Llama 2中的Margin Loss:为何更高的Margin导致更大的Loss和梯度?
Llama 2中的Margin Loss:为何更高的Margin导致更大的Loss和梯度?
在《Llama 2: Open Foundation and Fine-Tuned Chat Models》论文中,作者在强化学习与人类反馈(RLHF)的Reward Model训练中引入了Margin Loss的概念,相较于传统的InstructGPT方法有所创新。下面有一段关键描述:
“For instance, returning a higher margin via ‘m( r)’ will make the difference between the reward of the preferred and rejected responses smaller, resulting in a larger loss, which in turn results in larger gradients, and consequently model changes, during the policy gradient update.”
source: https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives
这段话涉及Margin Loss的逻辑:为什么更高的margin会导致更大的loss?为什么更大的loss会导致更大的梯度?本文将以中文博客的形式,详细解析这个过程的数学原理和直观意义,帮助你理解其中的因果关系。
1. Margin Loss的基本概念
在RLHF的Reward Model训练中,目标是让模型学会根据人类偏好对响应进行评分。对于一对响应 ( y c y_c yc )(优选响应,chosen)和 ( y r y_r yr )(拒绝响应,rejected),Reward Model ( r θ ( x , y ) r_\theta(x, y) rθ(x,y) ) 输出标量奖励值,要求 ( r θ ( x , y c ) > r θ ( x , y r ) r_\theta(x, y_c) > r_\theta(x, y_r) rθ(x,yc)>rθ(x,yr) )。
传统损失函数
传统的InstructGPT使用基于交叉熵的排名损失:这个loss是如何推导的,请参考笔者的另一篇博客:RLHF中的Reward Model是如何训练的?原理与代码实现
L ( θ ) = − log ( σ ( r θ ( x , y c ) − r θ ( x , y r ) ) ) L(\theta) = -\log\left(\sigma\left(r_\theta(x, y_c) - r_\theta(x, y_r)\right)\right) L(θ)=−log(σ(rθ(x,yc)−rθ(x,yr)))
- ( σ ( z ) = 1 1 + exp ( − z ) \sigma(z) = \frac{1}{1 + \exp(-z)} σ(z)=1+exp(−z)1 ) 是sigmoid函数,将差值映射为0到1的概率。
- ( r θ ( x , y c ) − r θ ( x , y r ) r_\theta(x, y_c) - r_\theta(x, y_r) rθ(x,yc)−rθ(x,yr) ) 是优选和拒绝响应的奖励差值。
- 损失的目标是使 ( r θ ( x , y c ) − r θ ( x , y r ) r_\theta(x, y_c) - r_\theta(x, y_r) rθ(x,yc)−rθ(x,yr) ) 尽可能大,从而让 ( σ \sigma σ ) 接近1,损失接近0。
Llama 2的Margin Loss
Llama 2在此基础上增加了margin参数 ( m ( r ) m(r) m(r) ):
L ( θ ) = − log ( σ ( r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) ) ) L(\theta) = -\log\left(\sigma\left(r_\theta(x, y_c) - r_\theta(x, y_r) - m(r)\right)\right) L(θ)=−log(σ(rθ(x,yc)−rθ(x,yr)−m(r)))
- ( m ( r ) m(r) m(r) ) 是人类标注的偏好程度(margin label),比如“显著更好”(significantly better)对应较大的 ( m ( r ) m(r) m(r) ),而“略好”(negligibly better)对应较小的 ( m ( r ) m(r) m(r) )。
- ( m ( r ) m(r) m(r) ) 是一个正值,表示优选响应比拒绝响应“应该”高出的最小奖励差距。
2. 为什么更高的Margin导致更大的Loss?
直观理解
- ( r θ ( x , y c ) − r θ ( x , y r ) r_\theta(x, y_c) - r_\theta(x, y_r) rθ(x,yc)−rθ(x,yr) ) 是模型当前预测的奖励差值。
- ( m ( r ) m(r) m(r) ) 是人类期望的“理想差值”。
- 损失函数中的 ( r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) r_\theta(x, y_c) - r_\theta(x, y_r) - m(r) rθ(x,yc)−rθ(x,yr)−m(r) ) 表示“实际差值”与“期望差值”的差距。
当 ( m ( r ) m(r) m(r) ) 变大时:
- 如果模型的预测差值 ( r θ ( x , y c ) − r θ ( x , y r ) r_\theta(x, y_c) - r_\theta(x, y_r) rθ(x,yc)−rθ(x,yr) ) 不变,减去一个更大的 ( m ( r ) m(r) m(r) ) 会使 ( r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) r_\theta(x, y_c) - r_\theta(x, y_r) - m(r) rθ(x,yc)−rθ(x,yr)−m(r) ) 变小(甚至可能变成负值)。
- ( σ \sigma σ ) 函数的值随之变小(因为 ( σ ( z ) \sigma(z) σ(z) ) 是单调递增的,( z z z ) 减小则 ( σ ( z ) \sigma(z) σ(z) ) 减小)。
- ( − log ( σ ( z ) ) -\log(\sigma(z)) −log(σ(z)) ) 会变大,因为 ( σ ( z ) \sigma(z) σ(z) ) 越小,对数的值越大,负号使损失增加。
简单来说,更高的 ( m ( r ) m(r) m(r) ) 提高了对模型的要求。如果模型的预测差值没有达到这个更高的标准,损失就会增大。
数学推导
设:
- z = r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) z = r_\theta(x, y_c) - r_\theta(x, y_r) - m(r) z=rθ(x,yc)−rθ(x,yr)−m(r)。
损失函数为:
L = − log ( σ ( z ) ) = − log ( 1 1 + exp ( − z ) ) L = -\log(\sigma(z)) = -\log\left(\frac{1}{1 + \exp(-z)}\right) L=−log(σ(z))=−log(1+exp(−z)1)
- 当 ( m ( r ) m(r) m(r) ) 增加时,( z z z ) 减小。
- ( exp ( − z ) \exp(-z) exp(−z) ) 增大(因为 ( − z -z −z ) 变大),使 ( 1 + exp ( − z ) 1 + \exp(-z) 1+exp(−z) ) 增大。
- ( σ ( z ) = 1 1 + exp ( − z ) \sigma(z) = \frac{1}{1 + \exp(-z)} σ(z)=1+exp(−z)1 ) 减小。
- ( − log ( σ ( z ) ) -\log(\sigma(z)) −log(σ(z)) ) 增大,即损失 ( L L L ) 增大。
举例说明
假设:
- ( r θ ( x , y c ) = 2 r_\theta(x, y_c) = 2 rθ(x,yc)=2 ),( r θ ( x , y r ) = 1 r_\theta(x, y_r) = 1 rθ(x,yr)=1 ),预测差值 ( r θ ( x , y c ) − r θ ( x , y r ) = 1 r_\theta(x, y_c) - r_\theta(x, y_r) = 1 rθ(x,yc)−rθ(x,yr)=1。
- 情况1:( m ( r ) = 0 m(r) = 0 m(r)=0 )(无margin):
- ( z = 1 − 0 = 1 z = 1 - 0 = 1 z=1−0=1 ),
- ( σ ( 1 ) = 1 1 + exp ( − 1 ) ≈ 0.731 \sigma(1) = \frac{1}{1 + \exp(-1)} \approx 0.731 σ(1)=1+exp(−1)1≈0.731 ),
- ( L = − log ( 0.731 ) ≈ 0.313 L = -\log(0.731) \approx 0.313 L=−log(0.731)≈0.313 )。
- 情况2:( m ( r ) = 0.5 m(r) = 0.5 m(r)=0.5 )(中等margin):
- ( z = 1 − 0.5 = 0.5 z = 1 - 0.5 = 0.5 z=1−0.5=0.5 ),
- ( σ ( 0.5 ) ≈ 0.622 \sigma(0.5) \approx 0.622 σ(0.5)≈0.622 ),
- ( L = − log ( 0.622 ) ≈ 0.475 L = -\log(0.622) \approx 0.475 L=−log(0.622)≈0.475 )。
- 情况3:( m ( r ) = 1 m(r) = 1 m(r)=1 )(高margin):
- ( z = 1 − 1 = 0 z = 1 - 1 = 0 z=1−1=0 ),
- ( σ ( 0 ) = 0.5 \sigma(0) = 0.5 σ(0)=0.5 ),
- ( L = − log ( 0.5 ) ≈ 0.693 L = -\log(0.5) \approx 0.693 L=−log(0.5)≈0.693 )。
可以看到,( m ( r ) m(r) m(r) ) 从0增加到1,损失从0.313增加到0.693,验证了更高的margin导致更大的loss。
3. 为什么更大的Loss会导致更大的梯度?
梯度的定义
在神经网络中,梯度是损失函数 ( L L L ) 对模型参数 ( θ \theta θ ) 的偏导数:
∇ θ L = ∂ L ∂ θ \nabla_\theta L = \frac{\partial L}{\partial \theta} ∇θL=∂θ∂L
梯度的大小决定了参数更新的步幅(通过学习率调整)。我们需要分析 ( L L L ) 如何通过 ( z z z ) 影响 ( θ \theta θ )。
计算梯度
损失函数:
L = − log ( σ ( z ) ) , z = r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) L = -\log(\sigma(z)),\quad z = r_\theta(x, y_c) - r_\theta(x, y_r) - m(r) L=−log(σ(z)),z=rθ(x,yc)−rθ(x,yr)−m(r)
-
首先计算 ( ∂ L ∂ z \frac{\partial L}{\partial z} ∂z∂L ):
- ( σ ( z ) = 1 1 + exp ( − z ) \sigma(z) = \frac{1}{1 + \exp(-z)} σ(z)=1+exp(−z)1 ),
- ( d σ ( z ) d z = σ ( z ) ⋅ ( 1 − σ ( z ) ) \frac{d\sigma(z)}{dz} = \sigma(z) \cdot (1 - \sigma(z)) dzdσ(z)=σ(z)⋅(1−σ(z)) )(sigmoid的导数),
- ( L = − log ( σ ( z ) ) L = -\log(\sigma(z)) L=−log(σ(z)) ),
- ( ∂ L ∂ z = − 1 σ ( z ) ⋅ d σ ( z ) d z = − σ ( z ) ⋅ ( 1 − σ ( z ) ) σ ( z ) = − ( 1 − σ ( z ) ) \frac{\partial L}{\partial z} = -\frac{1}{\sigma(z)} \cdot \frac{d\sigma(z)}{dz} = -\frac{\sigma(z) \cdot (1 - \sigma(z))}{\sigma(z)} = -(1 - \sigma(z)) ∂z∂L=−σ(z)1⋅dzdσ(z)=−σ(z)σ(z)⋅(1−σ(z))=−(1−σ(z)) )。
-
然后计算 ( ∂ z ∂ θ \frac{\partial z}{\partial \theta} ∂θ∂z ):
- ( z = r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) z = r_\theta(x, y_c) - r_\theta(x, y_r) - m(r) z=rθ(x,yc)−rθ(x,yr)−m(r) ),
- ( ∂ z ∂ θ = ∂ r θ ( x , y c ) ∂ θ − ∂ r θ ( x , y r ) ∂ θ \frac{\partial z}{\partial \theta} = \frac{\partial r_\theta(x, y_c)}{\partial \theta} - \frac{\partial r_\theta(x, y_r)}{\partial \theta} ∂θ∂z=∂θ∂rθ(x,yc)−∂θ∂rθ(x,yr) )(( m ( r ) m(r) m(r) ) 是常数,对 ( θ \theta θ ) 无导数)。
-
综合得梯度:
∂ L ∂ θ = ∂ L ∂ z ⋅ ∂ z ∂ θ = − ( 1 − σ ( z ) ) ⋅ ( ∂ r θ ( x , y c ) ∂ θ − ∂ r θ ( x , y r ) ∂ θ ) \frac{\partial L}{\partial \theta} = \frac{\partial L}{\partial z} \cdot \frac{\partial z}{\partial \theta} = -(1 - \sigma(z)) \cdot \left(\frac{\partial r_\theta(x, y_c)}{\partial \theta} - \frac{\partial r_\theta(x, y_r)}{\partial \theta}\right) ∂θ∂L=∂z∂L⋅∂θ∂z=−(1−σ(z))⋅(∂θ∂rθ(x,yc)−∂θ∂rθ(x,yr))
更高的Margin如何影响梯度
- 当 ( m ( r ) m(r) m(r) ) 增加时,( z z z ) 减小,( σ ( z ) \sigma(z) σ(z) ) 减小。
- ( 1 − σ ( z ) 1 - \sigma(z) 1−σ(z) ) 增大(因为 ( σ ( z ) \sigma(z) σ(z) ) 接近0时,( 1 − σ ( z ) 1 - \sigma(z) 1−σ(z) ) 接近1)。
- ( − ( 1 − σ ( z ) ) -(1 - \sigma(z)) −(1−σ(z)) ) 的绝对值增大(负值变更大),使梯度的绝对值 ( ∣ ∂ L ∂ θ ∣ |\frac{\partial L}{\partial \theta}| ∣∂θ∂L∣ ) 增大。
举例验证
继续上例:
- ( m ( r ) = 0 m(r) = 0 m(r)=0 ):( z = 1 z = 1 z=1 ),( σ ( 1 ) ≈ 0.731 \sigma(1) \approx 0.731 σ(1)≈0.731 ),( 1 − σ ( 1 ) ≈ 0.269 1 - \sigma(1) \approx 0.269 1−σ(1)≈0.269 ),
- 梯度因子 ( − ( 1 − σ ( z ) ) ≈ − 0.269 -(1 - \sigma(z)) \approx -0.269 −(1−σ(z))≈−0.269 )。
- ( m ( r ) = 1 m(r) = 1 m(r)=1 ):( z = 0 z = 0 z=0 ),( σ ( 0 ) = 0.5 \sigma(0) = 0.5 σ(0)=0.5 ),( 1 − σ ( 0 ) = 0.5 1 - \sigma(0) = 0.5 1−σ(0)=0.5 ),
- 梯度因子 ( − ( 1 − σ ( z ) ) = − 0.5 -(1 - \sigma(z)) = -0.5 −(1−σ(z))=−0.5 )。
梯度绝对值从0.269增加到0.5,说明更高的 ( m ( r ) m(r) m(r) ) 导致更大的梯度。
4. 逻辑总结与直观解释
为什么更高的Margin导致更大的Loss?
- ( m ( r ) m(r) m(r) ) 是一个“门槛”,表示人类期望的奖励差距。
- 当 ( m ( r ) m(r) m(r) ) 更高时,模型的预测差值 ( r θ ( x , y c ) − r θ ( x , y r ) r_\theta(x, y_c) - r_\theta(x, y_r) rθ(x,yc)−rθ(x,yr) ) 如果没跟上这个门槛,( z z z ) 变小,( σ ( z ) \sigma(z) σ(z) ) 变小,损失变大。
- 这就像考试:如果及格线从60分提高到80分,而你还是考70分,差距更大,得分(损失的反面)更低。
为什么更大的Loss导致更大的梯度?
- 损失变大意味着模型当前预测与目标偏离更多,梯度(误差的导数)自然更大。
- 更大的梯度推动参数更新更大幅度,使 ( r θ ( x , y c ) r_\theta(x, y_c) rθ(x,yc) ) 更快增加,( r θ ( x , y r ) r_\theta(x, y_r) rθ(x,yr) ) 更快减小,满足更高的 ( m ( r ) m(r) m(r) )。
整体逻辑
- 高 ( m ( r ) m(r) m(r) ) → 小 ( z z z ) → 小 ( σ ( z ) \sigma(z) σ(z) ) → 大 ( L L L ) → 大梯度 → 大更新。
- 这是Margin Loss的核心:通过引入偏好程度,放大模型的学习信号,让奖励差值更好地反映人类的主观判断。
5. 实际意义
在Llama 2中,加入 ( m ( r ) m(r) m(r) ) 的好处是:
- 区分偏好强度:不仅知道 ( y c > y r y_c > y_r yc>yr ),还能反映“多好”(如“显著好” vs “略好”)。
- 增强训练信号:更高的 ( m ( r ) m(r) m(r) ) 迫使模型更快调整,确保奖励差值与人类期望一致。
- 提升模型质量:更大的梯度加速收敛,使Reward Model更准确地捕捉偏好。
6. 总结
Margin Loss通过引入 ( m ( r ) m(r) m(r) ),将人类偏好的强度融入损失函数。更高的 ( m ( r ) m(r) m(r) ) 提高了对奖励差值的要求,若模型未达标,损失增大;损失增大则放大梯度,推动模型更快学习。这个机制既直观又高效,是Llama 2在RLHF中改进Reward Model的关键一步。希望这篇博客能解开你的疑惑!如果还有问题,欢迎继续探讨。
是的,在这个上下文中,“梯度的增大”指的是梯度的绝对值增大。让我详细解释一下这个问题,并以中文博客的形式进一步澄清这个概念,确保你对“梯度增大”的含义及其背后的逻辑有全面的理解。
梯度增大指的是梯度的绝对值增大吗?
在讨论Llama 2中Margin Loss的梯度计算时,我们提到更高的 ( m ( r ) m(r) m(r) ) 会导致“更大的梯度”。你的问题是:这里的“梯度增大”是否特指梯度的绝对值增大?答案是肯定的。下面我们将逐步解析这个问题,从数学推导到直观理解,解答你的疑问。
1. 梯度的定义与方向
在神经网络中,梯度 ( ∇ θ L \nabla_\theta L ∇θL ) 是损失函数 ( L L L ) 对模型参数 ( θ \theta θ ) 的偏导数:
∇ θ L = ∂ L ∂ θ \nabla_\theta L = \frac{\partial L}{\partial \theta} ∇θL=∂θ∂L
- 梯度是一个向量:它包含多个分量,每个分量对应 ( θ \theta θ ) 中的一个参数。
- 大小与方向:
- 大小:梯度的模(magnitude),即 ( ∣ ∇ θ L ∣ = ∑ i ( ∂ L ∂ θ i ) 2 |\nabla_\theta L| = \sqrt{\sum_i \left(\frac{\partial L}{\partial \theta_i}\right)^2} ∣∇θL∣=∑i(∂θi∂L)2 )。
- 方向:指向损失增加最快的方向。
- 训练中的作用:优化器(如Adam)使用梯度的负方向(( − ∇ θ L -\nabla_\theta L −∇θL ))更新参数,以减小损失。
当我们说“梯度增大”时,通常指的是梯度向量的大小(即绝对值或模)变大,因为这直接影响参数更新的幅度。
2. Margin Loss中的梯度表达式
在Llama 2的Margin Loss中,损失函数为:
L = − log ( σ ( r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) ) ) L = -\log\left(\sigma\left(r_\theta(x, y_c) - r_\theta(x, y_r) - m(r)\right)\right) L=−log(σ(rθ(x,yc)−rθ(x,yr)−m(r)))
定义:
z = r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) z = r_\theta(x, y_c) - r_\theta(x, y_r) - m(r) z=rθ(x,yc)−rθ(x,yr)−m(r)
梯度计算为:
∂ L ∂ θ = ∂ L ∂ z ⋅ ∂ z ∂ θ \frac{\partial L}{\partial \theta} = \frac{\partial L}{\partial z} \cdot \frac{\partial z}{\partial \theta} ∂θ∂L=∂z∂L⋅∂θ∂z
其中:
- ( ∂ L ∂ z = − ( 1 − σ ( z ) ) \frac{\partial L}{\partial z} = -(1 - \sigma(z)) ∂z∂L=−(1−σ(z)) )(上一节推导)。
- ( ∂ z ∂ θ = ∂ r θ ( x , y c ) ∂ θ − ∂ r θ ( x , y r ) ∂ θ \frac{\partial z}{\partial \theta} = \frac{\partial r_\theta(x, y_c)}{\partial \theta} - \frac{\partial r_\theta(x, y_r)}{\partial \theta} ∂θ∂z=∂θ∂rθ(x,yc)−∂θ∂rθ(x,yr) )。
完整梯度:
∂ L ∂ θ = − ( 1 − σ ( z ) ) ⋅ ( ∂ r θ ( x , y c ) ∂ θ − ∂ r θ ( x , y r ) ∂ θ ) \frac{\partial L}{\partial \theta} = -(1 - \sigma(z)) \cdot \left(\frac{\partial r_\theta(x, y_c)}{\partial \theta} - \frac{\partial r_\theta(x, y_r)}{\partial \theta}\right) ∂θ∂L=−(1−σ(z))⋅(∂θ∂rθ(x,yc)−∂θ∂rθ(x,yr))
- 梯度因子:( − ( 1 − σ ( z ) ) -(1 - \sigma(z)) −(1−σ(z)) ) 是一个标量,始终为负值(因为 ( 0 < σ ( z ) < 1 0 < \sigma(z) < 1 0<σ(z)<1 ))。
- 方向部分:( ∂ r θ ( x , y c ) ∂ θ − ∂ r θ ( x , y r ) ∂ θ \frac{\partial r_\theta(x, y_c)}{\partial \theta} - \frac{\partial r_\theta(x, y_r)}{\partial \theta} ∂θ∂rθ(x,yc)−∂θ∂rθ(x,yr) ) 是一个向量,决定了梯度的方向。
3. 更高的 ( m ( r ) m(r) m(r) ) 如何影响梯度?
影响梯度的大小
- 当 ( m ( r ) m(r) m(r) ) 增加时:
- ( z = r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) z = r_\theta(x, y_c) - r_\theta(x, y_r) - m(r) z=rθ(x,yc)−rθ(x,yr)−m(r) ) 减小。
- ( σ ( z ) \sigma(z) σ(z) ) 减小(sigmoid函数单调递增)。
- ( 1 − σ ( z ) 1 - \sigma(z) 1−σ(z) ) 增大。
- ( − ( 1 − σ ( z ) ) -(1 - \sigma(z)) −(1−σ(z)) ) 的绝对值增大(负值的幅度变大)。
例如:
- ( m ( r ) = 0 m(r) = 0 m(r)=0 ):( z = 1 z = 1 z=1 ),( σ ( 1 ) ≈ 0.731 \sigma(1) \approx 0.731 σ(1)≈0.731 ),( − ( 1 − σ ( 1 ) ) ≈ − 0.269 -(1 - \sigma(1)) \approx -0.269 −(1−σ(1))≈−0.269 )。
- ( m ( r ) = 1 m(r) = 1 m(r)=1 ):( z = 0 z = 0 z=0 ),( σ ( 0 ) = 0.5 \sigma(0) = 0.5 σ(0)=0.5 ),( − ( 1 − σ ( 0 ) ) = − 0.5 -(1 - \sigma(0)) = -0.5 −(1−σ(0))=−0.5 )。
标量因子 ( − ( 1 − σ ( z ) ) -(1 - \sigma(z)) −(1−σ(z)) ) 的绝对值从0.269增加到0.5。
梯度的绝对值
梯度的模为:
∣ ∂ L ∂ θ ∣ = ∣ − ( 1 − σ ( z ) ) ∣ ⋅ ∣ ∂ r θ ( x , y c ) ∂ θ − ∂ r θ ( x , y r ) ∂ θ ∣ \left|\frac{\partial L}{\partial \theta}\right| = \left|-(1 - \sigma(z))\right| \cdot \left|\frac{\partial r_\theta(x, y_c)}{\partial \theta} - \frac{\partial r_\theta(x, y_r)}{\partial \theta}\right| ∂θ∂L =∣−(1−σ(z))∣⋅ ∂θ∂rθ(x,yc)−∂θ∂rθ(x,yr)
- ( ∣ − ( 1 − σ ( z ) ) ∣ = 1 − σ ( z ) |-(1 - \sigma(z))| = 1 - \sigma(z) ∣−(1−σ(z))∣=1−σ(z) )(因为 ( − ( 1 − σ ( z ) ) < 0 -(1 - \sigma(z)) < 0 −(1−σ(z))<0 ))。
- ( ∂ r θ ( x , y c ) ∂ θ − ∂ r θ ( x , y r ) ∂ θ \frac{\partial r_\theta(x, y_c)}{\partial \theta} - \frac{\partial r_\theta(x, y_r)}{\partial \theta} ∂θ∂rθ(x,yc)−∂θ∂rθ(x,yr) ) 是模型内部计算的梯度向量,其大小取决于当前参数和输入。
当 ( m ( r ) m(r) m(r) ) 增加时,( 1 − σ ( z ) 1 - \sigma(z) 1−σ(z) ) 增大,直接导致 ( ∣ ∂ L ∂ θ ∣ \left|\frac{\partial L}{\partial \theta}\right| ∂θ∂L ) 增大。这里的“梯度增大”正是指梯度向量的绝对值(模)变大。
方向是否改变?
- ( − ( 1 − σ ( z ) ) -(1 - \sigma(z)) −(1−σ(z)) ) 只影响梯度的大小(标量缩放),不改变方向。
- 方向由 ( ∂ r θ ( x , y c ) ∂ θ − ∂ r θ ( x , y r ) ∂ θ \frac{\partial r_\theta(x, y_c)}{\partial \theta} - \frac{\partial r_\theta(x, y_r)}{\partial \theta} ∂θ∂rθ(x,yc)−∂θ∂rθ(x,yr) ) 决定,与 ( m ( r ) m(r) m(r) ) 无关。
因此,“梯度增大”特指绝对值增大,方向保持一致。
4. 为什么关注绝对值?
在训练过程中,梯度的大小(绝对值)决定了参数更新的幅度:
- 更新公式:( θ ← θ − η ⋅ ∇ θ L \theta \leftarrow \theta - \eta \cdot \nabla_\theta L θ←θ−η⋅∇θL )(( η \eta η) 是学习率)。
- ( ∣ ∇ θ L ∣ |\nabla_\theta L| ∣∇θL∣ ) 越大,参数变化越大。
更高的 ( m ( r ) m(r) m(r) ) 使 ( ∣ ∇ θ L ∣ |\nabla_\theta L| ∣∇θL∣ ) 增大,意味着:
- 模型感知到当前预测与人类期望的差距更大。
- 需要更大幅度调整参数,使 ( r θ ( x , y c ) r_\theta(x, y_c) rθ(x,yc) ) 增加,( r θ ( x , y r ) r_\theta(x, y_r) rθ(x,yr) ) 减小,以满足更高的margin。
5. 举例验证
继续之前的例子:
-
( r θ ( x , y c ) = 2 r_\theta(x, y_c) = 2 rθ(x,yc)=2 ),( r θ ( x , y r ) = 1 r_\theta(x, y_r) = 1 rθ(x,yr)=1 )。
-
假设 ( ∂ r θ ( x , y c ) ∂ θ = [ 0.1 , 0.2 ] \frac{\partial r_\theta(x, y_c)}{\partial \theta} = [0.1, 0.2] ∂θ∂rθ(x,yc)=[0.1,0.2] ),( ∂ r θ ( x , y r ) ∂ θ = [ 0.05 , 0.1 ] \frac{\partial r_\theta(x, y_r)}{\partial \theta} = [0.05, 0.1] ∂θ∂rθ(x,yr)=[0.05,0.1] )。
-
( ∂ z ∂ θ = [ 0.1 − 0.05 , 0.2 − 0.1 ] = [ 0.05 , 0.1 ] \frac{\partial z}{\partial \theta} = [0.1 - 0.05, 0.2 - 0.1] = [0.05, 0.1] ∂θ∂z=[0.1−0.05,0.2−0.1]=[0.05,0.1] ),模 ( 0.0 5 2 + 0. 1 2 ≈ 0.112 \sqrt{0.05^2 + 0.1^2} \approx 0.112 0.052+0.12≈0.112 )。
-
( m ( r ) = 0 m(r) = 0 m(r)=0 ):
- ( z = 1 z = 1 z=1 ),( − ( 1 − σ ( 1 ) ) ≈ − 0.269 -(1 - \sigma(1)) \approx -0.269 −(1−σ(1))≈−0.269 ),
- ( ∇ θ L = − 0.269 ⋅ [ 0.05 , 0.1 ] = [ − 0.01345 , − 0.0269 ] \nabla_\theta L = -0.269 \cdot [0.05, 0.1] = [-0.01345, -0.0269] ∇θL=−0.269⋅[0.05,0.1]=[−0.01345,−0.0269] ),
- 模 ( ∣ ∇ θ L ∣ ≈ 0.0301 |\nabla_\theta L| \approx 0.0301 ∣∇θL∣≈0.0301 )。
-
( m ( r ) = 1 m(r) = 1 m(r)=1 ):
- ( z = 0 z = 0 z=0 ),( − ( 1 − σ ( 0 ) ) = − 0.5 -(1 - \sigma(0)) = -0.5 −(1−σ(0))=−0.5 ),
- ( ∇ θ L = − 0.5 ⋅ [ 0.05 , 0.1 ] = [ − 0.025 , − 0.05 ] \nabla_\theta L = -0.5 \cdot [0.05, 0.1] = [-0.025, -0.05] ∇θL=−0.5⋅[0.05,0.1]=[−0.025,−0.05] ),
- 模 ( ∣ ∇ θ L ∣ ≈ 0.0559 |\nabla_\theta L| \approx 0.0559 ∣∇θL∣≈0.0559 )。
梯度模从0.0301增加到0.0559,绝对值确实增大。
6. 直观解释
- 更高的 ( m ( r ) m(r) m(r) ) 像更高的门槛:如果人类说 ( y c y_c yc ) “显著好于” ( y r y_r yr ),模型必须给出更大的奖励差值。当前差值不足时,损失变大,梯度绝对值随之增大,推动模型“努力”调整。
- 梯度绝对值决定更新强度:更大的绝对值意味着参数变化更剧烈,帮助模型更快接近目标。
7. 总结
是的,“梯度的增大”在这里指的是梯度的绝对值(模)增大。更高的 ( m ( r ) m(r) m(r) ) 使 ( z z z ) 减小,( 1 − σ ( z ) 1 - \sigma(z) 1−σ(z) ) 增大,梯度因子 ( − ( 1 − σ ( z ) ) -(1 - \sigma(z)) −(1−σ(z)) ) 的绝对值变大,从而使整个梯度向量的模增大。这反映了模型需要更强的更新信号来满足更高的偏好标准。希望这篇解析能清楚解答你的疑问!
后记
2025年3月1日16点33分于上海,在grok3大模型辅助下完成。
相关文章:

Llama 2中的Margin Loss:为何更高的Margin导致更大的Loss和梯度?
Llama 2中的Margin Loss:为何更高的Margin导致更大的Loss和梯度? 在《Llama 2: Open Foundation and Fine-Tuned Chat Models》论文中,作者在强化学习与人类反馈(RLHF)的Reward Model训练中引入了Margin Loss的概念&a…...

Python----数据分析(Numpy:安装,数组创建,切片和索引,数组的属性,数据类型,数组形状,数组的运算,基本函数)
一、 Numpy库简介 1.1、概念 NumPy(Numerical Python)是一个开源的Python科学计算库,旨在为Python提供 高性能的多维数组对象和一系列工具。NumPy数组是Python数据分析的基础,许多 其他的数据处理库(如Pandas、SciPy)都依赖于Num…...

Android Logcat 高效调试指南
工具概览 Logcat 是 Android SDK 提供的命令行日志工具,支持灵活过滤、格式定制和实时监控,官方文档详见 Android Developer。 基础用法 命令格式 [adb] logcat [<option>] ... [<filter-spec>] ... 执行方式 直接调用(通过ADB守…...

Pytest之fixture的常见用法
文章目录 1.前言2.使用fixture执行前置操作3.使用conftest共享fixture4.使用yield执行后置操作 1.前言 在pytest中,fixture是一个非常强大和灵活的功能,用于为测试函数提供固定的测试数据、测试环境或执行一些前置和后置操作等, 与setup和te…...

如何把网络ip改为动态:全面指南
在数字化时代,网络IP地址作为设备在网络中的唯一标识,扮演着至关重要的角色。随着网络环境的不断变化,静态IP地址的局限性逐渐显现,而动态IP地址则因其灵活性和安全性受到越来越多用户的青睐。那么,如何把网络IP改为动…...

anythingLLM和deepseek4j和milvus组合建立RAG知识库
1、deepseek本地化部署使用 ollama 下载模型 Tags bge-m3 bge-m3:latest deepseek-r1:32b deepseek-r1:8b 2、安装好向量数据库 milvus docker安装milvus单机版-CSDN博客 3、安装 anythingLLM AnythingLLM | The all-in-one AI application for everyone …...

和鲸科技推出人工智能通识课程解决方案,助力AI人才培养
2025年2月,教育部副部长吴岩应港澳特区政府邀请,率团赴港澳宣讲《教育强国建设规划纲要 (2024—2035 年)》。在港澳期间,吴岩阐释了教育强国目标的任务,并与特区政府官员交流推进人工智能人才培养的办法。这一系列行动体现出人工智…...

当我删除word文件时无法删除,提示:操作无法完成,因为已在Microsoft Word中打开
现象: 查看电脑桌面下方的任务栏,明明已经关闭了WPS和WORD软件,但是打开word文档时还是提示: 解决方法步骤: 1、按一下键盘上的ctrl Shift Esc 键打开任务管理器 2、在进程中找到如下: 快速找到的方法…...

高频面试题(含笔试高频算法整理)基本总结回顾3
目录 一、基本面试流程回顾 二、基本高频算法题展示 三、基本面试题总结回顾 (一)Java高频面试题整理 (二)JVM相关面试问题整理 (三)MySQL相关面试问题整理 (四)Redis相关面试…...

Python中字符串的常用操作
一、r原样输出 在 Python 中,字符串前加 r(即 r"string" 或 rstring)表示创建一个原始字符串(raw string)。下面详细介绍原始字符串的特点、使用场景及与普通字符串的对比。 特点 忽略转义字符࿱…...

卷积神经网络(cnn,类似lenet-1,八)
我们第一层用卷积核,前面已经成功,现在我们用两层卷积核: 结构如下,是不是很想lenet-1,其实我们24年就实现了sigmoid版本的: cnn突破九(我们的五层卷积核bpnet网络就是lenet-1)-CS…...

Win32 C++ 电源计划操作
CPowerCfgUtils.h #pragma once#include <Windows.h> #include <powrprof.h>// https://learn.microsoft.com/zh-cn/windows/win32/api/powrprof/?sourcerecommendations//节能 //DEFINE_GUID(GUID_MAX_POWER_SAVINGS, 0xA1841308, 0x3541, 0x4FAB, 0xBC, 0x81, …...

PH热榜 | 2025-03-01
1. Helix 标语:从想法到原型只需3分钟 介绍:Helix可以在几分钟内将你的创业想法变成一个准备好接受投资的原型。你可以创建功能齐全、可点击的用户界面和用户体验设计,完全不需要任何设计技能。 产品网站: 立即访问 Product H…...

如何管理路由器
一、管理路由器的必要性 1、需要修改拨号上网的密码。 2、需要修改WIFI的SSID名字和密码。 3、设置DHCP协议信息。 4、设置IP地址的过滤规则。 5、给某个设备连接设置网络限速。 二、常见的方式 (一)web网页方式 1、计算机用双绞线或者WIFI的方式连接路由器。 2、在计算机中打开…...

deepseek使用记录17
基于《资本论》方法论的"35岁危机"系统分析 一、劳动力商品化与价值贬值的双重绞索 马克思揭示:“劳动力作为商品,其价值由生产劳动力所需的社会必要劳动时间决定”。在数字资本主义时代,这一规律呈现特殊形态: 技能折…...

【Java】I/O 流篇 —— 打印流与压缩流
目录 打印流概述字节打印流构造方法成员方法代码示例 字符打印流构造方法成员方法代码示例 打印流的应用场景 解压缩/压缩流解压缩流压缩流 Commons-io 工具包概述Commons-io 使用步骤Commons-io 常见方法代码示例 Hutool 工具包 打印流 概述 分类:打印流一般是指…...

Tomcat基础知识及其配置
1.Tomcat简介 Tomcat是Apache软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache、Sun和其他一些公司及个人共同开发而成。 Tomcat服务器是一个免费的开放源代码的Web应用服务器,属于轻量级应用服…...

【LeetCode】739.每日温度
目录 题目描述输入输出示例及数据范围思路:单调栈C 实现 题目描述 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这…...

测试金蝶云的OpenAPI
如何使用Postman测试K3Cloud的OpenAPI 1. 引言 在本篇博客中,我将带你逐步了解如何使用Postman测试和使用K3Cloud的OpenAPI。内容包括下载所需的SDK文件、配置文件、API调用及测试等步骤。让我们开始吧! 2. 下载所需的SDK文件 2.1 获取SDK 首先&…...

SID History 域维权
SID History 域林攻击:域林攻击详解-CSDN博客 SID History 根据微软的描述,SID History 属性是微软对域内用户进行域迁移的支持而创建的。每当对象从一个域移动到另一个域时,都会创建一个新的 SID,并且该新 SID 将成为 objectSI…...

unittest自动化测试框架详解
一、Unittest简介 Unittest是python内置的一个单元测试框架,主要用于自动化测试用例的开发与执行 简单的使用如下 import unittestclass TestStringMethods(unittest.TestCase):def setUp(self):print("test start")def test_upper(self):self.assertE…...

ORM Bee V2.5.2.x 发布,支持 CQRS; sql 性能分析;更新 MongoDB ORM分片
Bee, 一个具有分片功能的 ORM 框架. Bee Hibernate/MyBatis plus Sharding JDBC Jpa Spring data GraphQL App ORM (Android, 鸿蒙) 小巧玲珑!仅 940K, 还不到 1M, 但却是功能强大! V2.5.2 (2025・LTS 版) 开发中... **2.5.2.1 新年 ** 支持 Mong…...

关于C/C++的输入和输出
目录 一、C语言中的scanf 有关scanf()的例子 二、C语言中的printf 有关printf()的例子 三、C中的cin、cout 四、字符的输入 1、cin.get() 2、cin.get() 3、cin.getline() 4、getline() 5、getchar() 五、string类型字符串长度 1、length() 2、size() 一、C语言中…...

1-kafka单机环境搭建
本文介绍kafka单机环境的搭建及可视化环境配置,虽然没有java代码,但是麻雀虽小五脏俱全,让大家在整体感官上对kafka有个认识。在文章的最后,我介绍了几个重要的配置参数,供大家参考。 0、环境 kafka:2.8.…...

Qt常用控件之旋钮QDial
旋钮QDial QDial 表示一个旋钮控件。 1. QDial属性 属性说明value当前数值。minimum最小值。maximum最大值。singleStep按下方向键时改变的步长。pageStep按下 pageUp/pageDown 的时候改变的步长。sliderPosition界面上旋钮显示的初始位置。tracking外观是否会跟踪数值变化&…...

基于DeepSeek,构建个人本地RAG知识库
经过一段使用DeepSeek后,感觉使用体验和ChatGPT基本差不多,回答问题的质量略有提升,因DeepSeek已开源,它的模型、模型参数权重从网上都可以下载到,所以可以基于开源的模型,在本地构建一个自己的知识库&…...

散户如何实现自动化交易下单——篇1:体系介绍与获取同花顺资金账户和持仓信息
一、为什么要实现自动化交易 在瞬息万变的金融市场中,越来越多的散户投资者开始尝试构建自己的交易策略:有人通过技术指标捕捉趋势突破,有人利用基本面分析挖掘低估标的,还有人设计出复杂的网格交易或均值回归模型。然而&a…...
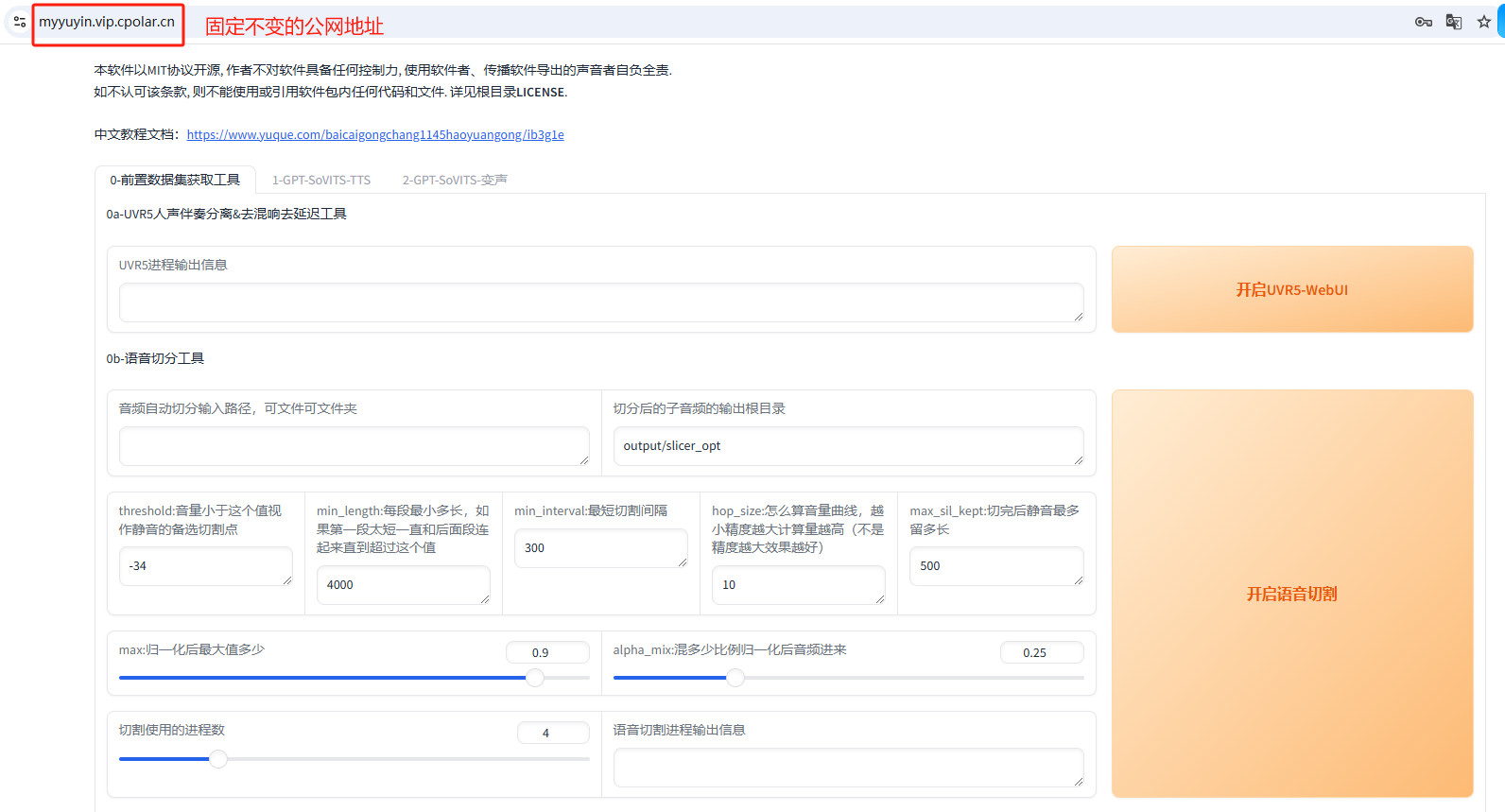
轻松实现语音生成:GPT-SoVITS V2整合包的远程访问操作详解
文章目录 前言1.GPT-SoVITS V2下载2.本地运行GPT-SoVITS V23.简单使用演示4.安装内网穿透工具4.1 创建远程连接公网地址 5. 固定远程访问公网地址 前言 今天要给大家安利一个绝对能让你大呼过瘾的声音黑科技——GPT-SoVITS!这款由花儿不哭大佬精心打造的语音克隆神…...

【微知】git 如何修改某个tag名字?如何根据某个commit创建一个tag?
背景 某些时候git tag名字搞错了,需要修改,如何处理? 删除某个tag git tag -d oldtagname修改某个tag名字 创建新的,删除老的 git tag newtagname git tag -d oldtagname基于某个老的commit创建一个tag git tag V0.1.0 xxxc…...

Java中使用for和Iterator遍历List集合的区别
在 Java 中,遍历 List 可以使用 for 循环 和 Iterator 两种方式。它们各有优缺点,适用于不同的场景。以下是它们的区别和适用场景: 1. 语法和使用方式 for 循环: 使用索引遍历列表。 示例: List<String> li…...