初识LLMs
目录
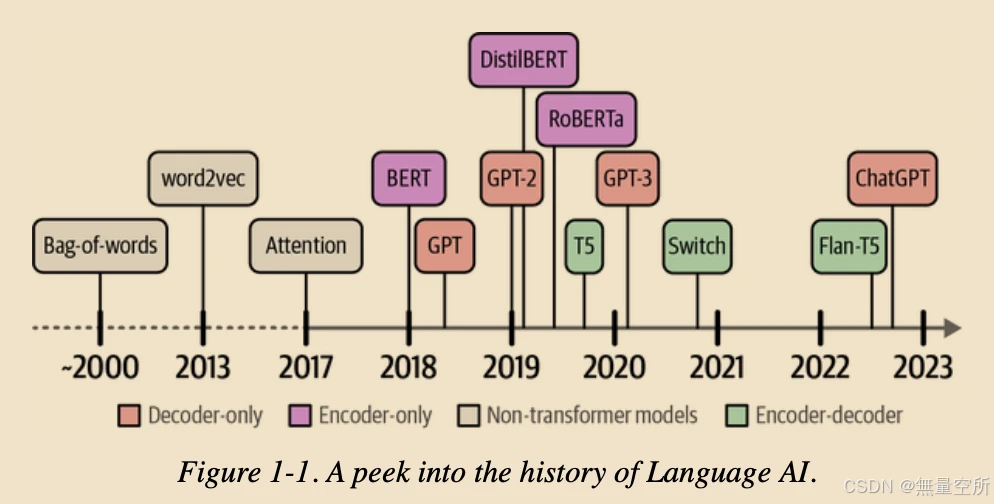
一、Language AI 历史
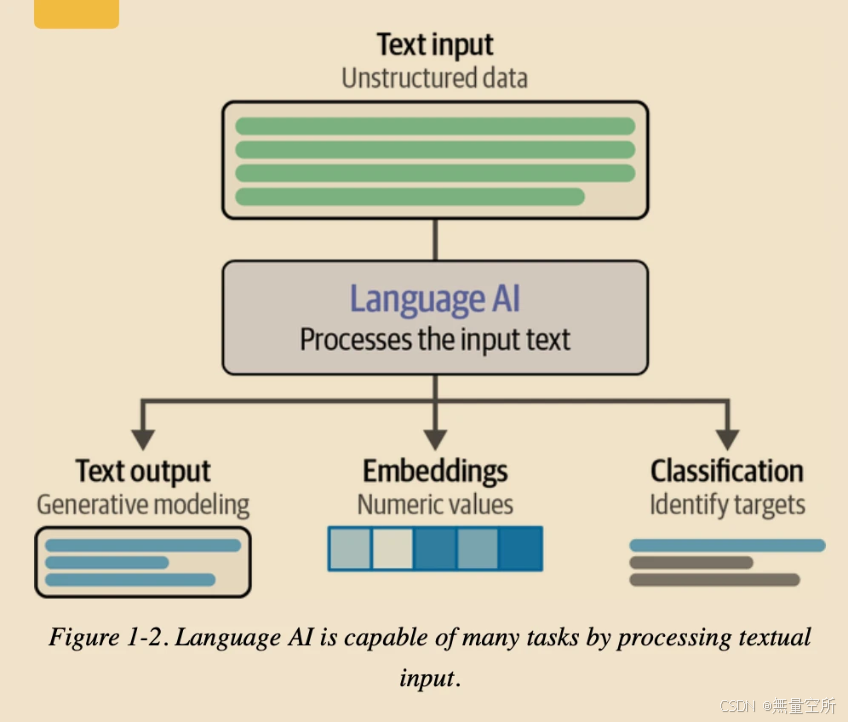
二、Language AI如何处理text
三、技术一:Bag-of-Words模型
缺点
四、技术二:word2vec(稠密向量 / 嵌入向量)
缺点
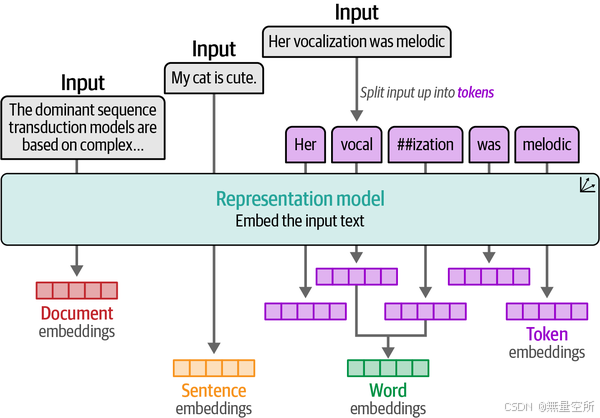
五、嵌入的多种形式
六、技术三:注意力机制
6.1 上下文嵌入
缺点
6.2 deconder+注意力机制
缺点
6.3 transformer
6.3.1 表示模型 vs 生成模型
6.3.2 表示模型:Encoder-Only 模型
6.3.3 生成模型:decoder-Only 模型
七、LLM说法
八、 创建LLM步骤
1、预训练
2、微调(后训练)
九、LLM责任
十、开源 vs 闭源
1、闭源
2、开源
十一、实验:Say Hi to LLM
一、Language AI 历史
在发展前期,text天生没有固定结构,用0和1表示text会失去text原本的含义。
二、Language AI如何处理text
三、技术一:Bag-of-Words模型
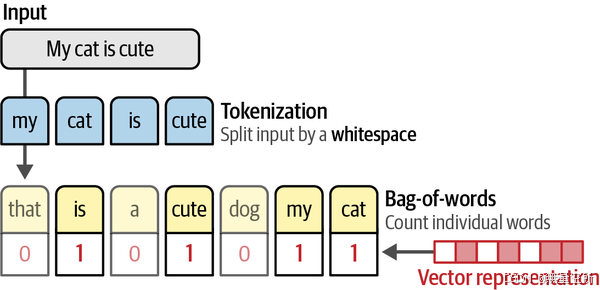
目的:将句子转变成数字表示
第一步:分词操作。将句子转变成一个个独立的words或subwords
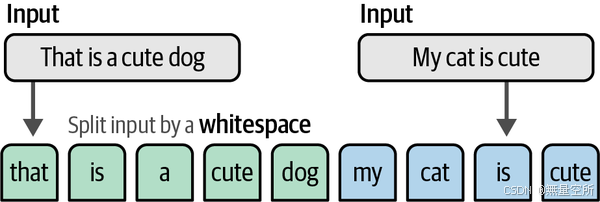
第二步:合并独立的words构造出能表示所有句子中word的词典
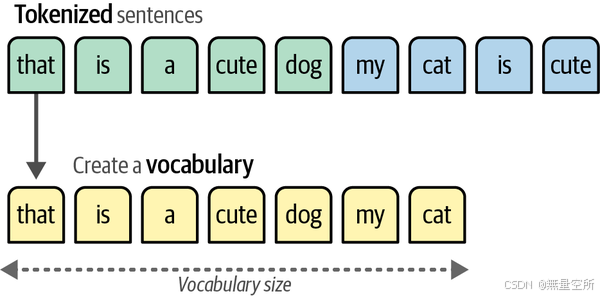
第三步:计算词典中每一个word在每一个句子中出现的频率,从而构建该句子的词包。词包可称为向量表示
缺点
-
忽略顺序:词包模型忽略了单词的顺序和语法结构,因此无法捕捉文本的语义和上下文信息。
-
维度灾难:如果词汇表很大,词包模型的维度也会很高,容易导致稀疏性和计算效率问题。
四、技术二:word2vec(稠密向量 / 嵌入向量)
word2vec利用神经网络。这些网络由相互连接的节点层组成用于处理信息。神经网络可以有多个层,每个连接都有一定的权重。
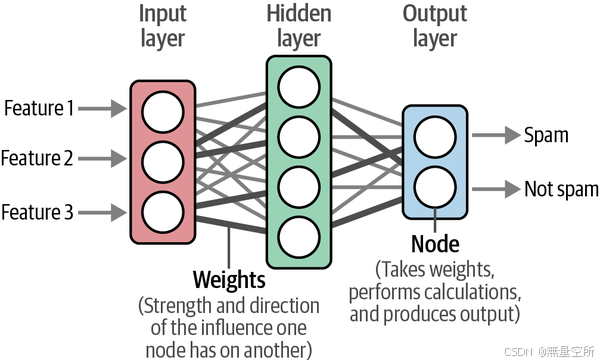
使用这些神经网络,word2vec通过观察在给定句子中它们倾向于出现在哪些其他单词旁边来生成词嵌入。
在训练开始之前,首先为词汇表中每个单词分配一个向量嵌入,例如每个单词对应一个50维度的向量,初始化为随机值,每一维度表示一种特征属性。然后在每个训练步骤中,如下图,从训练数据中取一对单词,模型尝试预测它们是否可能在句子中成为邻居。

在这个训练过程中,word2vec学习单词之间的关系,并将这些信息提炼成嵌入。如果两个单词倾向于有相同的邻居,它们的嵌入会更接近彼此,反之亦然。
例如:
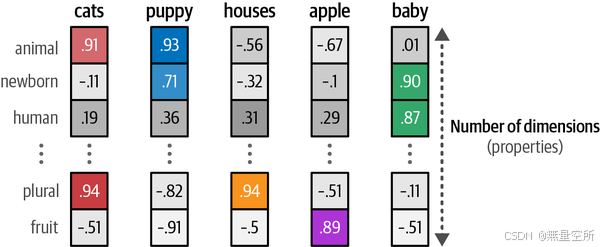
有2个单词的嵌入,即“苹果”和“婴儿”,“婴儿”这个词可能在“新生儿”和“人类”这些属性上得分较高,而“苹果”在这些属性上得分较低。 如下图,嵌入可以具有许多属性来表示单词的含义。由于嵌入的大小是固定的,因此选择它们的属性来创建单词的表示。
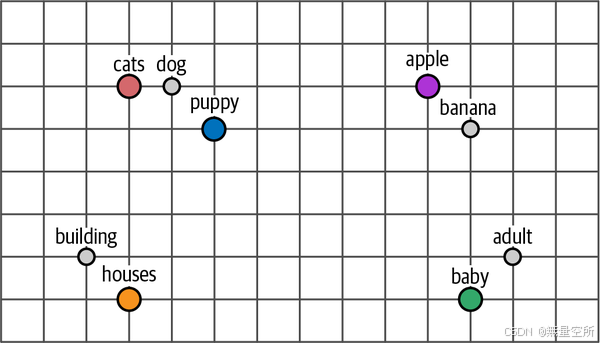
嵌入允许我们测量两个词之间的语义相似性。使用各种距离度量,我们可以判断一个词与另一个词有多接近。如下图,如果将这些嵌入压缩成二维表示,含义相似的词倾向于更靠近。
缺点
训练过程生成的是静态的单词嵌入表示,这意味着每个单词的嵌入向量是固定的,不会随着上下文的变化而改变。例如,单词“bank”无论在何种语境中使用,其嵌入向量始终相同。然而,“bank”既可以指“银行”,也可以指“河岸”,其含义会因上下文而变化。因此,Word2Vec无法根据上下文动态调整单词的嵌入
五、嵌入的多种形式
不同层级上(句子、单词)的⽂本都可以做Embedding
词包在整个文本层级创建嵌入,而word2vec在单词层级创建嵌入
六、技术三:注意力机制
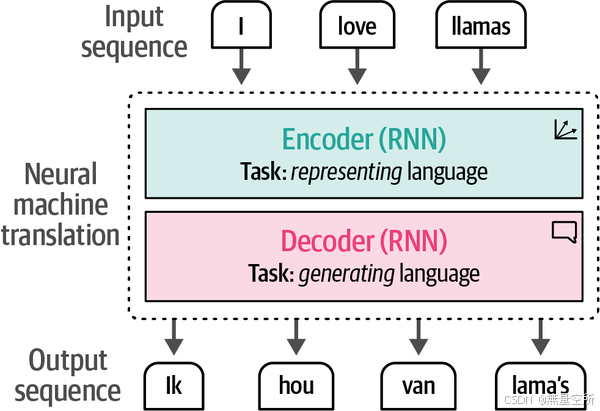
6.1 上下文嵌入
增加了encoding和decoding操作
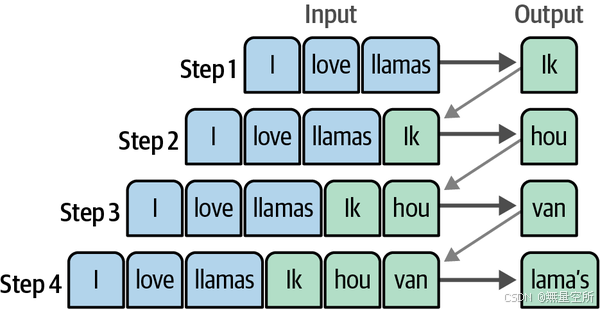
每一步都是自回归的,在生成下一个词时,需要使用之前生成的所有词
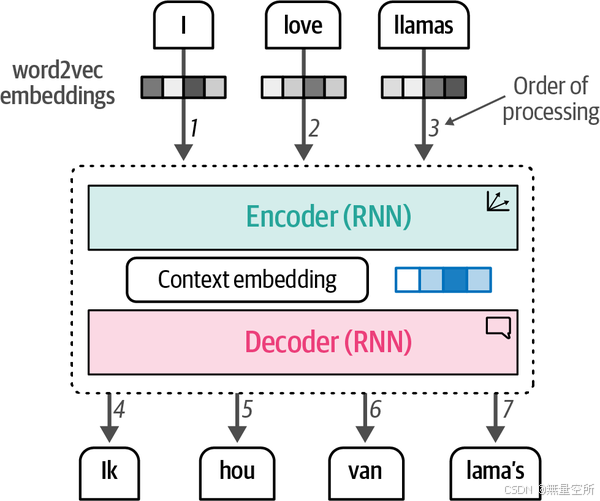
输入形式: 单词的嵌入向量(可以使用Word2Vec生成初始表示)
Encoding作用: 将单词嵌入转换为上下文嵌入表示,为解码器提供输入。
Decoding作用: 利用编码器生成的上下文表示,生成目标输出。
缺点
-
问题:上下文嵌入是一个单一的向量,用来表示整个输入序列。这使得处理长句子变得困难,因为所有信息都被压缩到一个固定长度的向量中,容易丢失细节。
-
原因:单一的嵌入向量无法有效区分输入序列中不同部分的重要性。
6.2 deconder+注意力机制
注意力机制允许模型专注于输入序列中相互相关的部分,并增强这些部分的信号。通过选择性地确定句子中哪些单词最重要,注意力机制能够更好地处理长句子,并保留关键信息。
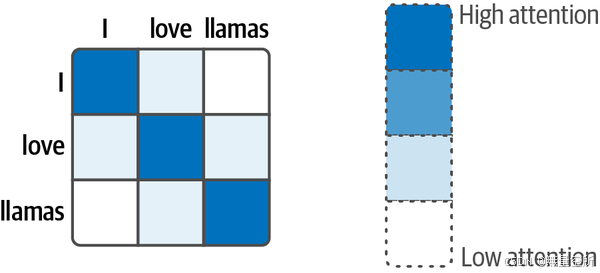
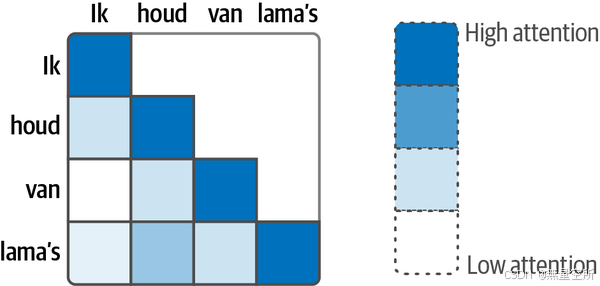
例如:输出词“lama's”是荷兰语中“lamas”的意思,这就是为什么两者之间的注意力同样,“lama's”和“I”这两个词的注意力较低,因为它们的相关性较低。
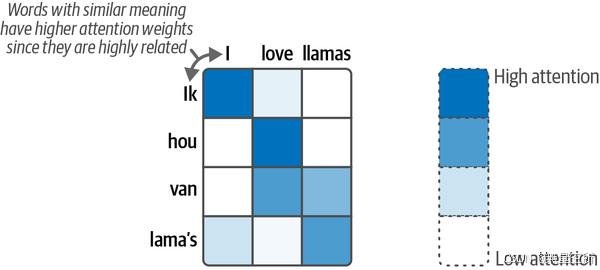
将注意力机制部署在decoder中,前边过程同1.6.1,decoder每次输出一个单词直到输出完整的句子。当decoder生成每个单词时,它会根据当前生成的单词动态地关注输入句子中的不同部分。例如,当生成“Ik”时,解码器可能会更多地关注输入句子中的“I”。
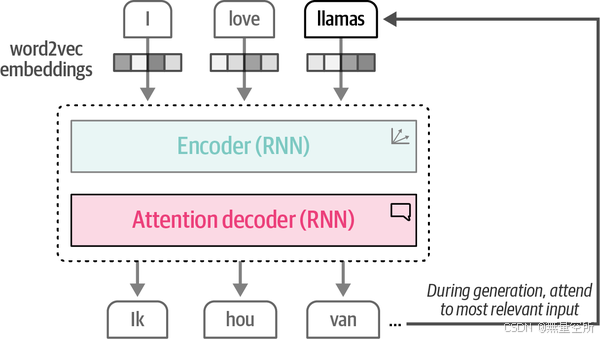
缺点
不能并行化训练模型
6.3 transformer
可以并行训练模型,保持自回归,encoder和decoder都围绕注意力展开
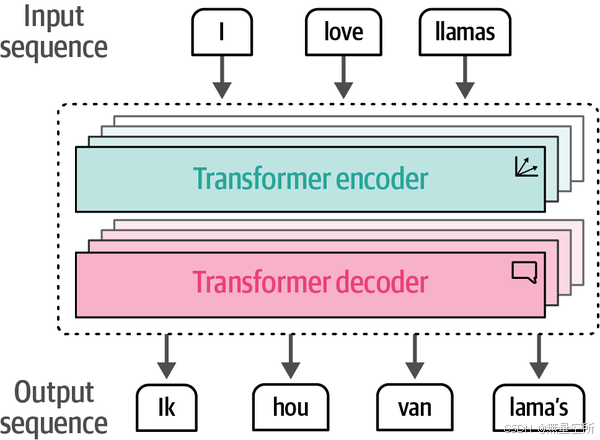
encoder模块
包括自注意力和反馈神经网络
自注意力可以关注单个序列中的不同位置,它一次可以处理整个序列,而不是一次处理一个token。
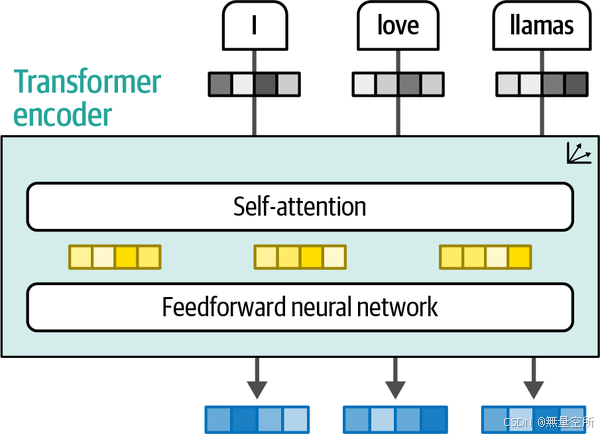
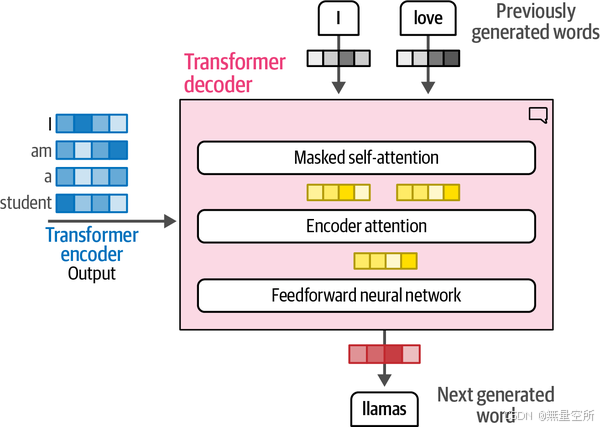
decoder模块
比encoder多了一层
masked self-attention层屏蔽了未来的位置,因此它只关注较早的位置,以防止在生成输出时泄露信息。
6.3.1 表示模型 vs 生成模型
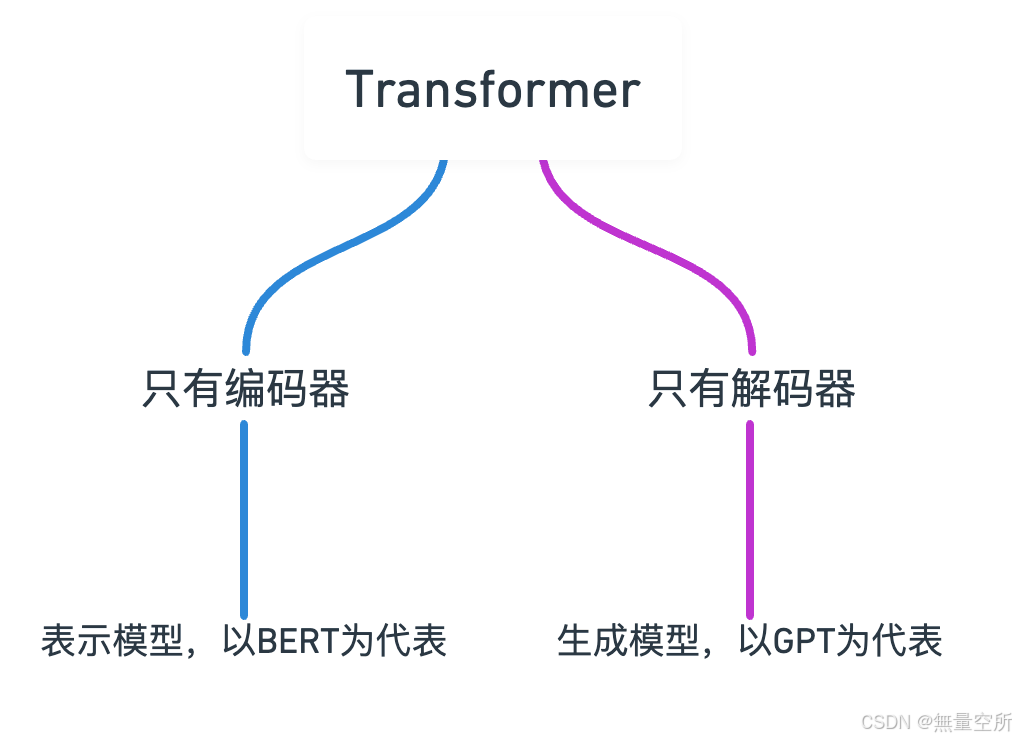
表示模型帮助我们理解数据,而生成模型则用于创造新的数据。
表示模型:
主要目的是理解数据,比如把文字转换成有意义的向量(嵌入)。
通常用于分类、聚类和搜索等任务。
例子:BERT,它通过学习来理解语言,但不直接生成文本。
生成模型:
主要目的是创造新的数据,比如生成新的句子或图像。
侧重于生成与训练数据相似的新内容。
例子:GPT-3,它可以生成连贯的新文本。
6.3.2 表示模型:Encoder-Only 模型
最初的Transformer模型是一个Encoer-Decoder架构,它可以很好地用于翻译任务,但不能很容易地处理其他任务,如文本分类。
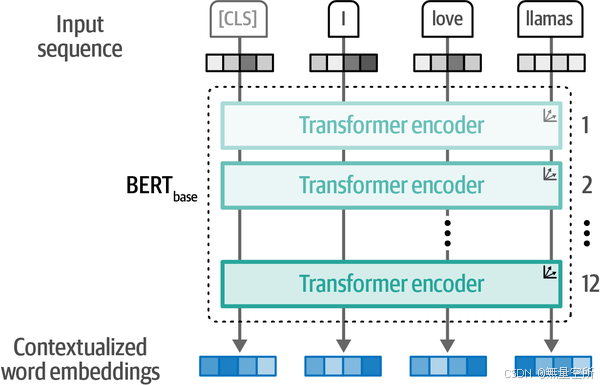
BERT是一个仅用于表示语言的编码架构,如图,使用Encoder堆叠架构。
预训练:
BERT 是通过在大量文本数据上进行预训练得到的。这意味着在应用到特定任务之前,BERT 已经学习了丰富的语言表示。双向编码器:
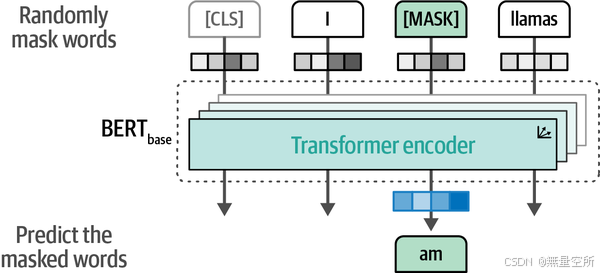
BERT 使用了 Transformer 架构中的编码器(Encoder)部分,并采用了双向(Bidirectional)训练策略。这使得 BERT 能够同时考虑单词的左右上下文,从而更好地理解单词的含义。掩码语言模型(Masked Language Model, MLM):
BERT 通过一种称为掩码语言模型(MLM)的方法进行预训练。在这种方法中,输入文本中的一些单词会被随机替换为一个特殊的[MASK]标记,BERT 的任务是预测这些被掩盖的单词。
下一句预测(Next Sentence Prediction, NSP):
除了 MLM 任务,BERT 还通过下一句预测(NSP)任务进行预训练。在 NSP 任务中,BERT 需要预测两个句子是否是顺序关系。微调(Fine-tuning):
预训练完成后,BERT 可以通过微调(Fine-tuning)来适应各种下游任务,如文本分类、问答、命名实体识别等。微调是在特定任务的数据集上进行的,通常只需要少量的数据和训练时间。
迁移学习:
BERT 可应用于迁移学习。通过在大规模数据集上预训练,BERT 学习到的通用语言表示可以迁移到各种不同的 NLP 任务中,从而提高这些任务的性能。
6.3.3 生成模型:decoder-Only 模型
GPT-1仅堆叠解码器块
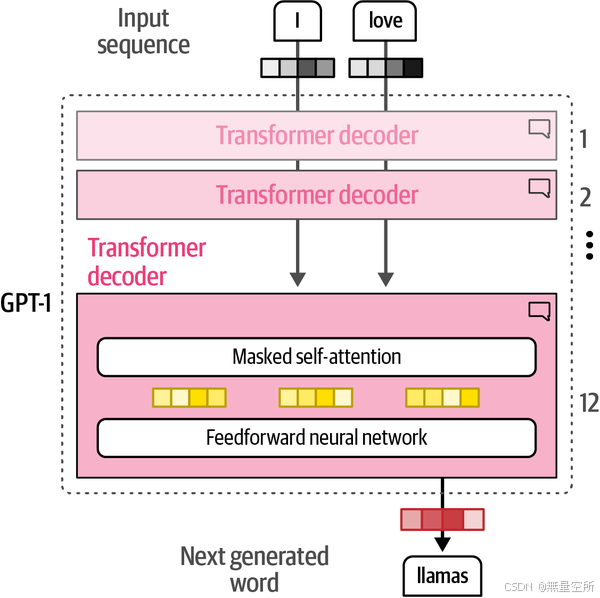
GPT-1由1.17亿个参数组成。每个参数都是一个数值,表示模型对语言的理解。GPT-2有15亿个参数8,GPT-3有1750亿个参数 。生成模型也可称为补全模型。
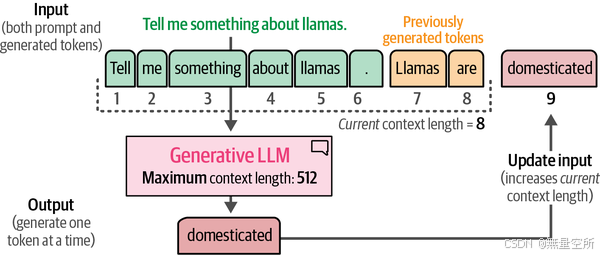
这些补全模型的一个重要部分是上下文长度或上下文窗口。上下文长度表示模型可以处理的token的最大数量,如图,一个大的上下文窗口允许将整个文档传递给LLM。请注意,由于这些模型的自回归特性,当前上下文长度将随着新令牌的生成而增加。
七、LLM说法
LLM并没有一个统一和严格的科学定义,但是它通常用来描述那些具有以下特征的模型:
参数规模大:
包含数亿甚至数千亿个参数,这些参数是在大量文本数据上训练得到的。预训练:
通常在大规模文本数据集上进行预训练,学习语言的通用特征和模式。深度学习架构:
基于深度学习架构,如Transformer,这是目前最常用的语言模型架构。多任务能力:
能够执行多种自然语言处理任务,如文本理解、生成、翻译、问答等。迁移学习能力:
学习到的语言表示可以迁移到其他特定的任务上,通常只需要少量的微调。生成能力:
尽管并非所有LLM都专注于文本生成,但许多模型具备生成连贯、相关文本的能力。计算资源需求高:
训练和运行这些模型通常需要大量的计算资源。持续学习:
能够通过持续学习不断改进和适应新的任务和数据。上下文理解:
能够理解长距离的依赖关系和复杂的语言结构。交互能力:
能够与用户或其他系统进行交互,提供语言相关的服务。
八、 创建LLM步骤
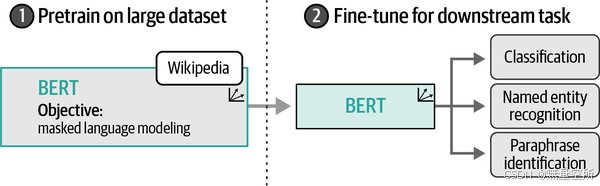
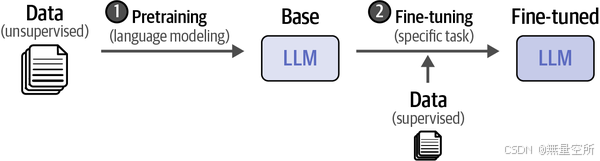
1、预训练
这是创建LLM的第一步,也是最耗时和计算密集型的阶段。
在预训练阶段,模型(如LLM)在大量的互联网文本数据上进行训练,以学习语言的语法、上下文和模式。
这个阶段不针对任何特定任务,而是让模型广泛地学习语言的各个方面,包括预测下一个单词。
预训练完成后,模型被称为基础模型或预训练模型,它具备了广泛的语言理解能力,但通常不直接用于特定任务。
2、微调(后训练)
在微调阶段,使用已经预训练好的模型,并在特定任务的数据集上进一步训练,以适应该任务的需求。
微调使得模型能够针对特定任务进行优化,例如文本分类、情感分析或遵循指令等。
这种方法节省了大量资源,因为预训练阶段的成本非常高,通常需要大量的数据和计算资源。
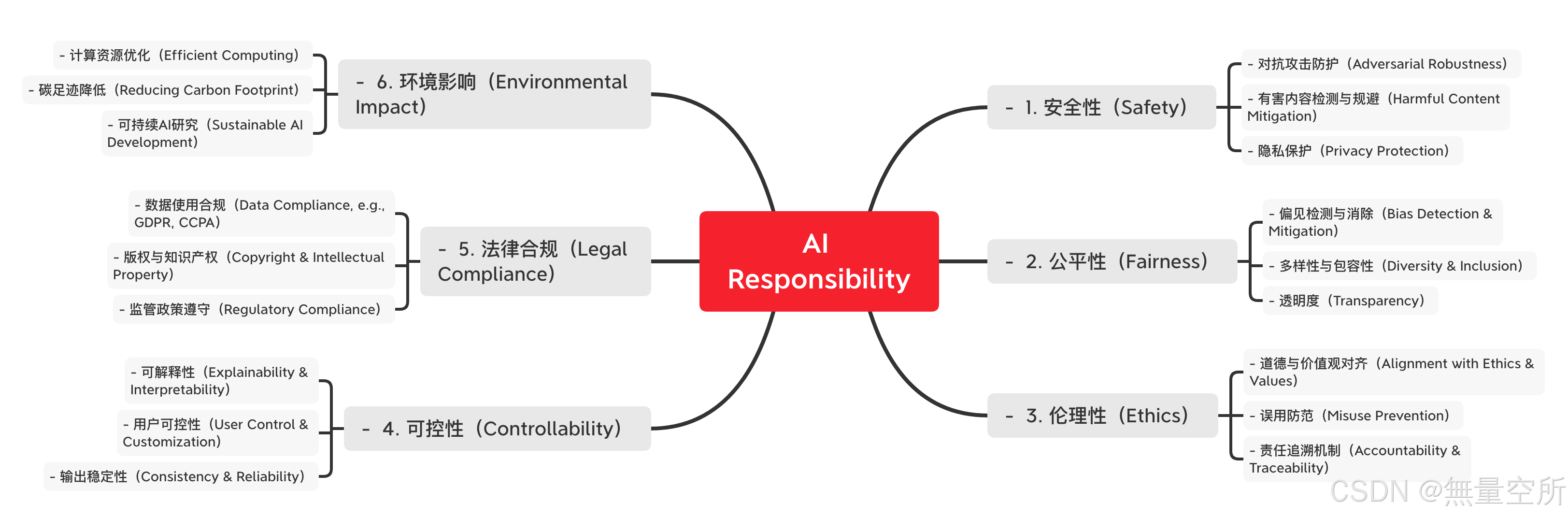
九、LLM责任
十、开源 vs 闭源
1、闭源
闭源的大型语言模型(LLM)是不公开其内部工作原理和细节的模型,由一些公司开发并保密。这些模型,比如OpenAI的GPT-4,可以通过网络接口(API)来使用,而不需要你自己有强大的计算设备。
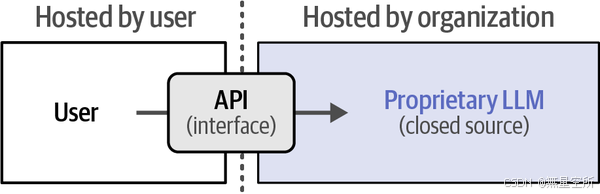
使用这些模型的好处是你不需要自己设置和维护复杂的系统,因为公司会帮你处理这些。而且,由于公司投入了很多资源,这些模型通常表现很好。
不过,使用这些模型也有缺点:
-
通常需要付费。
-
你不能根据自己的需要调整模型。
-
你的数据可能会被公司获取,这在某些情况下可能是个问题。
2、开源
开源的大型语言模型(LLM)是那些公开其权重和架构的模型,任何人都可以使用。这些模型由特定组织开发,但代码通常可以公开获取,允许你在本地运行模型,不过使用时可能有各种许可限制。
一些开源模型:Cohere的Command R、Mistral模型、微软的Phi和Meta的Llama模型。
开源模型的一个主要好处是你可以完全控制模型。你可以在本地使用模型,不需要依赖网络接口,可以自己调整模型,并且可以在保证数据隐私的情况下使用。此外,开源社区(如Hugging Face)提供了很多支持和资源。
不过,开源模型也有一些缺点。你需要有强大的硬件才能运行这些模型,特别是在训练或调整模型时。此外,设置和使用这些模型需要特定的知识。
十一、实验:Say Hi to LLM
from openai import OpenAIclient = OpenAI(api_key = "xxx", base_url = "xxx")response = client.chat.completions.create(model = "deepseek-chat",messages = [{"role": "system", "content": "You are a helpful assistant"},{"role": "user", "content": "Hello"},],stream = False
)print(response.choice[0].message.content)输出:

相关文章:
初识LLMs
目录 一、Language AI 历史 二、Language AI如何处理text 三、技术一:Bag-of-Words模型 缺点 四、技术二:word2vec(稠密向量 / 嵌入向量) 缺点 五、嵌入的多种形式 六、技术三:注意力机制 6.1 上下文嵌入 缺…...

SpringAI系列 - RAG篇(三) - ETL
目录 一、引言二、组件说明三、集成示例一、引言 接下来我们介绍ETL框架,该框架对应我们之前提到的阶段1:ETL,主要负责知识的提取和管理。ETL 框架是检索增强生成(RAG)数据处理的核心,其将原始数据源转换为结构化向量并进行存储,确保数据以最佳格式供 AI 模型检索。 …...

命令注入绕过
过滤cat 一、解题思路 当cat被过滤后,可以使用一下命令进行读取文件的内容 (1)more:一页一页的显示的显示档案内容 (2)less:与more类似,但是比more更好的是,他可以pg dn翻页 (3)head:查看头几行 (4)tac:从最后一行开始显示,可以看出tac是cat的反向显示 (5)tail:查看尾几行 (6)n…...

spring的核心配置
Spring框架的核心配置主要包括以下几个方面: 依赖注入(Dependency Injection, DI) 依赖注入是Spring的核心特性之一,它通过将依赖(如对象、服务等)注入到组件中,实现了组件间的松耦合。 常见…...

leetcode:942. 增减字符串匹配(python3解法)
难度:简单 由范围 [0,n] 内所有整数组成的 n 1 个整数的排列序列可以表示为长度为 n 的字符串 s ,其中: 如果 perm[i] < perm[i 1] ,那么 s[i] I 如果 perm[i] > perm[i 1] ,那么 s[i] D 给定一个字符串 s ࿰…...

【智驭未来】使用Deepseek进行业务系统集成场景分析
DeepSeek已经出来了一段时间,各系统厂商纷纷加入对他的支持行列,有使用他来进行数据智能预测分析的,有使用他来进行系统知识智能问答的,有进行多语言处理和文档智能解析的,也有开发工具支持AI代码生成的。根据厂商产品…...

探秘Transformer系列之(3)---数据处理
探秘Transformer系列之(3)—数据处理 接下来三篇偏重于工程,内容略少,大家可以当作甜点 _。 0x00 概要 有研究人员认为,大模型的认知框架看起来十分接近卡尔弗里斯顿(Karl Friston)描绘的贝叶斯大脑。基于贝叶斯概率…...

cesium视频投影
先看效果 使用cesium做视频投影效果,而且还要跟随无人机移动而移动,我现在用定时器更新无人机的坐标来实现效果具体代码如下: 1、CesiumVideo3d.js(某个cesium技术群大佬分享的) // import ECEF from "./CoordinateTranslate"; le…...

[算法学习笔记]1. 枚举与暴力
一、枚举算法 定义 枚举是基于已有知识来猜测答案的问题求解策略。即在已知可能答案的范围内,通过逐一尝试寻找符合条件的解。 2. 核心思想 穷举验证:对可能答案集合中的每一个元素进行尝试终止条件:找到满足条件的解,或遍历完…...

Burp Suite基本使用(web安全)
工具介绍 在网络安全的领域,你是否听说过抓包,挖掘漏洞等一系列的词汇,这篇文章将带你了解漏洞挖掘的热门工具——Burp Suite的使用。 Burp Suite是一款由PortSwigger Web Security公司开发的集成化Web应用安全检测工具,它主要用于…...

RabbitMQ 3.12.2:单节点与集群部署实战指南
前言:在当今的分布式系统架构中,消息队列已经成为不可或缺的组件之一。它不仅能够实现服务之间的解耦,还能有效提升系统的可扩展性和可靠性。RabbitMQ 作为一款功能强大且广泛使用的开源消息中间件,凭借其高可用性、灵活的路由策略…...

【故障处理】- 11G expdp导出缓慢 + Streams AQ: enqueue blocked on low memory等待事件
【故障处理】- 11G expdp导出缓慢 Streams AQ: enqueue blocked on low memory等待事件 一、概述二、故障原因三、解决方法 一、概述 该问题的数据库版本是11.2.0.4,执行expdp导出的时候,小表导出非常缓慢,同时有Streams AQ: enqueue blocke…...

mac相关命令
显示和隐藏usr等隐藏文件文件 terminal输入: defaults write com.apple.Finder AppleShowAllFiles YESdefaults write com.apple.Finder AppleShowAllFiles NO让.bashrc每次启动shell自动生效 编辑vim ~/.bash_profile 文件, 加上 if [ -f ~/.bashrc ]; then. ~/.bashrc fi注…...

30 款 Windows 和 Mac 下的复制粘贴软件对比
在日常电脑操作中,复制粘贴是极为高频的操作,一款好用的复制粘贴软件能极大提升工作效率。以下为你详细介绍 30 款 Windows 和 Mac 下的复制粘贴软件,并对比它们的优缺点,同时附上官网下载地址,方便大家获取软件。 Pa…...

MYSQL下载安装及使用
MYSQL官网下载地址:https://downloads.mysql.com/archives/community/ 也可以直接在服务器执行指令下载,但是下载速度比较慢。还是自己下载好拷贝过来比较快。 wget https://dev.mysql.com/get/Downloads/mysql-5.7.38-linux-glibc2.12-x86_64.tar.gz 1…...

《仙台有树》里的馅料(序)
《仙台有树》一起追剧吧(二):馅料合集概览 ●德爱武美玩,全面发展 ●猜猜我是谁&真假美清歌 ●失忆的风还是吹到了仙台 ●霸道师徒强制收&你拜我,我拜你,师徒徒师甜蜜蜜 ●霸道总裁强制爱 ●仙台有…...

C语言题目:链表数据求和操作
题目描述 读入10个复数,建立对应链表,然后求所有复数的和。 输入格式 无 输出格式 无 样例输入 1 2 1 3 4 5 2 3 3 1 2 1 4 2 2 2 3 3 1 1 样例输出 2323i 代码功能概述 createNode 函数: 创建一个包含 10 个复数节点的链表。 每个…...

如何在不依赖函数调用功能的情况下结合工具与大型语言模型
当大型语言模型(LLM)原生不支持函数调用功能时,如何实现智能工具调度?本文通过自然语言解析结构化输出控制的方法来实现。 GitHub代码地址 核心实现步骤 定义工具函数 使用tool装饰器声明可调用工具: from langcha…...

统信服务器操作系统V20 1070A 安装docker新版本26.1.4
应用场景: 硬件/整机信息:x86平台、深信服超融合平台 OS版本信息:统信V20 1070a 1.获取docker二进制包 链接: https://pan.baidu.com/s/1SukBlra0mQxvslTfFakzGw?pwd5s5y 提取码: 5s5y tar xvf docker-26.1.4.tgz groupadd docker ch…...

【Linux】文件系统:文件fd
🔥个人主页:Quitecoder 🔥专栏:linux笔记仓 目录 01.回顾C文件接口02.系统文件I/O02.1 openflags 参数(文件打开模式)标记位传参1. 访问模式(必须指定一个)2. 额外控制标志…...

电脑系统损坏,备份文件
一、工具准备 1.U盘:8G以上就够用,注意会格式化U盘,提前备份U盘内容 2.电脑:下载Windows系统并进行启动盘制作 二、Windows启动盘制作 1.微软官网下载启动盘制作工具微软官网下载启动盘制作工具https://www.microsoft.com/zh-c…...

View Binding小记
View Binding 1.简介 View Binding 是 Android 开发中的一项功能,它允许开发者以类型安全的方式直接访问布局文件中的视图,而无需使用 findViewById View Binding 生成的绑定类中的字段类型与布局文件中的视图类型完全一致,避免了 findVie…...

Python网络运维自动化:从零开始学习NetDevOps
零基础入门NetDevOps,让网络运维更简单、更高效。 Python网络运维自动化 1.从理论到实战:从基础理论入手,通过实战案例教学,手把手教读者掌握Python网络运维自动化,解决运维工作中的日常问题,提升运维效率…...

公网远程家里局域网电脑过程详细记录,包含设置路由器。
由于从校内迁居小区,校内需要远程控制访问小区内个人电脑,于是早些时间刚好自己是电信宽带,可以申请公网ipv4不需要花钱,所以就打电话直接申请即可,申请成功后访问光猫设备管理界面192.168.1.1,输入用户名密码登录超管(密码是网上查下就有了)设置了光猫为桥接模式,然后…...

网络安全示意图 网络安全路线图
其实网络安全本身的知识点并不算难,但需要学的东西比较多,如果想要从事网络安全领域,肯定是需要系统、全面地掌握清楚需要用到的技能的。 自学的方式基本是通过看视频或者相关的书籍,不论是什么方法,都是很难的&#…...

【多线程异步和MQ有什么区别?】
多线程异步和MQ有什么区别? 多线程异步MQ(消息队列)多线程异步与MQ的区别多线程异步 概念: 多线程异步是指在单个应用程序内部创建和管理多个线程,这些线程并行处理任务。 多线程主要用于提升应用程序的性能,特别是在处理计算密集型任务(如科学计算、图像处理、数据分…...

Annie导航2.0 新增加5个模版 开源免授权
新增5个模版 修复部分模版样式问题 采用最新技术tinkphp8.0 php8.1 mysql5.7 Funadmin框架 后台一键式统计访问人数 网站设置 分类设置 网站管理 工具管理 友情链接 广告管理 [color=var(–comiis-color)]联系方式 主题管理 配置多套模版随意切换 已更新市面上热门的几个模版...

Spring AI发布!让Java紧跟AI赛道!
1. 序言 在当今技术发展的背景下,人工智能(AI)已经成为各行各业中不可忽视的重要技术。无论是在互联网公司,还是传统行业,AI技术的应用都在大幅提升效率、降低成本、推动创新。从智能客服到个性化推荐,从语…...

一个简洁高效的Flask用户管理示例
Flask-Login 是 Flask 的用户管理扩展,提供 用户身份验证、会话管理、权限控制 等功能。 适用于: • 用户登录、登出 • 记住用户(“记住我” 功能) • 限制未登录用户访问某些页面 • 用户会话管理 1. 安装 Flask-Login pi…...

HTML之JavaScript Form表单事件
HTML之JavaScript Form表单事件 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title…...