常用的python库-安装与使用
常用的python库函数
- yield关键字
- openslide库
- openslide库的安装-linux
- openslide的使用
- openslide对象的常用属性
- cv2库
- numpy库
- ASAP库-multiresolutionimageinterface库
- ASAP库的安装
- ASAP库的使用
- concurrent.futures.ThreadPoolExecutor
- xml.etree.ElementTree库
- skimage库
- PIL.Image库 PIL.Image.Image
- detectron2库
- 数据增强
- MaskFormerSemanticDatasetMapper类:
- MetadataCatalog类常见属性
yield关键字
yield关键字:定义生成器函数。
生成器函数:允许在迭代过程中逐步生成值,而不是一次性返回所有值。
yield语句会暂停函数的执行,并返回一个值给调用者。下一次调用生成器的__next()__方法,函数会从暂停的地方继续执行。
生成器函数:节省内存,按需求生成值,而不是一次性将所有值加载到内存中。
openslide库
openslide库的安装-linux
很多虚拟环境都需要额外装openslide库,所以记录一下过程:
cd /home/liusn/00apps
conda activate 环境名
pip install openslide_bin-4.0.0.5-py3-none-manylinux_2_27_x86_64.whl
pip install openslide-python==1.3.1

openslide的使用
- openslide库是一个读取和操作显微镜图像的python库,支持.svs,.vms和.tiff等格式。
- 支持图像金字塔格式:在不同的分辨率下访问图像数据。
- 可以从原始图像中提取特定区域,不需要加载整个图像。
- 能够访问图像的元数据,如放大倍数、图像尺寸等。
import openslide
# 打开显微镜图像
slide = openslide.OpenSlide(wsi_path) # 获取特定金字塔层级的图像尺寸
# level从0开始,0表示最高分辨率
# w, h表示指定层级的图像宽度和高度
w, h = slide.level_dimensions[level] # 获取level层的下采样比例
# 下采样比例: 特定层级的像素大小与最高分辨率像素大小的比例关系
# 如果下采样比例为(2,2), 图像的宽和高都被缩小为原来的1/2
factor = slide.level_downsamples[level]
# 从显微镜图像中读取指定区域
# location: tuple, 左上角坐标; level: 金字塔层级
# size: (w, h), 要读取的区域大小; 返回一个PIL对象
image = slide.read_region(location, level, size)
openslide对象的常用属性
self.level_downsamples[level]:获取level层的下采样比例,相对于最高分辨率而言。self.level_dimension[level]:level层的图像尺寸。
cv2库
import cv2 # 在图像上绘制多边形
# img: 要在其上绘制的图像; pts: 一个包含多边形顶点的ndarray;
# color: 填充的颜色, (255)表示白色
cv2.fillPoly(img, pts, color) # 在图像上绘制文本
# img: 要绘制文本的图像; text: 要绘制的文本字符串
cv2.putText(img, text)
numpy库
import numpy as np
# 找到数组中满足条件的元组索引
# condition: bool数组, 返回所有为True的行, 列索引
X_idx, Y_idx = np.where(condition) # 根据条件condition进行数组的元素选择和替换
# condition为True时, 返回value1, 否则返回value2 inst_map = np.where(condition, value1, value2)
# 将数组按行的方向堆叠起来
# tup: 一个列表/元组, 返回一个新数组(总行数, 列数)
# 总行数 = 所有输入数组的行数之和 np.vstack(tup)
selected_x[..., 0:1] # ...表示前面所有的维度
ASAP库-multiresolutionimageinterface库
处理金字塔类型的数据结构。处理多分辨率图像的python库,适合医学图像和显微镜图像的分析。支持不同分辨率的访问与操作。
ASAP库的安装
安装ASAP linux(ubuntu18.04-A6000):https://www.freesion.com/article/4489476959/
安装ASAP linux(ubuntu22.04-4x3090)的安装步骤:
-
在ASAP官网下载最新版:ASAP 2.2,适配ubuntu2204。

-
安装ASAP的依赖包:用sudo apt-get install 命令。apt-get install是用于命令行操作的软件包管理工具,该命令是安装软件包。
-
离线安装ASAP的安装包:dpkg -i ASAP-2.2-Ubuntu2204.deb ,手动安装本地的deb文件。
-
看ASAP安装的位置:dpkg -L asap 。
-
把ASAP放入PYTHONPATH,然后可以import了。
PYTHONPATH="/opt/ASAP/bin":"${PYTHONPATH}"
export PYTHONPATH
ASAP库的使用
ASAP库是一个C++写的软件,所以不能读源码。少量的python调用文档见:https://academic.oup.com/gigascience/article/7/6/giy065/5026175
ASAP官网:https://github.com/computationalpathologygroup/ASAP/releases
通过python 访问tif数据:

将XML注释数据转换为tif图像,假设注释里的多边形坐标是基于图像最高分辨率级别的。

示例代码:
import multiresolutionimageinterface as mir # 创建图像接口
reader = mir.MultiResolutionImageReader() # 打开和加载多分辨率图像文件
mr_image = reader.open(path) # 获取level 6的图像尺寸 level=2
w, h = mr_image.getLevelDimensions(level)
ds = mr_image.getLevelDownsample(level) # 从level 6获取一个patch, patch左上角的坐标为(0,0), 返回的tile是一个numpy对象
tile = image.getUCharPatch(0, 0, w, h, 6) # 读取一个 300 像素宽、200 像素高的图像块,从level=2 的 (568, 732) XY 坐标开始
# ds是下采样倍数, 在level=2的坐标乘以ds, 得到level=0的坐标
tile = image.getUCharPatch(int(568 * ds), int(732 * ds), 300, 200, level)
# 存储和管理多分辨率图像相关的注释数据
annotation_list = mir.AnnotationList()
# 将注释数据转换以xml格式存储
xml_repository = mir.XmlRepository(annotation_list)
# 设置or更新xml文件的源路径 xml_repository.setSource(path)
# 从xml文件加载数据 xml_repository.load()
# 将注释数据转换为二值掩码
annotation_mask = mir.AnnotationToMask()
# 将提供的注释annotation_list转换为二值掩码
annotation_mask.convert(annotation_list, output_path,image_dimensions, image_spacing)
concurrent.futures.ThreadPoolExecutor
管理线程池并高效地执行多线程任务,可以加快I/O密集型任务的处理速度。通过提交任务来执行并发操作。
from concurrent.futures import ThreadPoolExecutor # 创建对象, max_workers指定最大线程数, 如果没有指定, python根据系统的线程数进行调整
executor = ThreadPoolExecutor(max_workers=3) # 使用map()提交多个任务
executor.map(task, range(5)) # 关闭线程池
executor.shutdown(wait=True)
xml.etree.ElementTree库
解析和创建xml文档,用于读取、修改和生成xml。
import xml.etree.ElementTree as ET # 从指定文件中读取xml数据, 并解析为一个树结构 ElementTree对象
tree = ET.parse(annot_path) # 获取根元素: xml文档最外层的元素
root = tree.getroot()
skimage库
import skimage # 生成多边形的像素坐标
# x: 一维数组, 多边形的列坐标; y: 一维数组, 多边形的行坐标
# shape: 指定输出坐标的图像形状
# rows, cols: 多边形内部像素的行和列坐标
# 多边形内部是指,所有的多边形都被填充好了
rows, cols = skimage.draw.polygon(x, y, shape)
PIL.Image库 PIL.Image.Image
from PIL import Image image = Image.open(path)
# 查看image的mode和channel nums
print(f"Image mode: {image.mode}")
print(f"Number of channels: {len(image.getbands())}")
# 转换mode mask = mask.convert("P")
detectron2库
数据增强
- 允许同时增强多种数据类型,如图像、边界框、掩码。
- 允许应用一系列静态声明的增强。
- 允许添加自定义新数据类型来增强,如旋转边界框、视频剪辑。
- 处理和操纵增强增强应用的operations。
如何在编写新的数据加载器时使用增强,如何编写新的增强。
MaskFormerSemanticDatasetMapper类:
- 从file_name读取image
- 将几何变换应用到image和annotation
- 查找合适的cropping,将其应用于image和annotation
- 把image和annotation变成Tensors
MetadataCatalog类常见属性
- stuff_classes:每个stuff类别的名称list,用于语义分割和全景分割。
- stuff_colors:每个stuff类别的预定义颜色(0-255),用于可视化。如果没有指定,则使用随机颜色。list[tuple(r, g, b)].
- ignore_label:int,gt中带有该类别标签的像素将在评估里被忽略,用于语义和全景分割任务。
相关文章:
常用的python库-安装与使用
常用的python库函数 yield关键字openslide库openslide库的安装-linuxopenslide的使用openslide对象的常用属性 cv2库numpy库ASAP库-multiresolutionimageinterface库ASAP库的安装ASAP库的使用 concurrent.futures.ThreadPoolExecutorxml.etree.ElementTree库skimage库PIL.Image…...

对接DeepSeek
其实,整个对接过程很简单,就四步,获取key,找到接口文档,接口测试,代码对接。 获取 KEY https://platform.deepseek.com/transactions 直接付款就是了(现在官网暂停充值2025年2月7日࿰…...

DevOps工具链概述
1. DevOps工具链概述 1.1 DevOps工具链的定义 DevOps工具链是支持DevOps实践的一系列工具的集合,这些工具覆盖了软件开发的整个生命周期,包括需求管理、开发、测试、部署和运维等各个环节。它旨在通过工具的集成和自动化,打破开发与运维之间…...

ChatGPT提问技巧:行业热门应用提示词案例-文案写作
ChatGPT 作为强大的 AI 语言模型,已经成为文案写作的得力助手。但要让它写出真正符合你需求的文案,关键在于如何与它“沟通”,也就是如何设计提示词(Prompt)。以下是一些实用的提示词案例,帮助你解锁 ChatG…...

分享如何通过Mq、Redis、XxlJob实现算法任务的异步解耦调度
一、背景 1.1 产品简介 基于大模型塔斯,整合传统的多项能力(NLP、OCR、CV等),构建以场景为中心的新型智能文档平台。通过文档审阅,实现结构化、半结构化和非结构化文档的信息获取、处理及审核,同时基于大…...

力扣-栈与队列-239 滑动窗口的最大值
双指针思路 每移动一次,可以比较上一次窗口的最大值和被移除的值,如果被移除的值小于最大值,则说明最大值仍在新的区间,但是最后超时了 双指针超时代码 class Solution { public:vector<int> maxSlidingWindow(vector<…...

在 MySQL 中,通过存储过程结合条件判断来实现添加表字段时,如果字段已存在则不再重复添加
-- 创建存储过程 DELIMITER $$ CREATE PROCEDURE add_column(IN db_name VARCHAR(255),IN table_name VARCHAR(255),IN column_name VARCHAR(255),IN column_definition VARCHAR(255),IN column_comment VARCHAR(255) ) BEGINDECLARE column_exists INT;-- 检查字段是否存在SEL…...

8.flask+websocket
http是短连接,无状态的。 websocket是长连接,有状态的。 flask中使用websocket from flask import Flask, request import asyncio import json import time import websockets from threading import Thread from urllib.parse import urlparse, pars…...

【大模型实战】使用Ollama+Chatbox实现本地Deepseek R1模型搭建
下载安装Ollama Ollama官方链接:https://ollama.com/,打开链接后就可以看到大大的下载按钮,如下图: 我选择用Win的安装。将Ollama的安装包下载到本地,如果下载慢可以复制链接到迅雷里面,提高下载速度,如下图: 双击之后,就可以开始安装了,如下图: 默认安装到C盘,…...
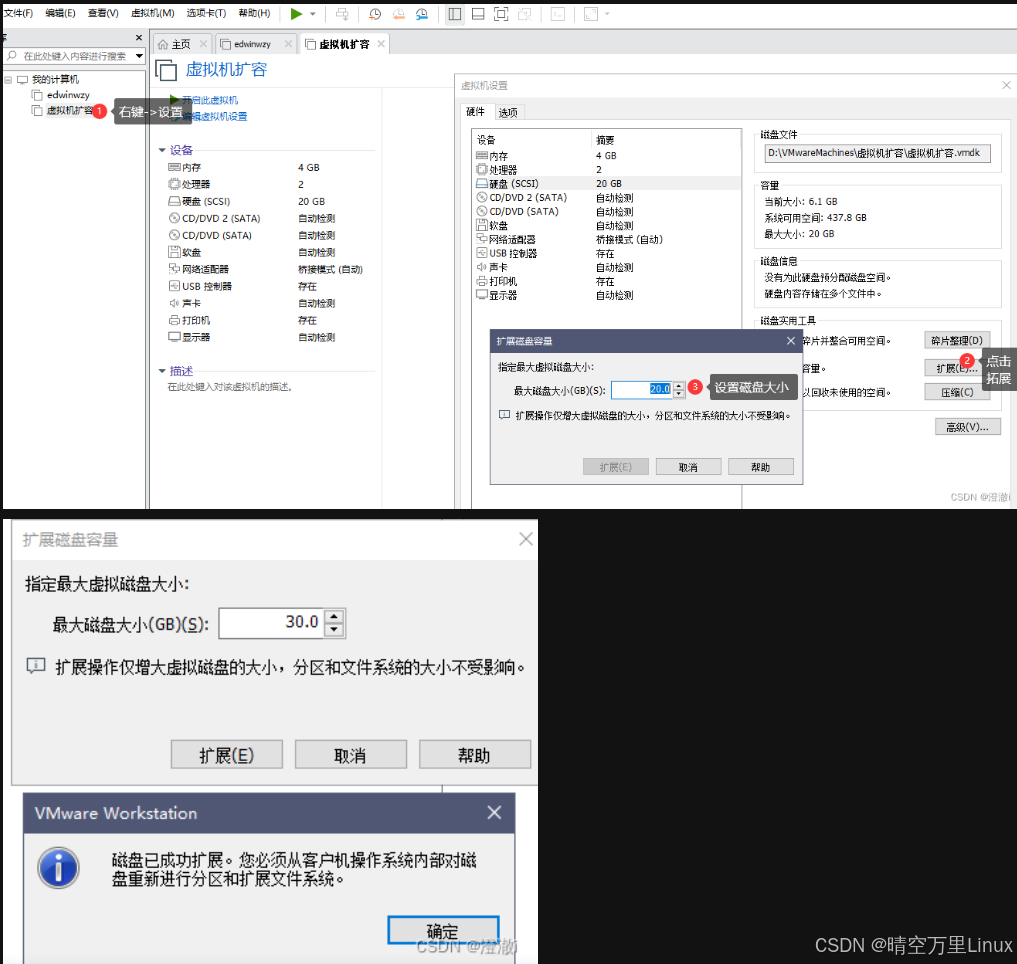
VMware 虚拟机 ubuntu 20.04 扩容工作硬盘
一、关闭虚拟机 关闭虚拟机参考下图,在vmware 调整磁盘容量 二、借助工具fdisk testubuntu ~ $ df -h Filesystem Size Used Avail Use% Mounted on udev 1.9G 0 1.9G 0% /dev tmpfs 388M 3.1M 385M 1% /run /dev/sda5 …...

ZooKeeper 和 Dubbo 的关系:技术体系与实际应用
引言 在现代微服务架构中,服务治理和协调是至关重要的环节。ZooKeeper 和 Dubbo 是两个在分布式系统中常用的技术工具,它们之间有着紧密的联系。本文将详细探讨 ZooKeeper 和 Dubbo 的关系,从基础概念、技术架构、具体实现到实际应用场景&am…...
(Go 语言实现))
【LeetCode 热题100】74:搜索二维矩阵(二分、线性两种方式 详细解析)(Go 语言实现)
🚀 力扣热题 74:搜索二维矩阵(详细解析) 📌 题目描述 力扣 74. 搜索二维矩阵 给你一个满足下述两条属性的 m x n 整数矩阵 matrix : 每行中的整数从左到右按非递减顺序排列。每行的第一个整数大于前一行的…...

《Peephole LSTM:窥视孔连接如何开启性能提升之门》
在深度学习的领域中,长短期记忆网络(LSTM)以其出色的序列数据处理能力而备受瞩目。而Peephole LSTM作为LSTM的一种重要变体,通过引入窥视孔连接,进一步提升了模型的性能。那么,窥视孔连接究竟是如何发挥作用…...

HTML之JavaScript变量和数据类型
HTML之JavaScript变量和数据类型 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</titl…...
关于讲解C++函数(认识,了解)的思考与总结)
(少儿编程)关于讲解C++函数(认识,了解)的思考与总结
前言: 在少儿编程中,讲解函数的概念时,需要将复杂的概念简化,并通过生动有趣的例子和互动方式来帮助孩子理解。以下是一个适合少儿的函数讲解思路和示例: 用生活中的例子引入函数的概念: 目标:…...

【漫话机器学习系列】082.岭回归(或脊回归)中的α值(alpha in ridge regression)
岭回归(Ridge Regression)中的 α 值 岭回归(Ridge Regression)是一种 带有 L2 正则化 的线性回归方法,用于处理多重共线性(Multicollinearity)问题,提高模型的泛化能力。其中&am…...

Node.js怎么调用到打包的python文件呢
在 Node.js 中调用打包后的 Python 可执行文件(如 PyInstaller 生成的 .exe 或二进制文件),可以通过以下步骤实现: 一、Python 打包准备 假设已有打包好的 Python 文件 your_script.exe(以 Windows 为例)&…...

9 Pydantic复杂数据结构的处理
在构建现代 Web 应用时,我们往往需要处理复杂的输入和输出数据结构。例如,响应数据可能包含嵌套字典、列表、元组,甚至是多个嵌套对象。Pydantic 是一个强大的数据验证和序列化库,可以帮助我们轻松地处理这些复杂的数据结构&#…...

C++ decltype 规则推导
C decltype 规则推导 文章目录 C decltype 规则推导**1. 基本规则****(1) 如果 decltype 的参数是变量名(无括号的标识符)****(2) 如果 decltype 的参数是表达式(带括号或操作符)** **2. 与 auto 的区别****3. 特殊场景****(1) 函…...

Rust 测试组织指南:单元测试与集成测试
一、为什么要同时使用单元测试与集成测试 单元测试:更为精细、聚焦某一逻辑单元;可以调用到私有函数,快速定位错误根源。集成测试:作为“外部代码”来使用库的公开接口,测试多个模块间的交互,确保整体功能…...

Day62_补20250210_图论part6_108冗余连接|109.冗余连接II
Day62_20250210_图论part6_108冗余连接|109.冗余连接II 108冗余连接 【把题意转化为并查集问题】 题目 有一个图,它是一棵树,他是拥有 n 个节点(节点编号1到n)和 n - 1 条边的连通无环无向图(其实就是一个线形图&am…...

kafka消费端之消费者协调器和组协调器
文章目录 概述回顾历史老版本获取消费者变更老版本存在的问题 消费者协调器和组协调器新版如何解决老版本问题再均衡过程**第一阶段CFIND COORDINATOR****第二阶段(JOINGROUP)**选举消费组的lcader选举分区分配策略 第三阶段(SYNC GROUP&…...

语法备忘04:将 事件处理函数 绑定到 组件 的事件上
示例1:<Table OnQueryAsync"OnQueryAsync" /> 示例2:<Table OnQueryAsync"OnQueryAsync" /> 说明:这两种写法在功能上是完全相同的,都是在将 OnQueryAsync 事件处理函数绑定到 Table 组件的 …...

C++20中的std::atomic_ref
一、std::atomic_ref 我们在学习C11后的原子操作时,都需要提前定义好std::atomic变量,然后才可以在后续的应用程序中进行使用。原子操作的优势在很多场合下优势非常明显,所以这也使得很多开发者越来习惯使用原子变量。 但是,在实…...

CSS 相关知识
1、高度已知,三栏布局,左右宽度 200,中间自适应,如何实现? <body><div class"box"><div class"box1">高度已知</div><div class"box2">左右宽度 200&…...

RocketMQ、RabbitMQ、Kafka 的底层实现、功能异同、应用场景及技术选型分析
1️⃣ 引言 在现代分布式系统架构中,📩消息队列(MQ)是不可或缺的组件。它在系统🔗解耦、📉流量削峰、⏳异步处理等方面发挥着重要作用。目前,主流的消息队列系统包括 🚀RocketMQ、&…...

IDEA升级出现问题Failed to prepare an update Temp directory inside installation
IDEA升级出现问题"Failed to prepare an update Temp directory inside installation…" 问题来源: 之前修改了IDEA的默认配置文件路径,然后升级新版本时就无法升级,提示"Failed to prepare an update Temp directory insid…...

DeepSeek提示词手册
一、核心原则:基于DeepSeek的推理特性 自然语言优先undefinedDeepSeek擅长理解自然表达,无需复杂模板。例如: ❌旧模板:"你是专业分析师,需分三步回答,第一步…" ✅高效提问:"…...

基于UVM搭验证环境
基于UVM搭验证环境基本思路: 首先,我们搭建环境时一般都有一个目标的DUT。此时,我们可以结合所要验证的的模块、是否需要VIP、验证侧重点等在典型的UVM验证环境的基础上做适当调整后形成一个大体的环境架构。比如,需要一个ahb_vip…...

C++性能优化—人工底稿版
C以高性能著称,性能优化是C程序员绕不过去的一个话题,性能优化是一个复杂、全局而又细节的问题,本文总结C性能分析中常用的知识。 性能优化的时机 大部分关于性能优化的文章都强调:不要过早的进行性能优化。 C编码层面 数据结…...