【三维分割】LangSplat: 3D Language Gaussian Splatting(CVPR 2024 highlight)
论文:https://arxiv.org/pdf/2312.16084
代码:https://github.com/minghanqin/LangSplat
文章目录
- 一、3D language field
- 二、回顾 Language Fields的挑战
- 三、使用SAM学习层次结构语义
- 四、Language Fields 的 3DGS
- 五、开放词汇查询(Open-vocabulary Querying)
- 六、实验
- 代码实现
一、3D language field
早期构建三维特征场的尝试包括蒸馏特征场[20]和神经特征融合场[43]。他们通过跨多个视图将LSeg [21]或DINO [4]特征提炼为一个NeRF,学习了3D一致特征。Shen等人[39]通过将clip征提取成NeRF,进一步提取特征场进行few-shot 语言引导的自动操作。[Panoptic lifting for 3d scene understanding with neural fields. CVPR 2023][In-place scene labelling and understanding with implicit scene representation. ICCV 2021]将语义信息嵌入到NeRF中,例如,Semantic NeRF [54]在NeRF中联合编码外观和几何语义,用于新的语义视图合成。LERF [18] 是第一个将CLIP特性嵌入到NeRF中的公司,它利用强大的CLIP表示方式实现了开放词汇表的3D查询。DINO特性也被用于监督LERF,以提高其性能。Liu等人[Weakly supervised 3d open-vocabulary segmentation.NeurIPS 2023]还利用CLIP和DINO特征训练NeRF模型用于3D开放词汇分割。
二、回顾 Language Fields的挑战
输入图像 I ∈ R 3 × H × W I∈R^{3×H×W} I∈R3×H×W;取一组校准图像{ I t ∣ t = 1 , 2 , . . . , T I_t|t=1,2,...,T It∣t=1,2,...,T}作为输入,用其训练一个3D Language Fields Φ Φ Φ。大多数现有的方法使用CLIP编码器 V V V 提取图像特征,监督3D语言字段 Φ Φ Φ,利用CLIP对齐的文本图像潜在空间,促进开放词汇表查询。然而, CLIP嵌入是由图像对齐的,而不是由像素对齐的 。即 V ( I t ) ∈ R D V(I_t)∈R^D V(It)∈RD是一个图像级的特征,而我们需要一个像素对齐的语言嵌入 L t ∈ R D × H × W L_t∈R^{D×H×W} Lt∈RD×H×W。同时,像素对齐的语言特征具有点模糊性 ,对象上的单个点有助于影响区域的多个语义层次(例如,猫耳朵上的一个点,同时指向猫的耳朵、猫头和整个猫,应该被三种类型的文本查询激活)
为了解决问题,现有方法[18,24]从裁剪后的图像patch中提取出CLIP特征的层次结构,即对坐标为 v = ( w , h ) v=(w,h) v=(w,h)的像素,在不同物理尺度下,以v为中心patch中获得相应的CLIP特征,patch可以完全包含对象。多尺度patch方法有两个局限性。首先,patch特征是不精确的,因为它们经常包含额外的上下文对象信息,导致过度平滑的语言域,对象边界模糊。为了缓解不稳定的问题,大多数方法[18,24]利用额外的像素对齐的DINO特性来监督网络。但是,学习到的三维语言特征仍然不精确,如图1所示。其次,推理需要在多个尺度上同时渲染,才能找到最优尺度。随着尺度的数量可能高达30 [18],大大降低了推理速度。
除了渲染目标,三维建模方法的选择也很重要。大多数现有的方法[2,43]都使用NeRF来进行3D表示,它们在每个3D点上学习一个语言特征,然后将该语言特征渲染到图像上,类似于彩色渲染。然而,基于NeRF的方法受到其耗时的渲染过程的限制;同时,在实际应用中,特别是在智能机器人等领域,对高效开放词汇查询的需求也很高。
三、使用SAM学习层次结构语义

SAM 可以准确地将一个像素与周围属于同一对象的像素进行分组,从而将图像分割成多个边界清晰的对象掩模。利用SAM,我们可以捕获三维场景中对象的语义层次,为每个输入图像提供准确和多尺度的分割map。
具体来说,使用32×32的规则网格进行point 提示,获得三个不同语义级别 mask: M 0 s 、 M 0 p 、 M 0 w M_0^s、M_0^p、M_0^w M0s、M0p、M0w,分别代表子部分、部分和整个物体。然后根据IoU评分、stability评分和mask之间的重叠率,去除集合的冗余mask。过滤后的mask 集合为: M s 、 M p 、 M w M^s、M^p、M^w Ms、Mp、Mw,将场景划分为语义上有意义的区域,用于提取区域CLIP特征。在数学上,所获得的像素对齐的语言嵌入为( M l ( v ) M^l (v) Ml(v)表示在语义级别 l l l上,像素 v v v属于的mask):

从3D语言场景中渲染的每个像素,现在都拥有一个与精确的语义上下文相一致的CLIP特性。这种对齐减少了模糊性,并提高了基于语言的查询的准确性。我们可以学习一个准确的三维语言场,即使没有常用的DINO正则化。我们基于SAMs的方法的另一个优点是预定义的 语义尺度。由于我们对“整体”、“部分”和“子部分”级别有不同的分割映射,因此我们可以在这些预定义的尺度上直接查询三维语言字段。这就消除了跨多个绝对尺度进行密集搜索的需要,从而使查询过程更加高效。
四、Language Fields 的 3DGS
在获得了一组二维图像{ L t l ∣ t = 1 , . . . , T L^l_t|t=1,...,T Ltl∣t=1,...,T}上的语言嵌入后,我们可以通过建模三维点和二维像素之间的关系来学习三维语言场景。3DGS明确地将三维场景表示为各向异性三维高斯分布的集合,每个高斯 G ( x ) G (x) G(x) 由均值 µ ∈ R 3 µ∈R^3 µ∈R3和协方差矩阵Σ参数化:

其中 c i c_i ci是第 i i i个高斯值的颜色,N表示tile中的高斯值, C ( v ) C(v) C(v)是像素v处的渲染颜色, α i = o i G i 2 D ( ⋅ ) α_i = o_iG_i^{2D}(·) αi=oiGi2D(⋅)。 o i o_i oi是第 i i i个高斯的不透明度, G i 2 D ( ⋅ ) G_i^{2D}(·) Gi2D(⋅)表示投影到二维上的第i个高斯的函数。
本文提出了3D language GS,它用三个language embedding { f s , f p , f w f^s,f^p,f^w fs,fp,fw}来增强每个3DGS。这些嵌入来自于CLIP特征。增强的高斯函数被称为三维语言高斯,采用基于tile的光栅化器来保持渲染效率:

F l ( v ) F^l(v) Fl(v)表示语义级别 l l l在像素 v v v处渲染的语言嵌入。通过将语言信息直接合并到3DGS中,3DLanguage Fields 能够响应基于语言的查询。
由于CLIP嵌入是高维特征,直接在CLIP潜在空间上学习 f l f^l fl显著增加了内存和时间成本。与学习没有球谐系数的RGB颜色相比,学习512维CLIP特征使存储3D高斯数据的内存需求增加了35倍以上,很容易导致L1 cache内存耗尽。为了降低内存成本和提高效率,我们 引入了一种场景级别的 language autoencoder,将场景中的CLIP嵌入映射到一个较低维的潜在空间,从而减少了内存需求。CLIP模型使用4亿对(图像、文本)对进行训练,它的d维潜在空间可能非常紧凑,因为它需要在这个空间中对齐任意的文本和图像。然而,Language Fields Φ Φ Φ 是特定于场景的,可以利用场景先验来压缩CLIP特征。事实上,对于每个输入图像,我们将得到数百个被SAM mask,明显小于CLIP训练中使用的图像数量。因此,一个场景中所有的mask都稀疏地分布在CLIP潜在空间中,允许我们使用一个场景特定的 Autoencoder进一步压缩这些CLIP特征
编码器 E E E将 D D D维CLIP特征 L t l ( v ) ∈ R D L^l_t(v)∈R^D Ltl(v)∈RD映射到 H t l ( v ) = E ( L t l ( v ) ) ∈ R D H_t^l(v) = E(L^l_t (v))∈R^D Htl(v)=E(Ltl(v))∈RD,其中d≪D。解码器 Ψ Ψ Ψ从压缩表示重构原始CLIP嵌入。Autoencoder 在CLIP嵌入上重建目标为 ( d a e d_{ae} dae表示距离函数,具体采用 l 1 l_1 l1和余弦距离损失):

让Language Gaussian 在特定场景的latent space 中学习 language embedding,而不是CLIP潜在空间,有 f l ∈ R d f^l∈R^d fl∈Rd。实验取d = 3(模型效率和准确性的均衡)。与直接建模D维CLIP嵌入相比,我们的方法通过合并场景先验显著降低了内存成本。语言嵌入的优化目标:

推理遵循等式(4),将language embedding 从3D渲染到2D,并使用场景特定解码器 Ψ Ψ Ψ恢复CLIP图像嵌入 Ψ ( F t l ) ∈ R D × H × W Ψ(F_t^l)∈R^{D×H×W} Ψ(Ftl)∈RD×H×W,这允许使用CLIP文本编码器进行开放词汇表查询。
五、开放词汇查询(Open-vocabulary Querying)
由于CLIP模型提供的图像和文本之间的对齐空间,学到的3D language field 支持开放词汇表3D查询,包括开放词汇表3D对象定位和开放词汇表3D语义分割。许多现有的开放词汇表三维语义分割方法[24]通常从一个类别列表中选择类别,其中包括图像中出现的类别。然而,获得一个全面的野外场景类别列表是具有挑战性的。与它们不同的是,我们的方法在给定任意文本查询时生成精确的对象mask。
按照LERF计算language embeddinig ϕ i m g ϕ_{img} ϕimg 与每个文本查询 ϕ q r y ϕ_{qry} ϕqry的相关性得分(其中, ϕ c a n o n i ϕ^i_{canon} ϕcanoni是从“object”, “things”, “stuff”,
和“texture”中选择的预定义规范短语的CLIP嵌入):

每个文本查询可以得到三个相关性映射,表示在特定的语义级别上的结果。遵循在LERF 的策略,选择产生最高相关性得分的语义level。对于三维对象定位任务,我们直接选择相关性得分最高的点。对于三维语义分割任务,我们过滤出相关性分数低于所选阈值的点,并预测剩余区域的对象mask。
六、实验
数据集。LERF数据集[18]是使用iPhone的app多摄像头捕获的,由复杂的野外场景组成,为三维对象定位任务设计的, 这里我们通过注释文本查询的地面真相掩码来扩展LERF数据集,允许在LERF数据集上评估开放词汇表的三维语义分割。由于用于三维对象定位的原始LERF注释相对简单,因此在某些场景下的性能已经接近饱和。因此,我们进一步手动注释了其他具有挑战性的定位样本,以更好地评估方法的性能。我们报告了在LERF [18]后的三维对象定位任务的定位精度,并报告了三维语义分割任务的IoU结果。 我们还使用了3DOVS数据集[24],包含了不同pose和背景下捕获的长尾对象的集合。这个数据集是为开放词汇表三维语义分割开发的,其中提供了完整的类别列表。 其他方法使用完整的列表来生成预测的掩码,而我们只使用查询类别来生成相应的掩码。mIoU度量用于这个数据集
实验细节。图像语言特征提取,使用OpenCLIP ViT-B/16模型;SAM使用ViT-H模型来分割二维mask;每个场景先使用3DGS来训练一个RGB,训练3万次迭代,每个场景都包含大约250万个点;然后固定三维高斯的所有其他参数,如均值和不透明度来训练我们的三维language gaussian。在这个阶段,只有语言特征是可学习的。语言特性训练3万次迭代,Autoencoder由一个MLP实现512维的CLIP特征压缩;1440×1080分辨率的场景,模型在NVIDIA RTX-3090 GPU上进行了25分钟训练,大约需要4GB的内存。
LERF数据集上算法对比。表1:算法达到84.3%的总体准确率,优于LERF;表2显示了三维语义分割的IoU结果,比LERF好14.0%

可视化分析。图1按照[20]PCA成分分析,可视化了学习到的三维language field。可以看到,LERF学习到的特征不能生成物体之间的清晰的边界,而我们的方法仅使用CLIP特征给出精确的物体形状。图3和图4中展示了对象定位和语义分割的可视化结果。我们观察到,LERF产生的激活区域更分散,而我们的激活区域更集中,与LERF产生的激活区域相比,我们的激活区域可以更好地符合真实形状



消融实验:

代码实现
- 安装环境
# 1.克隆项目到本地
git clone https://github.com/minghanqin/LangSplat.git --recursive# 2.安装依赖包
conda env create --file environment.yml
conda activate langsplat# 3.安装 sam
pip install git+https://github.com/facebookresearch/segment-anything.git
# 4.克隆并安装 segment-anything-langsplat
git clone https://github.com/minghanqin/segment-anything-langsplat.git
cd segment-anything-langsplat
pip install .
- 准备数据(数据应为以下格式)
<dataset_name>
|---images
| |---<image 0>
| |---<image 1>
| |---...
|---input
| |---<image 0>
| |---<image 1>
| |---...
|---output
| |---<dataset_name>
| | |---point_cloud/iteration_30000/point_cloud.ply
| | |---cameras.json
| | |---cfg_args
| | |---chkpnt30000.pth
| | |---input.ply
|---sparse|---0|---cameras.bin|---images.bin|---points3D.bin
- 开始训练(分为5步执行,可直接执行process.sh)
# 1: 生成场景的 Language Feature。图片需要放在 <dataset_name>中的"input" 文件夹
python preprocess.py --dataset_path data/lego(这是我自己的路径) # 2.训练 Autoencoder,得到低维的 3-dims Language Feature
cd autoencoder
python train.py --dataset_path /home/xzz/LangSplat/data/lego(这是我自己的路径) --dataset_name lego --encoder_dims 256 128 64 32 3 --decoder_dims 16 32 64 128 256 256 512 --lr 0.0007python test.py --dataset_name $dataset_path --output
# 3.最终训练语言场for level in 1 2 3
dopython train.py -s $dataset_path -m output/${casename} --start_checkpoint $dataset_path/$casename/chkpnt30000.pth --feature_level ${level}# e.g. python train.py -s data/sofa -m output/sofa --start_checkpoint data/sofa/sofa/chkpnt30000.pth --feature_level 3
done# 4.对不同level分割结果的渲染
for level in 1 2 3
do# render rgbpython render.py -m output/${casename}_${level}# render language featurespython render.py -m output/${casename}_${level} --include_feature# e.g. python render.py -m output/sofa_3 --include_feature
done相关文章:
【三维分割】LangSplat: 3D Language Gaussian Splatting(CVPR 2024 highlight)
论文:https://arxiv.org/pdf/2312.16084 代码:https://github.com/minghanqin/LangSplat 文章目录 一、3D language field二、回顾 Language Fields的挑战三、使用SAM学习层次结构语义四、Language Fields 的 3DGS五、开放词汇查询(Open-voca…...

如何使用 Jenkins 实现 CI/CD 流水线:从零开始搭建自动化部署流程
如何使用 Jenkins 实现 CI/CD 流水线:从零开始搭建自动化部署流程 在软件开发过程中,持续集成(CI)和持续交付(CD)已经成为现代开发和运维的标准实践。随着代码的迭代越来越频繁,传统的手动部署方式不仅低效,而且容易出错。为了提高开发效率和代码质量,Jenkins作为一款…...

【HarmonyOS Next】鸿蒙应用折叠屏设备适配方案
【HarmonyOS Next】鸿蒙应用折叠屏设备适配方案 一、前言 目前应用上架华为AGC平台,都会被要求适配折叠屏设备。目前华为系列的折叠屏手机,有华为 Mate系列(左右折叠,华为 Mate XT三折叠),华为Pocket 系列…...

Spark内存迭代计算
一、宽窄依赖 窄依赖:父RDD的一个分区数据全部发往子RDD的一个分区 宽依赖:父RDD的一个分区数据发往子RDD的多个分区,也称为shuffle 二、Spark是如何进行内存计算的?DAG的作用?Stage阶段划分的作用? &a…...

数据库基础二(数据库安装配置)
打开MySQL官网进行安装包的下载 https://www.mysql.com/ 接着找到适用于windows的版本 下载版本 直接点击下载即可 接下来对应的内容分别是: 1:安装所有 MySQL 数据库需要的产品; 2:仅使用 MySQL 数据库的服务器; 3&a…...

HumanPro逼真角色皮肤面部动画Blender插件V1.1版
https://www.youtube.com/watch?vnmV_jzgpIPM 本插件是关于HumanPro逼真角色皮肤面部动画Blender插件V1.1版,大小:2.9 MB,支持Blender 4.0 - 4.3版软件,支持Win系统,语言:英语。RRCG分享 HumanPro 是一款…...

基于javaweb的SSM+Maven幼儿园管理系统设计和实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论…...

PyTorch内存优化的10种策略总结:在有限资源环境下高效训练模型
在大规模深度学习模型训练过程中,GPU内存容量往往成为制约因素,尤其是在训练大型语言模型(LLM)和视觉Transformer等现代架构时。由于大多数研究者和开发者无法使用配备海量GPU内存的高端计算集群,因此掌握有效的内存优化技术变得尤为关键。本…...

SQL打折日期交叉问题
1. 数据结构:数据为平台商品促销数据 表名:good_promotion 字段名:brand(品牌)、stt(打折开始日期)、edt(打折结束日期)。 2. 需求: ① 创建表 ② 计算每个…...

【湖北省计算机信息系统集成协会主办,多高校支持 | ACM出版,EI检索,往届已见刊检索】第二届边缘计算与并行、分布式计算国际学术会议(ECPDC 2025)
第二届边缘计算与并行、分布式计算国际学术会议(ECPDC 2025)将于2025年4月11日至13日在中国武汉盛大召开。本次会议旨在为边缘计算、并行计算及分布式计算领域的研究人员、学者和行业专家提供一个高水平的学术交流平台。 随着物联网、云计算和大数据技术…...

硬件工程师入门教程
1.欧姆定律 测电压并联使用万用表测电流串联使用万用表,红入黑出 2.电阻的阻值识别 直插电阻 贴片电阻 3.电阻的功率 4.电阻的限流作用 限流电阻阻值的计算 单位换算关系 5.电阻的分流功能 6.电阻的分压功能 7.电容 电容简单来说是两块不连通的导体加上中间的绝…...

性能测试监控工具jmeter+grafana
1、什么是性能测试监控体系? 为什么要有监控体系? 原因: 1、项目-日益复杂(内部除了代码外,还有中间件,数据库) 2、一个系统,背后可能有多个软/硬件组合支撑,影响性能的因…...
DeepSeek如何快速开发PDF转Word软件
一、引言 如今,在线工具的普及让PDF转Word成为了一个常见需求,常见的PDF转Word工具有收费的WPS,免费的有PDFGear(详见:PDFGear:一款免费的PDF编辑、格式转化软件-CSDN博客),以及在线工具SmallP…...

目标检测——数据处理
1. Mosaic 数据增强 Mosaic 数据增强步骤: (1). 选择四个图像: 从数据集中随机选择四张图像。这四张图像是用来组合成一个新图像的基础。 (2) 确定拼接位置: 设计一个新的画布(输入size的2倍),在指定范围内找出一个随机点(如…...

基于springboot+vue的拖恒ERP-物资管理
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...

python容器之常用操作
以列表list为例,这个list相当于c中的数组或vector容器。那列表有哪些常用的操作呢? 获取列表的长度 list [1,2,3,4,5] //获取列表的长度 length len(list) 注意这里与c不同,c中的容器都是有各自的定义,每种容器类型都实现了自…...

spring结合mybatis多租户实现单库分表
实现单库分表-水平拆分 思路:student表数据量大,所以将其进行分表处理。一共有三个分表,分别是student0,student1,student2,在新增数据的时候,根据请求头中的meta-tenant参数决定数据存在哪张表…...

YoloV8改进策略:Block改进|CBlock,Transformer式的卷积结构|即插即用
摘要 论文标题: SparseViT: Nonsemantics-Centered, Parameter-Efficient Image Manipulation Localization through Spare-Coding Transformer 论文链接: https://arxiv.org/pdf/2412.14598 官方GitHub: https://github.com/scu-zjz/SparseViT 这段代码出自SparseViT ,代码如…...

微服务架构实践:SpringCloud与Docker容器化部署
## 微服务架构实践:SpringCloud与Docker容器化部署 随着互联网应用的复杂性不断增加,传统的单体应用架构面临着诸多挑战,如难以部署、维护困难、开发效率低下等问题凸显出来。为了解决这些问题,微服务架构应运而生,它通…...

如何从零开始理解LLM训练理论?预训练范式、模型推理与扩容技巧全解析
Part 1:预训练——AI的九年义务教育 📚 想象你往峨眉山猴子面前扔了1000本《五年高考三年模拟》-我那时候还在做的题(海量互联网数据),突然有一天它开口唱起《我在东北玩泥巴》,这有意思的过程就是LLM的预…...

[原创]openwebui解决searxng通过接口请求不成功问题
openwebui 对接 searxng 时 无法查询到联网信息,使用bing搜索,每次返回json是正常的 神秘代码: http://172.30.254.200:8080/search?q北京市天气&formatjson&languagezh&time_range&safesearch0&languagezh&locale…...

8 SpringBootWeb(下):登录效验、异步任务和多线程、SpringBoot中的事务管理@Transactional
文章目录 案例-登录认证1. 登录功能1.1 需求1.2 接口文档1.3 思路分析1.4 功能开发1.5 测试2. 登录校验2.1 问题分析2.2 会话技术2.2.1 会话技术介绍2.2.2 会话跟踪方案2.2.2.1 方案一 - Cookie2.2.2.2 方案二 - Session2.2.2.3 方案三 - 令牌技术2.2.3 JWT令牌(Token)2.2.3.…...
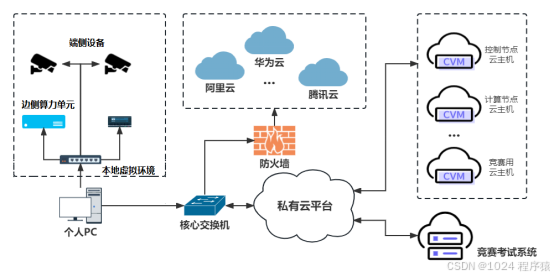
2025年山东省职业院校技能大赛(高职组)“云计算应用”赛项赛卷1
“云计算应用”赛项赛卷1 2025年山东省职业院校技能大赛(高职组)“云计算应用”赛项赛卷1模块一 私有云(30分)任务1 私有云服务搭建(5分)1.1.1 基础环境配置1.1.2 yum源配置1.1.3 配置无秘钥ssh1.1.4 基础安…...

MySQL数据库基本概念
目录 什么是数据库 从软件角度出发 从网络角度出发 MySQL数据库的client端和sever端进程 mysql的client端进程连接sever端进程 mysql配置文件 MySql存储引擎 MySQL的sql语句的分类 数据库 库的操作 创建数据库 不同校验规则对查询的数据的影响 不区分大小写 区…...

塔能科技:工厂智慧照明,从底层科技实现照明系统的智能化控制
在全球节能减碳和智慧生活需求激增的背景下,基于“用软件定义硬件,让物联运维更简捷更节能”的产品理念,塔能科技的智慧照明一体化方案如新星般崛起,引领照明行业新方向。现在,我们来深入探究其背后的创新技术。该方案…...

P3398 仓鼠找 sugar【题解】
这是LCA的一个应用,关于LCA P3398 仓鼠找 sugar 题目描述 小仓鼠的和他的基(mei)友(zi)sugar 住在地下洞穴中,每个节点的编号为 1 ∼ n 1\sim n 1∼n。地下洞穴是一个树形结构。这一天小仓鼠打算从从他…...

解决VirtualBox - Error In supR3HardenedWinReSpawn报错
问题描述 VirtualBox7.1.6启动虚拟机时报错: Error In supR3HardenedWinReSpawn NtCreateFile(\Device\VBoxDrvStub) failed: 0xc000000034 STATUS_OBJECT_NAME_NOT_FOUND (0 retries) (rc-101) Make sure the kernel module has been loaded successfully.原因分…...
Android Trace埋点beginSection打tag标签,Kotlin
Android Trace埋点beginSection打tag标签,Kotlin import android.os.Bundle import android.os.Trace import android.util.Log import androidx.appcompat.app.AppCompatActivityclass ImageActivity : AppCompatActivity() {companion object {const val TRACE_TA…...

Linux上用C++和GCC开发程序实现两个不同MySQL实例下单个Schema稳定高效的数据迁移到其它MySQL实例
设计一个在Linux上运行的GCC C程序,同时连接三个不同的MySQL实例,其中两个实例中分别有两个Schema的表结构分别与第三实例中两个Schema个结构完全相同,同时复制两个实例中两个Schema里的所有表的数据到第三个实例中两个Schema里,使…...

Lua的table(表)
Lua表的基本概念 Lua中的表(table)是一种多功能数据结构,可以用作数组、字典、集合等。表是Lua中唯一的数据结构机制,其他数据结构如数组、列表、队列等都可以通过表来实现。 表的实现 Lua的表由两部分组成: 数组部分…...