动手学深度学习11.7. AdaGrad算法-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。
本节课程地址:72 优化算法【动手学深度学习v2】_哔哩哔哩_bilibili
本节教材地址:11.7. AdaGrad算法 — 动手学深度学习 2.0.0 documentation
本节开源代码:...>d2l-zh>pytorch>chapter_optimization>adagrad.ipynb
AdaGrad算法
我们从有关特征学习中并不常见的问题入手。
稀疏特征和学习率
假设我们正在训练一个语言模型。 为了获得良好的准确性,我们大多希望在训练的过程中降低学习率,速度通常为 或更低。 现在讨论关于稀疏特征(即只在偶尔出现的特征)的模型训练,这对自然语言来说很常见。 例如,我们看到“预先条件”这个词比“学习”这个词的可能性要小得多。 但是,它在计算广告学和个性化协同过滤等其他领域也很常见。
只有在这些不常见的特征出现时,与其相关的参数才会得到有意义的更新。 鉴于学习率下降,我们可能最终会面临这样的情况:常见特征的参数相当迅速地收敛到最佳值,而对于不常见的特征,我们仍缺乏足够的观测以确定其最佳值。 换句话说,学习率要么对于常见特征而言降低太慢,要么对于不常见特征而言降低太快。
解决此问题的一个方法是记录我们看到特定特征的次数,然后将其用作调整学习率。 即我们可以使用大小为 的学习率,而不是
。 在这里
计下了我们截至
时观察到功能
的次数。 这其实很容易实施且不产生额外损耗。
AdaGrad算法 (ef="https://zh-v2.d2l.ai/chapter_references/zreferences.html#id36">Duchiet al., 2011) 通过将粗略的计数器 替换为先前观察所得梯度的平方之和来解决这个问题。 它使用
来调整学习率。 这有两个好处:首先,我们不再需要决定梯度何时算足够大。 其次,它会随梯度的大小自动变化。通常对应于较大梯度的坐标会显著缩小,而其他梯度较小的坐标则会得到更平滑的处理。 在实际应用中,它促成了计算广告学及其相关问题中非常有效的优化程序。 但是,它遮盖了AdaGrad固有的一些额外优势,这些优势在预处理环境中很容易被理解。
预处理
凸优化问题有助于分析算法的特点。 毕竟对大多数非凸问题来说,获得有意义的理论保证很难,但是直觉和洞察往往会延续。 让我们来看看最小化 这一问题。
正如在 11.6节 中那样,我们可以根据其特征分解 重写这个问题,来得到一个简化得多的问题,使每个坐标都可以单独解出:
在这里我们使用了 ,且因此
。 修改后最小化器为
且最小值为
。 这样更容易计算,因为
是一个包含
特征值的对角矩阵。
如果稍微扰动 ,我们会期望在
的最小化器中只产生微小的变化。 遗憾的是,情况并非如此。 虽然
的微小变化导致了
同样的微小变化,但
的(以及
的)最小化器并非如此。 每当特征值
很大时,我们只会看到
和
的最小值发生微小变化。 相反,对小的
来说,
的变化可能是剧烈的。 最大和最小的特征值之比称为优化问题的条件数(condition number)。
如果条件数 很大,准确解决优化问题就会很难。 我们需要确保在获取大量动态的特征值范围时足够谨慎:难道我们不能简单地通过扭曲空间来“修复”这个问题,从而使所有特征值都是1? 理论上这很容易:我们只需要
的特征值和特征向量即可将问题从
整理到
中的一个。 在新的坐标系中,
可以被简化为
。 可惜,这是一个相当不切实际的想法。 一般而言,计算特征值和特征向量要比解决实际问题“贵”得多。
虽然准确计算特征值可能会很昂贵,但即便只是大致猜测并计算它们,也可能已经比不做任何事情好得多。 特别是,我们可以使用 Q 的对角线条目并相应地重新缩放它。 这比计算特征值开销小的多。
在这种情况下,我们得到了 ,特别注意对于所有
,
。 在大多数情况下,这大大简化了条件数。 例如我们之前讨论的案例,它将完全消除眼下的问题,因为问题是轴对齐的。
遗憾的是,我们还面临另一个问题:在深度学习中,我们通常情况甚至无法计算目标函数的二阶导数:对于 ,即使只在小批量上,二阶导数可能也需要
空间来计算,导致几乎不可行。 AdaGrad算法巧妙的思路是,使用一个代理来表示黑塞矩阵(Hessian)的对角线,既相对易于计算又高效。
为了了解它是如何生效的,让我们来看看 。 我们有
其中 是
的最小化器。 因此,梯度的大小取决于
和
与最佳值的差值。 如果
没有改变,那这就是我们所求的。 毕竟在这种情况下,梯度
的大小就足够了。 由于AdaGrad算法是一种随机梯度下降算法,所以即使是在最佳值中,我们也会看到具有非零方差的梯度。 因此,我们可以放心地使用梯度的方差作为黑塞矩阵比例的廉价替代。 详尽的分析(要花几页解释)超出了本节的范围,请读者参考(ef="https://zh-v2.d2l.ai/chapter_references/zreferences.html#id36">Duchiet al., 2011)。
算法
让我们接着上面正式开始讨论。 我们使用变量 来累加过去的梯度方差,如下所示:
在这里,操作是按照坐标顺序应用。 也就是说, 有条目
。 同样,
有条目
, 并且
有条目
。 与之前一样,
是学习率,
是一个为维持数值稳定性而添加的常数,用来确保我们不会除以 0 。 最后,我们初始化
。
就像在动量法中我们需要跟踪一个辅助变量一样,在AdaGrad算法中,我们允许每个坐标有单独的学习率。 与SGD算法相比,这并没有明显增加AdaGrad的计算代价,因为主要计算用在 及其导数。
请注意,在 中累加平方梯度意味着
基本上以线性速率增长(由于梯度从最初开始衰减,实际上比线性慢一些)。 这产生了一个学习率
,但是在单个坐标的层面上进行了调整。 对于凸问题,这完全足够了。 然而,在深度学习中,我们可能希望更慢地降低学习率。 这引出了许多AdaGrad算法的变体,我们将在后续章节中讨论它们。 眼下让我们先看看它在二次凸问题中的表现如何。 我们仍然以同一函数为例:
我们将使用与之前相同的学习率来实现AdaGrad算法,即 。 可以看到,自变量的迭代轨迹较平滑。 但由于 st 的累加效果使学习率不断衰减,自变量在迭代后期的移动幅度较小。
%matplotlib inline
import math
import torch
from d2l import torch as d2l
def adagrad_2d(x1, x2, s1, s2):eps = 1e-6g1, g2 = 0.2 * x1, 4 * x2s1 += g1 ** 2s2 += g2 ** 2x1 -= eta / math.sqrt(s1 + eps) * g1x2 -= eta / math.sqrt(s2 + eps) * g2return x1, x2, s1, s2def f_2d(x1, x2):return 0.1 * x1 ** 2 + 2 * x2 ** 2eta = 0.4
d2l.show_trace_2d(f_2d, d2l.train_2d(adagrad_2d))输出结果:
epoch 20, x1: -2.382563, x2: -0.158591

我们将学习率提高到 2,可以看到更好的表现。 这已经表明,即使在无噪声的情况下,学习率的降低可能相当剧烈,我们需要确保参数能够适当地收敛。
eta = 2
d2l.show_trace_2d(f_2d, d2l.train_2d(adagrad_2d))输出结果:
epoch 20, x1: -0.002295, x2: -0.000000

从零开始实现
同动量法一样,AdaGrad算法需要对每个自变量维护同它一样形状的状态变量。
def init_adagrad_states(feature_dim):s_w = torch.zeros((feature_dim, 1))s_b = torch.zeros(1)return (s_w, s_b)def adagrad(params, states, hyperparams):eps = 1e-6for p, s in zip(params, states):with torch.no_grad():s[:] += torch.square(p.grad)p[:] -= hyperparams['lr'] * p.grad / torch.sqrt(s + eps)p.grad.data.zero_()与 11.5节 一节中的实验相比,这里使用更大的学习率来训练模型。
data_iter, feature_dim = d2l.get_data_ch11(batch_size=10)
d2l.train_ch11(adagrad, init_adagrad_states(feature_dim),{'lr': 0.1}, data_iter, feature_dim)输出结果:
loss: 0.242, 0.029 sec/epoch

简洁实现
我们可直接使用深度学习框架中提供的AdaGrad算法来训练模型。
trainer = torch.optim.Adagrad
d2l.train_concise_ch11(trainer, {'lr': 0.1}, data_iter)输出结果:
loss: 0.242, 0.011 sec/epoch

小结
- AdaGrad算法会在单个坐标层面动态降低学习率。
- AdaGrad算法利用梯度的大小作为调整进度速率的手段:用较小的学习率来补偿带有较大梯度的坐标。
- 在深度学习问题中,由于内存和计算限制,计算准确的二阶导数通常是不可行的。梯度可以作为一个有效的代理。
- 如果优化问题的结构相当不均匀,AdaGrad算法可以帮助缓解扭曲。
- AdaGrad算法对于稀疏特征特别有效,在此情况下由于不常出现的问题,学习率需要更慢地降低。
- 在深度学习问题上,AdaGrad算法有时在降低学习率方面可能过于剧烈。我们将在 11.10节 一节讨论缓解这种情况的策略。
练习
- 证明对于正交矩阵
和向量
,以下等式成立:
。为什么这意味着在变量的正交变化之后,扰动的程度不会改变?
解:
对于正交矩阵,其中
是单位矩阵。
根据欧几里得范数的定义,展开
,可得:
由于,故上式可以简化为:
而展开为:
因此:
等式两边同时开平方根,即证:
以上证明表明,由于正交变换保持了向量之间的欧几里得距离不变,所以在变量的正交变化之后,扰动的程度不会改变。 - 尝试对函数
、以及它旋转45度后的函数即
使用AdaGrad算法。它的表现会不同吗?
解:
对于旋转后的,AdaGrad算法也是使学习率不断衰减,自变量在迭代后期的移动幅度较小。
同时,旋转后的函数在梯度方向上更加对称,这有助于AdaGrad算法更均匀地调整学习率,进一步提高了收敛性。
代码如下:
def f_2d_rotation(x1, x2):return 0.1 * (x1 + x2) ** 2 + 2 * (x1 - x2) ** 2def adagrad_2d_rotation(x1, x2, s1, s2):eps = 1e-6g1, g2 = 4.2 * x1 - 3.8 * x2, 4.2 * x2 - 3.8 * x1s1 += g1 ** 2s2 += g2 ** 2x1 -= eta / math.sqrt(s1 + eps) * g1x2 -= eta / math.sqrt(s2 + eps) * g2return x1, x2, s1, s2d2l.show_trace_2d(f_2d_rotation, d2l.train_2d(adagrad_2d_rotation))输出结果:
epoch 20, x1: -1.054791, x2: -1.046482

3. 证明格什戈林圆盘定理,其中提到,矩阵 的特征值
在至少一个
的选项中满足
的要求。
解:
格什戈林圆盘定理可用于估计矩阵特征值的范围,具体定义是指:
对于任意一个 复数矩阵
,其特征值
满足:
对于每一个 ,存在至少一个
使得
位于以
为中心,半径为
的圆盘内,即:
证明如下:
是对应于
的特征向量,即
,且
。
设 满足
,且因为
,所以
。
将 按分量展开,得到
。
把等式左边的 单独分离出来,移项可得:
对上式两边取绝对值,根据绝对值不等式 ,有
。
又由于 ,所以对于所有的
,都有
。
由此可得:
上式两边同时除以 ,即证
。
4. 关于对角线预处理矩阵 的特征值,格什戈林的定理告诉了我们什么?
解:
对于 阶矩阵
,
,令
,是一个对角矩阵,其对角元素
(假设
)。
则对角线预处理矩阵 ,其中
为:
对于矩阵 的特征值
,根据格什戈林定理,至少存在一个
使得:
将 代入上述不等式,可得:
所以,格什戈林的定理告诉我们,对角线预处理矩阵 的特征值至少位于以 1 为圆心,以
为半径的圆盘内。这为我们估计预处理后矩阵的特征值提供了一个直观的几何区域,有助于判断特征值大致分布在哪些范围内。 通过这些圆盘的位置和大小,我们可以对预处理后矩阵的一些性质进行分析。例如,如果所有圆盘都集中在复平面上靠近 1 的位置,说明预处理后的矩阵的特征值相对比较集中,可能具有较好的条件数,这在数值计算中对于迭代算法的收敛性等方面是有利的;反之,如果圆盘分布比较分散,则特征值的分布范围较广,可能会对数值计算带来一些挑战。
5. 尝试对适当的深度网络使用AdaGrad算法,例如,6.6节 中应用于Fashion-MNIST的深度网络。
解:
代码如下:
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def train_ch6_optimizer(net, optimizer, train_iter, test_iter, num_epochs, lr, device):def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
lr, num_epochs = 0.01, 10
optimizer = torch.optim.Adagrad(net.parameters(), lr=lr)
train_ch6_optimizer(net, optimizer, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())输出结果:
loss 0.620, train acc 0.759, test acc 0.758
25309.8 examples/sec on cpu

6. 要如何修改AdaGrad算法,才能使其在学习率方面的衰减不那么激进?
解:
AdaGrad 算法通过累积梯度的平方和来调整每个参数的学习率,在训练后期,由于梯度平方和的不断累积,学习率会衰减得非常快,导致参数更新变得缓慢,甚至可能使模型提前停止学习。可以做如下改进:
- 11.8节的RMSProp算法是基于指数移动平均来改进AdaGrad的学习率衰减问题。它通过对梯度平方的累积和进行指数加权平均,使得学习率的衰减更加平滑。具体算法更改为:
其中γ是衰减率,。
这里是初始学习率,
是一个很小的常数(通常
),用于避免分母为零。
- 11.9节的AdaDelta算法也是对AdaGrad的改进,它不再使用梯度平方的累积和,而是引入了一个指数移动平均的思想,对梯度平方的累积和进行平滑处理,避免了学习率的过度衰减。具体算法更改为:
其中是衰减率,
。
其中是重新缩放的梯度,
其中),用于避免分母为零。
是重新缩放梯度的平方
初始化为0,每步用
下面将RMSProp和AdaDelta应用于Fashion-MNIST的深度网络,与Adagrad算法进行比较,代码如下:
lr, num_epochs = 0.001, 10
optimizer = torch.optim.RMSprop(net.parameters(), lr=lr)
train_ch6_optimizer(net, optimizer, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())输出结果:
loss 0.480, train acc 0.822, test acc 0.816
24535.0 examples/sec on cpu

lr, num_epochs = 0.01, 10
optimizer = torch.optim.Adadelta(net.parameters())
train_ch6_optimizer(net, optimizer, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())输出结果:
loss 0.483, train acc 0.818, test acc 0.801
23222.0 examples/sec on cpu

相关文章:
动手学深度学习11.7. AdaGrad算法-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:72 优化算法【动手学深度学习v2】_哔哩哔哩_bilibili 本节教材地址:11.7. AdaGrad算法…...
)
【鸿蒙开发】第三十六章 状态管理 - (V2)
目录 1 V2所属装饰器 1.1 ObservedV2装饰器和Trace装饰器:类属性变化观测 1、概述 2、装饰器说明 3、使用限制 1.2 ComponentV2装饰器:自定义组件 1、概述 1.3 Local装饰器:组件内部状态 1、概述 2、装饰器说明 3、…...

基础算法# 求一个数的二进制表示当中有几个1 (C++)
文章目录 题目链接题目解读思路完整代码参考 题目链接 题目解读 给定L,R。统计[L,R]区间内的所有数在二进制下包含的“1”的个数之和。 如5的二进制为101,包含2个“1”。 思路 直接将该数字转为二进制表示,求其有几个1即可。 完整代码 #include<bits/stdc.…...

3D机器视觉的类型、应用和未来趋势
3D机器视觉的类型、应用和未来趋势 类型 3D机器视觉技术主要分为以下几类: 立体视觉(Stereo Vision) 通过两个或多个摄像头从不同角度捕捉图像,利用视差计算深度信息,生成3D模型。 结构光(Structured Li…...

【linux】在 Linux 上部署 DeepSeek-r1:32/70b:解决下载中断问题
【linux】在 Linux 上部署 DeepSeek-r1:32/70b:解决下载中断问题 【承接商业广告,如需商业合作请+v17740568442】 文章目录 【linux】在 Linux 上部署 DeepSeek-r1:32/70b:解决下载中断问题问题描述:解决方法方法一:手动中断并重启下载方法二:使用 Bash 脚本自动化下载在…...

什么是高亮环形光源
高亮环形光源是一种常用于机器视觉、工业检测和光学测量的照明设备。其特点是光线均匀、亮度高,并且呈环形分布,能够为被检测物体提供均匀的照明,减少阴影和反光,提高图像采集的质量。 主要特点: 环形设计:光源呈环形分布,适合安装在镜头周围,能够为物体提供均匀的照明…...

SpringBoot+Vue+微信小程序的高校食堂点餐系统
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,我会一一回复,希望帮助更多的人。 系统介绍 食堂点餐系统,作为一款融合现代信息技术的高效餐饮服务利器,以其…...

gitlab修改默认端口
问题:gitlab和zabbix部署在同一台服务器上导致80端口冲突 修改gitlab默认端口为8088: 第一步:修改/etc/gitlab/gitlab.rb文件 nginx[listen_port] 8088 第二步:修改默认的gitlab nginx的web服务80端 /var/opt/git…...

大预言模型|微调大预言模型初探索(LLaMA-Factory)(1)
前言 微调模型通常比从零开始训练一个模型的技术要求低。公司不需要拥有大量的深度学习专家,利用现有的开源工具和库(如Hugging Face的Transformers等),中小型公司可以轻松地使用和微调大型模型,从而快速实现AI能力的集…...

IOTDB安装部署
IOTDB一般用于工业互联网,至于具体的介绍请自行搜索 1.环境准备 安装前需要保证设备上配有 JDK>1.8 的运行环境,并配置好 JAVA_HOME 环境变量。 设置最大文件打开数为 65535。 关闭防火墙 systemctl stop firewalld.service systemctl disable …...

【Day40 LeetCode】动态规划DP 回文子串问题
一、动态规划DP 回文子串问题 1、回文子串 647 dp数组如果采用一维的,很难进行推导。采用二维,一开始的想法是dp[i][j]表示s[i]~s[j]之间回文子串的个数,这样发现在推导递推公式时遇到困难,例如在s[i]s[j]时,不知道s…...

datasets: PyTorch version 2.5.1+cu124 available 这句话是什么意思
这句话的意思是: datasets:可能是 Python datasets 库的日志信息,说明它检测到了 PyTorch 的安装信息。PyTorch version 2.5.1cu124 available: PyTorch version 2.5.1:表示你的 PyTorch 版本是 2.5.1。cu124…...

如何通过MDM高效管理企业的Android平板?
目录 1. 批量配置设备(Batch Device Provisioning) 2. 应用推送与管理(App Deployment & Management) 3. 远程控制与故障排除(Remote Control & Troubleshooting) 4. 数据安全管理(…...

mybatis-plus逆向code generator pgsql实践
mybatis-plus逆向code generator pgsql实践 环境准备重要工具的版本供参考pom依赖待逆向的SQL 配置文件CodeGenerator配置类配置类说明 环境准备 重要工具的版本 jdk1.8.0_131springboot 2.7.6mybatis-plus 3.5.7pgsql 14.15 供参考pom依赖 <?xml version"1.0&quo…...

深入理解DOM:22个核心知识点与代码示例
本文系统介绍DOM相关的22个核心概念,每个知识点均提供代码示例及简要说明,帮助开发者全面掌握DOM操作技巧。 一、DOM基础概念 1. DOM概念 DOM(Document Object Model)是HTML/XML的编程接口,通过JavaScript可动态修改…...

基于YALMIP和cplex工具箱的微电网最优调度算法matlab仿真
目录 1.课题概述 2.系统仿真结果 3.核心程序与模型 4.系统原理简介 4.1 系统建模 4.2 YALMIP工具箱 4.3 CPLEX工具箱 5.完整工程文件 1.课题概述 基于YALMIP和cplex工具箱的微电网最优调度算法matlab仿真。通过YALMIP和cplex这两个工具箱,完成微电网的最优调…...

java.lang.NoClassDefFoundError: javax/xml/bind/ValidationException
Java8升级到17之后, 启动报错, :LocalValidatorFactoryBean]: Factory method defaultValidator threw exception; nested exception is java.lang.NoClassDefFoundError: javax/xml/bind/ValidationException 报错原因:这个错误通常是由于缺少 javax.xml.bind 相关的依赖引起…...

C++ STL容器之list的使用及复现
list 1. 序列式容器 vector、list、deque、forward_list(C11 )等STL容器,其底层为线性序列的数据结构,里面存储的是元素本身,这样的容器被统称为序列式容器。 2. list容器 list 是用双向带哨兵位头节点的循环链表实现的。list 通过类模板…...

二、OpenSM排障----实战生产
目录 一、确认 OpenSM 服务端故障的步骤 1. 检查客户端与服务器的连通性 2. 检查客户端 InfiniBand 接口状态 3. 检查子网管理器状态 4. 检查拓扑信息 5. 检查路由表 二、客户端日志位置及查看方法 1. 系统日志 2. OpenSM 客户端日志 3. 内核日志 4. 性能计数器日志…...

Windows 找不到文件gpedit.msc,没有组策略编辑器,解决办法附上
windows10和11都通用。是不是有人告诉你家庭版本没有gpedit.msc,没有组策略编辑器?这压根就是某软玩的小把戏。Win10/11家庭版可通过修改文件后缀新建bat脚本,添加组策略包,以管理员身份运行后,输入gpedit.msc即可打开…...

基于Docker-compose的禅道部署实践:自建MySQL与Redis集成及故障排查指南
基于Docker-compose的禅道部署实践:自建MySQL与Redis集成及故障排查指南 禅道镜像版本:easysoft/zentao:21.4 Redis版本:redis:6.2.0 Mysql版本:mysql:8.0.35 文章目录 **基于Docker-compose的禅道部署实践:自建MySQL与…...

C++20 多线程机制
C++20 多线程机制 C++20 多线程机制说明总结C++20 多线程机制说明 C++20 引入了许多新的多线程特性,增强了标准库对并发编程的支持。以下是 C++20 中多线程编程的关键特性和用法:C++20 多线程核心特性 std::jthread:std::jthread 是 C++20 引入的新线程类,与 std::thread …...

AIGC与AICG的区别解析
目录 一、AIGC(人工智能生成内容) (一)定义与内涵 (二)核心技术与应用场景 (三)优势与挑战 二、AICG(计算机图形学中的人工智能) (一&#x…...

基于 openEuler 构建 LVS-DR 群集
一、 对比 LVS 负载均衡群集的 NAT 模式和 DR 模式,比较其各自的优势 。 二、 基于 openEuler 构建 LVS-DR 群集。 一 NAT 模式 部署简单:NAT 模式下,所有的服务器节点只需要连接到同一个局域网内,通过负载均衡器进行网络地址转…...

Python练习11-20
题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少? 题目:判断101-200之间有多少…...

Java 实战:在图片指定位置贴二维码或条形码生成海报
在很多业务场景中,我们需要将生成的二维码或条形码贴到一张已有的图片上,从而生成一张完整的海报。下面就教你如何使用 Java 实现这个功能,我们将借助 ZXing 库生成二维码或条形码,使用 Java 的 java.awt 和 javax.imageio 包来处…...

深入指南:在IDEA中启用和使用DeepSeek
引言 2025年的春节可以说是人工智能在中国史上飘红的一段历史时刻,年后上班的第一天,便马不停蹄的尝试新技能。今天的科技在飞速发展,编程领域的人工智能工具犹如雨后春笋般涌现。其中,DeepSeek 则以其卓越的性能和智能化的功能&a…...

SPSS—回归分析
一、如何选择 回归方法的选择是根据因变量的类型进行选择,无论自变量是哪种类型。 如果因变量,也就是目标变量是连续的数值型变量,当自变量也是连续数值型,研究自变量是否对因变量有影响。选择普通的线性回归即可,根…...

深入剖析 Burp Suite:Web 应用安全测试利器
目录 前言 一、Burp Suite 简介 二、功能组件详解 三、使用场景 四、安装与使用步骤 安装步骤 使用步骤 五、总结 前言 在网络安全的复杂版图中,Burp Suite 宛如一颗璀璨的明珠,以其强大的功能和广泛的适用性,成为众多安全从业者不可…...
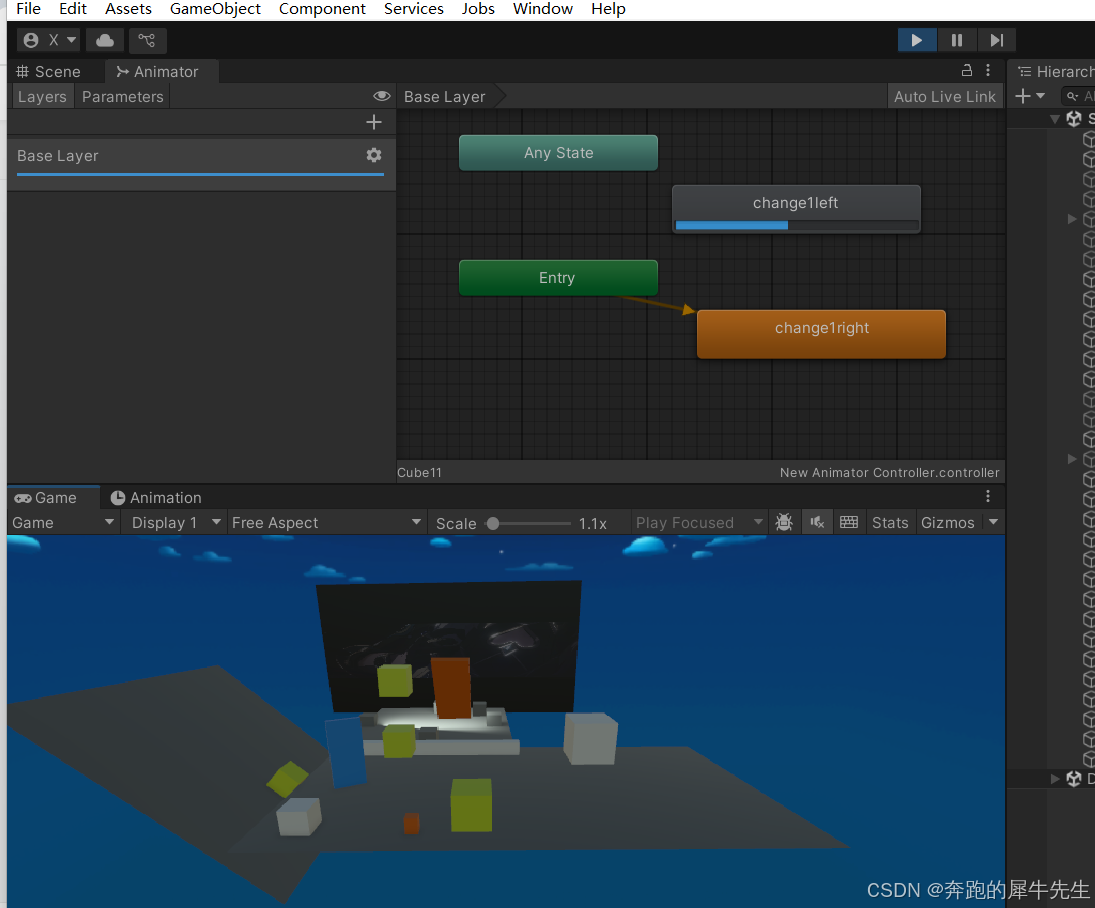
unity学习37:新版的动画器:动画状态机 Animator
目录 1 给游戏物体添加,新版的动画器 Animator 2 关于 Animator 3 创建 动画器的控制器 Animator Controller 4 打开动画编辑器 Animator 5 动画编辑器 还是Animation 5.1 创建新的动画 5.2 创建第2个动画 5.3 测试2个动画均可用 6 再次打开动画编辑器 A…...