OpenAI 实战进阶教程 - 第十一节 : 文档搜索与摘要生成
读者群体:面向哪类从业人员?
- 软件工程师 / 后端开发人员:需要在系统中集成对文档的搜索和问答功能。
- 技术支持 / 运维人员:需要快速查询、提炼大批量文档以提供高效支持。
- 项目经理 / 产品经理:想要更好地理解并利用已有技术文档,提高团队协作效率。
为什么要采用文档搜索与摘要生成技术?
在传统的文档管理方式下,文档量往往十分庞大,用户需要花费大量时间去搜索和阅读;对企业而言,搜索效率低、回答不统一、难以沉淀知识 都是棘手的问题。
通过 嵌入向量检索 + GPT 内容生成 的模式,可以:
- 动态提取文档上下文,让系统自动找到与用户问题最相关的文档片段。
- 自动生成高质量摘要或回答,使用户无需查看整个文档,即可获取关键信息。
这不仅极大地提升了搜索效率,还让答案更准确、更贴合实际场景。
原理与概念简明说明
- 文档拆分:将长文档(技术规格书、产品说明等)按逻辑或字数分割成小段,方便后续检索。
- 生成嵌入向量:使用 OpenAI 的
text-embedding-ada-002模型,将每个段落转换成向量表示(Embedding)。 - 向量检索:当用户输入问题后,对该问题也生成向量表示,并与已存储的文档向量比较,选出最相似的段落。
- GPT 内容生成:将检索到的文档片段与问题一起发给 GPT,生成最终的回答或摘要。
实操:将技术文档拆分为段落,生成嵌入向量
1. 文档准备与拆分
- 将产品技术文档(如 PDF、Markdown 等)转换为纯文本格式。
- 根据段落、章节、或限定长度(如 500 字/行)拆分成若干小段。
- 每个文档段落可记录为一个对象,存储段落内容与段落编号。
示例(假设已将文档转成文本并存储在 doc_text.txt 中):
def split_document(text, max_length=500):paragraphs = []start = 0while start < len(text):end = min(start + max_length, len(text))paragraphs.append(text[start:end])start = endreturn paragraphswith open("doc_text.txt", "r", encoding="utf-8") as f:doc_text = f.read()paragraph_list = split_document(doc_text, max_length=500)2. 为每个段落生成向量嵌入
import openaiopenai.api_key = "YOUR_API_KEY"embedding_data = []
for index, paragraph in enumerate(paragraph_list):response = openai.embeddings.create(input=paragraph,model="text-embedding-ada-002")embedding = response.data[0].embeddingembedding_data.append({"paragraph_index": index,"paragraph_text": paragraph,"embedding": embedding})
- 这里我们将段落及其对应的向量存储在列表或数据库中,以备后续检索。
实操:从文档中提取上下文并生成回答
1. 检索:基于相似度寻找最相关段落
当用户输入问题时,先生成问题的向量,再比较它与所有段落向量的余弦相似度,找出最相似的几个段落。
import numpy as npdef cosine_similarity(vec_a, vec_b):return np.dot(vec_a, vec_b) / (np.linalg.norm(vec_a) * np.linalg.norm(vec_b))def find_similar_paragraphs(query, embedding_data, top_k=3):# 生成 query 的向量response = openai.embeddings.create(input=query,model="text-embedding-ada-002")query_embedding = response.data[0].embedding# 计算与每个段落的相似度similarities = []for data in embedding_data:sim = cosine_similarity(query_embedding, data["embedding"])similarities.append((data, sim))# 按相似度降序排序similarities.sort(key=lambda x: x[1], reverse=True)# 返回相似度最高的段落return similarities[:top_k]
2. 组合并交给 GPT 生成答案
将检索到的段落作为上下文一起发送给 GPT,以此生成针对用户问题的回答。
def generate_answer_with_context(query, embedding_data):top_paragraphs = find_similar_paragraphs(query, embedding_data)context_texts = "\n".join([item[0]["paragraph_text"] for item in top_paragraphs])prompt = f"""
你是一个智能助手,下面是与你的问题相关的文档内容:
{context_texts}请根据这些内容回答下列问题,如无法找到答案,请直接说明:
用户问题:{query}
"""response = openai.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content": prompt}],max_tokens=200)return response.choices[0].message.content# 示例使用
question = "产品怎么执行初始化操作?"
answer = generate_answer_with_context(question, embedding_data)
print("Answer:", answer)示例输出:
Answer: 回答:用户可以在手表的“设置”菜单中选择“系统” > “恢复出厂设置”,然后长按确认键 5 秒,即可执行初始化操作。
说明:
- 我们将最相似的段落拼接为
context_texts。 - 在提示信息中让 GPT 明确知道:其回答必须基于给定的上下文。
- 如上下文中无匹配信息,提示它告知用户“无法找到答案”。
小结
- 文档拆分 + 向量检索 + GPT 生成 = 一个轻量且高效的文档搜索与问答系统。
- 这一做法让 AI 工具可以在用户提问时实时寻找文档中的相关内容,大大减少了不必要的“手动翻阅”环节,提高效率。
- 对企业而言,这意味着技术文档、操作手册、产品说明都能快速转换为智能搜索问答系统,让员工或客户轻松获取关键信息。
练习:构建智能搜索与问答系统
- 整理文档:
- 找到你所在项目或公司最常用的技术文档/操作流程,转换为可读文本格式。
- 实现分段与向量存储:
- 试着编写或修改拆分函数,自定义分段大小;将结果存入 CSV 或数据库。
- 完成检索与问答:
- 实现向量相似度函数,用于搜索最相关段落;
- 尝试根据检索到的上下文生成回答,并观察结果准确度。
通过以上步骤,你将能搭建一个贴近实际需求的文档搜索与摘要系统,让工作过程更高效、更智能。
相关文章:

OpenAI 实战进阶教程 - 第十一节 : 文档搜索与摘要生成
读者群体:面向哪类从业人员? 软件工程师 / 后端开发人员:需要在系统中集成对文档的搜索和问答功能。技术支持 / 运维人员:需要快速查询、提炼大批量文档以提供高效支持。项目经理 / 产品经理:想要更好地理解并利用已有…...

scss混合优化媒体查询书写
采用scss的混合和继承优化css的媒体查询代码书写 原写法 .header {width: 100%; } media (min-width: 320px) and (max-width: 480px) {.header {height: 50px;} } media (min-width: 481px) and (max-width: 768px) {.header {height: 60px;} } media (min-width: 769px) an…...

人类的算计与机器的算计
近日,国外一视频网站博主通过设定,使DeepSeek和ChatGPT开展了一场国际象棋对弈。前十分钟双方在正常对弈,互有输赢,且ChatGPT逐渐占优。随后DeepSeek突然以对话方式告诉ChatGPT,国际象棋官方刚刚更新了比赛规则&#x…...

android的ViewBinding的使用
参考: 安卓开发中的ViewBinding使用...

rockmq配置出现的问题
环境注意事项 java要配置javahome-- java8,并且rockmq配置 根目录 解决方法: https://blog.csdn.net/weixin_46661658/article/details/133753627 如果执行第二步报错jar的路径 命令: start mqbroker.cmd -n 127.0.0.1:9876 autoCreateTop…...

7 使用 Pydantic 验证 FastAPI 的请求数据
FastAPI 是一个快速、现代的 Web 框架,它提供了自动生成 OpenAPI 文档的功能,支持 Pydantic 模型进行请求和响应数据的验证。Pydantic 提供了强大的数据验证功能,可以帮助你确保请求的有效性,自动进行数据转换,并生成详…...

U3D支持webgpu阅读
https://docs.unity3d.com/6000.1/Documentation/Manual/WebGPU-features.html 这里看到已经该有的差不多都有了 WOW VFX更是好东西 https://unity.com/cn/features/visual-effect-graph 这玩意儿化简了纯手搓一个特效的流程 如果按原理说就是compute shader刷position&#…...

【10.10】队列-设计自助结算系统
一、题目 请设计一个自助结账系统,该系统需要通过一个队列来模拟顾客通过购物车的结算过程,需要实现的功能有: get_max():获取结算商品中的最高价格,如果队列为空,则返回 -1add(value):将价格为…...

Mac安装配置使用nginx的一系列问题
brew安装nginx https://juejin.cn/post/6986190222241464350 使用brew安装nginx,如下命令所示: brew install nginx 如下图所示: 2.查看nginx的配置信息,如下命令: brew info nginxFrom:xxx 这样的,是n…...
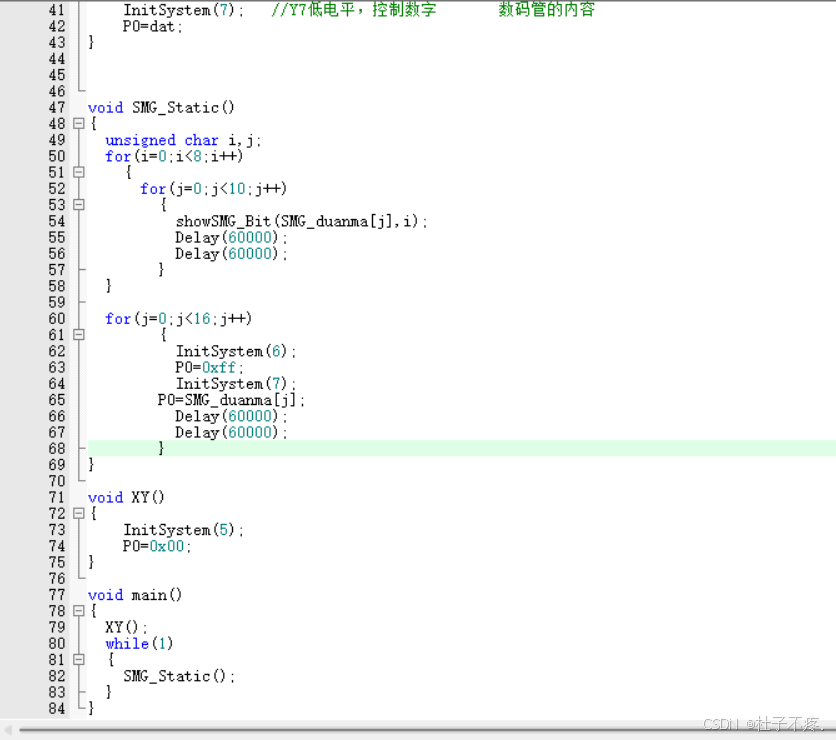
在CT107D单片机综合训练平台上,8个数码管分别单独依次显示0~9的值,然后所有数码管一起同时显示0~F的值,如此往复。
题目:在CT107D单片机综合训练平台上,8个数码管分别单独依次显示0~9的值,然后所有数码管一起同时显示0~F的值,如此往复。 延时函数分析LED首先实现8个数码管单独依次显示0~9的数字所有数码管一起同时显示0~F的值,如此往…...

00_Machine Vision_基础介绍
基础概念 由于计算机只能处理离散的数据,所以需要将连续的图片转化为离散的数据。主要包含:空间离散以及灰度值离散 空间离散:将图片的像素点离散化,即将图片的像素点转化为一个个的小方块,即为图片的分辨率。分辨率…...

组件库选择:ElementUI 还是 Ant Design
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

【Kubernetes的SpringCloud最佳实践】有Service是否还需要Eureka?
在 Kubernetes 中部署 Spring Cloud 微服务时,是否还需要 Eureka 取决于具体场景和架构设计。以下是详细的实践建议和结论: 1. Kubernetes 原生服务发现 vs Eureka Kubernetes 自身提供了完善的服务发现机制(通过 Service 资源)&…...
面试题及参考答案)
顺丰数据分析(数据挖掘)面试题及参考答案
你觉得数据分析人员必备的技能有哪些? 数据分析人员需具备多方面技能,以应对复杂的数据处理与解读工作。 数据处理能力:这是基础且关键的技能。数据常以杂乱、不完整的形式存在,需通过清洗,去除重复、错误及缺失值数据,确保数据质量。例如,在电商销售数据中,可能存在价…...

从运输到植保:DeepSeek大模型探索无人机智能作业技术详解
DeepSeek,作为一家专注于深度学习与人工智能技术研究的企业,近年来在AI领域取得了显著成果,尤其在无人机智能作业技术方面展现了其大模型的强大能力。以下是从运输到植保领域,DeepSeek大模型探索无人机智能作业技术的详解…...

超越LSTM!TCN模型如何精准预测股市波动(附代码)
作者:老余捞鱼 原创不易,转载请标明出处及原作者。 写在前面的话:最近我用TCN时间卷积网络预测了标普500指数(SPX)的每日回报率,发现效果远超传统方法。TCN通过因果卷积和膨胀卷积捕捉时间序列的长期依赖关…...

[每周一更]-(第133期):Go中MapReduce架构思想的使用场景
文章目录 **MapReduce 工作流程**Go 中使用 MapReduce 的实现方式:**Go MapReduce 的特点****哪些场景适合使用 MapReduce?**使用场景1. 数据聚合2. 数据过滤3. 数据排序4. 数据转换5. 数据去重6. 数据分组7. 数据统计8.**统计文本中单词出现次数****代码…...

QML初识
目录 一、关于QML 二、布局定位和锚点 1.布局定位 2.锚点详解 三、数据绑定 1.基本概念 2.绑定方法 3.数据模型绑定 四、附加属性及信号 1.附加属性 2.信号 一、关于QML QML是Qt框架中的一种声明式编程语言,用于描述用户界面的外观和行为;Qu…...

查询已经运行的 Docker 容器启动命令
一、导语 使用 get_command_4_run_container 查询 docker 容器的启动命令 获取镜像 docker pull cucker/get_command_4_run_container 查看容器命令 docker run --rm -v /var/run/docker.sock:/var/run/docker.sock cucker/get_command_4_run_container 容器id或容器名 …...

项目管理中的13个数据分析思维
01 信度与效度思维 信度:是指一个数据或指标自身的可靠程度,包括准确性和稳定性。 效度:是指一个数据或指标的生成,需贴合它所要衡量的事物,即指标的变化能够代表该事物的变化。 在项目管理中,信度和效度的…...

快速查看ROS节点的CPU和内存占用情况
他们可能是在排查资源泄漏的问题,所以需要监控节点的CPU和内存使用情况。可能他们遇到了节点占用过多资源导致服务器崩溃的情况,需要快速定位问题节点。现有的Linux命令方面,top和htop可以实时查看进程资源使用,但用户想要的是针对ROS节点的,可能需要更针对性的工具。ROS本…...

Centos Stream 10 根目录下的文件夹结构
/ ├── bin -> usr/bin ├── boot ├── dev ├── etc ├── home ├── lib -> usr/lib ├── lib64 -> usr/lib64 ├── lostfound ├── media ├── mnt ├── opt ├── proc ├── root ├── run ├── sbin -> usr/sbin ├── srv ├─…...

协议_CAN协议
物理层特征 信号传输原理: CAN控制器根据CAN_L和CAN_H上的电位差来判断总线电平,总线电平分为显性电平(CAN_H与CAN_L压差 2v)、隐性电平(CAN_H与CAN_L压差 0v),发送方通过总线电平的变化&am…...

nuxt3中报错: `setInterval` should not be used on the server.
那是因为在后端渲染没有浏览器的执行环境,一些浏览器环境提供的对象和方法都无法使用,代码判断下就行。 if (import.meta.client) {setInterval(() > {}, 1000) }Import meta Nuxt API...

leetcode_深度搜索和广度搜索 101. 对称二叉树
101. 对称二叉树 给你一个二叉树的根节点 root , 检查它是否轴对称思路: 1.判断根节点的左右子树是否为空, 若都为空则返回True2.根节点的左右子树其中之一为空或子树的根节点的值不同则返回False3.分别判断根节点左右子树是否相同, 判断时, 左边子树的左节点要对应…...

QT修仙之路2-2 对话框 尚欠火候
警告对话框 相关代码 错误对话框 相关代码 消息对话框 相关代码 询问对话框 相关代码 相关代码 警告对话框 QMessageBox::warning(this,"错误","账号密码不能为空",QMessageBox::Ok);错误对话框 QMessageBox msgBox(QMessageBox::Critical,"错误…...

NFT Insider #168:The Sandbox 推出新春{金蛇礼服}套装;胖企鹅合作 LINE Minini
引言:NFT Insider 由 NFT 收藏组织 WHALE Members、BeepCrypto 联合出品, 浓缩每周 NFT 新闻,为大家带来关于 NFT 最全面、最新鲜、最有价值的讯息。每期周报将从 NFT 市场数据,艺术新闻类,游戏新闻类,虚拟…...

ZooKeeper 技术全解:概念、功能、文件系统与主从同步
引言 随着分布式系统变得越来越复杂,对协调服务的需求也在不断增长。ZooKeeper 作为一个由 Apache 维护的开源分布式协调服务框架,广泛用于 Hadoop 生态系统和其他需要协调的分布式环境中。这一系统旨在解决分布式应用中常见的挑战,如配置管…...

什么是deepseek?
AI国产免费开源强大 DeepSeek 是由国内团队开发的一款开源人工智能工具库,专注于提供高效易用的 AI 模型训练与推理能力。它既包含预训练大语言模型(如 DeepSeek-R1 系列),也提供配套工具链,助力开发者快速实现 AI 应用…...

容器服务基础
1.腾讯云容器服务 使用该服务,开发者将无需安装、运维、扩展您的集群管理基础设施,只需进行简单的API调用,便可启动和停止 Docker 应用程序,查询集群的完整状态,以及使用各种云服务。 创建集群--创建工作负载/创建ingr…...