lab4 CSAPP:Cachelab
写在前面
最简单的一集
实验室分为两个部分。在A部分中,实现一个缓存模拟器。在B部分中,编写一个矩阵针对高速缓存性能优化的转置功能。
感觉是比较经典的问题,之前在体系结构的课程中接触过,终于能通过lab实操一下了。
实验目录的 traces 子目录包含参考跟踪文件的集合,将用于评估A部分中编写的缓存模拟器的正确性。跟踪文件是由 Linux 称为valgrind 的程序产生的。
先安装valgrind:
apt install valgrind
比如 我们用valgrind 捕获 ls -l 的内存访问
valgrind --log-fd=1 --tool=lackey -v --trace-mem=yes ls -l
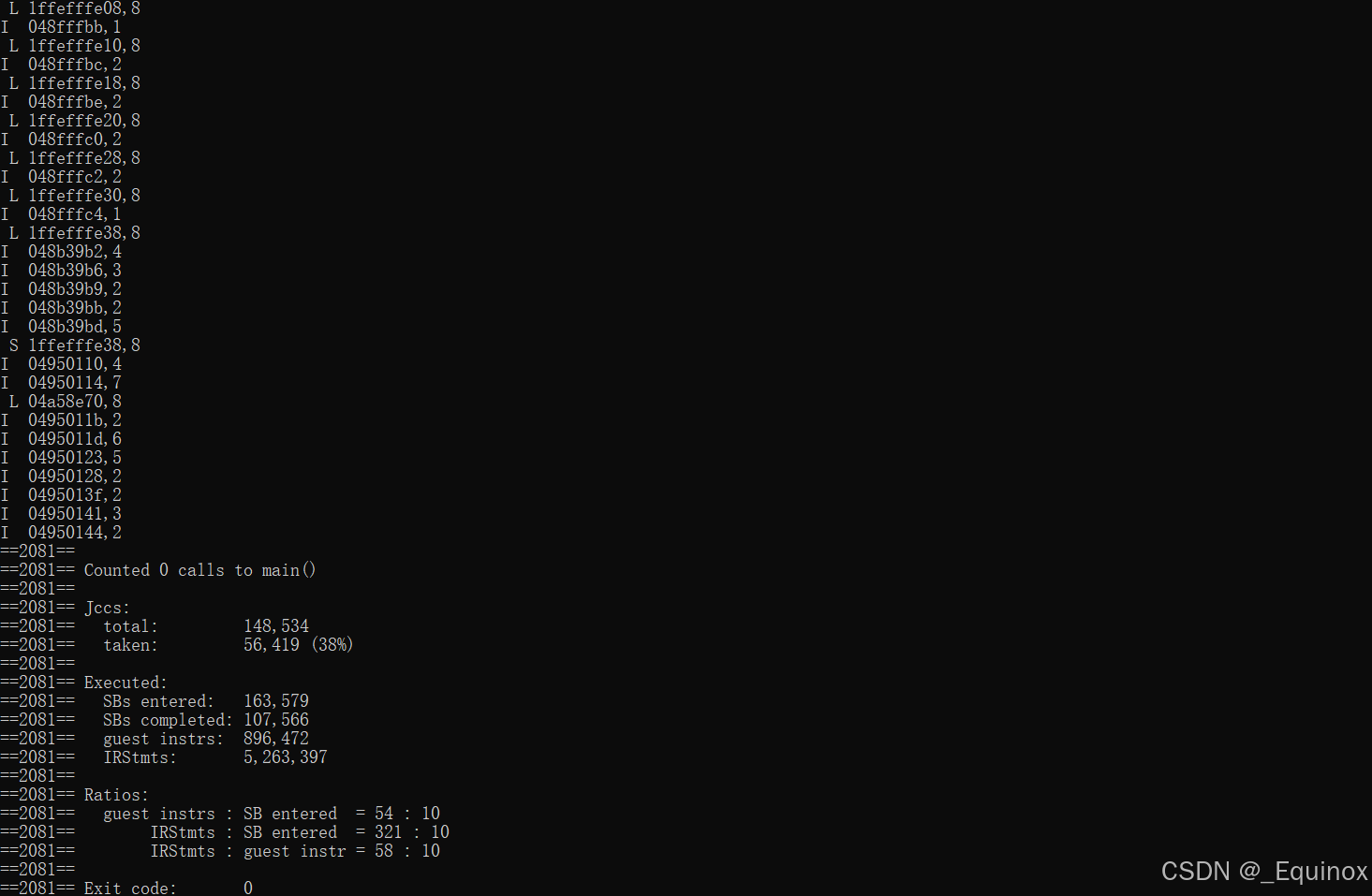
操作-地址-大小 三元组格式
- I 表示指令读取
- L 表示数据读取
- S 表示数据存储
- M 表示数据修改
PartA:Writing a Cache Simulator

在A部分中,需要在 csim.c 中编写一个缓存模拟器该模拟器将 valgrind 内存跟踪作为输入,模拟此跟踪上的高速缓存存储器的命中/未命中行为,并输出命中,不命中和驱逐的总数目。
需要考虑的问题
1、处理输入参数。
2、模拟缓存行为。
3、考虑LRU(最近最少使用)算法。
下面的程序参考了知乎 林夕丶 的做法
这个实验的pdf 提示通过 getopt() 来解析命令行参数,具体用法问大模型或者查阅文档即可。
需要用到的全局变量、数据结构以及函数:
s, E, b:缓存参数,分别表示组索引位数(S = 2^s)、每组行数(E)和块偏移位数(B = 2^b)。T:全局时间戳,用于LRU(最近最少使用)替换策略。(LRU其实可以O(1)维护,但是C语言没有哈希表,所以暴力了)cache:二维数组,表示缓存结构,每个组包含多个行(lineNode)。result[3]:统计命中、未命中和替换次数。lineNode:表示缓存行,包含标签(tag)和时间戳(t)。时间戳用于LRU策略。init():初始化缓存结构。findCache():处理内存访问,判断是否命中、未命中或替换。opt():解析命令行参数,配置缓存参数并打开轨迹文件。setResult():更新统计结果和缓存行状态。
/*===========头文件===============*/
#include "cachelab.h"
#include <fcntl.h>
#include <getopt.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/*===========头文件===============*/void usage(void) { exit(1); } // 打印帮助信息可以不实现
int verbose = 0, s, E, b, S, B; // cache的参数,由命令行输入,opt函数解析int T = 0; //时间戳,第一个访存指令的时刻为1,之后每次数据访存都累加1
typedef __uint64_t u64;
typedef unsigned int uint;// 行的定义
typedef struct lineNode { int t; // 时刻u64 tag; // 标记位
} * groupNode; // 组enum Category { HIT, MISS, EVICTION }; // 命中 / 缺失 / 驱逐
uint result[3]; // 统计命中、未命中和替换次数
const char *categoryString[3] = {"hit ", "miss ", "eviction "};
groupNode *cache; // cache 就是若干组
void init(); // 初始化cache
FILE *opt(int argc, char **argv); // 解析命令行选项
void findCache(u64 tag, int group_pos, char *result); // 查询
主函数的逻辑:
- 解析命令行参数
- 初始化cache
- 接收操作并处理
- pdf要求我们最后打印 命中次数 缺失次数 驱逐次数
int main(int argc, char **argv)
{FILE *tracefile = opt(argc, argv); // 从命令行获取 S E Binit(); // 根据输入参数初始化cache// 接下来处理每一条指令char oper[2];u64 address;int size; //访问的地址和字节数while (fscanf(tracefile, "%s %lx,%d\n", oper, &address, &size) == 3) {if (oper[0] == 'I') continue; // 忽略Iint group_pos = (address >> b) & ~(~0u << s); // 从 第 b位开始取,取s位u64 address_tag = address >> (b + s); // b + s之后的位都是char resultV[20]; // 为了 -v 设置的string显示memset(resultV, 0, sizeof resultV);++T;findCache(address_tag, group_pos, resultV);if (oper[0] == 'M') findCache(address_tag, group_pos, resultV); // M需要两次if (verbose) fprintf(stdout, "%s %lx,%d %s\n", oper, address, size, resultV);}printSummary(result[0], result[1], result[2]);return 0;
}
核心函数逻辑:
opt
就是利用 getopt 库函数,解析命令行参数
FILE *opt(int argc, char **argv)
{FILE *tracefile;/* Parse the command line 这里c用int是为了保证兼容性,因为有的系统char是unsigned的*/for (int c; (c = getopt(argc, argv, "hvsEbt")) != EOF;) {switch (c) {case 'h': /* print help message */usage();break;case 'v': /* emit additional diagnostic info */verbose = 1;break;case 't': /* 文件 */tracefile = fopen(argv[optind], "r");if (tracefile == NULL) usage();break;case 's': // 组数的位s = atoi(argv[optind]);if (s <= 0) usage();S = 1 << s;break;case 'E': // 每一组的行数E = atoi(argv[optind]);if (E <= 0) usage();break;case 'b':b = atoi(argv[optind]);if (b <= 0) usage();B = 1 << b;break;}}return tracefile;
}
findCache
模拟 cache访问,维护LRU逻辑
void findCache(u64 tag, int group_pos, char *resultV)
{groupNode group = cache[group_pos];int min_t_pos = 0, empty_line = -1;for (int i = 0; i < E; ++i) {struct lineNode line = group[i];if (!line.t)empty_line = i; // 有空行else {if (line.tag == tag) { // 命中,设置hitsetResult(group, HIT, tag, i, resultV);return;}if (group[min_t_pos].t > line.t)min_t_pos = i; // 取最小的时刻值,也就是最近最少访问的了}}setResult(group, MISS, tag, empty_line, resultV);if (empty_line == -1) //要读或者写但是没有一个 空行 说明得发生evictionsetResult(group, EVICTION, tag, min_t_pos, resultV);
}
剩下的都很简单
完整代码:
/*===========头文件===============*/
#include "cachelab.h"
#include <fcntl.h>
#include <getopt.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/*===========头文件===============*/void usage(void) { exit(1); } // 打印帮助信息可以不实现
int verbose = 0, s, E, b, S, B; // cache的参数,由命令行输入,opt函数解析int T = 0; //时间戳,第一个访存指令的时刻为1,之后每次数据访存都累加1
typedef __uint64_t u64;
typedef unsigned int uint;// 行的定义
typedef struct lineNode { int t; // 时刻u64 tag; // 标记位
} * groupNode; // 组enum Category { HIT, MISS, EVICTION }; // 命中 / 缺失 / 驱逐
uint result[3]; // 统计命中、未命中和替换次数
const char *categoryString[3] = {"hit ", "miss ", "eviction "};
groupNode *cache; // cache 就是若干组
void init(); // 初始化cache
FILE *opt(int argc, char **argv); // 解析命令行选项
void findCache(u64 tag, int group_pos, char *result); // 查询int main(int argc, char **argv)
{FILE *tracefile = opt(argc, argv); // 从命令行获取 S E Binit(); // 根据输入参数初始化cache// 接下来处理每一条指令char oper[2];u64 address;int size; //访问的地址和字节数while (fscanf(tracefile, "%s %lx,%d\n", oper, &address, &size) == 3) {if (oper[0] == 'I') continue; // 忽略Iint group_pos = (address >> b) & ~(~0u << s); // 从 第 b位开始取,取s位u64 address_tag = address >> (b + s); // b + s之后的位都是char resultV[20]; // 为了 -v 设置的string显示memset(resultV, 0, sizeof resultV);++T;findCache(address_tag, group_pos, resultV);if (oper[0] == 'M') findCache(address_tag, group_pos, resultV); // M需要两次if (verbose) fprintf(stdout, "%s %lx,%d %s\n", oper, address, size, resultV);}printSummary(result[0], result[1], result[2]);return 0;
}// 初始化整个cache
void init()
{cache = (groupNode *)malloc(sizeof(groupNode) * S);for (int i = 0; i < S; ++i) {cache[i] = (struct lineNode *)malloc(sizeof(struct lineNode) * E);for (int j = 0; j < E; ++j) cache[i][j].t = 0;}
}// category是缓存的种类,resultV是main传下来的,为了verbose的输出
void setResult(groupNode group, enum Category category, int tag, int pos, char *resultV)
{++result[category];group[pos].tag = tag;group[pos].t = T;if (verbose) strcat(resultV, categoryString[category]);
}// 遍历这个组的所有行,然后看一下是否命中,最后再进行相应的操作即可
void findCache(u64 tag, int group_pos, char *resultV)
{groupNode group = cache[group_pos];int min_t_pos = 0, empty_line = -1;for (int i = 0; i < E; ++i) {struct lineNode line = group[i];if (!line.t)empty_line = i; // 有空行else {if (line.tag == tag) { // 命中,设置hitsetResult(group, HIT, tag, i, resultV);return;}if (group[min_t_pos].t > line.t)min_t_pos = i; // 取最小的时刻值,也就是最近最少访问的了}}setResult(group, MISS, tag, empty_line, resultV);if (empty_line == -1) //要读或者写但是没有一个 空行 说明得发生evictionsetResult(group, EVICTION, tag, min_t_pos, resultV);
}FILE *opt(int argc, char **argv)
{FILE *tracefile;/* Parse the command line 这里c用int是为了保证兼容性,因为有的系统char是unsigned的*/for (int c; (c = getopt(argc, argv, "hvsEbt")) != EOF;) {switch (c) {case 'h': /* print help message */usage();break;case 'v': /* emit additional diagnostic info */verbose = 1;break;case 't': /* 文件 */tracefile = fopen(argv[optind], "r");if (tracefile == NULL) usage();break;case 's': // 组数的位s = atoi(argv[optind]);if (s <= 0) usage();S = 1 << s;break;case 'E': // 每一组的行数E = atoi(argv[optind]);if (E <= 0) usage();break;case 'b':b = atoi(argv[optind]);if (b <= 0) usage();B = 1 << b;break;}}// printf("-%d 4 -%d 1 -%d 4 -t \n", s, E, b);return tracefile;
}执行结果:
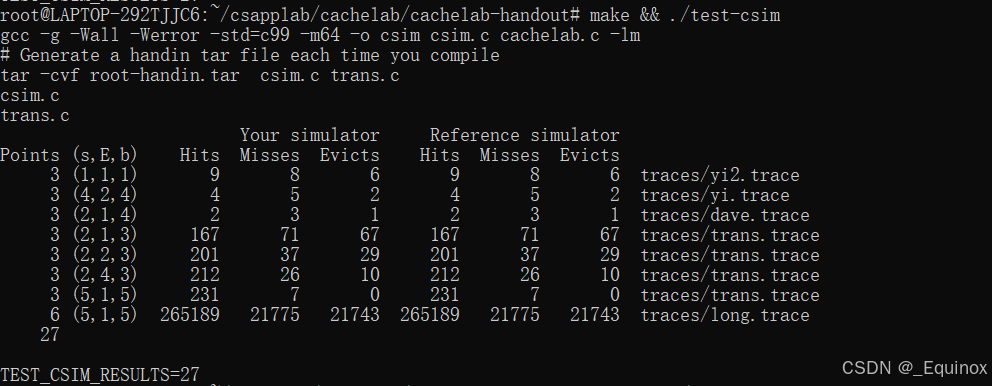
Part B: Optimizing Matrix Transpose
这个part指向性非常明确,我们优化矩阵转置的操作,令其缓存友好。
一共要实现三个转置函数:32×32,64×64,61×67
32×32
考虑分块转置,因为 一个 cache 块的大小为 32字节,即 8个int,我们 8 * 8 分块进行矩阵转置。
组号分布非常的舒服:
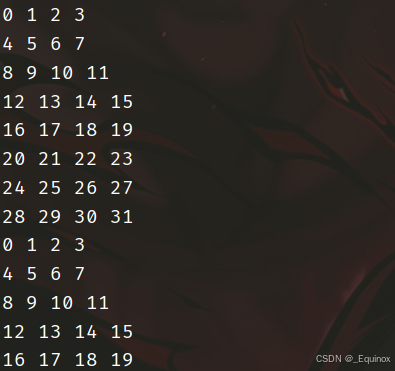
注意先把 A 的 每块一行取出来放到临时变量,如果直接赋值,那么会 load 然后 store 两次访存,造成块驱逐。
int i, j;
for (i = 0; i < 32; i += 8) { for (j = 0; j < 32; j += 8) { for (int cnt = 0; cnt < 8; ++cnt, ++i) {int temp1 = A[i][j]; int temp2 = A[i][j + 1];int temp3 = A[i][j + 2];int temp4 = A[i][j + 3];int temp5 = A[i][j + 4];int temp6 = A[i][j + 5];int temp7 = A[i][j + 6];int temp8 = A[i][j + 7];B[j][i] = temp1; B[j + 1][i] = temp2;B[j + 2][i] = temp3;B[j + 3][i] = temp4;B[j + 4][i] = temp5;B[j + 5][i] = temp6;B[j + 6][i] = temp7;B[j + 7][i] = temp8;}i -= 8;}
}
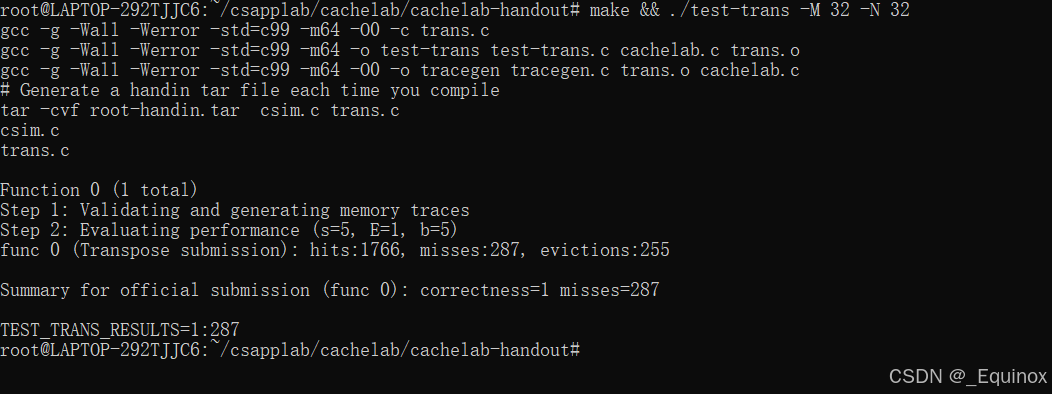
64×64
直接用 8 * 8 分块转置,会1:4699
注意到 64 * 64 的组号分布
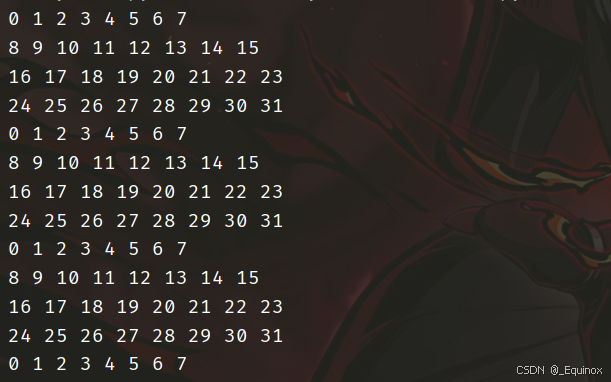
竖着循环周期是4,所以我们 8 * 8分块,往下填的时候,每4个就把上面四个驱逐,导致命中率极低。
那么我们不妨 改成4 * 4 的分块转置,然后就能通过了。
void transpose_64(int M, int N, int A[N][M], int B[M][N])
{int i, j;for (i = 0; i < 64; i += 4) { for (j = 0; j < 64; j += 4) { for (int cnt = 0; cnt < 4; ++cnt, ++i) { int temp1 = A[i][j]; int temp2 = A[i][j + 1];int temp3 = A[i][j + 2];int temp4 = A[i][j + 3];B[j][i] = temp1; B[j + 1][i] = temp2;B[j + 2][i] = temp3;B[j + 3][i] = temp4;}i -= 4;}}
}
61 × 67
组号分布:
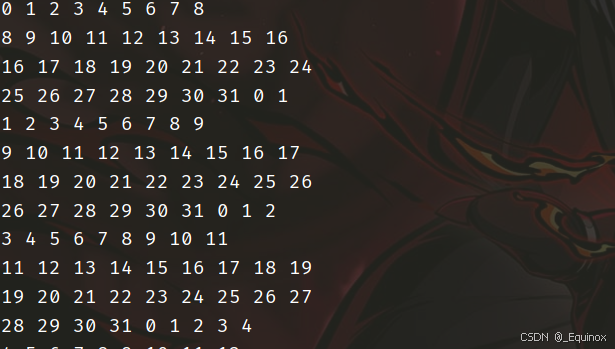
因为 61 和 67 俩数都是质数,导致组号分布很难被卡,我们想要直接计算比较好的分块大小很难,所以直接暴力枚举,测试出来17最优
void transpose_61(int M, int N, int A[N][M], int B[M][N])
{int i, j;const int BLOCK = 17;for (i = 0; i < N; i += BLOCK) { for (j = 0; j < M; j += BLOCK) { for (int x = i; x < N && x < i + BLOCK; ++x)for (int y = j; y < M && y < j + BLOCK; ++y) B[y][x] = A[x][y];}}
}
完整代码:
/** trans.c - Matrix transpose B = A^T** Each transpose function must have a prototype of the form:* void trans(int M, int N, int A[N][M], int B[M][N]);** A transpose function is evaluated by counting the number of misses* on a 1KB direct mapped cache with a block size of 32 bytes.*/
#include <stdio.h>#include "cachelab.h"int is_transpose(int M, int N, int A[N][M], int B[M][N]);/** transpose_submit - This is the solution transpose function that you* will be graded on for Part B of the assignment. Do not change* the description string "Transpose submission", as the driver* searches for that string to identify the transpose function to* be graded.*/// cache参数: 32个组,每组一块,block=32字节char transpose_submit_desc[] = "Transpose submission";
void transpose_32(int M, int N, int A[N][M], int B[M][N]);
void transpose_64(int M, int N, int A[N][M], int B[M][N]);
void transpose_61(int M, int N, int A[N][M], int B[M][N]);void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{switch (M) {case 32:transpose_32(M, N, A, B);break;case 64:transpose_64(M, N, A, B);break;case 61:transpose_61(M, N, A, B);break;}
}void transpose_32(int M, int N, int A[N][M], int B[M][N])
{int i, j;for (i = 0; i < 32; i += 8) { for (j = 0; j < 32; j += 8) { for (int cnt = 0; cnt < 8; ++cnt, ++i) { int temp1 = A[i][j]; int temp2 = A[i][j + 1];int temp3 = A[i][j + 2];int temp4 = A[i][j + 3];int temp5 = A[i][j + 4];int temp6 = A[i][j + 5];int temp7 = A[i][j + 6];int temp8 = A[i][j + 7];B[j][i] = temp1; B[j + 1][i] = temp2;B[j + 2][i] = temp3;B[j + 3][i] = temp4;B[j + 4][i] = temp5;B[j + 5][i] = temp6;B[j + 6][i] = temp7;B[j + 7][i] = temp8;}i -= 8;}}
}void transpose_64(int M, int N, int A[N][M], int B[M][N])
{int i, j;for (i = 0; i < 64; i += 4) { for (j = 0; j < 64; j += 4) { for (int cnt = 0; cnt < 4; ++cnt, ++i) { int temp1 = A[i][j]; int temp2 = A[i][j + 1];int temp3 = A[i][j + 2];int temp4 = A[i][j + 3];B[j][i] = temp1; B[j + 1][i] = temp2;B[j + 2][i] = temp3;B[j + 3][i] = temp4;}i -= 4;}}
}
void transpose_61(int M, int N, int A[N][M], int B[M][N])
{int i, j;const int BLOCK = 17;for (i = 0; i < N; i += BLOCK) { for (j = 0; j < M; j += BLOCK) { for (int x = i; x < N && x < i + BLOCK; ++x)for (int y = j; y < M && y < j + BLOCK; ++y) B[y][x] = A[x][y];}}
}/** You can define additional transpose functions below. We've defined* a simple one below to help you get started.*//** trans - A simple baseline transpose function, not optimized for the cache.*/
char trans_desc[] = "Simple row-wise scan transpose";
void trans(int M, int N, int A[N][M], int B[M][N])
{int i, j, tmp;for (i = 0; i < N; i++) {for (j = 0; j < M; j++) {tmp = A[i][j];B[j][i] = tmp;}}
}/** registerFunctions - This function registers your transpose* functions with the driver. At runtime, the driver will* evaluate each of the registered functions and summarize their* performance. This is a handy way to experiment with different* transpose strategies.*/
void registerFunctions()
{/* Register your solution function */registerTransFunction(transpose_submit, transpose_submit_desc);/* Register any additional transpose functions */// registerTransFunction(transpose_submit3, trans_desc);
}/** is_transpose - This helper function checks if B is the transpose of* A. You can check the correctness of your transpose by calling* it before returning from the transpose function.*/
int is_transpose(int M, int N, int A[N][M], int B[M][N])
{int i, j;for (i = 0; i < N; i++) {for (j = 0; j < M; ++j) {if (A[i][j] != B[j][i]) {return 0;}}}return 1;
}
相关文章:
lab4 CSAPP:Cachelab
写在前面 最简单的一集 实验室分为两个部分。在A部分中,实现一个缓存模拟器。在B部分中,编写一个矩阵针对高速缓存性能优化的转置功能。 感觉是比较经典的问题,之前在体系结构的课程中接触过,终于能通过lab实操一下了。 实验目…...

VScode C语言学习开发环境;运行提示“#Include错误,无法打开源文件stdio.h”
C/C环境配置 参考: VS Code 配置 C/C 编程运行环境(保姆级教程)_vscode配置c环境-CSDN博客 基本步骤 - 安装MinGW-W64,其包含 GCC 编译器:bin目录添加到环境变量;CMD 中输入gcc --version或where gcc验证…...

雷龙CS SD NAND(贴片式TF卡)测评体验
声明:非广告,为用户体验文章 前段时间偶然获得了雷龙出品的贴片式 TF 卡芯片及转接板,到手的是两片贴片式 nand 芯片搭配一个转接板,其中有一片官方已经焊接好了,从外观来看,正面和背面设计布局合理&#x…...

伯克利 CS61A 课堂笔记 11 —— Mutability
本系列为加州伯克利大学著名 Python 基础课程 CS61A 的课堂笔记整理,全英文内容,文末附词汇解释。 目录 01 Objects 02 Example: Strings Ⅰ Representing Strings: the ASCII Standard Ⅱ Representing Strings: the Unicode Standard 03 Mutatio…...
从零开始构建一个小型字符级语言模型的详细教程(基于Transformer架构)之一数据准备
最近特别火的DeepSeek,是一个大语言模型,那一个模型是如何构建起来的呢?DeepSeek基于Transformer架构,接下来我们也从零开始构建一个基于Transformer架构的小型语言模型,并说明构建的详细步骤及内部组件说明。我们以构建一个字符级语言模型(Char-Level LM)为例,目标是通…...

云原生DevOps:Zadig架构设计与企业实践分析
在云原生时代,随着微服务架构和容器技术的广泛应用,软件交付模式正经历着深刻的变革。DevOps作为一种文化、运动和实践,正逐渐成为企业快速交付高质量软件的关键。本文将探讨在云原生背景下,DevOps工程架构的设计与实践࿰…...

UMLS数据下载及访问
UMLS数据申请 这个直接在官网上申请即可,记得把地址填全,基本都会拿到lisence。 UMLS数据访问 UMLS的数据访问分为网页访问,API访问以及数据下载后的本地访问,网页访问,API访问按照官网的指示即可,这里主…...

DEX-EE三指灵巧手:扩展AI与机器人研究的边界
DEX-EE三指灵巧手,由Shadow Robot与Google DeepMind合作开发,以其先进技术和设计,正在引领AI与机器人研究的新趋势。其高精度传感器和灵活的机械手指,能够捕捉复杂的环境数据,为强化学习实验提供了可靠支持。 Shadow R…...

在ubuntu上用Python的openpyxl模块操作Excel的案例
文章目录 安装模块读取Excel数据库取数匹配数据和更新Excel数据 在Ubuntu系统的环境下基本职能借助Python的openpyxl模块实现对Excel数据的操作。 安装模块 本次需要用到的模块需要提前安装(如果没有的话) pip3 install openpyxl pip3 install pymysql在操作前,需…...

【STM32】外部时钟|红外反射光电开关
1.外部时钟 单片机如何对外部触发进行计数?先看一下内部时钟,内部时钟是接在APB1和APB2时钟线上的,APB1,APB2来自stm32单片机内部的脉冲信号,也叫内部时钟。我们用来定时。同样我们可以把外部的信号接入单片机,来对其…...

深入了解 DevOps 基础架构:可追溯性的关键作用
在当今竞争激烈的软件环境中,快速交付强大的应用程序至关重要。尽管如此,在不影响质量的情况下保持速度可能是一项艰巨的任务,这就是 DevOps 中的可追溯性发挥作用的地方。通过提供软件开发生命周期 (SDLC) 的透明视图…...

Django+Vue3全栈开发实战:从零搭建博客系统
文章目录 1. 开发环境准备2. 创建Django项目与配置3. 设计数据模型与API4. 使用DRF创建RESTful API5. 创建Vue3项目与配置6. 前端页面开发与组件设计7. 前后端交互与Axios集成8. 项目优化与调试9. 部署上线10. 总结与扩展10.1 项目总结10.1.1 技术栈回顾10.1.2 项目亮点 10.2 扩…...

深度学习之图像回归(一)
前言 图像回归任务主要是理解一个最简单的深度学习相关项目的结构,整体的思路,数据集的处理,模型的训练过程和优化处理。 因为深度学习的项目思路是差不多的,主要的区别是对于数据集的处理阶段,之后模型训练有一些小…...

使用vue-office报错TypeError: ft.createElementVNode is not a function
支持多种文件(.docx、.xlsx、.xls、.pdf、.pptx)预览的vue组件库,支持vue2/3。也支持非Vue框架的预览。 不支持.doc、.ppt(2003年及以前的版本) 官网:https://www.npmjs.com/package/vue-office/excel?activeTabreadme 官方有实…...

《深度揭秘:DeepSeek如何解锁自然语言处理密码》
在人工智能蓬勃发展的当下,自然语言处理(NLP)成为了连接人类与机器的关键桥梁。作为该领域的佼佼者,DeepSeek以其卓越的语义理解和生成能力,备受瞩目。今天,就让我们深入探寻DeepSeek在自然语言处理中实现语…...

解决 Mac 只显示文件大小,不显示目录大小
前言 在使用 mac 的时候总是只显示文件的大小,不显示文件夹的大小,为了解决问题可以开启“计算文件夹”。 步骤 1.进入访达 2.工具栏点击“显示”选项,点击 “查看显示选项” 3.勾选 显示“资源库"文件夹 和 计算所有大小 或者点击…...

从零开始学习PX4源码9(部署px4源码到gitee)
目录 文章目录 目录摘要1.gitee上创建仓库1.1 gitee上创建仓库PX4代码仓库1.2 gitee上创建子仓库2.固件在gitee部署过程2.1下载固件到本地2.2切换本地分支2.3修改.gitmodules内容2.4同步子模块仓库地址2.5同步子模块仓库地址更新(下载)子模块3.一级子模块和二级子模块的映射关…...

遗传算法与深度学习实战系列,自动调优深度神经网络和机器学习的超参数
遗传算法与深度学习实战系列文章 目录 进化深度学习生命模拟及其应用生命模拟与进化论遗传算法中常用遗传算子遗传算法框架DEAPDEAP框架初体验使用遗传算法解决N皇后问题使用遗传算法解决旅行商问题使用遗传算法重建图像遗传编程详解与实现粒子群优化详解与实现协同进化详解与…...
】爬虫时代,数据安全的坚盾与隐私保护的密锁)
【Python爬虫(28)】爬虫时代,数据安全的坚盾与隐私保护的密锁
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取ÿ…...

分布式光纤声波振动技术在钻井泄漏检测中的应用
在石油天然气的钻井作业中,及时发现并定位泄漏点对于保障开采安全、降低环境污染以及避免经济损失至关重要。传统的泄漏检测方法往往存在局限性,而分布式光纤声波振动技术凭借其独特的优势,正逐渐成为钻井过程中寻找泄漏的有力工具。 技术原理…...

2025年AI数字人大模型+智能家居HA引领未来(开源项目名称:AI Sphere Butler)
介绍 开源项目计划:AI Sphere Butler 打造全方位服务用户生活的AI全能管家——代号**“小粒”**(管家名称可以随意自定义) GitHub地址:https://github.com/latiaoge/AI-Sphere-Butler 项目名称:AI Sphere Butler&…...

UGUI RectTransform的SizeDelta属性
根据已知内容,SizeDelta offsetMax - offsetMin 1.锚点聚拢情况下 输出 那么此时SizeDelta就是UI元素的长宽大小 2. 锚点分散时 引用自此篇文章中的描述 揭秘!anchoredPosition的几何意义! SizeDelta offsetMax - offsetMin (rectMax…...

三甲医院网络架构与安全建设实战
一、设计目标 实现医疗业务网/卫生专网/互联网三网隔离 满足等保2.0三级合规要求 保障PACS影像系统低时延传输 实现医疗物联网统一接入管控 二、全网拓扑架构 三、网络分区与安全设计 IP/VLAN规划表 核心业务配置(华为CE6865) interface 100G…...

Ubuntu 防火墙ufw详解
ufw(Uncomplicated Firewall)是 Ubuntu 中一个简单易用的防火墙管理工具,基于 iptables,旨在简化防火墙配置。以下是 ufw 的详细说明和使用方法: 1. 安装 ufw 在大多数 Ubuntu 系统中,ufw 已经预装。如果没…...

机器学习笔记——常用损失函数
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本笔记介绍机器学习中常见的损失函数和代价函数,各函数的使用场景。 热门专栏 机器学习 机器学习笔记合集 深度学习 深度学习笔记合集 文章目录 热门…...

计算机网络:应用层 —— 动态主机配置协议 DHCP
文章目录 什么是 DHCP?DHCP 的产生背景DHCP 的工作过程工作流程地址分配机制 DHCP 中继代理总结 什么是 DHCP? 动态主机配置协议(DHCP,Dynamic Host Configuration Protocol)是一种网络管理协议,用于自动分…...

23种设计模式 - 解释器模式
模式定义 解释器模式(Interpreter Pattern)是一种行为型设计模式,用于为特定语言(如数控系统的G代码)定义文法规则,并构建解释器来解析和执行该语言的语句。它通过将语法规则分解为多个类,实现…...
)
C++中string常用方法操作指南(后续补充)
文章目录 1. 定义和初始化字符串2. 字符串的基本操作2.1 获取字符串长度2.2 检查字符串是否为空2.3 访问字符串中的字符 3. 输入字符串4. 常用的字符串操作4.1 截取子字符串4.2 查找子字符串4.3 替换字符串4.4 插入字符串4.5 删除字符串 5. 字符串的排序6. 字符串与数值的转换6…...

遥感与GIS在滑坡、泥石流风险普查中的实践技术应用
原文>>> 遥感与GIS在滑坡、泥石流风险普查中的实践技术应用 我国是地质灾害多发国家,地质灾害的发生无论是对于地质环境还是人类生命财产的安全都会带来较大的威胁,因此需要开展地质灾害风险普查。利用遥感(RS)技术进行地…...

14天速成PAT-BASIC基础知识!
两周关于PAT的基础学习计划。 Day 1: 基本语法和输入输出 知识点 数据类型(int, long, float, double, char)变量声明和初始化输入输出函数(scanf, printf)控制结构(if-else, switch, for, while, do-while࿰…...