八大排序算法细讲
目录
排序
概念
运用
常见排序算法
插入排序
直接插入排序
思想:
步骤(排升序):
代码部分:
时间复杂度:
希尔排序
思路
步骤
gap的取法
代码部分:
时间复杂度:
选择排序
直接选择排序
排升序思路:
排升序步骤:
代码部分:
时间复杂度:
堆排序
代码部分:
交换排序
冒泡排序
代码部分:
快速排序(递归版本)
思路:
hoare版本
排升序步骤:
相遇问题:
代码部分:
挖坑法版本
排升序思路:
代码部分:
前后指针版本:
排升序思路:
代码部分:
时间复杂度:
快速排序(非递归版本)
思路:
注意:
编辑
代码部分(找基准值部分用的是前后指针方法):
归并排序
思路:
排升序步骤:
代码部分:
时间复杂度:
非比较排序
计数排序
思路:
代码部分:
时间复杂度:
排序算法复杂度及稳定性分析
排序
概念
排序就是将一段记录,按照其中的某个或某些关键字大小,实现递增或递减的操作
运用
排序在我们的生活中运用也是极其广泛的,如:在购物软件中,根据不同条件来筛选商品;大学院校的排名……等等
常见排序算法

插入排序
直接插入排序
思想:
把待排序的记录按其关键码值的大小逐个插入到⼀个已经排好序的有序序列中,直到所有的记录插入完为止,得到⼀个新的有序序列
这种排序算法类似于玩扑克牌,就是依次将手中的牌进行排序
步骤(排升序):
1、先取出第二张牌与第一张进行比较,小的放前面,大的放后面
2、让后面的牌再进行上面那一步
这样看起来会比较抽象,举一个例子来实现就容易理解了

代码部分:
void InsertSort(int* arr, int n)
{for (int i = 0; i < n - 1; ++i){int end = i;int temp = arr[end + 1];while (end >= 0){if (arr[end] > temp){arr[end + 1] = arr[end];end--;}else{break;}}arr[end + 1] = temp;}
}
时间复杂度:
直接插入排序的时间复杂度为O(N^2),但在一般情况下是不会达到N^2的,只有在排序数组与要求排序方向相反时(也就是逆序),才会达到O(N^2)
这也就导致了一个问题,在面对逆序情况下,使用该排序算法,效率就会大大降低
面对这种情况,前人就在直接插入排序算法的基础上进行了改良,也就是接下来要讲的——希尔排序
希尔排序
根据上面的直接插入排序算法我们可以知道,在面对逆序数组时,算法复杂度太大了(O(N^2)),
所以前人就在该算法基础上进行了改良
思路
先选定一个整数,命名为gap,通常是gap=n/3+1,将带排序数组中元素根据gap值分为多组,也就是将相距gap值的元素分在同一组中,然后对每一组的元素进行排序,这是就完成一次排序,然后gap=gap/3+1,,再将数组根据gap值分为多组,进行插入排序,当gap=1时,就相当于进行直接插入排序算法。
步骤
步骤一(当gap>1):
1、将数组根据gap分为多组
2、将相距gap值的元素进行比较
注:步骤一也可以称为预排序,目的是为了:将数组转变为一个相对有序的情况,避免直接插入排序在面对逆序数组情况时时间复杂度变大
排升序时:小的元素在前面,大的元素在后面
排降序时:大的元素在前面,小的元素在后面
步骤二(当gap=1):
就相当于进行直接插入排序
举例可知

gap的取法
gap值的最初值取该数组的长度,当它进入while循环时,就先进行gap=gap/+1
然而,为什么是对gap/3,而不是除以其他值呢?
如果gap除以的值过小的话,比如:gap=gap/2,就会导致分的组太少,而每组内元素比较次数过多,while循环次数也会增多(因为gap值要不断除以2,直到gap=1时停止while循环)
如果gap除以的值过大的话,比如:gap=gap/8,就会导致分的组过多,而每组内元素比较次数较少,while循环次数少
所以gap除以的值要取适中的值,3则是较好的值
那为何还要加一呢?
加一的目的是为防止gap整除的值为0,这样可以防止gap=0时,直接退出循环,没有排序完全
代码部分:
void ShellSort(int* arr, int n)
{int gap = n;while (gap > 1)//gap不能等于1,如果为一进入循环,在gap/3+1中就会一直为1,就会死循环{gap = gap / 3 + 1;for (int i = 0; i < n - gap; ++i){int end = i;int temp = arr[end + gap];while (end >= 0){if (arr[end] > temp){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end + gap] = temp;}}}时间复杂度:
希尔排序算法的时间复杂度不好计算,大概为O(N^1.3)
选择排序
直接选择排序
排升序思路:
每一次循环,先从待排数组中找出最大和最小值,将最小值与待排数组的起始位置交换,最大值与待排数组的最后一个元素交换,直到所有待排数组元素排完
排升序步骤:
1、设立起始位置和最后一元素下标位置:begin、end,然后找到最大值和最小值下标
2、将最小值和起始元素交换、最大值和末尾元素交换
3、交换后,begin++、end--,然后进行[begin,end]区间元素的排序,按照上面两步
4、直到begin>end时结束排序

注:当begin与maxi、end与mini重叠时,会造成重复交换,所以就需要将maini和mini进行交换
代码部分:
void SelectSort(int* arr, int n)
{int begin = 0, end = n - 1;while (begin < end){int mini , maxi;mini = maxi = begin;for (int i = begin + 1; i <= end; ++i){if (arr[i] > arr[maxi]){maxi = i;}if (arr[i] < arr[mini]){mini = i;}}if (begin == maxi){maxi = mini;}Swap(&arr[begin], &arr[mini]);Swap(&arr[end], &arr[maxi]);begin++;end--;}
}时间复杂度:
直接选择排序的时间复杂度很好理解,为O(N^2),因为它的效率不是很好,所以实际上很少会用到
堆排序
堆排序的讲解,在前面的文章已经讲解过了,就不在这里过多说明,有兴趣的朋友可以移步
二叉树:堆的建立和应用_二叉树的应用,两种创建方式-CSDN博客
代码部分:
void AdJustDown(int* arr, int parent, int n)//向下调整
{int child = parent * 2 + 1;while (child < n){//这里左右孩子的比较,c>c+1,交换建小堆;c<c+1,交换建大堆//建大堆,先找大孩子;建小堆,先找小孩子if (child + 1 < n && arr[child] < arr[child + 1]){child++;}//>建大堆//<建小堆if (arr[child] > arr[parent]){Swap(&arr[child], &arr[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
void HeapSort(int* arr, int n)//向下调整算法建堆:时间复杂度O(n)
{//排升序建大堆//排降序建小堆//先建堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdJustDown(arr, i, n);}//再排序int end = n - 1;while (end > 0){Swap(&arr[0], &arr[end]);//交换堆顶和尾结点AdJustDown(arr, 0, end);end--;}}交换排序
冒泡排序
冒泡排序大家应该都不陌生,是我们C语言学习的第一个排序算法,它的时间复杂度为O(N^2),
关于它的思路步骤我就不过多说明了,它在实际当中也基本不会用到,它是起着一种教学作用的排序算法
代码部分:
void BubbleSort(int* arr, int n)
{int i = 0;for (i = 0; i < n - 1; ++i){int j = 0;int flag = 1;for (j = 0; j < n - 1 - i; ++j){if (arr[j] > arr[j + 1]){int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;flag = 0;}}if (flag == 1)//当提前完成排序后,就直接退出循环{break;}}
}快速排序(递归版本)
快速排序可以说是排序算法中最重要的排序算法,在实际学习和工作中运用得最多,接下来我们来好好学习快速排序算法
思路:
任取待排数组中某一个元素作为基准值(key),然后将基准值放到正确位置上,按照基准值将数组分割成两个序列,左子序列中所有元素小于基准值,右子序列中所有元素大于基准值(这里排升序),然后再对左右子序列重复该过程,直到所有元素都排列再在相对应位置上为止
hoare版本
排升序步骤:
1、找基准值:
起始令首元素为基准值(key),设right和left,right为末尾元素下标,left为首元素下标,
让left从左往右找比基准值大的值,right从右往左找比基准值大的值,
找到以后将left与right指向的值进行交换,这个交换的前提是right>=left;
而当right小于left时right所指向的值就与key进行交换,这时key就回到了正确的位置
2、二分
根据key所在位置,对数组进行二分,将数组分为左右两个子序列,然后再对左右两个子序列进行上述操作

相遇问题:
1、相遇点值小于基准值

由此可知,当相遇点小于基准值时,left依旧减减
2、相遇点值大于基准值

由此可知,当相遇点大于基准值时,right依旧加加
3、当相遇点值等于基准值

这种情况看似两种都可以,但是当选择了right依旧减减时,就会导致面对下面这种情况时,时间复杂度大大提高

这种情况便是相遇点值与基准值相同的情况,在这种情况下,该排序算法的时间复杂度就会大大提高,无法进行高效的分割排序
其实这也是这种hoare版本快速排序在面对待排数组中重复元素过多情况下的弊端
代码部分:
int Hoare_QuickSort(int* arr, int left, int right)
{int keyi = left;left++;while (left <= right){//rigth从右往左找比基准值小的值while (left<=right && arr[right]>arr[keyi])//这里的arr[rigth]>arr[keyi]只能取大于号,不能加上等于号,//加上的话在面对数组全相等或有序数组时,时间复杂度会变大{right--;}//left从左往右找比基准值大的值while (left<=right && arr[left]<arr[keyi])//这里的情况和rigth是一样的{left++;}if (left <= right)//当left还未大于rigth时,就进行交换{Swap(&arr[left], &arr[right]);}}Swap(&arr[right], &arr[keyi]);keyi = right;return keyi;
}void QuickSort(int* arr, int left, int right)//排升序
{if (left >= right){return;}//找基准值int keyi = Hoare_QuickSort(arr, left, right);//二分//[left,keyi-1] keyi [keyi+1,right]QuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);}挖坑法版本
排升序思路:
设立左右指针:left、right,先将基准值视为第一个坑:hole,
right从右往左找比基准值小的数,找到以后就放入到hole的位置,然后righ处就为新的坑;
left从左往右找比基准值大的数,找到以后就放入到hole的位置,然后left处就为新的坑;
当right==left时,就将保存的基准值放入到两者相遇处
就这样便完成了第一次基准值的寻找
找到以后就和hoare版本一样进行二分
注:
这种方法起始的left只能指向首元素;
和hoare版本不同的是,当right从右往左找比基准值小的值时,当遇到比基准值大的或者等于的值时,继续往左找;left也是一样的

代码部分:
int Hole_QuickSort(int* arr, int left, int right)
{int hole = left;int key = arr[hole];while (left < right){while (left<right && arr[right]>=key){right--;}//找到比基准值小的值arr[hole] = arr[right];hole = right;while (left<right && arr[left]<=key){left++;}//找到比基准值大的值arr[hole] = arr[left];hole = left;}//right和left相遇arr[hole] = key;return hole;
}void QuickSort(int* arr, int left, int right)//排升序
{if (left >= right){return;}//找基准值int keyi = Hole_QuickSort(arr, left, right);//二分//[left,keyi-1] keyi [keyi+1,right]QuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);}前后指针版本:
排升序思路:
设立两个变量:pcur(用于探路,来找比基准值小的值),prev(在pcur的后面)
1、当找到比基准值小的值时,++prev,prev所指向的元素和pcur所指向的元素交换,然后++pcur
2、当pcur所指向的元素没有比基准值小时,++pcur
当pcur越界(pcur>right)时,就将基准值与prev所指向的元素交换,就这样就实现了将比基准值小的元素放在基准值左边,大的放在右边
注:
有时候prev++后的值正好等于pcur,这个时候就不需要发生交换

代码部分:
int lomuto_QuickSort(int* arr, int left, int right)
{int prev = left, pcur = prev + 1;int keyi = left;while (pcur <= right){if (arr[pcur] < arr[keyi]&&++prev != pcur){Swap(&arr[prev], &arr[pcur]);}pcur++;}Swap(&arr[prev], &arr[keyi]);keyi = prev;return keyi;
}void QuickSort(int* arr, int left, int right)//排升序
{if (left >= right){return;}//找基准值int keyi = lomuto_QuickSort(arr, left, right);//二分//[left,keyi-1] keyi [keyi+1,right]QuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);}时间复杂度:
快速排序算法的时间复杂度为O(NlogN),在特殊情况下:待排数组中重复元素很多的时候,会到造成时间复杂度上升为O(N^2logN),这一点要记住,这与如何解决这一情况,在后面的文章中会着重讲解
快速排序(非递归版本)
我们讲解了递归版本的快速排序,那也会有非递归版本的快速排序
在非递归版本的快速排序和递归版本的快速排序有什么区别呢?
非递归版本的快速排序算法需要借助数据结构:栈来实现
思路:
我们首先需要建立一个栈,然后:
1、将数组的left和right下标入栈
2、进入一个循环(结束条件:栈为空),将从栈中出来的两个元素命名为begin和end
3、然后对[begin,end]这个区间来找基准值,找基准值的方法在上面已经说了三种方法,随便用那个都行
4、找完以后,根据基准值进行二分为左右两个子序列,再将左右两个子序列的首尾下标入栈,再重复上面的操作
注意:
1、当begin大于或等于keyi-1或者end小于或等于keyi+1时不进行入栈操作,也就是只有在begin<keyi-1或end>keyi+1的情况下才允许入栈操作
2、每次找完基准值后还要确定一次待排区间中下标是否都入栈了,首尾下标要再入一次栈,入栈条件也要满足上面的条件
3、建立了栈,在排完序后就需要进行销毁
如果对栈还有所不解的朋友,可以移步至【数据结构初阶】栈和队列的建立_实现线性表、栈和队列(要求顺序和链式两种实现)-CSDN博客
其实非递归版快速排序就是利用栈这一数据结构来模拟实现正常快速排序中的递归过程

代码部分(找基准值部分用的是前后指针方法):
void QuickSortNonR(int* arr, int left, int right)//非递归版本
{ST st;StackInit(&st);StackPush(&st, right);StackPush(&st, left);while (!StackEmpty(&st)){int begin = StackTop(&st);StackPop(&st);int end = StackTop(&st);StackPop(&st);int keyi = lomuto_QuickSort(arr, begin, end);if (end > keyi + 1){StackPush(&st, end);StackPush(&st, keyi+1);}if (begin < keyi - 1){StackPush(&st, keyi - 1);StackPush(&st, begin);}}StackDestroy(&st);}归并排序
思路:
将待排序数组不断进行二分,直到划分为一个个有序的子序列,然后再将这些子序列两两合并,成一个有序数组
也就是先二分再合并
排升序步骤:
1、二分:
对数组取中间值(mid),进行二分,要保证数组最左边下标left要小于最右边下标right(left<right)
mid = left+(right-left)/2
根据mid分为左右两个子序列([left,mid-1],[mid+1,right])
直到left大于或等于right时停止二分
2、合并:
将相邻有序数组两两合并为一个有序数组,并将这个有序数组存储在一个临时数组(temp)中
要注意的是:每次放入临时数组结束后,两个数组中可能会有元素没有放入到临时数组中,所以循环结束后要对两个数组进行检查,再进行一次放入临时数组
3、将临时数组中元素放回原先数组中

代码部分:
void _MergeSort(int* arr, int left, int right, int* temp)
{//二分if (left >= right){return;}int mid = left + (right - left) / 2;_MergeSort(arr, left, mid,temp);_MergeSort(arr, mid+1, right,temp);//合并int begin1 = left, end1 = mid;int begin2 = mid+1, end2 = right;int i = begin1;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){temp[i++] = arr[begin1++];}else{temp[i++] = arr[begin2++];}}//两个区间可能还有元素没有入tempwhile (begin1 <= end1){temp[i++] = arr[begin1++];}while (begin2 <= end2){temp[i++] = arr[begin2++];}//将temp中元素放回原数组中for (int i = left; i <= right; ++i){arr[i] = temp[i];}
}void MergeSort(int* arr, int n)
{int* temp = (int*)malloc(sizeof(int) * n);_MergeSort(arr, 0, n - 1, temp);free(temp);
}时间复杂度:
归并排序算法时间复杂度为O(NlogN),它二分的次数为logN次,合并次数为N次
非比较排序
计数排序
思路:
1、
先找出数组中的最大、最小值,
用最大值和最小值来求出待排数组中元素的出现次数数组大小
用一次数组来存储元素出现次数:count,它的大小为range = max-min+1
2、
遍历数组,求出待排数组中各个元素出现的次数
将每个元素和最小值相减可以得出它在countg数组中的下标,则该对应下标存储的值就加一
3、
根据count数组向原数组中放入元素
arr[index] = i + min
注:
当min和max跨度很大时就会造成空间的浪费,那就不适合这种算法

代码部分:
void CountSort(int* arr, int n)
{//先找最大值和最小值int max = arr[0], min = arr[0];for (int i = 1; i < n; ++i){if (arr[i] > max){max = arr[i];}if (arr[i] < min){min = arr[i];}}int range = max - min + 1;int* count = (int*)malloc(sizeof(int) * range);if (count == NULL){perror("malloc,fail!");}//初始化数组memset(count, 0, sizeof(int*) * range);//统计次数for (int i = 0; i < n; ++i){count[arr[i] - min]++;}//将count中出现的次数还原到原数组中int index = 0;for (int i = 0; i < range; ++i){while (count[i]--){arr[index++] = i + min;}}
}时间复杂度:
排序算法复杂度及稳定性分析
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
| 冒泡排序 | O(N^2) | O(N) | O(N^2) | O(1) | 稳定 |
| 直接选择排序 | O(N^2) | O(N^2) | O(N^2) | O(1) | 不稳定 |
| 直接插入排序 | O(N^2) | O(N) | O(N^2) | O(1) | 稳定 |
| 希尔排序 | O(NlogN)~O(N^2) | O(1.3) | O(N^2) | O(1) | 不稳定 |
| 堆排序 | O(NlogN) | O(NlogN) | O(NlogN) | O(1) | 不稳定 |
| 归并排序 | O(NlogN) | O(NlogN) | O(NlogN) | O(N) | 稳定 |
| 快速排序 | O(NlogN) | O(NlogN) | O(N^2) | O(logn)~O(N) | 不稳定 |
相关文章:
八大排序算法细讲
目录 排序 概念 运用 常见排序算法 插入排序 直接插入排序 思想: 步骤(排升序): 代码部分: 时间复杂度: 希尔排序 思路 步骤 gap的取法 代码部分: 时间复杂度: 选择排序 直接选…...
)
组合总和III(力扣216)
这道题在回溯的基础上加入了剪枝操作。回溯方面我就不过多赘述,与组合(力扣77)-CSDN博客 大差不差,主要讲解一下剪枝(下面的代码也有回溯操作的详细注释)。我们可以发现,如果我们递归到后面,可能集合过小,无法满足题目…...

鲜牛奶订购系统的设计与实现
🍅点赞收藏关注 → 添加文档最下方联系方式咨询本源代码、数据库🍅 本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目希望你能有所收获,少走一些弯路。🍅关注我不迷路🍅 项目视频 基…...

python:内置函数与高阶函数
1.内置函数 abs() round() print(abs(-6))#求绝对值 print(round(3.56))#四舍五入运行结果 6 4 2.高阶函数 高阶函数:把一个函数作为参数传递给另外一个函数 实例一:绝对值加减法与四舍五入 def add_num(a,b):return abs(a)abs(b) print(add_num…...

postgresql 函数错误捕捉
BEGIN 逻辑块 EXCEPTION WHEN 错误码(如:unique_violation) or others THEN 异常逻辑块 END; 在PL/pgSQL函数中,如果没有异常捕获,函数会在发生错误时直接退出,与其相关的事物也会随之回滚。我们可以通过使…...

Java面试场景题分享
假设你在做电商秒杀活动,秒杀开始时,成千上万的用户同时请求抢购商品。你会如何设计系统来处理这些请求,确保库存不超卖 你如何保证库存的准确性? 这个问题引导你思考如何在高并发下确保库存更新的原子性,最直接的方式…...

ESP32开发学习记录---》GPIO
she 2025年2月5日,新年后决定开始充电提升自己,故作此记,以前没有使用过IDF开发ESP32因此新年学习一下ESP32。 ESPIDF开发环境配置网上已经有很多的资料了,我就不再赘述,我这里只是对我的学习经历的一些记录。 首先学习一个…...

【PyTorch】解决Boolean value of Tensor with more than one value is ambiguous报错
理解并避免 PyTorch 中的 “Boolean value of Tensor with more than one value is ambiguous” 错误 在深度学习和数据科学领域,PyTorch 是一个强大的工具,它允许我们以直观和灵活的方式处理张量(Tensor)。然而,即使…...

文件 I/O 和序列化
文件I/O C#提供了多种方式来读写文件,主要通过System.IO命名空间中的类来实现,下方会列一些常用的类型: StreamReader/StreamWriter:用于以字符为单位读取或写入文本文件。 BinaryReader/BinaryWriter:用于以二进制格…...
)
python中的lambda function(ChatGPT回答)
Python 中的 lambda 函数是一个匿名函数,它没有名字,通常用于定义简单的、一次性使用的函数。它可以接受任意数量的参数,但只能有一个表达式,并且该表达式的结果就是返回值。 lambda 函数的语法是: lambda 参数1, 参…...

智慧停车系统:不同规模停车场的应用差异与YunCitys解决方案
在智慧停车领域,不同规模停车场因自身特点,对智慧停车系统的需求和应用效果存在显著差异。云创智城凭借丰富的经验和先进的技术,为各类规模停车场打造了贴合需求的智慧停车系统,下面为您详细剖析。 小型停车场:精准高…...
)
AI软件栈:LLVM分析(三)
LLVM IR 文章目录 CFG线性IR 主要采用CFG与线性IR组合描述 CFG *关键在于基本块(Basic Block)的定义 线性IR *关键来自于SSA,单静态赋值...

C++Primer逻辑和关系运算符
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...

从BIO到NIO:Java IO的进化之路
引言 在 Java 编程的世界里,输入输出(I/O)操作是基石般的存在,从文件的读取写入,到网络通信的数据传输,I/O 操作贯穿于各种应用程序的核心。BIO(Blocking I/O,阻塞式 I/O࿰…...

VMware Win10下载安装教程(超详细)
《网络安全自学教程》 从MSDN下载系统镜像,使用 VMware Workstation 17 Pro 安装 Windows 10 consumer家庭版 和 VMware Tools。 Win10下载安装 1、下载镜像2、创建虚拟机3、安装操作系统4、配置系统5、安装VMware Tools 1、下载镜像 到MSDN https://msdn.itellyou…...

Redis存储⑤Redis五大数据类型之 List 和 Set。
目录 1. List 列表 1.1 List 列表常见命令 1.2 阻塞版本命令 1.3 List命令总结和内部编码 1.4 List典型使用场景 1.4.1 消息队列 1.4.2 分频道的消息队列 1.4.3 微博 Timeline 2. Set 集合 2.1 Set 集合常见命令 2.2 Set 集合间命令 2.3 Set命令小结和内部编码 2.…...

3-kafka服务端之控制器
文章目录 概述控制器的选举与故障恢复控制器的选举故障恢复 优雅关闭分区leader的选举 概述 在Kafka集群中会有一个或多个broker,其中有一个broker会被选举为控制器(Kafka Controler),它负责管理整个集群中所有分区和副本的状态。…...
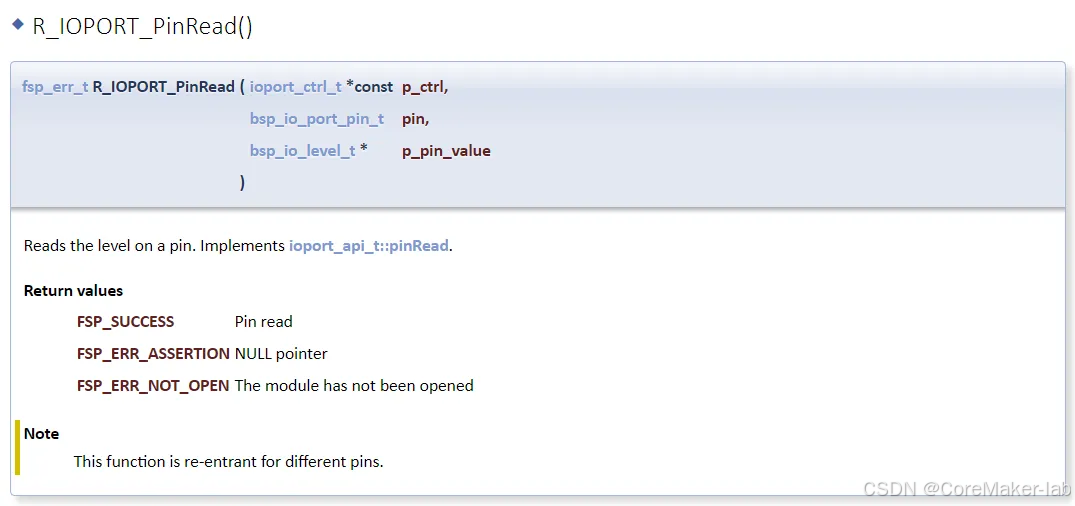
e2studio开发RA2E1(5)----GPIO输入检测
e2studio开发RA2E1.5--GPIO输入检测 概述视频教学样品申请硬件准备参考程序源码下载新建工程工程模板保存工程路径芯片配置工程模板选择时钟设置GPIO口配置按键口配置按键口&Led配置R_IOPORT_PortRead()函数原型R_IOPORT_PinRead()函数原型代码 概述 本篇文章主要介绍如何…...

[LeetCode]全排列I,II
全排列I 给定一个不含重复数字的整数数组 nums ,返回其 所有可能的全排列 。可以 按任意顺序 返回答案。 示例 1: 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]示例 2: 输入࿱…...

【Elasticsearch】parent aggregation
在Elasticsearch中,Parent Aggregation是一种特殊的单桶聚合,用于选择具有指定类型的父文档,这些类型是通过一个join字段定义的。以下是关于Parent Aggregation的详细介绍: 1.基本概念 Parent Aggregation是一种聚合操作&#x…...

Java 大视界 -- 深度洞察 Java 大数据安全多方计算的前沿趋势与应用革新(52)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

C# 使用ADO.NET访问数据全解析
.NET学习资料 .NET学习资料 .NET学习资料 在 C# 的应用开发中,数据访问是极为关键的部分。ADO.NET作为.NET 框架下用于数据访问的核心技术,能够帮助开发者便捷地与各类数据源进行交互。本文将深入剖析ADO.NET,带你掌握使用 C# 通过ADO.NET访…...
 》笔记-Chapter4-变量、作用域与内存)
【JavaScript】《JavaScript高级程序设计 (第4版) 》笔记-Chapter4-变量、作用域与内存
四、变量、作用域与内存 正如 ECMA-262 所规定的,JavaScript 变量是松散类型的,而且变量不过就是特定时间点一个特定值的名称而已。由于没有规则定义变量必须包含什么数据类型,变量的值和数据类型在脚本生命期内可以改变。 ECMAScript 变量可…...

Unity扩展编辑器使用整理(一)
准备工作 在Unity工程中新建Editor文件夹存放编辑器脚本, Unity中其他的特殊文件夹可以参考官方文档链接,如下: Unity - 手册:保留文件夹名称参考 (unity3d.com) 一、菜单栏扩展 1.增加顶部菜单栏选项 使用MenuItemÿ…...

如何查看:Buildroot所使用Linux的版本号、gcc交叉编译工具所使用的Linux的版本号、开发板上运行的Linux系统的版本号
定义编号①②③的含义 将“Buildroot所使用Linux的版本号”编号为① 将“gcc交叉编译工具所使用的Linux的版本号”编号为② 将“开发板上运行的Linux系统的版本号”编号为③ 查看①和②的共同方法(通过sysroot查看) 由于此二者都有目录sysroot,而通过目录sysroot…...

Java实战经验分享
1. 项目优化与性能提升 面试问题: 聊聊你印象最深刻的项目,或者做了哪些优化 你在项目中如何解决缓存穿透问题? 缓存穿透是我们做缓存优化时最常遇到的问题,特别是当查询的对象在数据库中不存在时,缓存层和数据库都会…...

python安装包,!pip 和不加!命令,功能区别一览
python安装包,!pip 和不加!命令,功能区别一览 1. !pip2. pip(不加 !)3. 区别总结4. 推荐用法5. 注意事项6. 总结 在 Jupyter Notebook 或 IPython 环境中,!pip 和 pip 的功能有所不同,主要体现在执行环境和…...

html转PDF文件最完美的方案(wkhtmltopdf)
目录 需求 一、方案调研 二、wkhtmltopdf使用 如何使用 文档简要说明 三、后端服务 四、前端服务 往期回顾 需求 最近在做报表类的统计项目,其中有很多指标需要汇总,网页内容有大量的echart图表,做成一个网页去浏览,同时…...

我最近在干什么【2】
前言 这系列的上一篇是2024.12.05写的,现在是2025.02.06,这都两个月🤔小久。 不是完整全面的技术分享,话题聚焦个人成长(学的技术、了解到的信息、看的书……) 方面。文章偏意识流点,单纯分享我…...

deepseek本地部署
DeepSeek本地部署详细指南 DeepSeek作为一款开源且性能强大的大语言模型,提供了灵活的本地部署方案,让用户能够在本地环境中高效运行模型,同时保护数据隐私,这里记录自己DeepSeek本地部署流程。 主机环境 cpu:amd 7500Fgpu:406…...