李宏毅机器学习笔记:【6.Optimization、Adaptive Learning Rate】
Optimization
- 1.Adaptive Learning Rate
- 2.不同的参数需要不同的学习率
- 3.Root Mean Square
- 4.RMSProp
- 5.Adam
- 6.learning rate scheduling
- 7.warm up
- 总结
critical point不一定是你在训练一个network时候遇到的最大的障碍。
1.Adaptive Learning Rate
也就是我们要给每个参数不同的Learning rate
往往在训练一个network的时候,你会把他的loss记录下来,随着你参数不断的update,你的loss呢不再下降了,就卡住了。。那多数时候这个时候大家就会猜说诶,那是不是走到了critical point,因为gradient等于零的关系,所以我们没有办法再更新参数。
当我们说走到critical point的时候,意味着gradient非常的小,但是你有确认过,当你的loss不再下降的时候,gradient真的很小吗?其实并不然。
下面这个例子,当我们的loss不再下降的时候,gradient的这个向量并没有真的变得很小,在最后训练的最终结的时候,loss几乎没有在减少了,但是gradient却突然还上升了一下。这个是我们的error surface,现在的gradient在error surface的两个谷壁间不断的来回的震荡,这个时候你的loss不会再下降,所以你会觉得看到这样子的状况,但是实际上他真的卡到了critical point、卡到了settle point、卡到了local minima吗?不是的。它的gradient仍然很大,只是loss不见得在减小了。
所以当你今天你训练个network,后来发现loss不再下降的时候,可能只是单纯的loss没有办法在下降,而不是卡在了那些点上。

我们在训练的时候其实很少卡到settle point或者是local minima,多数时候training在还没有走到critical point的时候,就已经停止了,但这并不代表说critical point不是一个问题,我们真正当你用gradient descent来做optimization的时候,你真正应该怪罪的对象往往不是critical point,而是其他的原因。
那为什么如果今天critical point不是问题的话,为什么我们的training会卡住呢,我这边举一个非常简单的例子。
你会发现说就连这种convex的error surface,形状这么简单的error surface,你用gradient descent都不见得能把它做好
学习率= 1 0 − 2 10^-2 10−2,时候,在震荡没有办法慢慢的滑到山谷里面,这时试着去调整了这个learning rate
学习率= 1 0 − 7 10^-7 10−7终于不再震荡了,终于从这个地方滑滑滑滑滑滑到山谷底,然后终于左转了,但是你发现说这个训练永远走不到终点,因为我的learning rate已经太小了,在这个很斜的地方,这个坡度很陡gradient的值很大,所以还能够前进一点,左转后的这个地方坡度已经非常的平滑了,这么小的learning rate根本没有办法再让我们的训练前进,,
gradient descent这个工具连这么简单的error surface都做不好,那如果难的问题,他又怎么有可能做好呢

那怎么把gradient descent做得更好呢?在之前我们的gradient descent里面,所有的参数都是设同样的learning rate,这显然是不够的,learning rate应该要为每一个参数特制化。
2.不同的参数需要不同的学习率
大原则:如果在某一个方向上gradient的值很小,在某一个方向上非常的平坦,那我们会希望learning rate调大一点;如果在某一个方向上非常的陡峭,某一个方向上坡度很大,那我learning rate可以设的小一点。
之前在讲gradient descent的时候,往往是讲所有参数update的式子,为了简化问题,我们现在只看一个参数,你完全可以把这个方法推广到所有参数的状况。

不同的参数我们要给它不同的sigma,同时他也是iteration dependent的,不同的iteration我们也会有不同的sigma。
如何计算这个sigma呢?
一个常见的类型是算gradient的Root Mean Square
3.Root Mean Square

这样的话坡度比较大的时候learning rate就减小,坡度比较小的时候learning rate就放大。
坡度比较小的时候如 θ 1 \theta_1 θ1,g小–> σ \sigma σ小—>learning rate就大(你在update的时候的量啊就比较大)
坡度比较大的时候如 θ 2 \theta_2 θ2,g大–> σ \sigma σ大—>learning rate就小
所以有了 σ \sigma σ这一项以后,你就可以随着gradient的不同,每个参数gradient的不同,来自动的调整learning rate的大小

上面的这个参数不会随时间改变,我们刚才的假设是同一个参数,它的gradient的大小就会固定是差不多的值,如果来看这个新月型的error surface,考虑横轴的话,有的地方地方坡度比较平滑,有的地方地方坡度比较陡峭,所以就算是同个参数,同一个方向,我们也期待说learning rate是可以动态的调整的。
所以就有了RMSProp

4.RMSProp
这个方法没有论文。
这个方法的第一步跟刚才讲的算Root Mean Square一模一样
第二步算 σ 1 \sigma_1 σ1的方法和算Root Mean Square的时候不一样,上一个的每一个gradient都有同等的重要性,但在RMSProp你可以自己调整现在的这个gradient的重要性,
如果我 α \alpha α设很小趋近于零,就代表说我觉得g1相较于之前所算出来的gradient而言比较重要;如果我 α \alpha α设很大趋近于1,那就代表说我觉得现在算出来的g1比较不重要。
这个 α \alpha α就会决定现在刚算出来的 g t g_t gt它有多重要

如果你用RMSProp的话,你就可以动态调整 σ 1 \sigma_1 σ1这一项.
比如下面的黑线,是我们的error surface,开始小球一路平坦,说明G算出来很小,G算出来很小,就代表说这个 σ \sigma σ算出来很小, σ \sigma σ算出来很小,就代表说现在update参数的时候,我们会走比较大的步伐;
当滚到斜坡时候,我们gradient变大了,如果是Adam的话,它反应比较慢;但如果你用RMSProp,把 α \alpha α设小,就是让新看到的gradient影响比较大,那你就可以很快的让 σ \sigma σ的值变大,然后很快让你的步伐呢变小。
又走到平滑的地方时候,调整 α \alpha α,让他比较看重于最近算出来的gradient,所以你gradient变小,它的这个 σ \sigma σ的值变大值呢就变小了,然后呢你走的步伐呢就变大了。

5.Adam
最常用optimization的策略就是Adam:RMSProp+Momentum

我们再看开始的例子,用了第二个的方法后做起来是这个样子的。这个gradient都取平方,再平均再开根号,然后接下来在左转的时候,刚才我们update了10万次卡住了,现在可以继续走下去,因为这个左右的方向的这个gradient很小,所以learning rate会自动调整,左右这个方向learning rate会自动变大,所以这个步伐呢就可以变大。
但走着走着突然爆炸了,为什么走到这边突然爆炸了呢?因为我们在算这个 σ \sigma σ的时候是把过去所有看到的gradient都拿来做平均,所以这个纵轴的这个方向,这个纵轴的方向虽然在初始的这个地方感觉gradient很大,但是这边走了很长一段路以后,这个纵轴的方向gradient算出来都很小,所以纵轴的这个方向就累积了小的 σ \sigma σ,累积到一个地步以后,这个step就变很大,然后就暴走就喷出去了,,
不过喷出去后走到gradient比较大的地方以后, σ \sigma σ又慢慢的变大, σ \sigma σ变大以后,这个参数update的距离,update的这个步伐大小又慢慢的变小,所以就发现说诶走着走着突然往左右喷了一下,但是这个喷这个喷了一下,不会永远就是震荡,不会做简谐运动,他这个左这个这个力道会慢慢变小,让它慢慢的慢慢的又回到中间这个峡谷了。
这样怎么办呢?有一个方法也许可以解决这个问题,这个叫做learning rate schedule

6.learning rate scheduling
我们这个式子还有个参数 η \eta η,他要是跟时间有关的,我们不要把它当成一个常数。
最常见的策略啊叫做learning rate decay,也就是说随着时间不断的进行,随着参数不断的update,我们这个 η \eta η让它越来越小,让这个learning rate越来越小。
为什么要让这个learning rate越来越小呢?因为一开始我们距离终点很远,随着参数不断update,我们距离终点越来越近,我们参数的更新要能够慢慢的慢下来。
所以刚才那个状况,如果加上learning rate decay的话,我们就可以很平顺的走到终点。因为在后面这个 η \eta η已经变得非常的小了,虽然说他本来想要左右乱喷,但是会乘上这个非常小的 η \eta η,那就停下来了,就可以慢慢的走到终点。

除了learning rate decay以外,还有另外一个经典非常常用的learning rate schedule的方式叫做warm up。
7.warm up
这个warm up的方法是说我们这个learning rate要先变大后变小

Residual Network这边特别注明它反其道而行,一开始要设0.01,接下来设0.1,还特别加个注解

同时warm up在transformer里面也用一个式子提了它好,你实际上把它的把这个方程画出来,就会发现它就2learning rate会先增加,然后接下来再递减。
所以发现说warm up这个技术,在很多知名的network里面都有被当做一个黑科技,就论文里面不解释说为什么要用这个,但就偷偷在一个小地方,你没有注意到。

那为什么需要warm up呢?这个仍然是今天一个可以研究的问题了。
这边有一个可能的解释是说,当我们在用Adam、RMSProp时候,我们要计算 σ \sigma σ,这个sigma它是一个统计的结果,告诉我们说某一个方向他到底有多陡或者是多平滑,那这个统计的结果要看了够多笔数据以后,这个统计才精准,所以我们一开始呢 σ \sigma σ不精准,所以开始不要让我们的参数走离初始的地方太远,一开始让learning rate比较小,是让他探索搜集一些有关error surface的情报,等sigma统计比较精准以后,再把让learning ray呢慢慢的爬升,这是一个解释为什么我们需要warm up的可能性。
如果你想要学更多有关warm up的东西的话,可以看RAdam。

总结
有关optimization的部分,我们从最原始的gradient descent进化到下面这个版本

这个版本我们有momentum,也就是说我们现在不是完全顺着这个时间点算出来gradient的方向来更新参数的,而是把过去所有算出来的规定的方向做一个加总,当做update方向,这个是momentum。
那接下来到底应该要update多大的步伐呢?我们要除掉gradient的root mean square。
疑问:这个momentum是考虑过去所有的gradient,这个 σ \sigma σ也是考虑过去所有的gradient,一个放在分子,一个放在分母,都考虑过去所有的gradient不就是正好抵消了吗?
其实这个momentum和 σ \sigma σ他们在使用过去所有gradient的方式是不一样的。
momentum是直接把所有的gradient通通都加起来,他有考虑方向,考虑gradient的正负号,考虑gradient是往左走还是往右走。
但是root mean square,它不考虑gradient的方向了,它只考虑gradient的大小,我们在算 σ \sigma σ时候都要取平方向,把gradient取一个平方向,是把平方的结果加起来,所以我们只考虑gradient的大小,不考虑它的方。
所以momentum跟这个 σ \sigma σ算出来的结果并不会互相抵消掉。
最后我们还会加上一个learning rate的schedule。
这种optimizer除了Adam以外还有各式各样的变形.

相关文章:
李宏毅机器学习笔记:【6.Optimization、Adaptive Learning Rate】
Optimization 1.Adaptive Learning Rate2.不同的参数需要不同的学习率3.Root Mean Square4.RMSProp5.Adam6.learning rate scheduling7.warm up总结 critical point不一定是你在训练一个network时候遇到的最大的障碍。 1.Adaptive Learning Rate 也就是我们要给每个参数不同的…...

vscode使用常见问题处理合集
目录 一、使用vite创建的vue3项目,script和style首行代码不会缩进,且格式化属性字段等会换行问题 首行缩进情况如下: 属性、参数格式化换行情况如下: 解决方式: 一、使用vite创建的vue3项目,script和style首行代码不…...

【技术解析】MultiPatchFormer:多尺度时间序列预测的全新突破
今天给我大家带来一篇最新的时间序列预测论文——MultiPatchFormer。这篇论文提出了一种基于Transformer的创新模型,旨在解决时间序列预测中的关键挑战,特别是在处理多尺度时间依赖性和复杂通道间相关性时的难题。MultiPatchFormer通过引入一维卷积技术&…...
)
Linux内核 - 非仿生机器人之感知主控系统(协议栈)
Linux内核 - 非仿生机器人之感知主控系统(协议栈) 注:该项目为18年实习期间,参与非仿生六足机器人(Linux方案)的个人理解和积累。时至今日,再看其实仅为一套系统编程相关框架,一直为…...

Node.js 工具模块
Node.js 工具模块 引言 Node.js 是一个开源的、基于 Chrome V8 引擎的 JavaScript 运行时环境。它允许开发者使用 JavaScript 编写服务器端代码,从而构建快速、可扩展的网络应用。在 Node.js 开发过程中,工具模块扮演着至关重要的角色。本文将详细介绍 Node.js 中常用的工具…...

【网络安全 | 漏洞挖掘】价值3133美元的Google IDOR
未经许可,不得转载。 文章目录 正文正文 目标URL:REDACTED.google.com。 为了深入了解其功能,我查阅了 developer.google.com 上的相关文档,并开始进行测试。 在测试过程中,我发现了一个 XSS 漏洞,但它触发的域名是经过正确沙盒化的 *.googleusercontent.com,这符合 …...

大脑网络与智力:基于图神经网络的静息态fMRI数据分析方法|文献速递-医学影像人工智能进展
Title 题目 Brain networks and intelligence: A graph neural network based approach toresting state fMRI data 大脑网络与智力:基于图神经网络的静息态fMRI数据分析方法 01 文献速递介绍 智力是一个复杂的构念,包含了多种认知过程。研究人员通…...
(A-E))
Codeforces Round 1004 (Div. 2)(A-E)
题目链接:Dashboard - Codeforces Round 1004 (Div. 2) - Codeforces A. Adjacent Digit Sums 思路 只有两种情况:n1之后没有进位,y-x1。n1之后进位(y-x-1)%90。 代码 void solve(){int x,y;cin>>x>>y;if(y-x1){cout<<…...

掌握正则表达式_模式匹配的艺术
当然,以下是《掌握正则表达式:模式匹配的艺术》文章内容,使用 Java 正则表达式,并包含丰富的代码示例: 1. 引言 1.1 正则表达式的定义与历史 正则表达式(Regular Expression,简称 regex 或 regexp)是一种用于描述文本模式的强大工具。它最初由数学家 Stephen Kleene…...

Python使用OpenCV图片去水印多种方案实现
1. 前言 本文为作者学习记录,使用Python结合OpenCV,总结了几种常见的水印去除方式,简单图片去水印效果良好,但是复杂图片有点一言难尽,本文部分代码仅供参考,并不能针对所有水印通用,需要根据具…...

论文阅读2——S波段宽波束圆极化天线设计
论文结构 研究背景,基于当前天线通信的应用基础进行分析,为了适应更多的应用环境和更复杂的通信信号提出宽波束圆极化的天线设计要求,圆极化天线可以接收到任意极化的电磁波且其辐射波也可以由其他任意极化天线接收到圆极化天线的特性&#…...

【java】基本数据类型和引用数据类型
在 Java 中,数据类型分为 基本数据类型 和 引用数据类型。它们的本质区别在于存储方式和操作方式。下面我会详细解释这两种数据类型,并用通俗易懂的语言帮助你理解。 1. 基本数据类型(Primitive Data Types) 基本数据类型是 Java…...

基于角色访问控制的UML 表示02
一个用户可以成为很多角色的成员,一个角色可以有许多用户。类似地,一个角色可以有多个权限,同一个权限可以被指派给多个角色。每个会话把一个用户和可能的许多角色联系起来。一个用户在激发他或她所属角色的某些子集时,建立了一个…...

CEF132 编译指南 Linux 篇 - 获取 CEF 源代码:源码同步详解(五)
1. 引言 在完成所有必要工具的安装和配置之后,我们来到了整个 CEF 编译流程中至关重要的环节:获取 CEF 源代码。CEF 源码的获取过程需要我们特别关注同步策略和版本管理,以确保获取的代码版本正确且完整。本篇将详细指导你在 Linux 系统上获…...

Golang关于结构体组合赋值的问题
现在有一个结构体,其中一个属性组合了另外一个结构体,如下所示: type User struct {Id int64Name stringAge int64UserInfo }type UserInfo struct {Phone stringAddress string }如果要给 User 结构体的 Phone 和 Address 赋值的话&am…...

django上传文件
1、settings.py配置 # 静态文件配置 STATIC_URL /static/ STATICFILES_DIRS [BASE_DIR /static, ]上传文件 # 定义一个视图函数,该函数接收一个 request 参数 from django.shortcuts import render # 必备引入 import json from django.views.decorators.http i…...

Springboot核心:统一异常处理
概述 统一异常处理机制在 Spring Boot 应用中是非常重要的核心点,因为它带来了多个方面的优势,能够显著提升应用的质量和开发效率。 为什么要优雅的处理异常 在后端发生异常或者是请求出错时,前端通常直接显示异常信息,而且对于…...

【银河麒麟高级服务器操作系统】服务器卡死后恢复系统日志丢失-分析及处理全过程
了解更多银河麒麟操作系统全新产品,请点击访问 麒麟软件产品专区:https://product.kylinos.cn 开发者专区:https://developer.kylinos.cn 文档中心:https://document.kylinos.cn 服务器环境以及配置 【机型】 处理器ÿ…...

【deepseek api 第三方平台使用参考】
1.硅基流动 1.1硅基流动网页版使用 打开硅基流动的官网 https://siliconflow.cn/zh-cn/ 点右上角登陆 在模型广场这里找到这个deepseek的r1 注意,一定选择下面标记【671B】的,这个是满血版 这个满血版收费标准是 4块钱/百万token输入 16块钱/百万token…...

通过 VBA 在 Excel 中自动提取拼音首字母
在excel里面把表格里的中文提取拼音大写缩写怎么弄 在Excel中,如果你想提取表格中的中文字符并转换为拼音大写缩写(即每个汉字的拼音首字母的大写形式),可以通过以下步骤来实现。这项工作可以分为两个主要部分: 提取拼…...

动态规划dp_4
一.背包 如果求组合数就是外层for循环遍历物品,内层for遍历背包。 如果求排列数就是外层for遍历背包,内层for循环遍历物品。 二.题 1. 思路:dp五部曲,思路在注释 /* dp[i]表示:到达第 i 个台阶有dp[i]种方法 状态转…...

对贵司需求的PLC触摸的远程调试的解决方案
远程监控技术解决方案 一、需求痛点分析 全球设备运维响应滞后(平均故障处理周期>72小时)客户定制化需求频繁(每月PLC程序修改需求超50次)人力成本高企(单次跨国差旅成本约$5000)多品牌PLC兼容需求&am…...

Python用PyMC3马尔可夫链蒙特卡罗MCMC对疾病症状数据贝叶斯推断
全文链接:https://tecdat.cn/?p39937 本文聚焦于马尔可夫链蒙特卡罗(MCMC)方法在贝叶斯推断中的Python实现。通过介绍MCMC的基础原理、在贝叶斯推断中的应用步骤,展示了其在解决复杂分布采样问题上的强大能力。同时,借…...

网络工程师 (39)常见广域网技术
一、HDLC 前言 HDLC(High-level Data Link Control,高级数据链路控制)是一种面向比特的链路层协议。 (一)定义与历史背景 HDLC是由国际电信联盟(ITU)标准化的,它基于IBM公司早期的同…...

每日Attention学习23——KAN-Block
模块出处 [SPL 25] [link] [code] KAN See In the Dark 模块名称 Kolmogorov-Arnold Network Block (KAN-Block) 模块作用 用于vision的KAN结构 模块结构 模块代码 import torch import torch.nn as nn import torch.nn.functional as F import mathclass Swish(nn.Module)…...

基于Python的Optimal Interpolation (OI) 方法实现
前言 Optimal Interpolation (OI) 方法概述与实现 Optimal Interpolation (OI) 是一种广泛应用于气象学、海洋学等领域的空间数据插值方法。该方法通过结合观测数据与模型预测数据,最小化误差方差,从而实现对空间数据的最优插值。以下是OI方法的一般步骤…...

学习数据结构(10)栈和队列下+二叉树(堆)上
1.关于栈和队列的算法题 (1)用队列实现栈 解法一:(参考代码) 题目要求实现六个函数,分别是栈初始化,入栈,移除并返回栈顶元素,返回栈顶元素,判空࿰…...
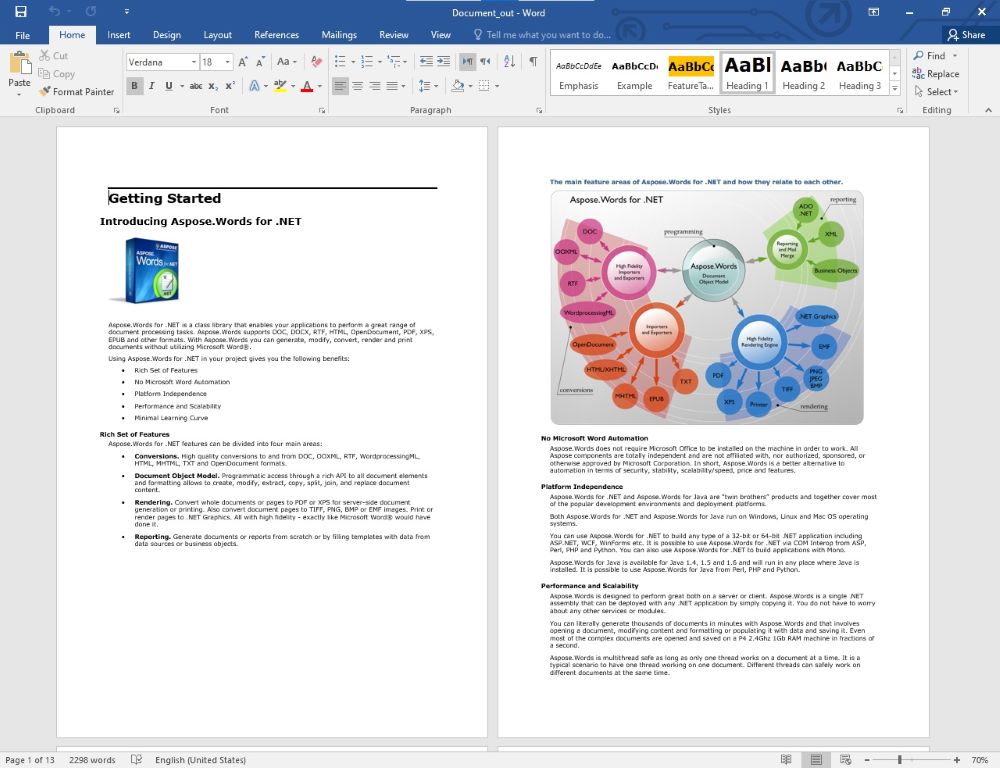
.NET版Word处理控件Aspose.Words教程:使用 C# 删除 Word 中的空白页
Word 文档中的空白页会使其看起来不专业并扰乱流程。用户会遇到需要删除 Word 中的空白页的情况,但手动删除它们需要时间和精力。在这篇博文中,我们将探讨如何使用 C# 删除 Word 中的空白页。 本文涵盖以下主题: C# 库用于删除 Word 中的空…...

《代码随想录》刷题笔记——回溯篇【java实现】
文章目录 组合组合总和 III电话号码的字母组合组合总和组合总和II思路代码实现 分割回文串※思路字符串分割回文串判断效率优化※ 复原 IP 地址优化版本 子集子集 II使用usedArr辅助去重不使用usedArr辅助去重 递增子序列※全排列全排列 II重新安排行程题意代码 N 皇后解数独直…...

【JavaEE进阶】验证码案例
目 🌲实现说明 🎄Hutool介绍 🌳准备工作 🌴约定前后端交互接口 🚩接口定义 🚩实现服务器后端代码 🚩前端代码 🚩整体测试 🌲实现说明 随着安全性的要求越来越⾼…...