LeetCode 热题 100_寻找两个正序数组的中位数(68_4_困难_C++)(二分查找)(先合并再挑选中位数;划分数组(二分查找))
LeetCode 热题 100_寻找两个正序数组的中位数(68_4)
- 题目描述:
- 输入输出样例:
- 题解:
- 解题思路:
- 思路一(先合并再挑选中位数):
- 思路二(划分数组(二分查找)):
- 代码实现
- 代码实现(思路一(先合并再挑选中位数)):
- 代码实现(思路二(划分数组(二分查找))):
- 以思路二为例进行调试
题目描述:
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
输入输出样例:
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
提示:
nums1.length== m
nums2.length == n
0 <= m <= 1000
0 <= n <= 1000
1 <= m + n <= 2000
-106 <= nums1[i], nums2[i] <= 106
题解:
解题思路:
思路一(先合并再挑选中位数):
1、因两个数组是有序,可以通过两个指针将两个数组进行合并,在进行合并时每次挑选一个较小的元素进行合并。合并后再挑选中位数,如果合并后元素个数为奇数,则返回中间的元素。如果为偶数则返回中间两个元素的平均数。
2、复杂度分析:
① 时间复杂度:O(m+n),m和n分别为两个有序数组元素的个数。合并两个有序数组的时间复杂度为O(m+n)。查找合并后的中位数时间为O(1)。
② 空间复杂度:O(m+n),需要一个额外的数组来存储合并后的数组。
思路二(划分数组(二分查找)):
1、我们首先考虑一个有序数组取中位数的情况:nums=[2,3,4,6,8,9,10,12,18,20] , n=10。
我们可以将分隔线放在8和9之间:[2,3,4,6,8 | 9 ,10,12,18,20]。(当元素个数为奇数时,左侧元素多1)
将nums拆分成两个数组(分隔线的情况如下):
nums1=[3,8 | 9,10]
nums2=[2,4,6 | 12,18,20]
将nums拆分成两个数组(分隔线的情况如下):
nums1=[2,3,4 |]
nums2=[6,8 | 9,10,12,18,20]
发现其中的规律:
① 分隔线的左侧元素值小于右侧元素值,且当前数组右侧的元素值大于另一个数组左侧的元素值。
② 分隔线左侧的元素个数(两个数组)等于分隔线右侧的元素个数或者左侧比右侧多一个元素。
③ 中位数一定在分隔线的左右两侧元素中选取。
2、通过分析出的规律可得出解题的步骤如下:
① 确定 nums1 中的分隔线(二分查找),再通过分隔线左右两侧元素的个数关系,确定 nums2 中的分隔线。
② 确定分隔线后,若nums1中左侧元素 > nums2中的右侧元素,则nums1中的分隔线需左移减小nums1中左侧元素的值(这里和下方的左侧元素和右侧元素指的是分隔线相邻的元素)。
③ 确定分隔线后,若nums2中左侧元素 > nums1中的右侧元素,则nums1中的分隔线需右移,增大nums1中右侧元素的值。
④ 确定分隔线后,若nums1中左侧元素 <= nums2中的右侧元素,且nums2中左侧元素 <= nums1中的右侧元素。若两个数组元素总和为奇数则输出左侧元素的最大值(nums1和nums2分隔线左侧)。若两个数组元素总和为偶数则输出左侧元素的最大值(nums1和nums2分隔线左侧)+右侧元素的最小值 再除以 2。
官方的视频题解链接(挺不错的)
3、复杂度分析
① 时间复杂度:O(logmin(m,n))),其中 m 和 n 分别是数组 nums1和 nums2 的长度,只对其中较小的数组进行二分查找。
② 空间复杂度:O(1)。
代码实现
代码实现(思路一(先合并再挑选中位数)):
class Solution1 {
public:double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {// 初始化指针 i, j 用于遍历 nums1 和 nums2,k 用于遍历合并后的数组 mergeint i = 0, j = 0, k = 0;// 创建一个合并后的数组 merge,其大小为 nums1 和 nums2 长度之和vector<int> merge(nums1.size() + nums2.size());// 合并两个已排序的数组 nums1 和 nums2 到 merge 数组中while (i < nums1.size() && j < nums2.size()) {// 比较 nums1 和 nums2 中当前元素的大小,选择较小的元素放入 merge 数组if (nums1[i] <= nums2[j]) {merge[k++] = nums1[i++]; // 将 nums1 的当前元素放入 merge 中} else {merge[k++] = nums2[j++]; // 将 nums2 的当前元素放入 merge 中}}// 如果 nums1 中还有剩余的元素,继续加入 merge 数组while (i < nums1.size()) {merge[k++] = nums1[i++];}// 如果 nums2 中还有剩余的元素,继续加入 merge 数组while (j < nums2.size()) {merge[k++] = nums2[j++];}// 计算合并后数组的中位数索引int mid = (nums1.size() + nums2.size()) / 2;// 如果合并后的数组长度为奇数,中位数就是中间的那个元素if ((nums1.size() + nums2.size()) % 2 == 1) {return double(merge[mid]); // 返回 merge[mid],直接返回该值} else {// 如果合并后的数组长度为偶数,中位数是中间两个数的平均值return double(merge[mid - 1] + merge[mid]) / 2; // 计算并返回平均值} }
};
代码实现(思路二(划分数组(二分查找))):
class Solution2 {
public:double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {// 确保 nums1 是较小的数组,以减少二分查找的次数if (nums1.size() > nums2.size()) {return findMedianSortedArrays(nums2, nums1);}int m = nums1.size(); // nums1 的大小int n = nums2.size(); // nums2 的大小int left = 0, right = m; // 在 nums1 数组上进行二分查找的左、右边界// 使用二分查找在较小的数组 nums1 中查找合适的分区while (left <= right) {// 计算 nums1 的分区点int partition1 = (left + right) / 2;// 计算 nums2 的分区点,使得左右两部分元素数量相等或相差1int partition2 = (m + n + 1) / 2 - partition1;// 计算分区后的左右部分的最大值和最小值// nums1 左侧最大值int maxLeft1 = (partition1 == 0) ? INT_MIN : nums1[partition1 - 1];// nums1 右侧最小值int minRight1 = (partition1 == m) ? INT_MAX : nums1[partition1];// nums2 左侧最大值int maxLeft2 = (partition2 == 0) ? INT_MIN : nums2[partition2 - 1];// nums2 右侧最小值int minRight2 = (partition2 == n) ? INT_MAX : nums2[partition2];// 判断分区是否有效if (maxLeft1 <= minRight2 && maxLeft2 <= minRight1) {// 有效分区,计算中位数if ((m + n) % 2 == 0) {// 如果总元素个数是偶数,中位数为左右最大值和最小值的平均值return (max(maxLeft1, maxLeft2) + min(minRight1, minRight2)) / 2.0;} else {// 如果总元素个数是奇数,中位数为左侧的最大值return max(maxLeft1, maxLeft2);}} // 如果 maxLeft1 > minRight2,说明 partition1 太大,需要向左缩小else if (maxLeft1 > minRight2) {right = partition1 - 1; // 调整右边界} // 如果 maxLeft2 > minRight1,说明 partition1 太小,需要向右扩大else {left = partition1 + 1; // 调整左边界}}// 如果没有找到合适的中位数,代码逻辑应达到这里,可能代表输入不符合条件return 0.0; // 通过编译需要添加返回值}
};
以思路二为例进行调试
#include<iostream>
#include <vector>
#include <algorithm>
using namespace std;class Solution2 {
public:double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {// 确保 nums1 是较小的数组,以减少二分查找的次数if (nums1.size() > nums2.size()) {return findMedianSortedArrays(nums2, nums1);}int m = nums1.size(); // nums1 的大小int n = nums2.size(); // nums2 的大小int left = 0, right = m; // 在 nums1 数组上进行二分查找的左、右边界// 使用二分查找在较小的数组 nums1 中查找合适的分区while (left <= right) {// 计算 nums1 的分区点int partition1 = (left + right) / 2;// 计算 nums2 的分区点,使得左右两部分元素数量相等或相差1int partition2 = (m + n + 1) / 2 - partition1;// 计算分区后的左右部分的最大值和最小值// nums1 左侧最大值int maxLeft1 = (partition1 == 0) ? INT_MIN : nums1[partition1 - 1];// nums1 右侧最小值int minRight1 = (partition1 == m) ? INT_MAX : nums1[partition1];// nums2 左侧最大值int maxLeft2 = (partition2 == 0) ? INT_MIN : nums2[partition2 - 1];// nums2 右侧最小值int minRight2 = (partition2 == n) ? INT_MAX : nums2[partition2];// 判断分区是否有效if (maxLeft1 <= minRight2 && maxLeft2 <= minRight1) {// 有效分区,计算中位数if ((m + n) % 2 == 0) {// 如果总元素个数是偶数,中位数为左右最大值和最小值的平均值return (max(maxLeft1, maxLeft2) + min(minRight1, minRight2)) / 2.0;} else {// 如果总元素个数是奇数,中位数为左侧的最大值return max(maxLeft1, maxLeft2);}} // 如果 maxLeft1 > minRight2,说明 partition1 太大,需要向左缩小else if (maxLeft1 > minRight2) {right = partition1 - 1; // 调整右边界} // 如果 maxLeft2 > minRight1,说明 partition1 太小,需要向右扩大else {left = partition1 + 1; // 调整左边界}}// 如果没有找到合适的中位数,代码逻辑应达到这里,可能代表输入不符合条件return 0.0; // 通过编译需要添加返回值}
};int main(int argc, char const *argv[])
{vector<int> nums1={1,2};vector<int> nums2={3,4};Solution2 s2;cout<<s2.findMedianSortedArrays(nums1,nums2);return 0;
}
寻找两个正序数组的中位数(68_4)原题链接
欢迎大家和我沟通交流(✿◠‿◠)
相关文章:
(二分查找)(先合并再挑选中位数;划分数组(二分查找)))
LeetCode 热题 100_寻找两个正序数组的中位数(68_4_困难_C++)(二分查找)(先合并再挑选中位数;划分数组(二分查找))
LeetCode 热题 100_寻找两个正序数组的中位数(68_4) 题目描述:输入输出样例:题解:解题思路:思路一(先合并再挑选中位数):思路二(划分数组(二分查找…...

MyBatis-Plus 为简化开发而生【核心功能】
文章目录 一、前言二、快速入门1. 入门案例2. 常见注解3. 常见配置 三、核心功能1. 条件构造器2. 自定义 SQL3. Service 接口3.1 基本使用3.2 复杂条件 一、前言 顾名思义,MyBatis-Plus 其实是 MyBatis 的一个加强版,它可以帮助我们快速高效地编写数据库…...

【MySQL】(2) 库的操作
SQL 关键字,大小写不敏感。 一、查询数据库 show databases; 注意加分号,才算一句结束。 二、创建数据库 {} 表示必选项,[] 表示可选项,| 表示任选其一。 示例:建议加上 if not exists 选项。 三、字符集编码和排序…...
通信原理速成笔记(信息论及编码)
信息论基础 信息的定义与度量 信息是用来消除不确定性的内容。例如,在猜硬币正反的情境中,结果存在正反两种不确定性,而得知正确结果能消除这种不确定性,此结果即为信息。单个事件的信息量:对于离散信源中的事件xi&…...

云和恩墨亮相PolarDB开发者大会,与阿里云深化数据库服务合作
2025年2月26日,备受瞩目的阿里云PolarDB开发者大会于北京嘉瑞文化中心盛大举行,众多行业精英齐聚一堂,共襄技术盛会。云和恩墨作为阿里云重要的生态合作伙伴受邀参会。云和恩墨联合创始人兼技术研究院总经理杨廷琨与阿里云智能数据库产品事业…...

kafka consumer 手动 ack
在消费 Kafka 消息时,手动确认(acknowledge)消息的消费,可以通过使用 KafkaConsumer 类中的 commitSync() 或 commitAsync() 方法来实现。这些方法将提交当前偏移量,确保在消费者崩溃时不会重新消费已处理的消息。 以…...

final 关键字在不同上下文中的用法及其名称
1. final 变量 名称:final 变量(常量)。 作用:一旦赋值后,值不能被修改。 分类: final 实例变量:必须在声明时或构造函数中初始化。 final 静态变量:必须在声明时或静态代码块中初…...

PHP面试题--后端部分
本文章持续更新内容 之前没来得及整理时间问题导致每次都得找和重新背 这次整理下也方便各位小伙伴一起更轻松的一起踏入编程之路 欢迎各位关注博主不定期更新各种高质量内容适合小白及其初级水平同学一起学习 一起成为大佬 数组函数有那些 ps:本题挑难的背因为…...

Python 高精度计算利器:decimal 模块详解
Python 高精度计算利器:decimal 模块详解 在 Python 编程中,处理浮点数时,标准的 float 类型往往会因二进制表示的特性而产生精度问题。decimal 模块应运而生,它提供了十进制浮点运算功能,能让开发者在需要高精度计算…...

hbase相关问题处理
1.如果遇到ZK宕机,通过HTable和Connection两种连接方式获取数据,在实现原理和故障恢复上有何异同? 通过new HTable方式,则每次方法调用都会建立新的连接,而且会从zk获取表的元数据,会导致将业务的并发传导到zookeeper服务,会对全局所有依赖zookeeper服务的节点存在一定…...

Linux下的网络通信编程
在不同主机之间,进行进程间的通信。 1解决主机之间硬件的互通 2.解决主机之间软件的互通. 3.IP地址:来区分不同的主机(软件地址) 4.MAC地址:硬件地址 5.端口号:区分同一主机上的不同应用进程 网络协议…...
?为何这类攻击被视为高风险威胁?)
什么是“零日漏洞”(Zero-Day Vulnerability)?为何这类攻击被视为高风险威胁?
正文 零日漏洞(Zero-Day Vulnerability) 是指软件、硬件或系统中存在的、尚未被开发者发现或修复的安全漏洞。攻击者在开发者意识到漏洞存在之前(即“零日”内)利用该漏洞发起攻击,因此得名。这类漏洞的“零日”特性使…...

AI数据分析:用DeepSeek做数据清洗
在当今数据驱动的时代,数据分析已成为企业和个人决策的重要工具。随着人工智能技术的快速发展,AI 驱动的数据分析工具正在改变我们处理和分析数据的方式。本文将着重介绍如何使用 DeepSeek 进行数据清洗。 数据清洗是数据分析的基础,其目的是…...
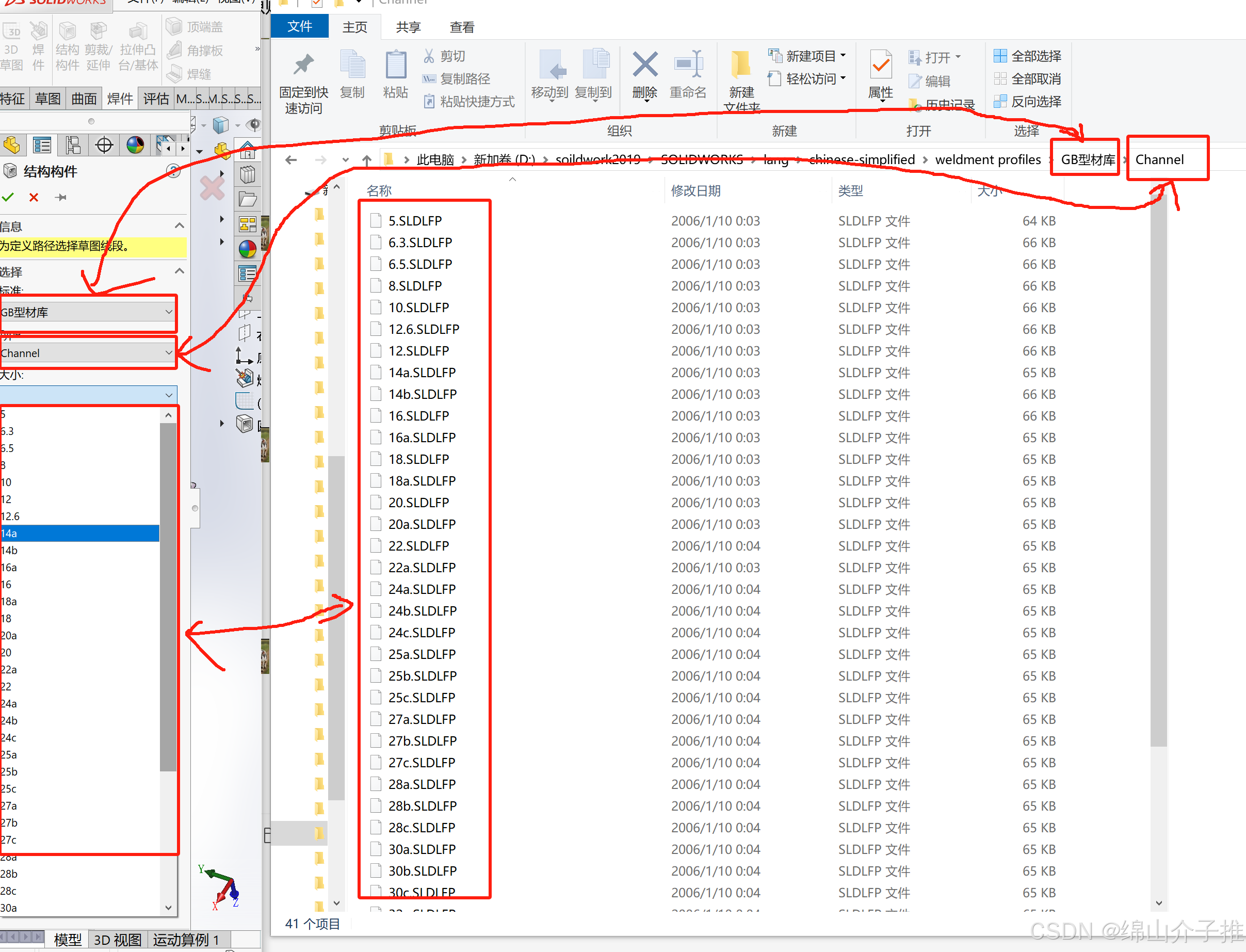
把GB型材库放入solidwork中点击库无法应
1、文件夹的位置要选择对,如下图: 2、文件夹一定要嵌套三层,如下图...

【前端】XML,XPATH,与HTML的关系
XML与HTML关系 XML(可扩展标记语言)和 HTML(超文本标记语言)是两种常见的标记语言,但它们有不同的目的和用途。它们都使用类似的标记结构(标签),但在设计上存在一些关键的差异。 XML…...

IP-----动态路由OSPF(2)
这只是IP的其中一块内容,IP还有更多内容可以查看IP专栏,前一章内容为动态路由OSPF ,可通过以下路径查看IP-----动态路由OSPF-CSDN博客,欢迎指正 注意!!!本部分内容较多所以分成了两部分在上一章 5.动态路…...

《HelloGitHub》第 107 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣、入门级的开源项目。 github.com/521xueweihan/HelloGitHub 这里有实战项目、入门教程、黑科技、开源书籍、大厂开源项目等,涵盖多种编程语言 Python、…...

leetcode_字典树 139. 单词拆分
139. 单词拆分 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。 注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。 思路: 定义状态: 设dp[i]表…...

计算机毕业设计Python+DeepSeek-R1大模型游戏推荐系统 Steam游戏推荐系统 游戏可视化 游戏数据分析(源码+文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

网络流算法: Dinic算法
图论相关帖子 基本概念图的表示: 邻接矩阵和邻接表图的遍历: 深度优先与广度优先拓扑排序图的最短路径:Dijkstra算法和Bellman-Ford算法最小生成树二分图多源最短路径强连通分量欧拉回路和汉密尔顿回路网络流算法: Edmonds-Karp算法网络流算法: Dinic算法 环境要求 本文所用…...

【Springboot】解决问题 o.s.web.servlet.PageNotFound : No mapping for *
使用 cursor 进行老项目更新为 springboot 的 web 项目,发生了奇怪的问题,就是 html 文件访问正常,但是静态文件就是 404 检查了各种配置,各种比较,各种调试,最后放弃时候,清理没用的配置文件&…...

Spring Boot 3.x 基于 Redis 实现邮箱验证码认证
文章目录 依赖配置开启 QQ 邮箱 SMTP 服务配置文件代码实现验证码服务邮件服务接口实现执行流程 依赖配置 <dependencies> <!-- Spring Boot Starter Web --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spr…...

PostgreSQL10 物理流复制实战:构建高可用数据库架构!
背景 PostgreSQL 10 在高可用架构中提供了物理复制,也称为流复制(Streaming Replication),用于实现实例级别的数据同步。PostgreSQL 复制机制主要包括物理复制和逻辑复制:物理复制依赖 WAL 日志进行物理块级别的同步&…...

从零开始开发纯血鸿蒙应用之语音朗读
从零开始开发纯血鸿蒙应用 〇、前言一、API 选型1、基本情况2、认识TextToSpeechEngine 二、功能集成实践1、改造右上角菜单2、实现语音播报功能2.1、语音引擎的获取和关闭2.2、设置待播报文本2.3、speak 目标文本2.4、设置语音回调 三、总结 〇、前言 中华汉字洋洋洒洒何其多…...
基本概念之Queue)
RabbitMQ系列(五)基本概念之Queue
在 RabbitMQ 中,Queue(队列) 是存储消息的容器,也是消息传递的核心载体。以下是其核心特性与作用的全方位解析: 一、Queue 的定义与核心作用 消息存储容器 Queue 是 RabbitMQ 中实际存储消息的实体,生产者…...

奔图Pantum M7165DN黑白激光打印一体机报数据清除中…维修
故障描述: 一台奔图Pantum M7165DN黑白激光打印一体机开机自检正常,自检过后就不能工作了,按键面板无任何反应一直提示数据清除中…,如果快速操作的话也能按出菜单、功能啥的,不过一会又死机了,故障请看下图: 故障检修: 经分析可能是主板数据出现了问题,看看能不能快速…...

TP-LINK路由器如何设置网段、网关和DHCP服务
目标 ①将路由器的网段由192.168.1.XXX改为192.168.5.XXX ②确认DHCP是启用的,并将DHCP的IP池的范围设置为排除自己要手动指定的IP地址,避免IP冲突。 01-复位路由器 路由器按住复位键10秒以上进行重置操作 02-进入路由器管理界面 电脑连接到路由器&…...

神经网络代码入门解析
神经网络代码入门解析 import torch import matplotlib.pyplot as pltimport randomdef create_data(w, b, data_num): # 数据生成x torch.normal(0, 1, (data_num, len(w)))y torch.matmul(x, w) b # 矩阵相乘再加bnoise torch.normal(0, 0.01, y.shape) # 为y添加噪声…...

设计一个“车速计算”SWC,通过Sender-Receiver端口输出车速信号。
1. 需求分析 功能目标:根据车轮脉冲信号(轮速传感器输入)计算当前车速,并将结果通过Sender端口发送给其他SWC。 输入:轮速脉冲数(如WheelPulse,类型uint32)。 输出:车速(如VehicleSpeed,类型float32,单位km/h)。 触发方式:周期性计算(例如每10ms执行一次)。 2.…...

TCP/IP 5层协议簇:网络层(IP数据包的格式、路由器原理)
目录 1. TCP/IP 5层协议簇 2. IP 三层包头协议 3. 路由器原理 4. 交换机和路由的对比 1. TCP/IP 5层协议簇 如下: 2. IP 三层包头协议 数据包如下:IP包头不是固定的,每一个数字是一个bit 其中数据部分是上层的内容,IP包头最…...