【大模型】DeepSeek使用与原理解析:从V3到R1

文章目录
- 一、引言
- 二、使用与测评
- 1.7大R1使用技巧
- 2.官网实测
- 发展历程
- 三、Deepseek MoE:专家负载均衡 (2024年1月)
- 四、GRPO:群体相对策略优化(DeepSeek-Math,2024年4月)
- 五、三代注意力:从MHA到MLA(DeepSeek-V2,2024年6月)
- 5.1 LLM推理过程,以及MHA(多头注意力)
- 5.1.1 MHA的KVcache
- 5.1.2 LLM推理阶段显存使用情况
- 5.2 MLA(即将到来)
- 六、MTP:多token预测(DeepSeek-V3,2024年12月)
- 七、DeepSeek-R1
- 总结
- Trick-GS
- 1.根据体积裁剪(Pruning with Volume Masking)
- 2.根据重要性裁剪(Pruning with Significance of Gaussians)
- 3.球形谐波(SH)mask
- 4.渐进式训练
- 5.3DGS的加速训练
- 实验
提示:以下是本篇文章正文内容,下面案例可供参考
一、引言
DeepSeek R1 是深度求索(DeepSeek,成立于2023年)公司开发的一款智能体(Agent)产品,它能够通过自然语言交互,帮助用户完成各种任务。
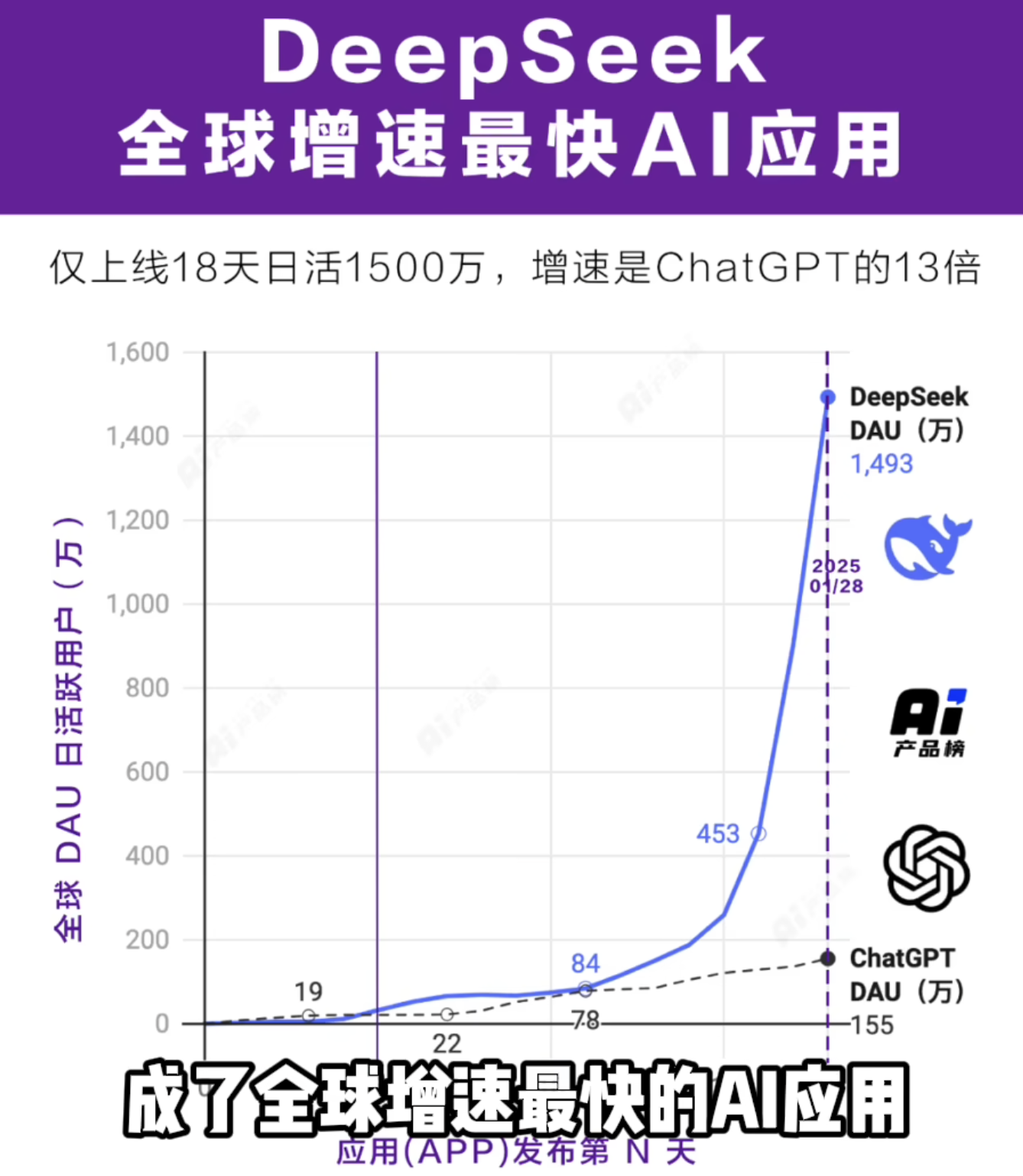
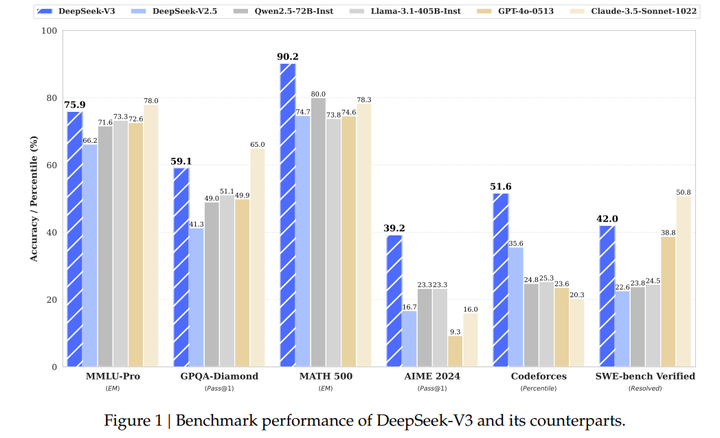
各种性能评估:
2000快阉割版H800,花费557亿美元(大约是使用1.6万个GPU的Llama3.1的1/10,GPT-4o的1/20),登顶了开源之最。来源于幻方量化,2023年4月成立的全资子公司。
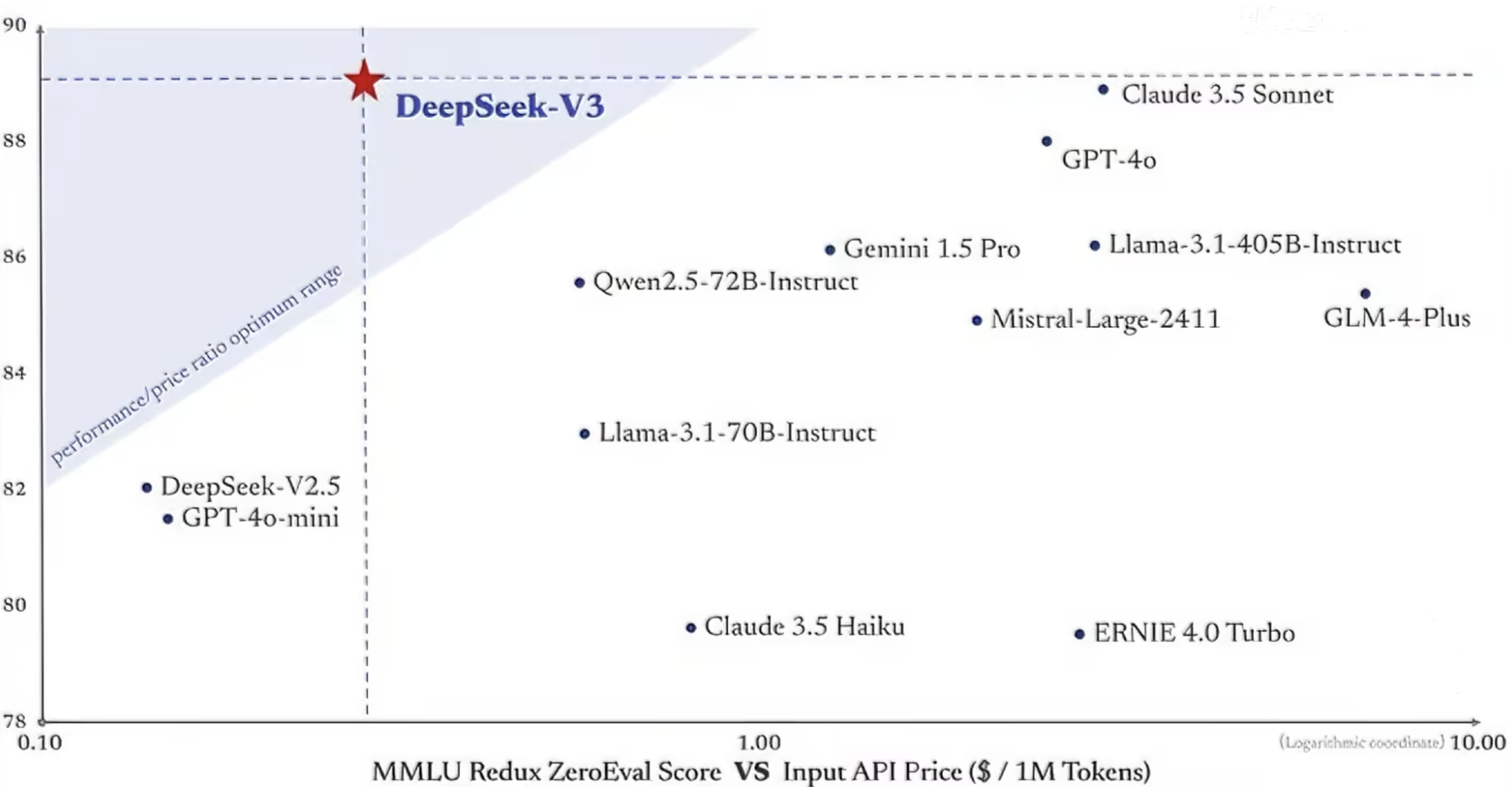
数学和推理能力:
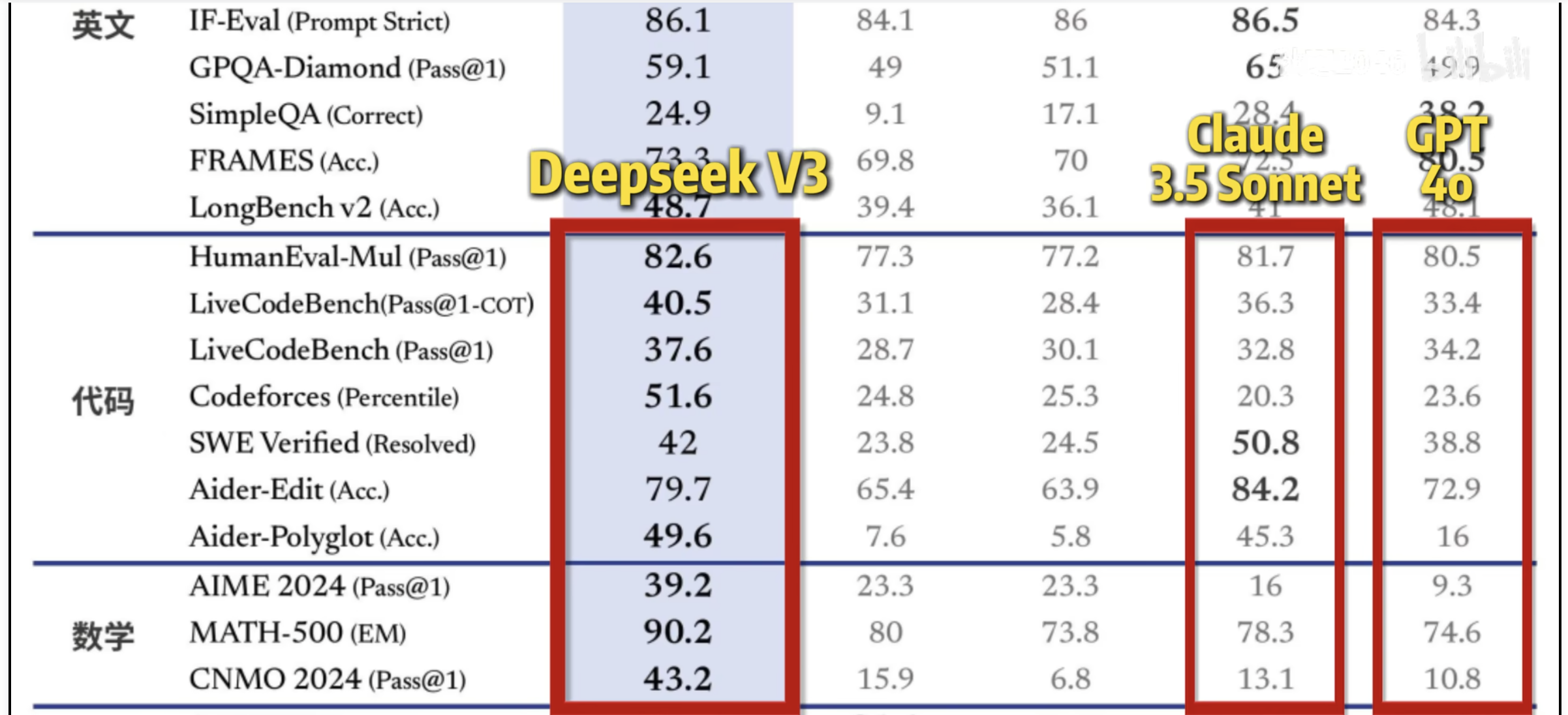
整体性能(MMLU代表理解能力):
二、使用与测评
1.7大R1使用技巧
-
1:提出明确的要求技巧
指出具体任务,字数要求等。 -
2:要求特定的风格技巧
明确写作风格,写作者身份等 -
3:提供充分的任务背景信息技巧
比如提供医疗帮助等,要先明确自己的身体状况。 -
4:主动标注自己的知识状态技巧
是否存在已知或未知的知识状态 -
5:定义目标,而非过程技巧
-
6:提供AI不具备的知识背景
因为模型知识的缺乏(24年之后的新知识,或者某公司的内部资料),需要手动补上 -
7:从开放到收敛
先询问一个大的范围,再逐步聚焦到其中一个小的点。
2.官网实测
1.提问:

2.数学题:

3.编程(效果略差于claud3.5)
整体在数学和编程能力上很强,创意生成方面差于chatGPT。上下文只有64k,远远低于cursor里的claude 200k
发展历程

三、Deepseek MoE:专家负载均衡 (2024年1月)
主要修改:传统Transformer最后的两层MLP。
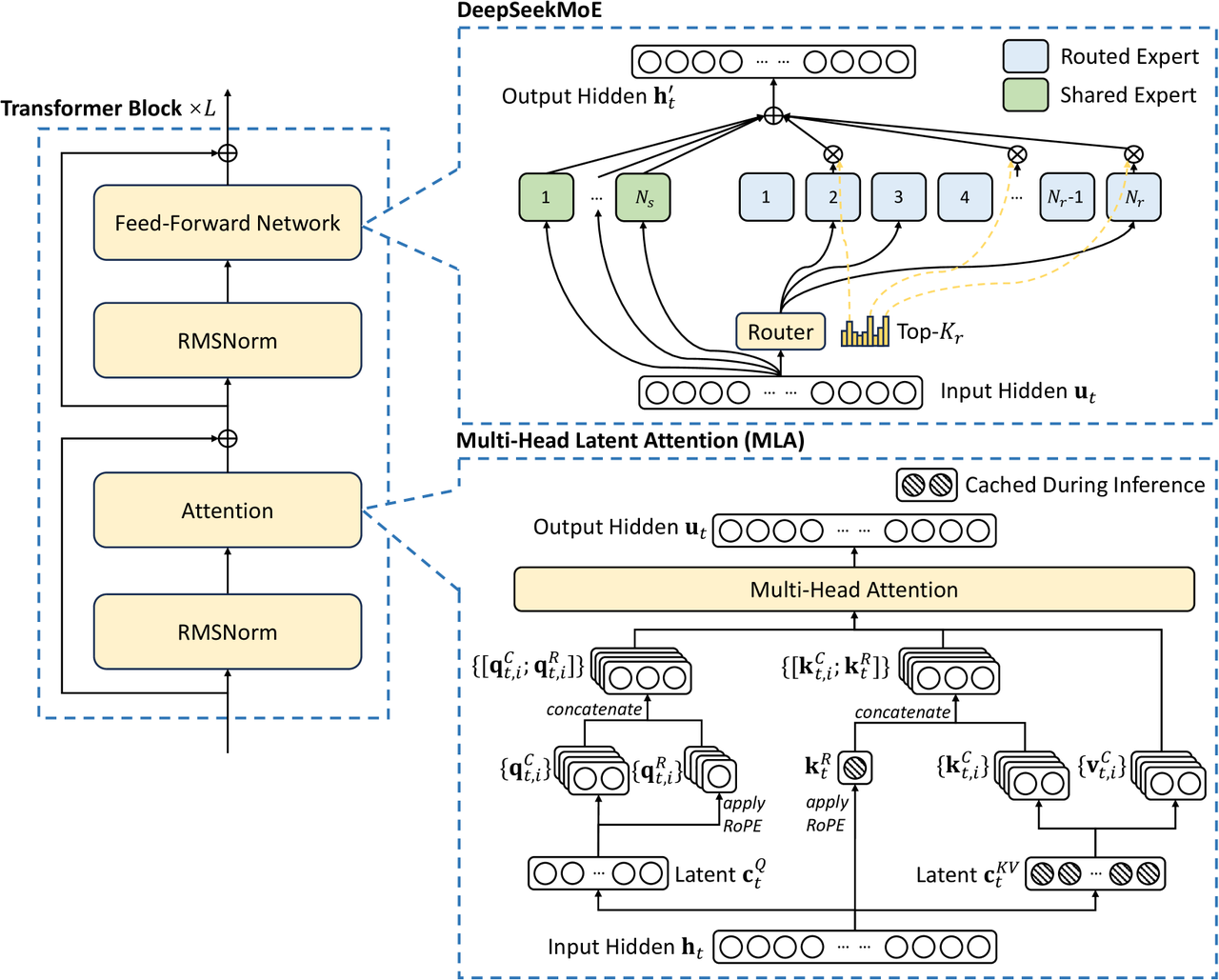
类似于给多个专家分配工作。下图中绿色为常驻专家Shared Expert,蓝色为随机参与工作的Routed Expert。具体激活状态如下:
设 u t u_t ut为第 t t t个标记的 FFN 输入,我们计算 FFN 输出 h t ′ h'_t ht′如下:

N s N_s Ns和 N r N_r Nr分别表示共享专家和路由专家的数量; F F N i ( s ) FFN_i^{(s)} FFNi(s)()和 F F N i ( r ) FFN_i^{(r)} FFNi(r)分别表示第 i i i个共享专家和第 i i i个路由专家; K r K_r Kr表示激活的路由专家数量; g i t g_{it} git是第 i i i个专家的门控值; s i t s_{it} sit是token到专家的亲和度; e i e_{i} ei是这一层中第个路由专家的质心;而Topk(,K)表示由计算出的第 t t t个token和所有路由专家的亲和度得分中最高的K个得分组成的集合。
模型架构层:
对于每一个专家的亲和度(值越高越容易激活)加上一个偏置 b,如下图所示:

训练过程中,记录每个专家的负载率,通过调整偏置 b 进行循环,最终保证专家负载率平衡。
#以下 a、b、c 为专家,第一个数字为原始亲和度 Sit,第二个数字为偏置 bi,第三个数字为该专家的输出值。
topk 为 2,output 为 MoE 层最终输出:a: 0.4 - 0.1 100
b: 0.35 + 0 50
c: 0.25 + 0.1 120
moe_output = 50 * 0.35 + 0.25 * 120
- 1.专家头包括 Share 专家 和 Router 专家。
- 2.Share 专家 是一直激活的,即输入的 token 都会被 Share 专家头计算。
- 3.Router 专家头会先和上图中的 u t u_t ut 计算亲和度(代码中直接用一个 Linear 层进行投影),选择 top-k 各专家进行推理。(代码中推理计算 top-k 时,会先将 N 各专家进行分组为 n g r o u p s n_{groups} ngroups,将每个组中 top-2 各专家的亲和力加起来,算出亲和力最高的 top_k_group 个组,然后在这些组里选 top-k 个专家)。
- 4.最终将所有的 Share 输出和 Router 专家进行亲和度加权相加,得到 MoE 层的输出
白强伟的dp与pp并行原理图:
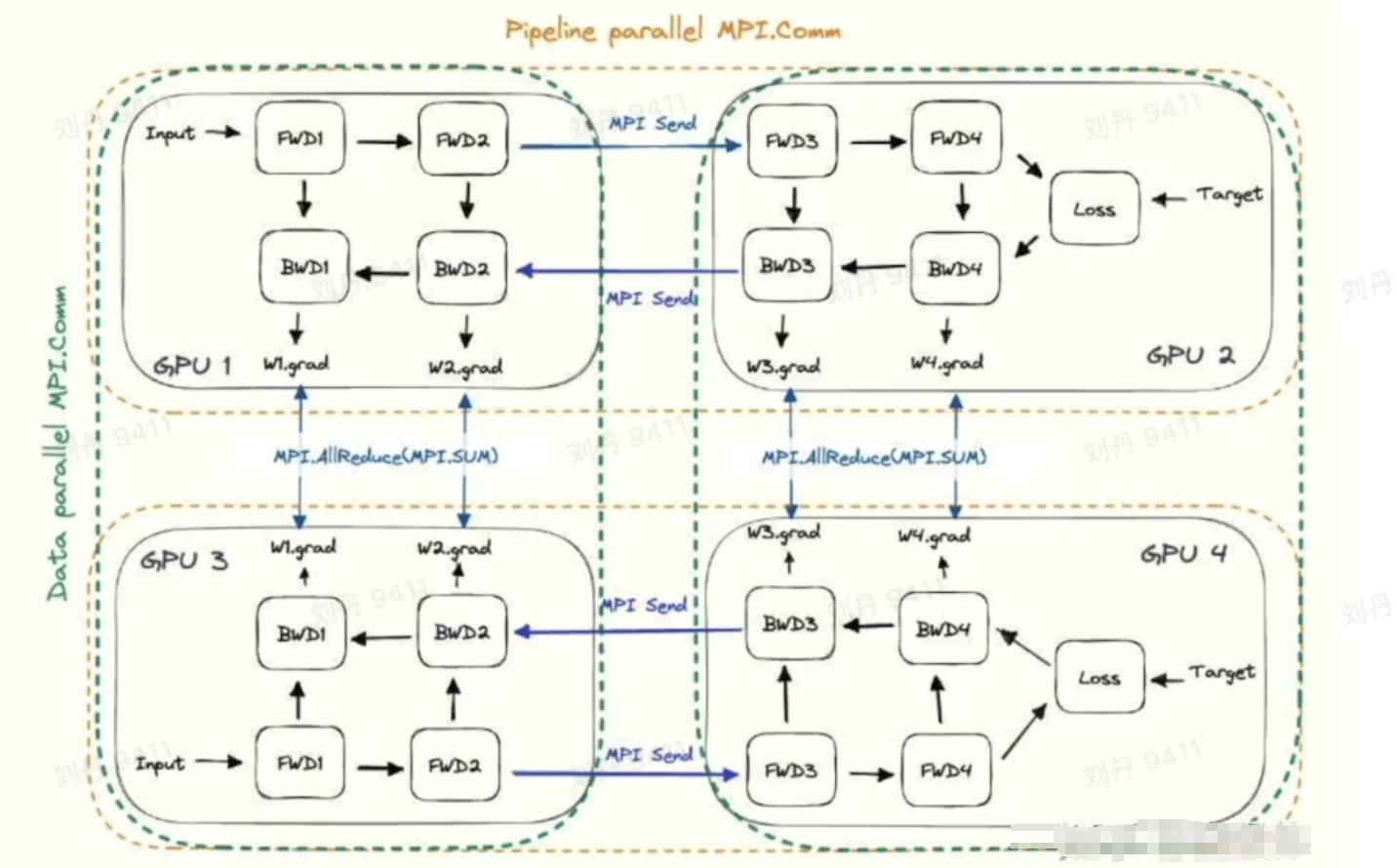
横向:同一数据在不同GPU、主机之间通信;
纵向:两个不同的input数据输入,计算出不同的loss,上下两个模型的梯度要求平均
1原始 MLP 的计算量
![- **两个矩阵**:
第一个矩阵:[h, 2.5h]。
第二个矩阵:[2.5h, h]。
每个 token 向量的计算量为:](https://i-blog.csdnimg.cn/direct/eac9eb36aae34da19bb3da8a416cdf3a.png)
2 MoE 的计算量

四、GRPO:群体相对策略优化(DeepSeek-Math,2024年4月)
从PPO 到 GRPO
Proximal Policy Optimization (PPO,2017)是一个 actor-critic 形式的RL算法 , 常用于LLMs中的fine-tuning阶段 ( 2022). 其通过最大化以下公式,优化LLMs :
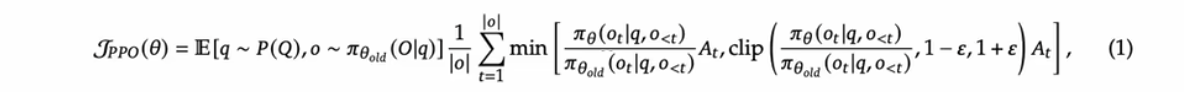
其中 π θ π_θ πθ 和 π θ o l d π_{θold} πθold分别是当前和旧的policy models,q,o 是从数据集中采样的问题和输出结果。 A t A_t At是优势函数,通过 Generalized Advantage Estimation (GAE,2015)计算得到。
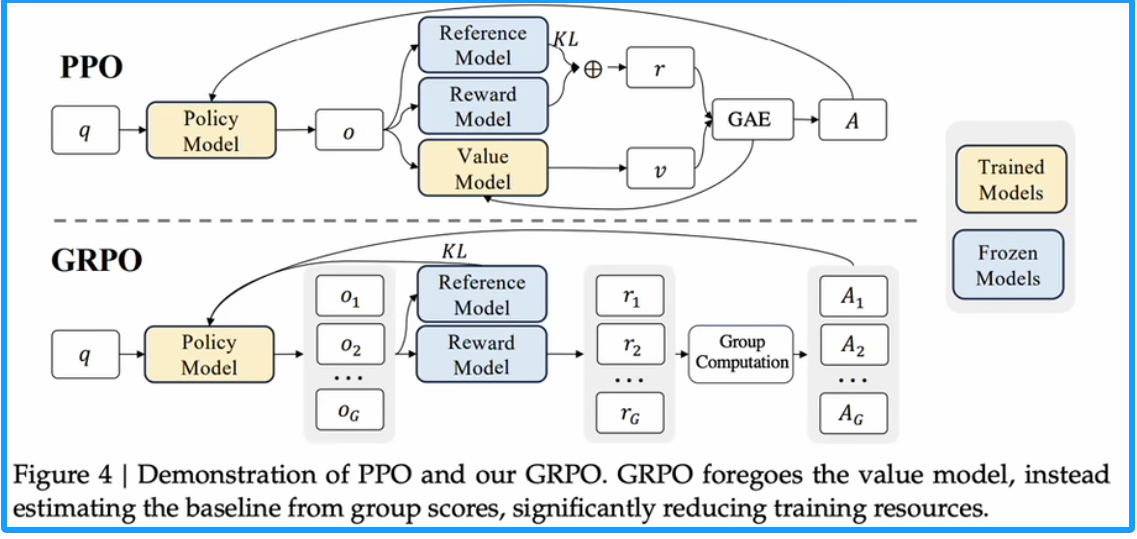
其中的KL-penalty:

GRPO目标函数:


1.以上GRPO不再计算Critic估计的优势函数,而是以组内的相对奖励作为优势进行训练。
- a.以下每次采样获得的优势,是该次采样的奖励减去组内奖励均值并且处以方差,即标准化过程
- b标准化过程的目的是:不同组内标准化有一个统一量纲:(每一个组代表ACTOR同输入下,不同的O.输出采样)
i.举例如下第一组(代码题)分数,5,4,3。第二组(写作)分数1,2,3。
ii.如果不做标准化,所有优势为正,更加重要的是,由于两组的整体均值为3,此时将导致第-第二组所有样本被惩罚。这种情况下完全不会使得模型变好,组所有样本被奖励,
2.为什么不使用dpo和ppo:
DPO(Distributed Policy Optimization)是一种分布式策略优化算法,它允许多个智能体(agents)在环境中并行地进行学习和策略优化。DPO的核心思想是通过分布式计算资源来加速学习过程,同时保持策略更新的稳定性和一致性。这种方法通常用于大规模强化学习问题,其中单个智能体的学习效率可能不足以在合理的时间内达到满意的性能。
- a.Dpo的数据样式:prompt:你好。answer1:你好,有什么可以帮您。answer2:我现在很忙,戴一a.边去。(离线强化学习)
标注成本高,将注定难以泛化。 - b.dpo需要对每个输入,标注至少两个相对优劣的answer,
- c.由于

PPO(Proximal Policy Optimization)由OpenAI提出,它是一种策略梯度方法,旨在通过限制策略更新的步长来确保训练的稳定性。PPO通过引入一个剪裁机制来避免过大的策略更新,这有助于防止策略性能的剧烈波动,并使得算法更加鲁棒
- d.ppo算法的优势依赖于Critic模型对状态价值进行估计,Value的的含义是当前状态未来所有可能的奖励(reward)期望总和,reward本身就是reward model进行估计的,使用Critic model估计value将更加难以泛化(reward model的误差将会二次放大)。

五、三代注意力:从MHA到MLA(DeepSeek-V2,2024年6月)
5.1 LLM推理过程,以及MHA(多头注意力)
LLM推理分为两个阶段:prefill阶段和 decode阶段
-
prefill阶段:是模型对全部的Prompt tokens一次性并行计算,最终会生成第一个输出token
-
decode阶段:每次生成一个token,直到生成EOS(end-of-sequence)token,产出最终的response
推理过程中,由于模型堆叠了多层transformer,所以核心的计算消耗在Transformer内部,包括MHA,FFN等操作,其中MHA要计算Q,K ,V 矩阵,来做多头注意力的计算。MiniCPM1.0(一个基于 Transformer的小型语言模型)中transformer计算过程如下:

Wq、Wk、Wv的个数不同。x通过和第 i i i头的 W i q Wiq Wiq, W i k Wik Wik, W i v Wiv Wiv投影得到第 i i i头的 q i qi qi, k i ki ki, v i vi vi的值。
代码中:代码中没有只有一个 W q Wq Wq即self.project_q,将x与self.project_q相乘后得到所有头的q值,再对q进行维度的切分,获得qi。简而言之:就是先切分后投影, 代码是先投影后切分。
注意力计算公式如下:
代码实现:
# 1.输入三个矩阵对hidden_state分别进行投影获得q,k,v三个值,类似图(4)操作
query = self.project_q(hidden_q)# [b,l,H]
key = self.project_k(hidden_kv)#
[b,l,H] value = self.project_v(hidden_kv)# [b,l,H]# 2.然后对q,k,v三个值在最后一维H进行切分成num_heads*h,维度从[b,l,H]变成[b,l,num_head,h]。类似图(4)
query = query.view(batch_size, len_q, self.num_heads, self.dim_head).permute(0, 2, 1, 3)
key = key.view(batch_size, len_k, self.num_heads, self.dim_head).permute(0, 2, 1, 3)
value = value.view(batch_size, len_k, self.num_heads, self.dim_head).permute(0, 2, 1, 3)# 3.进行注意力计算Attension:
#下面这行计算的是Q*KT,并且加上绝对位置编码
score = torch.matmul(query, key.transpose(-1, -2)) / math.sqrt(self.dim_head)
score = score + position_bias# 下面这行代码是加上了上三角为负无穷大的attentionmask,也就是单向注意力的由来
score = torch.masked_fill(score,attention_mask.view(batch_size, 1, len_q, len_k) == torch.tensor(False),torch.scalar_tensor(float("-inf"), device=score.device, dtype=score.dtype),
)
# 以下是进行softmax操作
score = self.softmax(score)#将pad的位置注意力归零
score = torch.masked_fill(score,attention_mask.view(batch_size, 1, len_q, len_k) == torch.tensor(False),torch.scalar_tensor(0, device=score.device, dtype=score.dtype),
)
# 以下这行是计算softmax(q*kT)*v的结果,socre=softmax(q*kT
# (batch_size, num_heads, len_q, len_k) @ (batch_size, num_heads, len_k, dim_head) -> (batch_size, num_heads, len_q, dim_head)
score = torch.matmul(score, value)# 4.以下实现上图中(5)操作,score的最终输出即为图中的z
# 以下两行是将多头聚合成单头
score = score.view(batch_size, self.num_heads, len_q, self.dim_head).permute(0, 2, 1, 3)
score = score.contiguous().view(batch_size, len_q, self.num_heads * self.dim_head)# 和o矩阵相乘,作为attention的最终输出
score = self.attention_out(score)
5.1.1 MHA的KVcache
在prefill阶段,模型会对输入的全部Prompt tokens进行一次性的并行计算,目的是为后续的自回归生成(decode阶段)做好准备。
a.Prefill阶段,具体步骤:
-
1.输入:整个Prompt序列 X=[ x 1 , x 2 , … , x n x_1,x_2,…,x_n x1,x2,…,xn]。
-
2.计算:
对每个token x i x_i xi ,计算其对应的Key K i K_i Ki 和 Value V i V_i Vi :
K i = W k ⋅ x i K_i=W_k·x_i Ki=Wk⋅xi, V i = W v ⋅ x i V_i=W_v·x_i Vi=Wv⋅xi ;同时计算每个token的Query Q i = W q ⋅ x i Q_i=W_q·x_i Qi=Wq⋅xi -
3.注意力计算:
使用所有token的 Q i , K i Q_i,K_i Qi,Ki和 V i V_i Vi 计算注意力分数,并生成每个token的上下文表示。 -
4.输出:
通过解码器的输出层,生成第一个输出token y1
b.KV-cache的初始化:
在prefill阶段,模型会计算并缓存所有Prompt tokens的Key和Value:
KV-cache =[ K 1 , K 2 , . . . , K n K_1, K_2, ..., K_n K1,K2,...,Kn], [ V 1 , V 2 , . . . , V n V_1, V_2, ..., V_n V1,V2,...,Vn]
这些缓存的Key和Value将在decode阶段被重复使用。
c.Decode阶段,具体步骤:
decode阶段,模型以自回归的方式逐步生成输出token,直到生成结束符(EOF)或达到最大生成长度
-
1初始输入
第一个输出token y 1 y_1 y1(即 x 1 x_1 x1)作为decode阶段的输入。 -
2.计算:
对 y 1 y_1 y1,计算其Query Q 1 Q_1 Q1: Q i = W Q ⋅ y 1 Q_i= W_Q·y_1 Qi=WQ⋅y1
使用prefill阶段缓存的Key和Value(即 K 1 : n K_{1:n} K1:n 和 V 1 : n V_{1:n} V1:n)计算注意力分数,并生成 y 1 y_1 y1的上下文表示
通过解码器的输出层,生成第二个输出token y 2 y_2 y2(即 x 2 x_2 x2)。 -
3.更新KV-cache
将 y 1 y_1 y1 对应的Key 和 Value 追加到KV-cache中:
KV-cache = KV-cache U [ K n + 1 , V n + 1 K_{n+1} , V_{n+1} Kn+1,Vn+1] -
4.迭代生成
重复上述过程,每次生成一个新token ",并将其对应的Key和Value追加到KV-cache中,直到生成结束符(EOF)或达到最大生成长度。
5.1.2 LLM推理阶段显存使用情况
为了直观理解访存的速率,我们以一个分布式推理架构为例。
比如2台机器,每台机器有8张A100, 那么在这样一个系统内,卡内,单机卡间,机器之间的数据访问效率如图3所示。注:我们的例子中,只描述了一种访存介质HBM (也就是我们常说的显卡的显存),我们知道通常GPU的存储介质除了显存,还有SRAM和DRAM。SRAM也被成为片上存储,是GPU计算单元上即时访问更快的存储,所有的计算都要先调度到片上存储SRAM才能做计算,一般只有几十M大小,带宽可达到20T/s左右,SRAM是跟计算单元强绑定的,推理阶段一般不考虑将SRAM作为存储单元使用。而DRAM是我们常说的CPU的内存,由于访问速率较慢,推理阶段一般也不考虑使用。所以我们讨论的推理存储介质,一般就指的是HBM(显存)
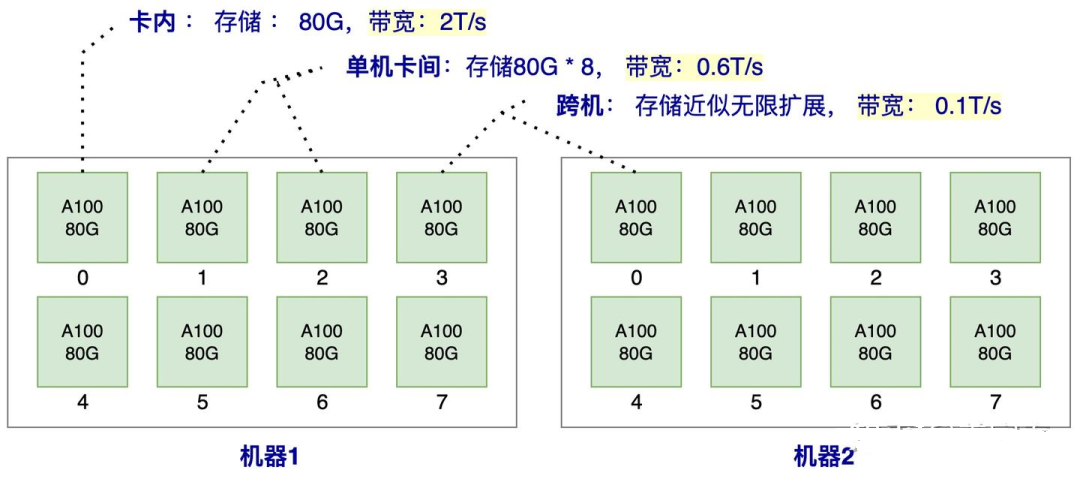
由上图的访存带宽可知,卡内的带宽是单机卡间的带宽的3倍,是跨机带宽的20倍,所以我们对于存储的数据应该优先放到卡内,其次单机内,最后可能才考虑跨机存储。
推理阶段显存占用(左)vs单个token kv缓存数据(右):


减少KV-cache的四类方法:
-
共享KV:多个Head共享使用1组KV,将原来每个Head一个KV,变成1组Head一个KV,来压缩KV的存储。代表方法:GQA,MQA等
-
窗口KV:针对长序列控制一个计算KV的窗口,KV cache只保存窗口内的结果(窗口长度远小于序列长度),超出窗口的KV会被丢弃,通过这种方法能减少KV的存储,当然也会损失一定的长文推理效果。代表方法:Longformer等
-
量化压缩:基于量化的方法,通过更低的Bit位来保存KV,将单KV结果进一步压缩,代表方法:INT8等
-
计算优化:通过优化计算过程,减少访存换入换出的次数,让更多计算在片上存储SRAM进行,以提升推理性能,代表方法:flashAttention等
MiniCPM 2.0:GQA (Grouped Query Attention,分组查询注意力机制),是对 MHA 的一种优化。GQA 将查询(Query)分组,共享键(Key)和值(Value),从而减少计算量和内存占用。在保持较高性能的同时,显著降低了计算成本,适合资源受限的场景
MHA是Q、K、V三者数量都和注意力头数(num_heads)相同。
GQA是Q的数量仍然和注意力头数(num_heads)相同。将注意力头数(num_heads)平均分成多个group,k和v每一个group共用。

在每个头计算注意力分数时(下图),Q每个头都是不同的,但是下图中的K和V在同一个group中是共用的。

5.2 MLA(即将到来)
六、MTP:多token预测(DeepSeek-V3,2024年12月)
24年12月底,深度求索公司再次推出DeepSeek-V2的升级版——DeepSeek-V3,其总参数量达671B,每个token激活37B个参数,GitHub地址为:github.com/deepseek-ai/DeepSeek-V3。 表现:V3训练成本:所用的GPU训练资源仅为Llama 3.1 405B的差不多1/14。
考虑到H100-80G和H800这两者的算力差不多,所以对比小时数的话
-Llama 3.3 或Llama 3.1训练:3930 万 H100 GPU 小时
-DeepSeek-V3 训练:278.8 万 H800 GPU 小时
来源:Meta官方的Llama 3.3 GitHub链接:“Training Energy Use Training utilized a cumulative of 39.3M GPU hours of computation on H100-80GB (TDP of 700W) type hardware, per the table below; llama 3.1的技术报告第9页中:“Llama 3 405B is trained on up to 16K H100 GPUs”。第13页称,“During a 54-day snapshot period of pre-training, we experienced a total of 466 job interruptions”
综上所述:考虑到54天是1296h,故16,384GPU×1,296小时=21,233,664GPU 小时 ≈ 2,123万 GPU 小时。因为涉及到各种中断,再加上后续的长上下文扩展、后训练,故最终llama 3.1所用的GPU训练资源和llama 3.3应该是差不多的——即39.3M GPU hours of computation on H100-80GB
模型架构层:
MTP区别于Next Token Prediction,能够预测多个token
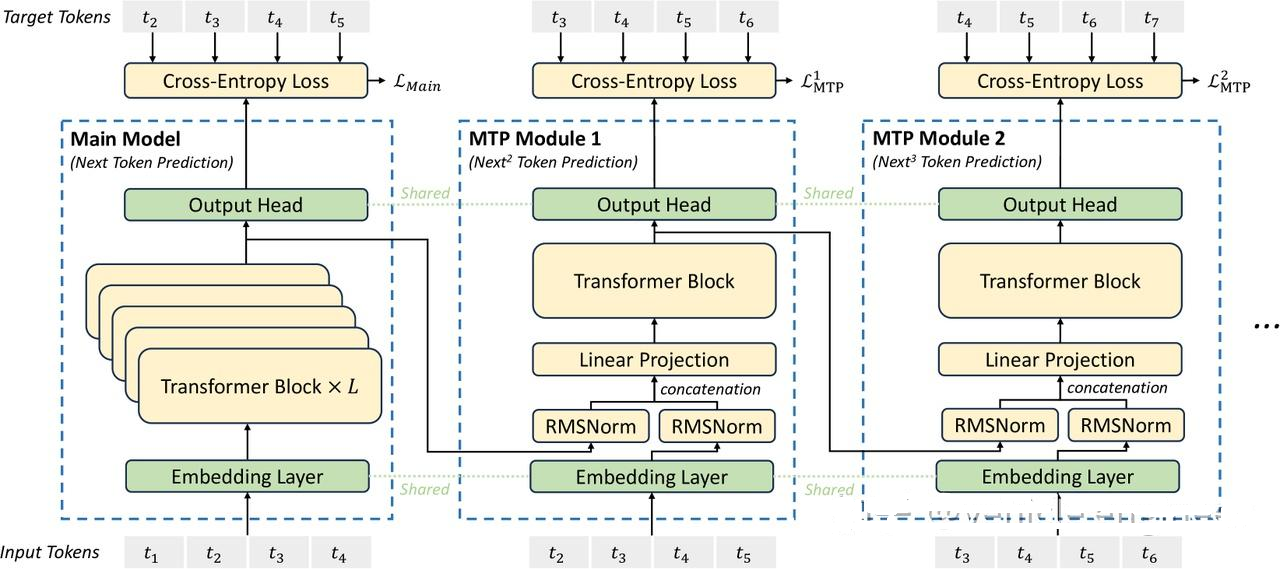
MTP 代码复现
class MTP_and_deepseek(nn.Module,config):def __init__(self,config:Deepseekv3Config):super().__init__()self.share_embedding = share_embedding(config)self.share_lm_head = share_output_head(config)self.loss = nn.CrossEntropyLoss(ignore = config.pad_token_id)self.Model_trans_blocks = nn.ModuleList([transformer_block(config, layer_idx)for layer_idx in range(config.num_hidden_layers)])self.MTP_trans_blocks = nn.ModuleList([transformer_block(config, layer_idx)for layer_idx in range(config.num_MTP_layers)])self.config = configself.alpha_list = config.alpha_list#对于每一个MTPloss的加权列表def forward(self,input_ids):## input_ids :###[bos,tok1,tok2......last_tok]##labels_origin:##[tok1,tok2,....,last_tok,eos/pad]##labels_MTP1##[tok2,.....last_tok,eos,pad]##labels_MTP2##[tok3,.....last_tok,eos,pad,pad]embeding_logits = self.share_embedding(input_ids)deepseek_hidden = embeding_logitsfor index,trans_block in enumerate(self.Model_trans_blocks):deepseek_hidden = trans_block(deepseek_hidden)deepseek_logits = self.share_lm_head(deepseek_hidden)labels = torch.cat([input_ids[:, 1:], torch.full((input_ids.size(0), 1), config.pad_token_id)], dim=1)Main_loss = self.loss(deepseek_logits,labels)last_mtp_out = deepseek_hiddenfor ind, MTP in enumerate(self.MTP_trans_blocks):input_ids_trunc = torch.cat([input_ids[:, ind + 1 :], # 截取从 ind+1 开始的部分torch.full((input_ids.size(0), ind + 1), self.config.pad_token_id), # 在后面添加 pad_token_id],dim=1,) mtp_out = MTP(last_mtp_out,input_ids_trunc,self.share_embedding)mtp_logits = self.share_lm_head(mtp_out)last_mtp_out = mtp_outlabels_trunc = torch.cat([input_ids_trunc[:, 1:], torch.full((input_ids.size(0), 1), config.pad_token_id)], dim=1)mtp_loss = self.loss(mtp_logits,labels_trunc)alpha = self.alpha_list[ind]Main_loss += alpha*mtp_lossreturn Main_loss
七、DeepSeek-R1
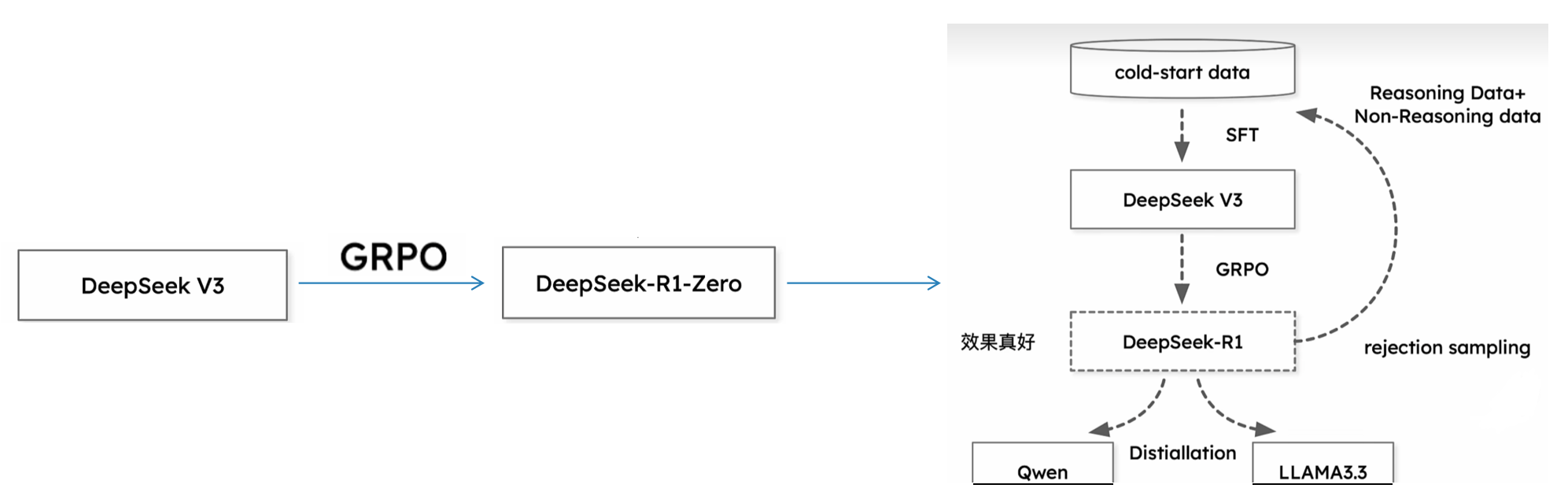
Reward model
-
奖励分为两块,一块是格式,一块是输出结果
-
不使用模特卡罗搜索树和过程奖励(PRM),不使用PRM的原因是:
1.难以对过程建立较好的reward判断,容易出现reward hack。
2.难以控制奖励的粒度,比如句子级、token级、还是cot级。
3.数据标注变得复杂,也难以泛化。 -
不使用MCTS(蒙特卡洛搜索树),这个主要由于句子生成的状态空间太大(比如长链条数据假设上限长度10000,中文词表数30000,状态空间将高达) 3000 0 10000 30000^{10000} 3000010000,状态空间太大,难以训练泛化性良好的Critic 模型估计Value。
-
训练:zero模型给予一个推理思考的模板,
DeepSeek-R1-Zero数据模板:

- zero模型在强化学习过程中会逐渐增加推理长度,从而获得正确答案,这是因为对于复杂问题,长链条的思考会结合反思逐步增加正确率,然后正确答案获得奖励,从而改变模型的推理范式。

SFT数据构成:
- 推理(cot)数据:使用之前RL的检查点进行数据生成,之前第一轮只用规则能够验证的通过的数据,后面我们可以扩充部分通过reward model拒绝采样的数据。
- 非推理数据:对于简单问题直接回复,否则直接使用deepseek v3的cot回复,进行数据收集。
- 为了与人类的偏好一致,再次进行了强化学习,这次强化学习与instruct gpt 相同,主要考虑无害性和有用性。
总结
提示:这里对文章进行总结:
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilon ϵ
ϕ \phi ϕ
Trick-GS
摘要。为了向设备友好型GS迈出一步,我们对高效生成GS管道的各种方法进行了原则性的分析。这些方法包括高斯剪枝[6]、渐进式训练[8]、[9]、模糊[8]和球谐函数的mask[10]。经过仔细的探索,我们提出了Trick-GS,这是一种通过系统地结合这些方法而创建的GS方法。Trick-GS在多个基准数据集上具有与普通GS和其他紧凑GS方法相当的精度,与其他方法相比,拥有2×的训练速度,40×更小的磁盘尺寸和2×的渲染速度。此外,Trick-GS是灵活的,人们可以调整设计,以确定管道的不同方面的优先级,如收敛和渲染速度、准确性和磁盘大小。
1.根据体积裁剪(Pruning with Volume Masking)
较小scale的高斯往往对整体质量的影响很小,需要学习mask和去除这种高斯。简而言之,学习N个高斯的N个二进制掩码, M ∈ M∈ M∈{0,1} N ^N N,应用于不透明度 α ∈ α∈ α∈[0,1] N ^N N,和非负的scale属性, s ∈ R + N × 3 s∈R^{N×3}_+ s∈R+N×3。然后对学习到的mask进行阈值处理,生成hard mask M:

其中,ϵ为掩蔽阈值,sg为停止梯度算子,1(·)和σ(·)分别为指示函数和s型函数。训练中,高斯在稠密化阶段使用这些mask进行裁剪,并在稠密化阶段后的每 k m k_m km次迭代中进行裁剪。
2.根据重要性裁剪(Pruning with Significance of Gaussians)
找到并删除对总体影响很小的高斯,高斯的影响是通过考虑它被光线击中的频率来决定的。更具体地说,所谓的重要性得分计算为 1 ( G ( X j ) , r i ) 1(G(X_j),r_i) 1(G(Xj),ri),其中 1 ( ⋅ ) 1(·) 1(⋅)是指标函数, r i r_i ri是训练集中每条射线i,Xj是高斯j命中ri的次数。然后这个分数与高斯的体积和不透明度在等式4。
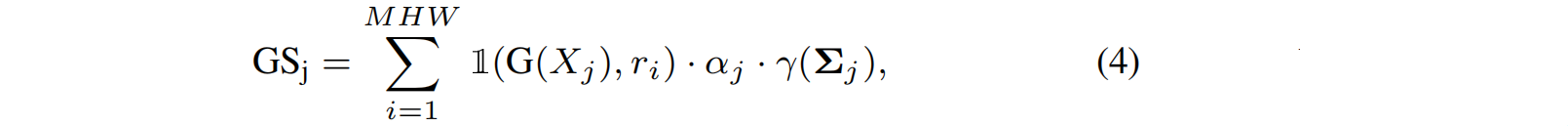
其中 j j j为高斯索引, i i i为像素, γ ( Σ j ) γ(Σ_j) γ(Σj)为高斯体积,M、H和W表示视图数量、图像宽高。然后,通过标准化所有排序高斯函数中高斯体积的前90%,以避免过度的浮动高斯分布。这个显著性得分用于在训练期间修剪预设的高斯函数的百分位数。由于这是一个昂贵的操作,我们在训练中使用这种修剪 k s g k_{sg} ksg次,考虑到上一轮中删除的百分比因数。
3.球形谐波(SH)mask
SHs被用来表示高斯的视图相关颜色,然而,并不是所有的高斯 have the same levels of varying colors depending on the scene(大致意思是不是所有高斯都是degree 3级这么高阶)。采用[End-to-end rate-distortion optimized 3d gaussian representation]策略,根据训练过程中学习到的mask 对SH band进行裁剪,并在训练完成后去除不必要的band。具体来说,每个高斯人在每个SH波段学习一个掩模。SH掩模的计算方法为等式如果对应的SH波段l的第i个高斯值值为零,则它的硬掩模Msh l i值为零,否则为不变。
mask计算与最终颜色渲染为:
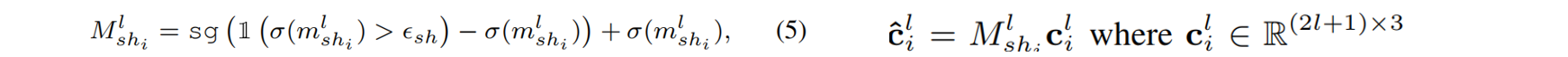
4.渐进式训练
高斯分布的渐进训练是指从较粗糙、较不详细的图像表示开始,逐渐将表示变回原始图像。该方法已被证明是一种正则化方案[8][9],用于高斯分布的稠密化和裁剪,因为从SfM点云中对高斯分布的初始化可以是次最优的。三种策略:
by blurring 。高斯模糊用于改变图像中的细节level。核大小在每 k b k_b kb次迭代时根据衰减因子逐步降低。该策略有助于从高斯分布的次优初始化中去除浮动伪影,并作为一种正则化来收敛到一个更好的局部最小值。它也显著地影响了训练时间,因为一个较粗的场景表示需要更少的高斯数来表示场景
by resolution 从较小的图像开始,在训练期间逐步提高图像分辨率,以帮助学习更广泛的全局信息[8][9]。这种方法特别帮助学习前景对象后面像素的更细粒度细节。

r e s ( i ) res(i) res(i)为第i次训练迭代时的图像分辨率, r e s s res_s ress为起始图像分辨率, r e s e res_e rese为全训练图像分辨率, τ r e s τ_{res} τres为阈值迭代。
by scales of Gaussians. 另一种策略是,在栅格化阶段,通过控制低通滤波器,在训练的早期阶段关注低频细节。如果每个三维高斯按照下式投影,一些高斯可能会小于单个像素,从而导致artifacts。协方差 Σ i ′ Σ'_i Σi′替换为 Σ i ′ + s I Σ'_i+sI Σi′+sI(在对角线元素中添加一个小值,s = 0.3,I是一个单位阵)。
优化过程中逐步改变每个高斯在的s,以确保每个高斯在在屏幕空间中覆盖的最小面积。在优化的开始阶段使用较大的s可以使高斯分布从更宽的区域接收梯度,因此可以有效地学习场景的粗结构。值s保证投影高斯面积大于9πs,证明请参考[28],s定义为s = HW/9πN,其中N、H和W分别表示高斯数、图像高度和宽度。随着高斯数的增加,该策略的下界为默认值为s = 0.3。我们从SfM初始化的20%的3D点开始优化,它具有最小的误差,以帮助更有效的训练。
5.3DGS的加速训练
在栅格化过程中,从第0波段分离出较高的SH波段(separating higher SH bands from the 0 t h 0^{th} 0th band),从而降低了较高的SH波段的更新次数。SH波段(45个dims)覆盖了这些更新的很大一部分,其中它们仅用于表示与视图相关的颜色变化。[23]修改光栅化器,从散射中分离出SH band(modifies the rasterizer to split
SH bands from the diffused color)。SH波段每16次迭代更新一次,其中散射颜色在每一步更新一次。为了加快训练速度,我们进一步用优化的CUDA内核修改了SSIM损失计算[23]。SSIM按标准配置为11×11高斯核卷积,其中优化版本是用两个较小的一维高斯核替换较大的二维核得到的。SSIM指标是用卷积输出的 a fused kernel计算的。对更高的SH波段应用较少的更新次数和优化SSIM损失计算对精度的影响可以忽略不计,而有助于加速训练时间。
损失定义为(只有 Gaussian 和 SH masking是可学习的):
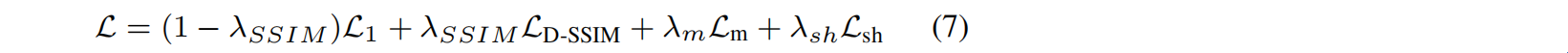
实验
实验设置。15个场景来自有界和无界的室内/室外场景;9个来自MipNeRF360,2个(卡车和火车)来自Tanks&Temples和2个(德约翰逊和游戏室)来自Deep Blending数据集。每个数据集中的每8张图像用于测试。模型经过30K次迭代的训练,并使用PSNR、SSIM和LPIPS 进行评估。
应用了一个简单的后处理,在训练后使用半张量存储所有16位精度的高斯参数,因为我们发现精度下降是不显著的。所有实验在NVIDIA RTX 3090上。
我们将图像降采样8×,并通过对数衰减逐渐增加到原来的分辨率,直到19500年迭代。类似地,我们对从9×9和σ = 2.4开始的训练图像应用高斯模糊,每 k b = 100 k_b =100 kb=100次迭代逐渐减少,直到19500次迭代。
ABE split 和渐进尺度策略用于10K迭代。之后,标准稠密化在每100次迭代中启用,直到迭代至15K。每100次迭代中的20K到20.5K的之间进行稠密化,以帮助模型恢复the loss that is from pruning of false-positive Gaussians。学习率分别为0.5和0.05,用于学习高斯掩模和SH掩模。选择损失权值和掩模阈值 λ m = λ s h = ϵ m = 0.05 λ_m = λ_{sh} =ϵ_m=0.05 λm=λsh=ϵm=0.05和 ϵ s h = 0.1 ϵ_{sh}=0.1 ϵsh=0.1。使用高斯掩模在每个致密化步骤和致密化停止后的每500次迭代中进行高斯化修剪
基于重要性评分的高斯剪枝应用6次,直到迭代22K,第一次剪枝率设置为60%,下一次迭代使用剪枝衰减因子为0.7
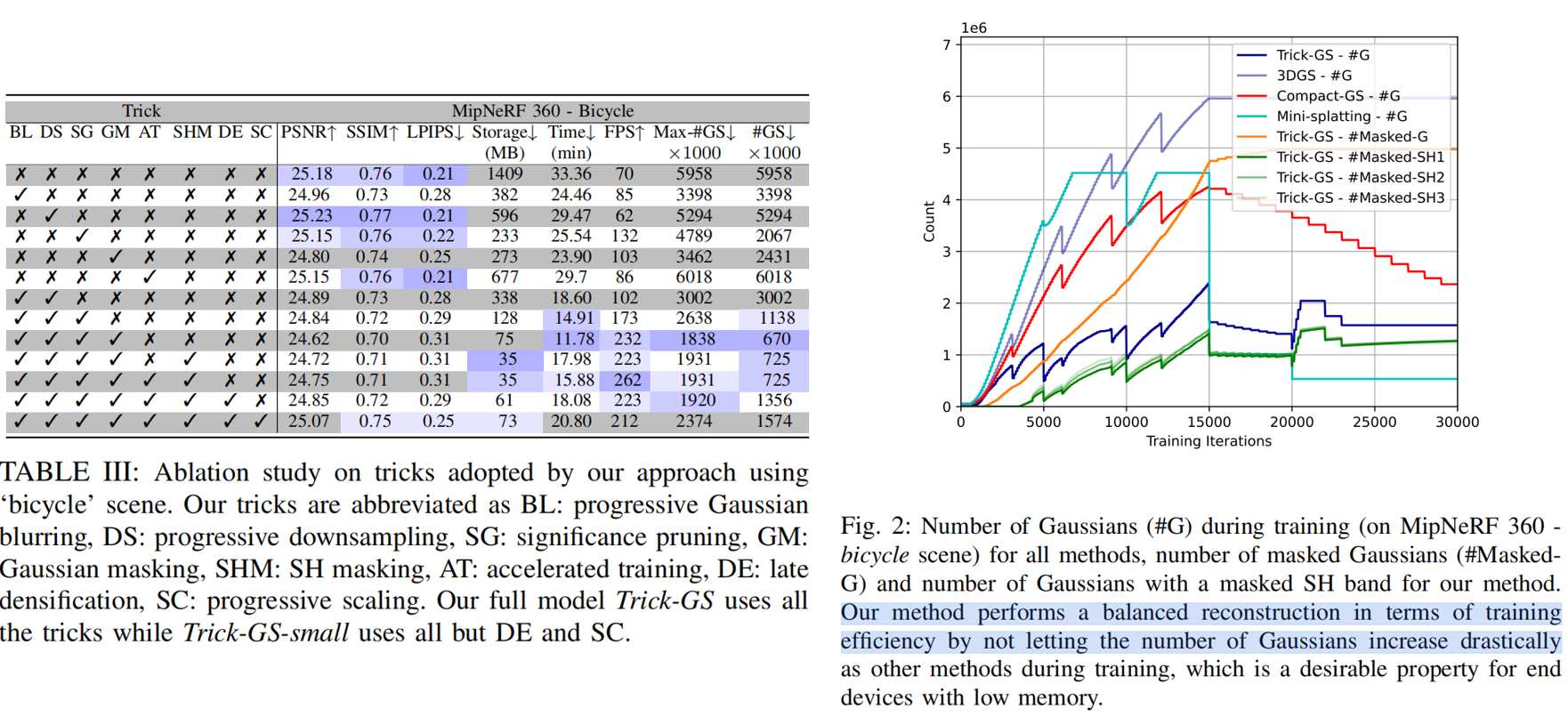
模型Trick-GS-small压缩了23×模型大小,训练时间和FPS分别提高了1.7×和2×。然而,这导致了准确性的轻微损失;模型Trick-GS使用后期的稠密化和渐进的基于尺度训练,不牺牲准确性
与Trick-GS-small相比,Trick-GS将PSNR平均提高了0.2 dB,存储空间减少了50%,训练时间减少了15%。


相关文章:
【大模型】DeepSeek使用与原理解析:从V3到R1
文章目录 一、引言二、使用与测评1.7大R1使用技巧2.官网实测 发展历程三、Deepseek MoE:专家负载均衡 (2024年1月)四、GRPO:群体相对策略优化(DeepSeek-Math,2024年4月)五、三代注意力ÿ…...

DAY04 Object、Date类、DateFormat类、Calendar类、Math类、System类
学习目标 能够说出Object类的特点是所有类的祖宗类,任意的一个类都直接或者间接的继承了Object类,都可以使用Object类中的方法Animal extends Object:直接继承Cat extends Animal:间接继承 能够重写Object类的toString方法altinsert,选择toString 能够重写Object类的equals方法…...

oracle 19c安装DBRU补丁时报错CheckSystemSpace的处理
oracle 19c的补丁目前已经发布到19.26版本了,数据库补丁安装也是数据库运维中的一个常见工作;近期在一个安装补丁的环境遇到了Prerequisite check "CheckSystemSpace" failed.错误,看起来是磁盘剩余空间不足的告警;按以…...

图像生成GAN和风格迁移
文章目录 摘要abstract1.生成对抗网络 GAN1.1 算法步骤 2.风格迁移2.1 损失函数2.2 论文阅读2.2.1 简介2.2.2 方法2.2.3 实验2.2.4 结论 3.总结 摘要 本周学习了生成对抗网络(GAN)与风格迁移技术在图像生成中的应用。首先介绍了GAN模型中生成器与判别器…...

golangAPI调用deepseek
目录 1.deepseek官方API调用文档1.访问格式2.curl组装 2.go代码1. config 配置2.模型相关3.错误处理4.deepseekAPI接口实现5. 调用使用 3.响应实例 1.deepseek官方API调用文档 1.访问格式 现在我们来解析这个curl 2.curl组装 // 这是请求头要加的参数-H "Content-Type:…...

【第15章:量子深度学习与未来趋势—15.3 量子深度学习在图像处理、自然语言处理等领域的应用潜力分析】
一、开篇:为什么我们需要关注这场"量子+AI"的世纪联姻? 各位技术爱好者们,今天我们要聊的这个话题,可能是未来十年最值得押注的技术革命——量子深度学习。这不是简单的"1+1=2"的物理叠加,而是一场可能彻底改写AI发展轨迹的范式转移。 想象这样一个…...

JAVA安全—Shiro反序列化DNS利用链CC利用链AES动态调试
前言 讲了FastJson反序列化的原理和利用链,今天讲一下Shiro的反序列化利用,这个也是目前比较热门的。 原生态反序列化 我们先来复习一下原生态的反序列化,之前也是讲过的,打开我们写过的serialization_demo。代码也很简单&…...

LangChain大模型应用开发:提示词工程应用与实践
介绍 大家好,博主又来给大家分享知识了。今天给大家分享的内容是LangChain提示词工程应用与实践。 在如今火热的大语言模型应用领域里,LangChain可是一个相当强大且实用的工具。而其中的提示词(Prompt),更是我们与语言模型进行有效沟通的关…...

【数据结构入门 65 题】目录
目录 1 函数题2 编程题3 数据结构实现 1 函数题 6-1 单链表逆转 6-2~6-6 线性表基本操作 6-7 在一个数组中实现两个堆栈 6-8 求二叉树高度 6-9 二叉树的遍历 6-10 二分查找 6-11 先序输出叶结点 6-12 二叉搜索树的操作集 2 编程题 3 数据结构实现 栈和队列...
)
osgearth控件显示中文(八)
当前自己知道的方法大概有以下两种: (一)直接转成utf8 其实在前面的文章中已经有了。 osgEarth::Annotation::PlaceNode *pn = new osgEarth::Annotation::PlaceNode(GeoPoint(geoSRS, 110, 34), String2UTF8("中国"), style);std::wstring String2Wstring(con…...

2025 N1CTF crypto 复现
近一个月都没有学习了,一些比赛也没有打,很惭愧自己还是处在刚放假时的水平啊,马上开学了,抓紧做一些训练来康复。 CheckIn import os from Crypto.Util.number import * from secret import FLAGp, q getPrime(512), getPrime…...

Windows Defender Control--禁用Windows安全中心
Windows Defender Control--禁用Windows安全中心 链接:https://pan.xunlei.com/s/VOJDuy2ZEqswU4sEgf12JthZA1?pwdtre6#...

mount 出现 2038 问题
在 linux 上挂载 ext4 文件系统时出现了 2038 年问题,如下: [ 236.388500] EXT4-fs (mmcblk0p2): mounted filesystem with ordered data mode. Opts: (null) [ 236.388560] ext4 filesystem being mounted at /root/tmp supports timestamps until 2…...

langchain+不同模型api使用教程
目录 一、Langchainopenai1. gpt-4o2. o13. o3-mini 二、Anthropic1.claude-3-5-sonnet-latest 三、四、 一、Langchainopenai langchain_community 可能是一个较旧的库,或者它的版本与 OpenAI 的最新 API 不兼容。OpenAI 的 API 可能会更新,而 langcha…...

【第12章:深度学习与伦理、隐私—12.4 深度学习与伦理、隐私领域的未来挑战与应对策略】
凌晨三点的自动驾驶测试场,AI系统突然在暴雨中做出惊人决策——它选择撞向隔离带而不是紧急变道,因为算法推演发现隔离带后的应急车道站着五个工程师。这个惊悚的伦理困境,揭开了深度学习伦理危机最尖锐的冰山一角。 一、潘多拉魔盒已开:深度学习伦理的四大原罪 1.1 数据原…...

2. 图片性能优化
图片性能优化 图片懒加载 如何判断图片出现在了当前视口 (即如何判断我们能够看到图片)如何控制图片的加载 原生实现 <img src"shanyue.jpg" loading"lazy" />loading"lazy" 延迟加载图像,直到它和视…...

Java与DeepSeek的完美结合:开启高效智能编程新时代 [特殊字符]
一、DeepSeek:Java开发者的智能编程伙伴 🤖 1.1 DeepSeek是什么? DeepSeek是一款AI驱动的智能编程工具,通过深度学习和自然语言处理技术,为Java开发者提供: 智能代码补全:根据上下文预测代码 …...

RL--2
强化学习当中最难的两个点是: 1.reward delay; 2.agent的行为会影响到之后看到的东西,所以agent要学会探索世界; 关于强化学习的不同类型,可以分为以下三种: 一种是policy based:可以理解为它是…...

SpringMVC新版本踩坑[已解决]
问题: 在使用最新版本springMVC做项目部署时,浏览器反复500,如下图: 异常描述: 类型异常报告 消息Request processing failed: java.lang.IllegalArgumentException: Name for argument of type [int] not specifie…...

2025 pwn_A_childs_dream
文章目录 fc/sfc mesen下载和使用推荐 fc/sfc https://www.mesen.ca/docs/ mesen2安装,vscode安装zg 任天堂yyds w d 左右移动 u结束游戏 i崩溃或者卡死了 L暂停 D658地方有个flag 发现DEEE会使用他。且只有这个地方,maybe会输出flag,应…...

pandas(11 分类数据和数据可视化)
前面内容:pandas(10 日期和Timedelta) 目录 一、Python Pandas 分类数据 1.1 pd.Categorical() 1.2 describe() 1.3 获取类别的属性 1.4 分类操作 1.5 分类数据的比较 二、Python Pandas 数据可视化 2.1 基础绘图:plot 2.2 条形图 2.3 直方…...

Redis 03章——10大数据类型概述
一、which10 (1)一图 (2)提前声明 这里说的数据类型是value的数据类型,key的类型都是字符串 官网:Understand Redis data types | Docs (3)分别是 1.3.1redis字符串࿰…...

bps是什么意思
本文来自DeepSeek "bps" 是 "bits per second" 的缩写,表示每秒传输的比特数,用于衡量数据传输速率。1 bps 即每秒传输 1 比特。 常见单位 bps:比特每秒 Kbps:千比特每秒(1 Kbps 1,000 bps&am…...

撕碎QT面具(1):Tab Widget转到某个Tab页
笔者未系统学过C语法,仅有Java基础,具体写法仿照于大模型以及其它博客。自我感觉,如果会一门对象语言,没必要先刻意学C,因为自己具有对象语言的基础,等需要用什么再学也不迟。毕竟不是专门学C去搞算法。 1…...

PCL源码分析:点云数学形态学操作
文章目录 一、简介二、源码分析三、实现效果参考资料一、简介 基本原理:使用结构元素(通常为滤波的窗口)的窗口模板作为处理单元,利用形态学中的膨胀与腐蚀相组合即可达到滤波的效果。 点云数据中的数学形态学运算其实和二维图像上的运算非常相似,图像上像素有x,y和亮度值…...

项目版本号生成
需求 项目想要生成一个更新版本号,格式为v2.0.20250101。 其中v2.0为版本号,更新时进行配置;20250101为更新日期,版本更新时自动生成。 实现思路 创建一个配置文件version.properties,在其中配置版本号;…...

rtsp rtmp 跟 http 区别
一 会话管理 与SDP 1. RTSP(Real Time Streaming Protocol) (1) 是否需要建立会话? 需要显式会话。 RTSP 是基于会话的协议,客户端与服务端通过 SETUP、PLAY、TEARDOWN 等命令明确控制会话生命周期。 会话标识:通过…...

善筹网设计与实现(代码+数据库+LW)
摘 要 信息数据从传统到当代,是一直在变革当中,突如其来的互联网让传统的信息管理看到了革命性的曙光,因为传统信息管理从时效性,还是安全性,还是可操作性等各个方面来讲,遇到了互联网时代才发现能补上自…...

SQL SERVER的PARTITION BY应用场景
SQL SERVER的PARTITION BY关键字说明介绍 PARTITION BY关键字介绍具体使用场景排名计算累计求和分组求最值分组内百分比计算分组内移动平均计算分组内数据分布统计分组内数据偏移计算 总结 PARTITION BY关键字介绍 在SQL SERVER中,关键字PARTITION BY主要用于窗口函…...

使用 MindSpore 训练 DeepSeek-V3 模型
MindeSpore 已经适配 DeepSeek-V3 的训练推理啦,下面是使用 MindSpore 对DeepSeek-V3做训练的过程。 一、环境确认 这里呢我使用的是 8张 910B2 的显卡: 其中 MindSpore Transformers 的环境依赖如下: PythonMindSporeCANN固件与驱动3.1…...