【Elasticsearch】match查询
Elasticsearch 的`match`查询是全文搜索中最常用和最强大的查询类型之一。它允许用户在指定字段中搜索文本、数字、日期或布尔值,并提供了丰富的功能来控制搜索行为和结果。以下是`match`查询的详细解析,包括其工作原理、参数配置和使用场景。
1.`match`查询的基本概念
`match`查询是 Elasticsearch 中用于执行全文搜索的标准查询方式。它通过分析器(Analyzer)对查询文本进行处理,然后在指定字段中搜索匹配的文档。`match`查询的主要特点是它能够处理复杂的文本数据,并提供灵活的搜索选项。
2.`match`查询的工作原理
`match`查询的工作过程可以分为以下几个步骤:
2.1 文本分析
查询文本首先会被分析器处理,分析器会将查询文本分解为一系列的词元(Tokens)。分析器通常包括以下几个部分:
• 分词器(Tokenizer):将文本分解为词元。
• 过滤器(Token Filters):对词元进行进一步处理,如小写化、停用词过滤、词干提取等。
• 字符过滤器(Character Filters):对原始文本进行预处理,如删除HTML标签、替换特殊字符等。
2.2 构建布尔查询
分析器处理后的词元会被用来构建一个布尔查询(`boolean query`)。布尔查询是`match`查询的核心,它通过布尔逻辑(`AND`或`OR`)来组合多个词元的匹配条件。
• `operator`参数:
• `OR`(默认值):文档中包含查询词中的任意一个词元即可匹配。
• `AND`:文档中必须包含查询词中的所有词元才能匹配。
2.3 模糊匹配(可选)
如果启用了模糊匹配(通过`fuzziness`参数),Elasticsearch 会为每个词元生成模糊变体,并尝试匹配这些变体。模糊匹配允许一定程度的拼写错误或相似性匹配。
2.4 同义词扩展(可选)
如果字段定义中使用了同义词过滤器(如`synonym_graph`),`match`查询会将查询词扩展为同义词,并尝试匹配这些同义词。
2.5 查询执行
构建好的布尔查询会被执行,Elasticsearch 会搜索索引中的文档,找出匹配的文档。每个文档的相关性分数(`_score`)会根据匹配的词元数量、词频、倒排索引等因素计算得出。
2.6 结果返回
最终,Elasticsearch 会返回匹配的文档列表,以及每个文档的相关性分数。用户可以通过其他参数(如`from`和`size`)来分页显示结果。
3.`match`查询的参数
`match`查询支持多种参数,这些参数可以用来控制查询的行为和结果。以下是一些常用的参数:
3.1`query`(必需)
查询文本,可以是文本、数字、日期或布尔值。
3.2`analyzer`(可选)
用于分析查询文本的分析器。默认情况下,Elasticsearch 使用字段在索引时定义的分析器。如果没有定义分析器,则使用索引的默认分析器。
3.3`operator`(可选)
布尔逻辑,用于组合查询词元:
• `OR`(默认值):文档中包含查询词中的任意一个词元即可匹配。
• `AND`:文档中必须包含查询词中的所有词元才能匹配。
3.4`fuzziness`(可选)
允许的模糊匹配程度,可以是以下值之一:
• `0`:不启用模糊匹配。
• `1`或`2`:允许的编辑距离。
• `AUTO`:自动根据词元长度选择合适的编辑距离。
3.5`prefix_length`(可选)
模糊匹配中不变的前缀字符数量。默认值为`0`。
3.6`max_expansions`(可选)
模糊匹配中生成的最大词元数量。默认值为`50`。
3.7`fuzzy_transpositions`(可选)
是否允许字符置换(如`ab`→`ba`)。默认值为`true`。
3.8`boost`(可选)
用于调整文档相关性分数的提升值。默认值为`1.0`。值越小,相关性分数越低;值越大,相关性分数越高。
3.9`minimum_should_match`(可选)
必须匹配的子句的最小数量。可以是整数(如`3`)或百分比(如`75%`)。
3.10`zero_terms_query`(可选)
如果分析器移除了所有查询词元(如停用词过滤器),是否返回所有文档:
• `none`(默认值):不返回任何文档。
• `all`:返回所有文档,类似于`match_all`查询。
3.11`auto_generate_synonyms_phrase_query`(可选)
是否为多词同义词生成短语查询:
• `true`(默认值):生成短语查询。
• `false`:将多词同义词拆分为独立的词元进行匹配。
4.`match`查询的示例
4.1 基本用法
```json
GET /_search
{
"query": {
"match": {
"message": "this is a test"
}
}
}
```
• 查询字段`message`中包含`"this is a test"`的文档。
4.2 使用`operator`参数
```json
GET /_search
{
"query": {
"match": {
"message": {
"query": "capital of Hungary",
"operator": "AND"
}
}
}
}
```
• 查询字段`message`中同时包含`"capital"`和`"Hungary"`的文档。
4.3 使用`fuzziness`参数
```json
GET /_search
{
"query": {
"match": {
"message": {
"query": "tezt",
"fuzziness": "AUTO"
}
}
}
}
```
• 查询字段`message`中包含与`"tezt"`模糊匹配的文档。
4.4 使用`zero_terms_query`参数
```json
GET /_search
{
"query": {
"match": {
"message": {
"query": "to be or not to be",
"zero_terms_query": "all"
}
}
}
}
```
• 如果分析器移除了所有查询词元,则返回所有文档。
4.5 使用`minimum_should_match`参数
```json
GET /_search
{
"query": {
"match": {
"message": {
"query": "this is a test",
"minimum_should_match": "75%"
}
}
}
}
```
• 查询字段`message`中至少匹配查询词元的 75%的文档。
5.`match`查询的高级用法
5.1 多字段搜索
可以通过`multi_match`查询在多个字段中搜索相同的文本:
```json
GET /_search
{
"query": {
"multi_match": {
"query": "this is a test",
"fields": ["message", "description"]
}
}
}
```
• 查询字段`message`和`description`中包含`"this is a test"`的文档。
5.2 同义词扩展
使用`synonym_graph`过滤器时,`match`查询会自动扩展同义词:
```json
GET /_search
{
"query": {
"match": {
"message": {
"query": "NY",
"auto_generate_synonyms_phrase_query": true
}
}
}
}
```
• 查询字段`message`中包含`"NY"`或`"New York"`的文档。
6.`match`查询的优化建议
6.1 合理选择分析器
• 根据字段的内容和搜索需求选择合适的分析器。
• 例如,对于英文文本,可以使用`standard`分析器;对于中文文本,可以使用`ik_max_word`分析器。
6.2 控制模糊匹配
• 模糊匹配会增加查询的复杂度和性能开销,建议谨慎使用。
• 可以通过`fuzziness`、`prefix_length`和`max_expansions`参数来控制模糊匹配的范围。
6.3 使用`minimum_should_match`
• 通过`minimum_should_match`参数可以提高查询的精确度,减少无关结果的返回。
6.4 分页和性能优化
• 使用`from`和`size`参数进行分页,避免一次性返回大量结果。
• 对于大数据量的查询,可以使用`filter`
6.5 使用`filter`来提高性能
在查询中使用`filter`来缩小搜索范围,可以显著提高查询性能。`filter`通常用于过滤出满足特定条件的文档,而这些条件不需要计算相关性分数(`_score`)。例如:
```json
GET /_search
{
"query": {
"bool": {
"must": {
"match": {
"message": "this is a test"
}
},
"filter": {
"range": {
"timestamp": {
"gte": "2025-01-01",
"lte": "2025-01-31"
}
}
}
}
}
}
```
• 这个查询会先过滤出`timestamp`在 2025 年 1 月的文档,然后再在这些文档中搜索包含`"this is a test"`的文档。
6.6 使用`boosting`来调整结果
`boosting`查询可以用来降低某些文档的相关性分数,而不是完全排除它们。例如:
```json
GET /_search
{
"query": {
"boosting": {
"positive": {
"match": {
"message": "this is a test"
}
},
"negative": {
"match": {
"message": "error"
}
},
"boost": 0.2
}
}
}
```
• 这个查询会搜索包含`"this is a test"`的文档,但如果文档中包含`"error"`,则其相关性分数会被降低到原来的 20%。
6.7 使用`profile`来调试查询
Elasticsearch 提供了`profile`参数,可以帮助调试查询的执行过程。例如:
```json
GET /_search
{
"profile": true,
"query": {
"match": {
"message": "this is a test"
}
}
}
```
• 查询结果中会包含详细的执行计划和性能分析信息,帮助优化查询。
8.`match`查询的高级用法(续)
8.1 使用`query_string`查询
`query_string`查询允许使用更复杂的查询语法,支持布尔运算符、通配符等。例如:
```json
GET /_search
{
"query": {
"query_string": {
"query": "(this AND test) OR (error AND warning)",
"fields": ["message"]
}
}
}
```
• 这个查询会搜索字段`message`中包含`(this AND test)`或`(error AND warning)`的文档。
8.2 使用`simple_query_string`查询
`simple_query_string`查询类似于`query_string`,但语法更简单,适合用户输入。例如:
```json
GET /_search
{
"query": {
"simple_query_string": {
"query": "this AND test",
"fields": ["message"]
}
}
}
```
• 这个查询会搜索字段`message`中包含`this`和`test`的文档。
8.3 使用`match_phrase`查询
`match_phrase`查询用于搜索短语匹配,要求文档中包含完整的短语。例如:
```json
GET /_search
{
"query": {
"match_phrase": {
"message": "this is a test"
}
}
}
```
• 这个查询会搜索字段`message`中包含完整短语`"this is a test"`的文档。
8.4 使用`match_phrase_prefix`查询
`match_phrase_prefix`查询用于搜索短语匹配,并允许短语的最后一个词元使用前缀匹配。例如:
```json
GET /_search
{
"query": {
"match_phrase_prefix": {
"message": "this is a te"
}
}
}
```
• 这个查询会搜索字段`message`中包含`"this is a"`并且以`"te"`开头的短语。
8.5 使用`multi_match`查询
`multi_match`查询允许在多个字段中搜索相同的文本。例如:
```json
GET /_search
{
"query": {
"multi_match": {
"query": "this is a test",
"fields": ["message", "description"]
}
}
}
```
• 这个查询会搜索字段`message`和`description`中包含`"this is a test"`的文档。
9.`match`查询的性能优化
9.1 索引优化
• 合理设计字段映射:根据字段的内容和查询需求,合理选择字段类型和分析器。
• 使用倒排索引:Elasticsearch 默认使用倒排索引,确保字段类型适合倒排索引。
• 使用`keyword`类型字段:对于不需要分词的字段,使用`keyword`类型以提高查询性能。
9.2 查询优化
• 避免使用`match_all`查询:尽量使用更具体的查询条件来缩小搜索范围。
• 使用`filter`来减少结果集:通过`filter`条件过滤出符合特定条件的文档。
• 限制返回的字段:使用`_source`参数指定返回的字段,减少数据传输量。
9.3 硬件优化
• 增加内存:Elasticsearch 是内存密集型应用,增加内存可以显著提高性能。
• 使用 SSD 磁盘:SSD 磁盘的读写速度比传统硬盘快得多,可以提高查询性能。
• 合理配置集群:根据数据量和查询负载,合理配置 Elasticsearch 集群的节点数量和硬件配置。
10.总结
`match`查询是 Elasticsearch 中最强大的全文搜索工具之一,它通过分析器将查询文本转换为词元,并通过布尔逻辑组合这些词元来搜索匹配的文档。通过合理配置参数和优化查询,可以实现高效、灵活的全文搜索。
相关文章:

【Elasticsearch】match查询
Elasticsearch 的match查询是全文搜索中最常用和最强大的查询类型之一。它允许用户在指定字段中搜索文本、数字、日期或布尔值,并提供了丰富的功能来控制搜索行为和结果。以下是match查询的详细解析,包括其工作原理、参数配置和使用场景。 1.match查询的…...

AndroidStudio中可用的Ai插件
GitHub Copilot 这是我目前主用的,还行 1. 安装 打开 Android Studio:启动您的 Android Studio。 导航到插件设置: 点击菜单栏中的 File(文件) > Settings(设置)。在设置窗口中࿰…...

【C】链表算法题7 -- 环形链表||
leetcode链接https://leetcode.cn/problems/linked-list-cycle-ii/description/ 问题描述 给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。如果链表中有某个节点,可以通过连续跟踪 next 指针再次到…...

STM32系统架构介绍
STM32系统架构 1. CM3/4系统架构2. CM3/4系统架构-----存储器组织结构2.1 寄存器地址映射(特殊的存储器)2.2 寄存器地址计算2.3 寄存器的封装 3. CM3/4系统架构-----时钟系统 STM32 和 ARM 以及 ARM7是什么关系? ARM 是一个做芯片标准的公司,…...

Android Studio:EditText常见4种监听方式
1. 文本变化监听(TextWatcher) TextWatcher 主要用于监听 EditText 里的文本变化,它有三个方法: beforeTextChanged(文本变化前)onTextChanged(文本正在变化时)afterTextChanged&a…...

window patch按块分割矩阵
文章目录 1. excel 示意2. pytorch代码3. window mhsa 1. excel 示意 将一个三维矩阵按照window的大小进行拆分成多块2x2窗口矩阵,具体如下图所示 2. pytorch代码 pytorch源码 import torch import torch.nn as nn import torch.nn.functional as Ftorch.set_p…...

机器学习(李宏毅)——BERT
一、前言 本文章作为学习2023年《李宏毅机器学习课程》的笔记,感谢台湾大学李宏毅教授的课程,respect!!! 读这篇文章必须先了解self-attention、Transformer,可参阅我其他文章。 二、大纲 BERT简介self-…...

数据科学之数据管理|统计学
使用python学习统计 目录 01 统计学基础 7 一、 统计学介绍 7 二、 数据和变量 8 02 描述统计 10 一、 描述统计概述 10 二、 分类变量的描述 11 三、 等距数值变量的描述 13 四、 等比数值变量的描述 16 五、 常用软件包介绍 16 六、 数值变量的描述统计 18 (一)…...

深度学习-111-大语言模型LLM之基于langchain的结构化输出功能实现文本分类
文章目录 1 langchain的结构化输出1.1 推荐的使用流程1.2 模式定义1.3 返回结构化输出1.3.1 工具调用(方式一)1.3.2 JSON模式(方式二)1.3.3 结构化输出法(方式三)2 文本分类2.1 定义分类模式2.2 配置分类提示模板2.3 初始化分类模型2.4 分类示例3 参考附录1 langchain的结构化输…...

常见的排序算法:插入排序、选择排序、冒泡排序、快速排序
1、插入排序 步骤: 1.从第一个元素开始,该元素可以认为已经被排序 2.取下一个元素tem,从已排序的元素序列从后往前扫描 3.如果该元素大于tem,则将该元素移到下一位 4.重复步骤3,直到找到已排序元素中小于等于tem的元素…...

C++17 中的 std::gcd:探索最大公约数的现代 C++ 实现
文章目录 一、std::gcd 的基本用法(一)包含头文件(二)函数签名(三)使用示例 二、std::gcd 的实现原理三、std::gcd 的优势(一)简洁易用(二)类型安全ÿ…...
)
力扣刷题(数组篇)
日期类 #pragma once#include <iostream> #include <assert.h> using namespace std;class Date { public:// 构造会频繁调用,所以直接放在类里面(类里面的成员函数默认为内联)Date(int year 1, int month 1, int day 1)//构…...

OpenWRT中常说的LuCI是什么——LuCI介绍(一)
我相信每个玩openwrt的小伙伴都或多或少看到过luci这个东西,但luci到底是什么东西,可能还不够清楚,今天就趁机来介绍下,openwrt中的luci,到底是个什么东西。 什么是LuCI? 首先,LuCI是OpenWRT中…...

机器学习核心算法解析
机器学习核心算法解析 机器学习是人工智能的核心技术之一,它通过从数据中学习模式并做出预测或决策。本文将深入解析机器学习的核心算法,包括监督学习、无监督学习和强化学习,并通过具体案例和代码示例帮助读者理解这些算法的实际应用。 1. …...

【目标检测json2txt】label从COCO格式json文件转YOLO格式txt文件
目录 🍀🍀1.COCO格式json文件 🌷🌷2.YOLO格式txt文件 💖💖3.xml2json代码(python) 🐸🐸4.输入输出展示 🙋🙋4.1输入json 🍂🍂4.2输出txt 整理不易,欢迎一键三连!!! 送你们一条美丽的--分割线-- 🍀🍀1.COCO格式json文件 COCO数…...
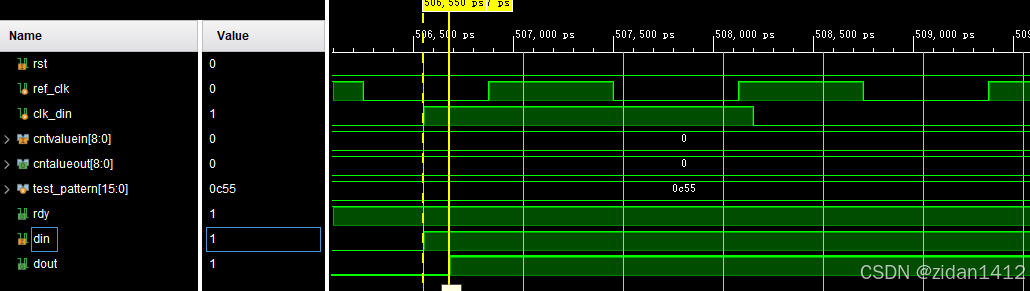
LVDS接口总结--(5)IDELAY3仿真
仿真参考资料如下: https://zhuanlan.zhihu.com/p/386057087 timescale 1 ns/1 ps module tb_idelay3_ctrl();parameter REF_CLK 2.5 ; // 400MHzparameter DIN_CLK 3.3 ; // 300MHzreg ref_clk ;reg …...

Flink内存配置和优化
在 Apache Flink 1.18 的 Standalone 集群中,内存设置是一个关键配置,它直接影响集群的性能和稳定性。 Flink 的内存配置主要包括 JobManager 和 TaskManager 的内存分配。 以下是如何在 Standalone 模式下配置内存的详细说明。 JobManager 内存配置 Jo…...

网络安全之笔记--Linus命令
Linux命令 文件和目录操作 ls 列出目录内容 常用选项 -a:显示所有文件和目录(包括隐藏文件,以.开头的文件)。 -l:以长格式显示文件和目录的详细信息。 -h:与-l配合使用,以更易读的方式显示文件大…...

deepseek和chatgpt对比
DeepSeek 和 ChatGPT 都是自然语言处理领域的工具,但它们的设计目标和功能有所不同。 功能定位: ChatGPT 是一个基于 OpenAI GPT-3 或 GPT-4 的聊天机器人,旨在进行人机对话、文本生成、问题解答等,广泛应用于教育、客服、创意写作…...

微服务与网关
什么是网关 背景 单体项目中,前端只用访问指定的一个端口8080,就可以得到任何想要的数据 微服务项目中,ip是不断变化的,端口是多个的 解决方案:网关 网关:就是网络的关口,负责请求的路由、转发、身份校验。 前段还是访问之前的端口8080即可 后端对于前端来说是透明的 网…...

Unity中实现动态图集算法
在 Unity 中,动态图集(Dynamic Atlas)是一种在运行时将多个纹理合并成一个大纹理图集的技术,这样可以减少渲染时的纹理切换次数,提高渲染效率。 实现原理: 动态图集的核心思想是在运行时动态地将多个小纹理…...

本地部署DeepSeek Nodejs版
目录 1.下载 Ollama 2.下载DeepSeek模型 3.下载 ollama.js 1.下载 Ollama https://ollama.com/ 下载之后点击安装,等待安装成功后,打开cmd窗口,输入以下指令: ollama -v 如果显示了版本号,则代表已经下载成功了。…...

字节跳动后端二面
📍1. 数据库的事务性质,InnoDB是如何实现的? 数据库事务具有ACID特性,即原子性、一致性、隔离性和持久性。InnoDB通过以下机制实现这些特性: 🚀 实现细节: 原子性:通过undo log实…...

TUSB422 MCU 软件用户指南
文章目录 TUSB422 MCU 软件用户指南 目录表格图表1. 介绍2. 配置2.1 通用配置2.2 USB-PD 3.0 支持2.3 VDM 支持 3. 代码 ROM/RAM 大小优化4. 通过 UART 调试4. 移植到其他微控制器 TUSB422 MCU 软件用户指南 摘要 本文档是 TUSB422 微控制器基于 Type-C 端口控制(…...

Django在终端创建项目(pycharm Windows)
1.选择目录 选择或新建一个文件夹,作为项目保存的地方 2.右键在终端打开 3.确定django-admin.exe安装位置 找到自己安装django时,django-admin.exe安装的位置,例如 4.运行命令 使用django-admin.exe的绝对路径,在刚才打开的终端…...

wordpress主题制作
工具/原料 <P><BR>使用divcss语言编写的html静态页面一个</P> <P>Macromedia Dreamweaver软件<BR></P> WordPress主题结构分析 1 1、index.php首页模板(最基本) ---- 1、header.php头部 ---- 2、sidebar.php侧边…...
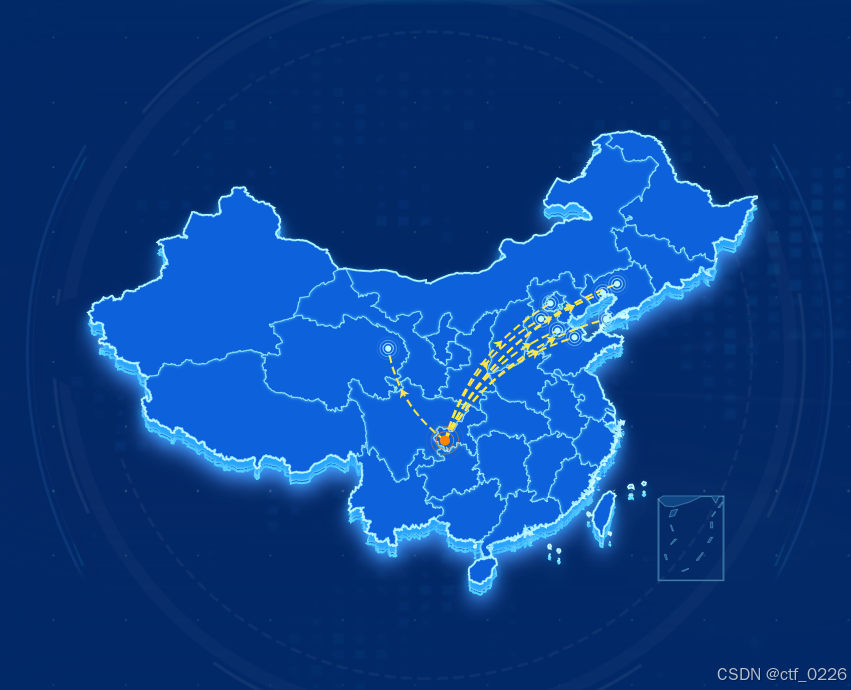
echarts 3d中国地图飞行线
一、3D中国地图 1. 一定要使用 echarts 5.0及以上的版本; 2. echarts 5.0没有内置中国地图了。点击下载 china.json; 3. 一共使用了四层地图。 (1)第一层是中国地图各省细边框和展示南海诸岛; (2)第二层是…...

视频基础操作
1.1. 例子 读取mp4格式的视频,将每一帧改为灰度图,并且打上水印(“WaterMark”),并将其输出保存为out.mp4,在这个例子中可以看到视频读取,每帧数据处理,视频保存的整体流程简单示例 import cv…...

微信小程序 - 组件和样式
组件和样式介绍 在开 Web 网站的时候: 页面的结构由 HTML 进行编写,例如:经常会用到 div、p、 span、img、a 等标签 页面的样式由 CSS 进行编写,例如:经常会采用 .class 、#id 、element 等选择器 但在小程序中不能…...

在本地校验密码或弱口令 (windows)
# 0x00 背景 需求是验证服务器的弱口令,如果通过网络侧校验可能会造成账户锁定风险。在本地校验不会有锁定风险或频率限制。 # 0x01 实践 ## 1 使用 net use 命令 可以通过命令行使用 net use 命令来验证本地账户的密码。打开命令提示符(CMD࿰…...