SpringBoot教程(三十二) SpringBoot集成Skywalking链路跟踪
SpringBoot教程(三十二) | SpringBoot集成Skywalking链路跟踪
- 一、Skywalking是什么?
- 二、Skywalking与JDK版本的对应关系
- 三、Skywalking下载
- 四、Skywalking 数据存储
- 五、Skywalking 的启动
- 六、部署探针
-
- 前提: Agents 8.9.0 放入 项目工程
- 方式一:IDEA 部署探针
- 方式二:Java 命令行启动方式
- 方式三:编写sh脚本启动(linux环境)
- 七、Springboot 的启动
-
- IDEA 部署探针方式启动
- Skywalking 进行日志配置
- 实现入参、返参都可查看
-
- 方式一:通过 Agent 配置实现 (有缺点)
- 方式二:通过 trace 和 Filter 实现
- 方式三:通过 trace 和 Aop 去实现
一、Skywalking是什么?
SkyWalking是一个开源的、用于观测分布式系统(特别是微服务、云原生和容器化应用)的平台。
它提供了对分布式系统的追踪、监控和诊断能力。
二、Skywalking与JDK版本的对应关系
SkyWalking 8.x版本要求Java版本至少为8(即JDK 1.8),
SkyWalking 9.x版本则要求Java版本至少为11(即JDK 11)
所以选择的时候需要注意一下JDK版本。
三、Skywalking下载
Skywalking 官网下载地址 https://skywalking.apache.org/downloads/

-
其他的版本的 APM 地址
https://archive.apache.org/dist/skywalking/ -
其他的java 版本的 Agents 地址
https://archive.apache.org/dist/skywalking/java-agent/
注意点:
7.x及以下版本 APM 包里面有包括 Agents,但是8.x的就发现被分开了,所以8.x的及以上的 就需要 Agents 也得下载
目前该文选择 下载 APM 8.9.1 和 Agents 8.9.0 后解压

四、Skywalking 数据存储
Skywalking 存在多种数据存储
- h2(默认的存储方式,重启后数据会丢失)
- Elasticsearch (最常用的数据存储方式)
- MySQL
- TiDB
- …
相关文件OAP 配置文件(config/application.yml)
我只截取了关于设置存储方式的部分
storage:selector: ${SW_STORAGE:h2}elasticsearch:namespace: ${SW_NAMESPACE:""}clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}connectTimeout: ${SW_STORAGE_ES_CONNECT_TIMEOUT:500}socketTimeout: ${SW_STORAGE_ES_SOCKET_TIMEOUT:30000}numHttpClientThread: ${SW_STORAGE_ES_NUM_HTTP_CLIENT_THREAD:0}user: ${SW_ES_USER:""}password: ${SW_ES_PASSWORD:""}trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # Shard number of new indexesindexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1} # Replicas number of new indexes# Super data set has been defined in the codes, such as trace segments.The following 3 config would be improve es performance when storage super size data in es.superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1} # Represent the number of days in the super size dataset record index, the default value is the same as dayStep when the value is less than 0superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0} # Represent the replicas number in the super size dataset record index, the default value is 0.indexTemplateOrder: ${SW_STORAGE_ES_INDEX_TEMPLATE_ORDER:0} # the order of index templatebulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:5000} # Execute the async bulk record data every ${SW_STORAGE_ES_BULK_ACTIONS} requests# flush the bulk every 10 seconds whatever the number of requests# INT(flushInterval * 2/3) would be used for index refresh period.flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:15}concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requestsresultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200}oapAnalyzer: ${SW_STORAGE_ES_OAP_ANALYZER:"{"analyzer":{"oap_analyzer":{"type":"stop"}}}"} # the oap analyzer.oapLogAnalyzer: ${SW_STORAGE_ES_OAP_LOG_ANALYZER:"{"analyzer":{"oap_log_analyzer":{"type":"standard"}}}"} # the oap log analyzer. It could be customized by the ES analyzer configuration to support more language log formats, such as Chinese log, Japanese log and etc.advanced: ${SW_STORAGE_ES_ADVANCED:""}h2:driver: ${SW_STORAGE_H2_DRIVER:org.h2.jdbcx.JdbcDataSource}url: ${SW_STORAGE_H2_URL:jdbc:h2:mem:skywalking-oap-db;DB_CLOSE_DELAY=-1}user: ${SW_STORAGE_H2_USER:sa}metadataQueryMaxSize: ${SW_STORAGE_H2_QUERY_MAX_SIZE:5000}maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}maxSizeOfBatchSql: ${SW_STORAGE_MAX_SIZE_OF_BATCH_SQL:100}asyncBatchPersistentPoolSize: ${SW_STORAGE_ASYNC_BATCH_PERSISTENT_POOL_SIZE:1}mysql:properties:jdbcUrl: ${SW_JDBC_URL:"jdbc:mysql://localhost:3306/swtest?rewriteBatchedStatements=true"}dataSource.user: ${SW_DATA_SOURCE_USER:root}dataSource.password: ${SW_DATA_SOURCE_PASSWORD:root@1234}dataSource.cachePrepStmts: ${SW_DATA_SOURCE_CACHE_PREP_STMTS:true}dataSource.prepStmtCacheSize: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_SIZE:250}dataSource.prepStmtCacheSqlLimit: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_LIMIT:2048}dataSource.useServerPrepStmts: ${SW_DATA_SOURCE_USE_SERVER_PREP_STMTS:true}metadataQueryMaxSize: ${SW_STORAGE_MYSQL_QUERY_MAX_SIZE:5000}maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}maxSizeOfBatchSql: ${SW_STORAGE_MAX_SIZE_OF_BATCH_SQL:2000}asyncBatchPersistentPoolSize: ${SW_STORAGE_ASYNC_BATCH_PERSISTENT_POOL_SIZE:4}tidb:properties:jdbcUrl: ${SW_JDBC_URL:"jdbc:mysql://localhost:4000/tidbswtest?rewriteBatchedStatements=true"}dataSource.user: ${SW_DATA_SOURCE_USER:root}dataSource.password: ${SW_DATA_SOURCE_PASSWORD:""}dataSource.cachePrepStmts: ${SW_DATA_SOURCE_CACHE_PREP_STMTS:true}dataSource.prepStmtCacheSize: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_SIZE:250}dataSource.prepStmtCacheSqlLimit: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_LIMIT:2048}dataSource.useServerPrepStmts: ${SW_DATA_SOURCE_USE_SERVER_PREP_STMTS:true}dataSource.useAffectedRows: ${SW_DATA_SOURCE_USE_AFFECTED_ROWS:true}metadataQueryMaxSize: ${SW_STORAGE_MYSQL_QUERY_MAX_SIZE:5000}maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}maxSizeOfBatchSql: ${SW_STORAGE_MAX_SIZE_OF_BATCH_SQL:2000}asyncBatchPersistentPoolSize: ${SW_STORAGE_ASYNC_BATCH_PERSISTENT_POOL_SIZE:4}influxdb:# InfluxDB configurationurl: ${SW_STORAGE_INFLUXDB_URL:http://localhost:8086}user: ${SW_STORAGE_INFLUXDB_USER:root}password: ${SW_STORAGE_INFLUXDB_PASSWORD:}database: ${SW_STORAGE_INFLUXDB_DATABASE:skywalking}actions: ${SW_STORAGE_INFLUXDB_ACTIONS:1000} # the number of actions to collectduration: ${SW_STORAGE_INFLUXDB_DURATION:1000} # the time to wait at most (milliseconds)batchEnabled: ${SW_STORAGE_INFLUXDB_BATCH_ENABLED:true}fetchTaskLogMaxSize: ${SW_STORAGE_INFLUXDB_FETCH_TASK_LOG_MAX_SIZE:5000} # the max number of fetch task log in a requestconnectionResponseFormat: ${SW_STORAGE_INFLUXDB_CONNECTION_RESPONSE_FORMAT:MSGPACK} # the response format of connection to influxDB, cannot be anything but MSGPACK or JSON.postgresql:properties:jdbcUrl: ${SW_JDBC_URL:"jdbc:postgresql://localhost:5432/skywalking"}dataSource.user: ${SW_DATA_SOURCE_USER:postgres}dataSource.password: ${SW_DATA_SOURCE_PASSWORD:123456}dataSource.cachePrepStmts: ${SW_DATA_SOURCE_CACHE_PREP_STMTS:true}dataSource.prepStmtCacheSize: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_SIZE:250}dataSource.prepStmtCacheSqlLimit: ${SW_DATA_SOURCE_PREP_STMT_CACHE_SQL_LIMIT:2048}dataSource.useServerPrepStmts: ${SW_DATA_SOURCE_USE_SERVER_PREP_STMTS:true}metadataQueryMaxSize: ${SW_STORAGE_MYSQL_QUERY_MAX_SIZE:5000}maxSizeOfArrayColumn: ${SW_STORAGE_MAX_SIZE_OF_ARRAY_COLUMN:20}numOfSearchableValuesPerTag: ${SW_STORAGE_NUM_OF_SEARCHABLE_VALUES_PER_TAG:2}maxSizeOfBatchSql: ${SW_STORAGE_MAX_SIZE_OF_BATCH_SQL:2000}asyncBatchPersistentPoolSize: ${SW_STORAGE_ASYNC_BATCH_PERSISTENT_POOL_SIZE:4}zipkin-elasticsearch:namespace: ${SW_NAMESPACE:""}clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # Shard number of new indexesindexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1} # Replicas number of new indexes# Super data set has been defined in the codes, such as trace segments.The following 3 config would be improve es performance when storage super size data in es.superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1} # Represent the number of days in the super size dataset record index, the default value is the same as dayStep when the value is less than 0superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0} # Represent the replicas number in the super size dataset record index, the default value is 0.user: ${SW_ES_USER:""}password: ${SW_ES_PASSWORD:""}secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:5000} # Execute the async bulk record data every ${SW_STORAGE_ES_BULK_ACTIONS} requests# flush the bulk every 10 seconds whatever the number of requests# INT(flushInterval * 2/3) would be used for index refresh period.flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:15}concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requestsresultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200}oapAnalyzer: ${SW_STORAGE_ES_OAP_ANALYZER:"{"analyzer":{"oap_analyzer":{"type":"stop"}}}"} # the oap analyzer.oapLogAnalyzer: ${SW_STORAGE_ES_OAP_LOG_ANALYZER:"{"analyzer":{"oap_log_analyzer":{"type":"standard"}}}"} # the oap log analyzer. It could be customized by the ES analyzer configuration to support more language log formats, such as Chinese log, Japanese log and etc.advanced: ${SW_STORAGE_ES_ADVANCED:""}iotdb:host: ${SW_STORAGE_IOTDB_HOST:127.0.0.1}rpcPort: ${SW_STORAGE_IOTDB_RPC_PORT:6667}username: ${SW_STORAGE_IOTDB_USERNAME:root}password: ${SW_STORAGE_IOTDB_PASSWORD:root}storageGroup: ${SW_STORAGE_IOTDB_STORAGE_GROUP:root.skywalking}sessionPoolSize: ${SW_STORAGE_IOTDB_SESSIONPOOL_SIZE:16}fetchTaskLogMaxSize: ${SW_STORAGE_IOTDB_FETCH_TASK_LOG_MAX_SIZE:1000} # the max number of fetch task log in a request
五、Skywalking 的启动
进入 D:apache-skywalking-apm-8.9.1apache-skywalking-apm-binin ,双击运行 startup.bat(用管理员方式启动),会开启两个命令行窗口。
- (1)Skywalking-Collector:追踪信息收集器,通过 gRPC/Http 收集客户端的采集信息 。Http默认端口 12800,gRPC默认端口 11800。(如需要修改,可前往 apache-skywalking-apm-binconfigapplicaiton.yml 进行修改)
- (2)Skywalking-Webapp:管理平台页面 默认端口 8080 (如需要修改,可前往 apache-skywalking-apm-binwebappwebapp.yml 进行修改)
启动图如下:

接着浏览器Skywalking访问:http://localhost:8080/
这个右边有个自动刷新的按钮,一定要启动起来
不然到时候,springboot工程启动以后,你以为没有连接成功(F5刷新页面是没有用的)

六、部署探针
前提: Agents 8.9.0 放入 项目工程
也不说放其他位置不好,不过放到项目里面更好一点,后面你就能感受到便利了

方式一:IDEA 部署探针
修改启动类的 VM options(虚拟机选项)配置


配置的jvm参数如下:
-javaagent:D:ideaObjectreactBootspringboot-fullsrcmainskywalking-agentskywalking-agent.jar
-Dskywalking.agent.service_name=woqu-ndy
-Dskywalking.collector.backend_service=127.0.0.1:11800
- javaagent: 表示 skywalking‐agent.jar的本地磁盘的路径
(我这边是放到项目里面了)
-Dskywalking.agent.service_name:表示在skywalking上显示的服务名
-Dskywalking.collector.backend_service:表示skywalking的collector服务的IP及端口- 注意:-Dskywalking.collector.backend_service 可以指定远程地址, 但是 javaagent 必须绑定你本机物理路径的 skywalking-agent.jar
方式二:Java 命令行启动方式
java -javaagent:D:ideaObjectreactBootspringboot-fullsrcmainskywalking-agentskywalking-agent.jar=-Dskywalking.agent.service_name=service-myapp,-Dskywalking.collector.backend_service=localhost:11800 -jar service-myapp.jar
方式三:编写sh脚本启动(linux环境)
#!/bin/bash # 设置 SkyWalking Agent 的路径
AGENT_PATH="/home/yourusername/Desktop/apache-skywalking-apm-6.6.0/apache-skywalking-apm-bin/agent" # 设置 Java 应用的 JAR 文件路径
JAR_PATH="/path/to/your/service-myapp.jar" # 设置 SkyWalking 服务名称和 Collector 后端服务地址
SERVICE_NAME="service-myapp"
COLLECTOR_BACKEND_SERVICE="localhost:11800" # 构造 Java Agent 参数
JAVA_AGENT="-javaagent:$AGENT_PATH/skywalking-agent.jar -Dskywalking.agent.service_name=$SERVICE_NAME -Dskywalking.collector.backend_service=$COLLECTOR_BACKEND_SERVICE" # 启动 Java 应用
java $JAVA_AGENT -jar $JAR_PATH
七、Springboot 的启动
IDEA 部署探针方式启动
启动后,控制台日志输出开头出现了以下的记录,就表示连接上Skywalking了

再看 Skywalking(http://localhost:8080/) 页面那边,你就会发现有个这个图(表示连接上了)

我们再请求一下 Controller 的接口,就会发现捕获了相关接口记录
(但是目前,还是没有接口具体详细的日志入参或者出参的)


Skywalking 进行日志配置
为log日志增加 skywalking的 traceId(追踪ID)。便于排查
首先引入maven依赖
<!-- SkyWalking 的日志工具包 -->
<dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-logback-1.x</artifactId><version>9.0.0</version>
</dependency>
接着在 resources文件夹下创建 logback-spring.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false"><!--定义日志文件的存储地址 勿在 LogBack 的配置中使用相对路径--><property name="LOG_HOME" value="D:/logs/" ></property><!-- 彩色日志 --><conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter" /><!--控制台日志, 控制台输出 --><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder"><layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout"><!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符--><pattern>%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} [%X{tid}] %clr([%-10.10thread]){faint} %clr(%-5level) %clr(%-50.50logger{50}:%-3L){cyan} %clr(-){faint} %msg%n</pattern></layout></encoder></appender><!--文件日志, 按照每天生成日志文件 (只能是 由 Logger 或者 LoggerFactory 记录的日志消息哦)--><!--以下关于 日志文件的pattern 需要去掉颜色,防止出现 ANSI转义序列--><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!--日志文件输出的文件名--><FileNamePattern>${LOG_HOME}/%d{yyyy-MM-dd}/pro.log</FileNamePattern><!--日志文件保留天数--><MaxHistory>30</MaxHistory></rollingPolicy><encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder"><layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout"><!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符--><!-- <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>--><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{tid}] [%-10.10thread] %-5level %-50.50logger{50}:%-3L - %msg%n</pattern></layout></encoder><!--日志文件最大的大小--><triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy"><MaxFileSize>10MB</MaxFileSize></triggeringPolicy></appender><!--skywalking grpc 日志收集--><appender name="grpc" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender"><encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder"><layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout"><Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{tid}] [%thread] %-5level %logger{36} -%msg%n</Pattern></layout></encoder></appender><!-- 日志输出级别 --><root level="INFO"><appender-ref ref="STDOUT" ></appender-ref><appender-ref ref="FILE" ></appender-ref><appender-ref ref="grpc"/></root>
</configuration>
请求接口就可以发现TID的输出
(在这里是882c67dc859046c398fbfc5725df9de0.109.17288962842340001)

然后把它放到 追踪 栏目的追踪id ,可以查到记录

然后把它放到 日志 栏目的追踪id ,可以查到记录

实现入参、返参都可查看
方式一:通过 Agent 配置实现 (有缺点)
首先,你需要确认SkyWalking的Agent配置。
SkyWalking的Agent在启动时会读取配置文件,通常是agent.config。
默认情况下,请求参数的采集是关闭的,你需要手动开启。
具体步骤如下:
在你的SkyWalking Agent配置文件agent.config中,找到plugin部分,确保以下配置项设置为true:
plugin.tomcat.collect_http_params=${SW_PLUGIN_TOMCAT_COLLECT_HTTP_PARAMS:true}
plugin.springmvc.collect_http_params=${SW_PLUGIN_SPRINGMVC_COLLECT_HTTP_PARAMS:true}
plugin.httpclient.collect_http_params=${SW_PLUGIN_HTTPCLIENT_COLLECT_HTTP_PARAMS:true}
缺点:可是以上设置,只能开启get请求的入参采集,post无法获取到,这个方式不怎么好
方式二:通过 trace 和 Filter 实现
一、引入追踪工具包
<!-- SkyWalking 追踪工具包 -->
<dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-trace</artifactId><version>9.0.0</version>
</dependency>
二、使用 HttpFilter 和 ContentCachingRequestWrapper
知识小贴士:为什么不用HttpServletRequest?
如果直接把HttpServletRequest中的InputStream读取后输出日志,会导致后续业务逻辑读取不到InputStream中的内容,因为流只能读取一次。
package com.example.springbootfull.quartztest.Filter;import lombok.extern.slf4j.Slf4j;
import org.apache.skywalking.apm.toolkit.trace.ActiveSpan;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import org.springframework.web.util.ContentCachingRequestWrapper;
import org.springframework.web.util.ContentCachingResponseWrapper;import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Enumeration;
import java.util.HashSet;
import java.util.Set;
import java.util.stream.Collectors;@Slf4j
@Component
public class ApmHttpInfo extends HttpFilter {//被忽略的头部信息 private static final Set<String> IGNORED_HEADERS;static {Set<String> ignoredHeaders = new HashSet<>();ignoredHeaders.addAll(java.util.Arrays.asList("Content-Type","User-Agent","Accept","Cache-Control","Postman-Token","Host","Accept-Encoding","Connection","Content-Length").stream().map(String::toUpperCase).collect(Collectors.toList()));IGNORED_HEADERS = ignoredHeaders;}@Overridepublic void doFilter(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws IOException, ServletException {ContentCachingRequestWrapper requestWrapper = new ContentCachingRequestWrapper(request);ContentCachingResponseWrapper responseWrapper = new ContentCachingResponseWrapper(response);try {filterChain.doFilter(requestWrapper, responseWrapper);} finally {try {//构造请求信息: 比如 curl -X GET http://localhost:18080/getPerson?id=1 -H 'token: me-token' -d '{ "name": "hello" }'//构造请求的方法&URL&参数StringBuilder sb = new StringBuilder("curl").append(" -X ").append(request.getMethod()).append(" ").append(request.getRequestURL().toString());if (StringUtils.hasLength(request.getQueryString())) {sb.append("?").append(request.getQueryString());}//构造headerEnumeration<String> headerNames = request.getHeaderNames();while (headerNames.hasMoreElements()) {String headerName = headerNames.nextElement();if (!IGNORED_HEADERS.contains(headerName.toUpperCase())) {sb.append(" -H '").append(headerName).append(": ").append(request.getHeader(headerName)).append("'");}}//获取bodyString body = new String(requestWrapper.getContentAsByteArray(), StandardCharsets.UTF_8);if (StringUtils.hasLength(body)) {sb.append(" -d '").append(body).append("'");}//输出到inputActiveSpan.tag("input", sb.toString());//获取返回值bodyString responseBody = new String(responseWrapper.getContentAsByteArray(), StandardCharsets.UTF_8);//输出到outputActiveSpan.tag("output", responseBody);} catch (Exception e) {log.warn("fail to build http log", e);} finally {//这一行必须添加,否则就一直不返回responseWrapper.copyBodyToResponse();}}}
}
效果如下(get请求):

效果如下(post请求):

方式三:通过 trace 和 Aop 去实现
在此就不细说了,这个也是一种方案
参考文章
【1】skywalking环境搭建(windows)
【2】windows下安装skywalking 9.2
【3】skywalking9.1结合logback配置日志收集
【4】SpringBoot集成Skywalking日志收集
【5】skywalking展示http请求和响应
相关文章:
SpringBoot教程(三十二) SpringBoot集成Skywalking链路跟踪
SpringBoot教程(三十二) | SpringBoot集成Skywalking链路跟踪 一、Skywalking是什么?二、Skywalking与JDK版本的对应关系三、Skywalking下载四、Skywalking 数据存储五、Skywalking 的启动六、部署探针 前提: Agents 8.9.0 放入 …...

IntelliJ IDEA 接入 AI 编程助手(Copilot、DeepSeek、GPT-4o Mini)
IntelliJ IDEA 接入 AI 编程助手(Copilot、DeepSeek、GPT-4o Mini) 📊 引言 近年来,AI 编程助手已成为开发者的高效工具,它们可以加速代码编写、优化代码结构,并提供智能提示。本文介绍如何在 IntelliJ I…...

【机器学习】深入浅出KNN算法:原理解析与实践案例分享
在机器学习中,K-最近邻算法(K-Nearest Neighbors, KNN)是一种既直观又实用的算法。它既可以用于分类,也可以用于回归任务。本文将简单介绍KNN算法的基本原理、优缺点以及常见应用场景,并通过一个简单案例帮助大家快速入…...

vscode的一些实用操作
1. 焦点切换(比如主要用到使用快捷键在编辑区和终端区进行切换操作) 2. 跳转行号 使用ctrl g,然后输入指定的文件内容,即可跳转到相应位置。 使用ctrl p,然后输入指定的行号,回车即可跳转到相应行号位置。...

JavaEE基础 Tomcat与Http (下)
目录 1.HTTP 协议 1.1 HTTP 协议概念 1.2. 无状态协议 1.3. HTTP1.0 和 HTTP1.1 1.4 请求协议和响应协议 编辑 1.5 请求协议 1.5.1 常见的请求协议 1.5.2 GET 请求 1.5.3 POST请求 1.5.4 响应协议 1.HTTP 协议 Http浏览器访问东西都是遵循的Http协议。 1.1 HTTP 协议…...

【Linux】【进程】epoll内核实现总结+ET和LT模式内核实现方式
【Linux】【网络】epoll内核实现总结ET和LT模式内核实现方式 1.epoll的工作原理 eventpoll结构 当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关. struct eventpoll{..../*红…...

英码科技基于昇腾算力实现DeepSeek离线部署
DeepSeek-R1 模型以其创新架构和高效能技术迅速成为行业焦点。如果能够在边缘进行离线部署,不仅能发挥DeepSeek大模型的效果,还能确保数据处理的安全性和可控性。 英码科技作为AI算力产品和AI应用解决方案服务商,积极响应市场需求࿰…...
)
测试常见问题汇总-检查表(持续完善)
WEB页面常见的问题 按钮功能的实现:返回按钮是否可以正常返回 信息保存提交后,系统是否给出“成功”的提示信息,列表数据是否自动刷新 没有勾选任何记录直接点【删除】,是否给出“请先选择记录”的提示 删除是否有删除确认框 …...

【SQL】SQL约束
🎄约束 📢作用:是用于限制存储再表中的数据。可以再创建表/修改表时添加约束。 📢目的:保证数据库中数据的正确、有效性和完整性。 📢对于一个字段可以同时添加多个约束。 🎄常用约束: 约束分类 约束 描述关键字非…...

解决 `pip is configured with locations that require TLS/SSL` 错误
问题描述 在使用 pip 安装 Python 包时,可能会遇到以下错误: WARNING: pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available.这意味着 Python 的 ssl 模块未正确安装或配置,导致 p…...

如何commit后更新.gitignore实现push
目录 步骤 1: 更新 .gitignore 文件 步骤 2: 移除已追踪的大文件 步骤 3: 提交更改 步骤 4: 尝试推送 注意事项 如果已经执行了git commit,但后来意识到需要更新.gitignore文件以排除某些不应该被追踪的大文件或目录,并希望在不丢失现有提交记录的情…...

Python 面向对象的三大特征
前言:本篇讲解面向对象的三大特征(封装,继承,多态),还有比较细致的(类属性类方法,静态方法),分步骤讲解,比较适合理清楚三大特征的思路 面向对象的…...

机器学习_18 K均值聚类知识点总结
K均值聚类(K-means Clustering)是一种经典的无监督学习算法,广泛应用于数据分组、模式识别和降维等领域。它通过将数据划分为K个簇,使得簇内相似度高而簇间相似度低。今天,我们就来深入探讨K均值聚类的原理、实现和应用…...

从低清到4K的魔法:FlashVideo突破高分辨率视频生成计算瓶颈(港大港中文字节)
论文链接:https://arxiv.org/pdf/2502.05179 项目链接:https://github.com/FoundationVision/FlashVideo 亮点直击 提出了 FlashVideo,一种将视频生成解耦为两个目标的方法:提示匹配度和视觉质量。通过在两个阶段分别调整模型规模…...

Nuclei 使用手册
Nuclei 是一个开源的快速、高效的漏洞扫描工具,主要用于网络安全领域的漏洞检测。它由 go 语言开发,设计目的是为了高效地扫描 Web 应用程序、网络服务等目标,帮助安全研究人员、渗透测试人员以及红队成员发现潜在的漏洞。 下载链接…...

python学opencv|读取图像(六十七)使用cv2.convexHull()函数实现图像轮廓凸包标注
【1】引言 前序学习进程中,已经初步探索了对图像轮廓的矩形标注和圆形标注: python学opencv|读取图像(六十五)使用cv2.boundingRect()函数实现图像轮廓矩形标注-CSDN博客 但实际上,这两种标注方法都是大致的&#x…...

基于SpringBoot的“高校创新创业课程体系”的设计与实现(源码+数据库+文档+PPT)
基于SpringBoot的“高校创新创业课程体系”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:SpringBoot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统整体功能图 系统首页界面 个人中心界…...

前端带样式导出excel表格,html表格生成带样式的excel表格
众所周知,前端生成表格通常是用xlsx、excel.js等js库,但这些库想要生成时增加excel样式会很麻烦。 有这么一个js库把html表格连样式带数据一并导出为excel表格: html-table-to-excel npm install html-table-to-excel 使用 html表格: <…...

人形机器人 - 仿生机器人核心技术与大小脑
以下是针对仿生机器人核心技术的结构化总结,涵盖通用核心技术与**“大脑-小脑”专用架构**两大方向: 一、机器人通用核心技术 这些技术是仿生机器人实现功能的基础,与生物体的“身体能力”对应: 1. 感知与交互技术 多模态传感器融合 视觉:3D视觉(如RGB-D相机)、动态目…...

【Linux】【网络】Libevent 内核实现简略版
【Linux】【网络】Libevent 内核实现简略版 1 event_base结构–>相当于Reactor 在使用libevent之前,就必须先创建这个结构。 以epoll为例: 1.1evbase void* evbase-->epollop结构体(以epoll为例) libevent通过一个void…...
 - Flink按键分区状态(Keyed State))
大数据学习(49) - Flink按键分区状态(Keyed State)
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…...

架构——LVS负载均衡主要模式及其原理、服务水平、优缺点
LVS(Linux Virtual Server)是一款高性能的开源负载均衡软件,支持多种负载均衡模式。以下是其主要模式及其原理、服务水平、优缺点: 1. NAT 模式(Network Address Translation) 原理: 请求流程…...

【React组件通讯双重视角】函数式 vs 类式开发指南
目录 前言 正文 父组件向子组件传值 函数式写法 类式写法 子组件向父组件传值 函数式写法 类式写法 兄弟组件通信 函数式写法 类式写法 跨层级通信(使用Context) 函数式写法 类式写法 进阶通讯方式(补充说明…...
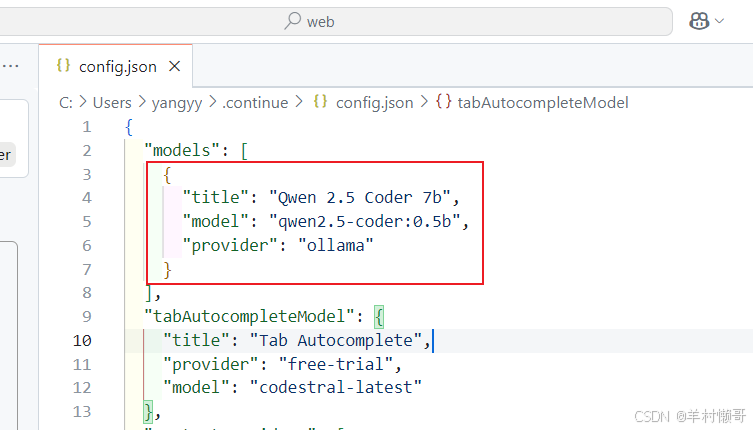
VScode内接入deepseek包过程(本地部署版包会)
目录 1. 首先得有vscode软件 2. 在我们的电脑本地已经部署了ollama,我将以qwen作为实验例子 3. 在vscode上的扩展商店下载continue 4. 下载完成后,依次点击添加模型 5. 在这里可以添加,各种各样的模型,选择我们的ollama 6. 选…...

Ubuntu虚拟机NDK编译ffmpeg
目录 一、ffmpeg源码下载1、安装git(用于下载ffmpeg源码)2、创建源码目录,下载ffmpeg源码 二、下载ubuntu对应的NDK,并解压到opt下1、下载并解压2、配置 ~/.bashrc 三、源码编译、1、创建编译脚本2、脚本文件内容3、设置可执行权限并运行4、编译的结果在…...

机器学习:k近邻
所有代码和文档均在golitter/Decoding-ML-Top10: 使用 Python 优雅地实现机器学习十大经典算法。 (github.com),欢迎查看。 K 邻近算法(K-Nearest Neighbors,简称 KNN)是一种经典的机器学习算法,主要用于分类和回归任务…...

js第十二题
题十二:轮播图 要求: 1.鼠标不在图片上方时,进行自动轮播,并且左右箭头不会显示;当鼠标放在图片上方时,停止轮播,并且左右箭头会显示; 2.图片切换之后,图片中下方的小…...

讯飞唤醒+VOSK语音识别+DEEPSEEK大模型+讯飞离线合成实现纯离线大模型智能语音问答。
在信息爆炸的时代,智能语音问答系统正以前所未有的速度融入我们的日常生活。然而,随着数据泄露事件的频发,用户对于隐私保护的需求日益增强。想象一下,一个无需联网、即可响应你所有问题的智能助手——这就是纯离线大模型智能语音…...

Day4 25/2/17 MON
【一周刷爆LeetCode,算法大神左神(左程云)耗时100天打造算法与数据结构基础到高级全家桶教程,直击BTAJ等一线大厂必问算法面试题真题详解(马士兵)】https://www.bilibili.com/video/BV13g41157hK?p4&v…...

HTML【详解】input 标签
input 标签主要用于接收用户的输入,随 type 属性值的不同,变换其具体功能。 通用属性 属性属性值功能name字符串定义输入字段的名称,在表单提交时,服务器通过该名称来获取对应的值disabled布尔值禁用输入框,使其无法被…...