DeepSeek-R1复现方案梳理
open-r1
项目地址:https://github.com/huggingface/open-r1
由huggingface组建,目前刚上线2周,发布了最新进展open-r1/update-1,在MATH-500任务上接近deepseek的指标,可以在open-r1/open-r1-eval-leaderboard查看指标的排行榜。

mini-deepseek-r1
项目地址:https://github.com/philschmid/deep-learning-pytorch-huggingface/blob/main/training/mini-deepseek-r1-aha-grpo.ipynb
用 GRPO 和倒计时游戏复制出一个简单版本的 R1。
在大约 50 步时,模型学会了正确的格式,即…\n…;在 100 步时,解方程的成功率约为 25%,并且模型开始用文字进行 “推理”;在 200 步时,收敛变慢,成功率约为 40%。模型开始学习一种新的“格式”,它通过尝试不同的组合并检查结果来解方程,这种方式类似于编程解决问题的方式;在 450 步时,解方程的成功率为 50%,性能仍然在缓慢提升,并且模型保持了从 200 步开始的新格式。

open-thoughts
项目地址:https://github.com/open-thoughts/open-thoughts
该项目目标是策划一个推理数据集来训练最先进的小型推理模型,该模型在数学和代码推理基准上超越DeepSeek-R1-Distill-Qwen-32B和DeepSeek-R1-Distill-Qwen-7B 。

TinyZero
项目地址:https://github.com/Jiayi-Pan/TinyZero
干净、简约、易于访问的 DeepSeek R1-Zero 复制品
TinyZero 是DeepSeek R1 Zero在倒计时和乘法任务中的复刻版。我们以veRL为基础进行构建。通过强化学习,3B 基础 LM 可以自行开发自我验证和搜索能力只需不到 30 美元,就可以亲身体验 Ahah 时刻。
simpleRL-reason
项目地址:https://github.com/hkust-nlp/simpleRL-reason
这是 DeepSeek-R1-Zero 和 DeepSeek-R1 在数据有限的小模型上进行训练的复制品
这个 repo 包含一个简单的强化学习方法,用于提高模型的推理能力。它很简单,因为只使用了基于规则的奖励,该方法与DeepSeek-R1中使用的方法几乎相同,只是代码当前使用的是 PPO 而不是 GRPO。我们已经使用此代码在有限的数据(8K 示例)上训练小型模型(7B),取得了令人惊讶的强劲结果 - 例如,从 Qwen2.5-Math-7B(基础模型)开始,我们直接在其上执行 RL。没有 SFT,没有奖励模型,只有 8K MATH 示例用于验证,结果模型在 AIME 上实现 (pass@1) 33.3%、在 AMC 上实现 62.5%、在 MATH 上实现 77.2%,优于 Qwen2.5-math-7B-instruct,并且可与使用 >50 倍更多数据和更复杂组件的以前基线相媲美。

RAGEN
项目地址:https://github.com/ZihanWang314/RAGEN
RAGEN 是 DeepSeek-R1 在 AGENT 训练上的第一个开源复现版。

RAGEN 是用于训练智能体模型的 DeepSeek-R1 (-Zero) 方法的首次复现,主要在gym-sokoban(传统的推箱子游戏)任务上进行训练。
unsloth-Reasoning - GRPO
项目地址:https://docs.unsloth.ai/basics/reasoning-grpo
使用 GRPO(强化学习微调的一部分)通过 Unsloth 训练自己的 DeepSeek-R1 推理模型。

DeepSeek 的 GRPO(组相对策略优化)是一种无需价值函数模型的强化学习技术,能够高效优化响应并降低内存和计算成本。借助 Unsloth,仅需 7GB VRAM 即可在本地训练高达 15B 参数的推理模型(如 Llama 3.1、Phi-4、Mistral 或 Qwen2.5),而此前类似任务需要 2xA100 GPU(160GB VRAM)。GRPO 现已支持 QLoRA 和 LoRA,可将标准模型转化为成熟的推理模型。测试显示,仅训练 Phi-4 100 步,GRPO 模型已能生成思考 token 并给出正确答案,显著优于未使用 GRPO 的模型。
oat-zero
项目地址:https://github.com/sail-sg/oat-zero
DeepSeek-R1-Zero 的轻量级复制品,对自我反思行为进行了深入分析。
DeepSeek-R1-Zero 最鼓舞人心的结果之一是通过纯强化学习 (RL) 实现**“顿悟时刻”**。在顿悟时刻,模型会学习自我反思等新兴技能,这有助于它进行情境搜索来解决复杂的推理问题。
在 R1-Zero 发布后的短短几天内,多个项目在较小规模(例如 1B 到 7B)上独立“复现”了类似 R1-Zero 的训练,并且都观察到了 Aha 时刻,这通常通过模型响应长度的突然增加来衡量。按照他们的设置仔细检查了类似 R1-Zero 的训练过程,并分享了以下发现:
- 在类似 R1-Zero 的训练中,可能不存在顿悟时刻。相反,发现顿悟时刻(例如自我反思模式)出现在第 0 个时期,即基础模型中。
- 从基础模型的反应中发现了肤浅的自我反思(SSR),在这种情况下自我反思并不一定会导致正确的最终答案。
- 通过 RL 仔细研究了类似 R1-Zero 的训练,发现响应长度增加的现象不是由于自我反思的出现,而是 RL 优化精心设计的基于规则的奖励函数的结果。

deepscaler
项目地址:https://github.com/agentica-project/deepscaler
只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。
第一步,研究人员会训练模来型进行短思考。他们使用DeepSeek的GRPO方法,设定了8k的上下文长度来训练模型,以鼓励高效思考。
经过1000步训练后,模型的token使用量减少了3倍,并比基础模型提升了5%。接下来,模型被训练进行长思考。强化学习训练扩展到16K和24K token,以解决更具挑战性、以前未解决的问题。随着响应长度增加,平均奖励也随之提高,24K的魔力,就让模型最终超越了o1-preview!

近日,来自UC伯克利的研究团队基于Deepseek-R1-Distilled-Qwen-1.5B,通过简单的强化学习(RL)微调,得到了全新的DeepScaleR-1.5B-Preview。在AIME2024基准中,模型的Pass@1准确率达高达43.1% ——不仅比基础模型提高了14.3%,而且在只有1.5B参数的情况下超越了OpenAI o1-preview!

grpo_demo
项目地址:https://gist.github.com/willccbb/4676755236bb08cab5f4e54a0475d6fb
原始的 grpo_demo.py 帖子
下面直接奉上源码:
# train_grpo.py
import re
import torch
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig
from trl import GRPOConfig, GRPOTrainer# Load and prep datasetSYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""XML_COT_FORMAT = """\
<reasoning>
{reasoning}
</reasoning>
<answer>
{answer}
</answer>
"""def extract_xml_answer(text: str) -> str:answer = text.split("<answer>")[-1]answer = answer.split("</answer>")[0]return answer.strip()def extract_hash_answer(text: str) -> str | None:if "####" not in text:return Nonereturn text.split("####")[1].strip().replace(",", "").replace("$", "")# uncomment middle messages for 1-shot prompting
def get_gsm8k_questions(split = "train") -> Dataset:data = load_dataset('openai/gsm8k', 'main')[split] # type: ignoredata = data.map(lambda x: { # type: ignore'prompt': [{'role': 'system', 'content': SYSTEM_PROMPT},#{'role': 'user', 'content': 'What is the largest single-digit prime number?'},#{'role': 'assistant', 'content': XML_COT_FORMAT.format(# reasoning="9 is divisble by 3 and 8 is divisible by 2, but 7 is prime.",# answer="7"#)},{'role': 'user', 'content': x['question']}],'answer': extract_hash_answer(x['answer'])}) # type: ignorereturn data # type: ignoredataset = get_gsm8k_questions()# Reward functions
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:responses = [completion[0]['content'] for completion in completions]q = prompts[0][-1]['content']extracted_responses = [extract_xml_answer(r) for r in responses]print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]def int_reward_func(completions, **kwargs) -> list[float]:responses = [completion[0]['content'] for completion in completions]extracted_responses = [extract_xml_answer(r) for r in responses]return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]def strict_format_reward_func(completions, **kwargs) -> list[float]:"""Reward function that checks if the completion has a specific format."""pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"responses = [completion[0]["content"] for completion in completions]matches = [re.match(pattern, r) for r in responses] return [0.5 if match else 0.0 for match in matches]def soft_format_reward_func(completions, **kwargs) -> list[float]:"""Reward function that checks if the completion has a specific format."""pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"responses = [completion[0]["content"] for completion in completions]matches = [re.match(pattern, r) for r in responses] return [0.5 if match else 0.0 for match in matches]def count_xml(text) -> float:count = 0.0if text.count("<reasoning>\n") == 1:count += 0.125if text.count("\n</reasoning>\n") == 1:count += 0.125if text.count("\n<answer>\n") == 1:count += 0.125count -= len(text.split("\n</answer>\n")[-1])*0.001if text.count("\n</answer>") == 1:count += 0.125count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001return countdef xmlcount_reward_func(completions, **kwargs) -> list[float]:contents = [completion[0]["content"] for completion in completions]return [count_xml(c) for c in contents]#model_name = "meta-llama/Llama-3.2-1B-Instruct"
model_name = "Qwen/Qwen2.5-1.5B-Instruct"if "Llama" in model_name:output_dir = "outputs/Llama-1B-GRPO"run_name = "Llama-1B-GRPO-gsm8k"
else:output_dir="outputs/Qwen-1.5B-GRPO"run_name="Qwen-1.5B-GRPO-gsm8k"training_args = GRPOConfig(output_dir=output_dir,run_name=run_name,learning_rate=5e-6,adam_beta1 = 0.9,adam_beta2 = 0.99,weight_decay = 0.1,warmup_ratio = 0.1,lr_scheduler_type='cosine',logging_steps=1,bf16=True,per_device_train_batch_size=1,gradient_accumulation_steps=4,num_generations=16,max_prompt_length=256,max_completion_length=786,num_train_epochs=1,save_steps=100,max_grad_norm=0.1,report_to="wandb",log_on_each_node=False,
)
peft_config = LoraConfig(r=16,lora_alpha=64,target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "up_proj", "down_proj", "gate_proj"],task_type="CAUSAL_LM",lora_dropout=0.05,
)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=torch.bfloat16,attn_implementation="flash_attention_2",device_map=None
).to("cuda")tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token# use peft at your own risk; not working for me with multi-GPU training
trainer = GRPOTrainer(model=model,processing_class=tokenizer,reward_funcs=[xmlcount_reward_func,soft_format_reward_func,strict_format_reward_func,int_reward_func,correctness_reward_func],args=training_args,train_dataset=dataset,#peft_config=peft_config
)
trainer.train()
数据集
- open-r1/OpenR1-Math-220k:OpenR1-Math-220k 是一个大规模数学推理数据集,包含 220k 道数学题,每道题都有DeepSeek R1针对 NuminaMath 1.5 中的问题生成的 2 到 4 条推理痕迹。
- OpenThoughts-114k:拥有 114,000 个高质量示例,涵盖数学、科学、代码和谜题等。
- bespokelabs/Bespoke-Stratos-17k:对伯克利 Sky-T1 数据的复制,使用 DeepSeek-R1 创建了一个包含问题、推理过程和答案的数据集。
- R1-Distill-SFT:目前有 17000 个样本,目的是创建数据以支持 Open-R1 项目。
- cognitivecomputations/dolphin-r1:包含 80 万个样本的数据集,其中的数据来自 DeepSeek-R1 和 Gemini flash 的生成结果,同时还有来自 Dolphin chat 的 20 万个样本。
- GSM8K:GSM8K(小学数学 8K)是一个包含 8.5K 道高质量、语言多样化的小学数学应用题的数据集。该数据集的创建是为了支持需要多步推理的基本数学问题的问答任务。
参考资料
- Deepseek R1 最新复现进展
- deepseek-r1开源复现方法整理
相关文章:
DeepSeek-R1复现方案梳理
open-r1 项目地址:https://github.com/huggingface/open-r1 由huggingface组建,目前刚上线2周,发布了最新进展open-r1/update-1,在MATH-500任务上接近deepseek的指标,可以在open-r1/open-r1-eval-leaderboard查看指标的…...

【Redis】 - Redis的Bitmap实现用户签到
Redis的Bitmap实现用户签到 使用Redis的Bitmap数据结构来记录用户的每日签到状态是一种高效且节省空间的方法。通过将用户ID和日期结合生成动态Key,可以轻松管理不同用户在不同日期的签到情况。下面详细介绍如何设计这一方案。 设计思路 动态Key生成:根…...

用php tp6对接钉钉审批流的 table 表格 明细控件 旧版sdk
核心代码 foreach ($flows[product_list] as $k>$gift) {$items_list[] [[name > 商品名称, value > $gift[product_name] ?? ],[name > 规格, value > $gift[product_name] ?? ],[name > 数量, value > $gift[quantity] ?? ],[name > 单位, v…...

使用DeepSeek建立一个智能聊天机器人0.07
进一步完善获取API密钥和DeepSeek的API端点,我们可以添加更多的错误处理和默认值设置,确保程序在各种情况下都能正常运行。同时,我们还可以提供一个更友好的用户界面,以便用户可以轻松地设置和查看配置信息。 以下是进一步完善的…...

PySpark查找Dataframe中的非ASCII字符并导出Excel文件
from pyspark.sql import SparkSession from pyspark.sql.types import StringType from pyspark.sql.functions import udf, col from pyspark.sql.types import BooleanType import pandas as pd# 初始化Spark会话 spark SparkSession.builder.appName("StringFilter&q…...

大模型RLHF:PPO原理与源码解读
大模型RLHF:PPO原理与源码解读 原文链接:图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读 本文直接从一个RLHF开源项目源码入手(deepspeed-chat),根据源码的实现细节,给出尽可能丰富的训…...

SQLite 数据库:优点、语法与快速入门指南
文章目录 一、引言二、SQLite 的优点 💯三、SQLite 的基本语法3.1 创建数据库3.2 创建表3.3 插入数据3.4 查询数据3.5 更新数据3.6 删除数据3.7 删除表 四、快速入门指南4.1 安装 SQLite4.2 创建数据库4.3 创建表4.4 插入数据4.5 查询数据4.6 更新数据4.7 删除数据4…...

pytorch笔记:mm VS bmm
1 bmm (batch matrix multiplication) 批量矩阵乘法,用于同时处理多个矩阵的乘法bmm 的输入是两个 3D 张量(batch of matrices),形状分别为 (batch_size, n, m) 和 (batch_size, m, p)bmm 输出的形状是 (batch_size, n, p) 2 mm…...
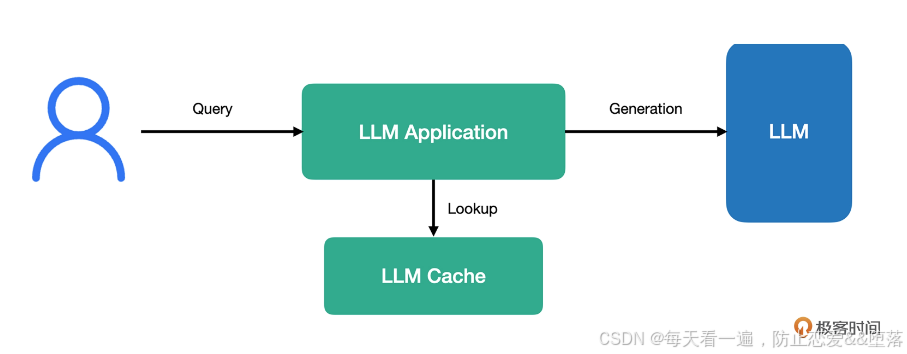
5、大模型的记忆与缓存
文章目录 本节内容介绍记忆Mem0使用 mem0 实现长期记忆 缓存LangChain 中的缓存语义缓存 本节内容介绍 本节主要介绍大模型的缓存思路,通过使用常见的缓存技术,降低大模型的回复速度,下面介绍的是使用redis和mem0,当然redis的语义…...

LangChain系列:LangChain基础入门教程
LangChain 是一个开源框架,旨在简化使用大型语言模型(LLM)创建应用程序的过程。它为链提供了标准接口,与许多其他工具进行了集成,并为常见应用提供了端到端的链。 LangChain 让 AI 开发人员能够基于大型语言模型&#…...

修改docker内容器中的某配置文件的命令
先找到配置文件config.php find / -name "config.php" 2>/dev/null 然后用vi编辑器修改配置文件 vi /var/www/config.php 最后就是vi的基本操作,根据具体需求使用: vi 有两种主要模式: 命令模式:进入 vi 后的默认…...

无人机遥感图像拼接及处理实践技术:生态环境监测、农业、林业等领域,结合图像拼接与处理技术,能够帮助我们更高效地进行地表空间要素的动态监测与分析
近年来,无人机技术在遥感领域的应用越来越广泛,尤其是在生态环境监测、农业、林业等领域,无人机遥感图像的处理与分析成为了科研和业务化工作中的重要环节。通过无人机获取的高分辨率影像数据,结合图像拼接与处理技术,…...

基于Springmvc+MyBatis+Spring+Bootstrap+EasyUI+Mysql的个人博客系统
基于SpringmvcMyBatisSpringBootstrapEasyUIMysql的个人博客系统 1.项目介绍 使用Maven3Spring4SpringmvcMybatis3架构;数据库使用Mysql,数据库连接池使用阿里巴巴的Druid;使用Bootstrap3 UI框架实现博客的分页显示,博客分类&am…...

Vision Transformer:打破CNN垄断,全局注意力机制重塑计算机视觉范式
目录 引言 一、ViT模型的起源和历史 二、什么是ViT? 图像处理流程 图像切分 展平与线性映射 位置编码 Transformer编码器 分类头(Classification Head) 自注意力机制 注意力图 三、Coovally AI模型训练与应用平台 四、ViT与图像…...

Tailwind CSS 的核心理念
实用优先(Utility-First) Tailwind CSS 的最核心理念是"实用优先"。这种方法颠覆了传统的 CSS 开发方式,不再编写自定义的类名和样式规则,而是通过组合预定义的工具类来构建界面。这种方式带来了以下优势: …...

软考高级《系统架构设计师》知识点(二)
操作系统知识 操作系统概述 操作系统定义:能有效地组织和管理系统中的各种软/硬件资源,合理地组织计算机系统工作流程,控制程序的执行,并且向用户提供一个良好的工作环境和友好的接口。操作系统有三个重要的作用: 管理…...

DeepSeek的魔法:如何让复杂概念变得通俗易懂?
日常生活中,常常会被复杂的概念所困扰。怎么样将这些晦涩难懂的概念变得通俗易懂?当然是利用大模型帮我们解答,不过让大模型解答也需要有好的沟通提示词。 我收集整理了 2 套提示词,大家一起学习一下。 一、用推理模型解释概…...

地弹噪声【信号完整性】
地弹、振铃、串扰、信号反射 地弹,就是地噪声! 低频时,地噪声主要是因为构成地线的导体有“电阻”,电路系统的电流都要流经地线而产生的电势差波动。 高频时,地噪声主要是因为构成地线的导体有“电感”,电路系统的电流快速变化地经过这个“电感”时,“电感”两端激发…...

【大模型】阿里云百炼平台对接DeepSeek-R1大模型使用详解
目录 一、前言 二、DeepSeek简介 2.1 DeepSeek 是什么 2.2 DeepSeek R1特点 2.2.1 DeepSeek-R1创新点 2.3 DeepSeek R1应用场景 2.4 与其他大模型对比 三、阿里云百炼大平台介绍 3.1 阿里云百炼大平台是什么 3.2 阿里云百炼平台主要功能 3.2.1 应用场景 3.3 为什么选…...

如何在 React 中使用 CSS Modules?
在 React 中使用 CSS Modules 是一种模块化 CSS 的方式,可以避免类名冲突,并为每个组件提供独立的样式。以下是如何在 React 项目中使用 CSS Modules 的步骤: 1. 创建 React 应用 如果你还没有创建一个 React 应用,可以使用 Create React App: npx create-react-app my…...

技术革新让生活更便捷
量子通信是一种利用量子力学原理进行信息传递的技术。它的基本原理是量子纠缠和量子密钥分发。量子纠缠指两个粒子即使相隔很远,一个粒子的状态改变会立刻引起另一个粒子状态的相应变化。量子密钥分发则是通过量子态传输实现加密密钥的安全交换。 在信息安全领域&a…...

但书条款与格式条款
但书条款与格式条款 一、定义 但书条款: 但书条款是指在法律条文中,对一般规定作出例外或补充说明的条款。通常以“但”字开头,表示在特定情况下不适用一般规定。例如,《民法典》第465条第二款规定:“依法成立的合同…...

相似性图相关性重构网络用于无监督跨模态哈希
《Similarity Graph-correlation Reconstruction Network for unsupervised cross-modal hashing》 摘要1. 引言2. 相关工作2.1. 监督跨模态哈希方法2.2. 无监督跨模态哈希方法 3. 方法论3.1 问题定义3.2 特征提取3.3 模态内关系图构建3.4. 局部关系图重置3.5. 跨模态关系图构建…...

问卷数据分析|SPSS实操之单因素方差分析
适用条件: 检验分类变量和定量变量之间的差异 分类变量数量要大于等于三 具体操作: 1.选择分析--比较平均值--单因素ANOVA检验 2. 下方填分类变量,上方为各个量表数据Z1-Y2 3. 点击选项,选择描述和方差齐性检验 4.此处为结果数…...

并发编程---多线程不安全示例以及解决,多线程创建方式
文章目录 并发并行多线程为什么需要多线程线程不安全示例并发出现问题的根源: 并发三要素可见性: CPU 缓存引起原子性:分时复用引起有序性: 重排序引起 线程不安全示例的解决方法使用AtomicLong类使用synchronized 关键字 改进代码避免不必要的延迟join()方法为什么…...

多模态模型详解
多模态模型是什么 多模态模型是一种能够处理和理解多种数据类型(如文本、图像、音频、视频等)的机器学习模型,通过融合不同模态的信息来提升任务的性能。其核心在于利用不同模态之间的互补性,增强模型的鲁棒性和准确性。 如何融合…...

从零到一:开发并上线一款极简记账本小程序的完整流程
从零到一:开发并上线一款极简记账本小程序的完整流程 目录 前言需求分析与功能设计 2.1 目标用户分析2.2 核心功能设计2.3 技术栈选择 开发环境搭建 3.1 微信开发者工具安装与配置3.2 项目初始化3.3 版本控制与协作工具 前端开发 4.1 页面结构与布局4.2 组件化开发…...

更加通用的Hexo多端部署原理及实现,适用于各种系统之间
本文推荐在作者的个人博客网站阅读:shenying.online 一、故事背景 故事发生在大学上学期间(而不是寒假)。上学期间,宿舍条件极其恶劣,半夜断电、空间狭小。我们大学垃圾条件使用游戏本的种种弊端被无限放大࿱…...

5g基站测试要求和关键点
5G基站的测试要求涉及多个方面,以确保其性能、覆盖能力、稳定性和合规性。以下是5G基站测试的主要要求和关键点: 一、基础性能测试 射频(RF)性能测试 发射机性能:验证基站的发射功率、频率误差、调制质量(E…...

算法——搜索算法:原理、类型与实战应用
搜索算法:开启高效信息检索的钥匙 在信息爆炸的时代,搜索算法无疑是计算机科学领域中熠熠生辉的存在,它就像一把神奇的钥匙,为我们打开了高效信息检索的大门。无论是在日常生活中,还是在专业的工作场景里,…...