flink cdc2.2.1同步postgresql表
目录
- 简要说明
- 前置条件
- maven依赖
- 样例代码
简要说明
在flink1.14.4 和 flink cdc2.2.1下,采用flink sql方式,postgresql同步表数据,本文采用的是上传jar包,利用flink REST api的方式进行sql执行。
前置条件
1.开启logical
确保你的 postgresql.conf 文件中的相关设置允许逻辑复制和插件的使用。特别是下面几个配置项:
wal_level 应该设置为 logical。
max_replication_slots 需要大于0。
配置文件修改完毕后,重启 PostgreSQL 服务
SHOW wal_level; 命令查看日志等级是否修改
2.创建逻辑复制槽
SELECT * FROM pg_create_logical_replication_slot(‘flink_slot’, ‘pgoutput’);
flink_slot 为槽名
pgoutput 是从PostgreSQL 10开始提供的一个内置输出插件,用于逻辑解码
验证逻辑复制槽:SELECT * FROM pg_replication_slots;
查询逻辑复制状态:SELECT * FROM pg_stat_replication;
3.更改复制标识包含更新和删除之前值(目的是为了确保表 xxxx(tableName) 在实时同步过程中能够正确地捕获并同步更新和删除的数据变化。如果不执行这两条语句,那么 xxxx 表可能无法实时同步时丢失更新和删除的数据行信息,从而影响同步的准确性)
ALTER TABLE xxxx REPLICA IDENTITY FULL;
4.修改类加载机制
在flink的flink-conf.yaml文件,classloader.resolve-order: child-first,将 child-first 改为 parent-first
maven依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.14.4</flink.version><flink-cdc.version>2.2.1</flink-cdc.version><scala.binary.version>2.12</scala.binary.version></properties>
<dependencies><!-- flink --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>1.14.4</version><!--<scope>provided</scope>--></dependency><!-- flink cdc --><dependency><groupId>com.ververica</groupId><artifactId>flink-sql-connector-mysql-cdc</artifactId><version>${flink-cdc.version}</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-sql-connector-oracle-cdc</artifactId><version>${flink-cdc.version}</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-sql-connector-postgres-cdc</artifactId><version>${flink-cdc.version}</version></dependency><dependency><groupId>com.ververica</groupId><artifactId>flink-sql-connector-sqlserver-cdc</artifactId><version>${flink-cdc.version}</version></dependency><!-- database driver --><!-- postgresql --><dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><version>42.2.5</version></dependency><!-- json --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.9.9.3</version></dependency><!-- lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency><!-- log --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.7</version><scope>runtime</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version><scope>runtime</scope></dependency><!-- junit --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency>
样例代码
sql:
CREATE TABLE `new_table1_37877` (
id INT,
name STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'debezium.database.tablename.case.insensitive'='false',
'debezium.log.mining.continuous.mine'='true',
'password'='*****',
'hostname'='***.**.**.***',
'debezium.log.mining.strategy'='online_catalog',
'connector'='postgres-cdc',
'port'='5432',
'schema-name'='public',
'database-name'='test',
'table-name'='new_table1',
'username'='******',
'slot.name'='flink_slot',
'decoding.plugin.name'='pgoutput'
);
CREATE TABLE `new_table1_bak_37877` (
id INT,
name STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'password'='*****',
'connector'='jdbc',
'table-name'='public.new_table1_bak',
'url'='jdbc:postgresql://地址:5432/test',
'username'='用户'
);
insert into new_table1_bak_37877 select * from new_table1_37877;
参数类:
@Data
public class InputOutputParams {/*** 作业名称*/private String jobName;/*** 代码文本,分号分隔的flink sql语句*/private String codeText;}
main方法:
public class FlinkMain {/*** flink job 运行入口** @param args 运行参数*/public static void main(String[] args) throws IOException {if (args == null || args.length == 0) {throw new RuntimeException("运行参数为空");}// 取第一个参数(必须是json字符串)为运行参数String json = args[0];ObjectMapper objectMapper =new ObjectMapper().configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);InputOutputParams params = objectMapper.readValue(json, InputOutputParams.class);// 获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 开启快照点,每 3 * 60秒保存一次快照env.enableCheckpointing(3 * 60 * 1000L);//检查点可容忍失败阈值env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);//检查点超时时间env.getCheckpointConfig().setCheckpointTimeout(10 * 60 * 1000);// 同一时间只允许一个 checkpoint 进行env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);// 开启在 job 中止后仍然保留的 externalized checkpointsenv.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 重启策略,最多尝试重启3次,每次重启的时间间隔为20秒env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(20L, TimeUnit.SECONDS)));env.setParallelism(1);EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();// 获取表执行环境StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);tEnv.getConfig().getConfiguration().setString("pipeline.name", params.getJobName());// 执行操作sqlString codeText = params.getCodeText();if (codeText == null || codeText.trim().isEmpty()) {throw new RuntimeException("flink sql is empty");}String[] flinkSqlArr = codeText.split(";");for (String flinkSql : flinkSqlArr) {if (flinkSql != null && !flinkSql.trim().isEmpty()) {tEnv.executeSql(flinkSql);}}}
}将项目打包成不带依赖的jar
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-dependency-plugin</artifactId><version>2.10</version><executions><execution><id>copy-dependencies</id><phase>package</phase><goals><!-- 复制依赖jar包 --><goal>copy-dependencies</goal></goals><configuration><!-- 依赖jar包输出目录 --><outputDirectory>${project.build.directory}/lib</outputDirectory></configuration></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-jar-plugin</artifactId><version>2.4</version><configuration><archive><manifest><!-- main方法所在主类 --><mainClass>com.test.FlinkMain</mainClass></manifest></archive></configuration></plugin></plugins></build>
然后将lib下的依赖全部拷贝到flink的lib下,将刚才打包好的jar界面上传

然后通过postman调用flink的REST api接口提交sql,接口文档地址:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/ops/rest_api/

相关文章:
flink cdc2.2.1同步postgresql表
目录 简要说明前置条件maven依赖样例代码 简要说明 在flink1.14.4 和 flink cdc2.2.1下,采用flink sql方式,postgresql同步表数据,本文采用的是上传jar包,利用flink REST api的方式进行sql执行。 前置条件 1.开启logical 确保你…...

Golang协程调度模型MPG
深入解析Golang协程调度模型MPG:原理、实践与性能优化 一、为什么需要MPG模型? 在传统操作系统调度中,线程作为CPU调度的基本单位存在两个根本性挑战:1)内核线程上下文切换成本高昂(约1-5μs)…...

纪念日倒数日项目的实现-【纪念时刻-时光集】
纪念日/倒数日项目的实现## 一个练手的小项目,uniappnodemysql七牛云。 在如今快节奏的生活里,大家都忙忙碌碌,那些具有特殊意义的日子一不小心就容易被遗忘。今天,想给各位分享一个“纪念日”项目。 【纪念时刻-时光集】 一…...

WPF的MVVMLight框架
在NuGet中引入该库: MVVMLight框架中的命令模式的使用: <StackPanel><TextBox Text"{Binding Name}"/><TextBox Text"{Binding Title}"/><Button Content"点我" Command"{Binding ShowCommand…...

DeepSeek从入门到精通(清华大学)
DeepSeek是一款融合自然语言处理与深度学习技术的全能型AI助手,具备知识问答、数据分析、编程辅助、创意生成等多项核心能力。作为多模态智能系统,它不仅支持文本交互,还可处理文件、图像、代码等多种格式输入,其知识库更新至2…...

【DeepSeek】DeepSeek R1 本地windows部署(Ollama+Docker+OpenWebUI)
1、背景: 2025年1月,DeepSeek 正式发布 DeepSeek-R1 推理大模型。DeepSeek-R1 因其成本价格低廉,性能卓越,在 AI 行业引起了广泛关注。DeepSeek 提供了多种使用方式,满足不同用户的需求和场景。本地部署在数据安全、性…...

windows平台上 oracle简单操作手册
一 环境描述 Oracle 11g单机环境 二 基本操作 2.1 数据库的启动与停止 启动: C:\Users\Administrator>sqlplus / as sysdba SQL*Plus: Release 11.2.0.4.0 Production on 星期五 7月 31 12:19:51 2020 Copyright (c) 1982, 2013, Oracle. All rights reserved. 连接到:…...

【弹性计算】弹性计算的技术架构
弹性计算的技术架构 1.工作原理2.总体架构3.控制面4.数据面5.物理设施层 虽然弹性计算的产品种类越来越多,但不同产品的技术架构大同小异。下面以当前最主流的产品形态 —— 云服务器为例,探查其背后的技术秘密。 1.工作原理 云服务器通常以虚拟机的方…...

RAG(检索增强生成)落地:基于阿里云opensearch视线智能问答机器人与企业知识库
文章目录 一、环境准备二、阿里云opensearch准备1、产品文档2、准备我们的数据3、上传文件 三、对接1、对接文本问答 一、环境准备 # 准备python环境 conda create -n opensearch conda activate opensearch# 安装必要的包 pip install alibabacloud_tea_util pip install ali…...

【踩坑】pytorch模型导出部署onnx问题记录
问题1:repeat_interleave 无法转译 具体报错为: TypeError: torch._C.Value object is not iterable (Occurred when translating repeat_interleave).原因是我的模型代码中有: batch_indices torch.repeat_interleave(torch.arange(can…...

利用prompt技术结合大模型对目标B/S架构软件系统进行测试
利用prompt技术结合大模型对目标B/S架构软件系统进行测试,可参考以下步骤和方法: 测试需求理解与prompt设计 明确测试点:梳理B/S架构软件系统的功能需求、非功能需求(如性能、安全性、兼容性等),确定具体的测试点,如用户登录功能、数据查询功能、系统响应时间要求等。设…...

DeepSeek vs ChatGPT:AI对决中的赢家是……人类吗?
DeepSeek vs ChatGPT:AI对决中的赢家是……人类吗? 文章目录 DeepSeek vs ChatGPT:AI对决中的赢家是……人类吗?一、引言1. 背景2. 问题 二、DeepSeek vs ChatGPT:谁更胜一筹?2.1 语言生成能力评测对比场景…...

基于ollama搭建本地deepseek大模型服务
基于ollama搭建本地deepseek大模型服务 简介准备工作系统要求ollama的安装ollama 模型ollama 安装流程ollama 如何运行大模型前端部署注意事项简介 本指南旨在帮助初学者在本地环境中设置和运行DeepSeek大模型服务。本文将使用Ollama平台来简化这一过程,确保即使是新手也能顺…...

elementUI rules 判断 el-cascader控件修改值未生效
今天修改一个前端项目,增加一个多选字段,使用的是el-cascader控件,因页面是通过引用子页面组件形式使用,出现一个点选后再勾选原有值,输入框内不展示或取消后的也未正常隐藏,如果勾选的值是全新的则其他已选…...

讯方·智汇云校华为授权培训机构的介绍
官方授权 华为授权培训服务伙伴(Huawei Authorized Learning Partner,简称HALP)是获得华为授权,面向公众(主要为华为企业业务的伙伴/客户)提供与华为产品和技术相关的培训服务,培养华为产业链所…...

力扣-二叉树-257 二叉树的所有路径
思路 除去根节点,每一层添加->val,然后使用前序遍历的顺序 代码 class Solution { public:vector<string> res;void getTreePaths(string s, TreeNode* root){s "->";s to_string(root->val);if(root->left nullptr &…...

DeepSeek4j 已开源,支持思维链,自定义参数,Spring Boot Starter 轻松集成,快速入门!建议收藏
DeepSeek4j Spring Boot Starter 快速入门 简介 DeepSeek4j 是一个专为 Spring Boot 设计的 AI 能力集成启动器,可快速接入 DeepSeek 大模型服务。通过简洁的配置和易用的 API,开发者可轻松实现对话交互功能。 环境要求 JDK 8Spring Boot 2.7Maven/Gr…...

Vue.js 组件开发深入解析:Vue 2 vs Vue 3
Vue.js 是一个渐进式框架,旨在通过声明式渲染和组件化开发来提高开发效率和可维护性。组件是 Vue 应用的基本组成部分,几乎所有的功能都可以通过组件来实现。随着 Vue 3 的发布,Vue.js 引入了许多新的特性,使得组件的开发变得更加…...
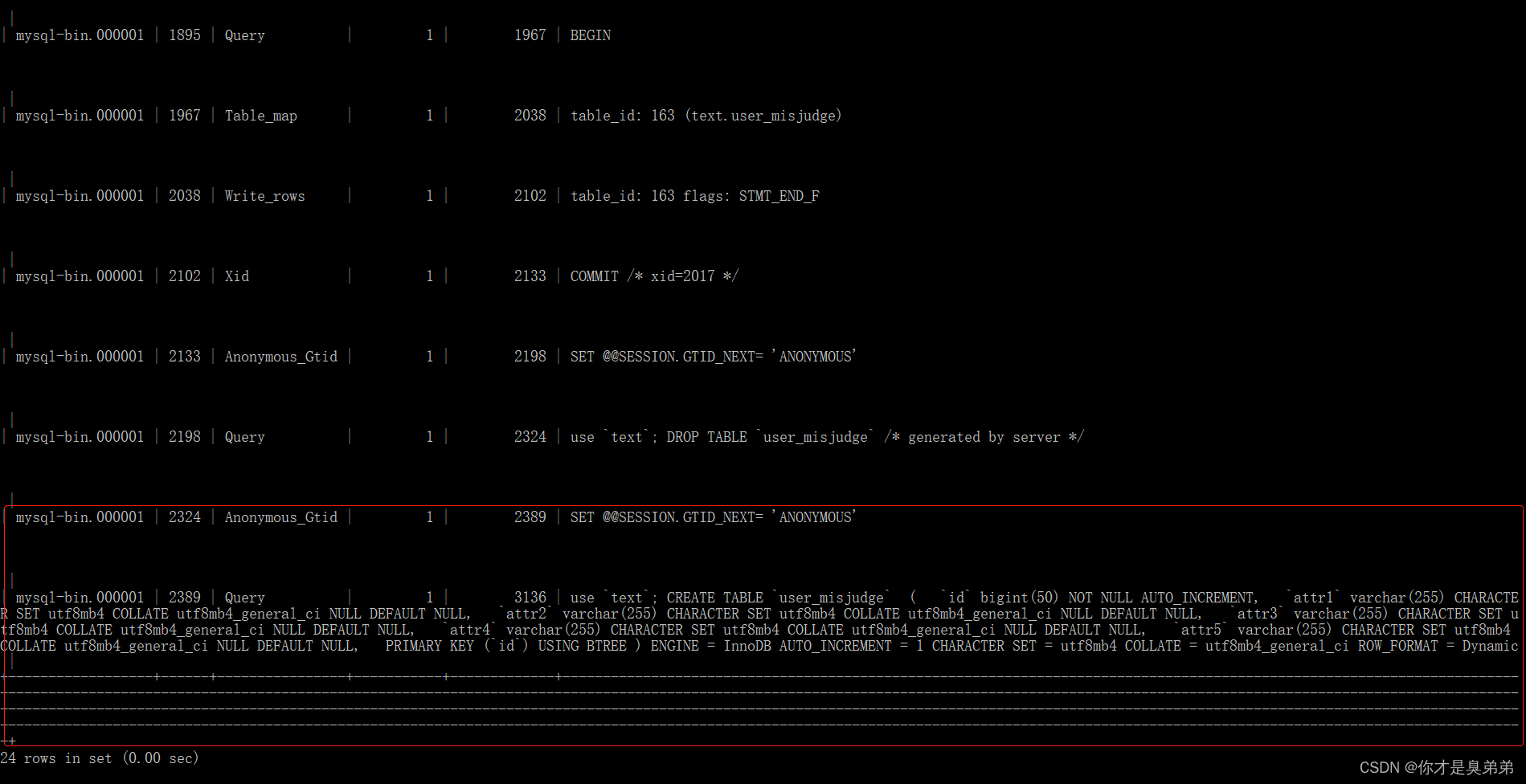
MySQL数据库误删恢复_mysql 数据 误删
2、BigLog日志相关 2.1、检查biglog状态是否开启 声明: 当前为mysql版本5.7 当前为mysql版本5.7****当前为mysql版本5.7 2.1.1、Navicat工具执行 SHOW VARIABLES LIKE LOG_BIN%;OFF 是未开启状态,如果不是ON 开启状态需要开启为ON。{默认情况下就是关闭状态} 2.…...

PHP 基础介绍
PHP 学习资料 PHP 学习资料 PHP 学习资料 PHP 是一种广泛使用的开源服务器端脚本语言,尤其适合 Web 开发,能轻松嵌入 HTML 中,生成动态网页内容。接下来,让我们一起了解 PHP 的基础内容。 一、PHP 的安装与配置 在开始编写 PH…...

避雷,Ubuntu通过ollama本地化部署deepseek,open-webui前端显示
0.如题,预期在Ubuntu上本地化部署DeepSeek,通过浏览器访问达到chatgpt的对话效果。 1.裸机,安装Ubuntu。 原有的系统盘采用大白菜,下载24.04.1的镜像,插到电脑上,无法识别,重新查到笔记本&…...

package.json 文件配置
创建 Node.js 的配置文件 package.json npm init -y package.json 文件配置说明 配置说明示例name指定项目的名称,必须是小写字母,可以包含字母、数字、连字符(-)或下划线(_),不能有特殊字符…...

Managed Lustre 和 WEKA:高性能文件系统的对比与应用
Managed Lustre 和 WEKA:高性能文件系统的对比与应用 1. 什么是 Managed Lustre?主要特点:适用场景: 2. 什么是 WEKA?主要特点:适用场景: 3. Managed Lustre 和 WEKA 的对比4. 如何选择 Managed…...

【matlab】大小键盘对应的Kbname
matlab中可以通过Kbname来识别键盘上的键。在写范式的时候,遇到一个问题,我想用大键盘上排成一行的数字按键评分,比如 Kbname(1) 表示键盘上的数字1,但是这种写法只能识别小键盘上的数字,无法达到我的目的,…...
)
Python实现从SMS-Activate平台,自动获取手机号和验证码(进阶版2.0)
前言 本文是该专栏的第52篇,后面会持续分享python的各种干货知识,值得关注。 在本专栏之前,笔者在文章《Python实现SMS-Activate接口调用,获取手机号和验证码》中,有详细介绍基于SMS-Activate平台,通过python来实现自动获取目标国家的手机号以及对应的手机号验证码。 而…...

HCIA项目实践--静态路由的拓展配置
7.7 静态路由的拓展配置 网络中的两个重要思想: (1) 实的不行来虚的; (2) 范围太大,划分范围。(分治) 7.7.1 负载均衡 (1)定义 负载均衡是一种网…...

缓存三大问题及其解决方案
缓存三大问题及其解决方案 1. 前言 在现代系统架构中,缓存与数据库的结合使用是一种经典的设计模式。为了确保缓存中的数据与数据库中的数据保持一致,通常会给缓存数据设置一个过期时间。当系统接收到用户请求时,首先会访问缓存。如果缓…...

Unity崩溃后信息结合符号表来查看问题
目录 SO文件符号表对调试和分析的重要性调试方面分析方面 错误数据安装Logcat解释符号表设置符号文件路径生成解析 相关参考 SO文件 so 文件(Shared Object File,共享目标文件)和符号表紧密相关,它们在程序的运行、调试和分析过程…...

C#的DataTable类精简汇总
目录 一、DataTable概述 1.创建 DataTable 2.添加行 3.修改行 4.删除行 5.查询行 6.排序行 7.合并 DataTable 8.克隆 DataTable 9.复制 DataTable 10.使用 DataView 过滤和排序 11.使用 DataTable 的事件 12.使用 DataTable 的约束 13.使用 DataTable 的表达式列 …...

DeepSeek官方发布R1模型推荐设置
今年以来,DeepSeek便在AI领域独占鳌头,热度一骑绝尘。其官方App更是创造了惊人纪录,成为史上最快突破3000万日活的应用,这一成绩无疑彰显了它在大众中的超高人气与强大吸引力。一时间,各大AI及云服务厂商纷纷投身其中&…...