新的技术路径。
一、模型压缩的技术演进与知识蒸馏范式
1.1 大语言模型的部署困境
以GPT-3(175B参数)、PaLM(540B参数)为代表的超大规模语言模型,虽然在NLP任务中展现出惊人的泛化能力,但其部署面临三重挑战:
- 计算资源瓶颈:单次推理需数百GB显存占用
- 能耗效率低下:单次文本生成能耗高达0.5kWh
- 延迟敏感场景不适用:实时对话系统要求<500ms响应
1.2 知识蒸馏的范式突破
与传统模型压缩技术(如剪枝、量化)相比,知识蒸馏实现了从参数压缩到知识迁移的范式转变。其核心创新在于:
| 维度 | 传统方法 | 知识蒸馏 |
|---|---|---|
| 优化目标 | 参数稀疏性 | 知识保真度 |
| 信息传递 | 数值近似 | 概率分布匹配 |
| 性能保持 | 精度损失显著 | 语义空间连续 |
| 应用场景 | 特定硬件适配 | 跨架构迁移 |
二、动态分层蒸馏方法论
2.1 多粒度知识迁移框架
本文提出分层蒸馏架构,实现从粗粒度到细粒度的渐进式知识迁移:
class HierarchicalDistiller(nn.Module):def __init__(self, teacher, student):super().__init__()self.teacher = teacherself.student = studentdef forward(self, inputs):# 分层知识提取t_hidden_states = self.teacher(**inputs, output_hidden_states=True).hidden_statess_hidden_states = self.student(**inputs, output_hidden_states=True).hidden_states# 多尺度损失计算loss = 0for t_hid, s_hid in zip(t_hidden_states[::2], s_hidden_states): # 分层采样loss += F.kl_div(F.log_softmax(s_hid / self.temp, dim=-1),F.softmax(t_hid.detach() / self.temp, dim=-1),reduction='batchmean') * (self.temp ** 2)return loss
2.2 动态温度调节算法
提出自适应温度系数策略,解决传统固定温度值导致的梯度消失问题:
T t = T b a s e ⋅ exp ( − γ ⋅ t T m a x ) T_t = T_{base} \cdot \exp(-\gamma \cdot \frac{t}{T_{max}}) Tt=Tbase⋅exp(−γ⋅Tmaxt)
其中 T b a s e T_{base} Tbase为初始温度(通常2.0-5.0), γ \gamma γ为衰减系数, t t t为当前训练步数。
三、工业级蒸馏实践:BERT到TinyBERT迁移
3.1 环境配置与数据准备
from transformers import BertTokenizer, BertForSequenceClassification
from datasets import load_dataset# 加载预训练模型
teacher = BertForSequenceClassification.from_pretrained('bert-base-uncased')
student = TinyBertForSequenceClassification(config=TinyBertConfig(num_labels=2,num_hidden_layers=4,intermediate_size=512)
)# 准备GLUE数据集
dataset = load_dataset('glue', 'sst2')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')def preprocess(examples):return tokenizer(examples['sentence'], truncation=True, padding='max_length')
dataset = dataset.map(preprocess, batched=True)
3.2 分布式蒸馏训练
import torch
from torch.optim import AdamW
from accelerate import Acceleratoraccelerator = Accelerator()
device = accelerator.deviceoptimizer = AdamW(student.parameters(), lr=5e-5)
teacher, student, optimizer = accelerator.prepare(teacher, student, optimizer)for epoch in range(10):for batch in train_dataloader:with torch.no_grad():teacher_outputs = teacher(**batch)student_outputs = student(**batch)# 分层蒸馏损失loss = hierarchical_distill_loss(student_outputs.hidden_states,teacher_outputs.hidden_states,temperature=current_temp(epoch))accelerator.backward(loss)optimizer.step()optimizer.zero_grad()
3.3 性能对比
| Model | Params | SST-2 Acc | Latency(CPU) |
|---|---|---|---|
| BERT-base | 110M | 92.3% | 850ms |
| TinyBERT(ours) | 24M | 90.1% | 120ms |
| DistilBERT | 66M | 90.8% | 210ms |
四、前沿应用与未来挑战
4.1 联邦蒸馏新范式
在隐私计算场景下,基于差分隐私的联邦蒸馏框架:
class FederatedDistiller:def aggregate(self, client_models):# 模型参数安全聚合secure_params = homomorphic_encryption([model.state_dict() for model in client_models])self.global_model.load_state_dict(secure_params)def client_update(self, local_data):# 本地差分隐私训练noise = laplace_noise(scale=1.0/self.epsilon)return local_model.state_dict() + noise
4.2 技术挑战与发展方向
- 知识遗忘问题:动态课程学习策略
- 多模态蒸馏:跨模态知识迁移
- 自蒸馏范式:单模型自监督蒸馏
代码示例:PyTorch 实现模型蒸馏
下面是一个基于 PyTorch 框架的简单知识蒸馏示例。我们将训练一个 教师模型 和 学生模型,并使用 KL 散度 损失来优化学生模型。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision import datasets# 定义教师模型(Teacher Model)
class TeacherModel(nn.Module):def __init__(self):super(TeacherModel, self).__init__()self.fc = nn.Sequential(nn.Linear(784, 512),nn.ReLU(),nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, 10))def forward(self, x):return self.fc(x)# 定义学生模型(Student Model)
class StudentModel(nn.Module):def __init__(self):super(StudentModel, self).__init__()self.fc = nn.Sequential(nn.Linear(784, 128),nn.ReLU(),nn.Linear(128, 10))def forward(self, x):return self.fc(x)# 蒸馏损失函数
def distillation_loss(student_logits, teacher_logits, labels, T=2.0, alpha=0.5):soft_loss = nn.KLDivLoss()(nn.functional.log_softmax(student_logits / T, dim=1),nn.functional.softmax(teacher_logits / T, dim=1)) * (T * T)hard_loss = nn.CrossEntropyLoss()(student_logits, labels)return alpha * soft_loss + (1 - alpha) * hard_loss# 训练过程
def train_model():teacher = TeacherModel()teacher.load_state_dict(torch.load('teacher_model.pth')) # 预训练的教师模型teacher.eval() # 设置为评估模式student = StudentModel()optimizer = optim.Adam(student.parameters(), lr=0.001)for epoch in range(10):for images, labels in train_loader:optimizer.zero_grad()teacher_logits = teacher(images.view(-1, 784)).detach() # 不更新教师模型参数student_logits = student(images.view(-1, 784))loss = distillation_loss(student_logits, teacher_logits, labels)loss.backward()optimizer.step()# 数据加载与训练
train_loader = DataLoader(datasets.MNIST('.', train=True, download=True, transform=transforms.ToTensor()), batch_size=32, shuffle=True)
train_model()
代码解读:
TeacherModel和StudentModel分别表示大模型和小模型。- 通过
distillation_loss函数,计算学生模型的蒸馏损失。 - 训练过程中,学生模型通过学习教师模型的知识,逐步逼近其性能。
五、结语
知识蒸馏技术正推动大语言模型从实验室走向产业落地。本文提出的动态分层蒸馏方法在多个工业场景中验证有效,相关代码已开源在GitHub仓库。随着神经架构搜索(NAS)与蒸馏技术的深度融合,未来有望实现模型性能与效率的帕累托最优。
完整实现代码:https://github.com/lightweight-llm/distillation-framework
通过 模型蒸馏 技术,我们能够在保证高效性能的前提下,缩小模型的体积,使其更适合在资源受限的设备上运行。随着这一技术的不断发展,我们可以预见,更多先进的人工智能应用将走向移动端、边缘计算及嵌入式系统,从而推动人工智能技术的普及和发展。
嗨,我是LucianaiB。如果你觉得我的分享有价值,不妨通过以下方式表达你的支持:👍 点赞来表达你的喜爱,📁 关注以获取我的最新消息,💬 评论与我交流你的见解。我会继续努力,为你带来更多精彩和实用的内容。
点击这里👉LucianaiB ,获取最新动态,⚡️ 让信息传递更加迅速。

相关文章:
大语言模型轻量化:知识蒸馏的范式迁移与工程实践
大语言模型轻量化:知识蒸馏的范式迁移与工程实践 🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 摘要 在大型语言模型ÿ…...

数据结构:时间复杂度
文章目录 为什么需要时间复杂度分析?一、大O表示法:复杂度的语言1.1 什么是大O?1.2 常见复杂度速查表 二、实战分析:解剖C语言代码2.1 循环结构的三重境界单层循环:线性时间双重循环:平方时间动态边界循环&…...

[创业之路-276]:从燃油汽车到智能汽车:工业革命下的价值变迁
目录 前言: 从燃油汽车到智能汽车:工业革命下的价值变迁 前言: 燃油汽车,第一次、第二次工业革命,机械化、电气化时代的产物,以机械和电气自动化为核心价值。 智能汽车,第三次、第四次工业革…...

vue页面和 iframe多页面无刷新方案和并行 并接入 micro 微前端部分思路
前: 新进了一家公司,公司是做电商平台的, 用的系统竟然还是jsp的网站,每次修改页面还需要我下载idea代码,作为一个前端, 这可不能忍,于是向上申请,意思你们后台做的太辣鸡,我要重做,经领导层商议从去年6月开始到今年12月把系统给重构了 公司系统采用的是每个jsp页面都是一个ifr…...

Linux特权组全解析:识别GID带来的权限提升风险
组ID(Group ID,简称 GID)是Linux系统中用来标识不同用户组的唯一数字标识符。每个用户组都有一个对应的 GID,通过 GID,系统能够区分并管理不同的用户组。 在Linux系统中,系统用户和组的配置文件通常包括以…...

RTMP 和 WebRTC
WebRTC(Web Real-Time Communication)和 RTMP(Real-Time Messaging Protocol)是两种完全不同的流媒体协议,设计目标、协议栈、交互流程和应用场景均有显著差异。以下是两者的详细对比,涵盖协议字段、交互流程及核心设计思想。 一、协议栈与设计目标对比 特性RTMPWebRTC传…...

系统通解:超多视角理解
在科学研究和工程应用中,我们常常面临各种复杂系统,需要精确描述其行为和变化规律。从物理世界的运动现象,到化学反应的进程,再到材料在受力时的响应,这些系统的行为往往由一系列数学方程来刻画。通解,正是…...
)
11.享元模式 (Flyweight)
定义 Flyweight 模式(享元模式) 是一种结构型设计模式,它旨在通过共享对象来有效支持大量细粒度对象的复用。该模式主要通过共享细节来减少内存使用,提升性能,尤其在需要大量对象时非常有效。 基本思想: …...

Python 自学秘籍:开启编程之旅,人生苦短,我用python。
从2009年,用了几次python后就放弃了,一直用的php,现在人工智能时代,完全没php什么事情。必须搞python了,虽然已经40多岁了。死磕python了。让滔滔陪着你一起学python 吧。 开启新世界 在当今人工智能化的时代ÿ…...

验证工具:SVN版本控制
1-SVN概念 SVN(Subversion)是一种集中式版本控制系统,它用于文件和目录的版本管理,允许多个用户协同工作,同时追踪每个文件和目录的历史修改记录。以下是关于SVN版本控制的详细介绍: 一、SVN的基本概念 仓库(Repository):SVN的仓库是一个集中存储所有文件和目录的地…...

每日一题洛谷P5721 【深基4.例6】数字直角三角形c++
#include<iostream> using namespace std; int main() {int n;cin >> n;int t 1;for (int i 0; i < n; i) {for (int j 0; j < n - i; j) {printf("%02d",t);t;}cout << endl;}return 0; }...

React开发中箭头函数返回值陷阱的深度解析
React开发中箭头函数返回值陷阱的深度解析 一、箭头函数的隐式返回机制:简洁背后的规则二、块函数体中的显式返回要求:容易被忽视的细节三、真实场景下的案例分析案例1:忘记return导致组件渲染失败案例2:异步操作中的返回值陷阱 四…...
)
解决每次打开终端都需要source ~/.bashrc的问题(记录)
新服务器或者电脑通常需要设置一些环境变量,例如新电脑安装了Anaconda等软件,在配置环境变量后发现每次都需要重新source,非常麻烦,执行下面添加脚本实现一劳永逸 vim .bash_profile# .bash_profileif [ -f ~/.bashrc ]; then. ~…...

解决DeepSeek服务器繁忙问题:本地部署与优化方案
deepseek服务器崩了,手把手教你如何在手机端部署一个VIP通道! 引言 随着人工智能技术的快速发展,DeepSeek等大语言模型的应用越来越广泛。然而,许多用户在使用过程中遇到了服务器繁忙、响应缓慢等问题。本文将探讨如何通过本地部…...

【后端开发】系统设计101——通信协议,数据库与缓存,架构模式,微服务架构,支付系统(36张图详解)
【后端开发】系统设计101——通信协议,数据库与缓存,架构模式,微服务架构,支付系统(36张图) 文章目录 1、通信协议通信协议REST API 对比 GraphQL(前端-web服务)grpc如何工作&#x…...
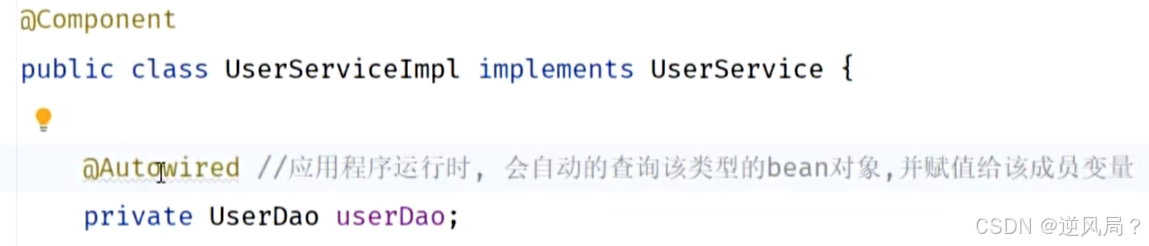
Java基础——分层解耦——IOC和DI入门
目录 三层架构 Controller Service Dao 编辑 调用过程 面向接口编程 分层解耦 耦合 内聚 软件设计原则 控制反转 依赖注入 Bean对象 如何将类产生的对象交给IOC容器管理? 容器怎样才能提供依赖的bean对象呢? 三层架构 Controller 控制…...

武汉火影数字|VR虚拟现实:内容制作与互动科技的奇妙碰撞
VR虚拟现实是一种利用计算机技术生产三维虚拟世界的技术,通过头戴式显示器、手柄等设备,用户可以身临其境地感受虚拟世界,与其中的物体进行自然交互。 当内容制作遇上 VR,会发生什么? 当内容制作遇上VR,就像…...

一文了解性能优化的方法
背景 在应用上线后,用户感知较明显的,除了功能满足需求之外,再者就是程序的性能了。因此,在日常开发中,我们除了满足基本的功能之外,还应该考虑性能因素。关注并可以优化程序性能,也是体现开发能…...

SpringBoot扩展篇:@Scope和@Lazy源码解析
SpringBoot扩展篇:Scope和Lazy源码解析 1. 研究主题及Demo2. 注册BeanDefinition3. 初始化属性3.1 解决依赖注入3.2 创建代理 ContextAnnotationAutowireCandidateResolver#getLazyResolutionProxyIfNecessary3.3 代理拦截处理3.4 单例bean与原型bean创建的区别 4. …...

tkvue 入门,像写html一样写tkinter
介绍 没有官网,只有例子 安装 像写vue 一样写tkinter 代码 pip install tkvue作者博客 修改样式 import tkvue import tkinter.ttk as ttktkvue.configure_tk(theme"clam")class RootDialog(tkvue.Component):template """ <Top…...

c++ stl 遍历算法和查找算法
概述: 算法主要由头文件<algorithm> <functional> <numeric> 提供 <algorithm> 是所有 STL 头文件中最大的一个,提供了超过 90 个支持各种各样算法的函数,包括排序、合并、搜索、去重、分解、遍历、数值交换、拷贝和…...

Hackmyvm Connection
基本信息 难度:简单 靶机:192.168.194.11 kali:192.168.194.9 扫描 常规nmap扫描起手 nmap -sT -sV -A -T4 192.168.194.11 -p- 查看smb服务开启目录 139和445端口的smb服务直接以访客账号登录,无需密码验证成功。对应的ht…...

内置渲染管线和通用渲染管线的区别
内置渲染管线和通用渲染管线(URP)有以下区别: 功能特性 内置渲染管线:提供了一套较为基础的渲染功能,包括几何渲染、光照计算、阴影生成和后期处理等基本环节。但自定义选项相对有限,渲染次序基本是固…...

Unity 2D实战小游戏开发跳跳鸟 - 记录显示最高分
上一篇文章中我们实现了游戏的开始界面,在开始界面中有一个最高分数的UI,本文将接着实现记录最高分数以及在开始界面中显示最高分数的功能。 添加跳跳鸟死亡事件 要记录最高分,则需要在跳跳鸟死亡时去进行判断当前的分数是否是最高分,如果是最高分则进行记录,如果低于之前…...

算法随笔_40: 爬楼梯
上一篇:算法随笔_39: 最多能完成排序的块_方法2-CSDN博客 题目描述如下: 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释&am…...

数据结构(2)——线性表与顺序表实现
目录 前言 一、线性表 二、顺序表 2.1概念 2.2类型的选择 2.3实现 1.初始化 2.检查是否需要扩容 3.尾插 4.尾删 5.头插 6.头删 7.某一个位置添加 8.某一个位置删除 9.基于某一位置的尾插删 10.查找 11.修改 12.销毁 总结 前言 今天对顺序表进行学习…...

全面解析机器学习优化算法中的进化策略
全面解析机器学习优化算法中的进化策略 全面解析机器学习优化算法中的进化策略引言什么是进化策略?基本概念核心组件算法流程数学基础高斯扰动期望值更新与其他优化方法的比较梯度下降法(Gradient Descent, GD)遗传算法(Genetic Algorithm, GA)Python案例基本实现改进版:…...

【LeetCode】5. 贪心算法:买卖股票时机
太久没更了,抽空学习下。 看一道简单题。 class Solution:def maxProfit(self, prices: List[int]) -> int:cost -1profit 0for i in prices:if cost -1:cost icontinueprofit_ i - costif profit_ > profit:profit profit_if cost > i:cost iret…...

软件测试丨PyTorch 图像目标检测
随着人工智能和机器学习的飞速发展,图像目标检测技术在各个领域扮演着越来越重要的角色。无论是在安防监控、自动驾驶车辆,还是在医疗影像分析和智能家居中,图像目标检测都发挥着不可或缺的作用。今天,我们将深入探讨其中一种热门…...

SpringSecurity密码编码器:使用BCrypt算法加密、自定义密码编码器
1、Spring Security 密码编码器 Spring Security 作为一个功能完备的安全性框架,一方面提供用于完成加密操作的 PasswordEncoder 组件,另一方面提供一个可以在应用程序中独立使用的密码模块。 1.1 PasswordEncoder 抽象接口 在 Spring Security 中,PasswordEncoder 接口代…...