【C++11】 并发⽀持库

🌈 个人主页:Zfox_
🔥 系列专栏:C++从入门到精通

目录
- 前言:🚀 并发⽀持库
- 一:🔥 thread库
- 二:🔥 this_thread
- 三:🔥 mutex
- 四:🔥 lock_guard
- 五:🔥 unique_lock
- 六:🔥 lock和 try_lock
- 七:🔥 call_once
- 八:🔥 atomic
- 九:🔥 condition_variable
- 十:🔥 共勉
前言:🚀 并发⽀持库
🧑💻 学习本节知识应该在学习了 Linux多线程博客 之后,也就是说我们并不是从零讲解并发相关的库,⽽是默认⼤家已经有进程线程的基础,所以本章节重点讲解库的使⽤,不会讲解进程线程相关的概念及基础知识。
一:🔥 thread库
thread 库⽂档https://zh.cppreference.com/w/cpp/thread/thread 和 https://legacy.cplusplus.com/reference/thread/thread/thread库底层是对各个系统的线程库进⾏封装 ,如 Linux 下的 pthread 库和 Windows下Thread库等,所以 C++11thread库的第⼀个特点是可以跨平台,第⼆个特点是 Linux 和 Windows 下提供的线程库都是⾯向过程的,C++11thread是库⾯向对象的,并且融合了⼀些 C++11 语⾔特点,如右值引⽤的移动语义,可变模板参数等,⽤起来会更好⽤⼀些。- 下⾯线程创建这⾥有 4 个构造函数,⽇常最常⽤的是第 2 个,他⽀持传⼀个可调⽤对象和参数即可,相⽐
pthread_create⽽⾔,这⾥不再局限于只传递函数指针,其次就是参数传递也更⽅便,pthread_create调⽤时,要传递多个参数需要打包成⼀个结构体,传结构体对象的指针过去。 - 另外也可以⽤第 1 个和第 4 个配合来创建线程,我们可以把右值线程对象移动构造或者移动赋值给另⼀个线程对象。
- 第 3 个可以看到线程对象是不⽀持拷⻉的。
join是主线程结束前需要阻塞等待创建的从线程,否则主线程结束,进程就结束了,从线程可能还在运⾏就被强⾏终⽌了。class thread::id是⼀个thread的内部类⽤来表⽰线程id,⽀持⽐较⼤⼩,流插⼊和提取,通过特化 hash仿函数做unordered_map和unordered_set的id等。底层的⻆度看thread本质还是封装各个平台的线程库接⼝。各个平台的线程id表⽰类型不同,所以只能⽤⼀个类来进⾏封装。线程对象可以通过get_id获取线程id,在执⾏体内可以通过this_thread::get_id()获取线程id。
default (1)
thread() noexcept;initialization (2)
template <class Fn, class... Args>
explicit thread (Fn&& fn, Args&&... args);copy [deleted] (3)
thread (const thread&) = delete;
copy [deleted] (3)
thread& operator= (const thread&) = delete;move (4)
thread (thread&& x) noexcept;
move (4)
thread& operator= (thread&& rhs) noexcept;// pthread库
int pthread_create(pthread_t *tidp, const pthread_attr_t *attr, void * (*start_rtn)(void*), void *arg);// windows线程创建API
HANDLE CreateThread(LPSECURITY_ATTRIBUTES lpThreadAttributes, //SDSIZE_T dwStackSize, //initialstacksizeLPTHREAD_START_ROUTINE lpStartAddress, //threadfunctionLPVOID lpParameter, //threadargumentDWORD dwCreationFlags, //creationoptionLPDWORD lpThreadId //threadidentifier
)void join();
#include<iostream>
#include<thread>
#include<vector>
#include<mutex>using namespace std;void Print(int n, int i)
{for (; i < n; i++){cout << this_thread::get_id() << ":" << i << endl;}cout << endl;
}int main()
{thread t1(Print, 10, 0);thread t2(Print, 20, 10);// 获取线程id//cout << t1.get_id() << endl;//cout << t2.get_id() << endl;t1.join();t2.join();// 获取当前运⾏线程idcout << this_thread::get_id() << endl;return 0;
}
二:🔥 this_thread
-
https://legacy.cplusplus.com/reference/thread/this_thread/
-
this_thread是⼀个命名空间,主要封装了线程相关的 4 个全局接⼝函数。 -

-
get_id是当前执⾏线程的线程id。 -
yield是主动让出当前线程的执⾏权,让其他线程先执⾏。此函数的确切⾏为依赖于实现,特别是取决于使⽤中的 OS 调度器机制和系统状态。例如,先进先出实时调度器(Linux的SCHED_FIFO)会挂起当前线程并将它放到准备运⾏的同优先级线程的队列尾,⽽若⽆其他线程在同优先级,则yield⽆效果。 -
sleep_for阻塞当前线程执⾏,⾄少经过指定的sleep_duration。因为调度或资源争议延迟,此函数可能阻塞⻓于sleep_duration。 -
sleep_until阻塞当前线程的执⾏,直⾄抵达指定的sleep_time。函数可能会因为调度或资源纠纷延迟⽽阻塞到sleep_time之后的某个时间点。 -
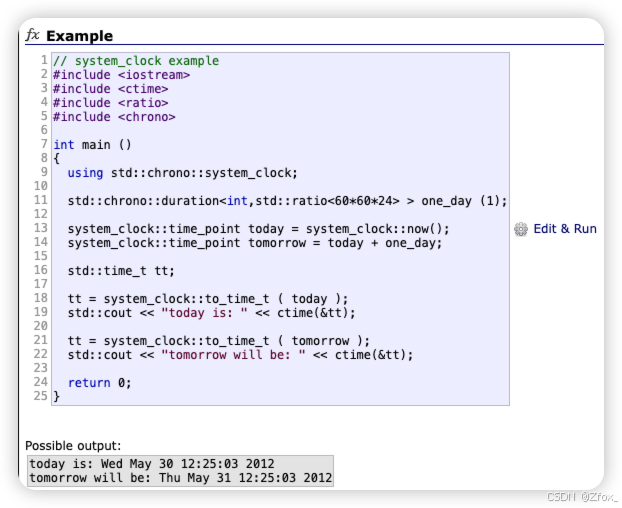
https://legacy.cplusplus.com/reference/chrono/ chrono 是⼀个计时相关的类型。
-
https://legacy.cplusplus.com/reference/chrono/duration/ 是⽤来管理⼀个相对时间段的类。
-
https://legacy.cplusplus.com/reference/chrono/time_point/ 是⽤来管理⼀个绝对时间点的类。
template <class Clock, class Duration>
void sleep_until (const chrono::time_point<Clock, Duration>& abs_time);template <class Rep, class Period>
void sleep_for (const chrono::duration<Rep, Period>& rel_time);
- this_thread::sleep_for example
#include <iostream> // std::cout, std::endl
#include <thread> // std::this_thread::sleep_for
#include <chrono> // std::chrono::secondsint main()
{std::cout << "countdown:\n";for (int i = 10; i > 0; --i) {std::cout << i << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));}std::cout << "Lift off!\n";return 0;
}
- this_thread::sleep_for example*
#include <iostream> // std::cout
#include <iomanip> // std::put_time
#include <thread> // std::this_thread::sleep_until
#include <chrono> // std::chrono::system_clock
#include <ctime> // std::time_t, std::tm, std::localtime, std::mktimeint main()
{using std::chrono::system_clock;std::time_t tt = system_clock::to_time_t(system_clock::now());struct std::tm* ptm = std::localtime(&tt);std::cout << "Current time: " << std::put_time(ptm, "%X") << '\n';std::cout << "Waiting for the next minute to begin...\n";++ptm->tm_min; ptm->tm_sec = 0;std::this_thread::sleep_until(system_clock::from_time_t(mktime(ptm)));std::cout << std::put_time(ptm, "%X") << " reached!\n";return 0;
}
三:🔥 mutex
- https://legacy.cplusplus.com/reference/mutex/
mutex是封装的互斥锁的类,⽤于保护临界区的共享数据。mutex主要提供lock和unlock两个接⼝函数。mutex提供排他性⾮递归所有权语义:- 调⽤⽅线程从它成功调⽤
lock或try_lock开始,到它调⽤unlock为⽌占有mutex。 - 线程占有
mutex时,其他线程如果试图要求mutex的所有权,那么就会阻塞(对于 lock 的调⽤), 对于try_lock就会返回 false 。
- 调⽤⽅线程从它成功调⽤
- 如果
mutex在仍为任何线程所占有时即被销毁,或在占有mutex时线程终⽌,那么⾏为未定义。 - ⽰例1代码 展⽰了
mutex的使⽤,其实如果线程对象传参给可调⽤对象时,使⽤引⽤⽅式传参,实参位置需要加上 ref(obj) 的⽅式,主要原因是 thread 本质还是系统库提供的线程 API 的封装,thread 构造取到参数包以后,要调⽤创建线程的 API,还是需要将参数包打包成⼀个结构体传参过去,那么打包成结构体时,参考包对象就会拷⻉给结构体对象,使⽤ ref 传参的参数,会让结构体中的对应参数成员类型推导为引⽤,这样才能实现引⽤传参,⽰例2代码 截取了 vs2019下 thread 库中的部分源码帮助理解。https://legacy.cplusplus.com/reference/functional/ref/?kw=ref
⽰例1:
#include <iostream>
#include <chrono>
#include <thread>
#include <mutex>using namespace std;void Print(int n, int& rx, mutex& rmtx)
{rmtx.lock();for (int i = 0; i < n; i++){// t1 t2++rx;}rmtx.unlock();
}int main()
{int x = 0;mutex mtx;// 这⾥必须要⽤ref()传参,现成中拿到的才是x和mtx的引⽤,具体原因需要看下⾯thread源码中的分析// httpt2.join();cout << x << endl;return 0;
}int main()
{int x = 0;mutex mtx;// 将上⾯的代码改成使⽤lambda捕获外层的对象,也就可以不⽤传参数,间接解决了上⾯的问题auto Print = [&x, &mtx](size_t n) {mtx.lock();for (size_t i = 0; i < n; i++){++x;}mtx.unlock();};thread t1(Print, 1000000);thread t2(Print, 2000000);t1.join();t2.join();cout << x << endl;return 0;
}
template <class _Fn, class... _Args,enable_if_t<!is_same_v<_Remove_cvref_t<_Fn>, thread>, int> = 0>
_NODISCARD_CTOR explicit thread(_Fn&& _Fx, _Args&&... _Ax) {_Start(_STD forward<_Fn>(_Fx), _STD forward<_Args>(_Ax)...);
}template <class _Fn, class... _Args>
void _Start(_Fn&& _Fx, _Args&&... _Ax) {// 从下⾯可以看到,线程要调⽤系统库的线程,最终还是要把参数包打包成⼀个结构体对象再传给线程,所以线程中拿到的参数包值是我们传的参数包值的拷⻉,所以要⽤ref才传参才能解决问题using _Tuple = tuple<decay_t<_Fn>, decay_t<_Args>...>;auto _Decay_copied = _STD make_unique<_Tuple>(_STD forward<_Fn>(_Fx), _STD forward<_Args>(_Ax)...);constexpr auto _Invoker_proc = _Get_invoke<_Tuple>(make_index_sequence<1 + sizeof...(_Args)>{});// pointer or reference to potentially throwing function passed to// extern C function under -EHc. Undefined behavior may occur// if this function throws an exception. (/Wall)_Thr._Hnd =reinterpret_cast<void*>(_CSTD _beginthreadex(nullptr, 0, _Invoker_proc, _Decay_copied.get(), 0, &_Thr._Id));if (_Thr._Hnd) { // ownership transferred to the thread(void) _Decay_copied.release();} else { // failed to start thread_Thr._Id = 0;_Throw_Cpp_error(_RESOURCE_UNAVAILABLE_TRY_AGAIN);}
}
- time_mutex 跟
mutex完全类似,只是额外提供 try_lock_for 和try_lock_untile 的接⼝,这两个接⼝跟 try_lock 类似,只是他不会⻢上返回,⽽是直接进⼊阻塞,直到时间条件到了或者解锁了就会唤醒试图获取锁资源。 - recursive_mutex 跟
mutex完全类似,recursive_mutex 提供排他性递归所有权语义:- 调⽤⽅线程在从它成功调⽤ lock 或 try_lock 开始的时期⾥占有 recursive_mutex。此时期之内,线程可以进⾏对 lock 或 try_lock 的附加调⽤。所有权的时期在线程进⾏匹配次数的 unlock 调⽤时结束。
- 线程占有 recursive_mutex 时,若其他所有线程试图要求 recursive_mutex 的所有权,则它们将阻塞(对于调⽤ lock)或收到 false 返回值(对于调⽤ try_lock)
timed_mutex::try_lock_for example
#include <iostream> // std::cout
#include <chrono> // std::chrono::milliseconds
#include <thread> // std::thread
#include <mutex> // std::timed_mutexstd::timed_mutex mtx;void fireworks(int i)
{//std::cout << i;// waiting to get a lock: each thread prints "-" every 200ms:while (!mtx.try_lock_for(std::chrono::milliseconds(1000))){std::cout << "-";}std::cout << i;// got a lock! - wait for 1s, then this thread prints "*"std::this_thread::sleep_for(std::chrono::milliseconds(5000));std::cout << "*\n";mtx.unlock();
}int main()
{std::thread threads[2];// 利⽤移动赋值的⽅式,将创建的临时对象(右值对象)移动赋值给创建好的空线程对象for (int i = 0; i < 2; ++i)threads[i] = std::thread(fireworks, i);for (auto& th : threads)th.join();return 0;
}
四:🔥 lock_guard
- 🐳
lock_guard是C++11提供的⽀持RAII⽅式管理互斥锁资源的类,这样可以更有效的防⽌因为异常等原因导致的死锁问题。他们的⼤致原理如下⾯模拟提供的 ⽰例代码1 的LockGuard类似。 - 🐳
lock_guard的功能简单纯粹,仅仅⽀持RAII的⽅式管理锁对象。也可以在构造的时候通过传参adopt_lock_t的adopt_lock对象管理已经lock的锁对象。其次lock_guard类不⽀持拷⻉构造。
⽰例1
#include <iostream>
#include <chrono>
#include <thread>
#include <mutex>using namespace std;template<class Mutex>
class LockGuard
{
public:LockGuard(Mutex& mtx):_mtx(mtx){_mtx.lock();}~LockGuard(){_mtx.unlock();}
private:Mutex& _mtx;
};int main()
{int x = 0;mutex mtx;auto Print = [&x, &mtx](size_t n) {//lock_guard<mutex> lock(mtx);LockGuard<mutex> lock(mtx);//mtx.lock();for (size_t i = 0; i < n; i++){++x;}//mtx.unlock();};thread t1(Print, 1000000);thread t2(Print, 2000000);t1.join();t2.join();cout << x << endl;return 0;
}
locking (1)
explicit lock_guard (mutex_type& m);adopting (2)
lock_guard (mutex_type& m, adopt_lock_t tag);copy [deleted](3)
lock_guard (const lock_guard&) = delete;#include <iostream>
#include <chrono>
#include <thread>
#include <mutex>using namespace std;std::mutex mtx; // mutex for critical sectionvoid print_thread_id(int id)
{mtx.lock();std::lock_guard<std::mutex> lck(mtx, std::adopt_lock);std::cout << "thread #" << id << '\n';
}int main()
{std::thread threads[10];// spawn 10 threads:for (int i = 0; i < 10; ++i)threads[i] = std::thread(print_thread_id, i + 1);for (auto& th : threads) th.join();return 0;
}
📚 在如上代码中:
lock_guard (mutex_type& m, adopt_lock_t tag);
🦅 std::adopt_lock_t 是一个标记类型,用于告诉 std::lock_guard 或 std::unique_lock,锁已经被当前线程持有,不需要再次锁定,而只需要在作用域结束时自动释放锁。
五:🔥 unique_lock
- 🐳
unique_lock也是C++11提供的⽀持RAII⽅式管理互斥锁资源的类,相⽐lock_guard他的功能⽀持更丰富复杂。这是unique_lock的 https://legacy.cplusplus.com/reference/mutex/unique_lock/ - 🦈
unique_lock⾸先在构造的时候传不同的tag,⽤以⽀持在构造的时候不同的⽅式处理锁对象

unique_lock⾸先在构造的时候传时间段和时间点,⽤来管理 time_mutex 系统,构造时调⽤ try_lock_for 和 try_lock_untilunique_lock不⽀持拷⻉和赋值,⽀持移动构造和移动赋值。unique_lock还提供了 lock / try_lock/ unlock 等系列的接⼝等系统的接⼝。unique_lock还可以通过 operator bool 去检查是否 lock 了锁对象。- 可以直接使用 if 判断是否 lock

- 可以直接使用 if 判断是否 lock
default (1)
unique_lock() noexcept;locking (2)
explicit unique_lock (mutex_type& m);try-locking (3)
unique_lock (mutex_type& m, try_to_lock_t tag);deferred (4)
unique_lock (mutex_type& m, defer_lock_t tag) noexcept;adopting (5)
unique_lock (mutex_type& m, adopt_lock_t tag);locking for (6)
template <class Rep, class Period>
unique_lock (mutex_type& m, const chrono::duration<Rep,Period>& rel_time);locking until (7)
template <class Clock, class Duration>
unique_lock (mutex_type& m, const chrono::time_point<Clock,Duration>& abs_time);copy [deleted] (8)
unique_lock (const unique_lock&) = delete;move (9)
unique_lock (unique_lock&& x);
六:🔥 lock和 try_lock
- lock 是⼀个函数模板,可以⽀持对多个锁对象同时锁定,如果其中⼀个锁对象没有锁住,lock 函数会把已经锁定的对象解锁⽽进⼊阻塞,直到锁定所有的所有的对象。
- try_lock 也是⼀个函数模板,尝试对多个锁对象进⾏同时尝试锁定,如果全部锁对象都锁定了,返回 -1,如果某⼀个锁对象尝试锁定失败,把已经锁定成功的锁对象解锁,并则返回这个对象的下标(第⼀个参数对象,下标从1开始算)。
template <class Mutex1, class Mutex2, class... Mutexes>
void lock (Mutex1& a, Mutex2& b, Mutexes&... cde);template <class Mutex1, class Mutex2, class... Mutexes>
int try_lock (Mutex1& a, Mutex2& b, Mutexes&... cde);
// std::lock example
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex, std::lockstd::mutex foo, bar;void task_a() {// foo.lock(); bar.lock(); // replaced by:std::lock(foo, bar);std::cout << "task a\n";foo.unlock();bar.unlock();
}void task_b() {// bar.lock(); foo.lock(); // replaced by:std::lock(bar, foo);std::cout << "task b\n";bar.unlock();foo.unlock();
}int main()
{foo.lock();std::thread th1(task_a);std::thread th2(task_b);std::cout << "xxxxxx" << std::endl;bar.lock();foo.unlock();std::cout << "yyyyyy" << std::endl;bar.unlock();th1.join();th2.join();return 0;
}// std::lock example
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex, std::try_lockstd::mutex foo, bar;void task_a() {foo.lock();std::cout << "task a\n";bar.lock();// ...foo.unlock();bar.unlock();
}void task_b() {int x = try_lock(bar, foo);if (x == -1) {std::cout << "task b\n";// ...bar.unlock();foo.unlock();}else {std::cout << "[task b failed: mutex " << (x ? "foo" : "bar") << " locked]\n";}
}int main()
{std::thread th1(task_a);std::thread th2(task_b);th1.join();th2.join();return 0;
}
七:🔥 call_once
- 多线程执⾏时,让
第⼀个线程执⾏Fn(可执行对象) ⼀次,其他线程不再执⾏Fn
template <class Fn, class... Args>
void call_once (once_flag& flag, Fn&& fn, Args&&... args);
call_once example
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>int winner;
void set_winner (int x) { winner = x; }
std::once_flag winner_flag;void wait_1000ms (int id)
{// count to 1000, waiting 1ms between increments:for (int i=0; i<1000; ++i)std::this_thread::sleep_for(std::chrono::milliseconds(1));// claim to be the winner (only the first such call is executed):std::call_once (winner_flag,set_winner,id);
}int main ()
{std::thread threads[10];// spawn 10 threads:for (int i=0; i<10; ++i)threads[i] = std::thread(wait_1000ms,i+1);std::cout << "waiting for the first among 10 threads to count 1000 ms...\n";for (auto& th : threads) th.join(); std::cout << "winner thread: " << winner << '\n';return 0;
}
🌊 通过以上代码就可以测试出哪个线程跑的最快
八:🔥 atomic
- 🪜
atomic是⼀个模板的实例化和全特化均定义的原⼦类型,他可以保证对⼀个原⼦对象的操作是线程安全的。 atomic对T类型的要求模板可⽤任何满⾜ 可复制构造 (CopyConstructible) 及 可复制赋值 (CopyAssignable) 的可平凡复制 (TriviallyCopyable) 类型 T 实例化,T类型⽤以下⼏个函数判断时,如果⼀个返回 false,则⽤于atomic不是原⼦操作。
std::is_trivially_copyable<T>::value
std::is_copy_constructible<T>::value
std::is_move_constructible<T>::value
std::is_copy_assignable<T>::value
std::is_move_assignable<T>::value
std::is_same<T, typename std::remove_cv<T>::type>::value
-
atomic对于整形和指针⽀持基本加减运算和位运算,具体如下图 :

-
load和store可以原⼦的读取和修改atomic封装存储的T对象。 -
atomic的原理主要是硬件层⾯的⽀持,现代处理器提供了原⼦指令来⽀持原⼦操作。例如,在 x86 架构 中有CMPXCHG(⽐较并交换)指令。这些原⼦指令能够在⼀个不可分割的操作中完成对内存的读取、⽐较和写⼊操作,简称CAS,Compare And Swap。另外为了处理多个处理器缓存之间的数据⼀致性问题,硬件采⽤了缓存⼀致性协议,当⼀个atomic操作修改了⼀个变量的值,缓存⼀致性协议会确保其他处理器缓存中的相同变量副本被正确地更新或标记为⽆效。
📚 具体可以参考下⾯的代码结合理解⼀下。
// gcc⽀持的CAS接⼝
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval);
type __sync_val_compare_and_swap (type *ptr, type oldval type newval);
// Windows⽀持的CAS接⼝
InterlockedCompareExchange ( __inout LONG volatile *Target, __in LONG Exchange, __in LONG Comperand);// C++11⽀持的CAS接⼝
template <class T>
bool atomic_compare_exchange_weak (atomic<T>* obj, T* expected, T val)
noexcept;template <class T>
bool atomic_compare_exchange_strong (atomic<T>* obj, T* expected, T val)
noexcept;// C++11中atomic类的成员函数
bool compare_exchange_weak (T& expected, T val,memory_order sync = memory_order_seq_cst) noexcept;
bool compare_exchange_strong (T& expected, T val,memory_order sync = memory_order_seq_cst) noexcept;
C++11的CAS操作⽀持,atomic对象跟expected按位⽐较相等,则⽤ val 更新atomic对象并返回值 true;若atomic对象跟expected按位⽐较不相等,则更新expected为当前的atomic对象并返回值 falsecompare_exchange_weak在某些平台上,即使原⼦变量的值等于expected,也可能“虚假地”失败(即返回 false)。这种失败是由于底层硬件或编译器优化导致的,但不会改变原⼦变量的。compare_exchange_strong保证在原⼦变量的值等于 expected 时不会虚假地失败。只要原⼦变量的值等于 expected,操作就会成功。compare_exchange_weak在某些平台上可能⽐compare_exchange_strong更快。compare_exchange_weak可能会虚假的失败主要是由于硬件层间的缓存⼀致性和编译器优化等等,compare_exchange_strong要避免这些原因就要付出⼀定的代价,⽐如要使⽤硬件的缓存⼀致性协议(如 MESI 协议)。- 关于 CPU 缓存的⼀些相关知识,这⾥我们贴⼀篇陈皓⼤佬的博客,有兴趣的可以扩展了解⼀下, 与程序员相关的 CPU 缓存知识 | 酷 壳 - CoolShell
- 关于⽆锁编程的⼀些知识,这⾥我们也再贴⼀篇陈皓⼤佬的博客,有兴趣的可以扩展了解⼀下,⽆锁队列的实现 | 酷 壳 - CoolShell
- 在
C++11标准库中,std::atomic提供了多种内存顺序(memory_order)选项,⽤于控制原⼦操作的内存同步⾏为。这些内存顺序选项允许开发者在性能与正确性之间进⾏权衡,特别是在多线程编程中。以下是std::atomic⽀持的六种内存顺序选项:
memory_order_relaxed最宽松的内存顺序,仅保证原⼦操作的原⼦性,不提供任何同步或顺序约束。使⽤场景:适⽤于不需要同步的场景,例如计数器或统计信息。
std::atomic<int> x(0);
x.store(42, std::memory_order_relaxed); // 仅保证原⼦性
memory_order_consume限制较弱的内存顺序,仅保证依赖于当前加载操作的数据的可⻅性。通常⽤于数据依赖的场景。使⽤场景:适⽤于某些特定的依赖链场景,但实际使⽤较少。
std::atomic<int*> ptr(nullptr);
int* p = ptr.load(std::memory_order_consume);
if (p) {int value = *p; // 保证 p 指向的数据是可⻅的
}
memory_order_acquire保证当前操作之前的所有读写操作(在当前线程中)不会被重排序到当前操作之后。通常⽤于加载操作。使⽤场景:⽤于实现锁或同步机制中的 “获取” 操作
std::atomic<bool> flag(false);
int data = 0;// 线程 1
data = 42;
flag.store(true, std::memory_order_release);// 线程 2
while (!flag.load(std::memory_order_acquire)) {}
std::cout << data; // 保证看到 data = 42
memory_order_release保证当前操作之后的所有读写操作(在当前线程中)不会被重排序到当前操作之前。通常⽤于存储操作。使⽤场景:⽤于实现锁或同步机制中的 “释放” 操作。
std::atomic<bool> flag(false);
int data = 0// 线程 1
data = 42;
flag.store(true, std::memory_order_release); // 保证 data = 42 在 flag = true 之前可⻅// 线程 2
while (!flag.load(std::memory_order_acquire)) {}
std::cout << data; // 保证看到 data = 42
memory_order_acq_rel结合了memory_order_acquire和memory_order_release的语义。适⽤于读-修改-写操作(如fetch_add或compare_exchange_strong)。使⽤场景:⽤于需要同时实现“获取”和“释放”语义的操作。
std::atomic<int> x(0);
x.fetch_add(1, std::memory_order_acq_rel); // 保证前后的操作不会被重排序
memory_order_seq_cst最严格的内存顺序,保证所有线程看到的操作顺序是⼀致的(全局顺序⼀致性)。默认的内存顺序。使⽤场景:适⽤于需要强⼀致性的场景,但性能开销较⼤。
std::atomic<int> x(0);
x.store(42, std::memory_order_seq_cst); // 全局顺序⼀致性
int value = x.load(std::memory_order_seq_cst);
内存顺序的关系, 宽松到严格:memory_order_relaxed < memory_order_consume < memory_order_acquire < memory_order_release < memory_order_acq_rel < memory_order_seq_cst 。宽松的内存顺序(如 memory_order_relaxed )性能最好,但同步语义最弱。严格的内存顺序(如 memory_order_seq_cst )性能最差,但同步语义最强。
- 总结⼀下,根据具体需求选择合适的内存顺序,可以在保证正确性的同时最⼤化性能。

atomic_flag是⼀种原⼦布尔类型。与所有atomic的特化不同,它保证是免锁的。与atomic<bool>不同,atomic_flag不提供加载或存储操作。主要提供test_and_set操作将flag原⼦的设置为true并返回之前的值,clear原⼦将flag设置为false。下⾯⼀个样例演⽰了⽤atomic_flag实现⾃旋锁。
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>using namespace std;atomic<int> acnt;
// atomic_int acnt;
int cnt;// 原子++如何实现?
void Add1(atomic<int>& cnt)
{int old = cnt.load();// 如果cnt的值跟old相等,则将cnt的值设置为old+1,并且返回true,这组操作是原子的// 那么如果在1oad和compare exchange_weak操作之间cnt对象被其他线程改了// 则old和cnt不相等,则将old的值改为cnt的值,并目返回false。while (!atomic_compare_exchange_weak(&cnt, &old, old + 1));// while(!cnt.compare_exchange_weak(old,old + 1));
}void f()
{for (int n = 0; n < 100000; ++n){// ++acnt;// Add1的用 CAS 模拟atomic的operator++原子操作 结果是一样的Add1(acnt);++cnt;}
}int main()
{std::vector<thread> pool;for (int i = 0; i < 4; i++){pool.emplace_back(f);}for (auto& e : pool){e.join();}cout << "原子计数器为: " << acnt << '\n' << "非原子计数器为: " << cnt << '\n';return 0;
}
struct Date
{int _year = 1;int _month = 1;int _day = 1;
};template<class T>
void check()
{cout << typeid(T).name() << endl;cout << std::is_trivially_copyable<T>::value << endl;cout << std::is_copy_constructible<T>::value << endl;cout << std::is_move_constructible<T>::value << endl;cout << std::is_copy_assignable<T>::value << endl;cout << std::is_move_assignable<T>::value << endl;cout << std::is_same<T, typename std::remove_cv<T>::type>::value << endl << endl;
}int main()
{check<int>();check<double>();check<int*>();check<Date>();check<Date*>();check<string>();check<string*>();return 0;
}
⾃旋锁(SpinLock)
#include <atomic>
#include <thread>
#include <iostream>
#include <vector>// ⾃旋锁(SpinLock)是⼀种忙等待的锁机制,适⽤于锁持有时间⾮常短的场景。
// 在多线程编程中,当⼀个线程尝试获取已被其他线程持有的锁时,⾃旋锁会让该
// 线程在循环中不断检查锁是否可⽤,⽽不是进⼊睡眠状态。这种⽅式可以减少上
// 下⽂切换的开销,但在锁竞争激烈或锁持有时间较⻓的情况下,会导致CPU资源的浪费。
// 以下是使⽤C++11实现的⼀个简单⾃旋锁⽰例:
class SpinLock
{
private:// ATOMIC_FLAG_INIT默认初始化为falsestd::atomic_flag flag = ATOMIC_FLAG_INIT;
public:void lock(){// test_and_set将内部值设置为true,并且返回之前的值// 第⼀个进来的线程将值原⼦的设置为true,返回false// 后⾯进来的线程将原⼦的值设置为true,返回true,所以卡在这⾥空转,// 直到第⼀个进去的线程unlock,clear,将值设置为falsewhile (flag.test_and_set(std::memory_order_acquire));}void unlock(){// clear将值原⼦的设置为falseflag.clear(std::memory_order_release);}
};// 测试⾃旋锁
void worker(SpinLock& lock, int& sharedValue) {lock.lock();// 模拟⼀些⼯作for (int i = 0; i < 1000000; ++i) {++sharedValue;}lock.unlock();
}int main()
{SpinLock lock;int sharedValue = 0;std::vector<std::thread> threads;// 创建多个线程for (int i = 0; i < 4; ++i) {threads.emplace_back(worker, std::ref(lock), std::ref(sharedValue));}// 等待所有线程完成for (auto& thread : threads) {thread.join();}std::cout << "Final shared value: " << sharedValue << std::endl;return 0;
}
九:🔥 condition_variable
- 🪜
condition_variable需要配合互斥锁系列进⾏使⽤,主要提供wait和notify系统接⼝。 wait需要传递⼀个unique_lock<mutex>类型的互斥锁,wait会阻塞当前线程直到被notify。在进⼊阻塞的⼀瞬间,会解开互斥锁,⽅便其他线程获取锁,访问条件变量。当被notify唤醒时,他会同时获取到锁,再继续往下运⾏。notify_one会唤醒当前条件变量上等待的其中⼀个线程,使⽤时他也需要⽤互斥锁保护,如果没有现成阻塞等待,他啥事都不做;notify_all会唤醒当前条件变量上等待的所有线程线程。condition_variable_any类是std::condition_variable的泛化。相对于只在std::unique_lock<std::mutex>上⼯作的std::condition_variable,condition_variable_any能在任何满⾜可基本锁定(BasicLockable)要求的锁上⼯作。
condition_variable::notify_all
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex, std::unique_lock
#include <condition_variable> // std::condition_variablestd::mutex mtx;
std::condition_variable cv;
bool ready = false;void print_id(int id)
{std::unique_lock<std::mutex> lck(mtx);while (!ready)cv.wait(lck);// ...std::cout << "thread " << id << '\n';
}void go()
{std::unique_lock<std::mutex> lck(mtx);ready = true;// 通知所有阻塞在条件变量上的线程cv.notify_all();
}int main()
{std::thread threads[10];// spawn 10 threads:for (int i = 0; i < 10; ++i)threads[i] = std::thread(print_id, i);std::cout << "10 threads ready to race...\n";std::this_thread::sleep_for(std::chrono::milliseconds(100));go(); // go!for (auto& th : threads)th.join();return 0;
}
- 下⾯演⽰⼀个经典问题,两个线程交替打印奇数和偶数
🧐 分析通过条件变量和锁是如何保证交替打印的
情况1:t1 先启动,t2 过了⼀会才启动(未启动或者还在排队)
- t1 启动以后先获取锁,flag 是 true 不会被条件变量阻塞,打印 i 为 0,flag 修改为 false,i 修改为 2,再⽤条件变量唤醒其他阻塞线程,但是没有线程等待,循环再继续,再次获取锁,flag 刚修改为 false 了,这时会阻塞在条件变量上,并且解锁,这⾥的逻辑保证了 t1 不会连续打印。
- t2 这时开始运⾏,先获取锁,flag 被t1修改为false了所以t2不会被条件变量阻塞,t1 打印 j 为1, flag 修改为 true,j 修改为3,再⽤条件变量唤醒其他阻塞线程,t1 被唤醒。那么这⾥ t1 被唤醒以后,也是需要分配时间⽚排队执⾏,这时有 2 种情况,第⼀种 t1 没有⽴即执⾏,t2 继续执⾏,t2 获取锁,但是 flag 为 true,所以阻塞在条件变量并且解锁,过⼀会 t1 开始执⾏了,flag 为 true 不会被条件变量继续阻塞,打印 2,继续上述循环逻辑,就交替打印了。第⼆种 t1 ⽴即执⾏,t1 抢占到锁,flag 为 true 不会被条件变量继续阻塞,打印 2,i 修改为 4,flag 修改为 false,再⽤条件变量唤醒其他阻塞线程,但是没有线程被阻塞,再继续循环逻辑就是 t1 和 t2 新⼀轮谁先执⾏或者抢到锁资源的逻辑了,这样也实现了交替打印。
**情况2:t2 先启动,t1 过了⼀会才启动(未启动或者还在排队)
- t2 启动以后先获取锁,flag 是 true 会被条件变量阻塞,并且同时解锁。
- ⼀会后,t1 开始运⾏,获取到锁资源,flag 是 true 不会被条件变量阻塞,打印 i 为 0,flag 修改为 false,i 修改为 2,再⽤条件变量唤醒阻塞线程t2。跟上⾯类似,t2 被唤醒以后也是需要分配时间⽚排队执⾏,这时有 2种情况,第⼀种 t2 没有⽴即执⾏,t1 继续执⾏循环,获取锁,但是 flag 为 false,所以阻塞在条件变量并且解锁。过⼀会 t2 开始执⾏了,flag 为 false不会被条件变量继续阻塞,打印 1,j 修改为 3,flag 修改为 true,唤醒阻塞线程t1,这时跟上述逻辑类似,循环往复,就可以实现交替打印了。第⼆种t2 ⽴即执⾏,t2 抢到锁,flag 为 false 不会被条件变量继续阻塞,打印 1,j修改为 3,flag 修改为 true,唤醒其他阻塞线程,这会没有线程被其他条件变量阻塞,再继续循环逻辑就是 t1 和 t2 新⼀轮谁先执⾏或者抢到锁资源的逻辑了,这样也实现了交替打印。
**情况3:t1 和 t2 ⼏乎同时启动
- 这种情况,本质就是两个线程抢夺先锁资源,t1 先抢到就类似 情况1, t2 先抢到就类似 情况2,这⾥就不再细节分析了。
下⾯演⽰⼀个经典问题,两个线程交替打印奇数和偶数
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex, std::unique_lock
#include <condition_variable> // std::condition_variableusing namespace std;int main()
{std::mutex mtx;condition_variable c;int n = 100;bool flag = true;// 第⼀个打印的是t1打印0thread t1([&]() {int i = 0;while (i < n){unique_lock<mutex> lock(mtx);// flag == false t1⼀直阻塞// flag == true t1不会阻塞while (!flag){c.wait(lock);}cout << i << endl;flag = false;i += 2; // 偶数c.notify_one();}});// this_thread::sleep_for(std::chrono::milliseconds(3000));thread t2([&]() {int j = 1;while (j < n){unique_lock<mutex> lock(mtx);// 只要flag == true t2⼀直阻塞// 只要flag == false t2不会阻塞while (flag)c.wait(lock);cout << j << endl;j += 2; // 奇数flag = true;c.notify_one();}});t1.join();t2.join();return 0;
}十:🔥 共勉
😋 以上就是我对 C++11 并发⽀持库 的理解, 觉得这篇博客对你有帮助的,可以点赞收藏关注支持一波~ 😉

相关文章:
【C++11】 并发⽀持库
🌈 个人主页:Zfox_ 🔥 系列专栏:C从入门到精通 目录 前言:🚀 并发⽀持库一:🔥 thread库 二:🔥 this_thread 三:🔥 mutex 四࿱…...

Windows 11【1001问】如何下载Windows 11系统镜像
随着科技的不断进步,操作系统也在不断地更新换代。Windows 11作为微软最新一代的操作系统,带来了许多令人兴奋的新特性与改进,如全新的用户界面、更好的性能优化以及增强的安全功能等。对于想要体验最新技术或者提升工作效率的用户来说&#…...

视觉分析之边缘检测算法
9.1 Roberts算子 Roberts算子又称为交叉微分算法,是基于交叉差分的梯度算法,通过局部差分计算检测边缘线条。 常用来处理具有陡峭的低噪声图像,当图像边缘接近于正45度或负45度时,该算法处理效果更理想。 其缺点是对边缘的定位…...

蓝桥杯 2013 省 B 翻硬币
题目背景 小明正在玩一个“翻硬币”的游戏。 题目描述 桌上放着排成一排的若干硬币。我们用 * 表示正面,用 o 表示反面(是小写字母,不是零),比如可能情形是 **oo***oooo,如果同时翻转左边的两个硬币&…...

深度学习-6.用于计算机视觉的深度学习
Deep Learning - Lecture 6 Deep Learning for Computer Vision 简介深度学习在计算机视觉领域的发展时间线 语义分割语义分割系统的类型上采样层语义分割的 SegNet 架构软件中的SegNet 架构数据标注 目标检测与识别目标检测与识别问题两阶段和一阶段目标检测与识别两阶段检测器…...

【大模型】蓝耘智算云平台快速部署DeepSeek R1/R3大模型详解
目录 一、前言 二、蓝耘智算平台介绍 2.1 蓝耘智算平台是什么 2.2 平台优势 2.3 应用场景 2.4 对DeepSeek 的支持 2.4.1 DeepSeek 简介 2.4.2 DeepSeek 优势 三、蓝耘智算平台部署DeepSeek-R1操作过程 3.1 注册账号 3.1.1 余额检查 3.2 部署DeepSeek-R1 3.2.1 获取…...

《计算机视觉》——图像拼接
图像拼接 图像拼接是将多幅有重叠区域的图像合并成一幅全景或更大视角图像的技术,以下为你详细介绍: 原理:图像拼接的核心原理是基于图像之间的特征匹配。首先,从每幅图像中提取独特的特征点,如角点、边缘点等&#x…...

Go入门之接口
type Usber interface {start()stop() } type Phone struct {Name string }func (p Phone) start() {fmt.Println(p.Name, "启动") } func (p Phone) stop() {fmt.Println(p.Name, "关机") } func main() {p : Phone{Name: "华为手机",}var p1 U…...

element实现需同时满足多行合并和展开的表格
element实现需同时满足多行合并和展开的表格 需求描述: 以下面这张图为例,此表格的“一级表格”这一行可能存在多行数据,这种情况下需要将“一级指标”,“一级指标扣分xxx”,“一级指标关联xxx”这三列数据的行展示根据后面数据(…...

气象干旱触发水文(农业)干旱的概率及其触发阈值的动态变化-贝叶斯copula模型
前言 在干旱研究中,一个关键的科学问题是:在某一地区发生不同等级的气象干旱时,气象干旱会以何种概率引发不同等级的水文干旱、农业干旱和地下水干旱?换句话说,气象干旱的不同程度会分别引发其他类型干旱的哪种等级&a…...

系统学习算法:专题十二 记忆化搜索
什么是记忆化搜索,我们先用一道经典例题来引入,斐波那契数 题目一: 相信一开始学编程语言的时候,就一定碰到过这道题,在学循环的时候,我们就用for循环来解决,然后学到了递归,我们又…...

c++入门-------命名空间、缺省参数、函数重载
C系列 文章目录 C系列前言一、命名空间二、缺省参数2.1、缺省参数概念2.2、 缺省参数分类2.2.1、全缺省参数2.2.2、半缺省参数 2.3、缺省参数的特点 三、函数重载3.1、函数重载概念3.2、构成函数重载的条件3.2.1、参数类型不同3.2.2、参数个数不同3.2.3、参数类型顺序不同 前言…...

豆包、扣子等产品如何与CSDN合作?
要实现CSDN开发者社区与豆包、扣子等产品的深度合作,构建创作者Agent生态体系,可通过以下结构化方案实现技术、生态与商业价值的闭环(含具体实施路径与数据指标): 一、战略合作框架搭建 开放平台互通 建立三方API网关&…...

51单片机测试题AI作答测试(DeepSeek Kimi)
单片机测试题 DeepSeek Kimi 单项选择题 (10道) 6题8题判断有误 6题判断有误 智谱清言6题靠谱,但仔细斟酌,题目出的貌似有问题,详见 下方。 填空题 (9道) 脉宽调制(Pulse …...

Java实际上只有值传递
在 Java 中,实际上只有值传递,这可以从基本数据类型和引用数据类型两个方面来看。 基本概念 值传递:指在方法调用时,将实际参数的值复制一份传递给形式参数,在方法内部对形式参数的修改不会影响到实际参数。引用传递…...

解析HTML时需要注意什么?
在使用PHP爬虫解析HTML内容时,需要注意以下几个关键点,以确保数据提取的准确性和程序的稳定性。以下是一些重要的注意事项和最佳实践: 1. 选择合适的解析工具 PHP提供了多种工具来解析HTML,但选择合适的工具可以简化开发过程并提…...

去耦电容的作用详解
在霍尔元件的实际应用过程中,经常会用到去耦电容。去耦电容是电路中装设在元件的电源端的电容,其作用详解如下: 一、基本概念 去耦电容,也称退耦电容,是把输出信号的干扰作为滤除对象。它通常安装在集成电路…...

2024-2025 学年广东省职业院校技能大赛 “信息安全管理与评估”赛项 技能测试试卷(二)
2024-2025 学年广东省职业院校技能大赛 “信息安全管理与评估”赛项 技能测试试卷(二) 第一部分:网络平台搭建与设备安全防护任务书第二部分:网络安全事件响应、数字取证调查、应用程序安全任务书任务 1:应急响应&…...

深入剖析:基于红黑树实现自定义 map 和 set 容器
🌟 快来参与讨论💬,点赞👍、收藏⭐、分享📤,共创活力社区。🌟 在 C 标准模板库(STL)的大家庭里,map和set可是超级重要的关联容器成员呢😎&#x…...

20-R 绘图 - 饼图
R 绘图 - 饼图 R 语言提供来大量的库来实现绘图功能。 饼图,或称饼状图,是一个划分为几个扇形的圆形统计图表,用于描述量、频率或百分比之间的相对关系。 R 语言使用 pie() 函数来实现饼图,语法格式如下: pie(x, l…...

第438场周赛:判断操作后字符串中的数字是否相等、提取至多 K 个元素的最大总和、判断操作后字符串中的数字是否相等 Ⅱ、正方形上的点之间的最大距离
Q1、判断操作后字符串中的数字是否相等 1、题目描述 给你一个由数字组成的字符串 s 。重复执行以下操作,直到字符串恰好包含 两个 数字: 从第一个数字开始,对于 s 中的每一对连续数字,计算这两个数字的和 模 10。用计算得到的新…...

STM32F4 adc扫描模式采集实验
做adc采集的时候用扫描模式发现读数据时只能读到一个通道的数据,想显示其他几个通道的数据只能进行多次单个扫描,违背了扫描模式的本意,故用ai做了一个将扫描数据用dma储存在内存的adc三通道采集实验,若有巨佬发现有错望告知。 代…...

软考教材重点内容 信息安全工程师 第17章 网络安全应急响应技术原理与应用
17.1 网络安全应急响应概述 网络安全应急响应是针对潜在发生的网络安全事件而采取的网络安全措施。 17.1.1 网络安全应急响应概念 网络安全应急响应是指为应对网络安全事件,相关人员或组织机构对网络安全事件进行监测、预警、分析、响应和恢复等工作。 17.2.3 网络安…...

点击修改按钮图片显示有问题
问题可能出在表单数据的初始化上。在 ave-form.vue 中,我们需要处理一下从后端返回的图片数据,因为它们可能是 JSON 字符串格式。 vue:src/views/tools/fake-strategy/components/ave-form.vue// ... existing code ...Watch(value)watchValue(v: any) …...

Node.js技术原理分析系列——Node.js的perf_hooks模块作用和用法
Node.js 是一个开源的、跨平台的 JavaScript 运行时环境,它允许开发者在服务器端运行 JavaScript 代码。Node.js 是基于 Chrome V8 引擎构建的,专为高性能、高并发的网络应用而设计,广泛应用于构建服务器端应用程序、网络应用、命令行工具等。…...

大模型在术后认知功能障碍预测及临床方案制定中的应用研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与方法 1.3 研究创新点 二、术后认知功能障碍概述 2.1 定义与表现 2.2 危害与影响 2.3 发病机制与相关因素 三、大模型技术原理与应用现状 3.1 大模型技术原理 3.2 大模型在医疗领域的应用 四、基于大模型的术后认知…...

用DeepSeek来帮助学习three.js加载3D太极模形
画一个平面的太极图是很容易,要实现3D的应该会很难 一、参考3D模形效果 看某网页看到一个效果,像一个3D太极球,觉得挺有趣,挺解压的,想进一步去了解下这是如何实现 效果: 链接地址: http://www.…...

【JavaEE进阶】Spring Boot配置文件
欢迎关注个人主页:逸狼 创造不易,可以点点赞吗 如有错误,欢迎指出~ 目录 SpringBoot配置⽂件 举例: 通过配置文件修改端口号 配置⽂件的格式 properties基本语法 读取配置⽂件 properties配置文件的缺点 yml配置⽂件 yml基本语法 yml和proper…...

学习通用多层次市场非理性因素以提升股票收益预测
“Learning Universal Multi-level Market Irrationality Factors to Improve Stock Return Forecasting” 论文地址:https://arxiv.org/pdf/2502.04737 Github地址:https://github.com/lIcIIl/UMI 摘要 深度学习技术与量化交易相结合,在股…...

【Godot4.3】基于绘图函数的矢量蒙版效果与UV换算
概述 在设计圆角容器时突发奇想: 将圆角矩形的每个顶点坐标除以对应圆角矩形所在Rect2的size,就得到了顶点对应的UV坐标。然后使用draw_colored_polygon,便可以做到用图片填充圆角矩形的效果。而且这种计算的效果就是图片随着其填充的图像缩…...