SQL 大厂面试题目(由浅入深)
今天给大家带来一份大厂SQL面试覆盖:基础语法 → 复杂查询 → 性能优化 → 架构设计,大家需深入理解执行原理并熟悉实际业务场景的解决方案。
1. 基础查询与过滤
题目:查询 employees 表中所有薪资(salary)大于 10000 且部门编号(dept_id)为 5 的员工姓名(name)和入职日期(hire_date)。
SELECT name, hire_date
FROM employees
WHERE salary > 10000 AND dept_id = 5;
2. 聚合函数与分组
题目:统计每个部门(dept_id)的平均薪资,并仅显示平均薪资高于 15000 的部门。
SELECT dept_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY dept_id
HAVING AVG(salary) > 15000;
3. 多表连接(JOIN)
题目:查询员工姓名(name)及其所属部门名称(dept_name),表结构为 employees(id, name, dept_id)和 departments(id, dept_name)。
SELECT e.name, d.dept_name
FROM employees e
JOIN departments d ON e.dept_id = d.id;
4. 子查询与 EXISTS
题目:查询没有订单的客户(customers 表的 id 不在 orders 表的 customer_id 中)。
SELECT c.id, c.name
FROM customers c
WHERE NOT EXISTS (SELECT 1 FROM orders o WHERE o.customer_id = c.id
);
5. 窗口函数
题目:查询每个部门薪资排名前 3 的员工姓名和薪资。
WITH ranked_employees AS (SELECT name, salary, dept_id,RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS rankFROM employees
)
SELECT name, salary, dept_id
FROM ranked_employees
WHERE rank <= 3;
6. 递归查询(CTE)
题目:查询树形结构表 categories(id, name, parent_id)中 ID=5 的所有子节点。
WITH RECURSIVE sub_categories AS (SELECT id, name, parent_idFROM categoriesWHERE id = 5UNION ALLSELECT c.id, c.name, c.parent_idFROM categories cJOIN sub_categories sc ON c.parent_id = sc.id
)
SELECT * FROM sub_categories;
7. 索引优化
题目:在 orders 表中,如何为 customer_id 和 order_date 设计联合索引以优化查询 WHERE customer_id = 100 AND order_date > '2024-02-10'?
答案:
CREATE INDEX idx_customer_order_date ON orders (customer_id, order_date);
原理:联合索引按最左前缀匹配原则,优先按 customer_id 过滤,再按 order_date 范围查询。
8. 事务与隔离级别
题目:解释“不可重复读”(Non-Repeatable Read)和“幻读”(Phantom Read)的区别。
答案:
不可重复读:同一事务中两次读取同一行数据,结果不同(由其他事务的 UPDATE 或 DELETE 导致)。
幻读:同一事务中两次查询同一范围的数据,结果行数不同(由其他事务的 INSERT 导致)。
9. 执行计划分析
题目:以下查询的执行计划中出现了 Full Table Scan,如何优化?
SELECT * FROM products WHERE category = 'Electronics' AND price > 1000;
答案:
添加联合索引 (category, price):
CREATE INDEX idx_category_price ON products (category, price);
10. 复杂场景设计
题目:设计一个数据库表结构,支持用户每日签到(可重复签到但仅第一次有效),并统计某用户最近 30 天的签到次数。
答案:
CREATE TABLE user_checkins (user_id INT,checkin_date DATE,PRIMARY KEY (user_id, checkin_date) -- 唯一约束避免重复
);-- 统计最近30天签到次数
SELECT COUNT(*)
FROM user_checkins
WHERE user_id = 100
AND checkin_date >= CURRENT_DATE - INTERVAL '30 days';
11. 死锁分析与解决
题目:两个事务分别执行以下操作,如何发生死锁?
事务1:UPDATE accounts SET balance = balance - 100 WHERE id = 1; UPDATE accounts SET balance = balance + 100 WHERE id = 2;
事务2:UPDATE accounts SET balance = balance - 200 WHERE id = 2; UPDATE accounts SET balance = balance + 200 WHERE id = 1;
答案:
事务1锁定id=1后等待id=2,事务2锁定id=2后等待id=1,形成循环等待。
解决方案:按固定顺序更新(如先更新id小的账户)。
12. 时间窗口统计
题目:统计每小时内订单量最多的前3个小时(表 orders 含字段 order_time)。
WITH hourly_orders AS (SELECT EXTRACT(HOUR FROM order_time) AS hour,COUNT(*) AS order_countFROM ordersGROUP BY EXTRACT(HOUR FROM order_time)
)
SELECT hour, order_count
FROM hourly_orders
ORDER BY order_count DESC
LIMIT 3;
13. 数据去重
题目:删除 logs 表中重复记录(保留id最小的一条)。
DELETE FROM logs
WHERE id NOT IN (SELECT MIN(id)FROM logsGROUP BY user_id, log_time, content
);
14. 分页查询优化
题目:优化大表的分页查询 SELECT * FROM users ORDER BY id LIMIT 1000000, 10;。
答案:
使用覆盖索引 + 游标分页:
SELECT * FROM users
WHERE id > 1000000
ORDER BY id
LIMIT 10;
15. 分区表设计
题目:如何按时间范围对 sales 表进行分区以优化查询性能?
答案:
-- 按月分区(以 PostgreSQL 为例)
CREATE TABLE sales (sale_id SERIAL,sale_date DATE,amount NUMERIC
) PARTITION BY RANGE (sale_date);CREATE TABLE sales_2023_01 PARTITION OF salesFOR VALUES FROM ('2024-01-10') TO ('2024-02-10');
16. JSON 数据处理
题目:从 products 表的 attributes(JSON 字段)中提取颜色(color)和尺寸(size)。
-- 以 MySQL 为例
SELECT attributes->>'$.color' AS color,attributes->>'$.size' AS size
FROM products;
17. 高级窗口函数
题目:计算每个员工薪资与所在部门平均薪资的差值。
SELECT name,salary,salary - AVG(salary) OVER (PARTITION BY dept_id) AS diff_from_avg
FROM employees;
18. 动态SQL与存储过程
题目:编写存储过程,根据输入的城市名动态查询 customers 表。
-- 以 PostgreSQL 为例
CREATE OR REPLACE PROCEDURE get_customers_by_city(city_name TEXT)
LANGUAGE plpgsql
AS $$
BEGINEXECUTE 'SELECT * FROM customers WHERE city = $1' USING city_name;
END;
$$;
19. 分布式ID生成方案
题目:在分布式系统中,如何设计全局唯一的订单ID?
答案:
雪花算法(Snowflake):时间戳 + 机器ID + 序列号。
UUID:随机生成,但存储效率低。
数据库分段分配:中央数据库分配ID范围给各节点。
20. 数据一致性保障
题目:如何实现“扣减库存时防止超卖”?
答案:
-- 事务内原子操作(以 MySQL 为例)
START TRANSACTION;
SELECT stock FROM products WHERE id = 100 FOR UPDATE;
UPDATE products SET stock = stock - 1 WHERE id = 100 AND stock > 0;
COMMIT;相关文章:
)
SQL 大厂面试题目(由浅入深)
今天给大家带来一份大厂SQL面试覆盖:基础语法 → 复杂查询 → 性能优化 → 架构设计,大家需深入理解执行原理并熟悉实际业务场景的解决方案。 1. 基础查询与过滤 题目:查询 employees 表中所有薪资(salary)大于 10000…...

在Linux上部署Jenkins的详细指南
引言 在当今快速迭代的软件开发环境中,持续集成和持续交付(CI/CD)变得越来越重要。Jenkins作为一个开源自动化服务器,能够帮助开发者更高效地进行代码集成、测试和部署。本文将详细介绍如何在Linux系统上安装和配置Jenkins。 准…...

《我在技术交流群算命》(三):QML的Button为什么有个蓝框去不掉啊(QtQuick.Controls由Qt5升级到Qt6的异常)
有群友抛出类似以下代码和运行效果截图: import QtQuick import QtQuick.ControlsWindow {width: 640height: 480visible: truetitle: qsTr("Hello World")Button{anchors.centerIn: parentwidth: 100height: 40background: Rectangle {color: "red…...

Golang:Go 1.23 版本新特性介绍
流行的编程语言Go已经发布了1.23版本,带来了许多改进、优化和新特性。在Go 1.22发布六个月后,这次更新增强了工具链、运行时和库,同时保持了向后兼容性。 Go 1.23 的新增特性主要包括语言特性、工具链改进、标准库更新等方面,以下…...

在 PyTorch 中理解词向量,将单词转换为有用的向量表示
你要是想构建一个大型语言模型,首先得掌握词向量的概念。幸运的是,这个概念很简单,也是本系列文章的一个完美起点。 那么,假设你有一堆单词,它可以只是一个简单的字符串数组。 animals ["cat", "dog…...

deepseek API 调用-python
【1】创建 API keys 【2】安装openai SDK pip3 install openai 【3】代码: https://download.csdn.net/download/notfindjob/90343352...

PHP中的魔术方法
在 PHP 中,以两个下划线 __ 开头的方法被称为魔术方法,它们在特定场景下会自动被调用,以下是一些常见的魔术方法: 1.__construct():类的构造函数,在对象创建完成后第一个自动调用,用于执行初始…...

Git、Github和Gitee完整讲解:丛基础到进阶功能
第一部分:Git 是什么? 比喻:Git就像是一本“时光机日记本” 每一段代码的改动,Git都会帮你记录下来,像是在写日记。如果出现问题或者想查看之前的版本,Git可以带你“穿越回过去”,找到任意时间…...

相对收益-固定收益组合归因-加权久期归因模型
固定收益组合归因-加权久期归因模型和Campisi模型 1 加权久期归因模型--推导方式11.1 债券策略组合收益率的分解1.1.2 加权久期归因(1)总久期贡献(2)债券类属配置贡献 1.1.3 如何应用加权久期归因 2 加权久期归因模型--推导方式22…...

原生鸿蒙版小艺APP接入DeepSeek-R1,为HarmonyOS应用开发注入新活力
原生鸿蒙版小艺APP接入DeepSeek-R1,为HarmonyOS应用开发注入新活力 在科技飞速发展的当下,人工智能与操作系统的融合正深刻改变着我们的数字生活。近日,原生鸿蒙版小艺APP成功接入DeepSeek-R1,这一突破性进展不仅为用户带来了更智…...

RabbitMQ 从入门到精通:从工作模式到集群部署实战(三)
文章目录 使用CLI管理RabbitMQrabbitmqctlrabbitmq-queuesrabbitmq-diagnosticsrabbitmq-pluginsrabbitmq-streamsrabbitmq-upgraderabbitmqadmin 使用CLI管理RabbitMQ RabbitMQ CLI 工具需要安装兼容的 Erlang/OTP版本。 这些工具假定系统区域设置为 UTF-8(例如en…...

AI-学习路线图-PyTorch-我是土堆
1 需求 PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili PyTorch 深度学习快速入门教程 配套资源 链接 视频教程 https://www.bilibili.com/video/BV1hE411t7RN/ 文字教程 https://blog.csdn.net/xiaotudui…...

2.1 Mockito核心API详解
Mockito核心API详解 1. 创建Mock对象 Mockito提供两种方式创建模拟对象: 1.1 手动创建(传统方式) // 创建接口/类的Mock对象 UserDao userDao Mockito.mock(UserDao.class);1.2 注解驱动(推荐方式) 结合JUnit 5的…...

傅里叶单像素成像技术研究进展
摘要:计算光学成像,通过光学系统和信号处理的有机结合与联合优化实现特定成像特性的成像系统,摆脱了传统成像系统的限制,为光学成像技术添加了浓墨重彩的一笔,并逐步向简单化与智能化的方向发展。单像素成像(Single-Pi…...

可视化工作流编排参数配置完整方案设计文档
一、背景及需求分析 1. 背景 在复杂的工作流程中,后续程序需要动态构造输入参数,这些参数源自多个前序程序的 JSON 数据输出。为了增强系统的灵活性和可扩展性,配置文件需要支持以下功能: 灵活映射前序程序的 JSON 数据。…...

镜头放大倍率和像素之间的关系
相互独立的特性 镜头放大倍率:主要取决于镜头的光学设计和结构,决定了镜头对物体成像时的缩放程度,与镜头的焦距等因素密切相关。比如,微距镜头具有较高的放大倍率,能将微小物体如昆虫、花朵细节等放大成像࿰…...

MariaDB *MaxScale*实现mysql8读写分离
1.MaxScale 是干什么的? MaxScale是maridb开发的一个mysql数据中间件,其配置简单,能够实现读写分离,并且可以根据主从状态实现写库的自动切换,对多个从服务器能实现负载均衡。 2.MaxScale 实验环境 中间件192.168.12…...

计算机毕业设计Spark+大模型知网文献论文推荐系统 知识图谱 知网爬虫 知网数据分析 知网大数据 知网可视化 预测系统 大数据毕业设计 机器学习
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

MySQL的事务实现原理和隔离级别?
目录 MySQL 事务实现原理 1. 事务的基本概念 2. 实现原理 日志系统 锁机制 MySQL 隔离级别 1. 隔离级别概述 2. 各隔离级别详解 读未提交(Read Uncommitted) 读已提交(Read Committed) 可重复读(Repeatable Read) 串行化(Serializable) 3. 设置隔离级别 My…...

JVM做GC垃圾回收时需要多久,都由哪些因素决定的
JVM进行垃圾回收(GC)的时间长短受多种因素影响,主要包括以下几个方面: 1. 堆内存大小 堆内存越大,GC需要扫描和回收的对象越多,耗时越长。堆内存较小时,GC频率增加,但每次回收的时…...

padding: 20rpx 0rpx 20rpx 20rpx(上、右、下、左的填充(顺时针方向))
CSS样式 padding: 20rpx 0rpx 20rpx 20rpx; 用于设置元素的填充区域。以下是对每个值的详细解释: 20rpx(上边距):设置元素顶部的填充为20rpx。0rpx(右边距):设置元素右侧的填充为0rpx。20rpx&a…...
)
2025-2-10-4.4 双指针(基础题1)
文章目录 4.4 双指针(基础题)**344. 反转字符串****125. 验证回文串****1750. 删除字符串两端相同字符后的最短长度****167.两数之和 II - 输入有序数组****2105. 给植物浇水 II****977. 有序数组的平方****658. 找到K个最接近的元素****1471. 数组中的k…...
)
Qt - 地图相关 —— 2、Qt调用百度在线地图功能示例全集,包含线路规划、地铁线路查询等(附源码)
效果:由于录制软件导致exe显示不正常,实际运行没有任何问题。 说明:exe试用下载(提取码: 4d8y )...

微信小程序如何使用decimal计算金额
第三方库地址:GitHub - MikeMcl/decimal.js: An arbitrary-precision Decimal type for JavaScript 之前都是api接口走后端计算,偶尔发现这个库也不错,计算简单,目前发现比较准确 上代码 导入js import Decimal from ../../uti…...

【AI学习】关于 DeepSeek-R1的几个流程图
遇见关于DeepSeek-R1的几个流程图,清晰易懂形象直观,记录于此。 流程图一 来自文章《Understanding Reasoning LLMs》, 文章链接:https://magazine.sebastianraschka.com/p/understanding-reasoning-llms?continueFlagaf07b1a0…...
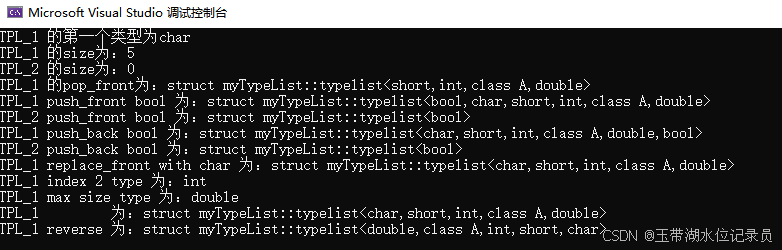
C++模板编程——typelist的实现
文章最后给出了汇总的代码,可直接运行 1. typelist是什么 typelist是一种用来操作类型的容器。和我们所熟知的vector、list、deque类似,只不过typelist存储的不是变量,而是类型。 typelist简单来说就是一个类型容器,能够提供一…...

Python3 ImportError: cannot import name ‘XXX‘ from ‘XXX‘
个人博客地址:Python3 ImportError: cannot import name XXX from XXX | 一张假钞的真实世界 例如如下错误: $ python3 git.py Traceback (most recent call last):File "git.py", line 1, in <module>from git import RepoFile &quo…...

数据可视化与交互融合:APP 界面设计的新维度
在数字化浪潮汹涌的当下,APP 已成为人们生活和工作中不可或缺的工具。如何在众多 APP 中脱颖而出,界面设计至关重要。而数据可视化与交互的融合,正为 APP 界面设计开辟了全新的维度。 数据可视化,简单来说,就是将复杂…...

502 Bad Gateway 错误详解:从表现推测原因,逐步排查直至解决
502 Bad Gateway 错误通常意味着服务器之间的通信失败,但导致的具体原因往往因场景而异。 场景一:高峰期频繁出现 502 错误 1.1 现象 在流量高峰期间(如促销活动、直播发布等),页面访问变慢甚至出现 502 错误&#…...

控制论与信息论:维纳和香农的核心分歧在于对「信息本质」的理解
控制论与信息论:维纳和香农的核心分歧在于对「信息本质」的理解 核心结论 控制论是「系统的方向盘」,通过反馈调节实现目标信息论是「信息的尺子」,量化信息传输的精度与效率根本分歧:维纳认为信息是「系统维持秩序的工具」&…...