机器学习算法 - 随机森林之决策树初探(1)
随机森林是基于集体智慧的一个机器学习算法,也是目前最好的机器学习算法之一。
随机森林实际是一堆决策树的组合(正如其名,树多了就是森林了)。在用于分类一个新变量时,相关的检测数据提交给构建好的每个分类树。每个树给出一个分类结果,最终选择被最多的分类树支持的分类结果。回归则是不同树预测出的值的均值。
要理解随机森林,我们先学习下决策树。
决策树 - 把你做选择的过程呈现出来
决策树是一个很直观的跟我们日常做选择的思维方式很相近的一个算法。
如果有一个数据集如下:
data <- data.frame(x=c(0,0.5,1.1,1.8,1.9,2,2.5,3,3.6,3.7), color=c(rep('blue',5),rep('green',5)))
data## x color
## 1 0.0 blue
## 2 0.5 blue
## 3 1.1 blue
## 4 1.8 blue
## 5 1.9 blue
## 6 2.0 green
## 7 2.5 green
## 8 3.0 green
## 9 3.6 green
## 10 3.7 green那么假如加入一个新的点,其x值为1,那么该点对应的最可能的颜色是什么?
根据上面的数据找规律,如果x<2.0则对应的点颜色为blue,如果x>=2.0则对应的点颜色为green。这就构成了一个只有一个决策节点的简单决策树。

决策树常用来回答这样的问题:给定一个带标签的数据集(标签这里对应我们的color列),怎么来对新加入的数据集进行分类?
如果数据集再复杂一些,如下,
data <- data.frame(x=c(0,0.5,1.1,1.8,1.9,2,2.5,3,3.6,3.7),y=c(1,0.5,1.5,2.1,2.8,2,2.2,3,3.3,3.5),color=c(rep('blue',3),rep('red',2),rep('green',5)))data## x y color
## 1 0.0 1.0 blue
## 2 0.5 0.5 blue
## 3 1.1 1.5 blue
## 4 1.8 2.1 red
## 5 1.9 2.8 red
## 6 2.0 2.0 green
## 7 2.5 2.2 green
## 8 3.0 3.0 green
## 9 3.6 3.3 green
## 10 3.7 3.5 green
-
如果
x>=2.0则对应的点颜色为green。 -
如果
x<2.0则对应的点颜色可能为blue,也可能为red。
这时就需要再加一个新的决策节点,利用变量y的信息。

这就是决策树,也是我们日常推理问题的一般方式。
训练决策树 - 确定决策树的根节点
第一个任务是确定决策树的根节点:选择哪个变量和对应阈值选择多少能给数据做出最好的区分。
比如上面的例子,我们可以先处理变量x,选择阈值为2 (为什么选2,是不是有比2更合适阈值,我们后续再说),则可获得如下分类:

我们也可以先处理变量y,选择阈值为2,则可获得如下分类:

那实际需要选择哪个呢?
实际我们是希望每个选择的变量和阈值能把不同的类分的越开越好;上面选择变量x分组时,Green完全分成一组;下面选择y分组时,Blue完全分成一组。怎么评价呢?
这时就需要一个评价指标,常用的指标有Gini inpurity和Information gain。
Gini Impurity
在数据集中随机选择一个数据点,并随机分配给它一个数据集中存在的标签,分配错误的概率即为Gini impurity。
我们先看第一套数据集,10个数据点,5个blue,5个green。从中随机选一个数据点,再随机选一个分类标签作为这个数据点的标签,分类错误的概率是多少?如下表,错误概率为0.25+0.25=0.5(看下面的计算过程)。
probility <- data.frame(Event=c("Pick Blue, Classify Blue","Pick Blue, Classify Green","Pick Green, Classify Blue","Pick Green, Classify Green"), Probability=c(5/10 * 5/10, 5/10 * 5/10, 5/10 * 5/10, 5/10 * 5/10),Type=c("Blue" == "Blue","Blue" == "Green","Green" == "Blue","Green" == "Green"))
probility## Event Probability Type
## 1 Pick Blue, Classify Blue 0.25 TRUE
## 2 Pick Blue, Classify Green 0.25 FALSE
## 3 Pick Green, Classify Blue 0.25 FALSE
## 4 Pick Green, Classify Green 0.25 TRUE我们再看第二套数据集,10个数据点,2个red,3个blue,5个green。从中随机选一个数据点,再随机选一个分类标签作为这个数据点的标签,分类错误的概率是多少?0.62。
probility <- data.frame(Event=c("Pick Blue, Classify Blue","Pick Blue, Classify Green","Pick Blue, Classify Red","Pick Green, Classify Blue","Pick Green, Classify Green","Pick Green, Classify Red","Pick Red, Classify Blue","Pick Red, Classify Green","Pick Red, Classify Red"),Probability=c(3/10 * 3/10, 3/10 * 5/10, 3/10 * 2/10, 5/10 * 3/10, 5/10 * 5/10, 5/10 * 2/10,2/10 * 3/10, 2/10 * 5/10, 2/10 * 2/10),Type=c("Blue" == "Blue","Blue" == "Green","Blue" == "Red","Green" == "Blue","Green" == "Green","Green" == "Red","Red" == "Blue","Red" == "Green","Red" == "Red"))
probility## Event Probability Type
## 1 Pick Blue, Classify Blue 0.09 TRUE
## 2 Pick Blue, Classify Green 0.15 FALSE
## 3 Pick Blue, Classify Red 0.06 FALSE
## 4 Pick Green, Classify Blue 0.15 FALSE
## 5 Pick Green, Classify Green 0.25 TRUE
## 6 Pick Green, Classify Red 0.10 FALSE
## 7 Pick Red, Classify Blue 0.06 FALSE
## 8 Pick Red, Classify Green 0.10 FALSE
## 9 Pick Red, Classify Red 0.04 TRUEWrong_probability = sum(probility[!probility$Type,"Probability"])
Wrong_probability## [1] 0.62Gini Impurity计算公式:
假如我们的数据点共有C个类,p(i)是从中随机拿到一个类为i的数据,Gini Impurity计算公式为:
$$ G = \sum_{i=1}^{C} p(i)*(1-p(i)) $$

对第一套数据集,10个数据点,5个blue,5个green。从中随机选一个数据点,再随机选一个分类标签作为这个数据点的标签,分类错误的概率是多少?错误概率为0.25+0.25=0.5。

对第二套数据集,10个数据点,2个red,3个blue,5个green。
从中随机选一个数据点,再随机选一个分类标签作为这个数据点的标签,分类错误的概率是多少?0.62。

决策树分类后的Gini Impurity
对第一套数据集来讲,按照x<2分成两个分支,各个分支都只包含一个分类数据,各自的Gini IMpurity值为0。
这是一个完美的决策树,把Gini Impurity为0.5的数据集分类为2个Gini Impurity为0的数据集。Gini Impurity== 0是能获得的最好的分类结果。


第二套数据集,我们有两种确定根节点的方式,哪一个更优呢?
我们可以先处理变量x,选择阈值为2,则可获得如下分类:
每个分支的Gini Impurity可以如下计算:

当前决策的Gini impurity需要对各个分支包含的数据点的比例进行加权,即

我们也可以先处理变量y,选择阈值为2,则可获得如下分类:
每个分支的Gini Impurity可以如下计算:

当前决策的Gini impurity需要对各个分支包含的数据点的比例进行加权,即

两个数值比较0.24<0.29,选择x作为第一个分类节点是我们第二套数据第一步决策树的最佳选择。
前面手算单个变量、单个分组不算麻烦,也是个学习的过程。后续如果有更多变量和阈值时,再手算就不合适了。下一篇我们通过暴力方式自写函数训练决策树。
当前计算的结果,可以作为正对照,确定后续函数结果的准确性。(NBT:你想成为计算生物学家?)
参考:
-
https://victorzhou.com/blog/intro-to-random-forests/
-
https://victorzhou.com/blog/gini-impurity/
-
https://stats.stackexchange.com/questions/192310/is-random-forest-suitable-for-very-small-data-sets
-
https://towardsdatascience.com/understanding-random-forest-58381e0602d2
-
https://www.stat.berkeley.edu/~breiman/RandomForests/reg_philosophy.html
-
https://medium.com/@williamkoehrsen/random-forest-simple-explanation-377895a60d2d
相关文章:
机器学习算法 - 随机森林之决策树初探(1)
随机森林是基于集体智慧的一个机器学习算法,也是目前最好的机器学习算法之一。 随机森林实际是一堆决策树的组合(正如其名,树多了就是森林了)。在用于分类一个新变量时,相关的检测数据提交给构建好的每个分类树。每个…...

原生Three.js 和 Cesium.js 案例 。 智慧城市 数字孪生常用功能列表
对于大多数的开发者来言,看了很多文档可能遇见不到什么有用的,就算有用从文档上看,把代码复制到自己的本地大多数也是不能用的,非常浪费时间和学习成本, 尤其是three.js , cesium.js 这种难度较高ÿ…...

在 PyCharm 中接入deepseek的API的各种方法
在 PyCharm 中接入 DeepSeek 的 API,通常需要以下步骤: 1. 获取 DeepSeek API 密钥 首先,确保你已经在 DeepSeek 平台上注册并获取了 API 密钥(API Key)。如果没有,请访问 DeepSeek 的官方网站注册并申请 …...

Haskell语言的软件工程
Haskell语言的软件工程 引言 在软件工程的领域中,选择合适的编程语言是每个开发者都需要面对的重要决策。作为一种功能强大的函数式编程语言,Haskell凭借其独特的特性和优势逐渐在许多软件项目中占据一席之地。本文将深入探讨Haskell语言在软件工程中的…...

【2025新】基于springboot的问卷调查小程序设计与实现
目录 一、整体目录(示范): 文档含项目技术介绍、E-R图、数据字典、项目功能介绍与截图等 二、运行截图 三、代码部分(示范): 四、数据库表(示范): 数据库表有注释,可以导出数据…...

数据结构——Makefile、算法、排序(2025.2.13)
目录 一、Makefile 1.功能 2.基本语法和相关操作 (1)创建Makefile文件 (2)编译规则 (3)编译 (4)变量 ①系统变量 ②自定义变量 二、 算法 1.定义 2.算法的设计 ÿ…...

思科、华为、H3C常用命令对照表
取消/关闭 思科no华为undo华三undo 查看 思科show华为display华三display 退出 思科exit华为quit华三quit 设备命名 思科hostname华为sysname华三sysname 进入全局模式 思科enable、config terminal华为system-view华三system-view 删除文件 思科delete华为delete华…...

learn_pytorch
第三章 深度学习分为如下几个步骤 1:数据预处理,划分训练集和测试集 2:选择模型,设定损失函数和优化函数 3:用模型取拟合训练数据,并在验证计算模型上表现。 接着学习了一些数据读入 模型构建 损失函数的构…...

什么是Docker多架构容器镜像
什么是Docker多架构容器镜像 在 Docker 中,同一个 Docker 镜像可以在不同的平台上运行,例如在 x86、ARM、PowerPC 等不同的 CPU 架构上。 为了支持这种多平台的镜像构建和管理,Docker 在 17.06 版本时引入了 Manifest 的概念,在…...

【devops】 Git仓库如何fork一个私有仓库到自己的私有仓库 | git fork 私有仓库
一、场景说明 场景: 比如我们Codeup的私有仓库下载代码 放入我们的Github私有仓库 且保持2个仓库是可以实现fork的状态,即:Github会可以更新到Codeup的最新代码 二、解决方案 1、先从Codeup下载私有仓库代码 下载代码使用 git clone 命令…...

【Elasticsearch】字符过滤器Character Filters
在 Elasticsearch 中,字符过滤器(Character Filters)是文本分析器的重要组成部分,用于在分词之前对原始文本进行预处理。它们可以对字符流进行转换,例如添加、删除或更改字符。Elasticsearch 提供了三种内置的字符过滤…...

RocketMQ及和Kafka的区别
目录 1 从场景入手2 RocketMQ是什么?3 RocketMQ及和Kafka的区别3.1 在架构上做了减法3.1.1 简化协调节点3.1.2 简化分区3.1.3 底层存储3.1.3.1 Kafka底层存储3.1.3.1 RocketMQ底层存储 3.1.4 简化备份模型3.1.4.1 Kafka备份模型3.1.4.2 RocketMQ备份模型 3.1.5 Rock…...

设置ollama接口能外部访问
为了配置Ollama以允许外网访问,你可以按照以下步骤进行操作: 确认Ollama服务已正确安装并运行: 使用以下命令检查Ollama服务的状态: bash Copy Code systemctl status ollama如果服务未运行,使用以下命令启动它&…...

数组_移除元素
数组_移除元素 一、leetcode-27二、题解1.代码2.思考 一、leetcode-27 移除元素 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。 假设 nums 中不等于 val 的元素数…...

【含文档+PPT+源码】基于微信小程序的乡村振兴民宿管理系统
项目介绍 本课程演示的是一款基于微信小程序的乡村振兴民宿管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套系统 3.该…...

macOs在vscode编辑器的cmd中,比如npm i 总是提示权限不够需要sudo
mac Os Apple M2 Pro在vscode 编辑器的cmd中比如npm i 总是提示权限不够,总要sudo npm i : 报错如下: npm warn peer webpack"^2.0.0 || ^3.0.0 || ^4.0.0" from the root project npm error code EACCES npm error syscall open npm error p…...

Vim 退出编辑模式
1. 按 Esc 键 按下键盘上的 Esc 键是最常见和推荐的方式。这会将光标从插入模式切换回普通模式。按下 Esc 键后,你就可以使用普通模式下的命令进行编辑。 2. 使用 Ctrl [ 在一些终端中,你也可以使用组合键 Ctrl [ 来模拟按下 Esc 键的效果。这对于一…...
 中实现流程图中的连线算法)
【流程图】在 .NET (WPF 或 WinForms) 中实现流程图中的连线算法
在 .NET (WPF 或 WinForms) 中实现流程图中的连线算法,通常涉及 图形绘制 和 路径计算。常见的连线方式包括 直线、折线 和 贝塞尔曲线。以下是几种方法的介绍和示例代码。 1. 直线连接(最简单) 适用场景: 两个节点之间没有障碍…...

Linux查找占用的端口,并杀死进程的简单方法
在Linux系统管理中,识别并管理占用特定端口的进程是一项常见且重要的任务。以下是优化过的步骤指南,帮助您高效地完成这一操作,同时提供了一个简洁的命令参考表。 Linux下识别并终止占用端口的进程 1. 探寻端口占用者 使用 lsof命令 lsof…...
)
【python语言应用】最新全流程Python编程、机器学习与深度学习实践技术应用(帮助你快速了解和入门 Python)
近年来,人工智能领域的飞速发展极大地改变了各个行业的面貌。当前最新的技术动态,如大型语言模型和深度学习技术的发展,展示了深度学习和机器学习技术的强大潜力,成为推动创新和提升竞争力的关键。特别是PyTorch,凭借其…...

Datawhale Ollama教程笔记3
小白的看课思路: Ollama REST API 是什么? 想象一下,你有一个智能的“盒子”(Ollama),里面装了很多聪明的“小助手”(语言模型)。如果你想让这些“小助手”帮你完成一些任务&#…...
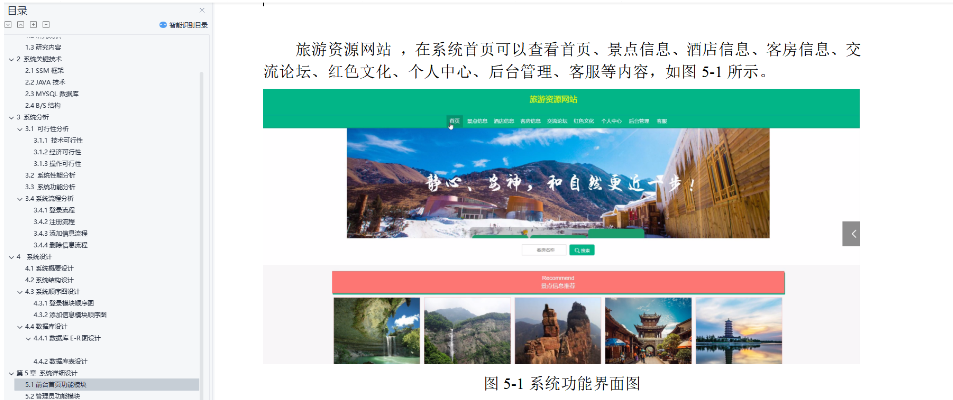
基于JavaWeb开发的Java+Spring+vue+element实现旅游信息管理平台系统
基于JavaWeb开发的JavaSpringvueelement实现旅游信息管理平台系统 🍅 作者主页 网顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 🍅 查看下方微信号获取联系方式 承接各…...

基础网络详解4--HTTP CookieSession 思考 2
一、Cookie与Set-Cookie 1. Cookie 定义: Cookie 是客户端(通常是浏览器)存储的一小段数据,由服务器通过 Set-Cookie 响应头设置,并在后续请求中通过 Cookie 请求头发送回服务器。作用: 用于在客户端保存状态信息,例…...

2.14日学习总结
题目一:接雨水问题 1.题目描述:给定一个数组 height 表示一个地形的高度图,数组中的每个元素代表每个宽度为 1 的柱子的高度。计算按此排列的柱子,下雨之后能接多少雨水。 2.示例:输入 height [0,1,0,2,1,0,1,3,2,1…...

【技术产品】DS三剑客:DeepSeek、DataSophon、DolphineSchduler浅析
引言 在大数据与云原生技术快速发展的时代,开源技术成为推动行业进步的重要力量。本文将深入探讨三个备受瞩目的开源产品组件:DeepSeek、DataSophon 和 DolphinScheduler,分别从产品定义、功能、技术架构、应用场景、优劣势及社区活跃度等方面…...

Go 语言里中的堆与栈
在 Go 语言里,堆和栈是内存管理的两个重要概念,它们在多个方面存在明显差异: 1. 内存分配与回收方式 栈 分配:Go 语言中,栈内存主要用于存储函数的局部变量和调用信息。当一个函数被调用时,Go 会自动为其…...

云计算实训室解决方案(2025年最新版)
一、中高职及本科院校在云计算专业建设中面临的挑战 随着大数据、信息安全、人工智能等新兴信息技术产业的快速发展,相关领域人才需求激增,许多本科及职业院校纷纷开设云计算及相关专业方向。 然而,大多数院校在专业建设过程中面临以下困难&…...

我的新书《青少年Python趣学编程(微课视频版)》出版了!
🎉 激动人心的时刻来临啦! 🎉 小伙伴们久等了,我的第一本新书 《青少年Python趣学编程(微课视频版)》 正式出版啦! 📚✨ 在这个AI时代,市面上的Python书籍常常过于枯燥&…...

网络安全要学python 、爬虫吗
网络安全其实并不复杂,只是比普通开发岗位要学习的内容多一点。无论是有过编程基础还是零基础的都可以学习的。网络安全目前可就业的岗位从技术上可分为两部分:web安全和二进制逆向安全。web安全是网络安全的入门方向,内容简单,就…...

DBSCAN 基于密度的空间带噪聚类法
DBSCAN 基于密度的空间带噪聚类法 DBSCAN(Density - Based Spatial Clustering of Applications with Noise)即基于密度的空间聚类算法,它是一种典型的密度聚类算法,以下从核心概念、算法步骤、优缺点及应用场景等方面进行解释。…...