从0到1的回溯算法学习
回溯算法
- 前言
- 这个算法能帮我们做啥
- 算法模版
- 力扣例题( 以下所有题目代码都经过力扣认证 )
- 形式一 元素无重不可复选
- 46.全排列
- 思路详解
- 代码
- 77.组合
- 思路详解
- 代码
- 78.子集
- 思路详解
- 代码
- 形式二 元素可重不可复选
- 思考(deepseek)
- 核心思想
- 90.子集-II
- 思路
- 代码
- 组合总和-II
- 思路
- 代码
- 剪枝操作解析
- 剪枝逻辑代码解析
- 形式三 元素无重可复选
- 39 组合总和
- 思路
- 代码
- 优质资源引用目录
前言
如果你点开篇文章,我默认你已经学习完前面的二叉树章节,那么相信大家对递归比较熟悉了,我觉得不要上来跟你说一个 {xx算法 }
你就觉得
{肯定很难啊 前面二叉树都没学懂我这个估计也学不会吧 }
真的完全没必要这样 其实我们已经在二叉树章节中不知不觉中学到了回溯算法 只不过有些题目并不需要回溯 准确的来说回溯是位于递归语句之后的部分
By the way :真的希望大家写代码都用增量编写法,很多时候,对于我们不了解还没掌握的知识,我们如果从大局去考虑它的实现是很难的,想要去把每个细节统统都搞出来更是难,所以希望大家如果跟我一样都是初学者,还是采用这种方法好一些,我自己实践下来,这确实是一个很好的习惯,
比如我们发现只靠一个函数对于程序的可读性和复用性都很差的时候 想到需要一个辅助函数 我们再去构造一下不就行了吗(对于我而言我现在更需要的是结构清晰,便于我回看能够很容易读懂的程序)
又比如一个函数的参数很多时候你没法一开始就知道我就要传一个vector一个整型变量进来,只有你想到用什么参数再给他补上去 键盘在你手上 不是在别人嘴上
希望大家能够受益
class Solution {
public:int result;void getdepth(TreeNode* node, int depth) {result = depth > result ? depth : result; // 中if (node->left == NULL && node->right == NULL) return ;if (node->left) { // 左depth++; // 深度+1getdepth(node->left, depth);depth--; // 回溯,深度-1}if (node->right) { // 右depth++; // 深度+1getdepth(node->right, depth);depth--; // 回溯,深度-1}return ;}int maxDepth(TreeNode* root) {result = 0;if (root == NULL) return result;getdepth(root, 1);return result;}
};
其实还有前面文章中提到的迷宫问题【DFS(深度优先搜索)】,小明是不是在走到死胡同的时候就会退回路口继续作判断 这个回退到路口的过程其实就是一个回溯的过程
对应文章
这个算法能帮我们做啥
其实我的意思是说:回溯算法听着挺牛B,我们得知道什么是它能做的别人做不了的,我才会去想要学它,比如我循环都能AC 我学你m的回溯呢
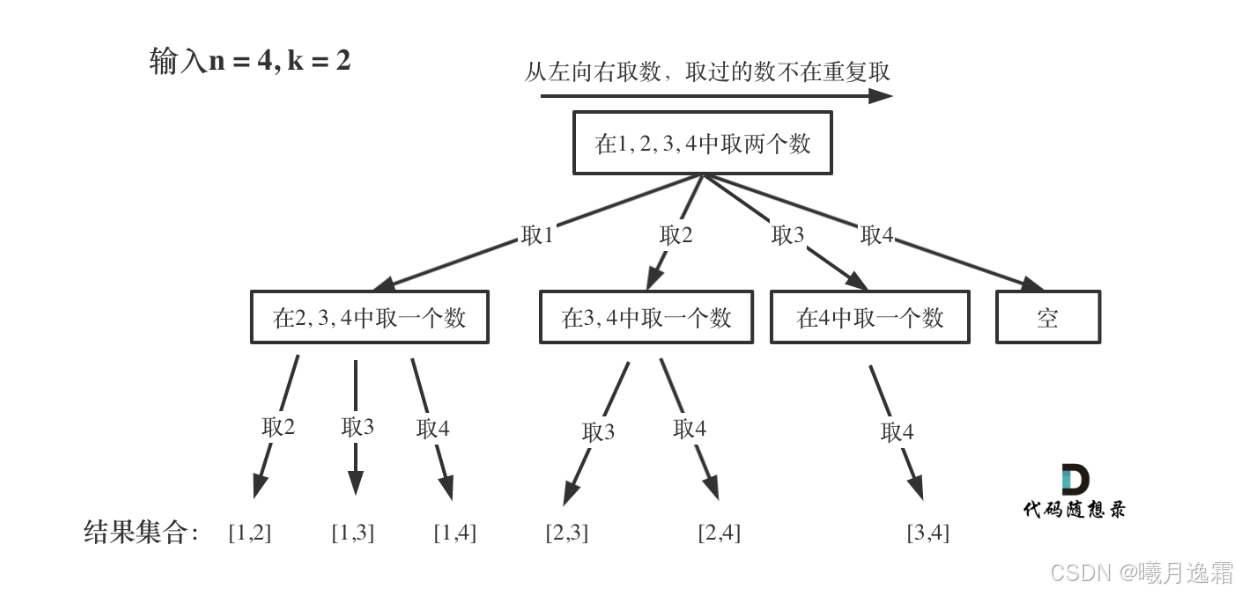
eg.一个非常经典的子集问题
给你一个数组[1,2,3,4,5],要求你找出大小为2的所有子集,你可能会想到用两层for循环去解决,一层控制第一个位置,第二层控制第二个位置
确实是可以这样去做,但是其实你会发现当数的范围和要求不断变化的时候(要解决 n为100,k为50的情况,暴力写法需要嵌套50层for循环),你甚至连暴力都写不出来
还是上面的例子,我们用回溯就能很好的解决这种变化的情况,我们可以把找子集/组合的过程抽象成一颗N叉树,这个其实就是我们在学数学时的一个找子集问题,只不过把我们思考的过程(先找第一个数,在分别找第二个)抽象成了一颗决策树,如下图所示
.
labuladong在它的文章中提到:其实回溯算法的本质是穷举出所有满足条件的结果,这跟动态规划不一样,动态规划虽然也是穷举,但是需要比较所有决策,找到最优解
言归正传,回溯算法就是 N 叉树的遍历,这个 N 等于当前可做的选择(choices)的总数,同时,在前序遍历的位置作出当前选择(choose 过程),然后开始递归,最后在后序遍历的位置取消当前选择(unchoose 过程)。
所以回溯算法的核心就在于我们如何设计 choose 和 unchoose 部分的逻辑。
你可以理解为,回溯算法相当于一个决策过程,递归地遍历一棵决策树,穷举所有的决策,同时把符合条件的决策挑出来。
举个例子,假如你要吃饭,但是去哪里吃,然后具体吃什么呢?这是个决策问题,而且不太容易,因为选择实在太多了,如下图。
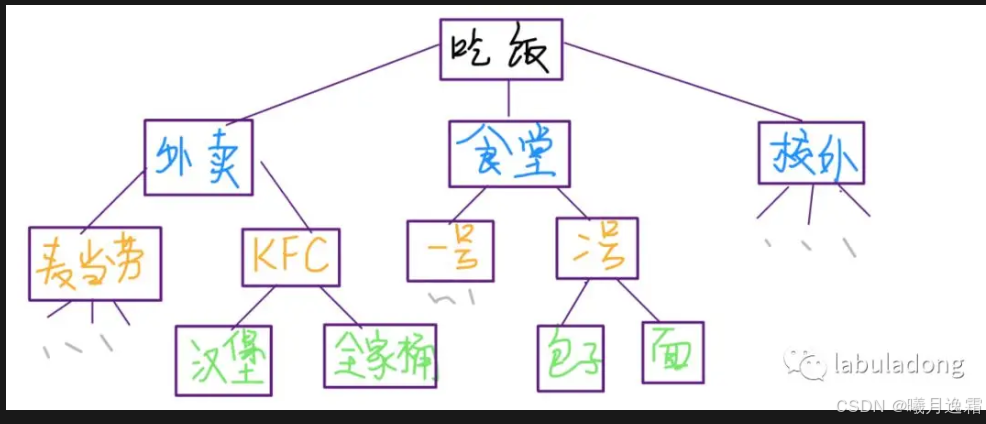
算法模版
"""
choiceList:当前可以进行的选择列表
track:可以理解为决策路径,即已经做出一系列选择
answer:用来储存我们的符合条件决策路径
"""def backtrack(choiceList, track, answer):if track is OK:answer.add(track)else:for choice in choiceList:# choose:选择一个 choice 加入 trackbacktrack(choices, track, answer)# unchoose:从 track 中撤销上面的选择*******************************************精简版result = []//用一个合适的容器存储我们需要结果
def backtrack(路径, 选择列表):if 满足结束条件:result.add(路径)returnfor 选择 in 选择列表:做选择backtrack(路径, 选择列表)撤销选择
其核心就是 for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」,特别简单。
力扣例题( 以下所有题目代码都经过力扣认证 )
首先回溯的问题主要分为三大类:排列,子集,组合
无论是排列、组合还是子集问题,简单说无非就是让你从序列 nums 中以给定规则取若干元素
但每一类问题都有三种形式 也就是九种类似但又不太一样的题目
下面是每一种形式对于的排列,子集,集合的例题
形式一 元素无重不可复选
即 nums 中的元素都是唯一的,每个元素最多只能被使用一次,这也是最基本的形式。
以组合为例,如果输入 nums = [2,3,6,7],和为 7 的组合应该只有 [7]。
46.全排列
思路详解
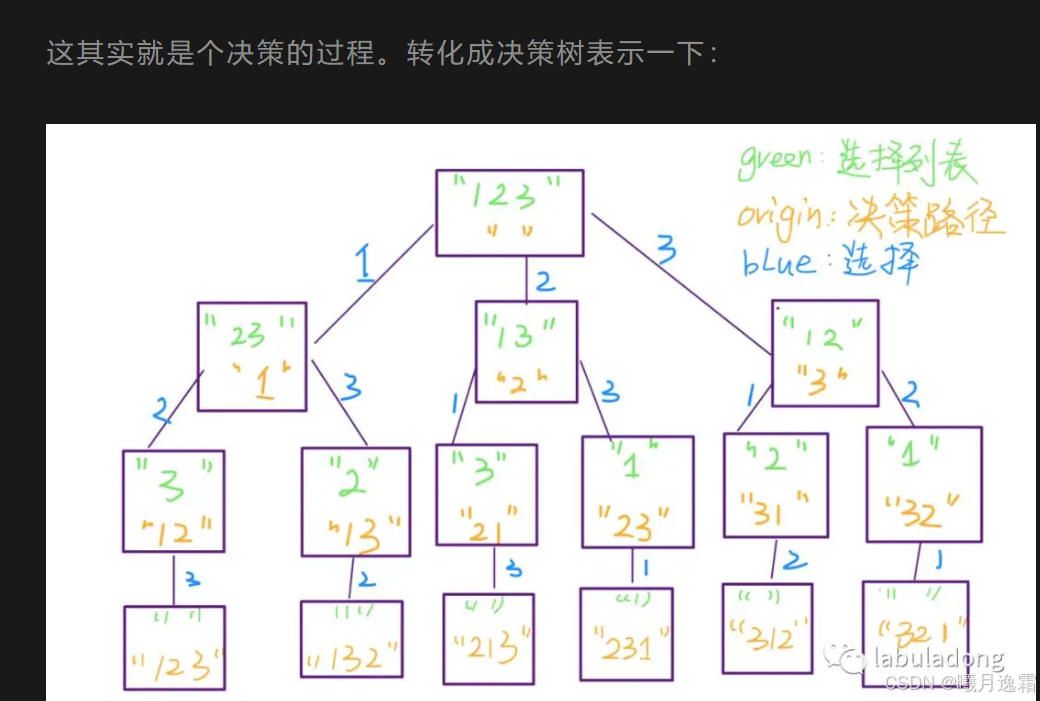
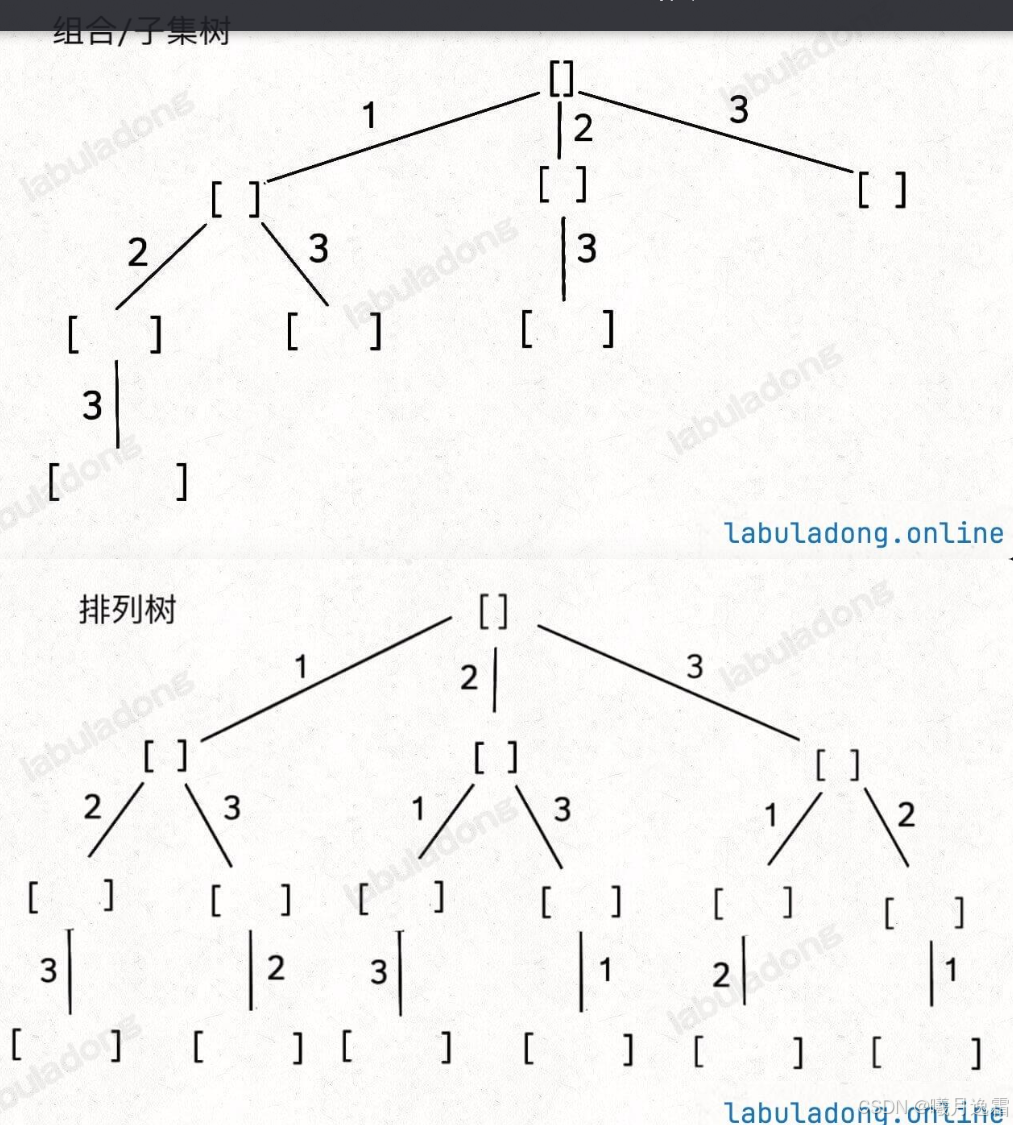
这个问题我们高中就做过,我们的思路是,先把第一个数固定为 1,然后全排列 2,3;再把第一个数固定为 2,全排列 1,3;再把第一个数固定为 3,全排列 1,2 。
- 容器的选择上
由于观察题目的输出格式,不难发现,我们需要一个用于存储数组的数组 还需要一个向量来保存我们递归的路径
那么就是vector<vector<int>> res;vector<int> track; - 当我们递归到叶子节点的时候,用于把这些排列的结果收集起来
res.push_back(track); - 那么结束条件自然就是:
track.size() == nums.size() - 还有一个重点就是全排列和组合或者子集问题不同,我们讲究的是顺序
- 比如123和321***是一种组合而并非一种排列***
其实并不难理解 一想到高中在排列组合中学的A33与C33他们的区别就好了
这也是两种决策树的根本不同之处
也就是说我们并不能像组合问题一样弄一个startindex(这一点后面再说)来保证不发生重复
举个例子来说 在组合问题中,我们只需要一个起始下标startindex来记录下一层递归,搜索的起始位置这是非常重要的
我一开始以为startindex只是个参数可以直接用固定值1来代替,这样的话 比如需要的是大小为2的集合 就会出现一直向后加的情况 这是不对的 具体的分析在后面的组合问题中
而是要用一个used数组来记录我们用过的值 记录这个路径里都放了哪些元素
代码
class Solution {
private:vector<vector<int>> res;
public:// 主函数,输入一组不重复的数字,返回它们的全排列vector<vector<int>> permute(vector<int>& nums) {// 记录「路径」vector<int> track;// 「路径」中的元素会被标记为true,避免重复使用vector<bool> used(nums.size(), false);backtrack(nums, track, used);return res;}// 路径:记录在 track 中// 选择列表:nums 中不存在于 track 的那些元素// 结束条件:nums 中的元素全都在 track 中出现void backtrack(vector<int>& nums, vector<int>& track, vector<bool>& used) {// 触发结束条件if (track.size() == nums.size()) {res.push_back(track);return;}for (int i = 0; i < nums.size(); i++) {// 排除不合法的选择if (used[i]) {// nums[i] 已经在 track 中,跳过continue;}// 做选择track.push_back(nums[i]);used[i] = true;// 进入下一层决策树backtrack(nums, track, used);// 取消选择track.pop_back();used[i] = false;}}
};
77.组合
思路详解
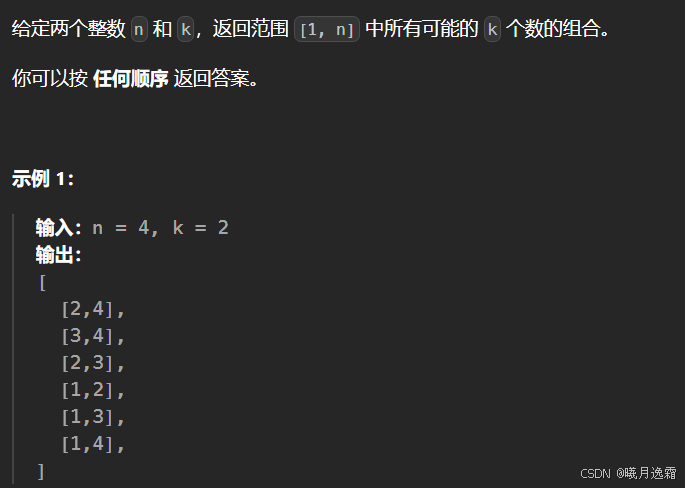
其实本质上还是子集的问题 给这题翻译一下,其实就还是子集的问题:
给你输入一个数组 nums = [1,2…,n] 和一个正整数 k,请你生成所有大小为 k 的子集。
还是以 nums = [1,2,3] 为例,刚才让你求所有子集,就是把所有节点的值都收集起来;现在你只需要把第 2 层(根节点视为第 0 层)的节点收集起来,就是大小为 2 的所有组合,稍微改一下模板里面的退出限制条件就行,因为我们只需要收集某一层的结果,而不是所有!!!
代码
class Solution {
public:vector<vector<int>> res;// 记录回溯算法的递归路径vector<int> track; // 主函数vector<vector<int>> combine(int n, int k) {backtrack(1, n, k);return res;}void backtrack(int start, int n, int k) {// base caseif (k == track.size()) {// 遍历到了第 k 层,收集当前节点的值res.push_back(track); // 直接使用 track,不需要转换return;}// 回溯算法标准框架for (int i = start; i <= n; i++) {// 选择track.push_back(i); // 在尾部添加元素// 通过 start 参数控制树枝的遍历,避免产生重复的子集backtrack(i + 1, n, k);// 撤销选择track.pop_back(); // 移除尾部元素}}
};
78.子集
思路详解
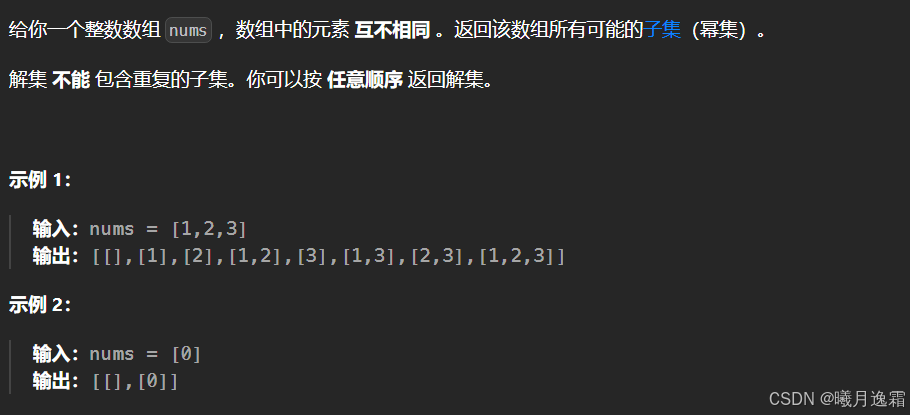
将上述问题抽象成n叉树 其实不难发现 一开始1可以有两个选择,2只有一个选择,3没得选,
根本原因就是【1,2】【2,1】是一种组合,
因为集合中的元素不用考虑顺序,[1,2,3] 中 2 后面只有 3,如果你添加了前面的 1,那么 [2,1] 会和之前已经生成的子集 [1,2] 重复。
换句话说,我们通过保证元素之间的相对顺序不变来防止出现重复的子集。
这里其实startindex的作用就十分重要了,对于一开始起始下标为i 那么下一次就直接从i+1开始搜索
代码
最后,backtrack 函数开头看似没有 base case(递归出口),会不会进入无限递归?
其实不会的,当 start == nums.length 时,叶子节点的值会被装入 res,但 for 循环不会执行,也就结束了递归。
class Solution {
private:vector<vector<int>> res;// 记录回溯算法的递归路径vector<int> track;public:// 主函数vector<vector<int>> subsets(vector<int>& nums) {backtrack(nums, 0);return res;}// 回溯算法核心函数,遍历子集问题的回溯树void backtrack(vector<int>& nums, int start) {// 前序位置,每个节点的值都是一个子集res.push_back(track);// 回溯算法标准框架for (int i = start; i < nums.size(); i++) {// 做选择track.push_back(nums[i]);// 通过 start 参数控制树枝的遍历,避免产生重复的子集backtrack(nums, i + 1);// 撤销选择track.pop_back();}}
};
形式二 元素可重不可复选
即 nums 中的元素可以存在重复,每个元素最多只能被使用一次。
以组合为例,如果输入 nums = [2,5,2,1,2],和为 7 的组合应该有两种 [2,2,2,1] 和 [5,2]。
思考(deepseek)
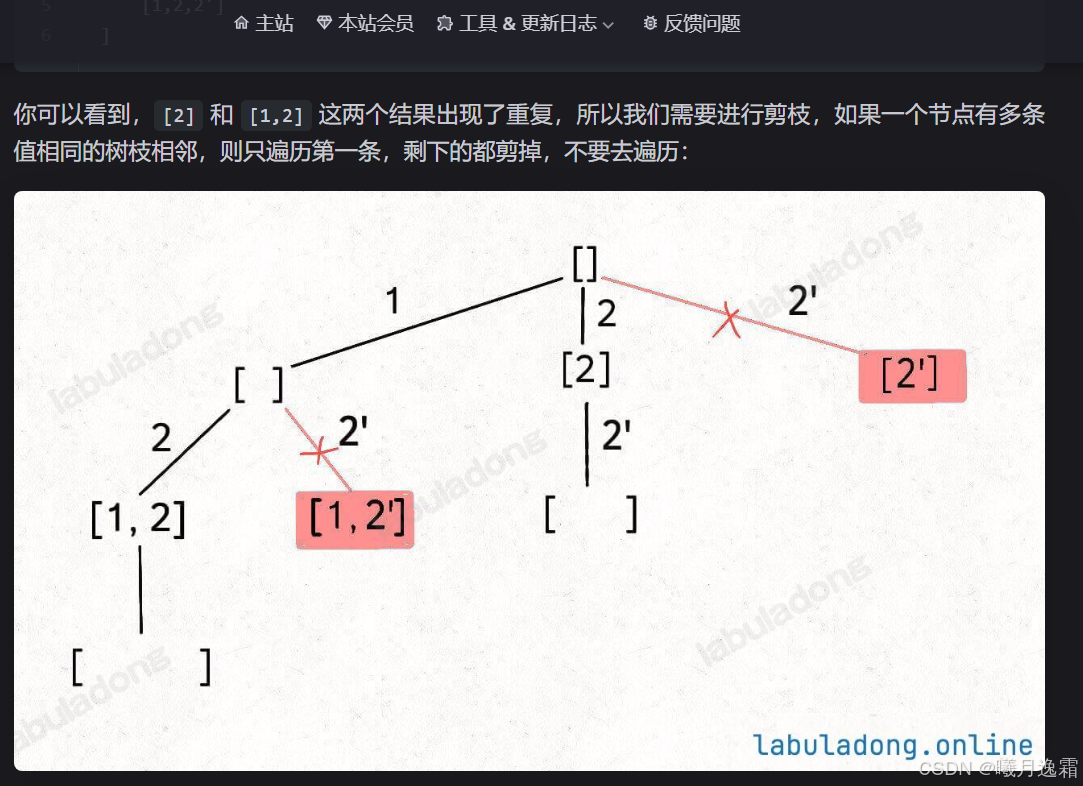
形式二与形式一有什么区别吗 其实核心区别就是nums数组里面会有重复的元素 给我们遍历n叉树带来了困难 因为前面数值是不同的 计算机当然知道只能选一个 因为数值一样 但我们需要让计算机知道这俩我只能走一个(剪枝),为啥这么说呢,因为如果不这么做就会产生重复的路径 也就是说值相同的相邻树枝我们只需要遍历一条就够了 我用deepseek生成了一些例子帮助大家理解
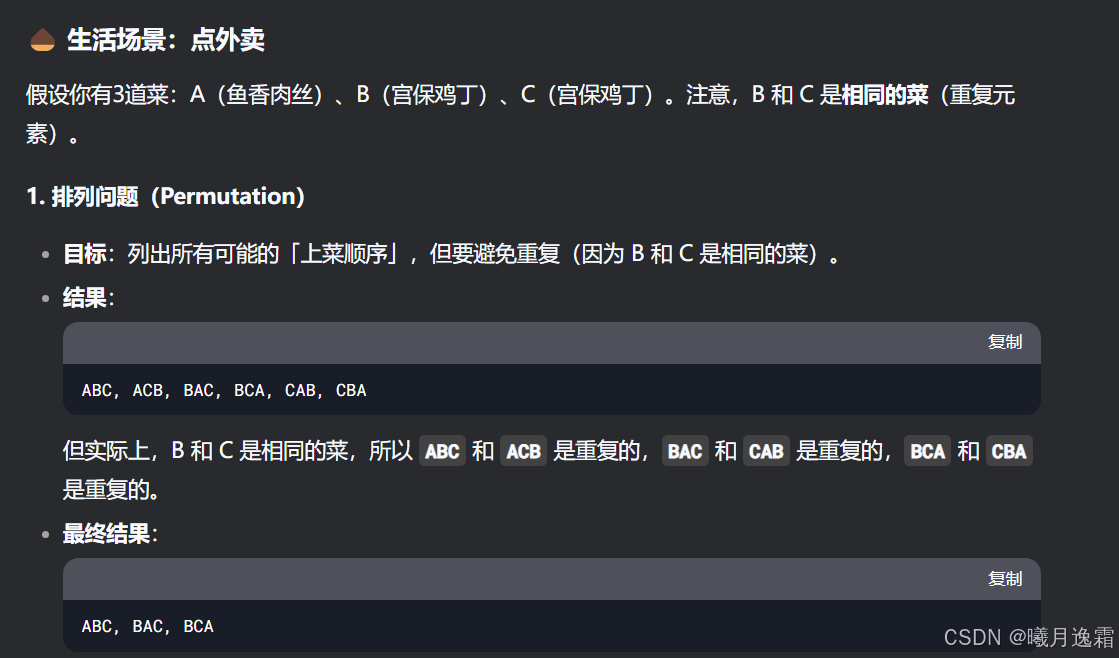
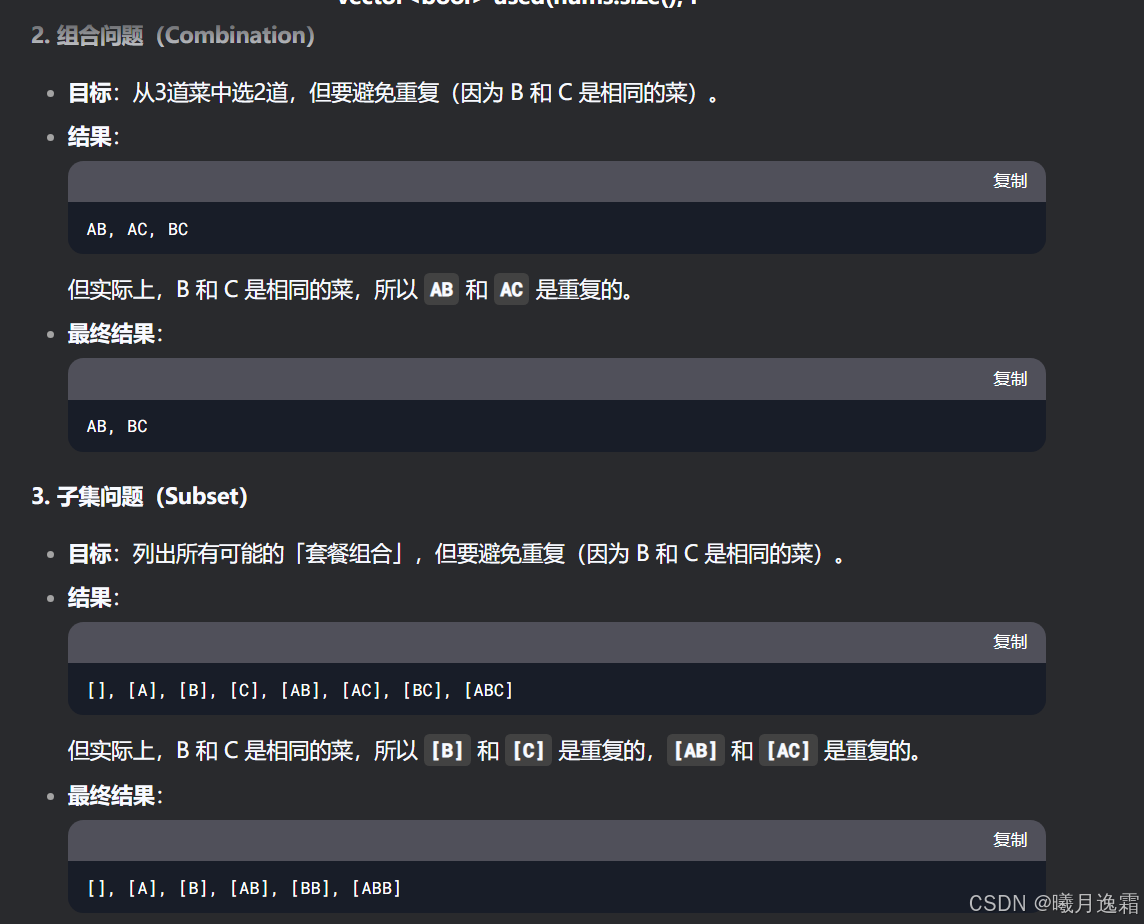
核心思想
90.子集-II
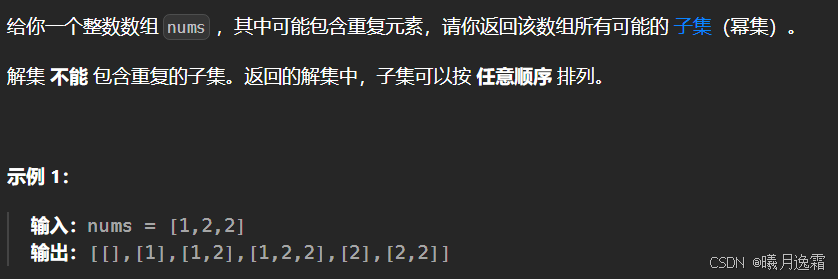
思路
代码
class Solution {
public:vector<vector<int>> res;deque<int> track;vector<vector<int>> subsetsWithDup(vector<int>& nums) {// 先排序,让相同的元素靠在一起sort(nums.begin(), nums.end());backtrack(nums, 0);return res;}void backtrack(vector<int>& nums, int start) {// 前序位置,每个节点的值都是一个子集res.push_back(vector<int>(track.begin(), track.end()));for (int i = start; i < nums.size(); i++) {// 剪枝逻辑,值相同的相邻树枝,只遍历第一条if (i > start && nums[i] == nums[i - 1]) {continue;}track.push_back(nums[i]);backtrack(nums, i + 1);track.pop_back();}}
};
组合总和-II
这个不就是我们在形式二开头举的例子吗 无非翻译一下
就是给你一个数组 里面有重复元素 找出所有和为targe的组合,
说这是一个组合问题,其实换个问法就变成子集问题了:请你计算 candidates 中所有和为 target 的子集。
思路
一分析完这思路不就来了吗,
首先容器:还是俩vector 一个储存每一条路径长啥样 一个存储所有路径的结果
结束条件:和正好等于target 直接把现在的结果给pushback到result数组里去就好,还有一种情况就是>target的时候直接退出就好了
核心操作就是在主函数中我们需要把这个nums排个序,然后在辅助函数中,我们需要进行剪枝操作,因为我们需要避免同一树层里有相同的元素,而不是一条路径(树枝)上有相同的元素,这一点其实就是剪枝的本质,也是避免出现重复的关键
代码
我用AI生成了注释便于大家理解
如果对于剪枝操作还是有些不理解的话我在后文贴出了解析
/c++
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
//signed 曦月逸霜class Solution {
public:vector<vector<int>>res; // 存储所有符合条件的组合vector<int>path; // 存储当前探索的组合int sum=0;//记录路径上的和/*** 解决组合总和问题,每个数字只能使用一次* @param candidates 候选数字数组* @param target 目标和* @return 所有符合条件的组合*/vector<vector<int>> combinationSum2(std::vector<int>& candidates, int target) {sort(candidates.begin(),candidates.end()); // 对候选数组排序,以便后续去重backtrack(candidates,0,target); // 从数组的第一个元素开始探索return res;}/*** 回溯函数,用于寻找所有符合条件的组合* @param nums 候选数字数组* @param start 当前探索的起始位置* @param target 目标和*/void backtrack(vector<int>&nums,int start,int target){if(sum==target){res.push_back(path); // 当前路径和达到目标和,加入结果集return;}if(sum>target){return; // 当前路径和超过目标和,回溯}for(int i=start;i<nums.size();i++){//剪枝if(i>start && nums[i]==nums[i-1]){continue;//直接跳过本次循环,避免重复组合}path.push_back(nums[i]); // 选择当前数字sum+=nums[i];backtrack(nums,i+1,target); // 递归探索下一个数字//撤销选择 回溯到上一层path.pop_back();sum-=nums[i];}}
};剪枝操作解析
在 combinationSum2 函数中,剪枝操作是为了避免生成重复的组合。具体来说,当候选数组中的元素可以重复时,如果不进行剪枝,可能会导致相同的组合被多次加入结果集中。
剪枝逻辑代码解析
if(i > start && nums[i] == nums[i-1])
{continue; // 直接跳过本次循环,避免重复组合
}
解释:
-
排序前提:在调用
backtrack函数之前,已经对candidates数组进行了排序(sort(candidates.begin(), candidates.end()))。这一步是剪枝操作的基础,因为只有在有序数组中,相同的元素才会相邻。 -
判断条件:
i > start:确保当前索引i不是本轮递归的第一个元素。如果i == start,说明这是本轮递归的第一个元素,不需要与前一个元素比较。nums[i] == nums[i-1]:检查当前元素是否与前一个元素相同。如果相同,则意味着当前路径已经在之前的递归中处理过该元素,继续使用它会导致重复组合。
-
跳过重复元素:
- 如果上述条件成立,即当前元素与前一个元素相同且不是本轮递归的第一个元素,则直接跳过当前循环(
continue),不再将该元素加入路径中。
- 如果上述条件成立,即当前元素与前一个元素相同且不是本轮递归的第一个元素,则直接跳过当前循环(
-
示例:
假设candidates = [1, 2, 2, 2, 5],目标和为5。排序后candidates = [1, 2, 2, 2, 5]。 -
当探索到第一个
2时,会生成包含2的组合。 -
接下来遇到第二个
2时,由于它与前一个2相同且不是本轮递归的第一个元素,因此会被跳过,避免生成[2, 2, ...]这样的重复组合。
通过这种方式,剪枝操作有效地减少了不必要的递归调用,提高了算法的效率,并确保结果集中没有重复的组合。
形式三 元素无重可复选
即 nums 中的元素都是唯一的,每个元素可以被使用若干次。
以组合为例,如果输入 nums = [2,3,6,7],和为 7 的组合应该有两种 [2,2,3] 和 [7]。
39 组合总和
思路
这道题说是组合问题,实际上也是子集问题:candidates 的哪些子集的和为 target?
想解决这种类型的问题,也得回到回溯树上,我们不妨先思考思考,标准的子集/组合问题是如何保证不重复使用元素的?
答案在于 backtrack 递归时输入的参数 start(思路来源:labuladong)

其实分析到这里代码大家就会写了
代码
labuladong的题解
对于双端队列不清楚的也可以用vector
class Solution {
public:vector<vector<int>> res;// 记录回溯的路径deque<int> track;// 记录 track 中的路径和int trackSum = 0;vector<vector<int>> combinationSum(vector<int>& candidates, int target) {backtrack(candidates, 0, target);return res;}// 回溯算法主函数void backtrack(vector<int>& nums, int start, int target) {// base case,找到目标和,记录结果if (trackSum == target) {res.push_back(vector<int>(track.begin(), track.end()));return;}// base case,超过目标和,停止向下遍历if (trackSum > target) {return;}// 回溯算法标准框架for (int i = start; i < nums.size(); i++) {// 选择 nums[i]trackSum += nums[i];track.push_back(nums[i]);// 递归遍历下一层回溯树// 同一元素可重复使用,注意参数backtrack(nums, i, target);// 撤销选择 nums[i]trackSum -= nums[i];track.pop_back();}}
};
优质资源引用目录
启蒙:
N皇后动画
学习:
带你学透回溯算法(理论篇)| 回溯法精讲!
代码随想录回溯篇
【labuladong】回溯算法核心套路详解
【labuladong】回溯算法秒杀所有排列/组合/子集问题
labuladong 的算法笔记
相关文章:
从0到1的回溯算法学习
回溯算法 前言这个算法能帮我们做啥算法模版力扣例题( 以下所有题目代码都经过力扣认证 )形式一 元素无重不可复选46.全排列思路详解代码 77.组合思路详解代码 78.子集思路详解代码 形式二 元素可重不可复选思考(deepseek)核心思想…...

24、深度学习-自学之路-卷积神经网络
一、你怎么理解卷积神经网络呢,我的理解是当你看一个东西的时候,你的眼睛距离图片越近,你看到的东西就越清晰,但是如果你看到的图片只是整个物体的一小部分,那么你将不知道你看到的物品是什么,因为关注整体…...

AVL树:高效平衡的二叉搜索树
🌟 快来参与讨论💬,点赞👍、收藏⭐、分享📤,共创活力社区。🌟 引言🤔 在数据结构的奇妙世界里,二叉搜索树(BST)原本是查找数据的好帮手。想象一下…...

RHCA练习5:配置mysql8.0使用PXC实现高可用
准备4台CentOS7的虚拟机(CentOS7-1、CentOS7-2、CentOS7-3、CentOS7-4) 备份原yum源的配置: mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup 更换阿里云镜像YUM源: curl -o /etc/yum.repos.…...

若输入超过 5 位数个时,推荐使用 scanf 输入数据。
【知识点】 在 C 中,当需要处理超过 5 位数个输入时,推荐使用 scanf 而不是 cin 输入数据。 这是因为 scanf 通常比 cin 更快。 另外,若整数超过 10 位,选择用 long long 型,而不是 int 型。 【参考文献】 https://b…...

Java 大视界 -- 边缘计算与 Java 大数据协同发展的前景与挑战(85)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

Android 原生层SurfaceView截屏
背景:flutter嵌入原生view时,原生view使用的surfaveview,导致下面两种方法无法正常使用。 导致flutter无法通过id找到RenderRepaintBoundary的toImage来抓取widget,原生层无法通过view去获取Bitmap 方案:使用PixelCopy…...

机器学习 - 理论和定理
在机器学习中,有一些非常有名的理论或定理,对理解机器学习的内在特性非常有帮助。本文列出机器学习中常用的理论和定理,并举出对应的举例子加以深化理解,有些理论比较抽象,我们可以先记录下来,慢慢啃&#…...

2025.2.11——一、[极客大挑战 2019]PHP wakeup绕过|备份文件|代码审计
题目来源:BUUCTF [极客大挑战 2019]PHP 目录 一、打开靶机,整理信息 二、解题思路 step 1:目录扫描、爆破 step 2:代码审计 1.index.php 2.class.php 3.flag.php step 3:绕过__wakeup重置 编辑 三、小结…...

读取本地excel删除第一行,并生成List数组
在 pom.xml 里添加如下依赖: <dependencies><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.3</version></dependency><dependency><groupId>org.ap…...

Vivado生成edif网表及其使用
介绍如何在Vivado中将模块设为顶层,并生成相应的网表文件(Verilog文件和edif文件),该过程适用于需要将一个模块作为顶层设计进行综合,并生成用于其他工程中的网表文件的情况。 例如要将fpga_top模块制作成网表给其它工…...

JAVA生产环境(IDEA)排查死锁
使用 IntelliJ IDEA 排查死锁 IntelliJ IDEA 提供了强大的工具来帮助开发者排查死锁问题。以下是具体的排查步骤: 1. 编写并运行代码 首先,我们编写一个可能导致死锁的示例代码: public class DeadlockExample {private static final Obj…...

Mac 下使用多版本 Node
一、导读 使用 n 实现 Mac 下 Nodejs 的多版本切换,需要先安装一个版本的 Node.js,然后使用 npm 安装 n,再通过 n 管理 node 的多版本切换。 二、使用 npm 全局安装 n sudo npm install -g n 三、根据需求安装指定版本的 node sudo -E n…...

AI学习记录 - 最简单的专家模型 MOE
代码 import torch import torch.nn as nn import torch.nn.functional as F from typing import Tupleclass BasicExpert(nn.Module):# 一个 Expert 可以是一个最简单的, linear 层即可# 也可以是 MLP 层# 也可以是 更复杂的 MLP 层(active function 设…...

【2025深度学习系列专栏大纲:深入探索与实践深度学习】
第一部分:深度学习基础篇 第1章:深度学习概览 1.1 深度学习的历史背景与发展轨迹 1.2 深度学习与机器学习、传统人工智能的区别与联系 1.3 深度学习的核心组件与概念解析 神经网络基础 激活函数的作用与类型 损失函数与优化算法的选择 1.4 深度学习框架简介与选择建议 第2…...

DDD聚合在 ASP.NET Core中的实现
目录 工作单元(UnitOfWork)的实现 聚合与聚合根的实现 实现 聚合与DbContext的关系 区分聚合根实体和其他实体 跨表查询 实现实体不要面向数据库建模 工作单元(UnitOfWork)的实现 EFCore的DbContext:跟踪对象状…...

数据治理双证通关经验分享 | CDGA/CDGP备考全指南
历经1个月多的系统准备,本人于2024年顺利通过DAMA China的CDGA(数据治理工程师)和CDGP(数据治理专家)双认证。现将备考经验与资源体系化整理,助力从业者高效通关。 🌟 认证价值与政策背景 根据…...

Aitken 逐次线性插值
Aitken 逐次线性插值 用 Lagrange 插值多项式 L n ( x ) L_n(x) Ln(x)计算函数近似值时,如需增加插值节点,那么原来算出的数据均不能利用,必须重新计算。为克服这个缺点,可用逐次线性插值方法求得高次插值。 令 I i 1 , i 2…...

亚信安全正式接入DeepSeek
亚信安全致力于“数据驱动、AI原生”战略,早在2024年5月,推出了“信立方”安全大模型、安全MaaS平台和一系列安全智能体,为网络安全运营、网络安全检测提供AI技术能力。自2024年12月DeepSeek-V3发布以来,亚信安全人工智能实验室利…...

unet学习(初学者 自用)
代码解读 | 极简代码遥感语义分割,结合GDAL从零实现,以U-Net和建筑物提取为例 以上面链接中的代码为例,逐行解释。 训练 unet的train.py如下: import torch.nn as nn import torch import gdal import numpy as np from torch…...

HTML之JavaScript运算符
HTML之JavaScript运算符 1.算术运算符 - * / %除以0,结果为Infinity取余数,如果除数为0,结果为NaN NAN:Not A Number2.复合赋值运算符 - * / %/ 除以0,结果为Infinity% 如果除数为0,结果为NaN NaN:No…...

CCFCSP第34次认证第一题——矩阵重塑(其一)
第34次认证第一题——矩阵重塑(其一) 官网链接 时间限制: 1.0 秒 空间限制: 512 MiB 相关文件: 题目目录(样例文件) 题目背景 矩阵(二维)的重塑(reshap…...

探索B-树系列
🌈前言🌈 本文将讲解B树系列,包含 B-树,B树,B*树,其中主要讲解B树底层原理,为什么用B树作为外查询的数据结构,以及B-树插入操作并用代码实现;介绍B树、B*树。 Ǵ…...

【Copilot】Redis SCAN SSCAN
目录 SCAN 命令SSCAN 命令使用示例原理Redis SCAN 和 SSCAN 命令的注意事项及风险注意事项风险 以下内容均由Github Copilot生成。 SCAN 和 SSCAN 命令是 Redis 提供的用于增量迭代遍历键或集合元素的命令。它们的主要优点是可以避免一次性返回大量数据,从而减少对 …...

GRN前沿:DeepMCL:通过深度多视图对比学习从单细胞基因表达数据推断基因调控网络
1.论文原名:Inferring gene regulatory networks from single-cell gene expression data via deep multi-view contrastive learning 2.发表日期:2023 摘要: 基因调控网络(GRNs)的构建对于理解细胞内复杂的调控机制…...

在软件产品从开发到上线过程中,不同阶段可能出现哪些问题,导致软件最终出现线上bug
在软件产品从开发到上线的全生命周期中,不同阶段都可能因流程漏洞、技术疏忽或人为因素导致线上问题。以下是各阶段常见问题及典型案例: 1. 需求分析与设计阶段 问题根源:业务逻辑不清晰或设计缺陷 典型问题: 需求文档模糊&#…...

Linux 内核架构入门:从基础概念到面试指南*
1. 引言 Linux 内核是现代操作系统的核心,负责管理硬件资源、提供系统调用、处理进程调度等功能。对于初学者来说,理解 Linux 内核的架构是深入操作系统开发的第一步。本篇博文将详细介绍 Linux 内核的架构体系,结合硬件、子系统及软件支持的…...

【竞技宝】PGL瓦拉几亚S4预选:Tidebound2-0轻取spiky
北京时间2月13日,DOTA2的PGL瓦拉几亚S4预选赛继续进行,昨日进行的中国区预选赛胜者组首轮Tidebound对阵的spiky比赛中,以下是本场比赛的详细战报。 第一局: 首局比赛,spiky在天辉方,Tidebound在夜魇方。阵容方面,spiky点出了幻刺、火枪、猛犸、小强、巫妖,Tidebound则是拿到飞…...

C#学习之DateTime 类
目录 一、DateTime 类的常用方法和属性的汇总表格 二、常用方法程序示例 1. 获取当前本地时间 2. 获取当前 UTC 时间 3. 格式化日期和时间 4. 获取特定部分的时间 5. 获取时间戳 6. 获取时区信息 三、总结 一、DateTime 类的常用方法和属性的汇总表格 在 C# 中&#x…...

EasyRTC智能硬件:小体积,大能量,开启音视频互动新体验
在万物互联的时代,智能硬件正以前所未有的速度融入我们的生活。然而,受限于硬件性能和网络环境,许多智能硬件在音视频互动体验上仍存在延迟高、卡顿、回声等问题,严重影响了用户的使用体验。 EasyRTC智能硬件,凭借其强…...