Docker的深入浅出
目录
Docker引擎
Docker镜像 (镜像由多个层组成,每层叠加之后,从外部看来就如一个独立的对象。镜像内部是一个精简的操作系统(OS),同时还包含应用运行所必须的文件和依赖包)
Docker容器
应用容器化--Docker化
最佳实践
Docker Compose 初识 (python工具)--> 一个声明式的配置文件YAML描述
Docker Swarm --> 安全集群、编排引擎
Docker网络
卷
Docker Stack
安全
容器为什么出现
容器的作用
容器的应用场景
虚拟机的不足: OS的认证,OS占用额外的CPU、RAM和存储,启动较慢并且可移植性较差
容器的运行不会独占操作系统。实际上,运行在相同宿主机上的容器是共享一个操作系统的,这样就能够节省大量的系统资源。容器同时还能节省大量花费在许可证上的开销,以及为OS打补丁等运维成本。
对容器发展影响比较大的技术包括内核命名空间(Kernel Namespace)、控制组(Control Group)、联合文件系统(Union File System),当然更少不了Docker。
容器技术很早就有了,只是Docker的出现让大众所接受
运行中的容器共享宿主机的内核。这意味着一个基于Windows的容器化应用在Linux主机上是无法运行的。但现在已经成为可能。
Kubernetes: Kubernetes是保证容器部署和运行的软件体系中很重要的一部分
CRI能够帮助Kubernetes实现将运行时环境从Docker快速替换为其他容器运行时
Docker用于创建、管理和编排容器。 -- 旧金山
Docker引擎是用于运行和编排容器的基础设施工具。

GitHub上的docker/docker库也被转移到了moby/moby,并且拥有了项目自己的Logo。Logo
Moby项目的目标是基于开源的方式,发展成为Docker上游,并将Docker拆分为更多的模块化组件。
许多Docker内置的组件都可以替换为第三方的组件。良性的竞争是创新之母
OCI是一个旨在对容器基础架构中的基础组件进行标准化的管理委员会。
Docker的安装目前很方便,此处不进行笔记记录。
Docker的更新大致步骤如下:
需要重视升级操作的每个前置条件,包括确保容器配置了正确的重启策略;在Swarm Mode模式下使用服务时,需要确保正确配置了draining node。当完成了上述前置条件的检查之后,可以通过如下步骤完成升级操作。
(1)停止Docker守护程序。
(2)移除旧版本Docker。
(3)安装新版本Docker。
(4)配置新版本的Docker为开机自启动。
(5)确保容器重启成功。
Docker在Linux底层支持几种不同的存储驱动的具体实现,每一种实现方式都采用不同方法实现了镜像层和写时复制。虽然底层实现的差异不影响用户与Docker之间的交互,但是对Docker的性能和稳定性至关重要。
注意: 如果读者修改了正在运行Docker主机的存储引擎类型,则现有的镜像和容器在重启之后将不可用,这是因为每种存储驱动在主机上存储镜像层的位置是不同的。切换到原来的存储驱动,之前的镜像和容器就可以继续使用了。
如果读者希望在切换存储引擎之后还能够继续使用之前的镜像和容器,需要将镜像保存为Docker格式,上传到某个镜像仓库,修改本地Docker存储引擎并重启,之后从镜像仓库将镜像拉取到本地,最后重启容器。
Docker存储驱动的选择
在Linux上,Docker可选择的一些存储驱动包括AUFS(最原始也是最老的)、Overlay2(*)、Device Mapper、Btrfs和ZFS。
Device Mapper配置: 为了达到Device Mapper在生产环境中的最佳性能,需要将底层实现修改为direct-lvm模式。这种模式下通过使用基于裸块设备(Raw Block Device)的LVM精简池(LVM thin pool)来获取更好的性能。
运维视角: 下载镜像、运行新的容器、登录新容器、在容器内运行命令,以及销毁容器
开发视角: Dockerfile,将应用容器化,并在容器中运行它们
通过docker version 来确认客户端和服务端是否都已经成功运行,并且可以互相通信

镜像: 将Docker镜像理解为一个包含了OS文件系统和应用的对象会很有帮助
在Docker主机上运行docker image ls命令

docker container run 来启动容器

-it 参数会将Shell切换到容器终端。
按Ctrl-PQ组合键,可以在退出容器的同时还保持容器运行。这样Shell就会返回到Docker主机终端。可以通过查看Shell提示符来确认。 (依次按P 然后按Q键)
![]()
docker container exec 重新进入容器内部
![]()
使用stop和rm , 分别停止和移除已建立的容器

docker ps -a 和 docker container ls -a 应该是等价的,列出所有的容器包括未运行的

开发---- Dockerfile 并将其容器化
基于Dockerfile构建新的镜像

如果自动拉取有问题,可以手动先执行docker pull 下来基础的镜像
Docker引擎
基于开放容器计划(OCI)相关标准的要求,Docker引擎采用了模块化的设计原则,其组件是可替换的。

总体逻辑的组成
Docker首次发布时,Docker引擎由两个核心组件构成:LXC和Docker daemon。
Docker daemon是单一的二进制文件,包含诸如Docker客户端、Docker API、容器运行时、镜像构建等。
LXC提供了对诸如命名空间(Namespace)和控制组(CGroup)等基础工具的操作能力,它们是基于Linux内核的容器虚拟化技术。
早期的Docker架构

Docker公司开发了名为Libcontainer的自研工具,用于替代LXC。Libcontainer的目标是成为与平台无关的工具,可基于不同内核为Docker上层提供必要的容器交互功能。
在Docker 0.9版本中,Libcontainer取代LXC成为默认的执行驱动。
然后进行拆解Docker daemon,将其模块化,目的是小而专的工具可以组装为大型工具。

OCI制定相关的标准。
runc: 是OCI容器运行时规范的参考实现。创建容器,这一点它非常拿手,速度很快。直接下载它或基于源码编译二进制文件,即可拥有一个全功能的runc。但它只是一个基础工具,并不提供类似Docker引擎所拥有的丰富功能。
containerd: Docker引擎技术栈中,containerd位于daemon和runc所在的OCI层之间。Kubernetes也可以通过cri-containerd使用containerd。如今containerd还能够完成一些除容器生命周期管理之外的操作。不过,所有的额外功能都是模块化的、可选的,便于自行选择所需功能。
![]()
daemon使用一种CRUD风格的API,通过gRPC与containerd进行通信。
虽然名叫containerd,但是它并不负责创建容器,而是指挥runc去做。整个流程如下所示

在旧模型中,所有容器运行时的逻辑都在daemon中实现,启动和停止daemon会导致宿主机上所有运行中的容器被杀掉。将所有的用于启动、管理容器的逻辑和代码从daemon中移除,意味着容器运行时与Docker daemon是解耦的,有时称之为“无守护进程的容器(daemonless container)。Docker daemon的维护和升级工作不会影响到运行中的容器。
shim组件
shim是实现无daemon的容器不可或缺的工具。
一旦容器进程的父进程runc退出,相关联的containerd-shim进程就会成为容器的父进程。作为容器的父进程
保持所有STDIN和STDOUT流是开启状态,从而当daemon重启的时候,容器不会因为管道(pipe)的关闭而终止。
将容器的退出状态反馈给daemon。
Docker镜像 (镜像由多个层组成,每层叠加之后,从外部看来就如一个独立的对象。镜像内部是一个精简的操作系统(OS),同时还包含应用运行所必须的文件和依赖包)
拉取操作会将镜像下载到本地Docker主机,读者可以使用该镜像启动一个或者多个容器。
镜像与容器的关系

在镜像上启动的容器全部停止之前,镜像是无法被删除的。镜像中还不包含内核——容器都是共享所在Docker主机的内核。容器仅包含必要的操作系统。
Windows镜像要远大于Linux镜像,镜像中分层也更多。
镜像存储的背景知识
镜像仓库 官方 Docker Hub

Docker命令行是通过镜像名字和标签来定位的
从官方仓库拉取镜像时,格式 docker image pull <repository>:<tag>
例:
$ docker image pull mongo:3.3.11 //该命令会从官方Mongo库拉取标签为3.3.11的镜像
$ docker image pull redis:latest //该命令会从官方Redis库拉取标签为latest的镜像
如果不加标签,就是拉取latest的版本,但不意味着是最新的,并且使用latest标签时需要谨慎。latest是一个非强制标签,不保证指向仓库中最新的镜像!
如果希望从第三方镜像仓库服务获取镜像(非Docker Hub),则需要在镜像仓库名称前加上第三方镜像仓库服务的DNS名称。
镜像标签: 一个镜像可以根据用户需要设置多个标签。在docker image pull命令中指定-a参数来拉取仓库中的全部镜像。如果发现标签指向了相同的IMAGE ID,这意味着这两个标签属于相同的镜像。
Docker提供--filter参数来过滤docker image ls命令返回的镜像列表内容
那些没有标签的镜像被称为悬虚镜像,在列表中展示为<none>:<none>。通常出现这种情况,是因为构建了一个新镜像,然后为该镜像打了一个已经存在的标签。
可以通过docker image prune命令移除全部的悬虚镜像。如果添加了-a参数,Docker会额外移除没有被使用的镜像(那些没有被任何容器使用的镜像)
dangling:可以指定true或者false,仅返回悬虚镜像(true),或者非悬虚镜像(false)。
before:需要镜像名称或者ID作为参数,返回在指定镜像之前被创建的全部镜像。
since:与before类似,不过返回的是指定镜像之后创建的全部镜像。
label:根据标注(label)的名称或者值,对镜像进行过滤。docker image ls命令输出中不显示标注内容。
其他的过滤方式可以使用reference。
应用:

只显示官方镜像: $ docker search alpine --filter "is-official=true"
只显示自动创建的仓库: $ docker search alpine --filter "is-automated=true"
搜索: docker search命令允许通过CLI的方式搜索Docker Hub。读者可以通过“NAME”字段的内容进行匹配,并且基于返回内容中任意列的值进行过滤。 ** 默认情况下,Docker只返回25行结果。但是,读者可以指定--limit参数来增加返回内容行数,最多为100行。
镜像的组成:

除了在pull的过程中可以查看镜像的分层,使用docker image inspect 命令可以查看镜像的分层

注意: docker history命令显示了镜像的构建历史记录,但其并不是严格意义上的镜像分层。例如,有些Dockerfile中的指令并不会创建新的镜像层。比如ENV、EXPOSE、CMD以及ENTRY- POINT。不过,这些命令会在镜像中添加元数据。
原理: 所有的Docker镜像都起始于一个基础镜像层,当进行修改或增加新的内容时,就会在当前镜像层之上,创建新的镜像层。例如:

上层镜像层中的文件覆盖了底层镜像层中的文件。这样就使得文件的更新版本作为一个新镜像层添加到镜像当中。例如:

Docker通过存储引擎(新版本采用快照机制)的方式来实现镜像层堆栈,并保证多镜像层对外展示为统一的文件系统。Linux上可用的存储引擎有AUFS、Overlay2、Device Mapper、Btrfs以及ZFS。
共享镜像层: 多个镜像之间可以并且确实会共享镜像层。这样可以有效节省空间并提升性能。
如果修复前和修复后的镜像标签是相同的,就无法区分出新旧,那么需要使用镜像摘要(散列值),因为散列值是基于内容的,内容变更意味着摘要一定会改变。只需要在docker image ls命令之后添加--digests参数即可在本地查看镜像摘要。
如果使用摘要值进行拉取,可以保证准确拉取。
镜像层才是实际数据存储的地方,镜像层之间是完全独立的。镜像的唯一标识是一个加密ID,即配置对象本身的散列值。每个镜像层同时会包含一个分发散列值(Distribution Hash)。这是一个压缩版镜像的散列值,当从镜像仓库服务拉取或者推送镜像的时候,其中就包含了分发散列值,该散列值会用于校验拉取的镜像是否被篡改过。
多架构镜像: 一个镜像标签之下可以支持多个平台和架构。镜像仓库服务API支持两种重要的结构:Manifest列表(新)和Manifest。

某些软件也并非跨平台的。在这个前提下,Manifest列表是可选的——在没有Manifest列表的情况下,镜像仓库服务会返回普通的Manifest。
通过docker image rm命令从Docker主机删除该镜像。如果某个镜像层被多个镜像共享,那只有当全部依赖该镜像层的镜像都被删除后,该镜像层才会被删除。先停止并删除基于该镜像的容器,然后才能删除该镜像。
删除某主机上的全部镜像: $ docker image rm $(docker image ls -q) -f
Docker容器
容器是镜像的运行时实例。虚拟机和容器最大的区别是容器更快并且更轻量级——与虚拟机运行在完整的操作系统之上相比,容器会共享其所在主机的操作系统/内核。

启动容器的简便方式是使用docker container run命令。该命令可以携带很多参数,其基础的格式docker container run <image> <app>。-it参数可以将当前终端连接到容器的Shell终端之上。
容器与虚拟机


从更高层面上来讲,Hypervisor是硬件虚拟化(Hardware Virtualization)——Hypervisor将硬件物理资源划分为虚拟资源;另外,容器是操作系统虚拟化(OS Virtualization)——容器将系统资源划分为虚拟资源。
每个虚拟机都需要有自己的操作系统来声明、初始化并管理这些虚拟资源,每个操作系统都占用一定的资源。容器模型具有在宿主机操作系统中运行的单个内核。在一台主机上运行数十个甚至数百个容器都是可能的——容器共享一个操作系统/内核。 容器的共享导致不需要初始化内核,因此启动要比虚拟机快。
如果在Linux中遇到无权限访问的问题,需要确认当前用户是否属于本地Docker UNIX组。如果不是,可以通过usermod -aG docker <user>来添加,然后退出并重新登录Shell,改动即可生效。
//使用System V在Linux系统中执行该命令
$ service docker status
docker start/running, process 29393
//使用Systemd在Linux系统中执行该命令
$ systemctl is-active docker active
比较简单启动容器的命令: $ docker container run -it ubuntu:latest /bin/bash 。命令中使用了-it参数使容器具备交互性并与终端进行连接;最终,在命令中指定了运行在容器中的程序,Linux示例中是Bash Shell。Docker默认非TLS网络端口为2375,TLS默认端口为2376。
如果通过输入exit退出Bash Shell,那么容器也会退出(终止)。原因是容器如果不运行任何进程则无法存在——杀死Bash Shell即杀死了容器唯一运行的进程,导致这个容器也被杀死。这对于Windows容器来说也是一样的——杀死容器中的主进程,则容器也会被杀死。
容器的生命周期(从创建、运行、休眠,直至销毁的整个过程)
![]()
docker container stop命令中指定容器的名称或者ID。具体格式为docker container stop <container-id or container-name>。
使用docker container exec命令连接到重启后的容器。$ docker container exec -it percy bash
尽管上面的示例阐明了容器的持久化特性,还是需要指出卷(volume)才是在容器中存储持久化数据的首选方式
通过在docker container rm命令后面添加-f参数来一次性删除运行中的容器是可行的。但是,删除容器的最佳方式还是分两步,先停止容器然后删除。因为给了时间反应,而不是突然杀停。
利用重启策略进行容器的自我修复: 建议在运行容器时配置好重启策略。这是容器的一种自我修复能力,可以在指定事件或者错误后重启来完成自我修复
容器支持的重启策略包括always、unless-stopped和on-failed。always策略是一种简单的方式。除非容器被明确停止,比如通过docker container stop命令,否则该策略会一直尝试重启处于停止状态的容器。
--restart always策略有一个很有意思的特性,当daemon重启的时候,停止的容器也会被重启。always和unless-stopped的最大区别,就是那些指定了--restart unless-stopped并处于Stopped(Exited)状态的容器,不会在Docker daemon重启的时候被重启。
on-failure策略会在退出容器并且返回值不是0的时候,重启容器。就算容器处于stopped状态,在Docker daemon重启的时候,容器也会被重启。
添加-d参数可以在后台运行。
一个事例: ![]()
在构建镜像时指定默认命令是一种很普遍的做法,因为这样可以简化容器的启动。这也为镜像指定了默认的行为,并且从侧面阐述了镜像的用途——可以通过Inspect镜像的方式来了解所要运行的应用。
快速清理会没有反应的情况,不建议使用
应用容器化--Docker化
容器能够简化应用的构建、部署和运行过程。
(1)编写应用代码。
(2)创建一个Dockerfile,其中包括当前应用的描述、依赖以及该如何运行这个应用。
(3)对该Dockerfile执行docker image build命令。
(4)等待Docker将应用程序构建到Docker镜像中。

Dockerfile
通常将Dockerfile放到构建上下文的根目录下。

以alpine镜像作为当前镜像基础,指定维护者(maintainer)为“nigelpoultion@hotmail.com”,安装Node.js和NPM,将应用的代码复制到镜像当中,设置新的工作目录,安装依赖包,记录应用的网络端口,最后将app.js设置为默认运行的应用。
RUN指令会在FROM指定的alpine基础镜像之上,新建一个镜像层来存储这些安装内容。
COPY. / src指令将应用相关文件从构建上下文复制到了当前镜像中,并且新建一个镜像层来存储。
RUN npm install指令会根据package.json中的配置信息,使用npm来安装当前应用的相关依赖包。npm命令会在前文设置的工作目录中执行,并且在镜像中新建镜像层来保存相应的依赖文件。
通过ENTRYPOINT指令来指定当前镜像的入口程序。
构建: docker image build -t web:latest . << don't forget the period (.)
通过docker image inspect web:latest,会列出Dockerfile中设置的所有配置项。
docker login 可以登陆 docker hub
为镜像打标签的示例: docker image tag web:latest nigelpoulton/web:latest。
后台运行并且指定了端口映射: docker container run -d --name c1 -p 80:8080 web:latest
Dockerfile译述: Dockerfile中的注释行,都是以#开头的 , 通常使用大写。
新增镜像层的指令包括FROM、RUN以及COPY,而新增元数据的指令包括EXPOSE、WORKDIR、ENV以及ENTERPOINT。一个基本的原则是,如果指令的作用是向镜像中增添新的文件或者程序,那么这条指令就会新建镜像层;如果只是告诉Docker如何完成构建或者如何运行应用程序,那么就只会增加镜像的元数据。
可以通过docker image history来查看在构建镜像的过程中都执行了哪些指令
基本的构建过程是,运行临时容器>在该容器中运行Dockerfile中的指令>将指令运行结果保存为一个新的镜像层>删除临时容器。
**通过将命令都写在一个RUN中,可以减少层的建设。另一个问题是开发者通常不会在构建完成后进行清理。当使用RUN执行一个命令时,可能会拉取一些构建工具,这些工具会留在镜像中移交至生产环境。这是不合适的!
多阶段构建能够在不增加复杂性的情况下优化构建过程。多阶段构建方式使用一个Dockerfile,其中包含多个FROM指令。每一个FROM指令都是一个新的构建阶段(Build Stage),并且可以方便地复制之前阶段的构件。
重点在于COPY --from指令,它从之前的阶段构建的镜像中仅复制生产环境相关的应用代码,而不会复制生产环境不需要的构件。
示例Dockerfile代码:
FROM node:latest AS storefront
WORKDIR /usr/src/atsea/app/react-app
COPY react-app .
RUN npm install
RUN npm run build
FROM maven:latest AS appserver
WORKDIR /usr/src/atsea
COPY pom.xml .
RUN mvn -B -f pom.xml -s /usr/share/maven/ref/settings-docker.xml dependency \:resolve
COPY . .
RUN mvn -B -s /usr/share/maven/ref/settings-docker.xml package -DskipTests
FROM java:8-jdk-alpine AS production
RUN adduser -Dh /home/gordon gordon
WORKDIR /static
COPY --from=storefront /usr/src/atsea/app/react-app/build/ .
WORKDIR /app
COPY --from=appserver /usr/src/atsea/target/AtSea-0.0.1-SNAPSHOT.jar .
ENTRYPOINT ["java", "-jar", "/app/AtSea-0.0.1-SNAPSHOT.jar"]
CMD ["--spring.profiles.active=postgres"]
最佳实践
1、利用构建缓存 --> 缓存命中能显著加快构建过程
如果在开头无法找到符合要求的镜像层,则设置缓存无效并构建该镜像层,后续的指令将全部执行而不会再尝试查找构建缓存。
通过对docker image build命令加入--no-cache=true参数可以强制忽略对缓存的使用。
COPY和ADD指令会检查复制到镜像中的内容自上一次构建之后是否发生了变化。Docker会计算每一个被复制文件的Checksum值,并与缓存镜像层中同一文件的checksum进行对比。如果不匹配,那么就认为缓存无效并构建新的镜像层。
2、合并镜像 --> 有好有坏 缺点是无法共享镜像层 ,存储空间低效利用,push pull 操作镜像体积更大
执行docker image build命令时,可以通过增加--squash参数来创建一个合并的镜像。

3、使用no-install-recommends --> 这能够确保APT仅安装核心依赖(Depends中定义)包,而不是推荐和建议的包
Docker Compose 初识 (python工具)--> 一个声明式的配置文件YAML描述
Docker Compose,它能够在Docker节点上,以单引擎模式(Single-Engine Mode)进行多容器应用的部署和管理。Docker Stack,它能够以Swarm模式对Docker节点上的多容器应用进行部署和管理。
示例Yaml文件


version是必须指定的,而且总是位于文件的第一行。它定义了Compose文件格式(主要是API)的版本。建议使用最新版本。
services用于定义不同的应用服务。上边的例子定义了两个服务。
networks用于指引Docker创建新的网络。默认情况下,Docker Compose会创建bridge网络。这是一种单主机网络,只能够实现同一主机上容器的连接。当然,也可以使用driver属性来指定不同的网络类型。
volumes用于指引Docker来创建新的卷。
build:.指定Docker基于当前目录(.)下Dockerfile中定义的指令来构建一个新镜像。该镜像会被用于启动该服务的容器。
command:python app.py指定Docker在容器中执行名为app.py的Python脚本作为主程序。因此镜像中必须包含app.py文件以及Python,这一点在Dockerfile中可以得到满足。
ports:指定Docker将容器内(-target)的5000端口映射到主机(published)的5000端口。这意味着发送到Docker主机5000端口的流量会被转发到容器的5000端口。容器中的应用监听端口5000。
networks:使得Docker可以将服务连接到指定的网络上。这个网络应该是已经存在的,或者是在networks一级key中定义的网络。对于Overlay网络来说,它还需要定义一个attachable标志,这样独立的容器才可以连接上它(这时Docker Compose会部署独立的容器而不是Docker服务)。
volumes:指定Docker将counter-vol卷(source:)挂载到容器内的/code(target:)。counter-vol卷应该是已存在的,或者是在文件下方的volumes一级key中定义的。
Docker Compose 会将所有的资源名称中加上前缀 目录名_
常用的启动一个Compose应用的方式就是docker-compose up命令。它会构建所需的镜像,创建网络和卷,并启动容器。
如果不是默认的yml名字,应该使用-f 来指定docker-compose.yml的名字。
Docker Compose会将项目名称(counter-app)和Compose文件中定义的资源名称(web-fe)连起来。
docker compose 帮助手册命令全集

Docker Compose会在部署服务之前创建网络和卷。


我们在 Docker 主机对卷中文件的修改,会立刻反应到应用中。
docker-compose restart命令会重启已停止的Compose应用。如果用户在停止该应用后对其进行了变更,那么变更的内容不会反映在重启后的应用中,这时需要重新部署应用使变更生效。
Compose文件应该被当作代码,因此应该将其保存在源控制库中。
Docker Swarm --> 安全集群、编排引擎
从集群角度来说,一个Swarm由一个或多个Docker节点组成。节点会被配置为管理节点(Manager)或工作节点(Worker)。管理节点负责集群控制面(Control Plane),进行诸如监控集群状态、分发任务至工作节点等操作。工作节点接收来自管理节点的任务并执行。
Swarm的配置和状态信息保存在一套位于所有管理节点上的分布式etcd数据库中。无需管理,作为Swarm一部分被安装。Swarm使用TLS进行通信加密、节点认证和角色授权。

2377/tcp:用于客户端与Swarm进行安全通信。
7946/tcp与7946/udp:用于控制面gossip分发。
4789/udp:用于基于VXLAN的覆盖网络。
搭建Swarm的过程有时也被称为初始化Swarm,大体流程包括初始化第一个管理节点>加入额外的管理节点>加入工作节点>完成。

docker swarm init --advertise-addr 10.0.0.1:2377 --listen-addr 10.0.0.1:2377
--advertise-addr指定其他节点用来连接到当前管理节点的IP和端口 ; --listen-addr指定用于承载Swarm流量的IP和端口。其设置通常与--advertise-addr相匹配,但是当节点上有多个IP的时候,可用于指定具体某个IP。并且,如果--advertise-addr设置了一个远程IP地址(如负载均衡的IP地址),该属性也是需要设置的。建议执行命令时总是使用这两个属性来指定具体IP和端口。
Swarm模式下的操作默认运行于2337端口。
在mgr1上执行docker swarm join-token命令来获取添加新的工作节点和管理节点到Swarm的命令和Token。 工作节点和管理节点的接入命令中使用的接入Token(SWMTKN...)是不同的。因此,一个节点是作为工作节点还是管理节点接入,完全依赖于使用了哪个Token。
示例:
docker swarm join --token SWMTKN-1-0uahebax...c87tu8dx2c 10.0.0.1:2377 --advertise-addr 10.0.0.4:2377 --listen-addr 10.0.0.4:2377
--advertise-addr与--listen-addr属性是可选的。在网络配置方面,请尽量明确指定相关参数,这是一种好的实践。

MANAGER STATUS一列无任何显示的节点是工作节点。注意,mgr2的ID列还显示了一个星号(*),这个星号会告知用户执行docker node ls命令所在的节点。
也总是仅有一个节点处于活动状态。通常处于活动状态的管理节点被称为“主节点”(leader),而主节点也是唯一一个会对Swarm发送控制命令的节点。也就是说,只有主节点才会变更配置,或发送任务到工作节点。如果一个备用(非活动)管理节点接收到了Swarm命令,则它会将其转发给主节点。

关于管理器高可用性的最佳实践
部署奇数个管理节点。
不要部署太多管理节点(建议3个或5个)。 --> 更多的节点意味着需要更多的时间达到共识
部署奇数个管理节点有利于减少脑裂(Split-Brain)情况的出现机会。

Docker提供了自动锁机制来锁定Swarm,这会强制要求重启的管理节点在提供一个集群解锁码之后才有权从新接入集群。
命令: docker swarm update --autolock=true

执行docker swarm unlock命令来为重启的管理节点解锁Swarm。该命令需要在重启的节点上执行,同时需要提供解锁码。
使用docker service create命令创建一个新的服务。

使用--replicas参数告知Docker应该总是有5个此服务的副本。最后,告知Docker哪个镜像用于副本——重要的是,要了解所有的服务副本使用相同的镜像和配置。
Swarm会一直确保实际状态能够满足期望状态的要求。

关于服务更为详细的信息可以使用docker service inspect命令查看。
一个简单的docker service scale命令即可对web-fe服务进行扩容。
创建一个覆盖网络,与要创建的服务结合使用。覆盖网络是创建于底层异构网络之上的一个新的二层容器网络。
![]()

创建一个新的服务,并将其接入uber-net网络

通过对服务声明-p 80:80参数,会建立Swarm集群范围的网络流量映射,到达Swarm任何节点80端口的流量,都会映射到任何服务副本的内部80端口。
默认的模式,是在Swarm中的所有节点开放端口——即使节点上没有服务的副本——称为入站模式(Ingress Mode)。此外还有主机模式(Host Mode),即仅在运行有容器副本的节点上开放端口。
每次更新两个副本,并且中间间隔20s。

Swarm服务的日志可以通过执行docker service logs命令来查看。Docker节点默认的配置是,服务使用json-file日志驱动,其他的驱动还有journald(仅用于运行有systemd的Linux主机)、syslog、splunk和gelf。
json-file和journald是较容易配置的,二者都可用于docker service logs命令。命令格式为docker service logs <service-name>。
Docker网络
Docker网络架构源自一种叫作容器网络模型(CNM)的方案,该方案是开源的并且支持插接式连接。Libnetwork是Docker对CNM的一种实现,提供了Docker核心网络架构的全部功能。不同的驱动可以通过插拔的方式接入Libnetwork来提供定制化的网络拓扑。

不过其实抽象来讲,CNM定义了3个基本要素:沙盒(Sandbox)、终端(Endpoint)和网络(Network)。

终端与常见的网络适配器类似,这意味着终端只能接入某一个网络。因此,如果容器需要接入到多个网络,就需要多个终端。

单机桥接网络
每个Docker主机都有一个默认的单机桥接网络。除非读者通过命令行创建容器时指定参数--network,否则默认情况下,新创建的容器都会连接到该网络。


多机覆盖网络
Docker为覆盖网络提供了本地驱动。这使得创建覆盖网络非常简单,只需要在docker network create命令中添加--d overlay参数。
接入现有网络
将容器化应用连接到网络

Macvlan的缺点是需要将主机网卡(NIC)设置为混杂模式(Promiscuous Mode),这在大部分公有云平台上是不允许的。所以Macvlan对于公司内部的数据中心网络来说很棒(假设公司网络组能接受NIC设置为混杂模式),但是Macvlan在公有云上并不可行。
服务发现
允许容器和Swarm服务通过名称互相定位。唯一的要求就是需要处于同一个网络当中。其底层实现是利用了Docker内置的DNS服务器,为每个容器提供DNS解析功能。
每个启动时使用了--name参数的Swarm服务或者独立的容器,都会将自己的名称和IP地址注册到Docker DNS服务。这意味着容器和服务副本可以通过Docker DNS服务互相发现。
示例:

Swarm支持两种服务发布模式,两种模式均保证服务从集群外可访问。通过Ingress模式发布的服务,可以保证从Swarm集群内任一节点(即使没有运行服务的副本)都能访问该服务;以Host模式发布的服务只能通过运行服务副本的节点来访问。
不能使用简单格式发布Host模式下的服务。
完整格式如--publish published=5000,target=80,mode=host。该方式采用逗号分隔多个参数,并且逗号前后不允许有空格。


Docker使用Libnetwork实现了基础服务发现功能,同时还实现了服务网格,支持对入站流量实现容器级别负载均衡。

1、VXLAN
Docker使用VXLAN隧道技术创建了虚拟二层覆盖网络。

以太网(veth)适配器接入本地Br0虚拟交换机

卷
在容器中持久化数据的方式推荐采用卷。
Docker卷挂载到容器的/code目录

创建一个卷: docker volume create myvol
默认情况下,Docker创建新卷时采用内置的local驱动。恰如其名,本地卷只能被所在节点的容器使用。使用-d参数可以指定不同的驱动。

块存储:相对性能更高,适用于对小块数据的随机访问负载。目前支持Docker卷插件的块存储例子包括HPE 3PAR、Amazon EBS以及OpenStack块存储服务(Cinder)。
文件存储:包括NFS和SMB协议的系统,同样在高性能场景下表现优异。支持Docker卷插件的文件存储系统包括NetApp FAS、Azure文件存储以及Amazon EFS。
对象存储:适用于较大且长期存储的、很少变更的二进制数据存储。通常对象存储是根据内容寻址,并且性能较低。支持Docker卷驱动的例子包括Amazon S3、Ceph以及Minio。
此外,还可以通过在Dockerfile中使用VOLUME指令的方式部署卷。具体的格式为VOLUME <container-mount-point。但是,在Dockerfile中无法指定主机目录。这是因为主机目录通常情况下是相对主机的一个目录,意味着这个目录在不同主机间会变化,并且可能导致构建失败。
在集群节点间共享存储
数据损坏: 容器A为了提高速度并没有真实的将数据写入,而且写入到了缓存中等待后续慢慢写入;而容器B已经将数据写入了,这时候,两个容器都认为自己已经将数据写入卷中,但是Node2的容器B对A的情况是不知道的,就造成了数据损坏。

Docker Stack
Stack能够在单个声明文件中定义复杂的多服务应用。Stack还提供了简单的方式来部署应用并管理其完整的生命周期:初始化部署 > 健康检查 > 扩容 > 更新 > 回滚,以及其他功能!
步骤: 在Compose文件中定义应用,然后通过docker stack deploy命令完成部署和管理。
示例程序的目录:

1、网络

该文件中定义了3个网络:front-tier、back-tier以及payment。默认情况下,这些网络都会采用overlay驱动,新建对应的覆盖类型的网络。但是payment网络比较特殊,需要数据层加密。
如果需要加密数据层,有两种选择。
在docker network create命令中指定-o encrypted参数。
在Stack文件中的driver_opts之下指定encrypted:'yes'。
2、密钥
密钥属于顶级对象,在当前Stack文件中定义了4个。

4个密钥都被定义为external。这意味着在Stack部署之前,这些密钥必须存在。
在应用部署时按需创建密钥也是可以的,只需要将file: <filename>替换为external: true。但该方式生效的前提是,需要在主机文件系统的对应路径下有一个文本文件,其中包含密钥所需的值,并且是未加密的。这种方式存在明显的安全隐患。
3、服务
部署中的主要操作都在服务这个环节。每个服务都是一个JSON集合(字典),其中包含了一系列关键字。
完整的示例程序文件:
示例服务:

image关键字是服务对象中唯一的必填项。
Docker Stack和Docker Compose的一个区别是,Stack不支持构建。这意味着在部署Stack之前,所有镜像必须提前构建完成。
secret关键字中定义了两个密钥:revprox_cert以及revprox_key。这两个密钥必须在顶级关键字secrets下定义,并且必须在系统上已经存在。
networks关键字确保服务所有副本都会连接到front-tier网络。网络相关定义必须位于顶级关键字networks之下,如果定义的网络不存在,Docker会以Overlay网络方式新建一个网络。
部署约束是一种拓扑感知定时任务,是一种很好的优化调度选择的方式。Swarm目前允许通过如下几种方式进行调度。
节点ID,如node.id==o2p4kw2uuw2a。
节点名称,如node.hostname==wrk-12。
节点角色,如node.role!=manager。
节点引擎标签,如engine.labels.operatingsystem==ubuntu16.04。
节点自定义标签,如node.labels.zone==prod1。
部署应用

部署命令: docker stack deploy -c docker-stack.yml seastack
可以运行docker network ls以及docker service ls命令来查看应用的网络和服务情况。
网络是先于服务创建的。这是因为服务依赖于网络,所以网络需要在服务启动前创建。
Docker将Stack名称附加到由他创建的任何资源名称前作为前缀。在本例中,Stack名为seastack,所以所有资源名称的格式都如:seastack_<resource>。例如,payment网络的名称是seastack_payment。而在部署之前创建的资源则没有被重命名,比如密钥。
另一个需要注意的点是出现了新的名为seastack_default的网络。该网络并未在Stack文件中定义,那为什么会创建呢?每个服务都需要连接到网络,但是visualizer服务并没有指定具体的网络。因此,Docker创建了名为seastack_default的网络,并将visualizer连接到该网络。
读者可以通过两个命令来确认当前Stack的状态。docker stack ls列出了系统中全部Stack,包括每个Stack下面包含多少服务。docker stack ps <stack-name>针对某个指定Stack展示了更详细的信息,例如期望状态以及当前状态。
管理应用:
Stack是由普通的Docker资源构建而来:网络、卷、密钥、服务等。这意味着可以通过普通的Docker命令对其进行查看和重新配置,例如docker network、docker volume、docker secret、docker service等。
推荐方式是通过声明式方式修改,即将Stack文件作为配置的唯一声明。这样,所有Stack相关的改动都需要体现在Stack文件中,然后更新重新部署应用所需的Stack文件。所有应用/Stack都应采用该方式进行更新。所有的变更都应该通过Stack文件进行声明,然后通过docker stack deploy进行部署。
安全
安全本质就是分层!通俗地讲,拥有更多的安全层,就能拥有更多的安全性。而Docker提供了很多安全层。

Docker Swarm模式:默认是开启安全功能的。无须任何配置,就可以获得加密节点ID、双向认证、自动化CA配置、自动证书更新、加密集群存储、加密网络等安全功能。
Docker内容信任(Docker Content Trust, DCT):允许用户对镜像签名,并且对拉取的镜像的完整度和发布者进行验证。
Docker安全扫描(Docker Security Scanning):分析Docker镜像,检查已知缺陷,并提供对应的详细报告。
Docker密钥:使安全成为Docker生态系统中重要的一环。Docker密钥存储在加密集群存储中,在容器传输过程中实时解密,使用时保存在内存文件系统,并运行了一个最小权限模型。
Linux安全技术。Namespace。Control Group(自定义设置共享资源)。Capability(选择容器运行所所需的root用户权限)。MAC。Seccomp。
Docker平台安全技术。Swarm模式。Docker安全扫描(镜像的二进制扫描)。Docker内容信任机制(镜像的完整性和发布者)。Docker密钥(通过docker secret子命令来管理密钥,可以通过在运行docker service create命令时附加--secret,从而为某个服务指定密钥)。
每个优秀的容器平台都应该使用命名空间和控制组技术来构建容器。
Docker容器是由各种命名空间组合而成的。再次强调一遍,Docker容器本质就是命名空间的有组织集合。

Swarm模式的安全配置: 加密节点ID。基于TLS的认证机制。安全准入令牌。支持周期性证书自动更新的CA配置。加密集群存储(配置DB)。加密网络。
向某个现存的Swarm中加入管理者和工作者所需的唯一凭证就是准入令牌。
令牌格式: PREFIX - VERSION - SWARM ID - TOKEN。
准入令牌保存在集群配置的数据库中,默认是加密的。
相关文章:
Docker的深入浅出
目录 Docker引擎 Docker镜像 (镜像由多个层组成,每层叠加之后,从外部看来就如一个独立的对象。镜像内部是一个精简的操作系统(OS),同时还包含应用运行所必须的文件和依赖包) Docker容器 应用容器化--Docker化 最佳…...

内存映射工作原理和适用场景
Linux 内存映射(Memory Mapping)是一种将文件或其他资源直接映射到进程虚拟内存地址空间的机制,允许进程像访问内存一样访问文件或设备。这种机制通过 mmap() 系统调用实现,常用于高效文件操作、进程间共享内存等场景。 1. 内存映…...

【Nginx + Keepalived 实现高可用的负载均衡架构】
使用 Nginx Keepalived 可以实现高可用的负载均衡架构,确保在某个 Nginx 节点故障时,自动将流量转移到备用节点。以下是详细的实现步骤: 1. 架构概述 Nginx:作为负载均衡器,将流量分发到后端服务器。Keepalived&…...

自动驾驶超声波雷达:市场潜力爆发,引领未来出行新趋势
在自动驾驶技术的飞速发展中,自动驾驶超声波雷达作为一项关键技术,正逐渐崭露头角,其重要性及市场增长潜力不容忽视。本文将深入探讨自动驾驶超声波雷达的重要性、市场增长趋势、显著优势、全球市场规模与驱动因素、主要市场参与者以及不同地…...
)
Apache服务器的基础配置(认证考试笔记)
Apache服务器的基本配置 配置Apache服务器,有如下需求: 不能修改Apache默认配置文件建立虚拟主机www.test.com,端口80将URLwww.test.com/data的请求引至目录/web/database,将URL www.test.com/img的请求导至目录/web/imagesweb/…...

41.兼职网站管理系统(基于springbootvue的Java项目)
目录 1.系统的受众说明 2.相关技术 2.1 B/S架构 2.2 Java技术介绍 2.3 mysql数据库介绍 2.4 Spring Boot框架 3.系统分析 3.1 需求分析 3.2 系统可行性分析 3.2.1技术可行性:技术背景 3.2.2经济可行性 3.2.3操作可行性: 3.3 项目设计目…...

Linux ARM64 将内核虚拟地址转化为物理地址
文章目录 前言一、通用方案1.1 kern_addr_valid1.2 __pa 二、ARM64架构2.1 AT S1E1R2.2 is_kernel_addr_vaild2.3 va2pa_helper 三、demo演示参考资料 前言 本文介绍一种通用的将内核虚拟地址转化为物理地址的方案以及一种适用于ARM64 将内核虚拟地址转化为物理地址的方案&…...
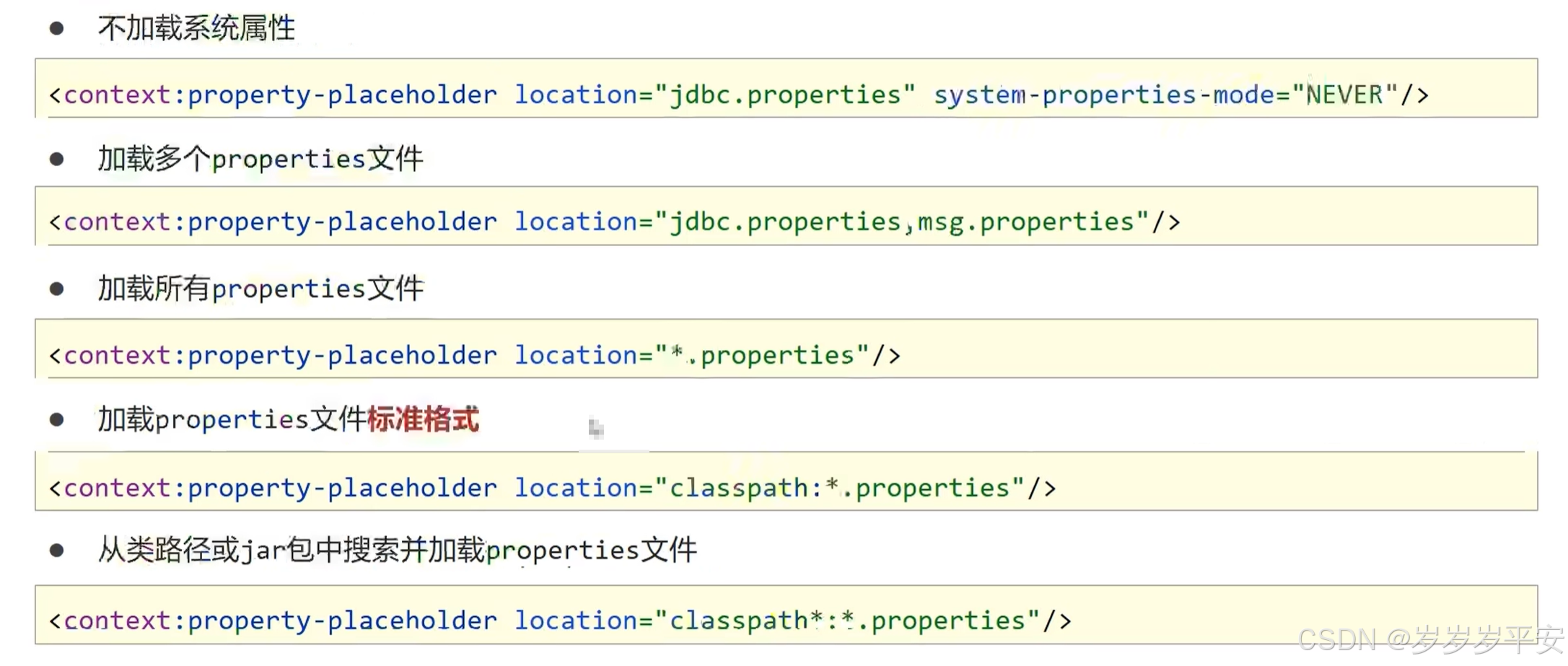
spring学习(使用spring加载properties文件信息)(spring自定义标签引入)
目录 一、博客引言。 二、基本配置准备。 (1)初步分析。 (2)初始spring配置文件。 三、spring自定义标签的引入。 (1)基本了解。 (2)引入新的命名空间:xmlns:context。 &…...

Flutter项目试水
1基本介绍 本文章在构建您的第一个 Flutter 应用指导下进行实践 可作为项目实践的辅助参考资料 Flutter 是 Google 的界面工具包,用于通过单一代码库针对移动设备、Web 和桌面设备构建应用。在此 Codelab 中,您将构建以下 Flutter 应用。 该应用可以…...

Linux(Ubuntu)安装pyenv和pyenv-virtualenv
Ubuntu安装pyenv和pyenv-virtualenv 安装 pyenv1. 下载 pyenv2. 配置环境变量3. 重启 Shell4. 安装依赖5.检测是否安装成功 安装 pyenv-virtualenv1. 安装 pyenv-virtualenv2. 配置环境变量3. 重启 Shell pyenv 的使用1. 查看可安装的 Python 版本2. 安装指定版本的 Python3. 查…...

调用DeepSeek官方的API接口
效果 前端样式体验链接:https://livequeen.top/deepseekshow 准备工作 1、注册deepseek官网账号 地址:DeepSeek 点击进入右上角【API开放平台】,并进行账号注册。 2、注册完成后,依次点击【API keys】-【生成API key】&#x…...

MFC线程安全案例
作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 目录 一、项目解析 二…...

【Elasticsearch】bucket_sort
Elasticsearch 的bucket_sort聚合是一种管道聚合,用于对父多桶聚合(如terms、date_histogram、histogram等)的桶进行排序。以下是关于bucket_sort的详细说明: 1.基本功能 bucket_sort聚合可以对父聚合返回的桶进行排序ÿ…...

计算机毕业设计——Springboot点餐平台网站
📘 博主小档案: 花花,一名来自世界500强的资深程序猿,毕业于国内知名985高校。 🔧 技术专长: 花花在深度学习任务中展现出卓越的能力,包括但不限于java、python等技术。近年来,花花更…...

MATLAB中count函数用法
目录 语法 说明 示例 对出现次数计数 使用模式对数字和字母进行计数 多个子字符串的所有出现次数 忽略大小写 对字符向量中的子字符串进行计数 count函数的功能是计算字符串中模式的出现次数。 语法 A count(str,pat) A count(str,pat,IgnoreCase,true) 说明 A c…...

Win11下搭建Kafka环境
目录 一、环境准备 二、安装JDK 1、下载JDK 2、配置环境变量 3、验证 三、安装zookeeper 1、下载Zookeeper安装包 2、配置环境变量 3、修改配置文件zoo.cfg 4、启动Zookeeper服务 4.1 启动Zookeeper客户端验证 4.2 启动客户端 四、安装Kafka 1、下载Kafka安装包…...

51c自动驾驶~合集49
我自己的原文哦~ https://blog.51cto.com/whaosoft/13164876 #Ultra-AV 轨迹预测新基准!清华开源:统一自动驾驶纵向轨迹数据集 自动驾驶车辆在交通运输领域展现出巨大潜力,而理解其纵向驾驶行为是实现安全高效自动驾驶的关键。现有的开…...

nexus部署及配置https访问
1. 使用docker-compose部署nexus docker-compose-nexus.yml version: "3" services:nexus:container_name: my-nexusimage: sonatype/nexus3:3.67.1hostname: my-nexusnetwork_mode: hostports:- 8081:8081deploy:resources:limits:cpus: 4memory: 8192Mreservations…...

ffmpeg -hwaccels
1. ffmpeg -hwaccels -loglevel quiet 显示ffmpeg支持的硬件设备 2. 输出 Hardware acceleration methods: vdpau cuda vaapi qsv drm opencl 3. 说明 输出中的cuda表示ffmpeg支持Nvidia 硬件设备。编译ffmpeg增加相关硬件设备的配置,输出会显示相应的信…...

Python——批量图片转PDF(GUI版本)
目录 专栏导读1、背景介绍2、库的安装3、核心代码4、完整代码总结专栏导读 🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手 🏳️🌈 博客主页:请点击——> 一晌小贪欢的博客主页求关注 👍 该系列文章专栏:请点击——>Python办公自动化专…...

LabVIEW无人机飞行状态监测系统
近年来,无人机在农业植保、电力巡检、应急救灾等多个领域得到了广泛应用。然而,传统的目视操控方式仍然存在以下三大问题: 飞行姿态的感知主要依赖操作者的经验; 飞行中突发的姿态异常难以及时发现; 飞行数据缺乏系统…...

算法16(力扣451)——根据字符出现频率排序
1、问题 给定一个字符串 s ,根据字符出现的 频率 对其进行 降序排序 。一个字符出现的频率 是它出现在字符串中的次数, 返回 已排序的字符串。如果有多个答案,返回其中任何一个。 2、示例 (1) 输入: s "tree&q…...

Response 和 Request 介绍
怀旧网个人博客网站地址:怀旧网,博客详情:Response 和 Request 介绍 1、HttpServletResponse 1、简单分类 2、文件下载 通过Response下载文件数据 放一个文件到resources目录 编写下载文件Servlet文件 public class FileDownServlet exten…...

ADB详细教程
目录 一、ADB简介 二、配置 配置环境变量 验证是否安装成功 三、简单使用 基本命令 设备连接管理 USB连接 WIFI连接(需要USB线) 开启手机USB调试模式 开启USB调试 四、其他 更换ADB默认启动端口 一、ADB简介 ADB(Android Debug…...

Jenkins+gitee 搭建自动化部署
Jenkinsgitee 搭建自动化部署 环境说明: 软件版本备注CentOS8.5.2111JDK1.8.0_211Maven3.8.8git2.27.0Jenkins2.319最好选稳定版本,不然安装插件有点麻烦 一、安装Jenkins程序 1、到官网下载相应的版本war或者直接使用yum安装 Jenkins官网下载 直接…...
)
今日AI和商界事件(2025-02-11)
今日AI大事件主要包括以下几个方面: 一、行业竞购与合作变动 马斯克组团竞购OpenAI 据《华尔街日报》报道,马斯克率投资者财团出价974亿美元竞购OpenAI,欲使其回归开源公益使命。xAI支持此次竞购,若成功,xAI或与OpenA…...

oracle dbms_sqltune 使用
创建测试表 CREATE TABLE test_table (id NUMBER PRIMARY KEY,event_date DATE,value NUMBER );插入测试数据 DECLAREi NUMBER; BEGINFOR i IN 1..1000000 LOOPINSERT INTO test_table (id, event_date, value)VALUES (i, SYSDATE - MOD(i, 365), DBMS_RANDOM.VALUE(1, 1000)…...

大前端之前端开发接口测试工具postman的使用方法-简单get接口请求测试的使用方法-简单教学一看就会-以实际例子来说明-优雅草卓伊凡
大前端之前端开发接口测试工具postman的使用方法-简单get接口请求测试的使用方法-简单教学一看就会-以实际例子来说明-优雅草卓伊凡 背景 前端开发接口请求,调试,联调,接入数据,前端必不可少工具,postman是一个非常好…...

AI大语言模型
一、AIGC和生成式AI的概念 1-1、AIGC Al Generated Content:AI生成内容 1-2、生成式AI:generative ai AIGC是生成式 AI 技术在内容创作领域的具体应用成果。 目前有许多知名的生成式 AI: 文本生成领域 OpenAI GPT 系列百度文心一言阿里通…...

数智百问 | 制造企业如何降低产线检测数据的存储和管理成本?
在《“十四五”智能制造发展规划》等政策的推动下,以及新能源汽车、消费电子等品牌商对产品质量和供应商智能化水平要求的提升,半导体、电子制造、动力电池等先进制造行业企业纷纷推进产线智能化升级,并投入大量机器视觉检测设备以实现自动化…...