机器学习在癌症分子亚型分类中的应用
学习笔记:机器学习在癌症分子亚型分类中的应用——Cancer Cell 研究解析

1. 文章基本信息
- 标题:Classification of non-TCGA cancer samples to TCGA molecular subtypes using machine learning
- 发表期刊:Cancer Cell
- 发表时间:2025 年,第 53 卷,第 2 期
- 研究目标:
- 开发机器学习分类器,用于将非 TCGA 样本映射到TCGA 定义的分子亚型。
- 支持多组学数据整合(mRNA、DNA 甲基化、CNV、突变、miRNA),提高分类准确度。
- 提供标准化工具(Docker 容器化),使研究和临床应用更便捷。
2. 文章的主要行文思路
(1) 引言(Introduction)
- 介绍癌症传统分类方法(基于组织学和解剖学分类)的局限性。
- 介绍 TCGA 数据集在癌症亚型研究中的重要性。
- 说明当前分子亚型分类方法在非 TCGA 样本上的应用挑战。
- 提出研究目标:使用机器学习方法开发分类器,将非 TCGA 样本归类到 TCGA 定义的亚型。
(2) 方法(Methods)
- 数据来源:使用 TCGA 的多组学数据,包括 mRNA、DNA 甲基化、CNV、miRNA、突变数据。
- 机器学习方法:
- 使用五种 ML 方法(AKLIMATE、CloudForest、SKGrid、JADBio、subSCOPE)。
- 训练 8,791 个 TCGA 样本,涵盖 26 种癌症队列和 106 个分子亚型。
- 使用交叉验证评估模型性能,最终选出 737 个最优分类器。
- 外部验证:
- 采用 METABRIC 和 AURORA 乳腺癌数据集,测试模型的泛化能力。

(3) 结果(Results)
-
分类模型构建与性能评估:
- 统计不同数据类型对分类的贡献。
- 发现 mRNA 在大多数癌症亚型分类中起主导作用。

-
外部数据集验证:
- 评估不同 ML 方法在不同测序平台(RNA-seq vs. 微阵列)上的稳健性。
-
模型泛化能力:
- 发现 70 个样本足以预测分类器的最终性能。
- 研究不同癌症亚型对单一数据类型的依赖程度。
(4) 讨论(Discussion)
- TCGA 亚型分类的临床应用潜力:
- 预测新样本时,可提供标准化的癌症分子亚型信息。
- 未来可用于开发简化的癌症检测面板。

- 研究局限性:
- TCGA 数据可能未涵盖所有癌症亚型。
- 不同测序平台可能影响模型泛化能力。
(5) 结论(Conclusion)
- 研究提供了一个通用的分类框架,可用于非 TCGA 样本的 TCGA 亚型分类。
- 公开 737 个高性能分类器,可用于癌症检测和精准医学研究。
3. 文章的主要贡献
(1) 机器学习驱动的癌症分型
- 使用 5 种机器学习方法 训练 TCGA 数据:
- AKLIMATE
- CloudForest
- SKGrid
- JADBio
- subSCOPE
- 训练 412,585 个分类模型,最终筛选出 737 个最优模型。
- 提供 Docker 版本,保证可复现性和易用性。
(2) 多组学数据整合
- 研究分析了不同数据类型的贡献:
- mRNA 对大多数癌症亚型分类最关键。
- DNA 甲基化 在 LGG、GBM 等脑肿瘤分类中尤为重要。
- 突变数据(Mutations) 适用于黑色素瘤(SKCM)。
- 整合多种组学数据可提高分类准确度。
(3) 临床应用价值
- 提供 TCGA 亚型分类,提高癌症精准医学能力:
- 不同 TCGA 亚型的患者具有不同的预后和治疗策略。
- 例如:CMS1 结直肠癌(高 MSI-H)对 PD-1 免疫治疗敏感,而 CMS4 免疫排斥明显。
- 帮助医生和研究人员在新数据集中分类样本,指导精准治疗。
(4) 公开可用的工具
- 提供 Docker 容器,简化安装和使用。
- GitHub 代码公开,提高可复现性。
https://github.com/NCICCGPO/gdan-tmp-models
3. 作者的主要单位
| 单位 | 机构类型 | 研究重点 | 是否与临床相关 |
|---|---|---|---|
| Oregon Health & Science University (OHSU) | 医学中心 | 癌症基因组学、精准医学 | ✅ 高度相关 |
| University of California, San Francisco (UCSF) | 医学中心 | 肿瘤学、精准医学 | ✅ 高度相关 |
| Dana-Farber Cancer Institute (DFCI) | 癌症中心 | 肿瘤学、临床研究 | ✅ 高度相关 |
| MD Anderson Cancer Center (UTMDACC) | 癌症医院 | 癌症治疗、精准医学 | ✅ 高度相关 |
| National Cancer Institute (NCI) | 政府研究机构 | 癌症基因组、精准医学 | ✅ 高度相关 |
| The Broad Institute (MIT & Harvard) | 研究机构 | 癌症基因组、药物开发 | ✅ 高度相关 |
| University of California, Santa Cruz (UCSC) | 大学 | 计算生物学、生物信息学 | ❌ 主要是计算研究 |
| King Abdullah University of Science and Technology (KAUST) | 大学 | 计算机科学、机器学习 | ❌ 主要是算法,不直接涉及临床 |
📌 结论:
- 该研究团队涵盖了癌症精准医学、基因组学、计算生物学、机器学习等多个领域,保证了该研究的高临床相关性和计算分析的前沿性。
4. 如何使用 Docker 进行数据处理
(1) 安装 Docker
首先,确保服务器已安装 Docker:
docker --version # 确认安装
如果未安装,可以运行以下命令安装:
sudo apt update
sudo apt install docker.io -y
sudo systemctl start docker
sudo systemctl enable docker
(2) 克隆 GitHub 仓库
git clone https://github.com/NCICCGPO/gdan-tmp-models.git
cd gdan-tmp-models
(3) 拉取 Docker 镜像
docker pull nciccpo/gdan-tmp-aklimate:latest
docker pull nciccpo/gdan-tmp-cloudforest:latest
docker pull nciccpo/gdan-tmp-skgrid:latest
docker pull nciccpo/gdan-tmp-jadbio:latest
docker pull nciccpo/gdan-tmp-subscope:latest
(4) 准备输入数据
mkdir -p ~/gdan-input
mkdir -p ~/gdan-config
将**RNA-seq 表达数据(FPKM/TPM)**放入 ~/gdan-input/ 目录,并创建 YAML 配置文件 ~/gdan-config/config.yml:
model: aklimate
input_data:mRNA: /data/mRNA_expression.csv
output:results: /data/prediction_results.csv
(5) 运行 Docker 进行 TCGA 亚型预测
docker run --rm --cpus=64 \-v ~/gdan-input:/data \-v ~/gdan-config:/config \nciccpo/gdan-tmp-aklimate:latest /config/config.yml
📌 参数解释
--cpus=64:使用 64 核 CPU(可根据服务器性能调整)。-v ~/gdan-input:/data:映射输入数据目录到/data。-v ~/gdan-config:/config:映射 YAML 配置文件目录到/config。
(6) 查看预测结果
ls ~/gdan-input
cat ~/gdan-input/prediction_results.txt
或者:
import pandas as pd
df = pd.read_csv("~/gdan-input/prediction_results.csv")
print(df.head())
5. 结果解读
示例结果:
Sample_ID Predicted_TCGA_Subtype Confidence_Score
Sample_001 BRCA_LuminalA 0.95
Sample_002 LGG_IDH_Mutant 0.87
Sample_003 SKCM_BRAF_Mutant 0.92
📌 解读
Predicted_TCGA_Subtype:模型预测的 TCGA 亚型Confidence_Score(0-1):置信度,越高表示分类越可靠- 如果置信度低(如 <0.7),说明该样本可能更偏向其他亚型或需要额外数据支持(如 DNA 甲基化)。
6. 结论
✅ 该研究基于 TCGA 数据,提供了精准的癌症亚型分类工具
✅ 支持 RNA-seq(mRNA)数据,适用于临床研究和精准医学
✅ 使用 Docker 容器化,保证可复现性,提供 737 个高性能分类器
✅ 有助于个性化治疗,如免疫治疗和靶向治疗策略的选择
📌 下一步
- 尝试用自己的 RNA-seq 数据跑一次分析
- 如果分类结果置信度较低,可考虑添加 DNA 甲基化或突变数据
- 如有问题,可以查看 Docker 日志:
docker logs <CONTAINER_ID>
相关文章:
机器学习在癌症分子亚型分类中的应用
学习笔记:机器学习在癌症分子亚型分类中的应用——Cancer Cell 研究解析 1. 文章基本信息 标题:Classification of non-TCGA cancer samples to TCGA molecular subtypes using machine learning发表期刊:Cancer Cell发表时间:20…...

从MySQL优化到脑力健康:技术人与效率的双重提升
文章目录 零:前言一:MySQL性能优化的核心知识点1. 索引优化的最佳实践实战案例: 2. 高并发事务的处理机制实战案例: 3. 查询性能调优实战案例: 4. 缓存与连接池的优化实战案例: 二:技术工作者的…...

Qt:项目文件解析
目录 QWidget基础项目文件解析 .pro文件解析 widget.h文件解析 widget.cpp文件解析 widget.ui文件解析 main.cpp文件解析 认识对象模型 窗口坐标系 QWidget基础项目文件解析 .pro文件解析 工程新建好之后,在工程目录列表中有⼀个后缀为 ".pro" …...

react使用if判断
1、第一种 function Dade(req:any){console.log(req)if(req.data.id 1){return <span>66666</span>}return <span style{{color:"red"}}>8888</span>}2、使用 {win.map((req,index) > ( <> <Dade data{req}/>{req.id 1 ?…...

conda 修复 libstdc++.so.6: version `GLIBCXX_3.4.30‘ not found 简便方法
ImportError: /data/home/hum/anaconda3/envs/ipc/bin/../lib/libstdc.so.6: version GLIBCXX_3.4.30 not found (required by /home/hum/anaconda3/envs/ipc/lib/python3.11/site-packages/paddle/base/libpaddle.so) 1. 检查版本 strings /data/home/hum/anaconda3/envs/ipc/…...

在服务器部署JVM后,如何评估JVM的工作能力,比如吞吐量
在服务器部署JVM后,评估其工作能力(如吞吐量)可以通过以下步骤进行: 1. 选择合适的基准测试工具 JMH (Java Microbenchmark Harness):适合微基准测试,测量特定代码片段的性能。Apache JMeter:…...

python学opencv|读取图像(六十)先后使用cv2.erode()函数和cv2.dilate()函数实现图像处理
【1】引言 前序学习进程中,先后了解了使用cv2.erode()函数和cv2.dilate()函数实现图像腐蚀和膨胀处理的效果,相关文章链接为: python学opencv|读取图像(五十八)使用cv2.erode()函数实现图像腐蚀处理-CSDN博客 pytho…...
 -- PdfReader)
Itext源代码阅读(2) -- PdfReader
本文基于Itext 5,Itext7相较itext5虽然有较大变化,但是原理是一样的。 参考资料: 使用iText处理pdf文件的入门级教程_itextpdf 教程-CSDN博客 比较详实的介绍了长用的itext 的pdf处理。 深入iText7:第5章源代码实践指南-CSDN博…...

JavaScript-Object 对象的相关方法
1. Object.getPrototypeOf() Object.getPrototypeOf方法返回参数对象的原型。这是获取原型对象的标准方法。 var F function () {}; var f new F(); Object.getPrototypeOf(f) F.prototype // true 上面代码中,实例对象 f的原型是 F.prototype。 下面是几种特殊对…...

Flink 内存模型各部分大小计算公式
Flink 的运行平台 如果 Flink 是运行在 yarn 或者 standalone 模式的话,其实都是运行在 JVM 的基础上的,所以首先 Flink 组件运行所需要给 JVM 本身要耗费的内存大小。无论是 JobManager 或者 TaskManager ,他们 JVM 内存的大小都是一样的&a…...

每日一题——缺失的第一个正整数
缺失的第一个正整数 题目描述进阶:数据范围: 示例示例 1示例 2示例 3 题解思路代码实现代码解释复杂度分析总结 题目描述 给定一个无重复元素的整数数组 nums,请你找出其中没有出现的最小的正整数。 进阶: 时间复杂度ÿ…...

Qt修仙之路2-1 仿QQ登入 法宝初成
widget.cpp #include "widget.h" #include<QDebug> //实现槽函数 void Widget::login1() {QString userusername_input->text();QString passpassword_input->text();//如果不勾选无法登入if(!check->isChecked()){qDebug()<<"xxx"&…...

从家庭IP到全球网络资源的无缝连接:Cliproxy的专业解决方案
数字化时代,家庭IP作为个人或家庭接入互联网的门户,其重要性日益凸显。然而,要实现从家庭IP到全球网络资源的无缝连接,并享受高效、安全、稳定的网络访问体验,往往需要借助专业的代理服务。Cliproxy,作为业…...

Python 脚本实现数据可视化
使用 Python 脚本实现数据可视化可以通过以下步骤: 一、准备工作 安装必要的库: matplotlib:这是一个广泛使用的 Python 2D 绘图库,可以生成各种静态、动态和交互式的图表。seaborn:建立在 matplotlib 之上ÿ…...

【Java】多线程和高并发编程(四):阻塞队列(上)基础概念、ArrayBlockingQueue
文章目录 四、阻塞队列1、基础概念1.1 生产者消费者概念1.2 JUC阻塞队列的存取方法 2、ArrayBlockingQueue2.1 ArrayBlockingQueue的基本使用2.2 生产者方法实现原理2.2.1 ArrayBlockingQueue的常见属性2.2.2 add方法实现2.2.3 offer方法实现2.2.4 offer(time,unit)方法2.2.5 p…...
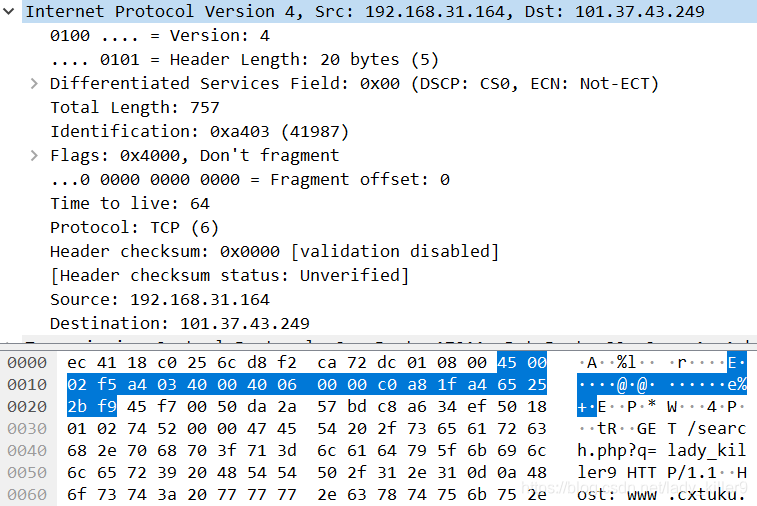
TCP/IP 协议图解 | TCP 协议详解 | IP 协议详解
注:本文为 “TCP/IP 协议” 相关文章合辑。 未整理去重。 TCP/IP 协议图解 退休的汤姆 于 2021-07-01 16:14:25 发布 TCP/IP 协议简介 TCP/IP 协议包含了一系列的协议,也叫 TCP/IP 协议族(TCP/IP Protocol Suite,或 TCP/IP Pr…...

点大商城V2-2.6.6源码全开源uniapp +搭建教程
一.介绍 点大商城V2独立开源版本,版本更新至2.6.6,系统支持多端,前端为UNiapp,多端编译。 二.搭建环境: 系统环境:CentOS、 运行环境:宝塔 Linux 网站环境:Nginx 1.21 MySQL 5.…...

【GitHub】相关工具下载及使用
目录 背景GitHub的使用Git工具下载及安装 背景 需要在GitHub查阅相关资料,以下是对使用GitHub做相关记录。 GitHub的使用 参考链接: GitHub入门指南:一步一步教你使用GitHub Git工具下载及安装 参考链接: windows安装git(全网最详细&…...

阿里云百炼初探DeepSeek模型调用
阿里云百炼初探DeepSeek模型调用 阿里云百炼为什么选择百炼开始使用百炼方式一:文本对话方式二:文本调试方式三:API调用 DeepSeek调用1、搜索模型2、查看API调用3、开始调用安装依赖查看API Key运行以下代码 4、流式输出 总结 阿里云百炼 阿…...

蓝桥杯备赛——“双指针”“三指针”解决vector相关问题
一、寄包柜 相关代码: #include <iostream> #include <vector> using namespace std; const int N 1e5 10; int n, q; vector<int> a[N]; // 创建 N 个柜⼦ int main() {cin >> n >> q;while(q--){int op, i, j, k;cin >> …...

【Java 面试 八股文】Redis篇
Redis 1. 什么是缓存穿透?怎么解决?2. 你能介绍一下布隆过滤器吗?3. 什么是缓存击穿?怎么解决?4. 什么是缓存雪崩?怎么解决?5. redis做为缓存,mysql的数据如何与redis进行同步呢&…...

SIPp的参数及命令示例
以下是SIPp参数的分类表格整理,方便快速查阅和使用: SIPp 参数分类表格 分类参数描述默认值示例基本参数-sc指定XML场景文件(客户端模式)无-sc uac.xml-sd指定XML场景文件(服务器端模式)无-sd uas.xml-i本…...
)
全面理解-友元(friend关键字)
在 C 中,friend 关键字用于授予其他类或函数访问当前类的 私有(private)和保护(protected)成员 的权限。这种机制打破了严格的封装性,但可以在特定场景下提高代码的灵活性和效率。以下是 friend 的详细说明…...

【Java】多线程和高并发编程(三):锁(下)深入ReentrantReadWriteLock
文章目录 4、深入ReentrantReadWriteLock4.1 为什么要出现读写锁4.2 读写锁的实现原理4.3 写锁分析4.3.1 写锁加锁流程概述4.3.2 写锁加锁源码分析4.3.3 写锁释放锁流程概述&释放锁源码 4.4 读锁分析4.4.1 读锁加锁流程概述4.4.1.1 基础读锁流程4.4.1.2 读锁重入流程4.4.1.…...

macbook2015升级最新MacOS 白苹果变黑苹果
原帖:https://www.bilibili.com/video/BV13V411c7xz/MAC OS系统发布了最新的Sonoma,超酷的动效锁屏壁纸,多样性的桌面小组件,但是也阉割了很多老款机型的升级权利,所以我们可以逆向操作,依旧把老款MAC设备强…...
如何使用C++将处理后的信号保存为PNG和TIFF格式
在信号处理领域,我们常常需要将处理结果以图像的形式保存下来,方便后续分析和展示。C提供了多种库来处理图像数据,本文将介绍如何使用stb_image_write库保存为PNG格式图像以及使用OpenCV库保存为TIFF格式图像。 1. PNG格式保存 使用stb_ima…...

探索从传统检索增强生成(RAG)到缓存增强生成(CAG)的转变
在人工智能快速发展的当下,大型语言模型(LLMs)已成为众多应用的核心技术。检索增强生成(RAG)(RAG 系统从 POC 到生产应用:全面解析与实践指南)和缓存增强生成(CAG&#x…...

尝试一下,交互式的三维计算python库,py3d
py3d是一个我开发的三维计算python库,目前不定期在PYPI上发版,可以通过pip直接安装 pip install py3d 开发这个库主要可视化是想把自己在工作中常用的三维方法汇总积累下来,不必每次重新造轮子。其实现成的python库也有很多,例如…...

[创业之路-289]:《产品开发管理-方法.流程.工具 》-15- 需求管理 - 第1步:原始需求收集
概述: 需求收集是需求管理的第一步,也是产品开发、项目管理或软件设计中的关键步骤。原始需求收集主要是指从各种来源获取关于产品或服务的初步需求和期望。 以下是对需求管理中的原始需求收集的详细分析: 1、原始需求收集的目的 原始需求…...

蓝桥杯---数青蛙(leetcode第1419题)
文章目录 1.题目重述2.例子分析3.思路分析4.思路总结5.代码解释 1.题目重述 这个题目算是模拟这个专题里面的一类比较难的题目了,他主要是使用crock这个单词作为一个整体,让我们确定:给你一个字符串,至少需要多少个青蛙进行完成鸣…...