Kafka偏移量管理全攻略:从基础概念到高级操作实战
#作者:猎人
文章目录
- 前言:
- 概念剖析
- kafka的两种位移
- 消费位移
- 消息的位移
- 位移的提交
- 自动提交
- 手动提交
- 1、使用--to-earliest重置消费组消费指定topic进度
- 2、使用--to-offset重置消费offset
- 3、使用--to-datetime策略指定时间重置offset
- 4、使用--to-current 重置offset
- 5、使用--shift-by 重置offset
- 6、使用--by-duration 重置offset
- 7、使用--from-file cvs文档重置offset
- 8、删除偏移量(--delete-offsets)
- 9、查询消费者成员信息(--members)
- 10、查询消费者组状态信息(--state)
- 11、查看topic指定分区offset的最大偏移量值(最新offsets)或最小值(--time)
- 12、查询topic的offset的范围(消费了多少条消息)
前言:
在Kafka Version为0.11.0.0之后,Consumer的Offset信息不再默认保存在Zookeeper上,而是选择用Topic的形式保存下来。在命令行中可以使用kafka-consumer-groups的脚本实现Offset的相关操作。kafka把位移保存在一个叫做__consumer_offsets的内部主题中,叫做位移主题。既然它也是主题,那么离不开分区和副本这两个机制。我们并没有手动创建这个主题并且指定,所以是kafka自动创建的,分区的数量取决于Broker 端参数 offsets.topic.num.partitions,默认是50个分区,而副本参数取决于offsets.topic.replication.factor,默认是3。
任何主题都会有消息,会存在消息格式。肯定也会有删除策略,否则消息会无限膨胀。但是位移主题的删除策略和其他主题删除策略又不太一样。我们知道普通主题的删除是可以通过配置删除时间或者大小的。而位移主题的删除,叫做 Compaction。Kafka 使用Compact 策略来删除位移主题中的过期消息,对于同一个 Key 的两条消息 M1 和 M2,如果 M1 的发送时间早于 M2,那么 M1 就是过期消息。Compact 的过程就是扫描日志的所有消息,剔除那些过期的消息,然后把剩下的消息整理在一起。
概念剖析
设置位移偏移量可分java api方式和命令方式2种,命令方式更方便简单。
kafka的两种位移
关于位移(Offset),其实在kafka里有两种位移:
-
分区位移:生产者向分区写入消息,每条消息在分区中的位置信息由一个叫offset的数据来表征。假设一个生产者向一个空分区写入了 10 条消息,那么这 10 条消息的位移依次是 0、1、…、9;
-
消费位移:消费者需要记录消费进度,即消费到了哪个分区的哪个位置上,这是消费者位移(Consumer Offset)。
注意,这和上面所说的消息在分区上的位移完全不是一个概念。上面的“位移”表征的是分区内的消息位置,它是不变的,即一旦消息被成功写入到一个分区上,它的位移值就是固定的了。而消费者位移则不同,它可能是随时变化的,毕竟它是消费者消费进度的指示器。
消费位移
消费位移,记录的是 Consumer 要消费的下一条消息的位移,切记,是下一条消息的位移! 而不是目前最新消费
消息的位移
假设一个分区中有 10 条消息,位移分别是 0 到 9。某个 Consumer 应用已消费了 5 条消息,这就说明该 Consumer 消费了位移为 0 到 4 的 5 条消息,此时 Consumer 的位移是 5,指向了下一条消息的位移。
至于为什么要有消费位移,很好理解,当 Consumer 发生故障重启之后,就能够从 Kafka 中读取之前提交的位移值,然后从相应的位移处继续消费,从而避免整个消费过程重来一遍。就好像书签一样,需要书签你才可以快速找到你上次读书的位置。
那么了解了位移是什么以及它的重要性,我们自然而然会有一个疑问,kafka是怎么记录、怎么保存、怎么管理位移的呢?
位移的提交
Consumer 需要上报自己的位移数据,这个汇报过程被称为位移提交。因为 Consumer 能够同时消费多个分区的数据,所以位移的提交实际上是在分区粒度上进行的,即Consumer 需要为分配给它的每个分区提交各自的位移数据。
鉴于位移提交甚至是位移管理对 Consumer 端的巨大影响,KafkaConsumer API提供了多种提交位移的方法,每一种都有各自的用途,这些都是本文将要谈到的方案。
位移提交分为自动提交和手动提交;而手动提交又分为同步提交和异步提交。
自动提交
当消费配置enable.auto.commit=true的时候代表自动提交位移。
自动提交位移是发生在什么时候呢?auto.commit.interval.ms默认值是50000ms。即kafka每隔5s会帮你自动提交一次位移。自动位移提交的动作是在 poll()方法的逻辑里完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移。假如消费数据量特别大,可以设置的短一点。越简单的东西功能越不足,自动提交位移省事的同时肯定会带来一些问题。自动提交带来重复消费和消息丢失的问题:
重复消费
在默认情况下,Consumer 每 5 秒自动提交一次位移。现在,我们假设提交位移之后的 3 秒发生了 Rebalance 操作。在 Rebalance 之后,所有 Consumer 从上一次提交的位移处继续消费,但该位移已经是 3 秒前的位移数据了,故在 Rebalance 发生前 3 秒消费的所有数据都要重新再消费一次。虽然你能够通过减少 auto.commit.interval.ms 的值来提高提交频率,但这么做只能缩小重复消费的时间窗口,不可能完全消除它。这是自动提交机制的一个缺陷。
消息丢失
假设拉取了100条消息,正在处理第50条消息的时候,到达了自动提交窗口期,自动提交线程将拉取到的每个分区的最大消息位移进行提交,如果此时消费服务挂掉,消息并未处理结束,但却提交了最大位移,下次重启就从100条那消费,即发生了50-100条的消息丢失。
手动提交
当消费配置enable.auto.commit=false的时候代表手动提交位移。用户必须在适当的时机(一般是处理完业务逻辑后),手动的调用相关api方法提交位移。
手动提交明显能解决消息丢失的问题,因为你是处理完业务逻辑后再提交的,假如此时消费服务挂掉,消息并未处理结束,那么重启的时候还会重新消费。
但是对于业务层面的失败导致消息未消费成功,是无法处理的。因为业务层的逻辑千变万化、比如格式不正确,你叫Kafka消费端程序怎么去处理?应该要业务层面自己处理,记录失败日志做好监控等。
另外手动提交不能解决消息重复的问题,也很好理解,假如消费0-100条消息,50条时挂了,重启后由于没有提交这一批消息的offset,是会从0开始重新消费。
手动提交又分为异步提交和同步提交。这个涉及业务java代码,略。
更新Offset的三个维度:Topic的作用域,重置策略,执行方案。
Topic的作用域:下面是kafka-consumer-groups.sh可携带的参数(下面命令执行时必须带–group groupname)
- –reset-offsets:重置消费组的偏移量。后面可接 --to-earliest --to-latest --xxxxx 等等等
- -–reset-offsets-by-duration:指定重置的时间(从现在往前)。
- -–reset-offsets-by-topic:指定重置的topic和partition。
- -–reset-offsets-by-times:指定重置的时间点。
- -–new-consumer:使用新消费者API。
- -–topic:指定要操作的topic。
- -–exclude-internal:不列出.kafka/*的topic。
- –all-topics:为consumer group下所有topic的所有分区调整位移。列出所有topic的所有消费组。
- –topic t1 --topic t2:为指定的若干个topic的所有分区调整位移
- –topic t1:0,1,2:为指定的topic分区调整位移,可单个分区、多个分区调整
- –to-earliest:把位移调整到分区当前最小位移。设置到最早位移处,也就是0。分区中第一条消息。
- –to-latest:把位移调整到分区当前最新位移。最后一个offset,即主题分区HW的位置(HW可理解为木桶原理的最低点)。分区中最后一条消息
- –to-current:把位移调整到分区当前位移。直接重置offset到当前的offset,也就是LOE。
- –to-offset <offset数值>: 把当前位移调整到指定位移处(偏移量),指定具体的位移位置。重置到指定的offset;
- –shift-by N: 把位移调整到当前位移 + N处,注意N可以是负数,表示向前移动。 基于当前位移向前回退多少。
- –to-datetime:将消费者的偏移量重置为大于或等于指定日期时间的最早偏移量。你需要提供符合yyyy-MM-ddTHH:mm:ss.xxx格式的日期时间。–to-datetime重置到指定时间的offset。把位移调整到大于给定时间的最早位移处,datetime格式是yyyy-MM-ddTHH:mm:ss.xxx,比如2017-08-04T00:00:00.000。DateTime 允许你指定一个时间,然后将位移重置到该时间之后的最早位移处。
- –by-duration :将消费者的偏移量重置为当前时间减去指定时长的位置。例如,P1D表示一天前,PT2H表示两小时前,PT3M表示3分钟前,PT5S表示5秒前。
- –from-file :从CSV文件中读取调整策略。根据CVS文档来重置。从CSV文件中读取重置策略。CSV文件应包含消费者组、主题和分区信息,以及相应的偏移量或时间戳。
执行方案
什么参数都不加:只是打印出位移调整方案,不具体执行
- –execute:执行真正的位移调整。
- –export:把位移调整方案按照CSV格式打印,方便用户成csv文件,供后续直接使用。
注意事项
- consumer group状态必须是inactive的,即不能是处于正在工作中的状态
- 不加执行方案,默认是只做打印操作
kafka-consumer-groups.sh可携带的其他参数:
- command-config:kafka的安全认证配置文件路径。
- group:指定要操作的消费组。
- describe:列出消费组的详情。
- delete:删除消费组。
- dry-run:仅输出要执行的操作,不实际运行。
kafka-run-class.sh可携带的其他参数:
运行kafka-run-class.sh脚本,调用kafka.admin.TopicCommand类,kafka.tools.DumpLogSegments类,kafka.tools.GetOffsetShell 类等等,同时接受一个操作指令参数。
该指令包括:
- create 创建topic
- alter 修改topic
- list 列举topic
- describe 描述topic
- delete 删除topic
- topic
- time //后接-1时表最大值,含义是-1时用来请求分区最新的offset --> 每个分区最大的offset。后接-2时表最小值,-2时用来请求分区最早有效的offset --> 例如,有些offset 在7(设置)天删除数据, 最早的0,但是最早有效的不一定是0 。后面也可接具体的timestamp,如–time 16423252638。
–broker-list //接kafka ip:9092 ,必须使用broker-list,不能使用–bootstrap-server
1、使用–to-earliest重置消费组消费指定topic进度
注意:设置offset前提是停止生产和消费的业务服务(如果所有topic是–all-topics,具体topic加 --topic)
重置某topic的offset。本命令可更新到当前group最初的offset位置,就是0
更新所有topic到当前最初的offset位置,即最早位置,就是CURRENT-OFFSET为0(如果是具体topic加 --topic).再次查询消费组消费状态发现CURRENT-OFFSET列都变0了
–group参数必须携带,指定消费组
]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --group console-consumer-20733 --reset-offsets --all-topics --to-earliest --execute


案例二:

更新offset位置为0后,再次消费该topic全部消息,然后再次查询消费组情况,发现CURRENT-OFFSET恢复到正常消费位移状态了

2、使用–to-offset重置消费offset
简单查询消费组状态:
[root@kafka18 ~]# ./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.40.18:9092 --list --state
GROUP STATE
console-consumer-61774 Stable
复杂查询消费组状态
snapshot]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --all-groups --describe --state
在Kafka中,消费者组的状态可以是以下几种之一,只有Inactive才可以重置消费点位:
Stable:消费者组正在正常消费,没有任何重平衡操作正在进行。
Rebalancing:消费者组正在进行重平衡操作,此时不能执行偏移量重置。
Joining:新的消费者正在加入消费者组。
PreparingRebalance:消费者组即将进行重平衡。
Syncing:消费者组正在进行同步操作,通常发生在重平衡之后。
需要先查询消费组等信息,client id这列为‘-’,才可执行重置命令(即设置offset前提是停止生产、消费的业务服务)。–to-offset <offset新数值>: 把当前位移调整到指定位移处
如果是具体topic加 --topic。调具体分区加–topic topic_name:0,1,2,可单分区、多分区调整
]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --group console-consumer-20733 --reset-offsets --all-topics --to-offset 500000 --execute
往高调验证:发现只有25这个执行成功了

往低调验证:

如果往低调值,都符合值的要求,则都执行成功。

按照具体分区调整案例:zgdx是topic名称,0是分区号,用冒号分开,属于固定语法。可单个分区、多个分区调整


3、使用–to-datetime策略指定时间重置offset
DateTime 允许你指定一个时间点,然后将位移重置到该时间之后的最早位移处。
所有topic的offset设置到指定时刻开始,如果指定时间太早,发现当前位移是0(当前CURRENT-OFFSET)(如果是具体topic加 --topic)
需要注意这个–to-datetime使用UTC伦敦时间,后必须接伦敦时间
命令案例
]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --group console-consumer-20733 --reset-offsets --all-topics --to-datetime 2024-06-14T09:30:00.000 --execute
因为服务器使用纽约时间,我们操作如,纽约时间2025-01-6T01:35:00.000时下面偏移量为120分区的偏移量分别为688。纽约时间2025-01-6T01:37:00.000时偏移量为120分区的偏移量分别为799。
当我们使用伦敦时间2025-01-6T06:35:00.000,也就是说纽约时间的06:35就是纽约时间的01:35,所以设置06:35的偏移量为688

可以看到我们再次设置纽约时间01:37时偏移量确实为799

4、使用–to-current 重置offset
更新所有topic到当前offset位置。但执行后当前任何位移都不会变动
]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --group console-consumer-20733 --reset-offsets --all-topics --to-current --execute

5、使用–shift-by 重置offset
所有topic的CURRENT-OFFSET的offset位置按设置的值进行位移,向前移动10(即减10)。如果是具体topic加 --topic
]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --group console-consumer-20733 --reset-offsets --all-topics --shift-by -10 --execute
–shift-by接调整的位移数量,接±值,使用加时+号可省略。-为减去CURRENT-OFFSET值。
向前移动案例:
可以看出如果CURRENT-OFFSET值不够减,CURRENT-OFFSET立刻归0。如果再次加位移值,则再下面方框基础上全部加值

6、使用–by-duration 重置offset
将所有分区位移调整为多少时间之前的最早位,可按照天、时、分、秒单位位移。例如,P1D表示1天前,PT2H表示两小时前,PT3M表示3分钟前,PT5S表示5秒前。
案例如:将所有分区位移调整为3分钟之前的最早位移
./kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --group console-consumer-20733 --reset-offsets --all-topics --by-duration PT3M --execute

7、使用–from-file cvs文档重置offset
通过cvs文档配置消费组”name”的”testTopic”上的所有分区的偏移量为10000
offsets.cvs格式为:Topic,分区号,偏移量 testTopic,0,10000
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group name --reset-offsets --from-file offsets.cvs --execute
8、删除偏移量(–delete-offsets)
能够执行成功的一个前提是 消费组这会是不可用状态; 偏移量被删除了之后,Consumer Group下次启动的时候,会从头消费; 将消费组console-consumer-20733的topic上的所有分区的偏移量删除
shot]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --group console-consumer-20733 --topic aaa --delete-offsets
Request succeed for deleting offsets with topic aaa group console-consumer-20733
TOPIC PARTITION STATUS
aaa 0 Successful
aaa 1 Successful
aaa 2 Successful
再次查询该消费组,发现查不到了
[root@localhost local]# /usr/local/kafka_2.13-2.7.1/bin/kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --group console-consumer-20733 --describe
Error: Consumer group 'console-consumer-20733' does not exist.
操作案例二:

9、查询消费者成员信息(–members)
查询消费者成员:
snapshot]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --all-groups --describe --members
Consumer group 'console-consumer-20733' has no active members.
GROUP CONSUMER-ID HOST CLIENT-ID #PARTITIONS
test-consumer-group consumer-test-consumer-group-1-bc47e46d-1a55-4e85-a383-41aa345d13e4 /192.168.40.14 consumer-test-consumer-group-1 3
10、查询消费者组状态信息(–state)
参数解释:
STATE:消费者组的状态。常见的状态有:
Stable:所有成员都已经成功加入了该组,并且正在进行正常的消费。
PreparingRebalance:组正在准备进行再平衡操作,此时消费者可能暂时停止消费。
CompletingRebalance:再平衡过程即将完成,消费者正重新分配分区。
Dead:消费者组不再活跃,可能是因为所有成员都已离开或崩溃。
Empty:组存在但没有任何活动成员。
MEMBERS:当前属于该消费者组的成员数量。
简单查询:
[root@kafka18 ~]# ./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.40.18:9092 --list --state
GROUP STATE
console-consumer-61774 Stable
复杂查询
snapshot]# ./kafka-consumer-groups.sh --bootstrap-server 192.168.40.11:9092 --all-groups --describe --state
Consumer group ‘console-consumer-20733’ has no active members.
GROUP COORDINATOR (ID) ASSIGNMENT-STRATEGY STATE #MEMBERS
console-consumer-20733 192.168.40.18:9092 (18) Empty 0
GROUP COORDINATOR (ID) ASSIGNMENT-STRATEGY STATE #MEMBERS
test-consumer-group 192.168.40.11:9092 (11) range Stable 1
11、查看topic指定分区offset的最大偏移量值(最新offsets)或最小值(–time)
必须用–broker-list 参数,指定任何ip输出结果一样。
time为-1时表最大偏移量值(最新offsets),为-2时表偏移量最小值,即起始偏移量,一般都为0。
–time 1589300000000表示时间戳,数字为具体时间戳。
bin]# ./kafka-run-class.sh kafka.tools.GetOffsetShell --topic aaa --time -1 --broker-list 192.168.40.11:9092
aaa:0:13
aaa:1:9
aaa:2:11]# ./kafka-run-class.sh kafka.tools.GetOffsetShell --topic aaa --time -1 --broker-list 192.168.40.11:9092 --partitions 0
aaa:0:13
经查询消费组消费情况证实,查看偏移量,最大offset确实是13


补充
12、查询topic的offset的范围(消费了多少条消息)
查询offset最小值,即起始偏移量:-2代表最小值
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic testTopic --time -2

查询offset最大值:-1代表最大值
aaa为topic名称,中间列为该topic分区号,有3个分区。最后一列代表该topic的该分区最新偏移量,即LOG-END,不是消费了多少的偏移量。从查询结果看,符合上述截图内容
]# ./bin/kafka-run-class.sh kafka.tools.GetOffsetShell --topic aaa --time -1 --broker-list 192.168.40.14:9092
aaa:0:11
aaa:1:9
aaa:2:10
相关文章:
Kafka偏移量管理全攻略:从基础概念到高级操作实战
#作者:猎人 文章目录 前言:概念剖析kafka的两种位移消费位移消息的位移位移的提交自动提交手动提交 1、使用--to-earliest重置消费组消费指定topic进度2、使用--to-offset重置消费offset3、使用--to-datetime策略指定时间重置offset4、使用--to-current…...

一周学会Flask3 Python Web开发-Debug模式开启
锋哥原创的Flask3 Python Web开发 Flask3视频教程: 2025版 Flask3 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili 默认情况,项目开发是普通模式,也就是你修改了代码,必须重启项目,新代码才生效&…...

单例模式、构造函数、左值右值
拷贝构造函数 简单的说就是——用一个对象构造另外一个对象 class Myclass {public:int d0;Myclass(int d_){d d_}; //常用的构造函数Myclass(Myclass c) //拷贝构造函数{d c.d;} }; //对比 class Myclass {public:int d0;Myclass(int d_){d d_}; //常用的构造函数Myclass…...

java练习(28)
ps:练习来自力扣 给定一个二叉树,判断它是否是平衡二叉树 // 定义二叉树节点类 class TreeNode {int val;TreeNode left;TreeNode right;TreeNode() {}TreeNode(int val) { this.val val; }TreeNode(int val, TreeNode left, TreeNode right) {this.va…...

【信息学奥赛一本通 C++题解】1285:最大上升子序列和
信息学奥赛一本通(C版)在线评测系统 基础算法 第一节 动态规划的基本模型 1285:最大上升子序列和 “最大上升子序列和”问题课堂讲解 1. 理解题意 同学们,想象我们有一串数字,就像一串彩色的珠子,每个珠子…...

深入了解 CSS 常用的样式
在网页开发中,CSS(层叠样式表)起着至关重要的作用,它可以让我们的网页变得更加美观和易于阅读。除了一些特定场景下的 CSS 样式,还有许多其他常用的 CSS 样式,下面就让我们一起来详细了解一下。 一、文本相…...

Web安全|渗透测试|网络安全
基础入门(P1-P5) p1概念名词 1.1域名 什么是域名? 域名:是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时对计算机的定位标识(有时也指地理位置)。 什么是二级域名多级域名&am…...
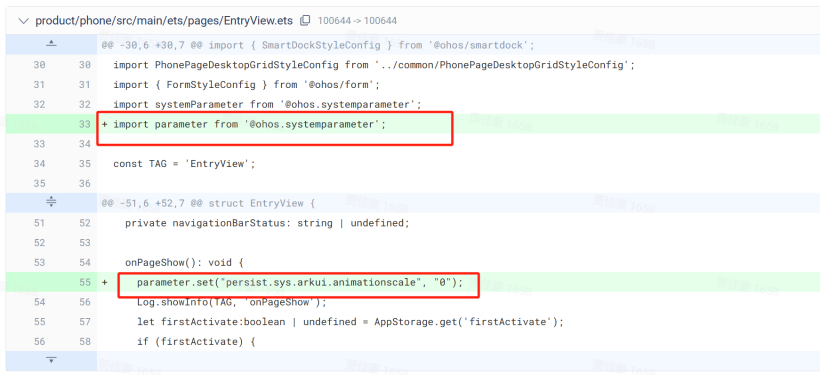
OpenHarmony 系统性能优化——默认关闭全局动画
笔者最近发现,关闭OpenHarmony全局动画,系统UI的响应速度会极大的提升 1.全局动画的开关由系统属性persist.sys.arkui.animationscale来控制,默认为1。也就是 动画缩放 1x 2.如果让persist.sys.arkui.animationscale默认为0,也就是关闭的状态…...

C 程序多线程拆分文件
C 程序多线程拆分文件 在C语言中,实现多线程来拆分文件通常需要借助多线程库,比如 POSIX 线程库(pthread)或者 Windows 的线程库(CreateThread 或类似的函数)。下面我将分别展示在 Linux 和 Windows 环境下…...

【Linux】Ubuntu Linux 系统——Python集成开发环境
ℹ️大家好,我是练小杰,今天周四了,明天就周五了,再坚持坚持又能休息了!!😆 本文是有关Linux 操作系统中Python集成开发环境基础知识,后续将添加更多相关知识噢,谢谢各位…...

数据库加密全解析:从传输到存储的安全实践
title: 数据库加密全解析:从传输到存储的安全实践 date: 2025/2/17 updated: 2025/2/17 author: cmdragon excerpt: 数据加密是数据库安全的最后一道物理防线。传输层SSL/TLS配置、存储加密技术及加密函数实战应用,覆盖MySQL、PostgreSQL、Oracle等主流数据库的20+生产级加密…...

【Prometheus】prometheus结合domain_exporter实现域名监控
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。 🏆《博客》:Python全…...

计算机专业知识【软件开发中的常用图表:E - R图、HIPO、DFD、N - S、PAD详解】
在软件开发过程中,有许多种图表工具被用于不同阶段的设计和分析,帮助开发者更清晰地理解系统结构、数据流程和算法逻辑。下面将详细介绍E - R图、HIPO图、DFD图、N - S图和PAD图,包括它们的样子和用途。 一、E - R图(实体 - 联系…...

机器学习_13 决策树知识总结
决策树是一种直观且强大的机器学习算法,广泛应用于分类和回归任务。它通过树状结构的决策规则来建模数据,易于理解和解释。今天,我们就来深入探讨决策树的原理、实现和应用。 一、决策树的基本概念 1.1 决策树的工作原理 决策树是一种基于…...

Linux 命令行编辑快捷键
初学者在Linux命令窗口(终端)敲命令时,肯定觉得通过输入一串一串的字符的方式来控制计算是效率很低。 但是Linux命令解释器(Shell)是有很多快捷键的,熟练掌握可以极大的提高操作效率。 下面列出最常用的快捷…...

智能马达保护器:为工业电机安全运行保驾护航
在工业生产中,电动机作为核心动力设备,其稳定运行直接关系到生产效率与安全性。然而,复杂的工况环境、频繁启停和突发负载变化,常导致电机面临过载、缺相、短路等故障风险。安科瑞智能马达保护器凭借其智能化、高精度、多功能的设…...

-bash:/usr/bin/rm: Argument list too long 解决办法
问题概述 小文件日志太多导致无法使用rm命令,因为命令行参数列表的长度超过了系统允许的最大值。 需要删除/tmp目录下的所有文件,文件数量比较多。 ls -lt /tmp | wc -l 5682452 解决方法如下: 使用find -exec 遍历,然后执行删…...

深度集成DeepSeek大模型:WebSocket流式聊天实现
目录 5分钟快速接入DeepSeek大模型:WebSocket实时聊天指南创建应用开发后端代码 (Python/Node.js)结语 5分钟快速接入DeepSeek大模型:WebSocket实时聊天指南 创建应用 访问DeepSeek官网 前往 DeepSeek官网。如果还没有账号,需要先注册一个。…...

Python函数的函数名250217
函数名其实就是一个变量,这个变量就是代指函数而已函数也可以被哈希,所以函数名也可以当作集合中的元素,也可作为字典的key值 # 将函数作为字典中的值,可以避免写大量的if...else语句 def fun1():return 123 def fun2():return 4…...

QT基础二、信号和槽
一、什么是信号和槽? 1、简述 在Qt框架中,信号和槽(Signals and Slots) 是一种用于对象间通信的机制。它是一种非常强大且灵活的设计模式,广泛应用于事件驱动编程中。信号和槽机制允许对象之间以松耦合的方式进行交互…...

MongoDB between ... and ... 操作
个人博客地址:MongoDB between ... and ... 操作 | 一张假钞的真实世界 MongoDB中类似SQL的between and操作可以采用如下语法: db.collection.find( { field: { $gt: value1, $lt: value2 } } );...

C++虚函数:解锁多态的“动态密码
C虚函数:解锁多态的“动态密码” 开篇小故事:遥控器的“智能按钮” 假设你有一个万能遥控器,上面只有一个“开关”按钮: 按下时,电视会开机,空调会制冷,电灯会亮起。同一个按钮,却…...
【深度学习】计算机视觉(CV)-目标检测-Faster R-CNN —— 高精度目标检测算法
1.什么是 Faster R-CNN? Faster R-CNN(Region-based Convolutional Neural Network) 是 目标检测(Object Detection) 领域的一种 双阶段(Two-Stage) 深度学习方法,由 Ross Girshick…...

Blazor-父子组件传递任意参数
在我们从父组件传参数给子组件时,可以通过子组件定义的[Parameter]特性的公开属性进行传值,但是当我们需要传递多个值的时候,就需要通过[Parameter]特性定义多个属性,有没有更简便的方式? 我们可以使用定义 IDictionar…...
【原创】vue-element-admin-plus完成编辑页面中嵌套列表功能
前言 vue-element-admin-plus对于复杂业务的支持程度确实不怎么样,我这里就遇到了编辑页面中还要嵌套列表的真实案例,比如字典,主字典嵌套子信息,类似于一个树状结构。目前vue-element-admin-plus给出的例子是无法满足这个需求的…...
【深度学习】计算机视觉(CV)-目标检测-DETR(DEtection TRansformer)—— 基于 Transformer 的端到端目标检测
1.什么是 DETR? DETR(DEtection TRansformer) 是 Facebook AI(FAIR)于 2020 年提出的 端到端目标检测算法,它基于 Transformer 架构,消除了 Faster R-CNN、YOLO 等方法中的 候选框(…...

DeepSeek教unity------MessagePack-02
内置支持类型: 对象序列化 MessagePack for C# 可以序列化你自己定义的公共类或结构体类型。默认情况下,可序列化的类型必须用 [MessagePackObject] 属性进行注解,成员需要用 [Key] 属性进行注解。键可以是索引(整数)…...

【达梦数据库】disql工具参数绑定
前言 在达梦数据库的使用过程中尽管管理工具很好用,但是命令行工具还是有着得天独厚的优势,但是在参数绑定方面就没有管理工具做的更加完美,现在就汇总下disql 工具参数绑定的常用几种方式 disql 参数绑定 使用 ? select * from v$dm_in…...

H5应用抓包及调试技巧
由于图片和格式解析问题,可前往 阅读原文 在现代移动互联网时代,H5 应用以其跨平台、轻量化、快速迭代的特性,成为移动开发的重要一环。然而,随着功能的复杂化和用户体验要求的提升,H5应用的调试也面临着诸多挑战&…...

Django后台新建管理员
在 Django 中,新建管理员用户通常涉及使用 Django 自带的命令行工具 manage.py。以下是具体步骤: 前提条件 Django 项目已创建:确保你已经创建了一个 Django 项目和应用。数据库已迁移:确保你已经运行了 python manage.py migra…...