Moonshot AI 新突破:MoBA 为大语言模型长文本处理提效论文速读
前言
在自然语言处理领域,随着大语言模型(LLMs)不断拓展其阅读、理解和生成文本的能力,如何高效处理长文本成为一项关键挑战。近日,Moonshot AI Research 联合清华大学、浙江大学的研究人员提出了一种创新方法 —— 混合块注意力机制(Mixture of Block Attention,MoBA),它将专家混合(Mixture of Experts,MoE)原理应用于注意力机制,为解决长文本处理难题带来了新的思路。

在 Transformer 架构广泛应用的当下,其注意力机制存在明显弊端。在处理长文本时,传统注意力机制需将每个 token 与其他所有 token 进行比较,这使得计算成本随序列长度呈二次方增长。当模型处理长篇文档、多章书籍、法律简报或大型代码库等包含大量文本信息的任务时,这种计算成本会变得难以承受。此前,为解决这一问题,研究人员尝试过多种方法。例如,滑动窗口机制将 token 限制在局部邻域内,虽降低了计算量,但会忽略重要的全局关系;而一些彻底改变基本架构的方法,如用全新结构替代 softmax 注意力机制,往往需要从头开始重新训练模型,难以利用现有的预训练成果。

核心原理
MoBA 的出现有效弥补了上述方法的不足。它的核心在于将输入划分为易于管理的 “块”,并借助可训练的门控系统来确定每个查询 token 相关的块。这种设计遵循 “少结构” 原则,不预先定义哪些 token 应该相互作用,而是由学习到的门控网络做出决策。与固定结构或近似处理的方法不同,MoBA 能让模型自主学习注意力的聚焦点。而且,MoBA 可与现有的基于 Transformer 的模型无缝协作,它作为一种 “插件” 或替代方案,保持与原模型相同的参数数量,避免架构膨胀,同时保留因果掩码,确保自回归生成的准确性。在实际应用中,MoBA 能在稀疏注意力和全注意力之间灵活切换。处理超长输入时,稀疏注意力可提升速度;而在训练的某些层或阶段,若需要全注意力,模型也能切换回标准模式。
从技术细节来看,MoBA 将上下文划分为多个块,每个块包含连续的 token 序列。门控机制通过比较查询 token 与块的池化键表示,计算查询 token 与每个块之间的 “亲和度” 分数,然后选择得分最高的块。这样,只有最相关块中的 token 才会对最终的注意力分布产生影响。同时,包含查询 token 本身的块始终被纳入,以确保局部上下文信息可访问。并且,MoBA 执行因果掩码,防止 token 关注未来位置,维持从左到右的自回归属性。这种基于块的方法大幅减少了 token 比较次数,使计算规模低于二次方,随着上下文长度增加到数十万甚至数百万个 token,效率提升愈发显著。此外,MoBA 与现代加速器和专用内核兼容性良好。研究人员将 MoBA 与 FlashAttention(一种高性能的快速、内存高效的精确注意力库)相结合,根据所选块对查询 - 键 - 值操作进行精心分组,进一步优化了计算流程。实验数据显示,在处理一百万个 token 时,MoBA 相比传统全注意力机制速度提升约 6 倍,凸显了其在实际应用中的优势。
在性能测试方面,MoBA 表现出色。技术报告显示,在多种任务中,MoBA 的性能与全注意力机制相当,但在处理长序列时可显著节省计算资源。在语言建模数据测试中,当序列长度为 8192 或 32768 个 token 时,MoBA 的困惑度与全注意力 Transformer 相近。更为关键的是,当研究人员将上下文长度逐渐扩展到 128000 及更长时,MoBA 仍能保持强大的长上下文理解能力。在 “尾随 token” 评估中,MoBA 能够有效处理长提示末尾附近的 token 预测任务,且预测质量没有明显下降。研究人员还对 MoBA 的块大小和门控策略进行了敏感性探索。实验表明,细化粒度(使用更小的块但选择更多的块)有助于模型更接近全注意力的效果。即使在忽略大部分上下文的情况下,自适应门控也能识别与查询真正相关的块。此外,“混合” 模式展现出一种平衡策略:部分层继续使用 MoBA 提升速度,少数层则恢复全注意力。这种混合方法在监督微调任务中尤为有益,例如当输入中的某些位置在训练目标中被屏蔽时,保留少数上层的全注意力,可使模型保持广泛的上下文覆盖,有助于需要全局视角的任务。
关键代码分析:
以下是对 MoBA 库关键代码 MixedAttention 类的分析以及关键代码的摘录与注释:
整体分析
MixedAttention 类是一个自定义的 torch.autograd.Function,用于实现混合块注意力机制。这个类主要包含两个静态方法:forward 和 backward,分别用于前向传播和反向传播。
class MixedAttention(torch.autograd.Function):# 前向传播函数@staticmethoddef forward(ctx,q, # 查询张量k, # 键张量v, # 值张量self_attn_cu_seqlen, # 自注意力累积序列长度moba_q, # MoBA 查询张量moba_kv, # MoBA 键值张量moba_cu_seqlen_q, # MoBA 查询累积序列长度moba_cu_seqlen_kv, # MoBA 键值累积序列长度max_seqlen, # 最大序列长度moba_chunk_size, # MoBA 块大小moba_q_sh_indices, # MoBA 查询块索引):# 保存一些参数,用于后续的反向传播ctx.max_seqlen = max_seqlenctx.moba_chunk_size = moba_chunk_sizectx.softmax_scale = softmax_scale = q.shape[-1] ** (-0.5)# 自注意力计算_, _, _, _, self_attn_out_sh, self_attn_lse_hs, _, _ = (_flash_attn_varlen_forward(q=q,k=k,v=v,cu_seqlens_q=self_attn_cu_seqlen,cu_seqlens_k=self_attn_cu_seqlen,max_seqlen_q=max_seqlen,max_seqlen_k=max_seqlen,softmax_scale=softmax_scale,causal=True,dropout_p=0.0,))# MoBA 注意力计算_, _, _, _, moba_attn_out, moba_attn_lse_hs, _, _ = _flash_attn_varlen_forward(q=moba_q,k=moba_kv[:, 0],v=moba_kv[:, 1],cu_seqlens_q=moba_cu_seqlen_q,cu_seqlens_k=moba_cu_seqlen_kv,max_seqlen_q=max_seqlen,max_seqlen_k=moba_chunk_size,softmax_scale=softmax_scale,causal=False,dropout_p=0.0,)# 转换 lse 形状,从 hs 转换为 sh(遵循传统混合注意力逻辑)self_attn_lse_sh = self_attn_lse_hs.t().contiguous()moba_attn_lse = moba_attn_lse_hs.t().contiguous()# 初始化输出缓冲区,形状与 q 相同output = torch.zeros((q.shape[0], q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32)# 将输出张量展平为二维,便于后续索引操作output_2d = output.view(-1, q.shape[2])# 计算混合 lse# 减去最大 lse 以避免指数爆炸max_lse_1d = self_attn_lse_sh.view(-1)max_lse_1d = max_lse_1d.index_reduce(0, moba_q_sh_indices, moba_attn_lse.view(-1), "amax")self_attn_lse_sh = self_attn_lse_sh - max_lse_1d.view_as(self_attn_lse_sh)moba_attn_lse = (moba_attn_lse.view(-1).sub(max_lse_1d.index_select(0, moba_q_sh_indices)).reshape_as(moba_attn_lse))# 计算自注意力和 MoBA 注意力的 softmax 结果mixed_attn_se_sh = self_attn_lse_sh.exp()moba_attn_se = moba_attn_lse.exp()# 将 MoBA 注意力结果累加到自注意力结果上mixed_attn_se_sh.view(-1).index_add_(0, moba_q_sh_indices, moba_attn_se.view(-1))mixed_attn_lse_sh = mixed_attn_se_sh.log()# 加权自注意力输出factor = (self_attn_lse_sh - mixed_attn_lse_sh).exp() # [ vS, H ]self_attn_out_sh = self_attn_out_sh * factor.unsqueeze(-1)output_2d += self_attn_out_sh.reshape_as(output_2d)# 加权 MoBA 输出mixed_attn_lse = (mixed_attn_lse_sh.view(-1).index_select(0, moba_q_sh_indices).view_as(moba_attn_lse))factor = (moba_attn_lse - mixed_attn_lse).exp() # [ vS, H ]moba_attn_out = moba_attn_out * factor.unsqueeze(-1)raw_attn_out = moba_attn_out.view(-1, moba_attn_out.shape[-1])output_2d.index_add_(0, moba_q_sh_indices, raw_attn_out)# 将输出转换为与输入相同的数据类型output = output.to(q.dtype)# 恢复最大 lsemixed_attn_lse_sh = mixed_attn_lse_sh + max_lse_1d.view_as(mixed_attn_se_sh)# 保存中间结果,用于反向传播ctx.save_for_backward(output,mixed_attn_lse_sh,q,k,v,self_attn_cu_seqlen,moba_q,moba_kv,moba_cu_seqlen_q,moba_cu_seqlen_kv,moba_q_sh_indices,)return output# 反向传播函数@staticmethoddef backward(ctx, d_output):# 从上下文中获取保存的参数max_seqlen = ctx.max_seqlenmoba_chunk_size = ctx.moba_chunk_sizesoftmax_scale = ctx.softmax_scale(output,mixed_attn_vlse_sh,q,k,v,self_attn_cu_seqlen,moba_q,moba_kv,moba_cu_seqlen_q,moba_cu_seqlen_kv,moba_q_sh_indices,) = ctx.saved_tensors# 确保输入梯度连续d_output = d_output.contiguous()# 计算自注意力的梯度dq, dk, dv, _ = _flash_attn_varlen_backward(dout=d_output,q=q,k=k,v=v,out=output,softmax_lse=mixed_attn_vlse_sh.t().contiguous(),dq=None,dk=None,dv=None,cu_seqlens_q=self_attn_cu_seqlen,cu_seqlens_k=self_attn_cu_seqlen,max_seqlen_q=max_seqlen,max_seqlen_k=max_seqlen,softmax_scale=softmax_scale,causal=True,dropout_p=0.0,window_size=(-1, -1),softcap=0.0,alibi_slopes=None,deterministic=True,)# 计算 MoBA 注意力的梯度headdim = q.shape[-1]d_moba_output = (d_output.view(-1, headdim).index_select(0, moba_q_sh_indices).unsqueeze(1))moba_output = (output.view(-1, headdim).index_select(0, moba_q_sh_indices).unsqueeze(1))mixed_attn_vlse = (mixed_attn_vlse_sh.view(-1).index_select(0, moba_q_sh_indices).view(1, -1))dmq, dmk, dmv, _ = _flash_attn_varlen_backward(dout=d_moba_output,q=moba_q,k=moba_kv[:, 0],v=moba_kv[:, 1],out=moba_output,softmax_lse=mixed_attn_vlse,dq=None,dk=None,dv=None,cu_seqlens_q=moba_cu_seqlen_q,cu_seqlens_k=moba_cu_seqlen_kv,max_seqlen_q=max_seqlen,max_seqlen_k=moba_chunk_size,softmax_scale=softmax_scale,causal=False,dropout_p=0.0,window_size=(-1, -1),softcap=0.0,alibi_slopes=None,deterministic=True,)# 合并 MoBA 的键和值的梯度dmkv = torch.stack((dmk, dmv), dim=1)return dq, dk, dv, None, dmq, dmkv, None, None, None, None, None代码关键部分解释
-
前向传播 (
forward):- 分别计算自注意力和 MoBA 注意力的结果。
- 对注意力分数进行处理,包括形状转换、归一化等操作,以避免指数爆炸。
- 将自注意力和 MoBA 注意力的结果进行加权合并,得到最终的输出。
- 保存中间结果,用于后续的反向传播。
-
反向传播 (
backward):- 根据前向传播保存的中间结果,计算自注意力和 MoBA 注意力的梯度。
- 最终返回各个输入张量的梯度。
小结
通过这种方式,MixedAttention 类实现了 MoBA 混合块注意力机制,通过将上下文划分为块并进行选择性的注意力计算,有效减少了计算量,提升了处理长文本的效率。
总结
总体而言,MoBA 非常适合处理涉及大量上下文的任务,如长篇文档阅读理解、大规模代码补全以及需要完整对话历史的多轮对话系统。它在提高效率的同时,性能损失极小,为大规模训练大语言模型提供了一种极具吸引力的方法。虽然目前 MoBA 主要应用于文本领域,但研究人员认为,其底层机制在其他数据模态中也具有应用潜力。只要序列长度足够长,引发计算或内存问题,将查询分配给块 “专家” 的思路就有望缓解瓶颈,同时保持处理关键全局依赖关系的能力。随着语言应用中的序列长度持续增长,像 MoBA 这样的方法可能会在推动神经语言建模的可扩展性和成本效益方面发挥关键作用,为人工智能的发展注入新的活力。
相关文章:
Moonshot AI 新突破:MoBA 为大语言模型长文本处理提效论文速读
前言 在自然语言处理领域,随着大语言模型(LLMs)不断拓展其阅读、理解和生成文本的能力,如何高效处理长文本成为一项关键挑战。近日,Moonshot AI Research 联合清华大学、浙江大学的研究人员提出了一种创新方法 —— 混…...

Deepseek首页实现 HTML
人工智能与未来:机遇与挑战 引言 在过去的几十年里,人工智能(AI)技术取得了突飞猛进的发展。从语音助手到自动驾驶汽车,AI 正在深刻地改变我们的生活方式、工作方式以及社会结构。然而,随着 AI 技术的普及…...

AI革命下的多元生态:DeepSeek、ChatGPT、XAI、文心一言与通义千问的行业渗透与场景重构
前言 人工智能技术的爆发式发展催生了多样化的AI模型生态,从通用对话到垂直领域应用,从数据挖掘到创意生成,各模型凭借其独特的技术优势与场景适配性,正在重塑全球产业格局。本文将以DeepSeek、ChatGPT、XAI(可解释人…...

VS2022配置FFMPEG库基础教程
1 简介 1.1 起源与发展历程 FFmpeg诞生于2000年,由法国工程师Fabrice Bellard主导开发,其名称源自"Fast Forward MPEG",初期定位为多媒体编解码工具。2004年后由Michael Niedermayer接任维护,逐步发展成为包含音视频采…...

kafka基本知识
什么是 Kafka? Apache Kafka 是一个开源的分布式流处理平台,最初由 LinkedIn 开发,后来成为 Apache 软件基金会的一部分。Kafka 主要用于构建实时数据管道和流处理应用程序。它能够高效地处理大量的数据流,广泛应用于日志收集、数…...

类型系统下的语言分类与类型系统基础
类型系统是一种根据计算值的种类对程序语法进行分类的方式,目的是自动检查是否有可能导致错误的行为。 —Benjamin.C.Pierce,《类型与编程语言》(2002) 每当谈到编程语言时,人们常常会提到“静态类型”和“动态类型”。…...

力扣-回溯-93 复原IP地址
思路 用一个vector存放可能的结果,然后用一个变量判断插入点的数量,假设再最后一段后也插入点 代码 class Solution { public:vector<string> result;vector<string> path;int toNum(string s){int d 1;int result 0;for(int i s.size…...

SpringSecurity设置白名单
Spring Security 访问权限系列文章: 《SpringSecurity基于配置方法控制访问权限:MVC匹配器、Ant匹配器》 《SpringSecurity基于注解实现方法级别授权:PreAuthorize、PostAuthorize、Secured》 《SpringSecurity设置白名单》 白名单࿰…...

有没有使用wxpython开发的类似于visio或drawio的开源项目(AI生成)
有没有使用wxpython开发的类似于visio或drawio的开源项目 是的,有一些使用wxPython开发的类似于Microsoft Visio或draw.io(现为diagrams.net)的开源项目。wxPython 是一个跨平台的GUI工具包,它允许Python开发者创建桌面应用程序&…...
)
HTML之JavaScript DOM操作元素(2)
HTML之JavaScript DOM操作元素(2) 4.增删元素var element document.createElement("元素名") 创建新元素父元素.appendChild(子元素) 在父元素中追加子元素父元素.insertBefore(新元素,参照元素) 在特定元素之前新增元…...

前端八股——JS+ES6
前端八股:JSES6 说明:个人总结,用于个人复习回顾,将持续改正创作,已在语雀公开,欢迎评论改正。...

day58 第十一章:图论part08
拓扑排序精讲 关键: 先找到入度为0的节点,把这些节点加入队列/结果,然后依次循环再找。 #include <iostream> #include <vector> #include <queue> #include <unordered_map> using namespace std; int main() {int …...

【MySQL 一 数据库基础】深入解析 MySQL 的索引(3)
索引 索引操作 自动创建 当我们为一张表加主键约束(Primary key),外键约束(Foreign Key),唯一约束(Unique)时,MySQL会为对应的的列自动创建一个索引;如果表不指定任何约束时,MySQL会自动为每一列生成一个索引并用ROW_I…...

【C++】优先级队列宝藏岛
> 🍃 本系列为初阶C的内容,如果感兴趣,欢迎订阅🚩 > 🎊个人主页:[小编的个人主页])小编的个人主页 > 🎀 🎉欢迎大家点赞👍收藏⭐文章 > ✌️ 🤞 …...

解决elementUi el-select 响应式不生效的问题
情况一,字段类型不匹配 考虑option的value值的字段类型是否和api返回的字段类型一致,如果一个为字符串一个为数字类型是无法匹配上的 <template> <div><el-select v-model"value" size"large"style"width: 240px"&…...

List 接口中的 sort 和 forEach 方法
List 接口中的 sort 和 forEach 方法是 Java 8 引入的两个非常实用的函数,分别用于 排序 和 遍历 列表中的元素。以下是它们的详细介绍和用法: sort 函数 功能 对列表中的元素进行排序。 默认使用自然顺序(如数字从小到大,字符…...
MusicGPT的本地化部署与远程调用:让你的Windows电脑成为AI音乐工作站
文章目录 前言1. 本地部署2. 使用方法介绍3. 内网穿透工具下载安装4. 配置公网地址5. 配置固定公网地址 前言 在如今快节奏的生活里,音乐不仅能够抚慰我们的心灵,还能激发无限创意。想象一下,在忙碌的工作间隙或闲暇时光中,只需输…...

小波变换背景预测matlab和python样例
小波变换使用matlab和python 注意1d和2d的函数区别。注意默认参数问题。最终三个版本结果能够对齐。 matlab load(wave_in.mat)% res: image of 1536 x 1536 th1; dlevel7; wavenamedb6;[m,n] wavedec2(res, dlevel, wavename);vec zeros(size(m)); vec(1:n(1)*n(1)*1) m…...

Unity通过Vosk实现离线语音识别方法
标注:deepseek直接生成,待验证 在Unity中实现离线语音识别可以通过集成第三方语音识别库来实现。以下是一个使用 Unity 和 Vosk(一个开源的离线语音识别库)的简单示例。 准备工作 Vosk:一个开源的离线语音识别库&am…...
--《设计图纸如何从电脑飞进生产线?揭秘研发系统的 “暗箱操作”》)
【登月计划】 DAY2 中期:产品研发与设计验证(4-6)--《设计图纸如何从电脑飞进生产线?揭秘研发系统的 “暗箱操作”》
目录 四、乐高教学:拆解 CAD/CAE 与 PLM 的 “共生关系” 1. CAD 系统:工程师的 “数字画笔” 🎨 2. CAE 系统:产品的 “虚拟实验室” 🔬 3. PLM 系统:设计的 “大管家” 五、装逼话术:设计…...

智能优化算法:莲花算法(Lotus flower algorithm,LFA)介绍,提供MATLAB代码
一、 莲花算法 1.1 算法原理 莲花算法(Lotus flower algorithm,LFA)是一种受自然启发的优化算法,其灵感来源于莲花的自清洁特性和授粉过程。莲花的自清洁特性,即所谓的“莲花效应”,是由其叶片表面的微纳…...

Qt开源项目获取
GitHub上超实用的Qt开源项目,码住不谢!🎉 宝子们,今天来给大家安利一波GitHub上超棒的Qt开源项目,无论是学习还是开发,都能找到超多灵感和实用工具,快来看看有没有你需要的吧!1. Qt-Advanced-Docking-System完美的Dock窗口布局解决方案,让你的窗口管理变得超级灵活。…...

Python 高级特性-迭代
目录 迭代 练习 小结 迭代 如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。 在Python中,迭代是通过for ... in来完成的,而很多语言比如C语言&a…...

企业数据集成:实现高效调拨出库自动化
调拨出库对接调出单-v:旺店通企业奇门数据集成到用友BIP 在企业信息化管理中,数据的高效流转和准确对接是实现业务流程自动化的关键。本文将分享一个实际案例,展示如何通过轻易云数据集成平台,将旺店通企业奇门的数据无缝集成到用…...

基于GraphQL的电商API性能优化实战
以下是一个基于 GraphQL 的电商 API 性能优化实战案例,涵盖从问题分析到具体优化措施的实施过程: 一、初始问题分析 在电商场景下,随着业务发展,基于 GraphQL 的 API 出现了一些性能瓶颈。例如: 复杂查询导致响应时间过…...

UniApp SelectorQuery 讲解
一、SelectorQuery简介 在UniApp中,SelectorQuery是一个非常强大的工具,它允许开发者查询节点信息。通过这个API,我们可以获取到页面元素的尺寸、位置、滚动条位置等信息。这在处理动态布局、动画效果或是用户交互时尤为重要。 二、基本使用…...

数据库管理-第295期 IT架构与爆炸半径(20250221)
数据库管理295期 2025-02-21 数据库管理-第295期 架构与爆炸半径(20250221)1 术语新解2 硬件:存储VS本地盘3 数据库3.1 多模VS专用3.2 集中式VS分布式 4 公有云VS非公有云总结 数据库管理-第295期 架构与爆炸半径(20250221&#x…...

基于WOA鲸鱼优化的BiLSTM双向长短期记忆网络序列预测算法matlab仿真,对比BiLSTM和LSTM
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 (完整程序运行后无水印) 2.算法运行软件版本 matlab2022a/matlab2024b 3.部分核心程序 (完整版代码包含详细中文注释和操作步骤视频…...
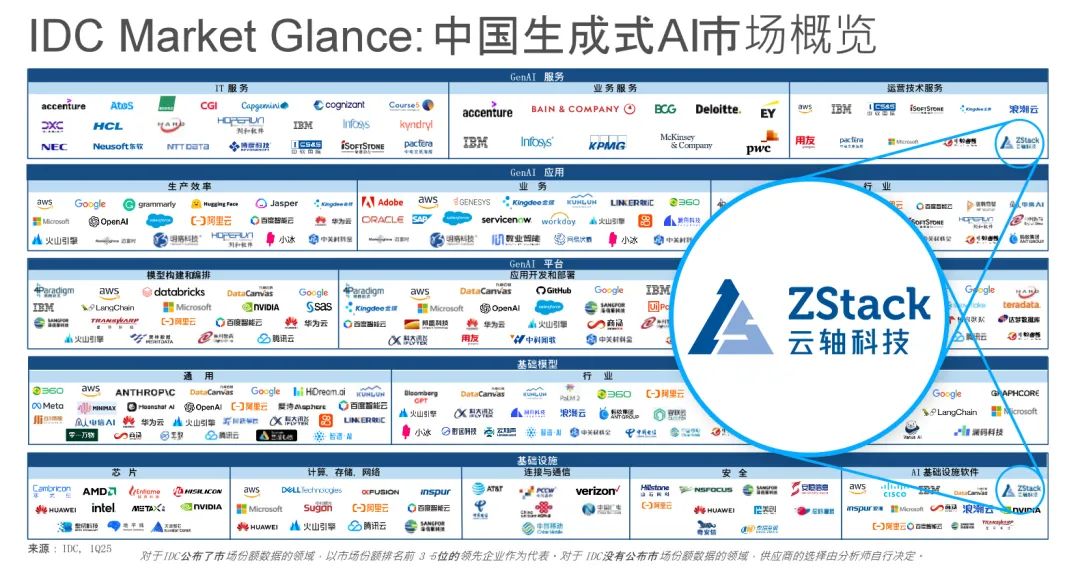
DeepSeek私有化专家 | 云轴科技ZStack入选IDC中国生成式AI市场概览
DeepSeek 火爆全球AI生态圈,并引发企业用户大量私有化部署需求。 国际数据公司IDC近日发文《DeepSeek爆火的背后,大模型/生成式AI市场生态潜在影响引人关注》,认为中国市场DeepSeekAI模型的推出在大模型/生成式AI市场上引起了轰动,…...

linux下软件安装、查找、卸载
目录 常见安装方式有三种: 1.源码安装。 2.rpm安装方式。 3.yum/apt工具级别安装。 对于前两种安装方式,因为软件可能有依赖关系(安装的软件依赖于某些库,而这些库又依赖于某些库,这些都需要手动安装)…...