泛型编程、函数模板、类模板
目录
一、泛型编程
1.泛型编程提出背景
1.1.代码复用案例解析
案例1:实现一个交换函数,并对不同类型参数进行函数重载
(1)调试
(2)代码解析
①代码复用问题
②泛型编程的解决方案
③上面泛型Swap函数模版的优点
1.2.泛型编程提出背景
2.泛型编程、模版介绍
2.1.泛型编程概念
2.2.模板概念
2.3.模板的分类
二、函数模版
1.函数模板概念
2.函数模板格式介绍
2.1.函数模版格式的解析
(1)函数模版的两种写法
①写法1
②写法2
(2)函数模版的详细解析
(3)案例1:单个类型的函数模版——定义Swap函数模版
3.函数模板的原理
3.1.分析当使用相同的函数模板来处理不同类型的参数时,是否会实例化出相同的函数实体。
3.2.函数模板原理介绍
4.函数模板的实例化
4.1.函数模板实例化概念
4.2.隐式实例化:让编译器根据实参自动推断出模板参数的实际类型
4.2.1.隐式实例化介绍
(1)隐式实例化概念
(2)隐式实例化格式
4.2.2.隐式实例化案例
(1)案例1:错误的函数模板实例化
(2)案例2:类型转换
4.3.显式实例化:在函数名后的<>中指定模板参数的实际类型
4.3.1.显示实例化介绍
(1).显示实例化概念
(2)显式实例化案例
(3)显式实例化作用
(4)注意事项
5.模板参数的匹配原则
5.1.一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数。
5.1.1.分析同函数名的函数模板和普通函数可以同时存在而不发生编译报错的原因
(1)案例
(2)原因
5.1.2.同函数名的函数模版和普通函数同时存在时,隐式实例化和显试实例化分别如何调用?
(1)隐式实例化只会调用普通函数,而不调用函数模板
(2)显式实例化只会调用函数模板,而不调用普通函数
(3)总结
5.2.对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
(1)案例1
(2)案例2:模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
三、类模版
1.类模板介绍
1.1.类模板概念
1.2.类模板的语法
1.3.类模板的背景
1.4.类模板的作用
1.5.类模板的案例
案例:实现一个数组的类模板
2.类模板实例化介绍
2.1.类模板实例化概念
2.2.类模板显式实例化格式
(1)有了类模板后,如何区分类名和类型
(2)类名与类型在普通类和类模板中的区别
(3)类模板不能隐式实例化,只能显示实例化的原因
3.类模板的声明和定义分离
3.1.类模板的声明和定义必须在同一文件中
(1)案例:在头文件中声明,在源文件中定义,声明和定义不在同一文件中使得在编译时发生链接错误
(2)类模板的声明和定义必须在同一文件的原因
3.2.普通类和类模板声明与定义分离的区别
(1)普通类
(2)类模板
类模板的成员函数在类外部定义的规则
3.3.类模板的声明和定义在同一文件的几种写法
(1)写法1:在头文件中声明和定义,成员函数在类模板内部定义
(2)写法2:在头文件中声明和定义,成员函数在类模板中定义外部定义
4.以栈为例,typedef 类型重命名不能解决容器存储不同数据类型的问题
一、泛型编程
1.泛型编程提出背景
1.1.代码复用案例解析
案例1:实现一个交换函数,并对不同类型参数进行函数重载
#include<stdlib.h>
#include <iostream>
using namespace std;//解析:
//1.当我们想写一个交换函数Swap时,针对不同的参数类型都需要编写函数重载。这样做会导致代码重复,
//因为每个重载函数的内部逻辑都是类似的,只是参数类型不同。为了解决这个问题,C++提供了模板机制来
//实现泛型编程。
//2.使用函数重载虽然可以实现,但是有一下几个不好的地方:重载的函数仅仅是类型不同,代码复用率比
//较低,只要有新类型出现时,就需要用户自己增加对应的函数; 同时代码的可维护性比较低,一个出错可
//能所有的重载均出错//Swap的函数重载
void Swap(int& left, int& right)
{int temp = left;left = right;right = temp;
}
void Swap(double& left, double& right)
{double temp = left;left = right;right = temp;
}void Swap(char& left, char& right)
{char temp = left;left = right;right = temp;
}int main()
{int a = 1, b = 2;Swap(a, b);double c = 1.1, d = 2.22;Swap(c, d);char e = 'a', f = 'b';Swap(e, f);return 0;
}
(1)调试
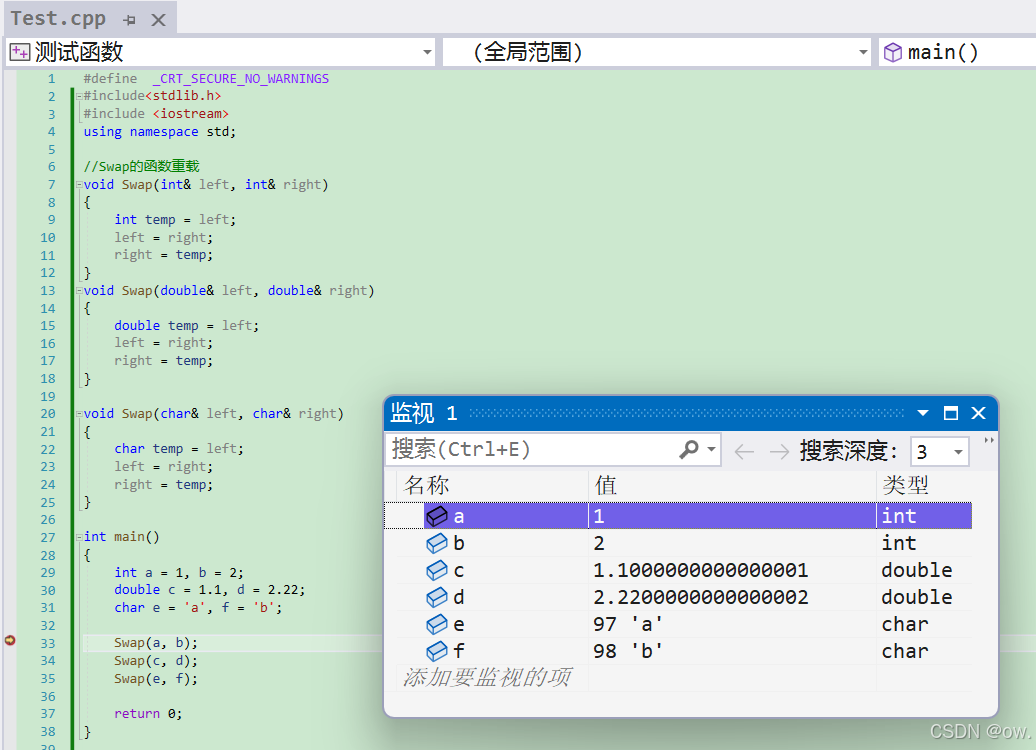
(2)代码解析
上面的C++代码示例展示了函数重载的使用,通过为不同类型的参数提供不同的函数实现,从而实现了对不同类型数据的交换。然而,这种方法存在代码重复的问题,因为对于每种数据类型,都需要编写几乎相同的代码。这就是C++提出泛型编程要解决的一个重要问题。
①代码复用问题
在上述代码中,Swap函数被重载了三次,分别用于交换int、double和char类型的值。这些函数的实现几乎是一样的,只是数据类型不同。如果需要为更多类型提供交换功能,就需要编写更多的重载函数,这导致了代码的重复和冗余。
②泛型编程的解决方案
C++通过模板机制提供了泛型编程的能力,可以解决上述代码复用的问题。使用模板,可以编写一个通用的Swap函数,该函数可以用于任何类型的数据。下面是使用模板重写的Swap函数:
#include<stdlib.h>
#include <iostream>
using namespace std;//template:译为模板//泛型编程 -- 模板
template<class T> //或者写成:template<typename T>
//解析:T是模板类型参数的名称。这个参数名称不一定叫T,也可以是其他标识符,如X、Y等。void Swap(T& x, T& y) //类型参数T的具体类型是由调用时的实参类型决定的。
{T tmp = x;x = y;y = tmp;
}int main()
{int a = 1, b = 2;Swap(a, b); //调用Swap模板函数,T被实例化为intdouble c = 1.1, d = 2.22;Swap(c, d); //调用Swap模板函数,T被实例化为doublechar e = 'a', f = 'b';Swap(e, f); //调用Swap模板函数,T被实例化为charreturn 0;
}
③上面泛型Swap函数模版的优点
-
减少代码重复:只需要编写一个模板函数,就可以用于任何类型的数据,大大减少了代码的重复。
-
提高可维护性:如果需要修改交换逻辑,只需要更改模板函数,所有使用该模板的代码都会自动使用新的逻辑。
-
增加灵活性:模板函数可以用于任何类型,包括自定义类型,而无需为每种类型编写特定的重载函数。
-
编译时类型检查:模板在编译时进行实例化,保证了类型安全,避免了运行时类型错误。
通过这个例子,我们可以看到C++提出泛型编程是为了提供一种更高效、更灵活、更安全的代码复用机制,从而解决了传统函数重载带来的代码重复和维护困难的问题。
1.2.泛型编程提出背景
在C++中,泛型编程的提出背景与软件开发中的一些常见需求和挑战密切相关,主要包括以下几个方面:
(1)代码复用:在泛型编程出现之前,程序员经常需要为不同的数据类型编写相同的算法或数据结构,例如,排序算法可能需要为整数、浮点数和字符数组分别实现。这导致了大量的代码重复,增加了维护成本。泛型编程通过允许编写与数据类型无关的代码,提高了代码的复用性。
(2)类型安全:早期的一些编程语言中,为了实现代码复用,程序员可能会使用像void*这样的指针来处理不同类型的对象,但这牺牲了类型安全,因为编译器无法在编译时检查类型错误。泛型编程在编译时进行类型检查,从而提高了代码的类型安全性。
(3)算法的通用性:许多算法和数据结构的概念是通用的,它们不依赖于特定的数据类型。程序员希望能够以一种通用的方式表达这些概念,而不是针对特定的数据类型。
(4)总结:C++中的泛型编程是为了解决代码复用、提高类型安全性、增强算法的通用性以及提升开发效率等问题而提出的。它通过模板机制在编译时根据传入的类型参数生成特定类型的代码,从而实现了同一份代码在不同数据类型上的重用,同时保证了类型的安全性和算法的灵活性。这种编程范式极大地简化了编程模型,减少了代码冗余,并提高了软件的可维护性和可扩展性。
2.泛型编程、模版介绍
2.1.泛型编程概念
泛型编程是一种编程范式,它允许程序员编写与数据类型无关的代码,从而创建可重用的代码组件。泛型编程的核心思想是将算法和数据结构的通用概念抽象化为模板,这样这些模板就可以被用来处理多种数据类型,而不仅仅是单一特定的类型。泛型编程使得代码更加通用、灵活,并且易于维护。
以下是对泛型编程详细说明:
-
类型无关性:泛型编程关注于编写不依赖于特定数据类型的代码。这意味着相同的代码可以用于不同的数据类型,比如整数、浮点数、字符串等。
-
模板:在C++中,泛型编程通常是通过模板实现的。模板允许程序员定义一个框架,这个框架可以在编译时针对不同的数据类型进行实例化。
-
算法和数据结构的通用性:泛型编程鼓励开发通用的算法和数据结构,这些算法和数据结构可以应用于多种数据类型,而不是为每种类型编写特定的实现。
-
代码重用:泛型编程提高了代码的重用性,因为相同的代码可以用于不同的数据类型,减少了代码的重复。
2.2.模板概念
模板提供了一种方法来定义函数或类,使得这些函数或类可以处理任何类型的数据,而不仅仅是单一特定类型。模板的定义并不是函数或类的具体实现,而是一个蓝图或公式,在编译时模板用于生成针对特定类型的函数或类的具体实现。
注意:泛型编程是用模版实现的。
2.3.模板的分类
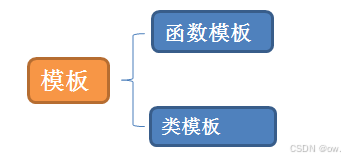
(1)函数模板: 函数模板允许编写一个函数,它可以操作任何类型的参数。编译器会根据传递给函数的参数类型自动生成函数的特定实例。
(2)类模板: 类模板允许定义一个可以处理任何类型的类。类模板成员函数通常在类模板外部定义。
二、函数模版
1.函数模板概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
2.函数模板格式介绍
2.1.函数模版格式的解析
(1)函数模版的两种写法
①写法1
//函数模版的定义格式:
template<typename T1, typename T2,......,typename Tn>//模板参数列表。模板参数列表
//用来声明一个或多个类型参数,这些类型参数在函数模板被调用时将被具体的类型所替换。返回值类型 函数名(参数列表)
{//函数体,这里编写函数的具体实现。//函数体内部可以使用模板参数 T1, T2, ..., Tn来定义变量的类型。
}②写法2
注意:我们常用写法2来实现函数模版。
//函数模版的定义格式:
template<class T1, class T2,......,class Tn>返回值类型 函数名(参数列表)
{//函数体,这里编写函数的具体实现。
}(2)函数模版的详细解析
template<typename T1, typename T2, ..., typename Tn>是声明一个函数模板的关键字和语法结构。注:class 和 typename 在模板参数列表中都可以用来定义类型参数,一定不可以使用struct定义类型参数,我们一般使用class定义类型参数。
-
template:这是一个关键字,告诉编译器后面跟着的是一个模板的声明。模板是C++中实现泛型编程的一种机制,模板允许编写与类型无关的代码即这段代码可以适用于多种不同的数据类型,而不需要为每种类型单独编写代码。编译器根据模板和提供的实际类型生成特定的代码。 -
模板参数列表位于模板声明中的
template关键字之后,并用尖括号<>括起来。 -
typename:这是另一个关键字,用于在模板参数列表中声明一个类型参数。在C++早期版本中也可以使用class关键字来声明类型参数,但是typename更准确地反映了参数是一个类型。 -
T1, T2, ..., Tn:这些是类型参数的名称(注:一般使用大写),它们代表在函数模板定义中可以使用的任意类型。在函数模板实例化时,这些参数会被实际的类型所替换。T1,T2, …,Tn是习惯上的命名,但实际上可以使用任何有效的标识符。 -
返回值类型:这是函数模板返回的类型,它可以是任何类型,也可以是模板参数之一。 -
函数名:这是模板函数的名称。函数名应该遵循C++标识符的命名规则,并且应该能够清楚地描述函数的目的。 -
参数列表:这是函数模板的参数列表,参数的类型可以是模板参数(如T1,T2, …),也可以是具体的类型(如int,double等)。参数传递方式:参数可以按值传递,也可以按引用传递(如T1&表示对T1类型的引用),但是若可以使用传引用传递就用引用传递而不是值传递,因为引用可以减少拷贝。
(3)案例1:单个类型的函数模版——定义Swap函数模版
注意:C++库会提供一个swap函数
swap - C++ 参考 (cplusplus.com)
#include<stdlib.h>
#include <iostream>
using namespace std;
//template:译为模版//泛型编程 -- 模板
template<class T>//或者写成:template<typename T>
//解析:T是模版类型的名称。这个类型名称不一定叫T,也可以叫X 或者 叫Y。void Swap(T& x, T& y)//类型参数T的具体类型是由调用时的实参类型决定的。
{T tmp = x;x = y;y = tmp;
}int main()
{int a = 1, b = 2;Swap(a, b);double c = 1.1, d = 2.22;Swap(c, d);char e = 'a', f = 'b';Swap(e, f);return 0;
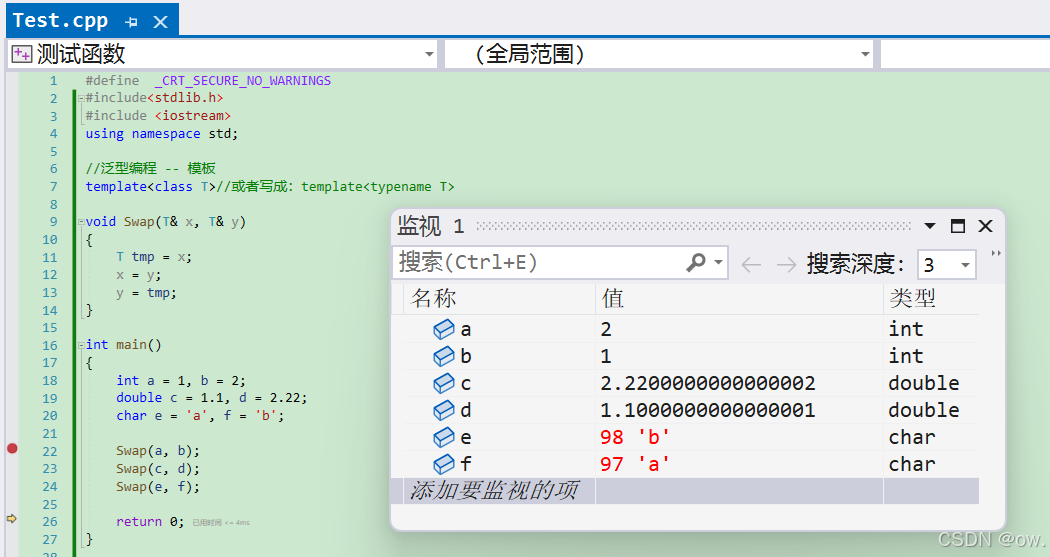
}调试:
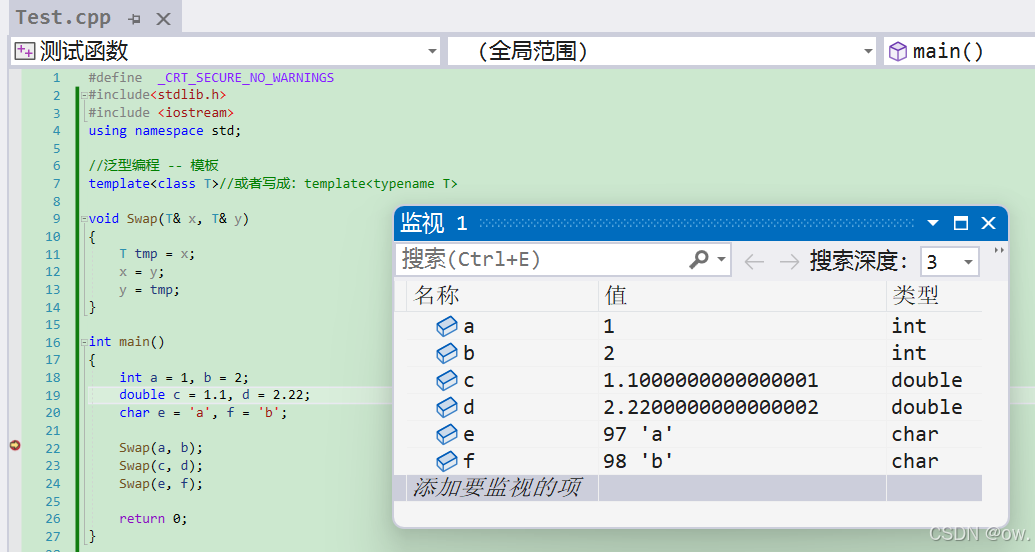
3.函数模板的原理
3.1.分析当使用相同的函数模板来处理不同类型的参数时,是否会实例化出相同的函数实体。
(1)解析:在上述代码中,我们定义了一个名为Swap的函数模板,它的作用是交换两个相同类型的值。在main函数里,我们三次调用了这个函数模板,每次调用都传入了不同类型的参数:Swap(a, b)第一次是两个int类型的变量,Swap(c, d)第二次是两个double类型的变量,ap(e, f)第三次是两个char类型的变量。
在C++中,编译器对函数模板的处理方式是:每当函数模板被调用时,如果模板参数是不同的类型,编译器就会根据这些类型生成一个特定的函数。因此,当我们分别用int、double和char类型调用Swap函数时,编译器为每种类型创建了一个独立的函数实例。
Swap(a, b):这里,T被替换为int,编译器生成了一个void Swap(int& x, int& y)的函数。Swap(c, d):这里,T被替换为double,编译器生成了一个void Swap(double& x, double& y)的函数。Swap(e, f):这里,T被替换为char,编译器生成了一个void Swap(char& x, char& y)的函数。
(2)Swap(a, b)、Swap(c, d)、Swap(e, f)这三个函数调用是否是同一个函数?
解答:Swap(a, b)、Swap(c, d)、Swap(e, f)这三个函数调用并不是调用同一个函数。每个调用都会导致编译器根据传入的参数类型生成一个特定的函数版本。以下是详细的解析:
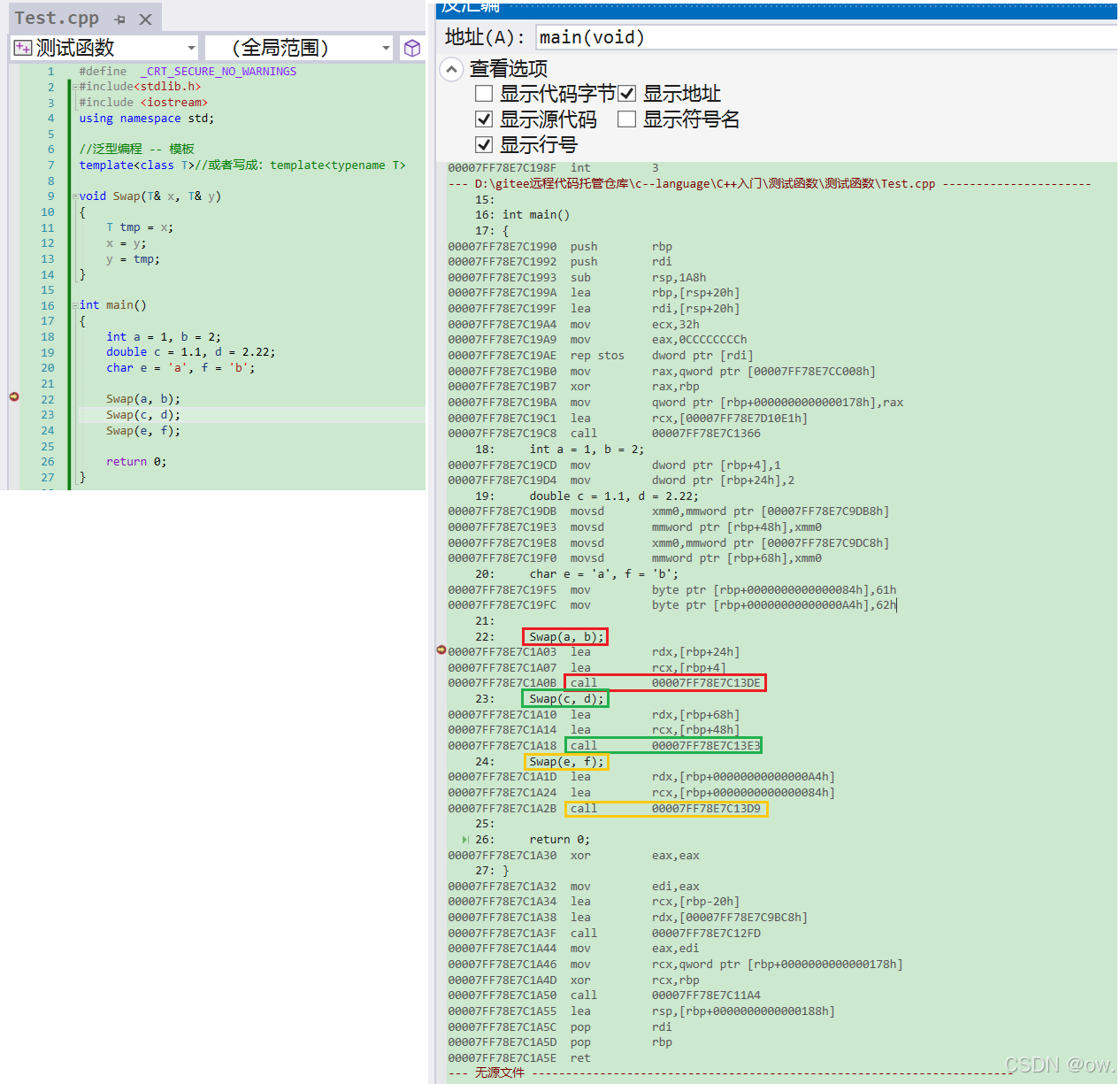
从汇编语言层面来看,由于每次调用Swap函数时传入的参数类型不同,编译器通过函数模版实例化生成了具有特定参数类型的函数(例如Swap(int& x, int& y)、Swap(double& x, double& y)、Swap(char& x, char& y))。因此,在调试时,当我们使用Swap(a, b)、Swap(c, d)、Swap(e, f)进行函数调用时,虽然看起来我们是在调用同一个Swap函数,但实际上在计算机内部,它们分别调用了三个完全不同的函数实例,每个实例都有不同的内存地址和对应的汇编指令集,这一点可以从汇编代码中的call指令指向的地址不同来证实。
(3)注意事项
① 当我们调用Swap函数模板时,例如Swap(a, b)、Swap(c, d)、Swap(e, f),编译器会为每种参数类型生成一个特定的函数版本。由于int、double和char类型在内存中占用的空间大小不同,这些特定版本的函数在执行时创建的栈帧大小也可能不同。
② 在汇编语言中,同一个函数意味着它们具有相同的机器指令序列和在内存中的唯一地址。由于Swap函数模板针对不同的类型参数生成了不同的函数版本,这些版本在汇编层面有不同的指令序列和地址。因此,Swap(int& x, int& y)、Swap(double& x, double& y)和Swap(char& x, char& y)是三个不同的函数,它们在程序中的call指令将指向不同的地址。
3.2.函数模板原理介绍
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器。
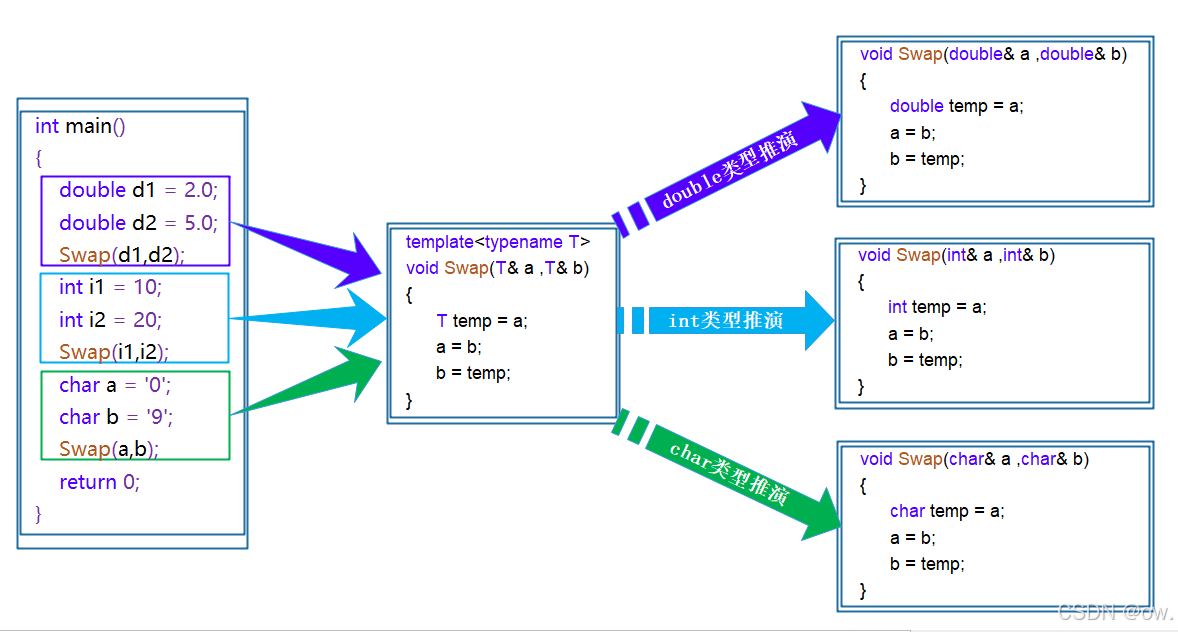
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
注意:函数模板实例化是指编译器在遇到函数模板调用时,根据传入的实际参数的类型来推断模板参数T的具体类型,并生成针对这些特定类型的函数代码的过程。
4.函数模板的实例化
4.1.函数模板实例化概念
(1)概念:在C++中,函数模板实例化是指编译器根据模板定义和传入的实际参数,生成具体函数实现的过程。函数模板是C++中的一种特性,允许编写与类型无关的代码,然后可以用不同的数据类型来调用这个模板,从而生成相应的函数版本。
总的来说,通过传参调用函数模板是触发函数模板实例化的过程,也可以理解为传参调用函数模版就是函数模板实例化。函数模板实例化分为两种类型:隐式实例化和显式实例化。
(2)注意事项
-
模板参数:函数模板定义中包含一个或多个模板参数(如
typename T或class T),模板参数T只是一个占位符这些参数在函数调用时会被具体的类型所替代。 -
函数模板实例化:是将函数模板转换为具体类型函数的过程,这个过程涉及到模板参数的具体化。注意:当我们多次使用相同类型的参数调用函数模板时,函数模板只会在第一次调用时被实例化。
-
实例化时机:模板实例化通常发生在编译时,而不是运行时。编译器在编译过程中检查模板调用,并生成相应的代码。
-
实例化结果:模板实例化产生的是一个具体的函数,它具有确定的类型参数,可以像普通函数一样被调用和优化。
4.2.隐式实例化:让编译器根据实参自动推断出模板参数的实际类型
4.2.1.隐式实例化介绍
(1)隐式实例化概念
当传参调用函数模板时,隐式实例化不需要程序员指定模板参数的具体类型。编译器会自动根据函数调用中的实际参数类型自动推断出模板参数的类型,并生成一个具体类型的函数版本。这个过程完全由编译器在编译时自动完成,无需程序员在代码中显式地指示编译器去做。
注意事项:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅。
(2)隐式实例化格式
template<class T>
T Add(const T& left, const T& right);//隐式实例化调用示例
Add(a1, a2); //隐式实例化,编译器推导 T 为 int
Add(d1, d2); //隐式实例化,编译器推导 T 为 double
Add(a1, (int)d1);//隐式实例化:d1被强制转换为int后再传参,然后编译器会根据转换后的类型推导模板参//数T。则编译器推导 T 为 int。
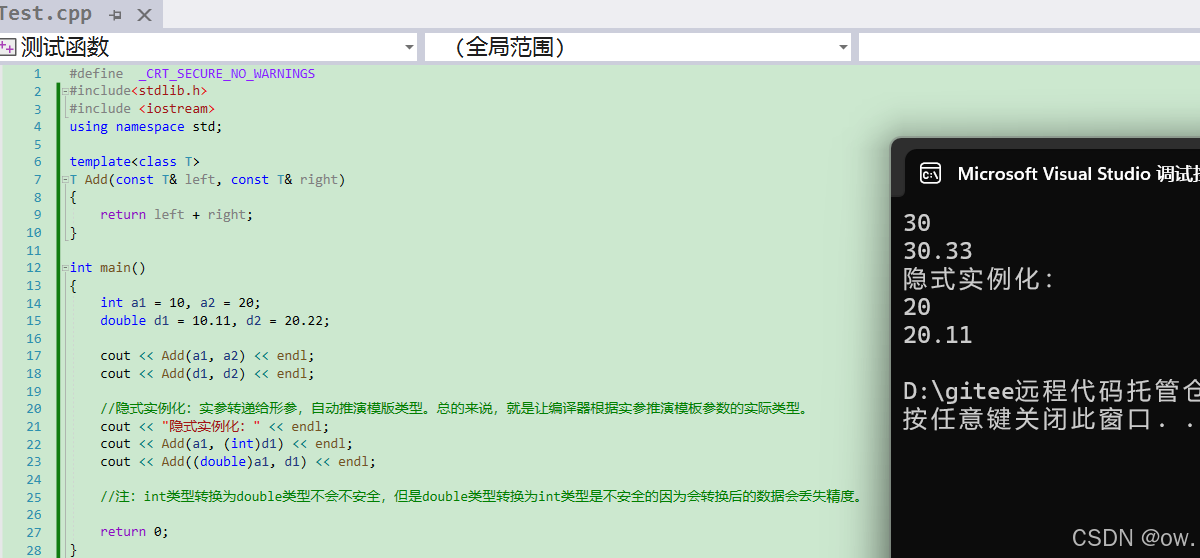
Add((double)a1, d1);//隐式实例化:a1被强制转换为double,然后编译器会根据转换后的类型推导模板参数 //T。则编译器推导 T 为 double。4.2.2.隐式实例化案例
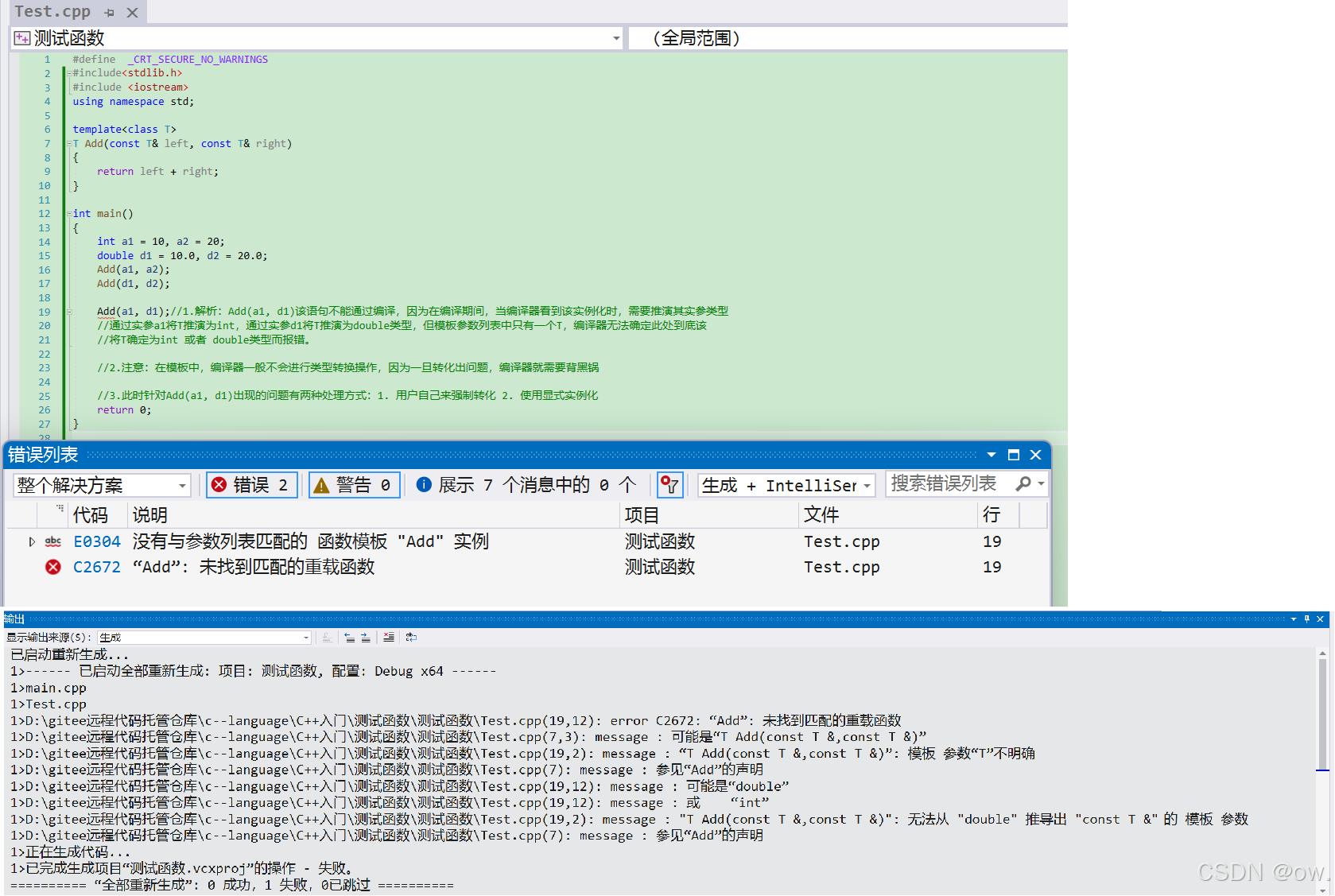
(1)案例1:错误的函数模板实例化
解决方式:
#include <string>
#include <iostream>
using namespace std;template<class T>
T Add(const T& left, const T& right)
{return left + right;
}int main()
{int a1 = 10, a2 = 20;double d1 = 10.0, d2 = 20.0;Add(a1, a2);Add(d1, d2);//Add(a1, d1);//该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,//需要推演其实参类型通过实参a1将T推演为int,通过实参d1将T推演为double类型,//但模板参数列表中只有一个T,编译器无法确定此处到底该将T确定为int 或者 //double类型而报错。注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,//编译器就需要背黑锅//此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化Add(a, (int)d);return 0;
}(2)案例2:类型转换
4.3.显式实例化:在函数名后的<>中指定模板参数的实际类型
4.3.1.显示实例化介绍
(1).显示实例化概念
①显式实例化是指程序员在代码中明确告诉编译器应该使用哪些具体类型来实例化一个函数模版或模板类。这与隐式实例化不同,在隐式实例化中,编译器会根据函数调用中的参数类型自动推断出模板参数的类型。
②在显式实例化的过程中,程序员通过在函数名后的尖括号<>中指定模板参数的实际类型来指导编译器。这可以用于以下几种情况:
- 当编译器无法从函数调用中推断出模板参数类型时。
- 当程序员想要确保使用特定的类型实例化模板时。
- 当需要提高代码的可读性,明确指出模板实例化的类型时。
③显示实例化语法:传参调用函数模板时,在函数名后加上<类型>,其中类型是你想要用于实例化的具体类型。
(2)显式实例化案例
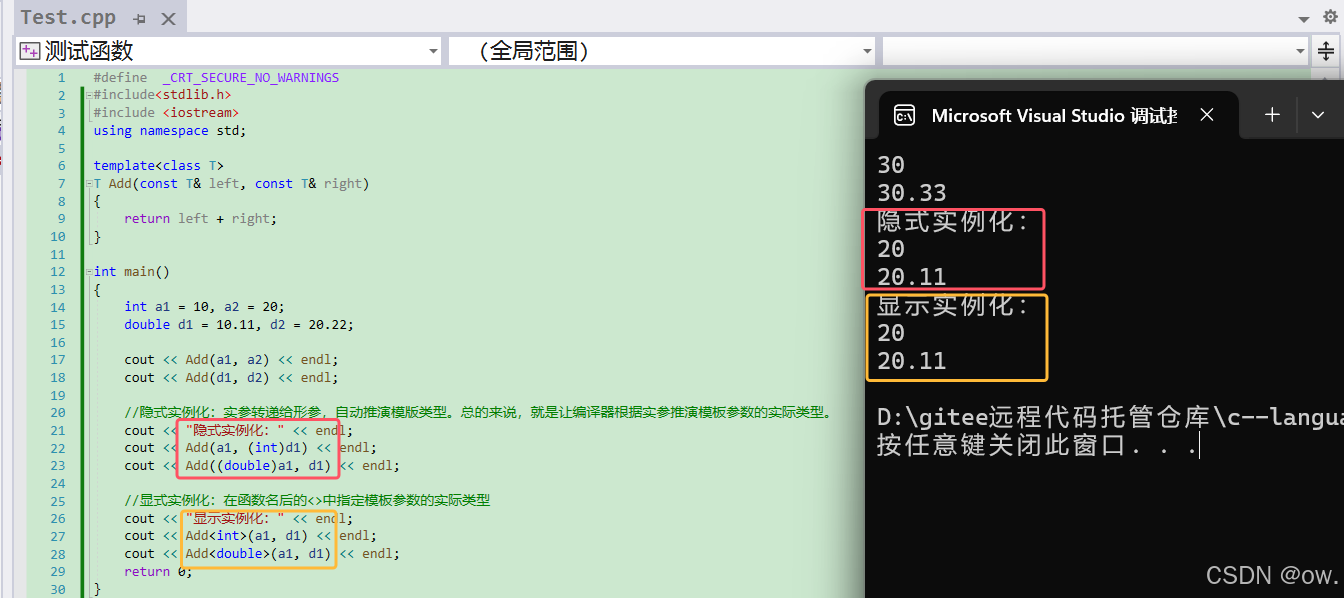
解析:
template<class T>
T Add(const T& left, const T& right);//显式类型转换调用示例
Add<int>(a1, d1); //显式指定 T 为 int
Add<double>(a1, d1); //显式指定 T 为 double//解析:Add<int>(a1, d1); 和 Add<double>(a1, d1); 是显式实例化的例子,这里明确指定了模板
//参数T的类型,即使实参a1和d1的类型不一致。在Add<int>(a1, d1);的情况下,d1会被从double转换
//为int,可能会丢失精度。(3)显式实例化作用
- 明确类型: 显式指定模板参数类型,可以避免编译器推导错误或解决类型歧义。
- 类型转换: 即使实参类型不一致,显式实例化允许指定一个统一的类型,从而在调用时进行必要的类型转换。例如,
Add<double>(a1, d1)会将a1从int转换为double。
(4)注意事项
显式实例化本身并不直接进行类型转换,而是指定了模板函数应该使用的具体类型。类型转换是在函数调用时发生的,而不是在显式实例化时。
类型转换:即使在函数调用时实参的类型与模板参数的类型不一致,显式实例化可以指定一个特定的模板参数类型,这样在调用函数时,编译器会自动将实参转换为模板参数指定的类型。例如,如果有一个模板函数Add,通过显式实例化Add<double>,在调用Add<double>(a1, d1)时,如果a1是int类型而d1是double类型,编译器会将a1从int类型转换为double类型,然后再调用Add函数。
总的来说,如果函数调用中的实参类型与显式实例化指定的模板参数类型不匹配,编译器会尝试进行隐式类型转换换,如果无法转换成功编译器将会报错。
5.模板参数的匹配原则
5.1.一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数。
解析:同函数名的函数模板和普通函数可以同时存在,并且该函数模板可以被实例化为与普通函数相同类型的函数。
5.1.1.分析同函数名的函数模板和普通函数可以同时存在而不发生编译报错的原因
(1)案例
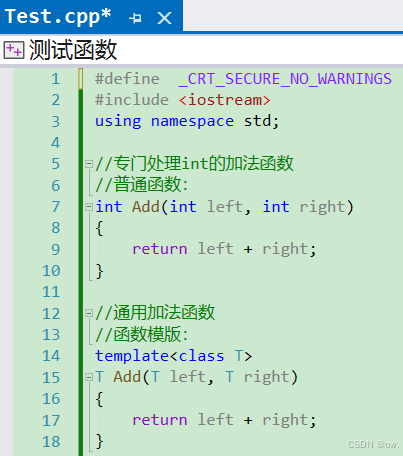
(2)原因
同函数名的普通函数和函数模版实例化之后生成的函数构成函数重载,而且普通函数和函数模版实例化之后生成的函数的函数命名规则不一样。
5.1.2.同函数名的函数模版和普通函数同时存在时,隐式实例化和显试实例化分别如何调用?
(1)隐式实例化只会调用普通函数,而不调用函数模板
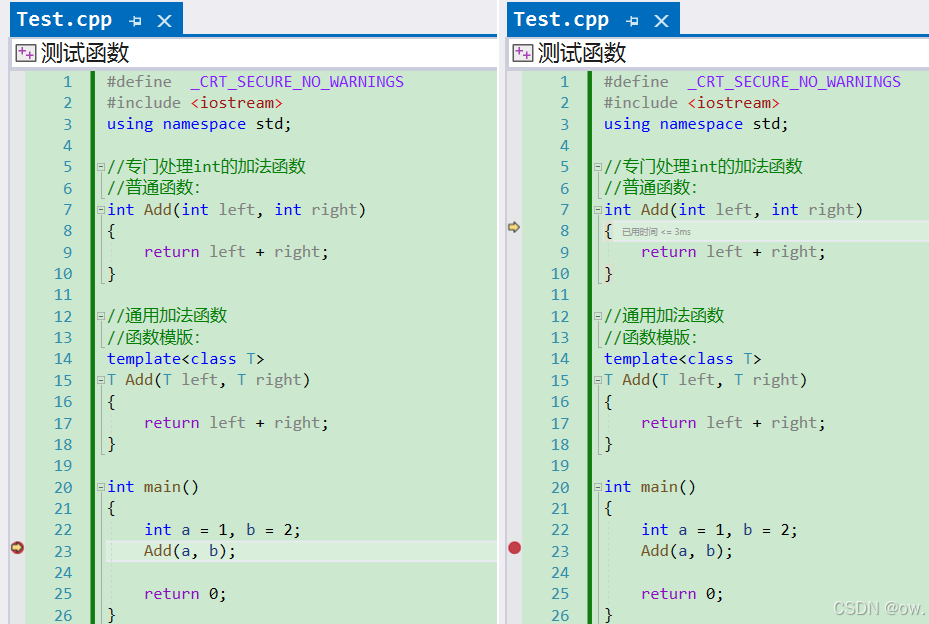
原因:
- 精确匹配优先:在C++中,当调用一个函数时,编译器会优先选择与调用参数最匹配的函数。在这个例子中,
Add(1, 2);直接对应于专门处理int类型的非模板函数Add(int left, int right),这是一个精确匹配,因此编译器会选择这个函数而不是去实例化模板函数。 - 名称查找规则:在C++的名称查找阶段,非模板函数的名称会被先找到,因为它们在编译时就已经是确定的,不需要进行模板参数推导。如果存在一个与调用匹配的非模板函数,编译器会使用这个函数,而不是继续查找模板函数。这是因为C++的名称查找规则规定了非模板函数的优先级高于模板函数。这意味着在名称查找阶段,如果有一个非模板函数可以匹配当前的函数调用,那么编译器就会选择这个非模板函数,而不会考虑模板函数。
(2)显式实例化只会调用函数模板,而不调用普通函数
原因:
- 明确指示:通过使用显式实例化
Add<int>(1, 2);,程序员明确指示编译器使用模板函数,并且指定了模板参数类型为int。这告诉编译器忽略任何同名的非模板函数,即使非模板函数也能处理这个调用。 - 调用意图:显式实例化反映了程序员的意图,即使用模板版本而不是普通函数版本。因此,编译器会忽略普通函数,即使它们存在,也会实例化并调用模板函数。
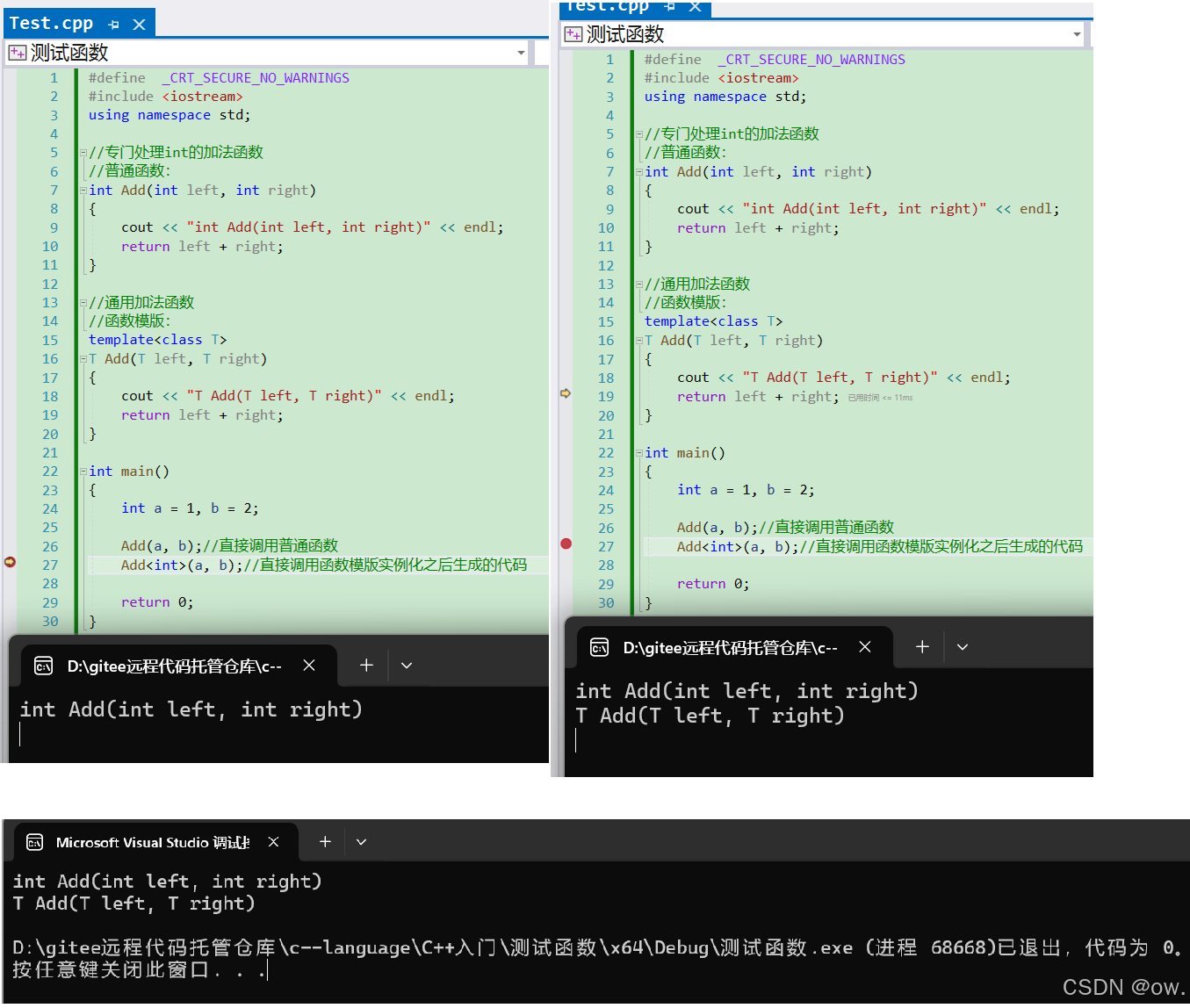
(3)总结
总结来说,隐式实例化选择普通函数是因为它提供了最精确的匹配,而显式实例化选择模板函数是因为程序员明确要求编译器使用模板版本。
5.2.对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
(1)案例1
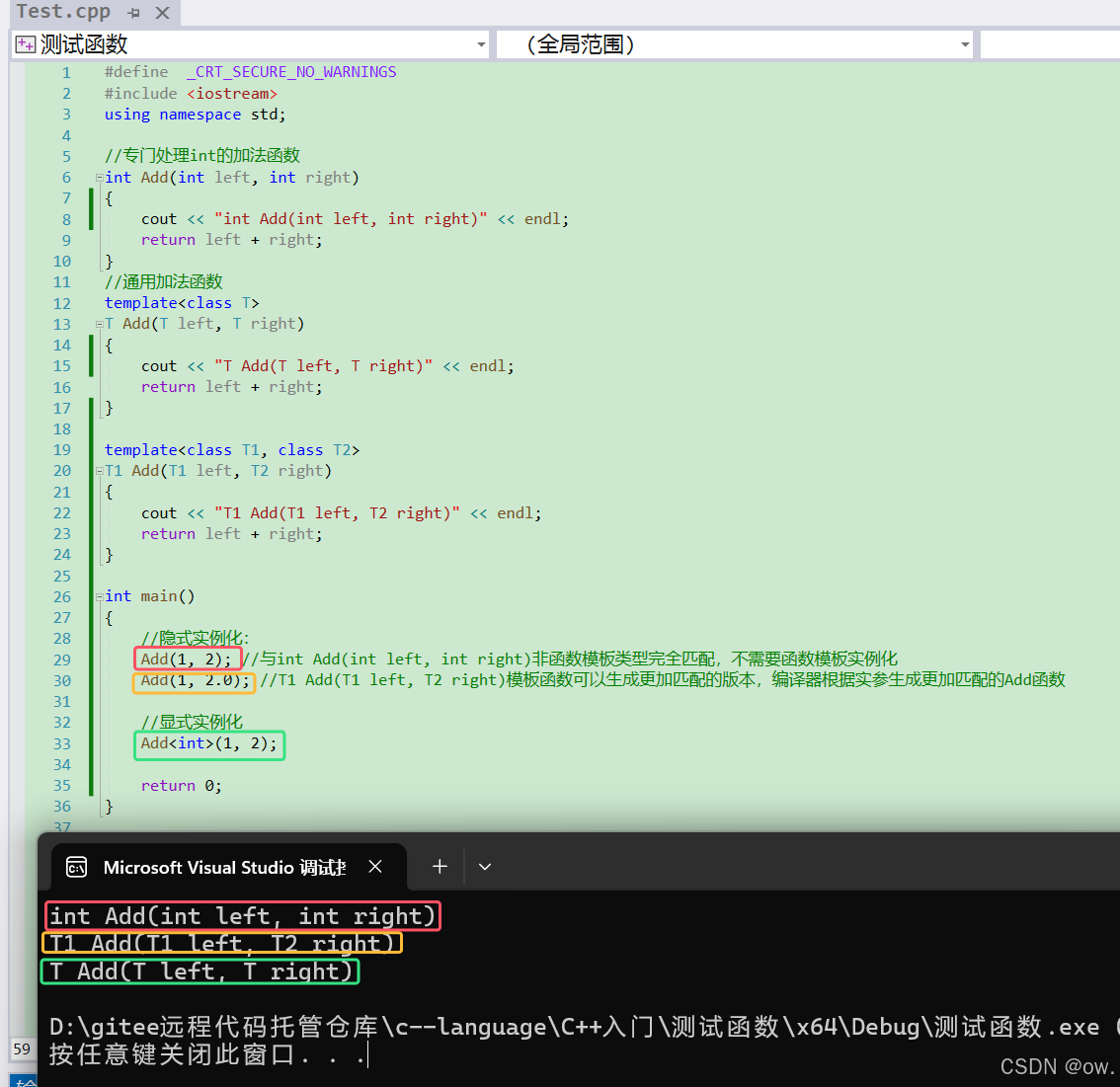
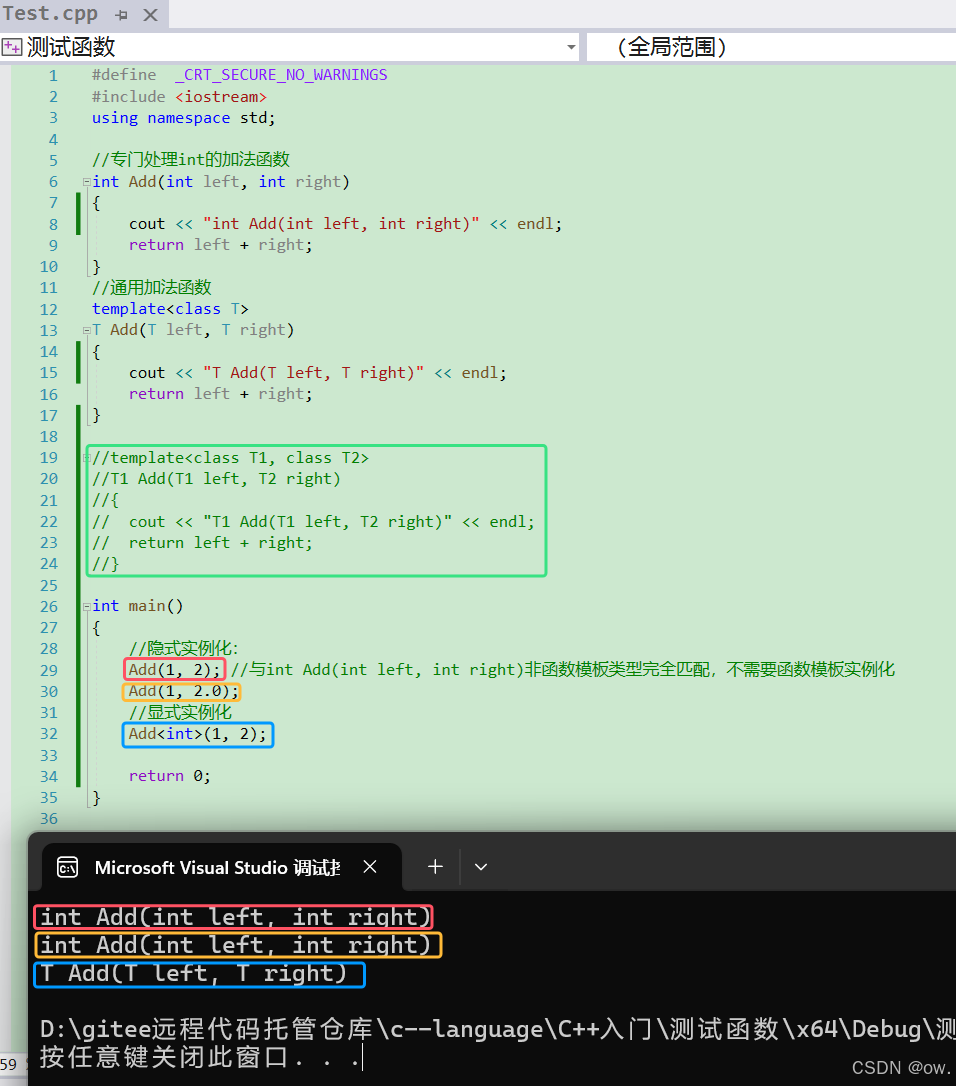
(2)案例2:模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
三、类模版
1.类模板介绍
1.1.类模板概念
在C++中,类模板是一种用于创建泛型类的方法,它允许程序员编写一个类定义,该定义不是针对任何特定的数据类型,而是可以用于任何数据类型。类模板提供了一种方式,可以创建出能够处理不同数据类型的类,而不必为每种数据类型编写单独的类代码。
1.2.类模板的语法
类模板的定义以关键字 template 开始,后跟一个模板参数列表,该列表用尖括号 <> 括起来。模板参数列表可以包含一个或多个由逗号分隔的类型参数。以下是类模板的基本语法:
template<class T1, class T2, ..., class Tn>
class ClassName//类模板名
{//类成员变量和成员函数
};这里的 T 是一个占位符名称,可以在类定义中使用它来表示任何类型。
1.3.类模板的背景
类模板的提出背景是为了解决代码复用的问题。在类模板出现之前,如果需要编写可以处理不同数据类型的类,程序员必须为每种数据类型编写几乎相同的代码,这导致了代码的冗余和维护困难。例如,如果要实现一个可以存储任何类型的数组类,那么就需要为 int、float、double 等每种类型分别编写一个数组类。
为了解决这个问题,C++引入了类模板的概念,使得可以用一种通用的方式来定义类,而不必关心具体的数据类型。
1.4.类模板的作用
- 代码复用:通过使用类模板,可以编写一次代码,然后用于多种数据类型,大大减少了代码量。
- 类型安全:类模板确保了在编译时类型错误会被检测出来,因为模板实例化时会检查类型的使用是否正确。
- 性能优化:由于模板类在编译时就已经确定了数据类型,编译器可以生成针对特定类型的优化代码。
1.5.类模板的案例
案例:实现一个数组的类模板
#include <cstring> //用于 memcpy
#include <cassert> //用于 asserttemplate <typename T>
class Array
{
private:T* _arr;size_t _size; //数组大小,即当前实际存储的元素个数size_t _capacity; //数组容量,即数组当前可容纳的最大元素个数public://构造函数Array(size_t newcapacity = 4): _size(0), _capacity(newcapacity), _arr(nullptr){_arr = new T[_capacity];}//(深拷贝)拷贝构造函数Array(const Array& a): _size(a._size), _capacity(a._capacity), _arr(nullptr){_arr = new T[_capacity];std::memcpy(_arr, a._arr, a._size * sizeof(T));}//拷贝赋值运算符Array& operator=(const Array& a){if (this != &a){T* tmp = new T[a._capacity];std::memcpy(tmp, a._arr, a._size * sizeof(T));delete[] _arr;_arr = tmp;_size = a._size;_capacity = a._capacity;}return *this; // 传引用返回}//析构函数~Array(){delete[] _arr;_arr = nullptr;_size = _capacity = 0;}size_t size() const {return _size;}size_t capacity() const {return _capacity;}//下标运算符,添加越界检查const T& operator[](size_t pos) const{assert(pos < _size);return _arr[pos];}T& operator[](size_t pos){assert(pos < _size);return _arr[pos];}bool empty() const{return _size == 0;}// 其他成员函数…………
};注意:在这个例子中,Array 类可以用于任何数据类型,如 Array<int>、Array<double> 或 Array<std::string> 等。
2.类模板实例化介绍
注意:类模板提供了一种方式,使得我们可以创建出针对不同数据类型的类。当我们定义一个类模板时,我们并没有定义一个具体的类,而是定义了一个类的蓝图。只有当我们为这个蓝图指定了具体的数据类型时,编译器才会生成一个具体的类。
2.1.类模板实例化概念
类模板实例化是指使用具体的类型来替换类模板中的模板参数,从而生成一个具体的类的过程。这个过程是由编译器在编译时完成的。
注意:类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类。类模板实例化必须只能显式实例化而不能隐式实例化。
2.2.类模板显式实例化格式
//类模板定义
//注意:在 C++ 语法中,当定义类模板时,模板参数列表中的类型参数是允许提供默认值的。当显式实
//例化这个类模板时,如果有模板参数带有默认值,对于这些带有默认值的参数,用户可以选择不提供
//具体类型。template<class T1, class T2, ..., class Tn>
class ClassName//类模板名
{//类成员变量和成员函数
};//类模板显式实例化
ClassName<具体类型1, 具体类型2, ..., 具体类型n> 变量名(构造参数列表);// 解析:
//1. 当定义的类模板的参数列表中的类型参数没有提供缺省值时,则我们在显式实例化类模板时,提供的
//具体类型参数个数必须与类模板定义中的类型参数个数相匹配,否则编译器会报错。
//2. 实例化类模板时,可以指定任意具体类型,包括但不限于基本数据类型(如int, double)和用
//户自定义类型(如类、结构体)。
//3. 变量名是您为显式实例化后的类实例所取的名称,它遵循C++变量命名规则。
//4. 构造参数列表仅在您需要调用非默认构造函数时提供。如果类模板定义了默认构造函数,并且您
//希望使用它,则可以省略构造参数列表。(1)有了类模板后,如何区分类名和类型
在C++中,类模板是一个蓝图,用于生成具体的类。类模板本身不是类型,但是它可以来创建类型,即通过提供具体的模板参数来把类模板实例化为一个类型。以下是如何区分类名(即类模板名)、类型(即类模板实例化后创建的类型):
-
类模板名(类名):在C++中,类模板名通常用于指示这是一个类模板,而不是一个具体的类型。例如,
MyClass是一个类模板名(类名)。 -
类模板实例化(类型):类模板实例化是通过将具体类型参数传递给模板来创建一个具体的类型。例如,
MyClass<int>是一个类模板实例化(类型),它是一个具体的类型。 -
类型:一旦类模板被实例化,它就变成了一个具体的类型。例如,
MyClass<int>变量名中的MyClass<int>是一个类型,你可以用它来声明变量、创建对象等。
#include <iostream>
using namespace std;//类模板定义
template <typename T>
class MyClass
{T value;
public:MyClass(T val) : value(val) {}//其他成员函数...
};//区分
//MyClass 是类模板名称(类名)
//MyClass<int> 是类型,由类模板实例化得到,可以用来声明变量或创建对象//使用类型
MyClass<int> myIntObject; //声明一个 MyClass<int> 类型的对象
MyClass<double> myDoubleObject; //声明一个 MyClass<double> 类型的对象//错误示例:不能直接使用类模板名称来声明对象
//MyClass myObject; //错误,因为 MyClass 是模板名称,不是类型(2)类名与类型在普通类和类模板中的区别
在使用 class 定义类时,对于普通类而言,类名本身就代表一种类型。例如,定义 class MyClass {};,这里的 MyClass 既是类名,也是类型
而对于类模板,类名和类型需要区分开来。类模板是一种通用的类定义,它可以根据不同的类型参数生成不同的具体类。以 template <class T> class Vector {}; 为例,Vector 是类模板的类名,它本身并不是一个具体的类型;而 Vector<int> 是使用 int 作为类型参数对 Vector 模板进行实例化后得到的具体类型。
(3)类模板不能隐式实例化,只能显示实例化的原因
- 类模板显式实例化后,它变成了一个具体的类型,这个类型可以用来声明变量和创建对象。显式实例化是必要的,因为类模板在定义时不包含具体类型信息,只有在实例化时才会填充这些信息。
- 由于类模板的成员变量和成员函数中存在使用模板参数的情况,我们只有在显式实例化类模板后才能知道模板参数的具体类型,进而确定成员变量的大小,并最终确定整个对象的大小,以便在定义对象时为它分配正确的内存空间。
- 函数模板可以通过隐式实例化,在函数调用时通过实参推导出模板参数的具体类型。然而,类模板没有类似的推导机制,因为类模板实例化(即对象的创建)不涉及传递参数来推导类型。因此,类模板需要显式实例化来指定模板参数的具体类型。
3.类模板的声明和定义分离
3.1.类模板的声明和定义必须在同一文件中
(1)案例:在头文件中声明,在源文件中定义,声明和定义不在同一文件中使得在编译时发生链接错误
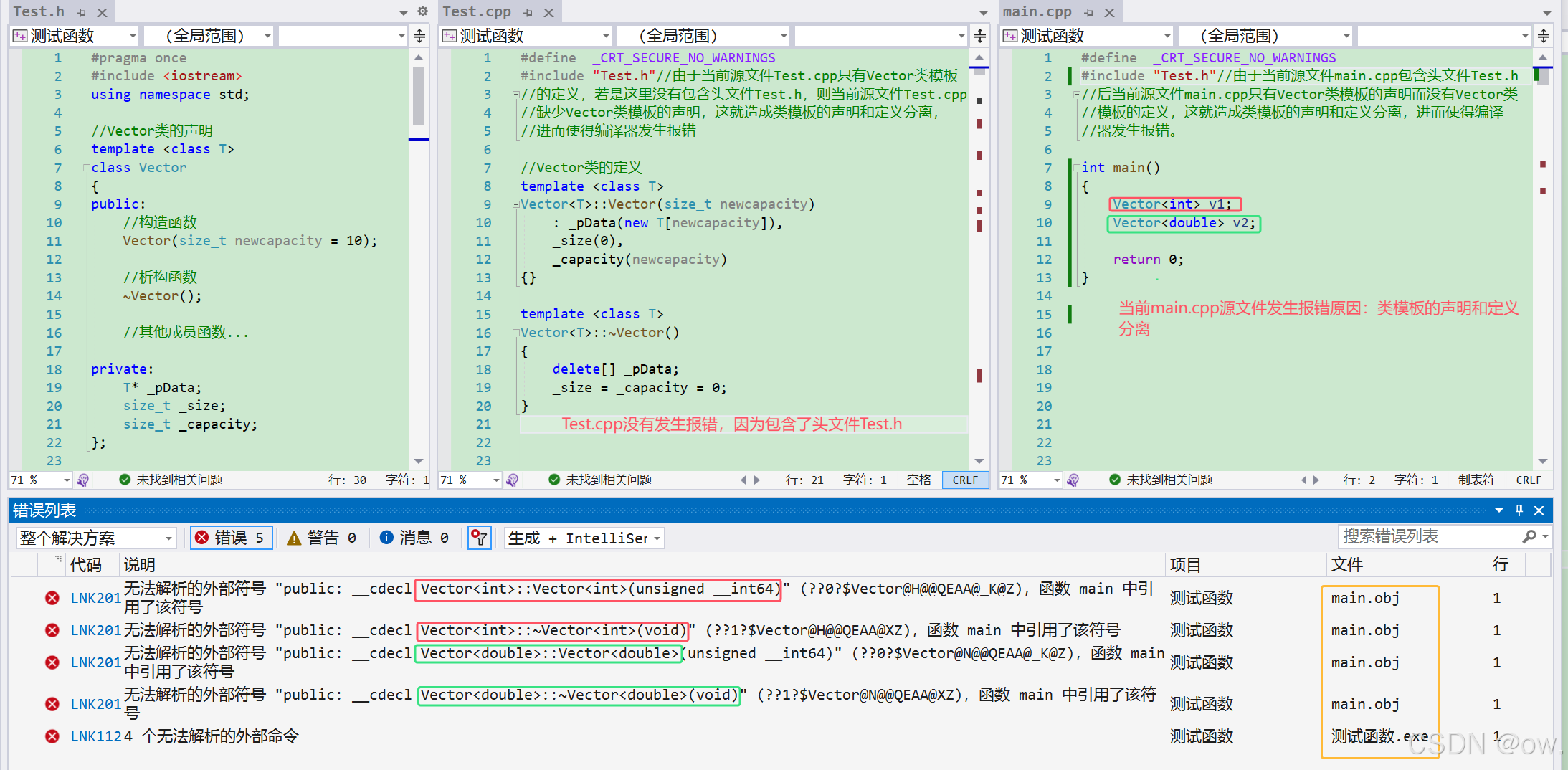
(2)类模板的声明和定义必须在同一文件的原因
C++编译器在编译时需要模板的定义来生成具体的模板实例。如果模板的定义不在声明所在的文件中,编译器在编译时可能无法找到模板的定义,从而无法实例化模板。这是因为模板不是像普通函数或类那样在编译时生成代码,而是根据模板参数在编译时生成。因此,模板的定义需要在使用模板的每个翻译单元中都是可见的。
3.2.普通类和类模板声明与定义分离的区别
(1)普通类
普通类可以将声明和定义分离,通常的做法是在头文件(.h 或 .hpp)中进行类的声明,而在源文件(.cpp)中进行类成员函数的定义。例如:
- 头文件
MyClass.h
class MyClass
{
public:MyClass();~MyClass();void print();
};
- 源文件
MyClass.cpp
#include "MyClass.h"
#include <iostream>MyClass::MyClass()
{//构造函数实现
}MyClass::~MyClass()
{//析构函数实现
}void MyClass::print()
{std::cout << "Hello, World!" << std::endl;
}(2)类模板
类模板同样可以进行声明和定义的分离,但与普通类不同的是,类模板的声明和定义必须放在同一个文件中。这是因为编译器在编译源文件时,需要知道模板会被实例化的具体类型才能生成对应的代码。如果将类模板的声明和定义分别放在 .h 和 .cpp 文件中,编译器在编译 .cpp 文件时,由于不知道模板会被实例化的具体类型,无法生成对应的代码,而在链接阶段又找不到对应的实例化代码,从而导致链接错误。
通常的做法是将类模板的声明和定义都放在头文件(.h)中,并且一般上面写声明,下面写定义。例如:
- 头文件
Vector.h
//注:小写的vector是C++库中提供的顺序表。但是下面代码中的大写的Vector什么都不是,
//大写的Vector只是用来和小写的vector进行区分。//动态顺序表
//注意:Vector不是具体的类,是编译器根据被实例化的类型生成具体类的模具
template<class T>
class Vector
{
public://构造函数Vector(size_t capacity = 10): _pData(new T[capacity]), _size(0), _capacity(capacity){}//自定义实现深拷贝构造函数//…………//析构函数~Vector();//使用析构函数演示:在类中声明,在类外定义。//插入函数void PushBack(const T& data);//删除函数void PopBack();//其他成员函数的声明//…………//统计栈存放有效数据个数size_t Size(){return _size;}//返回动态数组下标为pos位置的T类型数据T& operator[](size_t pos){assert(pos < _size);return _pData[pos];}private:T* _pData;//动态数组size_t _size;//记录栈存放有效数据的个数size_t _capacity;//记录栈最大容量
};//注意:类模板中函数放在类外进行定义时,需要加模板参数列表
template <class T>
Vector<T>::~Vector()
{if (_pData)delete[] _pData;_size = _capacity = 0;
}template <class T>
void Vector<T>::PushBack(const T& data)
{}template <class T>
void Vector<T>::PopBack()
{}//其他成员函数的定义
//…………类模板的成员函数在类外部定义的规则
当类模板的声明和定义分离时,在类外部定义成员函数之前必须加上模板参数列表。具体来说,要使用 template <class T>(这里的 T 是类型参数,可根据实际情况使用其他标识符)来表明这是一个模板函数。同时,要指定成员函数所属的具体类域,即使用 Vector<T>:: 来表示该成员函数属于 Vector 类模板以 T 为类型参数实例化后的类。例如,定义析构函数的语法为:
template <class T>
Vector<T>::~Vector()
{//析构函数的具体实现
}3.3.类模板的声明和定义在同一文件的几种写法
(1)写法1:在头文件中声明和定义,成员函数在类模板内部定义
注:在类模板内部定义成员函数时,成员函数无需带模板参数列表同时也不需要指定所在的类域。
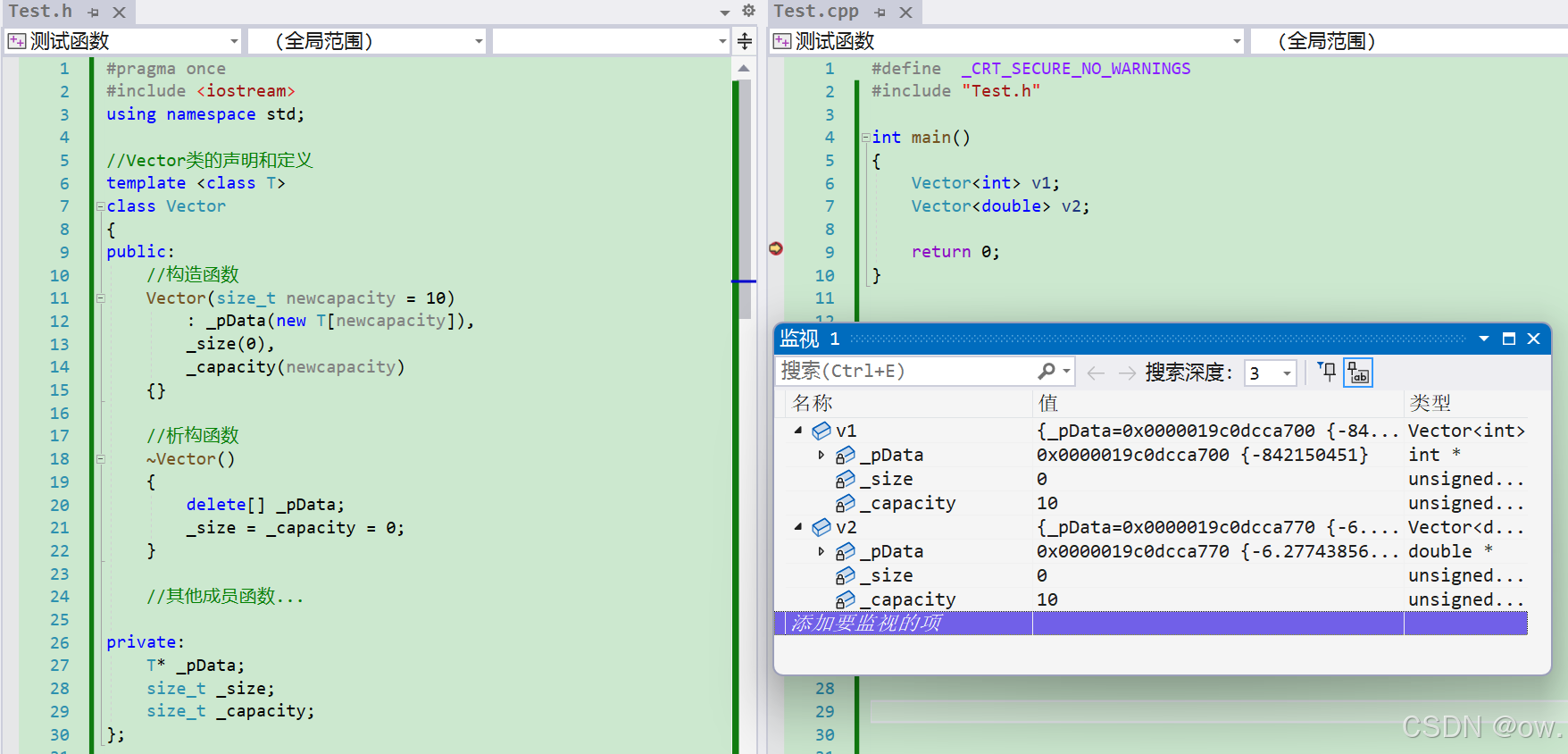
(2)写法2:在头文件中声明和定义,成员函数在类模板中定义外部定义
注意:成员函数在类模板外部定义时,每个成员函数都必须带上模板参数列表,并且要使用域作用限定符‘::’来明确指定成员函数所属的类域。需要注意的是,这里的类域是指类模板通过实例化所生成的具体类型的类域,例如对于类模板Vector<T>,其类域表示为Vector<T>::。

4.以栈为例,typedef 类型重命名不能解决容器存储不同数据类型的问题
(1)案例:在设计栈类时,我们常常希望栈能够存储不同类型的数据。然而,使用 typedef 进行类型重命名在解决栈类存储不同类型数据的问题上存在一定局限性。
(2)typedef 类型重命名及局限性
typedef 可以为类型定义别名,在一定程度上方便代码编写,但不能完全解决栈类存储不同类型数据的问题。示例代码如下:
//typedef int STDataType;
typedef double STDataType;
class Stack
{
private:STDataType* _a;size_t _top;size_t _capacity;
};int main()
{Stack st1; Stack st2; //解析:用 typedef 对类型重命名后再用类 Stack 定义的栈后,栈 st1、栈 st2 //只能同时存放 int 或者 double 类型的数据,做不到让栈 st1 存放 int 类型的//数据同时让栈 st2 存放 double 类型的数据。return 0;
}
在上述代码中,使用 typedef 为栈存放的数据类型取别名后,通过 Stack 类定义的栈对象 st1 和 st2 只能存储同一种类型的数据(如上述代码中只能存储 double 类型),无法同时存储不同类型(如 int 和 double)的数据。
(3)解决方式
①定义存放不同数据类型的栈类
通过分别定义不同数据类型的栈类,如 Stackint 和 Stackdouble,可以让不同的栈对象存储不同类型的数据。示例代码如下:
class Stackint
{
private:int* _a;size_t _top;size_t _capacity;
};class Stackdouble
{
private:double* _a;size_t _top;size_t _capacity;
};int main()
{Stackint st1; //栈 st1 存放 int 类型的数据Stackdouble st2; //栈 st2 存放 double 类型的数据return 0;
}
这种方式的缺点是代码冗余,当需要存储更多不同类型的数据时,需要定义更多的栈类。
②利用类模板解决
类模板是一种更灵活的解决方式,它可以根据不同的类型参数实例化出不同的类,从而实现栈类存储不同类型的数据。示例代码如下:
template<class T>
class Stack
{
public:// 构造函数Stack(int newcapacity = 4){_a = new T[newcapacity]; //即使 new 失败了,我们也不需要检查动态空间是否申请失败,因为 new 失败会抛异常。_top = 0;_capacity = newcapacity;}// 析构函数~Stack(){delete[] _a; //new[] 和 delete[] 要匹配使用来销毁指针 _a 指向的动态空间_capacity = _top = 0;_a = nullptr;}//其他成员函数…………private:T* _a;size_t _top;size_t _capacity;
};int main()
{//类模板的调用方式:类模板只能显示实例化调用Stack<int> st1; //栈 st1 存放 int 类型的数据Stack<double> st2; //栈 st2 存放 double 类型的数据return 0;
}
在上述代码中,通过类模板 Stack,可以根据不同的类型参数(如 int 和 double)实例化出不同的栈类,从而让 st1 存储 int 类型的数据,st2 存储 double 类型的数据。这种方式避免了代码冗余,提高了代码的可复用性。
相关文章:
泛型编程、函数模板、类模板
目录 一、泛型编程 1.泛型编程提出背景 1.1.代码复用案例解析 案例1:实现一个交换函数,并对不同类型参数进行函数重载 (1)调试 (2)代码解析 ①代码复用问题 ②泛型编程的解决方案 ③上面泛型Swap函数模版的优点 1.2.泛型编程提出背景 2.泛型编…...

【Vue3】浅谈setup语法糖
Vue3 的 setup 语法糖是通过 <script setup> 标签启用的特性,它是对 Composition API 的进一步封装,旨在简化组件的声明式写法,同时保留 Composition API 的逻辑组织能力。以下是其核心概念和原理分析: 一、<script setu…...

经验总结:使用vue3测试后端接口的模板
为了方便在开发中途,比较即时地,测试自己写的接口,是否有BUG,所以整理了这个测试模板。 效果就是可以通过自己编码,比较灵活,比较快得触发接口调用。 下边这个是最核心的模板,然后还有一个写axi…...

Vosk语音识别包
Vosk介绍 Vosk作为一款开源的离线语音识别工具包,其核心特点可归纳为以下五个方面,结合多篇技术文档的实践与分析 一、离线高效识别 完全脱离网络依赖:所有语音处理均在本地完成,无需云端数据传输,既保障隐私安全又…...

【欢迎来到Git世界】Github入门
241227 241227 241227 Hello World 参考:Hello World - GitHub 文档. 1.创建存储库 r e p o s i t o r y repository repository(含README.md) 仓库名需与用户名一致。 选择公共。 选择使用Readme初始化此仓库。 2.何时用分支…...

简洁的个人地址发布页HTML源码
源码介绍 简洁的个人地址发布页HTML源码,源码由HTMLCSSJS组成,记事本打开源码文件可以进行内容文字之类的修改,双击html文件可以本地运行效果 效果预览 源码获取 简洁的个人地址发布页HTML源码...

【VSCode】VSCode下载安装与配置极简描述
VSCode 参考网址:[Visual Studio Code Guide | GZTime’s Blog]. 下载安装 下载地址:Download Visual Studio Code - Mac, Linux, Windows. 注:推荐不更改安装位置,并且在附加任务中“其他”中的四项全部勾选,即将用…...

wav格式的音频压缩,WAV 转 MP3 VBR 体积缩减比为 13.5%、多个 MP3 格式音频合并为一个、文件夹存在则删除重建,不存在则直接建立
🥇 版权: 本文由【墨理学AI】原创首发、各位读者大大、敬请查阅、感谢三连 🎉 声明: 作为全网 AI 领域 干货最多的博主之一,❤️ 不负光阴不负卿 ❤️ 文章目录 问题一:wav格式的音频压缩为哪些格式,网络传输给用户播放…...

Linux权限 -- 开发工具(一)
文章目录 包管理器yumyum具体操作 Linux编辑器 - vim的使用vimvim的多模式 包管理器yum Linux中安装软件: 1.源码安装 2. 软件包安装 – rpm 3. 包管理器yum(centos) apt/apt-get(ubuntu) 为什么有包管理器? 包管理器会自动帮我们解决包依赖的问题 2. 什…...

leetcode_动态规划/递归 279**. 完全平方数
279. 完全平方数 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 …...

【leetcode】二分查找专题
文章目录 1.二分查找1.题目2.解题思路3. 解题代码 2.在排序数组中查找元素的第一个和最后一个位置1.题目2.算法原理3. 代码 3.x的平方根1.题目2.代码 4.搜索插入位置1.题目2.解题思路3.解题代码 5.山脉数组的索引1.题目2.解题思路3. 代码 6.寻找峰值1.题目2.解题思路3.代码 7. …...
与Stable Diffusion(SD)对比分析)
腾讯混元文生图大模型(Hunyuan-DiT)与Stable Diffusion(SD)对比分析
腾讯混元文生图大模型(Hunyuan-DiT)与Stable Diffusion(SD)对比分析 腾讯混元文生图大模型(Hunyuan-DiT)与Stable Diffusion(SD)作为当前文生图领域的两大代表模型,各自…...

《Python实战进阶》No 7: 一个AI大模型聊天室的构建-基于WebSocket 实时通信开发实战
第7集: 一个AI大模型聊天室的构建-基于WebSocket 实时通信开发实战 在现代 Web 开发中,实时通信已经成为许多应用的核心需求。无论是聊天应用、股票行情推送,还是多人协作工具,WebSocket 都是实现高效实时通信的最佳选择之一。本…...

vector习题
完数和盈数 题目 完数VS盈数_牛客题霸_牛客网 一个数如果恰好等于它的各因子(该数本身除外)之和,如:6321。则称其为“完数”;若因子之和大于该数,则称其为“盈数”。 求出2到60之间所有“完数”和“盈数”。 输入描述ÿ…...

unity学习59: 滑动条 和 滚动条 滚动区域
目录 1 滑动条 slider 1.1 创建slider 1.2 构成的子物体 1.2.1 找到 某个UI的 方法 1.3 构成的component,主体就是 slider 2 核心属性 2.1 value 2.2 direction 3 作用 3.1 由于是fill back 可以实现血条效果 3.2 可以取得 slider.value 数值 1 滑动条…...

基于vue框架的游戏博客网站设计iw282(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,博客信息,资源共享,游戏视频,游戏照片 开题报告内容 基于FlaskVue框架的游戏博客网站设计开题报告 一、项目背景与意义 随着互联网技术的飞速发展和游戏产业的不断壮大,游戏玩家对游戏资讯、攻略、评测等内容的需求日…...

UWB人员定位:精准、高效、安全的智能管理解决方案
在现代企业管理、工业生产、安全监测等领域,UWB(超宽带)人员定位系统正逐步成为高精度定位技术的首选。相较于传统的GPS、Wi-Fi、蓝牙等定位方式,UWB具备厘米级高精度、低延迟、高安全性、抗干扰强等突出优势,能够实现…...

etcd 3.15 三节点集群管理指南
本文档旨在提供 etcd 3.15 版本的三节点集群管理指南,涵盖节点的新增、删除、状态检查、数据库备份和恢复等操作。 1. 环境准备 1.1 系统要求 操作系统:Linux(推荐 Ubuntu 18.04 或 CentOS 7) 内存:至少 2GB 磁盘&a…...

在ubuntu 24.04.2 通过 Kubeadm 安装 Kubernetes v1.31.6
文章目录 1. 简介2. 准备3. 配置 containerd4. kubeadm 安装集群5. 安装网络 calico 插件 1. 简介 本指南介绍了如何在 Ubuntu 24.04.2 LTS 上安装和配置 Kubernetes 1.31.6 集群,包括容器运行时 containerd 的安装与配置,以及使用 kubeadm 进行集群初始…...

DO-254航空标准飞行器电机控制器设计注意事项
DO-254航空标准飞行器电机控制器设计注意事项 1.核心要求1.1 设计保证等级(DAL)划分1.2生命周期管理1.3验证与确认2.电机控制器硬件设计的关键注意事项2.1需求管理与可追溯性2.2冗余与容错设计2.3验证与确认策略2.4元器件选型与管理2.5环境适应性设计2.6文档与配置管理3.应用…...

【Pandas】pandas Series fillna
Pandas2.2 Series Computations descriptive stats 方法描述Series.backfill(*[, axis, inplace, limit, …])用于填充 Series 中缺失值(NaN)的方法Series.bfill(*[, axis, inplace, limit, …])用于填充 Series 中缺失值(NaN)的…...

文字描边实现内黄外绿效果
网页使用 <!DOCTYPE html> <html> <head> <style> .text-effect {color: #ffd700; /* 黄色文字 */-webkit-text-stroke: 2px #008000; /* 绿色描边(兼容Webkit内核) */text-stroke: 2px #008000; /* 标准语法 *…...

解决Deepseek“服务器繁忙,请稍后再试”问题,基于硅基流动和chatbox的解决方案
文章目录 前言操作步骤步骤1:注册账号步骤2:在线体验步骤3:获取API密钥步骤4:安装chatbox步骤5:chatbox设置 价格方面 前言 最近在使用DeepSeek时,开启深度思考功能后,频繁遇到“服务器繁忙&am…...

python-leetcode-使用最小花费爬楼梯
746. 使用最小花费爬楼梯 - 力扣(LeetCode) 解法 1:动态规划(O(n) 时间,O(n) 空间) class Solution:def minCostClimbingStairs(self, cost: List[int]) -> int:n len(cost)dp [0] * (n 1) # 额外多…...

图书数据采集:使用Python爬虫获取书籍详细信息
文章目录 一、准备工作1.1 环境搭建1.2 确定目标网站1.3 分析目标网站二、采集豆瓣读书网站三、处理动态加载的内容四、批量抓取多本书籍信息五、反爬虫策略与应对方法六、数据存储与管理七、总结在数字化时代,图书信息的管理和获取变得尤为重要。通过编写Python爬虫,可以从各…...

ChatGPT 提示词框架
作为一个资深安卓开发工程师,我们在日常开发中经常会用到 ChatGPT 来提升开发效率,比如代码优化、bug 排查、生成单元测试等。 但要想真正发挥 ChatGPT 的潜力,我们需要掌握一些提示词(Prompt)的编写技巧,并…...

【构建工具】Gradle 8中Android BuildConfig的变化与开启方法
随着Gradle 8的发布,Android开发者需要注意一个重要变化:BuildConfig类的生成现在默认被关闭了!!!。这个变化可能会影响许多依赖于BuildConfig的项目(别问,问就是我也被影响了,多好用…...

性能测试测试策略制定|知名软件测评机构经验分享
随着互联网产品的普及,产品面对的用户量级也越来越大,能抗住指数级增长的瞬间访问量以及交易量是保障购物体验是否顺畅的至关重要的一环,而我们的性能测试恰恰也是为此而存在的。 性能测试是什么呢?性能测试要怎么测呢?…...

SAP-ABAP:SAP数据库视图(Database View)详解-创建
在SAP系统中,数据库视图(Database View) 是一种基于物理数据库表的虚拟表,通过关联多个表(使用INNER JOIN)生成逻辑数据集。它存储在数据库中,但本身不存储数据,仅通过查询动态生成结…...

BUG: 解决新版本SpringBoot3.4.3在创建项目时勾选lombok但无法使用的问题
前言 当使用Spring Boot 3.4.3创建新项目时,即使正确勾选Lombok依赖,编译时仍出现找不到符号的错误,但代码中Lombok注解的使用完全正确。 原因 Spring Boot 3.4.3在自动生成的pom.xml中新增了maven-compiler-plugin的配置,该插件…...