【多线程】线程池核心数到底如何配置?
🥰🥰🥰来都来了,不妨点个关注叭!
👉博客主页:欢迎各位大佬!👈

文章目录
- 1. 前置回顾
- 2. 动态线程池
- 2.1 JMX 的介绍
- 2.1.1 MBeans 介绍
- 2.2 使用 JMX + jconsole 实现动态修改线程池
- 2.2.1 介绍 ManagementFactory
- 2.2.2 JMX 与 ManagementFactory 的区别与联系
回顾这期内容:【多线程】线程池,介绍了线程池,其中 5.3 介绍如何给线程池设置合适线程数量(这期内容会再回顾一遍),这期内容,具体讨论一下,线程池核心数到底如何配置~
1. 前置回顾
在实际开发中如何给线程池设置合适的线程数量呢?
我们要知道,线程不是越多越好,线程的本质上是要在 CPU 上调度的,一个线程池的线程数量设置为多少合适,这需要结合实际情况实际任务决定,一般分为 CPU 密集型和 IO 密集型,通常是如下配置:
- CPU 密集型任务:N+1,主要做一些计算工作,要在 CPU上运行
- IO 密集型任务:2N+1,主要是等待 IO 操作,比如等待读写硬盘,读写网卡等,不怎么消耗 CPU 资源
(其中 N 为 CPU 的核心数量)
Q:为什么要加 1
A:+1 个线程是为了在某个线程因为一些原因,比如缓存未命中、遇到短暂的指令停顿等,暂时阻塞时,能有一个额外的线程可以在 CPU 上运行,从而充分利用 CPU 的空闲时间,避免 CPU 核心出现空闲等待的情况,提高整体的 CPU 利用率,应对一些特殊情况或系统开销等,确保即使在某些线程出现意外阻塞等情况时,系统仍能有额外的线程来维持一定的处理能力,保证系统的稳定性和性能
极端情况下,如果线程全是使用 CPU 运行,线程数就不应该超过 CPU 核心数(逻辑核心,比如一个电脑是6核12线程,即12个逻辑核心,以12为基准),如果线程全是使用的 IO,则线程数可以设置很多,远远超出 CPU 的核心数
在实际开发中,很少有这么极端的情况,就是以实际情况来设定,需要具体通过测试的方式来确定,测试方式的大体思路是,运行程序,通过记录时间戳计算一下执行时间,同时监测资源的使用状态,线程数量取一个执行效率可以并且占用资源也还可以的数量~
这里的两个关键点:
- 记录时间戳计算执行时间
- 监测资源的使用状态
计算执行时间的具体操作方法是,可以统计一个完整的请求中,耗费 CPU 计算的过程占用了多少时间,等待的过程,如读取缓存、读取 DB 等占用了多少时间,假设统计结果是 100ms 用来做 CPU 计算,900ms 都是 IO 相关的操作,不占 CPU 时间,那么就可以通过 (100+900) / 100 的计算公式,得出对于单核 CPU,设置线程数为 10 就可以把 CPU 跑满,同理,如果是 6 核 CPU,那么就设置线程数为 60
监测资源的使用状态具体操作方法,在程序执行过程中,持续监测 CPU、内存、线程等资源的使用情况
具体代码如下:
import java.lang.management.ManagementFactory;
import java.lang.management.OperatingSystemMXBean;
import java.lang.management.ThreadMXBean;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class ResourceMonitoringExample {// 这里进行模拟任务static class Task implements Runnable {@Overridepublic void run() {try {// 模拟耗时操作Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}public static void main(String[] args) {int threadCount = 10; // 初始线程数量ExecutorService executor = Executors.newFixedThreadPool(threadCount);// 记录开始时间long startTime = System.currentTimeMillis();// 提交任务for (int i = 0; i < 20; i++) {executor.submit(new Task());}// 关闭线程池executor.shutdown();while (!executor.isTerminated()) {// 监测资源使用状态monitorResources();try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}// 记录结束时间long endTime = System.currentTimeMillis();long executionTime = endTime - startTime;System.out.printf("程序执行时间: %d 毫秒%n", executionTime);}// 监测资源使用状态private static void monitorResources() {// 监测 CPU 使用情况OperatingSystemMXBean osBean = ManagementFactory.getOperatingSystemMXBean();if (osBean instanceof com.sun.management.OperatingSystemMXBean) {com.sun.management.OperatingSystemMXBean sunOsBean = (com.sun.management.OperatingSystemMXBean) osBean;double cpuLoad = sunOsBean.getSystemCpuLoad();if (cpuLoad >= 0) {System.out.printf("当前系统 CPU 使用率: %.2f%%%n", cpuLoad * 100);}}// 监测线程数量ThreadMXBean threadBean = ManagementFactory.getThreadMXBean();int threadCount = threadBean.getThreadCount();System.out.printf("当前活动线程数量: %d%n", threadCount);}
}
其中:ManagementFactory 是 Java 中的一个实用工具类,位于 java.lang.management 包下,该类提供了一系列静态方法,用于获取 JVM 的各种管理接口实例,这些管理接口允许你监控和管理 JVM 的运行时状态、系统资源使用情况等(后文会详细介绍)~
总结:
线程池的核心参数并不是这么冰冷冷且固定的数字,还是需要结合实际场景考虑,一般线程池核心数,可以根据实际情况进行计算后配置~
下面介绍动态线程池,我们一起来看看~
2. 动态线程池
线程池线程数的设置是个难题,线程池核心数到底如何配置?最好的办法是能够动态调整线程池线程数,并能够看到调整后的效果,也就是线程利用率,有一个工具能够实现这样的效果 —— 使用 JMX
那么 JMX 是什么呢? 我们先来一起了解一下!
2.1 JMX 的介绍
- JMX 是什么:JMX(Java Management Extensions)是 Java 平台的一部分,它提供了一种管理和监控 Java 应用程序的标准方法,即是一个为应用程序、设备、系统等植入管理功能的框架,JMX 允许监控和管理系统资源、应用程序和服务,以及获取关于这些实体的运行时信息,简单来说,就是通过 JMX 可以动态查看对象的运行信息,并且可以动态修改对象属性~
- JMX 的架构:如下图

分析这张图我们可以发现,JMX 底层是由很多不同的 MBeans 组成的,即 MBeans 是 JMX 的核心
2.1.1 MBeans 介绍
MBeans 是什么:它们是实现了特定接口的 Java 对象,用于表示可以被监控和管理的资源
MBeans 的类型:可以分为四种不同的类型
- Standard MBeans
- Dynamic MBeans
- Open MBeans
- Model MBeans
MBeans 的作用:这些 MBeans 的作用就是获取对象的信息,或是修改对象信息,都是通过 MBeans 来完成的
MBeans 的用法:所有的 MBeans 都需要注册到 MBeanServer 上,然后再通过一些外部工具如 JMX、Web 浏览器等,就可以去获取或者修改 MBeans 的信息了
补充:
Q:那 MBean Server 是什么呢?
A:这里的 MBean Server 是一个代理,它提供一个注册、检索和操作 MBeans 的 API,它是 JMX 架构中的核心组件,负责管理所有 MBeans 的生命周期
接下来,我们一起来看看如何使用 JMX 诗仙女动态修改线程池
2.2 使用 JMX + jconsole 实现动态修改线程池
1)自定义一个动态线程池
首先,我们先来自定义一个动态线程池,如下:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;/*** Created with IntelliJ IDEA.* Description:* User: 26727* Date: 2025-02-05* Time: 18:41*/
public class DynamicThreadPool {private ThreadPoolExecutor threadPoolExecutor;public DynamicThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {threadPoolExecutor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);}public ThreadPoolExecutor getThreadPoolExecutor() {return threadPoolExecutor;}public void setCorePoolSize(int corePoolSize) {threadPoolExecutor.setCorePoolSize(corePoolSize);}public void setMaximumPoolSize(int maximumPoolSize) {threadPoolExecutor.setMaximumPoolSize(maximumPoolSize);}
}
动态线程池的相关参数如下,动态线程池其实就是传统的线程传统的线程池对象 ThreadPoolExecutor 封装了一下,并且提供了两个方法 setCorePoolSize 和 setMaximumPoolSize,这样通过这两个方法,我们就可以动态设置线程池的线程数了~

2)自定义一个 MBean 接口
接下来,我们自定义一个 MBean 这个接口中提供四个方法,分别用来获取或者设置线程数的信息
public interface DynamicThreadPoolMXBean {int getCorePoolSize();void setCorePoolSize(int corePoolSize);int getMaximumPoolSize();void setMaximumPoolSize(int maximumPoolSize);
}
3)自定义类实现 DynamicThreadPoolMXBean 接口
接着,我们自定义类实现 DynamicThreadPoolMXBean 接口,并继承 StandardMBean 类,如下:
import javax.management.MBeanServer;
import javax.management.ObjectName;
import javax.management.StandardMBean;
import java.lang.management.ManagementFactory;/*** Created with IntelliJ IDEA.* Description:* User: 26727* Date: 2025-02-04* Time: 23:02*/
public class DynamicThreadPoolMBean extends StandardMBean implements DynamicThreadPoolMXBean {private DynamicThreadPool dynamicThreadPool;public DynamicThreadPoolMBean(DynamicThreadPool dynamicThreadPool) throws Exception {super(DynamicThreadPoolMXBean.class);this.dynamicThreadPool = dynamicThreadPool;registerMBean();}private void registerMBean() {try {MBeanServer mbs = ManagementFactory.getPlatformMBeanServer();ObjectName name = new ObjectName("org.javaboy:type=DynamicThreadPool");mbs.registerMBean(this, name);} catch (Exception e) {e.printStackTrace();}}@Overridepublic int getCorePoolSize() {return dynamicThreadPool.getThreadPoolExecutor().getCorePoolSize();}@Overridepublic void setCorePoolSize(int corePoolSize) {dynamicThreadPool.setCorePoolSize(corePoolSize);}@Overridepublic int getMaximumPoolSize() {return dynamicThreadPool.getThreadPoolExecutor().getMaximumPoolSize();}@Overridepublic void setMaximumPoolSize(int maximumPoolSize) {dynamicThreadPool.setMaximumPoolSize(maximumPoolSize);}
}
【解析】
-
构造函数接受一个 DynamicThreadPool 类型的参数,用于初始化 dynamicThreadPool 的成员变量
super(DynamicThreadPoolMXBean.class)调用父类 StandardMBean 的构造函数,传入 DynamicThreadPoolMXBean 类的 Class 对象,用于指定 MBean 的管理接口,调用 registerMBean() 方法将该 MBean 注册到 JMX 平台 MBean 服务器中,即在构造器中,调用了 registerMBean() 方法,这个方法用来将当前对象注册到 MBeanServer 上~ -
注册 MBean 方法
registerMBean(),ManagementFactory.getPlatformMBeanServer()获取平台 MBean 服务器的实例,ObjectName 用于唯一标识 MBean,这里使用org.javaboy:type=DynamicThreadPool作为 MBean 的名称,
mbs.registerMBean(this, name)将当前 DynamicThreadPoolMBean 实例注册到 MBean 服务器中
4)执行代码
最后,就可以启动自己的这段代码了~
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.TimeUnit;/*** Created with IntelliJ IDEA.* Description:* User: 26727* Date: 2025-02-04* Time: 23:07*/
public class Main {public static void main(String[] args) throws Exception {DynamicThreadPool dynamicThreadPool = new DynamicThreadPool(2, 6, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(10));DynamicThreadPoolMBean mBean = new DynamicThreadPoolMBean(dynamicThreadPool);while (true) {System.out.println("CorePoolSize:"+dynamicThreadPool.getThreadPoolExecutor().getCorePoolSize());System.out.println("MaximumPoolSize:"+dynamicThreadPool.getThreadPoolExecutor().getMaximumPoolSize());try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
为了看到线程池的线程数量,这里使用了一个死循环一直打印线程数量信息,这样一会通过 jconsole 修改线程池信息的时候,就能看到修改的效果了~
程序启动之后,使用 jconsole 连接上当前应用程序,如下图:
(jconsole 使用忘记的小伙伴可回顾往期内容:【多线程】如何使用jconsole工具查看Java线程的详细信息?)
点击 Main 进入连接

点击 MBean 这个选项卡位置,可以看到刚刚配置的 MBean,右侧的值则可以点击直接修改,修改之后,回到应用程序控制台,可以发现线程相关数据已经发生变化了,实现了动态修改的效果~

可以看到,控制台信息已经发生变化,如下:

这样就可以动态修改了!
2.2.1 介绍 ManagementFactory
可以看到上面使用了 ManagementFactory 类,下面具体介绍其用法:
1) 获取线程管理接口实例 —— getThreadMXBean()
返回一个 ThreadMXBean 实例,用于监控和管理 Java 虚拟机中的线程,通过该接口,可以获取线程的各种信息,如线程的状态、CPU 时间、阻塞时间等
import java.lang.management.ManagementFactory;
import java.lang.management.ThreadMXBean;public class ThreadMonitoringExample {public static void main(String[] args) {// 获取 ThreadMXBean 实例ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();// 获取所有线程的 IDlong[] threadIds = threadMXBean.getAllThreadIds();for (long threadId : threadIds) {// 获取线程信息System.out.println("Thread ID: " + threadId + ", Thread Name: " + threadMXBean.getThreadInfo(threadId).getThreadName());}}
}
2)获取内存管理接口实例 —— getMemoryMXBean()
返回一个 MemoryMXBean 实例,用于监控和管理 Java 虚拟机的内存使用情况。通过该接口,可以获取堆内存和非堆内存的使用情况,还可以触发垃圾回收操作~
import java.lang.management.ManagementFactory;
import java.lang.management.MemoryMXBean;
import java.lang.management.MemoryUsage;public class MemoryMonitoringExample {public static void main(String[] args) {// 获取 MemoryMXBean 实例MemoryMXBean memoryMXBean = ManagementFactory.getMemoryMXBean();// 获取堆内存使用情况MemoryUsage heapMemoryUsage = memoryMXBean.getHeapMemoryUsage();System.out.println("Heap Memory Usage: " + heapMemoryUsage);// 获取非堆内存使用情况MemoryUsage nonHeapMemoryUsage = memoryMXBean.getNonHeapMemoryUsage();System.out.println("Non-Heap Memory Usage: " + nonHeapMemoryUsage);}
}
3)获取运行时管理接口实例 —— getRuntimeMXBean()
返回一个 RuntimeMXBean 实例,用于获取 Java 虚拟机的运行时信息,如 JVM 的启动时间、系统属性、命令行参数等
import java.lang.management.ManagementFactory;
import java.lang.management.RuntimeMXBean;public class RuntimeInfoExample {public static void main(String[] args) {// 获取 RuntimeMXBean 实例RuntimeMXBean runtimeMXBean = ManagementFactory.getRuntimeMXBean();// 获取 JVM 启动时间long startTime = runtimeMXBean.getStartTime();System.out.println("JVM Start Time: " + startTime);// 获取系统属性System.out.println("System Properties: " + runtimeMXBean.getSystemProperties());}
}
ManagementFactory 类为 Java 开发者提供了便捷的方式来监控和管理 JVM 的运行时状态,通过获取不同的管理接口实例,可以深入了解 JVM 的内部运行情况,从而进行性能调优、故障排查等相关工作~
2.2.2 JMX 与 ManagementFactory 的区别与联系
区别:
JMX —— Java 扩展管理,是一个为应用程序、设备、系统等植入管理功能的框架
ManagementFactory —— Java 标准库中用于辅助使用 JMX 功能的实用工具类
联系:
- ManagementFactory 是 JMX 功能使用的便捷入口
JMX 架构复杂:JMX 定义了一套完整的架构,包括 MBean、MBeanServer等核心组件,使用 JMX 进行管理和监控时,需要涉及多个步骤和类的使用,整体较为复杂,而 ManagementFactory 简化操作,ManagementFactory 类提供了一系列静态方法,通过调用这些方法可以方便地获取各种 JMX 管理接口的实例。如,ManagementFactory.getThreadMXBean() 方法返回的 ThreadMXBean 是一个 JMX 的 MXBean,它允许开发者监控和管理 Java 虚拟机中的线程。这些方法隐藏了底层 JMX 架构的复杂性,使得开发者可以更轻松地使用 JMX 功能~ - ManagementFactory 实例基于 JMX 标准
ManagementFactory 所返回的各种管理接口实例(如 MemoryMXBean、RuntimeMXBean 等)都是遵循 JMX 规范的 MXBean,这些 MXBean 定义了一组标准的管理操作和属性,可以通过 JMX 代理进行访问和管理,并且可集成到 JMX 系统,通过 ManagementFactory 获取的管理接口实例可以无缝集成到 JMX 系统中。开发者可以将这些 MXBean 注册到 MBeanServer 上,然后使用 JMX 客户端远程或本地监控和管理 Java 应用程序~ - ManagementFactory 服务于 JMX 监控和管理目的
支持监控:JMX 的主要目的之一是对 Java 应用程序进行监控和管理,ManagementFactory 所提供的各种管理接口实例可以提供丰富的监控数据,例如,MemoryMXBean 可以提供 Java 虚拟机的内存使用情况,包括堆内存和非堆内存的使用量、峰值等信息;并且ThreadMXBean 可以提供线程的状态、CPU 时间等信息。
支持管理:除了监控数据,ManagementFactory 所提供的管理接口实例还支持一些管理操作,例如,MemoryMXBean 可以触发垃圾回收操作,ThreadMXBean 可以获取线程的堆栈跟踪信息等,这些操作可以帮助开发者对 Java 应用程序进行动态管理和故障排查~

💛💛💛本期内容回顾💛💛💛

✨✨✨本期内容到此结束啦~
相关文章:
【多线程】线程池核心数到底如何配置?
🥰🥰🥰来都来了,不妨点个关注叭! 👉博客主页:欢迎各位大佬!👈 文章目录 1. 前置回顾2. 动态线程池2.1 JMX 的介绍2.1.1 MBeans 介绍 2.2 使用 JMX jconsole 实现动态修改线程池2.2.…...

三维空间全局光照 | 及各种扫盲
Lecture 6 SH for diffuse transport Lecture 7关于 SH for glossy transport 三维空间全局光照 diffuse case和glossy case的区别 在Lambertian模型中,BRDF是一个常数 diffuse case 跟outgoing point无关 glossy case 跟outgoing point有关 (Gloss…...

通过C/C++编程语言实现“数据结构”课程中的链表
引言 链表(Linked List)是数据结构中最基础且最重要的线性存储结构之一。与数组的连续内存分配不同,链表通过指针将分散的内存块串联起来,具有动态扩展和高效插入/删除的特性。本文将以C/C++语言为例,从底层原理到代码实现,手把手教你构建完整的链表结构,并深入探讨其应…...

Polardb三节点集群部署安装--附虚拟机
1. 架构 PolarDB-X 采用 Shared-nothing 与存储计算分离架构进行设计,系统由4个核心组件组成。 计算节点(CN, Compute Node) 计算节点是系统的入口,采用无状态设计,包括 SQL 解析器、优化器、执行器等模块。负责数据…...

java s7接收Byte字节,接收word转16位二进制
1图: 2.图: try {List list getNameList();//接收base64S7Connector s7Connector S7ConnectorFactory.buildTCPConnector().withHost("192.168.46.52").withPort(102).withTimeout(1000) //连接超时时间.withRack(0).withSlot(3).build()…...

挑战项目 --- 微服务编程测评系统(在线OJ系统)
一、前言 1.为什么要做项目 面试官要问项目,考察你到底是理论派还是实战派? 1.希望从你的项目中看到你的真实能力和对知识的灵活运用。 2.展示你在面对问题和需求时的思考方式及解决问题的能力。 3.面试官会就你项目提出一些问题,或扩展需求…...

基于springboot的体质测试数据分析及可视化设计
作者:学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等 文末获取“源码数据库万字文档PPT”,支持远程部署调试、运行安装。 项目包含: 完整源码数据库功能演示视频万字文档PPT 项目编码࿱…...

java-重载与重写
介绍 在 Java 中,重载(Overloading) 和 重写(Overriding) 是两个重要的概念,它们都与方法有关,但它们的应用场景和行为完全不同。 通过理解重载和重写的区别,可以更好地设计类的继承…...

使用C++构建一个优先级队列
1.优先级队列的介绍 优先级队列是一种特殊的队列数据结构,它是队列,但又不完全是,因为它要将装载的数据进行优先级排序,找到一个最大或者最小优先级的元素,下一次出队列的元素就是这个元素,所以说它不完全是…...

linux驱动开发之字符设备与总线设备驱动模型的区别与联系
Linux驱动开发核心概念解析 1. 字符设备(Character Device) 定义与特点: 以字节流形式进行数据交换,适用于顺序访问的设备(如键盘、鼠标、串口)。 用户空间通过设备文件(如/dev/xxx࿰…...

AI deepseek对数据治理的影响
DEEPSEEK作为智能一款助手,在数据治理体系中具有深远的影响。它通过提供智能化、自动化和高效化的解决方案,推动企业在数据治理变革与领域的优化。以下是EPSEEK对数据治理体系影响的多角度分析: 一、战略层面:推动数据治理目标的…...

DeepSeek各版本说明与优缺点分析
DeepSeek各版本说明与优缺点分析 DeepSeek是最近人工智能领域备受瞩目的一个语言模型系列,其在不同版本的发布过程中,逐步加强了对多种任务的处理能力。本文将详细介绍DeepSeek的各版本,从版本的发布时间、特点、优势以及不足之处࿰…...

iOS 老项目适配 #Preview 预览功能
前言 iOS 开发者 最憋屈的就是UI 布局慢,一直以来没有实时预览功能,虽然swiftUI 早就支持了,但是目前主流还是使用UIKit在布局,iOS 17 苹果推出了 #Preview 可以支持UIKit 实时预览,但是仅仅是 iOS 17,老项目怎么办呢?于是就有了这篇 老项目适配 #Preview 预览 的文章,…...

在ubuntu22.04上先部署docker,再编译安装kamailio,附详细操作流程及docker和makailio的版本号
以下是在Ubuntu 22.04上部署Docker并编译安装Kamailio的详细操作流程,包含版本号信息: 一、部署Docker(版本:24.0.7) 更新系统包 sudo apt update && sudo apt upgrade -y安装依赖工具 sudo apt install -y ap…...

蓝桥杯试题:排序
一、问题描述 给定 nn 个正整数 a1,a2,…,ana1,a2,…,an,你可以将它们任意排序。现要将这 nn 个数字连接成一排,即令相邻数字收尾相接,组成一个数。问,这个数最大可以是多少。 输入格式 第一行输入一个正整数 nnÿ…...

C++常用拷贝和替换算法
算法简介: copy // 容器内指定的元素拷贝到另一容器replace // 将容器内指定范围的旧元素改为新元素replace_if // 容器内指定范围满足条件的元素替换为新元素swap //互换两个容器的元素 1. copy 功能描述: 将容器内指定范围的数据拷贝到另一容器中函…...

2024年12月 Scratch 图形化(三级)真题解析 中国电子学会全国青少年软件编程等级考试
202412 Scratch 图形化(三级)真题解析 中国电子学会全国青少年软件编程等级考试 一、选择题(共18题,共50分) 第 1 题 气温和对应的穿衣建议如下表所示,下列选项能正确给出穿衣建议的是?( ) A. …...

C# 中记录(Record)详解
从C#9.0开始,我们有了一个有趣的语法糖:记录(record) 为什么提供记录? 开发过程中,我们往往会创建一些简单的实体,它们仅仅拥有一些简单的属性,可能还有几个简单的方法,比如DTO等等…...

【MQTT协议 03】 抓包分析
一、MQTT测试工具 1、mqtt服务器 emqx 2、mqtt 客户端 mqttx 3、抓包工具 wireshark 搭建参考 【MQTT 协议 01】MQTT 服务器搭建_mqtt服务器搭建-CSDN博客 二、报文测试 2.1、CONNECT (客户端连接) 2.1.1、抓包 2.1.2、解析 #16进制表示 10300…...

深度学习-100-RAG技术之最简单的RAG系统概念和效果优化提升方向
文章目录 1 数据是基础2 Naive RAG(最简单的RAG系统)2.1 RAG周边技术2.2 标准的RAG流程2.3 RAG的潜在问题2.4 如何应对RAG的问题3 优化方向3.1 原始数据创建/准备3.1.1 易于理解的文本3.1.2 提高数据质量3.2 预检索优化3.2.1 分块优化3.2.2 添加元数据3.2.3 选对嵌入模型3.2.4 …...
)
Redis面试题总结(题目来源JavaGuide)
Redis 基础 问题1:Redis 有什么作用?为什么要用 Redis/为什么要用缓存? Redis 是一个开源的高性能键值对数据库,它的作用主要体现在以下几个方面: 缓存:Redis 常被用作缓存系统,可以将频繁访问的数据存储…...

Django 多数据库
django 支持项目连接多个数据库 DATABASES = {default: {ENGINE: django.db.backends.mysql,NAME: xxx,USER: root,"PASSWORD": xxxxx,HOST: xxxx,PORT: 3306,},bak: {ENGINE: django.db.backends.mysql,NAME: xxx,USER: root,"PASSWORD": xxxx,HOST: xxx…...

为AI聊天工具添加一个知识系统 之87 详细设计之28 Derivation 统一建模元模型 之1
文本要点 要点 Derivation 统一建模元模型 Derivation 统一建模元模型:意识原型的祖传代码,即支撑 程序框架的 符号学中的 自然和逻辑树。 这棵树的雏形中描述了三种建模工件:语用钩子,语法糖和语义胶水。 三种工件对应的三“…...

手机上运行AI大模型(Deepseek等)
最近deepseek的大火,让大家掀起新一波的本地部署运行大模型的热潮,特别是deepseek有蒸馏的小参数量版本,电脑上就相当方便了,直接ollamaopen-webui这种类似的组合就可以轻松地实现,只要硬件,如显存…...

电商项目-分布式事务(四)基于消息队列实现分布式事务
基于消息队列实现分布式事务,实现消息最终一致性 如何基于消息队列实现分布式事务? 通过消息队列实现分布式事务的话,可以保证当前数据的最终一致性。实现思路:将大的分布式事务,进行拆分,拆分成若干个小…...

leetcode_双指针 160.相交链表
160.相交链表 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 思路: 本题中,交点不是数值相等,而是指针相等 双指针遍历两遍后必定相遇,…...

深入理解浮点数:单精度、双精度、半精度和BFloat16详解
文章目录 深入理解浮点数:单精度、双精度、半精度和BFloat16详解 🔢简介 🌟1. 单精度(Single Precision)🎯应用场景 🚀 2. 双精度(Double Precision)💪应用场…...
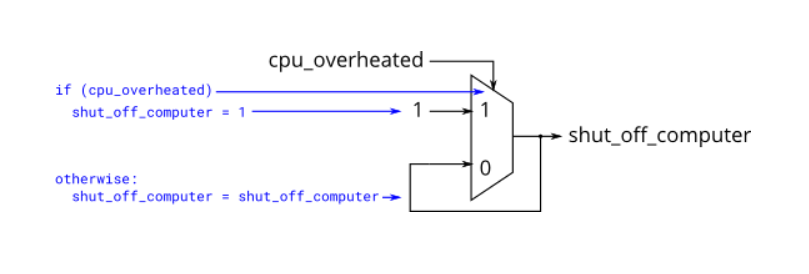
Verilog基础(三):过程
过程(Procedures) - Always块 – 组合逻辑 (Always blocks – Combinational) 由于数字电路是由电线相连的逻辑门组成的,所以任何电路都可以表示为模块和赋值语句的某种组合. 然而,有时这不是描述电路最方便的方法. 两种always block是十分有用的: 组合逻辑: always @(…...

前端知识速记:POST和GET
前端知识速记:POST和GET请求的区别 一、GET请求概述 GET请求是一种用于获取服务器资源的请求方式。**使用GET请求时,数据通过URL传递,适合用于获取数据而不修改资源。**以下是GET请求的一些基本特征: 数据附在URL后面ÿ…...

【Java】MyBatis动态SQL
在MyBatis中使用动态SQL语句。 动态SQL是指根据参数数据动态组织SQL的技术。 生活中的案例: 在京东上买东西时,用户搜索商品,可以选择筛选条件,比如品牌,价格,材质等,也可以不使用筛选条件。这时…...