Fisher信息矩阵与Hessian矩阵:区别与联系全解析
Fisher信息矩阵与Hessian矩阵:区别与联系全解析
在统计学和机器学习中,Fisher信息矩阵(FIM)和Hessian矩阵是两个经常出现的概念,它们都与“二阶信息”有关,常用来描述函数的曲率或参数的敏感性。你可能听说过,Fisher信息矩阵可以定义为对数似然函数二阶导数的负期望值,看起来很像Hessian矩阵的某种形式。那么,这两者到底有什么区别,又有哪些联系呢?今天我们就来一探究竟。
Fisher信息矩阵是什么?
Fisher信息矩阵是统计学中的一个核心工具,用来衡量概率分布 ( p ( x ∣ θ ) p(x|\theta) p(x∣θ) ) 中包含的参数 ( θ \theta θ ) 的信息量。它有两种等价定义:
-
基于得分函数(Score Function):
I ( θ ) i j = E [ ∂ log p ( x ∣ θ ) ∂ θ i ∂ log p ( x ∣ θ ) ∂ θ j ∣ θ ] I(\theta)_{ij} = E\left[ \frac{\partial \log p(x|\theta)}{\partial \theta_i} \frac{\partial \log p(x|\theta)}{\partial \theta_j} \bigg| \theta \right] I(θ)ij=E[∂θi∂logp(x∣θ)∂θj∂logp(x∣θ) θ]
这是得分函数的协方差,反映了参数变化引起的似然波动。 -
基于二阶导数:
I ( θ ) i j = − E [ ∂ 2 log p ( x ∣ θ ) ∂ θ i ∂ θ j ∣ θ ] I(\theta)_{ij} = -E\left[ \frac{\partial^2 \log p(x|\theta)}{\partial \theta_i \partial \theta_j} \bigg| \theta \right] I(θ)ij=−E[∂θi∂θj∂2logp(x∣θ) θ]
这是对数似然函数二阶偏导数的负期望值。
这两种定义在正则条件下(比如可微性和积分交换性)是等价的,我们稍后会证明。
通俗理解
Fisher信息矩阵像一个“信息探测器”,告诉你通过数据能了解多少关于 ( θ \theta θ ) 的知识。它是期望值,代表分布的平均特性。
Hessian矩阵是什么?
Hessian矩阵则是一个更广义的概念,出现在数学和优化领域。对于任意函数 ( f ( θ ) f(\theta) f(θ) ),Hessian矩阵 ( H ( θ ) H(\theta) H(θ) ) 定义为:
H ( θ ) i j = ∂ 2 f ( θ ) ∂ θ i ∂ θ j H(\theta)_{ij} = \frac{\partial^2 f(\theta)}{\partial \theta_i \partial \theta_j} H(θ)ij=∂θi∂θj∂2f(θ)
在统计学或机器学习中,如果 ( f ( θ ) = − log p ( x ∣ θ ) f(\theta) = -\log p(x|\theta) f(θ)=−logp(x∣θ) )(负对数似然,作为损失函数),Hessian就是:
H ( θ ) i j = − ∂ 2 log p ( x ∣ θ ) ∂ θ i ∂ θ j H(\theta)_{ij} = -\frac{\partial^2 \log p(x|\theta)}{\partial \theta_i \partial \theta_j} H(θ)ij=−∂θi∂θj∂2logp(x∣θ)
注意,这里的Hessian是一个具体的数据函数,依赖于观测值 ( x x x )。
通俗理解
Hessian矩阵像一张“曲率地图”,告诉你函数在某一点的凹凸性或变化速度。在优化中(如牛顿法),它直接用来调整步长。
Fisher信息矩阵与Hessian的联系
从定义上看,Fisher信息矩阵和Hessian矩阵似乎很像,尤其是Fisher的二阶导数定义:
I ( θ ) i j = − E [ ∂ 2 log p ( x ∣ θ ) ∂ θ i ∂ θ j ∣ θ ] I(\theta)_{ij} = -E\left[ \frac{\partial^2 \log p(x|\theta)}{\partial \theta_i \partial \theta_j} \bigg| \theta \right] I(θ)ij=−E[∂θi∂θj∂2logp(x∣θ) θ]
而Hessian是:
H ( θ ) i j = − ∂ 2 log p ( x ∣ θ ) ∂ θ i ∂ θ j H(\theta)_{ij} = -\frac{\partial^2 \log p(x|\theta)}{\partial \theta_i \partial \theta_j} H(θ)ij=−∂θi∂θj∂2logp(x∣θ)
它们的联系显而易见:Fisher信息矩阵是Hessian矩阵在真实参数 ( θ \theta θ ) 下的期望值。换句话说,Fisher取了Hessian的平均,抹去了单个数据的随机性,反映了分布的整体特性。
证明两种定义的等价性
为什么 ( I ( θ ) i j = E [ s i s j ] = − E [ ∂ 2 log p ∂ θ i ∂ θ j ] I(\theta)_{ij} = E\left[ s_i s_j \right] = -E\left[ \frac{\partial^2 \log p}{\partial \theta_i \partial \theta_j} \right] I(θ)ij=E[sisj]=−E[∂θi∂θj∂2logp] )?我们来推导一下:
得分函数 ( s i = ∂ log p ∂ θ i s_i = \frac{\partial \log p}{\partial \theta_i} si=∂θi∂logp ),其二阶导数为:
∂ s i ∂ θ j = ∂ 2 log p ∂ θ i ∂ θ j \frac{\partial s_i}{\partial \theta_j} = \frac{\partial^2 \log p}{\partial \theta_i \partial \theta_j} ∂θj∂si=∂θi∂θj∂2logp
计算得分函数的协方差:
I ( θ ) i j = E [ s i s j ] I(\theta)_{ij} = E[s_i s_j] I(θ)ij=E[sisj]
考虑 ( E [ s i ] = 0 E[s_i] = 0 E[si]=0 )(得分函数期望为零,请参考笔者的另一篇博客:统计学中的得分函数(Score Function)是什么?它和Fisher信息矩阵有什么关系?),我们对 ( s i s_i si ) 求偏导的期望:
E [ ∂ s i ∂ θ j ] = E [ ∂ 2 log p ∂ θ i ∂ θ j ] E\left[ \frac{\partial s_i}{\partial \theta_j} \right] = E\left[ \frac{\partial^2 \log p}{\partial \theta_i \partial \theta_j} \right] E[∂θj∂si]=E[∂θi∂θj∂2logp]
另一方面:
∂ s i ∂ θ j = ∂ ∂ θ j ( 1 p ∂ p ∂ θ i ) = − 1 p 2 ∂ p ∂ θ j ∂ p ∂ θ i + 1 p ∂ 2 p ∂ θ i ∂ θ j \frac{\partial s_i}{\partial \theta_j} = \frac{\partial}{\partial \theta_j} \left( \frac{1}{p} \frac{\partial p}{\partial \theta_i} \right) = -\frac{1}{p^2} \frac{\partial p}{\partial \theta_j} \frac{\partial p}{\partial \theta_i} + \frac{1}{p} \frac{\partial^2 p}{\partial \theta_i \partial \theta_j} ∂θj∂si=∂θj∂(p1∂θi∂p)=−p21∂θj∂p∂θi∂p+p1∂θi∂θj∂2p
= − s i s j + ∂ 2 log p ∂ θ i ∂ θ j = -s_i s_j + \frac{\partial^2 \log p}{\partial \theta_i \partial \theta_j} =−sisj+∂θi∂θj∂2logp
取期望:
E [ ∂ 2 log p ∂ θ i ∂ θ j ] = E [ s i s j ] + E [ ∂ s i ∂ θ j ] E\left[ \frac{\partial^2 \log p}{\partial \theta_i \partial \theta_j} \right] = E[s_i s_j] + E\left[ \frac{\partial s_i}{\partial \theta_j} \right] E[∂θi∂θj∂2logp]=E[sisj]+E[∂θj∂si]
由于 ( E [ s i ] = 0 E[s_i] = 0 E[si]=0 ),且在正则条件下可以交换积分和导数:
E [ ∂ s i ∂ θ j ] = ∂ ∂ θ j E [ s i ] = 0 E\left[ \frac{\partial s_i}{\partial \theta_j} \right] = \frac{\partial}{\partial \theta_j} E[s_i] = 0 E[∂θj∂si]=∂θj∂E[si]=0
所以:
E [ ∂ 2 log p ∂ θ i ∂ θ j ] = E [ s i s j ] E\left[ \frac{\partial^2 \log p}{\partial \theta_i \partial \theta_j} \right] = E[s_i s_j] E[∂θi∂θj∂2logp]=E[sisj]
取负号:
I ( θ ) i j = E [ s i s j ] = − E [ ∂ 2 log p ∂ θ i ∂ θ j ] I(\theta)_{ij} = E[s_i s_j] = -E\left[ \frac{\partial^2 \log p}{\partial \theta_i \partial \theta_j} \right] I(θ)ij=E[sisj]=−E[∂θi∂θj∂2logp]
这证明了两种定义的等价性。
Fisher信息矩阵与Hessian的区别
尽管有联系,两者在使用和性质上有显著差别:
1. 定义基础
- Fisher信息矩阵:基于概率分布 ( p ( x ∣ θ ) p(x|\theta) p(x∣θ) ),是期望值,反映分布的统计特性。
- Hessian矩阵:基于具体函数(比如 ( − log p ( x ∣ θ ) -\log p(x|\theta) −logp(x∣θ) )),依赖特定数据 ( x x x ),是瞬时值。
2. 随机性
- Fisher:取了期望,消除了数据的随机波动,是理论上的平均曲率。
- Hessian:直接计算某次观测的二阶导数,受数据噪声影响,可能不稳定。
3. 应用场景
- Fisher:用于统计推断,比如Cramér-Rao下界,衡量参数估计的理论精度。
- Hessian:用于优化算法(如牛顿法),直接处理损失函数的局部曲率。
4. 计算复杂度
- Fisher:需要知道分布并计算期望,理论上精确但实践中常需近似(如K-FAC)。
- Hessian:只需对具体数据求二阶导数,但在大规模模型中计算和存储成本高。
举例:正态分布
对于 ( x ∼ N ( μ , σ 2 ) x \sim N(\mu, \sigma^2) x∼N(μ,σ2) ):
-
Fisher:
I μ μ = − E [ − 1 σ 2 ] = 1 σ 2 I_{\mu\mu} = -E\left[ -\frac{1}{\sigma^2} \right] = \frac{1}{\sigma^2} Iμμ=−E[−σ21]=σ21
(二阶导数为常数,期望不变) -
Hessian:
H μ μ = − ∂ 2 log p ∂ μ 2 = 1 σ 2 H_{\mu\mu} = -\frac{\partial^2 \log p}{\partial \mu^2} = \frac{1}{\sigma^2} Hμμ=−∂μ2∂2logp=σ21
(对于单次观测,值固定)
这里两者相等,但如果数据有噪声或分布复杂,Hessian会波动,而Fisher保持稳定。
实际中的联系与应用
1. 大样本近似
在最大似然估计(MLE)中,当样本量很大时,Hessian矩阵的平均值趋近于Fisher信息矩阵:
1 n ∑ i = 1 n H ( θ ; x i ) ≈ I ( θ ) \frac{1}{n} \sum_{i=1}^n H(\theta; x_i) \approx I(\theta) n1i=1∑nH(θ;xi)≈I(θ)
这为参数估计的协方差提供了近似:( Cov ( θ ^ ) ≈ I ( θ ) − 1 \text{Cov}(\hat{\theta}) \approx I(\theta)^{-1} Cov(θ^)≈I(θ)−1 )。
2. 优化中的融合
- 牛顿法:直接用Hessian调整步长,但计算昂贵。
- 自然梯度下降:用Fisher信息代替Hessian,结合统计特性,效率更高。
- 折中方案:如K-FAC,用Fisher的近似加速Hessian类优化。
3. 参数正交性
Fisher的非对角元素 ( I i j = 0 I_{ij} = 0 Iij=0 ) 表示参数正交,而Hessian的非对角元素反映具体数据的参数耦合。Fisher提供理论指导,Hessian提供实践反馈。
总结
Fisher信息矩阵和Hessian矩阵是一对“亲戚”:Fisher是Hessian的期望版本,前者关注分布的统计信息,后者关注具体数据的曲率。它们在统计推断和优化中各有侧重,但在理论和实践中常常相辅相成。理解它们的区别与联系,能帮助我们在模型设计和训练中更灵活地选择工具——是追求理论精度,还是优化实际收敛?答案就在这两者之中。
后记
2025年2月24日23点00分于上海,在Grok3大模型辅助下完成。
相关文章:

Fisher信息矩阵与Hessian矩阵:区别与联系全解析
Fisher信息矩阵与Hessian矩阵:区别与联系全解析 在统计学和机器学习中,Fisher信息矩阵(FIM)和Hessian矩阵是两个经常出现的概念,它们都与“二阶信息”有关,常用来描述函数的曲率或参数的敏感性。你可能听说…...

有哪些开源大数据处理项目使用了大模型
以下是一些使用了大模型的开源大数据处理项目: 1. **RedPajama**:这是一个开源项目,使用了LLM大语言模型数据处理组件,对GitHub代码数据进行清洗和处理。具体流程包括数据清洗、过滤低质量样本、识别和删除重复样本等步骤。 2. …...

ubuntu离线安装Ollama并部署Llama3.1 70B INT4
文章目录 1.下载Ollama2. 下载安装Ollama的安装命令文件install.sh3.安装并验证Ollama4.下载所需要的大模型文件4.1 加载.GGUF文件(推荐、更容易)4.2 加载.Safetensors文件(不建议使用) 5.配置大模型文件 参考: 1、 如…...

机器学习数学通关指南——泰勒公式
前言 本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见《机器学习数学通关指南》 正文 一句话总结 泰勒公式是用多…...

目标检测tricks
A. Stochastic Weight Averaging (SWA) 1. 基本思想 SWA 的核心思想是通过对训练过程中不同时间点的模型参数进行加权平均,从而获得一个更好的模型。具体来说,SWA 在训练过程的后期阶段对多个不同的模型快照(snapshots)进行平均…...

JNA基础使用,调用C++返回结构体
C端 test.h文件 #pragma oncestruct RespInfo {char* path;char* content;int statusCode; };extern "C" { DLL_EXPORT void readInfo(char* path, RespInfo* respInfo); }test.cpp文件 #include "test.h"void readInfo(char* path, RespInfo* respInfo…...

【算法】793. 高精度乘法
题目 793. 高精度乘法 思路 把b当作一个整体进行乘法,用A的每一位和b相乘,还要加上判断001的情况,把前面的0删掉。 代码 #include<iostream> #include<vector> using namespace std; vector<int>mul(vector<int>…...

解锁养生密码,拥抱健康生活
在快节奏的现代生活中,养生不再是一种选择,而是我们保持活力、提升生活质量的关键。它不是什么高深莫测的学问,而是一系列融入日常的简单习惯,每一个习惯都在为我们的健康加分。 早晨,当第一缕阳光洒进窗户,…...

OpenCV(6):图像边缘检测
图像边缘检测是计算机视觉和图像处理中的一项基本任务,它用于识别图像中亮度变化明显的区域,这些区域通常对应于物体的边界。是 OpenCV 中常用的边缘检测函数及其说明: 函数算法说明适用场景cv2.Canny()Canny 边缘检测多阶段算法,检测效果较…...

spark的一些指令
一,复制和移动 1、复制文件 格式:cp 源文件 目标文件 示例:把file1.txt 复制一份得到file2.txt 。那么对应的命令就是:cp file1.txt file2.txt 2、复制目录 格式:cp -r 源文件 目标文件夹 示例:把目…...

OpenHarmony全球化子系统
OpenHarmony全球化子系统 简介系统架构目录相关仓 简介 当OpenHarmony系统/应用在全球不同区域使用时,系统/应用需要满足不同市场用户关于语言、文化习俗的需求。全球化子系统提供支持多语言、多文化的能力,包括: 资源管理能力 根据设备类…...
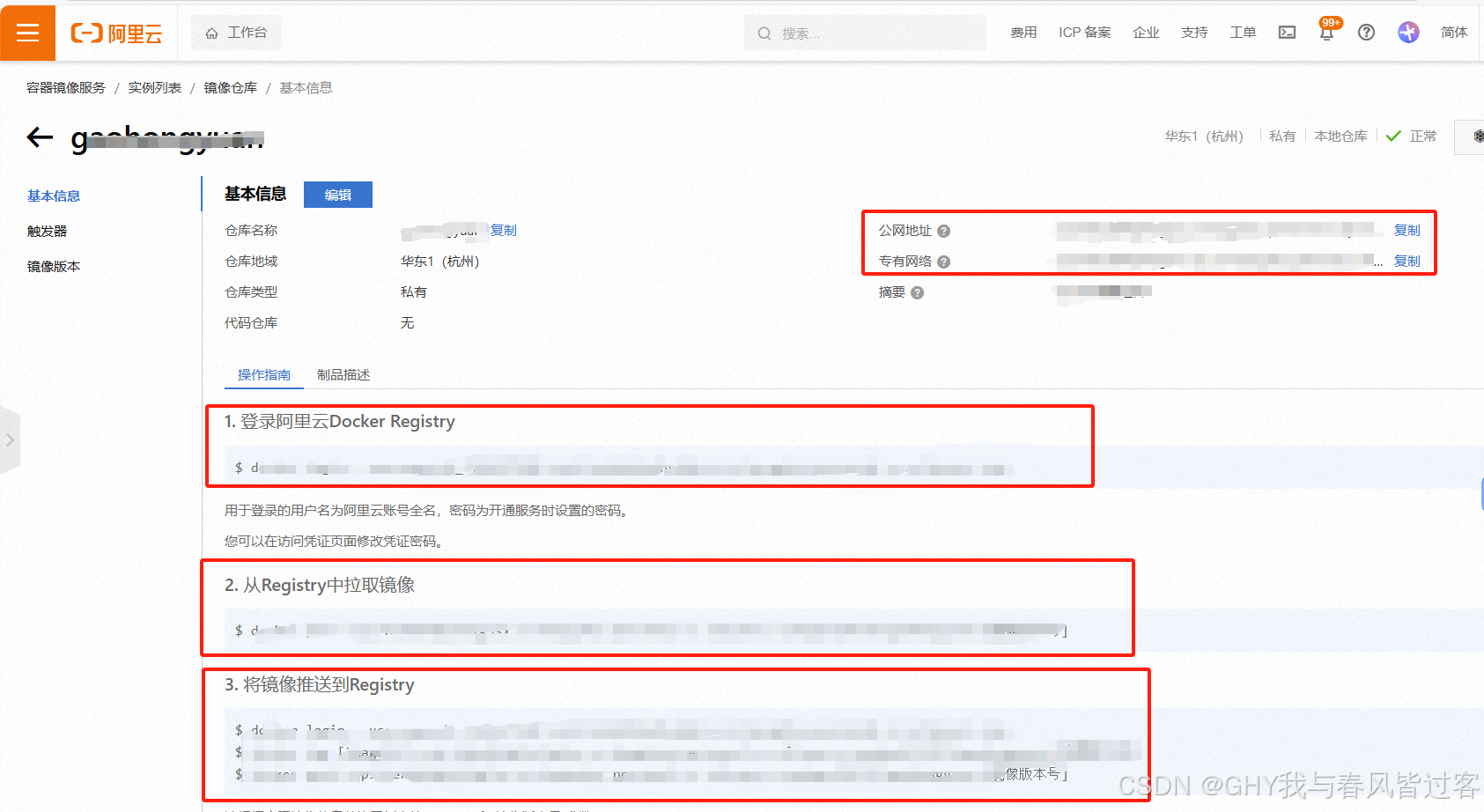
创建私人阿里云docker镜像仓库
步骤1、登录阿里云 阿里云创建私人镜像仓库地址:容器镜像服务 步骤2、创建个人实例 步骤:【实例列表】 》【创建个人实例】 》【设置Registry登录密码】 步骤3、创建命名空间 步骤:【个人实例】》【命名空间】》【创建命名空间】 注意&am…...

【LLM】本地部署LLM大语言模型+可视化交互聊天,附常见本地部署硬件要求(以Ollama+OpenWebUI部署DeepSeekR1为例)
【LLM】本地部署LLM大语言模型可视化交互聊天,附常见本地部署硬件要求(以OllamaOpenWebUI部署DeepSeekR1为例) 文章目录 1、本地部署LLM(以Ollama为例)2、本地LLM交互界面(以OpenWebUI为例)3、本…...

【考研】复试相关上机题目
文章目录 22机试回忆版1、判断燃气费描述输入格式输出格式输入样例输出样例 C o d e Code Code 2、统计闰年数量描述输入格式输出格式输入样例输出样例 C o d e Code Code 3、打印图形描述输入格式输出格式 C o d e Code Code 4、密文数据描述输入格式输出格式输入样例输出样例…...

vue3除了pinia/vuex的其他通讯方式还有那些
1. Props 和 Events Props:父组件通过 props 向子组件传递数据。 Events:子组件通过 $emit 向父组件发送事件。 <!-- ParentComponent.vue --> <template><ChildComponent :message"parentMessage" update-message"updat…...
】当Python爬虫邂逅边缘计算:探索数据采集新境界)
【Python爬虫(80)】当Python爬虫邂逅边缘计算:探索数据采集新境界
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取ÿ…...

LLM之论文阅读——Context Size对RAG的影响
前言 RAG 系统已经在多个行业中得到广泛应用,尤其是在企业内部文档查询等场景中。尽管 RAG 系统的应用日益广泛,关于其最佳配置的研究却相对缺乏,特别是在上下文大小、基础 LLM 选择以及检索方法等方面。 论文原文: On the Influence of Co…...

2025-02-25 学习记录--C/C++-用C语言实现删除字符串中的子串
用C语言实现删除字符串中的子串 在C语言中,你可以使用strstr函数来查找子串,然后用memmove或strcpy来覆盖或删除找到的子串。 一、举例 🐰 #include <stdio.h> // 包含标准输入输出库,用于使用 printf 函数 #include <s…...

网络原理--常见的请求和响应的格式
1.xml 类似于html,也是一种标签语言,标签成对出现。 例如: <request> <userId>1000</userId> </request> 其中: <userId>称为开始标签,</userId>称为结束标签。开始标签和结…...

【Linux】Ubuntu服务器的安装和配置管理
ℹ️大家好,我是练小杰,今天周二了,哪吒的票房已经到了138亿了,饺子导演好样的!!每个人的成功都不是必然的,坚信自己现在做的事是可以的!!😆 本文是有关Ubunt…...

2.3做logstash实验
收集apache日志输出到es 在真实服务器安装logstash,httpd systemctl start httpd echo 666 > /var/www/html/index.html cat /usr/local/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns/httpd #系统内置变量 cd /usr/local/…...

pandas读取数据
pandas读取数据 导入需要的包 import pandas as pd import numpy as np import warnings import oswarnings.filterwarnings(ignore)读取纯文本文件 pd.read_csv 使用默认的标题行、逗号分隔符 import pandas as pd fpath "./datas/ml-latest-small/ratings.csv" 使…...

rabbitmq 延时队列
要使用 RabbitMQ Delayed Message Plugin 实现延时队列,首先需要确保插件已安装并启用。以下是实现延时队列的步骤和代码示例。 1. 安装 RabbitMQ Delayed Message Plugin 首先,确保你的 RabbitMQ 安装了 rabbitmq-delayed-message-exchange 插件。你可…...

Deepseek 实战全攻略,领航科技应用的深度探索之旅
想玩转 Deepseek?这攻略别错过!先带你了解它的基本原理,教你搭建运行环境。接着给出自然语言处理、智能客服等应用场景的实操方法与代码。还分享模型微调、优化技巧,结合案例加深理解,让你全面掌握,探索科技…...

Go语言中的信号量:原理与实践指南
Go语言中的信号量:原理与实践指南 引言 在并发编程中,控制对共享资源的访问是一个经典问题。Go语言提供了丰富的并发原语(如sync.Mutex),但当我们需要灵活限制并发数量时,信号量(Semaphore&am…...

计算机网络与通讯知识总结
计算机网络与通讯知识总结 基础知识总结 1)FTP:文件传输 SSH:远程登录 HTTP:网址访问 2)交换机 定义:一种基于MAC地址实现局域网(LAN)内数据高速转发的网络设备,可为接入设备提供独享通信通道。 - 核心功能: 1.数据链路层(OSI第二层)工作,通过MAC地址…...

ReentrantLock 用法与源码剖析笔记
📒 ReentrantLock 用法与源码剖析笔记 🚀 一、ReentrantLock 核心特性 🔄 可重入性:同一线程可重复获取锁(最大递归次数为 Integer.MAX_VALUE)🔧 公平性:支持公平锁(按等…...

Vscode无法加载文件,因为在此系统上禁止运行脚本
1.在 vscode 终端执行 get-ExecutionPolicy 如果返回是Restricted,说明是禁止状态。 2.在 vscode 终端执行set-ExecutionPolicy RemoteSigned 爆红说明没有设置成功 3.在 vscode 终端执行Set-ExecutionPolicy -Scope CurrentUser RemoteSigned 然后成功后你再在终…...

java进阶专栏的学习指南
学习指南 java类和对象java内部类和常用类javaIO流 java类和对象 类和对象 java内部类和常用类 java内部类精讲Object类包装类的认识String类、BigDecimal类初探Date类、Calendar类、SimpleDateFormat类的认识java Random类、File类、System类初识 javaIO流 java IO流【…...

架构思维:架构的演进之路
文章目录 引言为什么架构思维如此重要架构师的特点软件架构的知识体系如何提升架构思维大型互联网系统架构的演进之路一、大型互联网系统的特点二、系统处理能力提升的两种途径三、大型互联网系统架构演化过程四、总结 引言 在软件开发行业中,有很多技术人可能会问…...